
3D Shape Generation via Variational Autoencoder with Signed Distance Function Relativistic Average Generative Adversarial Network


Abstract
:1. Introduction
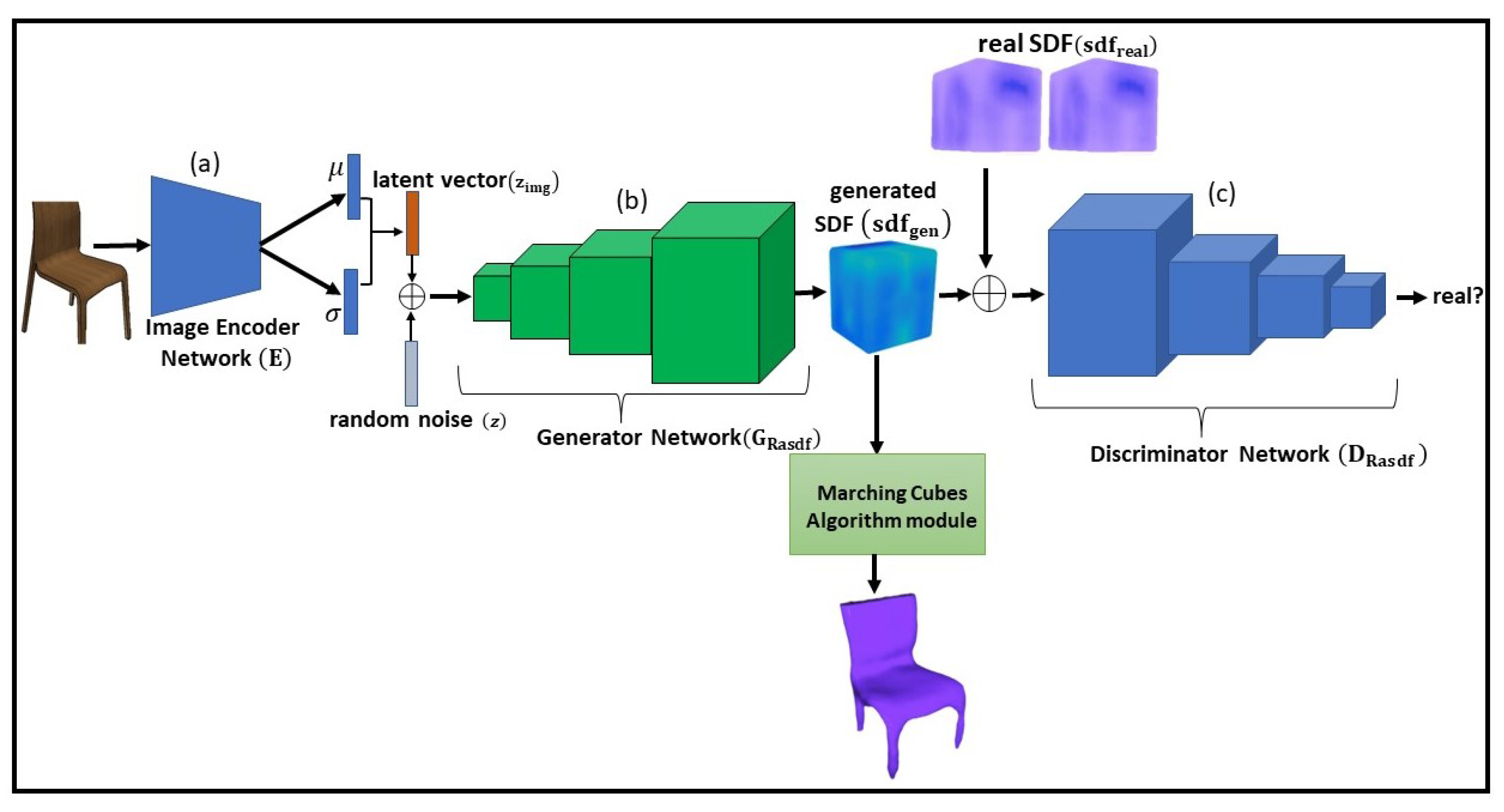
- VAE and GAN are integrated to enable the simultaneous learning of encoding, generating, and comparing data. The proposed method explicitly learns the latent spaces of 2D images, which are then used to generate corresponding signed distance functions of objects and reconstruct them into high-quality 3D mesh-based shapes.
- A relativistic average GAN loss function is proposed to enhance the stability of the GAN training process, leading to a better convergence with the VAE-GAN framework.
- The proposed 3D-VAE-SDFRaGAN model not only generates high-quality 3D shapes from their corresponding 2D images but also achieves superior results compared to other state-of-the-art 3D shape generative methods.
2. Related Work
2.1. Modeling and Generation of 3D Shapes
2.2. 3D Shape Generation via Deep Neural Networks
2.3. 3D Shape Generation with Signed Distance Functions
2.4. Improving GAN Training for Quality 3D Model Generation
3. Proposed 3D-VAE-SDFRaGAN
3.1. 2D Image and 3D SDF Dataset Generation
3.2. VAE, GAN, and VAE-GAN
3.3. 3D-VAE-SDFRaGAN Framework
3.3.1. 2D-Image Encoder Network
3.3.2. SDF-Generator and SDF-Discriminator Networks
4. Experiments
4.1. Training Procedure
4.2. Performance Evaluation
5. Limitations and Future Directions
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. ShapeNet: An Information-Rich 3D Model Repository. arXiv 2015, arXiv:1512.03012. [Google Scholar]
- Xiang, Y.; Kim, W.; Chen, W.; Ji, J.; Choy, C.; Su, H.; Mottaghi, R.; Guibas, L.; Savarese, S. Objectnet3D: A large scale database for 3D object recognition. In Proceedings of the Computer Vision—ECCV 2016 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 160–176. [Google Scholar] [CrossRef]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D ShapeNets: A deep representation for volumetric shapes. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar] [CrossRef]
- Fu, H.; Jia, R.; Gao, L.; Gong, M.; Zhao, B.; Maybank, S.; Tao, D. 3D-FUTURE: 3D Furniture Shape with TextURE. Int. J. Comput. Vis. 2021, 129, 3313–3337. [Google Scholar] [CrossRef]
- Rezende, D.J.; Ali Eslami, S.M.; Mohamed, S.; Battaglia, P.; Jaderberg, M.; Heess, N. Unsupervised learning of 3D structure from images. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 5003–5011. [Google Scholar]
- Wu, J.; Zhang, C.; Xue, T.; Freeman, W.T.; Tenenbaum, J.B. Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling. CVGIP Graph. Model. Image Process. 2016, 53, 157–185. [Google Scholar] [CrossRef]
- Smith, E.; Meger, D. Improved Adversarial Systems for 3D Object Generation and Reconstruction. In Proceedings of the Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017; pp. 87–96. [Google Scholar]
- Zhu, J.; Xie, J.; Fang, Y. Learning Adversarial 3D Model Generation with 2D Image Enhancer; AAAI: Palo Alto, CA, USA, 2018; pp. 7615–7622. [Google Scholar]
- Fan, H.; Guibas, L. DeepPointSet: A Point Set Generation Network for 3D Object Reconstruction from a Single Image Supplementary Material. In Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1–4. [Google Scholar]
- Yang, G.; Huang, X.; Hao, Z.; Liu, M.Y.; Belongie, S.; Hariharan, B. Pointflow: 3D point cloud generation with continuous normalizing flows. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4540–4549. [Google Scholar] [CrossRef]
- Liu, H.; Yuan, H.; Hou, J.; Hamzaoui, R.; Gao, W. PUFA-GAN: A Frequency-Aware Generative Adversarial Network for 3D Point Cloud Upsampling. IEEE Trans. Image Process. 2022, 31, 7389–7402. [Google Scholar] [CrossRef] [PubMed]
- Tan, Q.; Gao, L.; Lai, Y.K.; Xia, S. Variational Autoencoders for Deforming 3D Mesh Models. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5841–5850. [Google Scholar] [CrossRef]
- Feng, Y.; Feng, Y.; You, H.; Zhao, X.; Gao, Y. MeshNet: Mesh neural network for 3D shape representation. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27–28 January 2019; pp. 8279–8286. [Google Scholar] [CrossRef]
- Cheng, S.; Bronstein, M.; Zhou, Y.; Kotsia, I.; Pantic, M.; Zafeiriou, S. MeshGAN: Non-linear 3D Morphable Models of Faces. arXiv 2019, arXiv:1903.10384. [Google Scholar]
- Li, H.; Zheng, Y.; Wu, X.; Cai, Q. 3D Model Generation and Reconstruction Using Conditional Generative Adversarial Network. Int. J. Comput. Intell. Syst. 2019, 12, 697. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Adv. Neural Inf. Process. Syst. 2014, 177, 326–333. [Google Scholar] [CrossRef]
- Roberts, L.G. Machine Perception of Three-Dimensional Solids. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 1963. [Google Scholar]
- Marr, D.; Ullman, S. A Computational Investigation into the Human Representation and Processing of Visual Information; Technical Report; Henry Holt and Co. Inc.: New York, NY, USA, 1982. [Google Scholar]
- Sung, M.; Kim, V.G.; Angst, R.; Guibas, L. Data-Driven Structural Priors for Shape Completion. ACM Trans. Graph. 2015, 34, 1–11. [Google Scholar] [CrossRef]
- Sundar, H.; Silver, D.; Gagvani, N.; Dickinson, S. Skeleton based shape matching and retrieval. In Proceedings of the SMI 2003: Shape Modeling International 2003, Seoul, Republic of Korea, 12–16 May 2003; pp. 130–139. [Google Scholar] [CrossRef]
- Li, C.; Zia, M.Z.; Tran, Q.H.; Yu, X.; Hager, G.D.; Chandraker, M. Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5465–5474. [Google Scholar]
- Miao, Y.; Hu, F.; Zhang, X.; Chen, J.; Pajarola, R. SymmSketch: Creating symmetric 3D free-form shapes from 2D sketches. Comput. Vis. Media 2015, 1, 3–16. [Google Scholar] [CrossRef]
- Huang, H.; Kalogerakis, E.; Marlin, B. Analysis and synthesis of 3D shape families via deep-learned generative models of surfaces. Eurographics Symp. Geom. Process. 2015, 34, 25–38. [Google Scholar] [CrossRef]
- Jones, R.K.; Barton, T.; Xu, X.; Wang, K.; Jiang, E.; Guerrero, P.; Mitra, N.J.; Ritchie, D. ShapeAssembly: Learning to Generate Programs for 3D Shape Structure Synthesis. ACM Trans. Graph. 2020, 39, 3417812. [Google Scholar] [CrossRef]
- Wang, K.; Guerrero, P.; Kim, V.; Chaudhuri, S.; Sung, M.; Ritchie, D. The Shape Part Slot Machine: Contact-Based Reasoning for Generating 3D Shapes from Parts. In Computer Vision—ECCV 2022, Proceedings of the 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Technical Report; Springer Nature Switzerland: Cham, Switzerland, 2022; pp. 610–626. [Google Scholar]
- Kar, A.; Tulsiani, S.; Carreira, J.; Malik, J. Category-specific object reconstruction from a single image. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1966–1974. [Google Scholar] [CrossRef]
- Girdhar, R.; Fouhey, D.F.; Rodriguez, M.; Gupta, A. Learning a predictable and generative vector representation for objects. In Proceedings of the Computer Vision—ECCV 2016 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 484–499. [Google Scholar] [CrossRef]
- Park, J.J.; Florence, P.; Straub, J.; Newcombe, R.; Lovegrove, S. Deepsdf: Learning continuous signed distance functions for shape representation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 165–174. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Springenberg, J.T.; Brox, T. Learning to generate chairs with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1538–1546. [Google Scholar]
- Choy, C.B.; Xu, D.; Gwak, J.Y.; Chen, K.; Savarese, S. 3D-R2N2: A unified approach for single and multi-view 3D object reconstruction. In Proceedings of the Computer Vision—ECCV 2016 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 628–644. [Google Scholar] [CrossRef]
- Denton, E.; Chintala, S.; Szlam, A.; Fergus, R. Deep Generative Image Models Using a Laplacian Pyramid of Adversarial Networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–10. [Google Scholar]
- Gadelha, M.; Maji, S.; Wang, R. 3D shape induction from 2D views of multiple objects. In Proceedings of the 2017 International Conference on 3D Vision, 3DV 2017, Qingdao, China, 10–12 October 2017; pp. 402–411. [Google Scholar] [CrossRef]
- Li, R.; Li, X.; Hui, K.H.; Fu, C.W. SP-GAN: Sphere-guided 3D shape generation and manipulation. ACM Trans. Graph. 2021, 40, 3459766. [Google Scholar] [CrossRef]
- Gao, J.; Shen, T.; Wang, Z.; Chen, W.; Yin, K.; Li, D.; Litany, O.; Gojcic, Z.; Fidler, S. GET3D: A Generative Model of High Quality 3D Textured Shapes Learned from Images. Adv. Neural Inf. Process. Syst. 2022, 35, 31841–31854. [Google Scholar]
- Shen, B.; Yan, X.; Qi, C.R.; Najibi, M.; Deng, B.; Guibas, L.; Zhou, Y.; Anguelov, D. GINA-3D: Learning to Generate Implicit Neural Assets in the Wild. arXiv 2023, arXiv:2304.02163. [Google Scholar]
- Jiang, C.M.; Marcus, P. Hierarchical Detail Enhancing Mesh-Based Shape Generation with 3D Generative Adversarial Network. In Proceedings of the 2006 IEEE International Conference on Acoustics Speech and Signal Processing, Toulouse, France, 14–19 May 2006. [Google Scholar] [CrossRef]
- Kingkan, C.; Hashimoto, C. Generating Mesh-based Shapes from Learned Latent Spaces of Point Clouds with VAE-GAN. In Proceedings of the International Conference on Pattern Recognition, Beijing, China, 20–24 August 2018; pp. 308–313. [Google Scholar] [CrossRef]
- Zheng, X.Y.; Liu, Y.; Wang, P.S.; Tong, X. SDF-StyleGAN: Implicit SDF-Based StyleGAN for 3D Shape Generation. Comput. Graph. Forum 2022, 41, 52–63. [Google Scholar] [CrossRef]
- Wang, W.; Huang, Q.; You, S.; Yang, C.; Neumann, U. Shape Inpainting Using 3D Generative Adversarial Network and Recurrent Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2298–2306. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved Techniques for Training GANs. arXiv 2016, arXiv:1606.03498. [Google Scholar]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets. arXiv 2016, arXiv:1606.03657. [Google Scholar]
- Doersch, C. Tutorial on Variational Autoencoders. arXiv 2016, arXiv:1606.05908. [Google Scholar]
- Osher, S.; Fedkiw, R. Signed Distance Functions. In Level Set Methods and Dynamic Implicit Surfaces. Applied Mathematical Sciences; Springer: New York, NY, USA, 2003; Volume 153, pp. 17–22. [Google Scholar] [CrossRef]
- Larsen, A.B.L.; Sønderby, S.K.; Larochelle, H.; Winther, O. Autoencoding Beyond Pixels Using a Learned Similarity Metric. Int. Conf. Mach. Learn. 2015, 29, 1558–1566. [Google Scholar]
- Lewiner, T.; Lopes, H.; Vieira, A.W.; Tavares, G. Efficient Implementation of Marching Cubes’ Cases with Topological Guarantees. J. Graph. Tools 2003, 8, 1–15. [Google Scholar] [CrossRef]
- Wang, N.; Zhang, Y.; Li, Z.; Fu, Y.; Liu, W.; Jiang, Y.G. Pixel2Mesh: Generating 3D Mesh Models from Single RGB Images. In Proceedings of the Computer Vision—ECCV 2018 15th European Conference, Munich, Germany, 8–14 September 2018; pp. 55–71. [Google Scholar] [CrossRef]
- Genova, K.; Cole, F.; Vlasic, D.; Sarna, A.; Freeman, W.; Funkhouser, T. Learning shape templates with structured implicit functions. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7153–7163. [Google Scholar] [CrossRef]
- Kato, H.; Ushiku, Y.; Harada, T. Neural 3D Mesh Renderer. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Remelli, E.; Lukoianov, A.; Richter, S.R.; Guillard, B.; Bagautdinov, T.; Baque, P.; Fua, P. MeshSDF: Differentiable Iso-Surface Extraction. Adv. Neural Inf. Process. Syst. 2020, 33, 22468–22478. [Google Scholar]
- Xu, Q.; Wang, W.; Ceylan, D.; Mech, R.; Neumann, U. DISN: Deep Implicit Surface Network for High-Quality Single-View 3D Reconstruction. arXiv 2019, arXiv:1905.10711. [Google Scholar]
- Trevithick, A.; Yang, B. GRF: Learning a General Radiance Field for 3D Representation and Rendering. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seattle, WA, USA, 13–19 June 2020; pp. 15182–15192. [Google Scholar]
- Genova, K.; Cole, F.; Sud, A.; Sarna, A.; Funkhouser, T. Local Deep Implicit Functions for 3D Shape. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4856–4865. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Criteria | Approach | Architecture | Training Data | Input Data Type | Output Data Type | Performance | Computational Complexity | Limitation | Future Work |
|---|---|---|---|---|---|---|---|---|---|
| SymmSketch [22] | Algorithmic | Symmetry-aware algorithm | 2D sketches | 2D sketches | Symmetric 3D shapes | Fast generation of symmetric 3D shapes with limited input | Low | Not suitable for non-symmetric shapes | Improving the ability to generate 3D shapes from multiple viewpoints |
| AS3DS-DLGM [23] | Deep Learning | Generative model of surfaces | 3D shapes within a family | 3D meshes | 3D meshes | Accurate generation of diverse 3D shapes within a family | High | Requires a large amount of training data | Exploring ways to generate higher-quality shapes with more user control |
| ShapeAss [24] | Deep Learning | CNNs, LSTM | Database of 3D parts and their assembly rules | Parts and assembly rules | 3D meshes | High structural integrity of complex 3D shapes | High | Requires a large library of parts and complex reasoning algorithms | Investigating methods for reducing the computational complexity |
| 3D ShapeNet [3] | Deep learning based volumetric shape representation | CNN | Volumetric 3D shapes | Voxelized 3D shapes | Voxelized 3D shapes | Can generate high-quality 3D shapes with complex structures | High | Can be memory-intensive and computationally expensive | Improving the ability to generate 3D shapes from multiple viewpoints |
| SP-GAN [33] | Sphere-guided 3D shape generation | GAN with a sphere-guided generator | Volumetric 3D shapes | 2D image + sphere representation | Voxelized 3D shapes | Can generate high-quality 3D shapes with better user control | High | Generated shapes may not be visually consistent with the input data | Investigating methods for reducing the computational complexity |
| PrGAN [32] | 3D shape generation from 2D views and manipulation | Multi-view CNN | 2D images of multiple objects from various viewpoints | 2D images | Voxelized 3D shapes | Can generate 3D shapes from limited 2D views with moderate quality | Moderate | The generated shapes may be limited by the quality and diversity of the input images | Exploring ways to generate higher-quality shapes with more user control |
| GET3D [34] | Generative model of 3D textured shapes learned from images | GAN with a novel 3D convolutional architecture | 3D textured shapes from various viewpoints | RGB images | 3D textured meshes | Can generate high-quality 3D textured meshes | High | Computationally intensive and requires significant computational resources, including high-end GPUs and large amounts of memory | Investigating ways to improve the texture quality and resolution of generated meshes |
| 3D-VAE-GAN [6] | Generative adversarial modeling of 3D shapes | GAN with a 3D generator and discriminator | 2D images and corresponding 3D shapes | Voxelized 3D shapes | Voxelized 3D shapes | Can generate high-quality 3D shapes with a probabilistic latent space | High | The generated shapes may be limited by the quality and diversity of the input images | Exploring ways to better control the probabilistic latent space for generating 3D shapes |
| MSVAE-GAN [37] | Generative Model | VAE-GAN | Point cloud + SDF | Point cloud | Meshes | Can generate high-quality 3D shapes with complex structures | Moderate | Requires a large amount of training data to accurately capture the underlying shape distribution | Incorporation of semantic labels |
| HDEM-3DGAN [36] | Generative Model | 3D-GAN | Latent vector + SDF | SDF | Meshes | Can generate 3D shapes from limited 2D views with moderate quality | High | Computationally expensive, it may be challenging to incorporate user-defined constraints or preferences into the generated shapes | Improved hierarchical representation |
| Ours | Generative Model | VAE-SDFRaGAN | 2D images + SDF | 2D image | Meshes | Can generate high-quality 3D shapes with better user | Moderate | It requires a large amount of training data and computational resources | Incorporation of texture and colour |
| Criteria | 3D-VAE-IWGAN [7] | InfoGAN [41] | Ours |
|---|---|---|---|
| Approach | Generative Model | Generative Model | Generative Model |
| Architecture | VAE-IWGAN-based | GAN-based | VAE-SDFRaGAN-based |
| Training Data | 2D images and corresponding 3D voxels | Latent vector and 3D Face dataset | 2D images and corresponding 3D shapes |
| Input Data Type | 2D images | 3D Face, 2D Images | 2D Images |
| Output Data Type | 3D voxels | Meshes | Meshes |
| Performance | High-quality 3D shape generation, smooth interpolation between shapes, controllable output via latent space manipulation | Disentangles latent factors for interpretable representations, can learn without explicit supervision | Fast training and generation, good visual quality, can handle large-scale 3D shapes |
| Adversarial Loss | Wasserstein GAN (WGAN) | GAN | Relativistic Average GAN (RaGAN) |
| Training Approach | Iterative Optimization | Adversarial and Mutual Information | Iterative Optimization |
| Benefits | High-quality 3D object generation, improved stability | Interpretable Latent Code, improved Stability | Improved 3D shape generation, improved stability |
| Latent Code Interpretability | Limited (WGAN) | High | High |
| Limitation | May suffer from mode collapse and instability during training | May require a larger number of training samples to achieve optimal performance | May require more complex pre-processing steps to convert 3D shapes into 2D images and signed distance functions |
| Potential Applications | Computer graphics, gaming, medical imaging, and virtual reality | Image synthesis, feature extraction | Computer graphics, gaming, medical imaging, and virtual reality |
| Categories | Size (Pixel) |
|---|---|
| Chair, Table, Car, Lamb, Sofa, Cabinet | 64 × 64 |
| Category | 3D-R2N2 [30] | SIF [47] | N3MR [48] | MeshSDF [49] | DISN [50] | Ours |
|---|---|---|---|---|---|---|
| Chair | 1.432 | 1.540 | 2.084 | 0.590 | 0.754 | 0.589 |
| Table | 1.116 | 1.570 | 2.383 | 1.070 | 1.329 | 0.672 |
| Car | 0.845 | 1.080 | 2.298 | 0.960 | 0.492 | 0.491 |
| Lamb | 4.009 | 3.420 | 3.013 | 1.490 | 2.273 | 0.662 |
| Sofa | 1.135 | 0.800 | 3.512 | 0.780 | 0.871 | 0.566 |
| Cabinet | 0.750 | 1.100 | 2.555 | 0.780 | 1.130 | 0.314 |
| Average | 1.545 | 1.585 | 2.641 | 0.945 | 1.142 | 0.578 |
| Criteria | 3D-R2N2 [30] | SIF [47] | N3MR [48] | MeshSDF [49] | DISN [50] | Ours |
|---|---|---|---|---|---|---|
| Approach | Multi-view reconstruction using 3D convolutional neural networks | Reconstruction using implicit functions and shape templates | Rendering 3D shapes from learned feature maps | Reconstruction using implicit functions and iso-surface extraction | Reconstruction using implicit functions and single-view input | Learning a generative model for 3D shapes via 2D images |
| Architecture | 2D-CNN + 3D-LSTM + 3D-DCNN | Multi-layer perceptron | Neural network with geometric encoding | Multi-layer perceptron | Convolutional neural network | VAE-SDFRaGAN |
| Dataset | ShapeNet and PASCAL 3D | ShapeNet | ShapeNet | ShapeNet | ShapeNet | ShapeNet |
| Training Data | Set of 2D views with corresponding 3D shapes | 3D shapes | 3D mesh models | 3D mesh represented as SDFs | 3D shapes | 2D images and corresponding 3D shapes |
| Input Data Type | 2D images of an object from different viewpoints | Stack of depth images around the mesh | 3D mesh | SDF | 2D images | 2D images |
| Output Data Type | Volumetric 3D shape | Learned shape templates | 3D mesh | 3D meshes | 3D meshes | 3D meshes |
| Performance | Utilizes a 3D recurrent neural network to generate a 3D voxel grid from a 2D image or a sequence of images | Learns a 3D shape template from a set of 3D shapes using implicit functions | Uses a neural network to estimate the visibility of each vertex and generates the 2D image using a differentiable renderer | Uses a differentiable iso-surface extraction algorithm to generate the SDF and trains a neural network to approximate the SDF | Uses a deep neural network to estimate the implicit function and generates the 3D mesh using marching cubes | Can generate high-quality 3D meshes with complex structure |
| Computational Complexity | High | Low | High | Low | Low | High |
| Limitation | Limited to objects that can be approximated by a set of primitive shapes | Limited to learning shapes that can be described by implicit functions | Limited to rendering objects that have a corresponding mesh representation | Limited to shapes that can be represented by a signed distance function | Limited to learning shapes that can be represented by implicit functions | It requires a large amount of training data and computational resources |
| Potential Future Work | Improving the accuracy and resolution of the reconstructed 3D models | Incorporating texture information into the model | Improving the efficiency and speed of the rendering process | Improving the model’s robustness to handle noise and outliers in the input data | Investigating the use of more complex neural network architectures to improve the model’s accuracy and efficiency | Incorporating texture, Incorporating semantic labels |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ajayi, E.A.; Lim, K.M.; Chong, S.-C.; Lee, C.P. 3D Shape Generation via Variational Autoencoder with Signed Distance Function Relativistic Average Generative Adversarial Network. Appl. Sci. 2023, 13, 5925. https://doi.org/10.3390/app13105925
Ajayi EA, Lim KM, Chong S-C, Lee CP. 3D Shape Generation via Variational Autoencoder with Signed Distance Function Relativistic Average Generative Adversarial Network. Applied Sciences. 2023; 13(10):5925. https://doi.org/10.3390/app13105925
Chicago/Turabian StyleAjayi, Ebenezer Akinyemi, Kian Ming Lim, Siew-Chin Chong, and Chin Poo Lee. 2023. "3D Shape Generation via Variational Autoencoder with Signed Distance Function Relativistic Average Generative Adversarial Network" Applied Sciences 13, no. 10: 5925. https://doi.org/10.3390/app13105925