
Optimization of the Join between Large Tables in the Spark Distributed Framework

Abstract
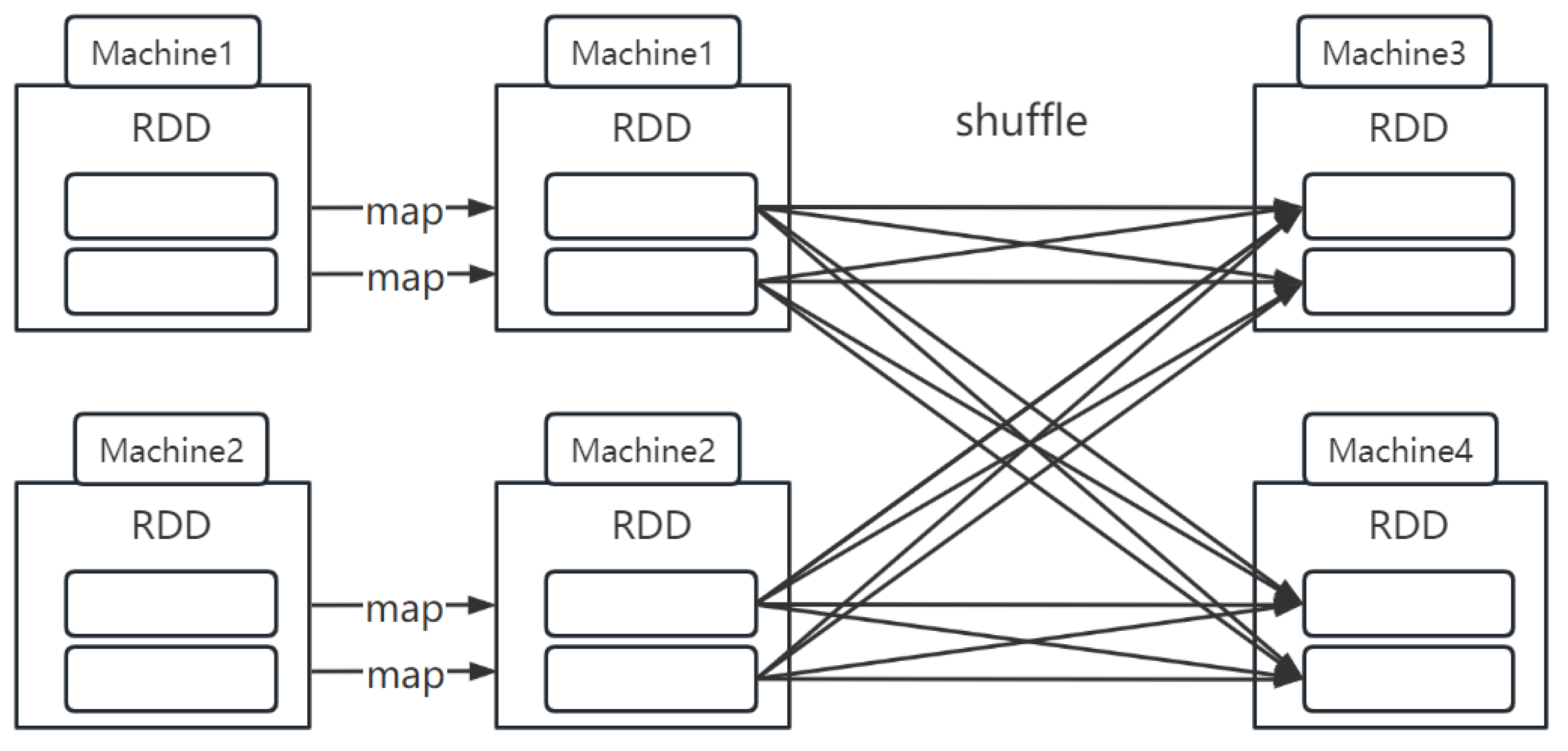
:1. Introduction
2. Related Work
3. Related Technologies
3.1. RoaringBitmap Algorithm
3.2. Spark Accumulator
3.3. Spark Broadcast Variable
4. Optimization of Project Analysis
4.1. Cost Optimization Estimation
4.2. Optimization of Work Content
5. Experiment
5.1. System Configuration
5.2. Testing Dataset
5.3. Experimental Results and Analysis
5.3.1. First Round of Experiments
5.3.2. Second Round of Experiments
5.3.3. Summary and Analysis of Experiments
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Salloum, S.; Dautov, R.; Chen, X.; Peng, P.X.; Huang, J.Z. Big data analytics on Apache Spark. Int. J. Data Sci. Anal. 2016, 1, 145–164. [Google Scholar] [CrossRef]
- Zaharia, M.; Chowdhury, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Spark: Cluster computing with working sets. In Proceedings of the 2nd USENIX Workshop on Hot Topics in Cloud Computing (HotCloud 10), Boston, MA, USA, 22–25 June 2010; HotCloud: Berkeley, CA, USA, 2010. [Google Scholar]
- Zaharia, M.; Xin, R.S.; Wendell, P.; Das, T.; Armbrust, M.; Dave, A.; Meng, X.; Rosen, J.; Venkataraman, S.; Franklin, M.J.; et al. Apache spark: A unified engine for big data processing. Commun. ACM 2016, 59, 56–65. [Google Scholar] [CrossRef]
- Carbone, P.; Katsifodimos, A.; Ewen, S.; Markl, V.; Haridi, S.; Tzoumas, K. Apache flink: Stream and batch processing in a single engine. Bull. Tech. Comm. Data Eng. 2015, 38, 28–38. [Google Scholar]
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Dean, J.; Ghemawat, S. MapReduce: A flexible data processing tool. Commun. ACM 2010, 53, 72–77. [Google Scholar] [CrossRef]
- Asad, M.; Asif, M.U.; Khan, A.A.; Allam, Z.; Satar, M.S. Synergetic effect of entrepreneurial orientation and big data analytics for competitive advantage and SMEs performance. In Proceedings of the 2022 International Conference on Decision Aid Sciences and Applications (DASA), Chiangrai, Thailand, 23–25 March 2022. [Google Scholar]
- Asad, M.; Asif, M.U.; Bakar, L.J.; Altaf, N. Entrepreneurial orientation, big data analytics, and SMEs performance under the effects of environmental turbulence. In Proceedings of the 2021 International Conference on Data Analytics for Business and Industry (ICDABI). Sakheer, Bahrain, 25–26 October 2021. [Google Scholar]
- Zaharia, M.; Chowdhury, M.; Das, T.; Dave, A.; Ma, J.; McCauly, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing. In Proceedings of the 9th USENIX Symposium on Networked Systems Design and Implementation (NSDI), San Jose, CA, USA, 25–27 April 2012; pp. 15–28. [Google Scholar]
- Chambi, S.; Lemire, D.; Kaser, O.; Godin, R. Better bitmap performance with roaring bitmaps. Softw. Pract. Exp. 2016, 46, 709–719. [Google Scholar] [CrossRef]
- Ren, R.; Wu, C.; Fu, Z.; Song, T.; Liu, Y.; Qi, Z.; Guan, H. Efficient shuffle management for DAG computing frameworks based on the FRQ model. J. Parallel Distrib. Comput. 2021, 149, 163–173. [Google Scholar] [CrossRef]
- Li, C.; Cai, Q.; Luo, Y. Data balancing-based intermediate data partitioning and check point-based cache recovery in Spark environment. J. Supercomput. 2022, 78, 3561–3604. [Google Scholar] [CrossRef]
- Kumar, S.; Mohbey, K.K. A Utility-Based Distributed Pattern Mining Algorithm with Reduced Shuffle Overhead. IEEE Trans. Parallel Distrib. Syst. 2022, 34, 416–428. [Google Scholar] [CrossRef]
- Choi, J.; Lee, J.; Kim, J.S.; Lee, J. Optimization Techniques for a Distributed In-Memory Computing Platform by Leveraging SSD. Appl. Sci. 2021, 11, 8476. [Google Scholar] [CrossRef]
- Tang, Z.; Zeng, A.; Zhang, X.; Yang, L.; Li, K. Dynamic memory-aware scheduling in spark computing environment. J. Parallel Distrib. Comput. 2020, 141, 10–22. [Google Scholar] [CrossRef]
- Zeidan, A.; Vo, H.T. Efficient spatial data partitioning for distributed kNN joins. J. Big Data 2022, 9, 77. [Google Scholar] [CrossRef]
- Zhao, Y.; Dong, J.; Liu, H.; Wu, J.; Liu, Y. Performance improvement of dag-aware task scheduling algorithms with efficient cache management in spark. Electronics 2021, 10, 1874. [Google Scholar] [CrossRef]
- Tang, Z.; Lv, W.; Li, K.; Li, K. An intermediate data partition algorithm for skew mitigation in spark computing environment. IEEE Trans. Cloud Comput. 2018, 9, 461–474. [Google Scholar] [CrossRef]
- Jiang, K.; Du, S.; Zhao, F.; Huang, Y.; Li, C.; Luo, Y. Effective data management strategy and RDD weight cache replacement strategy in Spark. Comput. Commun. 2022, 194, 66–85. [Google Scholar] [CrossRef]
- Bazai, S.U.; Jang-Jaccard, J.; Alavizadeh, H. Scalable, high-performance, and generalized subtree data anonymization approach for Apache Spark. Electronics 2021, 10, 589. [Google Scholar] [CrossRef]
- Modi, A.; Rajan, K.; Thimmaiah, S.; Jain, P.; Mann, S.; Agarwal, A.; Shetty, A.; Gosalia, A.; Partho, P. New query optimization techniques in the Spark engine of Azure synapse. Proc. VLDB Endow. 2021, 15, 936–948. [Google Scholar] [CrossRef]
- Chen, Z.; Yao, B.; Wang, Z.J.; Zhang, W.; Zheng, K.; Kalnis, P.; Tang, F. ITISS: An efficient framework for querying big temporal data. GeoInformatica 2020, 24, 27–59. [Google Scholar] [CrossRef]
- Shen, M.; Zhou, Y.; Singh, C. Magnet: Push-based shuffle service for large-scale data processing. Proc. VLDB Endow. 2020, 13, 3382–3395. [Google Scholar] [CrossRef]
- Qalati, S.A.; Qureshi, N.A.; Ostic, D.; Sulaiman, M.A. An extension of the theory of planned behavior to understand factors influencing Pakistani households’ energy-saving intentions and behavior: A mediated–moderated model. Energy Effic. 2022, 15, 40. [Google Scholar] [CrossRef]
- Lim, J.; Kim, B.; Lee, H.; Choi, D.; Bok, K.; Yoo, J. An Efficient Distributed SPARQL Query Processing Scheme Considering Communication Costs in Spark Environments. Appl. Sci. 2021, 12, 122. [Google Scholar] [CrossRef]
- Hammami, S.M.; Ahmed, F.; Johny, J.; Sulaiman, M.A. Impact of knowledge capabilities on organizational performance in the private sector in Oman: An SEM approach using path analysis. Int. J. Knowl. Manag. (IJKM) 2021, 17, 15–18. [Google Scholar] [CrossRef]
- Thusoo, A.; Sarma, J.S.; Jain, N.; Shao, Z.; Chakka, P.; Anthony, S.; Murthy, R. Hive: A Warehousing Solution over A Map-Reduce Framework. Proc. VLDB Endow 2009, 2, 1626–1629. [Google Scholar] [CrossRef]
- Vavilapalli, V.K.; Murthy, A.C.; Douglas, C.; Agarwal, S.; Konar, M.; Evans, R.; Graves, T.; Lowe, J.; Shah, H.; Seth, S.; et al. Apache Hadoop YARN: Yet another resource negotiator. In Proceedings of the 4th Annual Symposium on Cloud Computing, Santa Clara, CA, USA, 1–3 October 2013. [Google Scholar]
- Shvachko, K.; Kuang, H.; Radia, S.; Chansler, R. The hadoop distributed file system. In Proceedings of the 2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), Incline Village, NV, USA, 3–7 May 2010. [Google Scholar]
- Hunt, P.; Konar, M.; Junqueira, F.P.; Reed, B. ZooKeeper: Wait-free coordination for internet-scale systems. In Proceedings of the USENIX Annual Technical Conference (USENIX ATC’10), Boston, MA, USA, 23–25 June 2010. [Google Scholar]
- Borthakur, D. HDFS architecture guide. Hadoop Apache Proj. 2008, 53, 2. [Google Scholar]
- Ivanov, T.; Rabl, T.; Poess, M.; Queralt, A.; Poelman, J.; Poggi, N.; Buell, J. Big data benchmark compendium. In Proceedings of the 7th TPC Technology Conference, Kohala Coast, HI, USA, 31 August–4 September 2015. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Server Name | CPU | Memory | Hard Disk |
|---|---|---|---|
| Hadoop201 | 8-core | 64 GB | 200 GB |
| Hadoop202 | 8-core | 64 GB | 200 GB |
| Hadoop203 | 8-core | 64 GB | 200 GB |
| Tool | Versions |
|---|---|
| Operating System | Centos7.5 |
| CDH | 6.3.2 |
| JDK | 1.8.0_181 |
| Hadoop | 3.0.0 + cdh6.3.2 |
| Hive | 2.1.1 + cdh6.3.2 |
| Zookeeper | 3.4.5 + cdh6.3.2 |
| Spark | 2.4.0 + cdh6.3.2 |
| Hue | 4.2.0 + cdh6.3.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, X.; He, Y. Optimization of the Join between Large Tables in the Spark Distributed Framework. Appl. Sci. 2023, 13, 6257. https://doi.org/10.3390/app13106257
Wu X, He Y. Optimization of the Join between Large Tables in the Spark Distributed Framework. Applied Sciences. 2023; 13(10):6257. https://doi.org/10.3390/app13106257
Chicago/Turabian StyleWu, Xiang, and Yueshun He. 2023. "Optimization of the Join between Large Tables in the Spark Distributed Framework" Applied Sciences 13, no. 10: 6257. https://doi.org/10.3390/app13106257
APA StyleWu, X., & He, Y. (2023). Optimization of the Join between Large Tables in the Spark Distributed Framework. Applied Sciences, 13(10), 6257. https://doi.org/10.3390/app13106257