

A Target Re-Identification Method Based on Shot Boundary Object Detection for Single Object Tracking


Abstract
:1. Introduction
- (1)
- Target occlusion. Due to the complex environment in videos, when the tracked targets are moving or when other objects in the shots are moving, the tracked targets may be obscured by other objects for a period of time. In Figure 1, the moving ship is obstructed by the railing in front of the camera.
- (2)
- Target out-of-view. This situation often occurs in videos where the tracked targets are moving rapidly, regardless of whether the shots are fixed or moving. Because the targets are generally not aware of the range of the shots, as they move, it may cause them to leave the cameras. The monkey’s rapid movement causes it to leave the shot in Figure 1.
- (3)
- Target deformation. Tracked targets with irregular shapes and sizes or actively changing their own appearance can cause this situation, especially when they move. In Figure 1, the small boat changes its plane shape in the shots due to its rotational motion.
- (4)
- Target scale variation. This situation occurs when the tracked targets approach or move away from the shots. The small dog’s running back and forth in front of the camera changes its scale within the lens in Figure 1.
- (1)
- There is no uniform standard for videos, which are shot from different perspectives, and it is common for objects to move in and out of view. Videos, especially daily videos, are often casually shot, capturing scenes that are not the entire actual space but a limited fan-shaped area. At the same time, due to the ease of interaction between objects in videos and the uncertainty of their behavior, it is easy to cause objects to leave the shot.
- (2)
- The SOT algorithms are generally weak in the re-identification of objects out of shots [29]. Most SOT models focus on enhancing the performance of tracking by improving the ability of feature extraction and relation modeling [19]. However, when objects are obscured or change their appearance, the effective features of the object itself are extremely limited [30]. After the target leaves the shot, the model will choose the object with the highest confidence score in the current frame for long-term tracking, causing an inability to achieve target re-identification in a short period of time.
- To deal with the problem of unsatisfactory tracking results resulting from target out-of-view, we propose a target re-identification method based on shot boundary object detection for single object tracking, called TRTrack;
- We build a bipartite matching model of candidate tracklets and neighbor tracklets optimized by the Hopcroft–Karp algorithm to judge the target leaves the shot and introduce the alpha-IoU loss function to YOLOv5-DeepSORT to enhance object detection capability;
- Through a wide range of experiments by self-built videos dataset CLV and benchmark dataset, TRTrack is verified to be applied well for target re-identification in most video tracking tasks.
2. Related Work
2.1. Methods of Disappearing Target Re-Identification
2.2. Single Object Tracking Model Based on Transformer
- (1)
- Two-stream framework. This framework first inputs the template and the search region into the backbone of the model and shares the weight. It then concatenates the output results to feed into the Transformer. Finally, the location of the object is predicted by classification, regression, and other methods. In recent years, Chen et al. [43] proposed TransT, which fuses iterative features through stacked self-concern layers and cross-concern layers. The STARK [21] model implemented by Yan et al. connects a new template with the search region in a way that automatically updates template images. Lin et al. [44] proposed SwinTrack based on the total attention mechanism instead of using CNN and other neural networks. These algorithms have satisfactory tracking accuracy, but their inference efficiency is not very fast because of heavy relation modeling.
- (2)
- One-stream framework. In this framework, the template and the search region are concatenated before they are input into the backbone, and the subsequent process is similar to that of the two-stream framework. A typical example is the MixFormer [18] developed by Cui et al., which introduces a mixed attention module to build an information interaction channel between the template-search image pairs. The OSTrack [19] proposed by Ye et al. connects the template and the search region to bidirectional information flows to combine feature learning with interaction. Chen et al. [45] built the SimTrack, which is a simplified tracking model using the Transformer as a backbone for relation modeling and feature extraction. These algorithms achieve not only high tracking accuracy but also fast inference speed, thereby balancing between performance and speed.
2.3. Object Detection Method Following the Top-Down Approach
- (1)
- Two-stage method. This method uses a proposal mechanism to decrease negative candidates generated by anchors and outputs the object detection results consisting of prediction bounding boxes and corresponding probabilities of object category through the detection network, such as CNNs. R-CNN [21], proposed by Donahue et al., combines region proposals with CNNs and can predict and partition objects by applying high-capacity convolutional neural networks. Girshick [22] designed the Fast R-CNN object detection model, which uses deep convolutional networks to classify object proposals efficiently; R-FCN [49], developed by Dai et al., contains position-sensitive score maps to resolve the contradiction between image classification and object detection. However, this method often results in a long training time and slow testing speed due to a large amount of repeated computation of convolutional features.
- (2)
- One-stage method. This method is created to realize object detection directly from anchors after extracting the input image features without using any proposal elimination mechanisms. Wei et al. [24] presented the SSD, which removes the generating proposal and image feature extraction modules and implements all the work of the model into a single network. RetinaNet [50] is designed to address imbalance problems of object detection by optimizing the standard cross entropy loss. Redmon et al. [25] converted the object detection task into a regression problem of object bounding boxes and corresponding category probabilities while proposing a single object detection network, YOLO, which has attained optimal accuracy and speed performance. This type of method can optimize the detection performance from end to end and has very high computation efficiency.
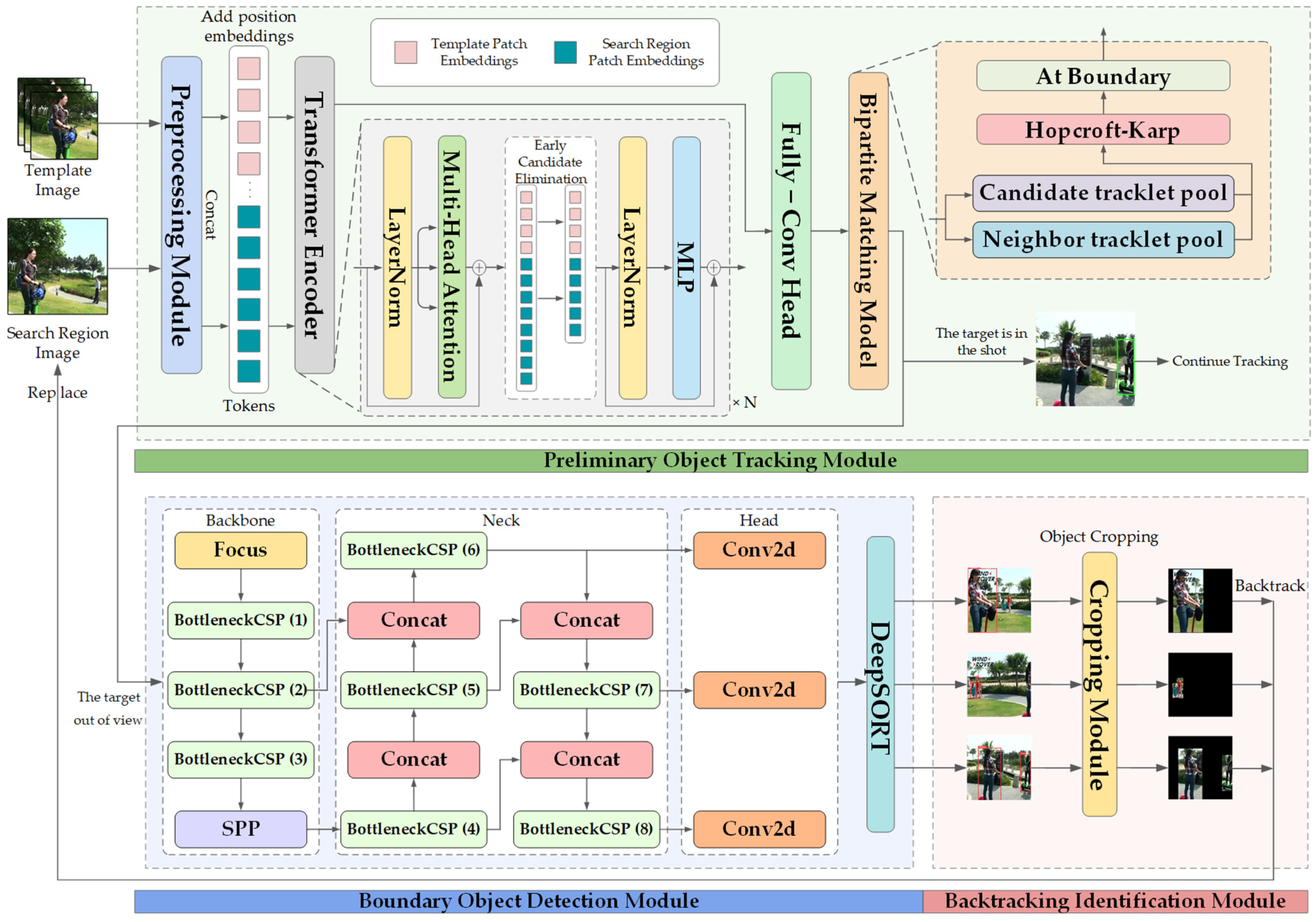
3. Proposed Method
3.1. Preliminary Object Tracking Module
3.2. Boundary Object Detection Module
3.3. Backtracking Identification Module
4. Experimental Results
4.1. Experimental Setup
4.1.1. Datasets
4.1.2. Evaluation Metrics
4.1.3. Implementation Details
4.2. Results and Analysis
4.2.1. Results of Preliminary Object Tracking
4.2.2. Results of Object Detection
4.2.3. Results of Target Re-Identification
4.2.4. Ablation Study of Target Re-Identification
- Effect of the bipartite matching model of the preliminary object tracking module
- Effect of improved YOLOv5-DeepSORT of boundary object detection module
4.2.5. More Visualization of Target Re-Identification
5. Conclusions and Future Work
5.1. Conclusions
5.2. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, P.; Wang, D.; Wang, L.; Lu, H. Deep visual tracking: Review and experimental comparison. Pattern Recognit. 2018, 76, 323–338. [Google Scholar] [CrossRef]
- Subaweh, M.; Wibowo, E. Implementation of Pixel Based Adaptive Segmenter method for tracking and counting vehicles in visual surveillance. In Proceedings of the 2016 International Conference on Informatics and Computing (ICIC), Mataram, Indonesia, 28–29 October 2016; pp. 1–5. [Google Scholar]
- Li, H.; Wu, C.; Chu, D.; Lu, L.; Cheng, K. Combined Trajectory Planning and Tracking for Autonomous Vehicle Considering Driving Styles. IEEE Access 2021, 9, 9453–9463. [Google Scholar] [CrossRef]
- Yi, J.; Liu, J.; Zhang, C.; Lu, X. Magnetic Motion Tracking for Natural Human Computer Interaction: A Review. IEEE Sens. J. 2022, 22, 22356–22367. [Google Scholar] [CrossRef]
- Liu, H.; Fang, S.; Zhang, Z.; Li, D.; Lin, K.; Wang, J. MFDNet: Collaborative Poses Perception and Matrix Fisher Distribution for Head Pose Estimation. IEEE Trans. Multimed. 2022, 24, 2449–2460. [Google Scholar] [CrossRef]
- Marvasti-Zadeh, S.; Cheng, L.; Ghanei-Yakhdan, H.; Kasaei, S. Deep Learning for Visual Tracking: A Comprehensive Survey. IEEE Trans. Intell. Transp. Syst. 2022, 23, 3943–3968. [Google Scholar] [CrossRef]
- Henriques, J.; Caseiro, R.; Martins, P.; Batista, J. High-Speed Tracking with Kernelized Correlation Filters. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 583–596. [Google Scholar] [CrossRef] [PubMed]
- Danelljan, M.; Häger, G.; Khan, F.; Felsberg, M. Learning Spatially Regularized Correlation Filters for Visual Tracking. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4310–4318. [Google Scholar]
- Danelljan, M.; Bhat, G.; Shahbaz Khan, F.; Felsberg, M. ECO: Efficient Convolution Operators for Tracking. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6931–6939. [Google Scholar]
- Galoogahi, H.; Sim, T.; Lucey, S. Correlation filters with limited boundaries. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4630–4638. [Google Scholar]
- Javed, S.; Danelljan, M.; Khan, F.; Khan, M.; Felsberg, M.; Matas, J. Visual Object Tracking with Discriminative Filters and Siamese Networks: A Survey and Outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 6552–6574. [Google Scholar] [CrossRef]
- Bertinetto, L.; Valmadre, J.; Henriques, J.; Vedaldi, A.; Torr, P. Fully-Convolutional Siamese Networks for Object Tracking. arXiv 2016, arXiv:1606.09549. [Google Scholar]
- Zhu, Z.; Wang, Q.; Li, B.; Wu, W.; Yan, J.; Hu, W. Distractor-aware Siamese Networks for Visual Object Tracking. arXiv 2018, arXiv:1808.06048. [Google Scholar]
- Yu, Y.; Xiong, Y.; Huang, W.; Scott, M. Deformable Siamese Attention Networks for Visual Object Tracking. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 6727–6736. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Huang, Y.; Li, X.; Lu, R.; Qi, N. RGB-T object tracking via sparse response-consistency discriminative correlation filters. Infrared Phys. Technol. 2023, 128, 104509. [Google Scholar] [CrossRef]
- Yan, B.; Peng, H.; Fu, J.; Wang, D.; Lu, H. Learning Spatio-Temporal Transformer for Visual Tracking. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 10428–10437. [Google Scholar]
- Cui, Y.; Jiang, C.; Wu, G.; Wang, L. MixFormer: End-to-End Tracking with Iterative Mixed Attention. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 13598–13608. [Google Scholar]
- Ye, B.; Chang, H.; Ma, B.; Shan, S.; Chen, X. Joint Feature Learning and Relation Modeling for Tracking: A One-Stream Framework. In Computer Vision—ECCV 2022; ECCV 2022. Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2022; Volume 13682. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; ECCV 2016. Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; Volume 9905. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Computer Vision—ECCV 2020; ECCV 2020. Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12346, pp. 213–229. [Google Scholar]
- Oksuz, K.; Cam, B.; Kalkan, S.; Akbas, E. Imbalance Problems in Object Detection: A Review. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3388–3415. [Google Scholar] [CrossRef]
- Huang, L.; Zhao, X.; Huang, K. GOT-10k: A Large High-Diversity Benchmark for Generic Object Tracking in the Wild. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1562–1577. [Google Scholar] [CrossRef] [PubMed]
- Thangavel, J.; Kokul, T.; Ramanan, A.; Fernando, S. Transformers in Single Object Tracking: An Experimental Survey. arXiv 2023, arXiv:2302.11867. [Google Scholar]
- Chen, Y.; Wang, C.-Y.; Yang, C.-Y.; Chang, H.-S.; Lin, Y.-L.; Chuang, Y.-Y.; Mark Liao, H.-Y. NeighborTrack: Improving Single Object Tracking by Bipartite Matching with Neighbor Tracklets. arXiv 2022, arXiv:2211.06663. [Google Scholar]
- Wang, Z.; Arabnia, H.; Taha, T. Review of Person Re-identification Methods. In Proceedings of the 2017 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 14–16 December 2017; pp. 541–546. [Google Scholar]
- Zheng, L.; Yang, Y.; Hauptmann, A. Person Re-identification: Past, Present and Future. arXiv 2016, arXiv:1610.02984. [Google Scholar]
- Liu, T.; Wang, J.; Yang, B.; Wang, X. NGDNet: Nonuniform Gaussian-label distribution learning for infrared head pose estimation and on-task behavior understanding in the classroom. Neurocomputing 2021, 436, 210–220. [Google Scholar] [CrossRef]
- Xue, W.; Wang, A.; Zhao, L. FLFuse-Net: A fast and lightweight infrared and visible image fusion network via feature flow and edge compensation for salient information. Infrared Phys. Technol. 2022, 127, 104383. [Google Scholar] [CrossRef]
- Liu, T.; Liu, H.; Li, Y.; Zhang, Z.; Liu, S. Efficient Blind Signal Reconstruction with Wavelet Transforms Regularization for Educational Robot Infrared Vision Sensing. IEEE/ASME Trans. Mechatron. 2019, 24, 384–394. [Google Scholar] [CrossRef]
- Wang, M.; Liu, Y.; Huang, Z. Large Margin Object Tracking with Circulant Feature Maps. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4800–4808. [Google Scholar]
- Liu, Y.; Cheng, L.; Tan, R.; Sui, X. Object Tracking Using Spatio-Temporal Networks for Future Prediction Location. In Computer Vision—ECCV 2020; ECCV 2020. Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2020; Volume 12367. [Google Scholar]
- Voigtlaender, P.; Luiten, J.; Torr, P.; Leibe, B. Siam R-CNN: Visual Tracking by Re-Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 6577–6587. [Google Scholar]
- Ahn, W.-J.; Ko, K.-S.; Lim, M.-T.; Pae, D.-S.; Kang, T.-K. Multiple Object Tracking Using Re-Identification Model with Attention Module. Appl. Sci. 2023, 13, 4298. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the 2021 International Conference on Learning Representations (ICLR), Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Liu, T.; Liu, H.; Yang, B.; Zhang, Z. LDCNet: Limb Direction Cues-aware Network for Flexible Human Pose Estimation in Industrial Behavioral Biometrics Systems. IEEE Trans. Ind. Inform. 2023. [Google Scholar] [CrossRef]
- Liu, H.; Nie, H.; Zhang, Z.; Li, Y. Anisotropic angle distribution learning for head pose estimation and attention understanding in human-computer interaction. Neurocomputing 2021, 433, 310–322. [Google Scholar] [CrossRef]
- Chen, X.; Yan, B.; Zhu, J.; Wang, D.; Yang, X.; Lu, H. Transformer Tracking. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8122–8131. [Google Scholar]
- Lin, L.; Fan, H.; Xu, Y.; Ling, H. SwinTrack: A Simple and Strong Baseline for Transformer Tracking. In Proceedings of the 2022 Neural Information Processing Systems (NeurIPS), New Orleans, LA, USA, 28 November–9 December 2022. [Google Scholar]
- Chen, B.; Li, P.; Bai, L.; Qiao, L.; Shen, Q.; Li, B.; Gan, W.; Wu, W.; Ouyang, W. Backbone is All Your Need: A Simplified Architecture for Visual Object Tracking. In Computer Vision—ECCV 2022; ECCV 2022. Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2022; Volume 13682. [Google Scholar]
- Ling, L.; Tao, J.; Wu, G. Pedestrian Detection and Feedback Application Based on YOLOv5s and DeepSORT. In Proceedings of the 2022 34th Chinese Control and Decision Conference (CCDC), Hefei, China, 15–17 August 2022; pp. 5716–5721. [Google Scholar]
- Dai, X. Hybridnet: A fast vehicle detection system for autonomous driving. Signal Process. Image Commun. 2019, 70, 79–88. [Google Scholar] [CrossRef]
- Shen, R.; Zhen, T.; Li, Z. YOLOv5-Based Model Integrating Separable Convolutions for Detection of Wheat Head Images. IEEE Access 2023, 11, 12059–12074. [Google Scholar] [CrossRef]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems (NIPS’16), Barcelona, Spain, 5–10 December 2016; Curran Associates Inc.: Red Hook, NY, USA, 2016; pp. 379–387. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; DollárFocal, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- He, J.; Erfani, S.; Ma, X.; Bailey, J.; Chi, Y.; Hua, X. Alpha-IoU: A Family of Power Intersection over Union Losses for Bounding Box Regression. arXiv 2021, arXiv:2110.13675v2. [Google Scholar]
- Chang, Y.; Li, D.; Gao, Y.; Su, Y.; Jia, X. An Improved YOLO Model for UAV Fuzzy Small Target Image Detection. Appl. Sci. 2023, 13, 5409. [Google Scholar] [CrossRef]
- Fan, H.; Lin, L.; Yang, F.; Chu, P.; Deng, G.; Yu, S.; Bai, H.; Xu, Y.; Liao, C.; Ling, H. LaSOT: A High-Quality Benchmark for Large-Scale Single Object Tracking. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5369–5378. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Video ID | Video Duration | Video Size | Frame Rate | Number of Times the Target Leaves the Shot | Total Time of the Target Leaves the Shot |
|---|---|---|---|---|---|
| 001 | 40:20 | 1920 × 1080 | 30 fps | 11 times | 79.674 s |
| 002 | 50:35 | 1920 × 1080 | 30 fps | 9 times | 179.614 s |
| 003 | 37:42 | 1920 × 1080 | 30 fps | 11 times | 106.721 s |
| 004 | 33:51 | 1920 × 1080 | 30 fps | 9 times | 142.153 s |
| 005 | 43:35 | 1920 × 1080 | 30 fps | 24 times | 332.490 s |
| 006 | 45:14 | 1920 × 1080 | 30 fps | 15 times | 163.069 s |
| 007 | 32:04 | 1920 × 1080 | 30 fps | 3 times | 110.833 s |
| 008 | 41:40 | 1280 × 960 | 30 fps | 8 times | 58.689 s |
| 009 | 38:26 | 1920 × 1080 | 30 fps | 7 times | 174.110 s |
| 010 | 32:11 | 1920 × 1080 | 30 fps | 14 times | 88.457 s |
| 011 | 36:58 | 1280 × 960 | 30 fps | 6 times | 101.776 s |
| 012 | 40:46 | 1920 × 1080 | 30 fps | 19 times | 254.330 s |
| 013 | 30:09 | 1280 × 960 | 30 fps | 4 times | 76.541 s |
| 014 | 31:32 | 1920 × 1080 | 30 fps | 13 times | 94.879 s |
| 015 | 35:27 | 1920 × 1080 | 30 fps | 16 times | 143.556 s |
| 016 | 38:43 | 1920 × 1080 | 30 fps | 12 times | 167.123 s |
| Model | LaSOT | GOT-10k | ||||
|---|---|---|---|---|---|---|
| AUC | PNorm | P | mAO | mSR50 | mSR75 | |
| AiATrack | 0.690 | 0.794 | 0.738 | 0.696 | 0.800 | 0.632 |
| SwinTrack-B-384 | 0.702 | 0.784 | 0.753 | 0.724 | 0.805 | 0.678 |
| MixFormer-L | 0.701 | 0.799 | 0.763 | 0.756 | 0.8573 * | 0.728 |
| OSTrack-384 | 0.711 | 0.811 | 0.776 | 0.737 | 0.832 | 0.708 |
| NeighborTrack-OSTrack | 0.722 | 0.818 | 0.780 | 0.757 | 0.8572 | 0.733 |
| Ours | 0.731 | 0.814 | 0.787 | 0.763 | 0.854 | 0.739 |
| Loss Function | AP | AP50 | AP75 | mAP | mAP75:95 |
|---|---|---|---|---|---|
| LIoU | 47.61% | 67.52% | 53.48% | 48.76% | 34.51% |
| LGIoU | 50.10% | 69.49% | 55.58% | 51.22% | 36.04% |
| LCIoU | 49.38% | 68.84% | 54.69% | 50.59% | 35.58% |
| Ours | 52.97% * | 72.19% | 57.84% | 53.51% | 38.62% |
| Video ID | OSTrack-384 | MixFormer-L | NeighborTrack-OSTrack | TRTrack (Ours) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ET (Times) | ED (s) | TD (s) | ET (Times) | ED (s) | TD (s) | ET (Times) | ED (s) | TD (s) | ET (Times) | ED (s) | TD (s) | |
| 001 | 20 | 44.62 | 13.98 | 26 | 49.83 | 18.65 | 9 | 25.42 | 24.49 | 2 * | 2.72 | 2.64 |
| 002 | 15 | 27.93 | 8.72 | 24 | 32.11 | 14.56 | 5 | 430.76 | 416.88 | 2 | 2.71 | 2.71 |
| 003 | 16 | 34.77 | 14.21 | 13 | 24.89 | 17.55 | 6 | 29.56 | 27.14 | 4 | 5.27 | 5.27 |
| 004 | 19 | 41.10 | 17.44 | 19 | 29.74 | 18.33 | 8 | 24.11 | 23.98 | 4 | 2.94 | 2.94 |
| 005 | 22 | 137.73 | 95.56 | 26 | 113.86 | 106.49 | 5 | 38.66 | 36.54 | 3 | 3.01 | 3.01 |
| 006 | 8 | 146.29 | 136.61 | 12 | 90.01 | 74.79 | 4 | 9.12 | 7.55 | 2 | 2.01 | 1.89 |
| 007 | 17 | 24.80 | 8.56 | 8 | 17.13 | 6.59 | 0 | 0.00 | 0.00 | 0 | 0.00 | 0.00 |
| 008 | 9 | 13.11 | 6.78 | 6 | 14.89 | 4.23 | 1 | 1.29 | 1.29 | 0 | 0.00 | 0.00 |
| 009 | 14 | 47.88 | 24.96 | 12 | 39.47 | 26.55 | 11 | 26.54 | 24.48 | 3 | 5.42 | 4.89 |
| 010 | 7 | 16.22 | 14.56 | 9 | 21.54 | 17.77 | 4 | 5.89 | 5.43 | 2 | 1.69 | 1.43 |
| 011 | 16 | 42.98 | 36.66 | 17 | 54.32 | 47.62 | 1 | 4.32 | 4.16 | 2 | 5.67 | 4.93 |
| 012 | 24 | 145.96 | 115.43 | 22 | 121.11 | 103.67 | 13 | 254.55 | 241.69 | 7 | 9.43 | 9.12 |
| 013 | 9 | 54.22 | 38.14 | 10 | 43.12 | 34.56 | 6 | 16.55 | 14.29 | 3 | 8.76 | 7.84 |
| 014 | 12 | 15.77 | 12.97 | 11 | 18.56 | 12.13 | 3 | 3.98 | 3.68 | 0 | 0.00 | 0.00 |
| 015 | 14 | 66.35 | 38.54 | 16 | 64.59 | 42.84 | 8 | 54.51 | 48.67 | 2 | 7.56 | 7.07 |
| 016 | 15 | 101.56 | 87.52 | 18 | 121.76 | 105.43 | 7 | 43.56 | 41.70 | 4 | 11.56 | 8.79 |
| Avg | 14.81 | 60.08 | 41.92 | 15.56 | 53.56 | 40.74 | 5.69 | 60.55 | 57.62 | 2.50 | 4.30 | 3.91 |
| Sum | 237 | 961.29 | 670.64 | 249 | 856.93 | 651.76 | 91 | 968.82 | 921.97 | 40 | 68.75 | 62.53 |
| Video ID | TRTrack with Original NeighborTrack | TRTrack with Bipartite Matching Model (Ours) | ||||
|---|---|---|---|---|---|---|
| ET (Times) | ED (s) | TD (s) | ET (Times) | ED (s) | TD (s) | |
| 001 | 4 | 8.74 | 6.79 | 2 * | 2.72 | 2.64 |
| 002 | 5 | 9.26 | 7.42 | 2 | 2.71 | 2.71 |
| 003 | 4 | 6.38 | 5.16 | 4 | 5.27 | 5.27 |
| 004 | 5 | 7.29 | 6.94 | 4 | 2.94 | 2.94 |
| 005 | 7 | 12.16 | 10.07 | 3 | 3.01 | 3.01 |
| 006 | 6 | 6.11 | 4.83 | 2 | 2.01 | 1.89 |
| 007 | 0 | 0.00 | 0.00 | 0 | 0.00 | 0.00 |
| 008 | 1 | 1.65 | 0.54 | 0 | 0.00 | 0.00 |
| Video ID | TRTrack with Original YOLOv5-DeepSORT | TRTrack with Improved YOLOv5-DeepSORT (Ours) | ||||
|---|---|---|---|---|---|---|
| ET (Times) | ED (s) | TD (s) | ET (Times) | ED (s) | TD (s) | |
| 001 | 7 | 17.53 | 15.44 | 2 * | 2.72 | 2.64 |
| 002 | 8 | 16.74 | 13.10 | 2 | 2.71 | 2.71 |
| 003 | 7 | 11.98 | 10.56 | 4 | 5.27 | 5.27 |
| 004 | 9 | 19.24 | 15.13 | 4 | 2.94 | 2.94 |
| 005 | 14 | 22.87 | 19.06 | 3 | 3.01 | 3.01 |
| 006 | 7 | 14.88 | 12.65 | 2 | 2.01 | 1.89 |
| 007 | 4 | 5.43 | 3.29 | 0 | 0.00 | 0.00 |
| 008 | 5 | 8.47 | 7.08 | 0 | 0.00 | 0.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Miao, B.; Chen, Z.; Liu, H.; Zhang, A. A Target Re-Identification Method Based on Shot Boundary Object Detection for Single Object Tracking. Appl. Sci. 2023, 13, 6422. https://doi.org/10.3390/app13116422
Miao B, Chen Z, Liu H, Zhang A. A Target Re-Identification Method Based on Shot Boundary Object Detection for Single Object Tracking. Applied Sciences. 2023; 13(11):6422. https://doi.org/10.3390/app13116422
Chicago/Turabian StyleMiao, Bingchen, Zengzhao Chen, Hai Liu, and Aijun Zhang. 2023. "A Target Re-Identification Method Based on Shot Boundary Object Detection for Single Object Tracking" Applied Sciences 13, no. 11: 6422. https://doi.org/10.3390/app13116422
APA StyleMiao, B., Chen, Z., Liu, H., & Zhang, A. (2023). A Target Re-Identification Method Based on Shot Boundary Object Detection for Single Object Tracking. Applied Sciences, 13(11), 6422. https://doi.org/10.3390/app13116422