
Phishing Node Detection in Ethereum Transaction Network Using Graph Convolutional Networks



Abstract
1. Introduction
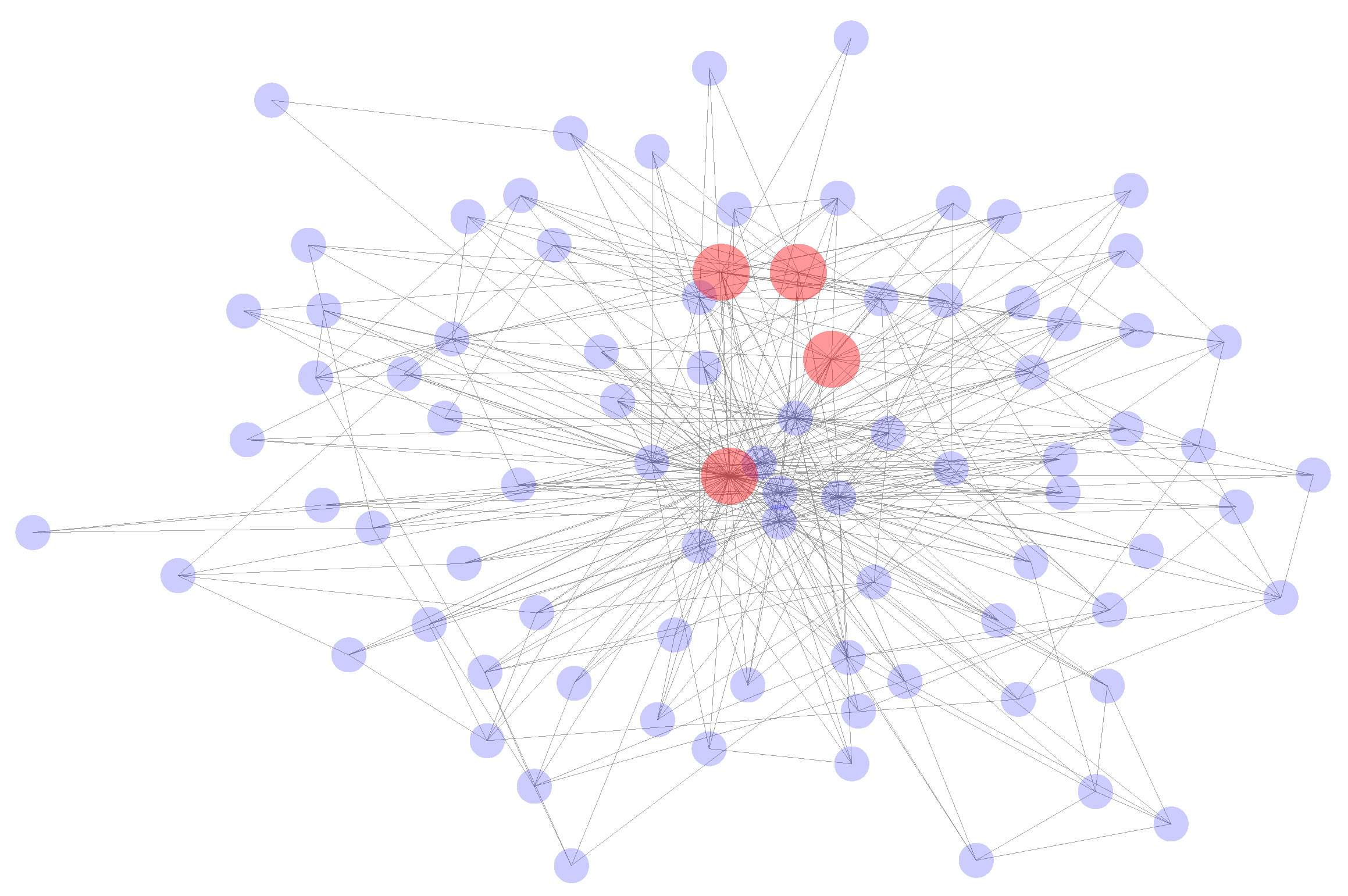
- There is a very large amount of transaction data. Although only a few dozen nodes are shown in the figure, there are hundreds of edges among the nodes. Thus, it can be concluded that the transaction network is very complex.
- There is an intricate relationship between the nodes. Figure 1 shows that the nodes in the transaction network are connected closely with other nodes, and there are multiple edges between nodes.
- There is an imbalance in the data. Based on the figure, phishing nodes only account for a small proportion of the data compared to normal nodes, and this indicates that a serious data imbalance problem exists in the Ethereum transaction data.
2. Related Work
2.1. Scams on Blockchain Platforms
2.2. Detection of Phishing Scams on Ethereum
2.3. Graph Embedding
3. Research Motivations
3.1. Challenges
3.2. Potential Solutions
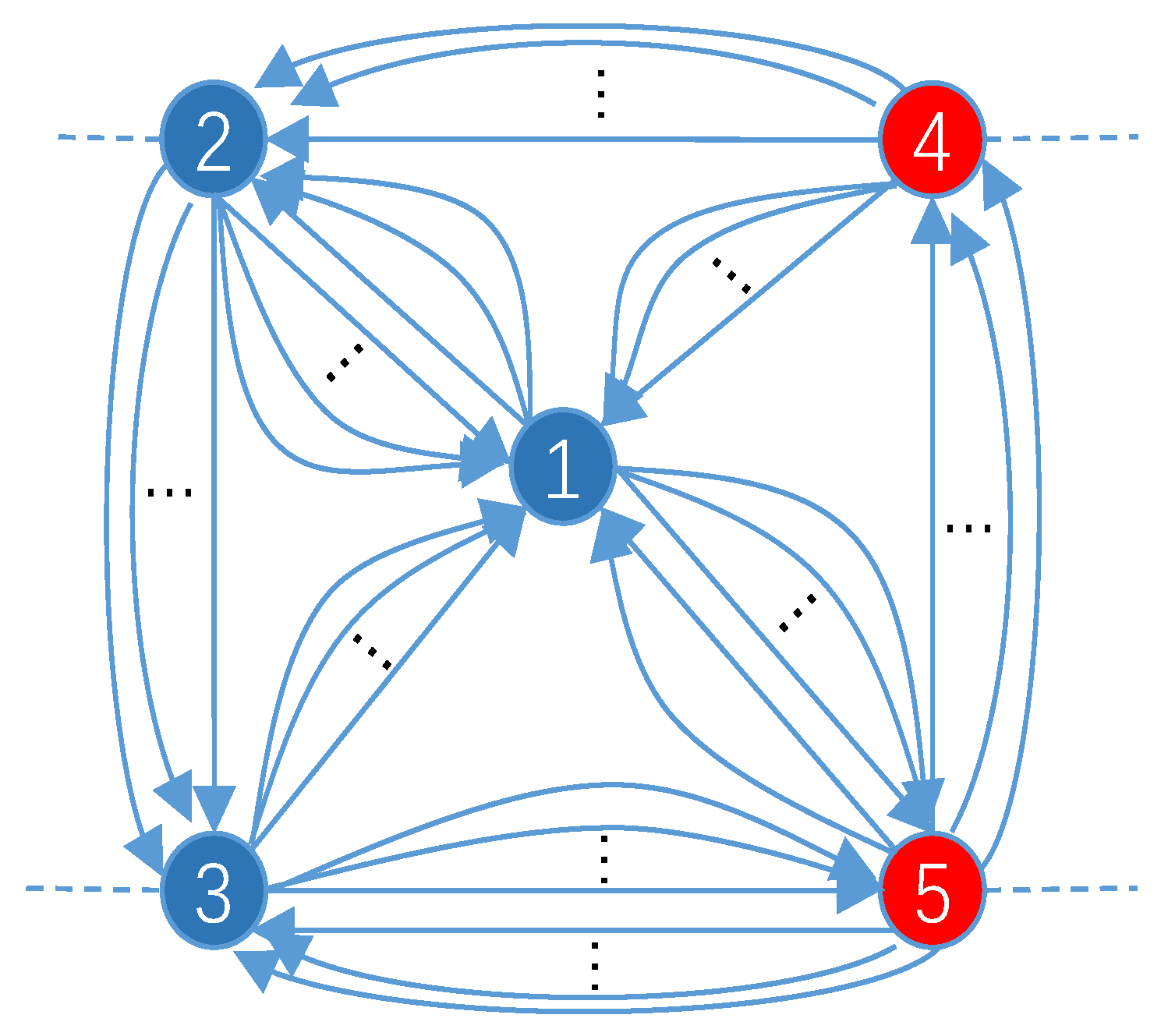
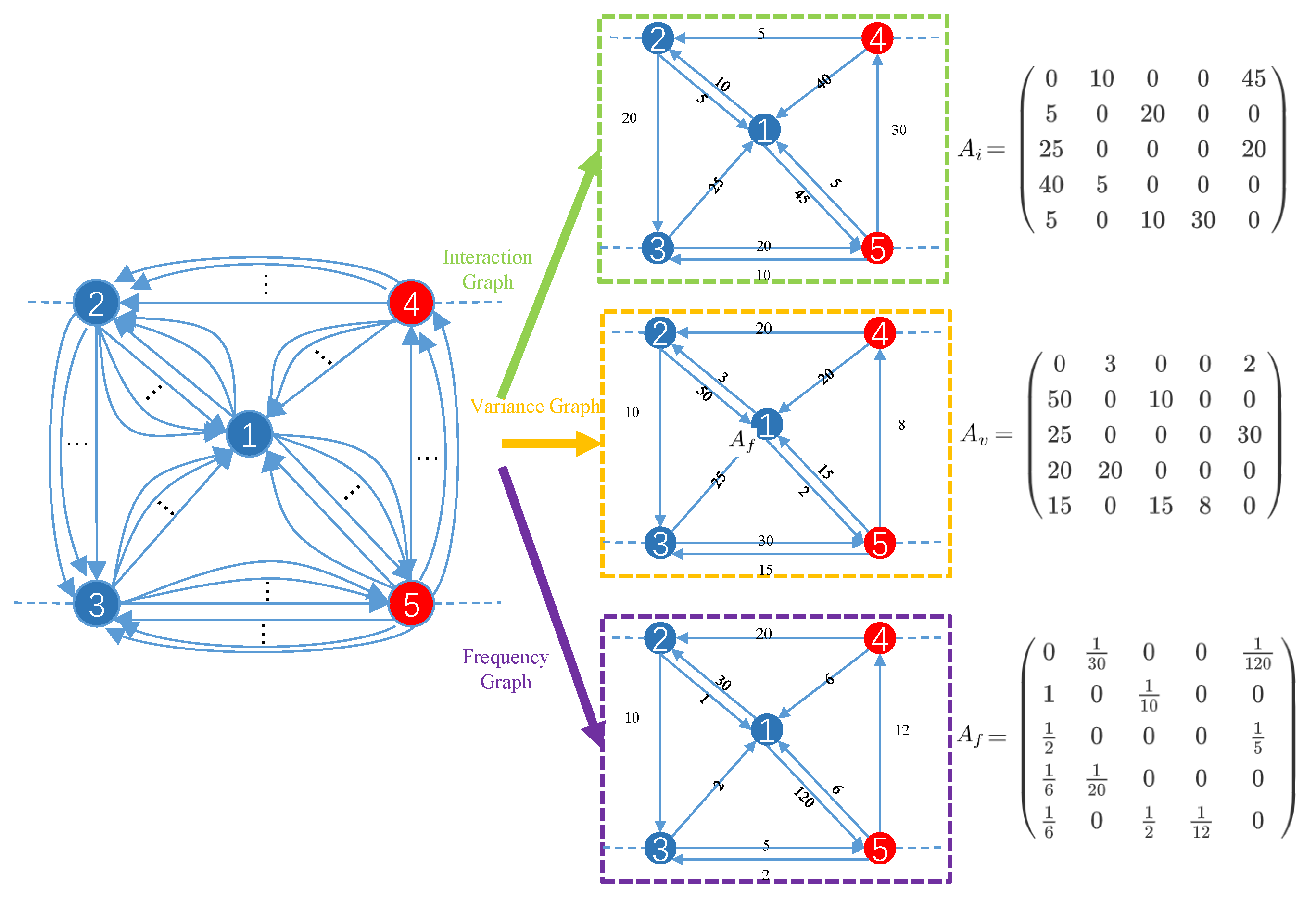
- To address the multiedge graph problem, we extract three features from the transactions, i.e., inter-node interaction, transaction time variance, and transaction frequency. For each feature, we replace the edges between two nodes that have the same direction with a single directed edge and construct a feature graph to represent the information contained in the multiedges.
- We use the bagging strategy [28] to deal with both data imbalances and the PU problem. In doing so, we use bootstrap aggregating techniques to leverage unlabeled data and mitigate the limitations associated with the PU problem. In addition, the sampling method used in the bagging strategy also minimizes the impact of the imbalance in the data on the classification results.
4. Proposed BM-GCN Model
4.1. Representing the Features of the Graph
4.1.1. Node Interaction Graph
4.1.2. Time Variance Graph
4.1.3. Transaction Frequency Graph
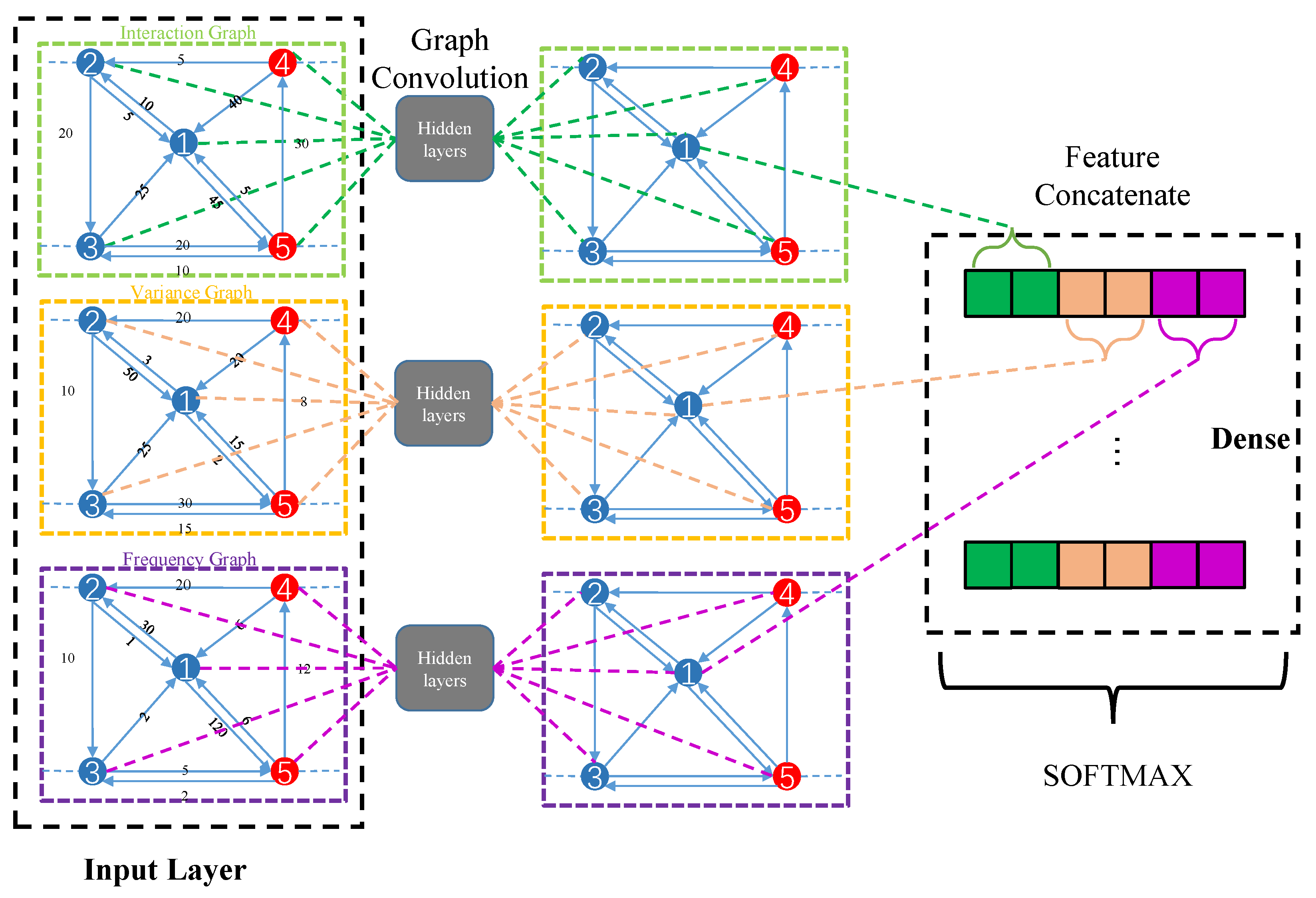
4.2. GCN for Inter-Node Graphs
4.3. Bagging
| Algorithm 1 Bagging learning |
Input: size of bootstrap samples, number of bootstraps Output: a function for to T do Draw a bagging sample of size K in U. Make a bootstrap set S from P and with corresponding labels. Use bootstrap set S to train the classifier f to discriminate P against . while stopping criterion not met do Update w with Adam optimizer end while end for return f |
5. Evaluation
5.1. Dataset and Evaluation Metrics
5.2. Baseline Methods
- SVM represents the examples as vectors in space, and it chooses a hyperplane that represents the largest separation between examples in order to classify them.
- As a statistical classification method, LR models a binary dependent variable using a logistic function and obtains the corresponding probability of the class of examples.
- RF is an ensemble learning method that constructs a large number of decision trees at training time and outputs the modes of the classes as the classification result.
5.3. Findings
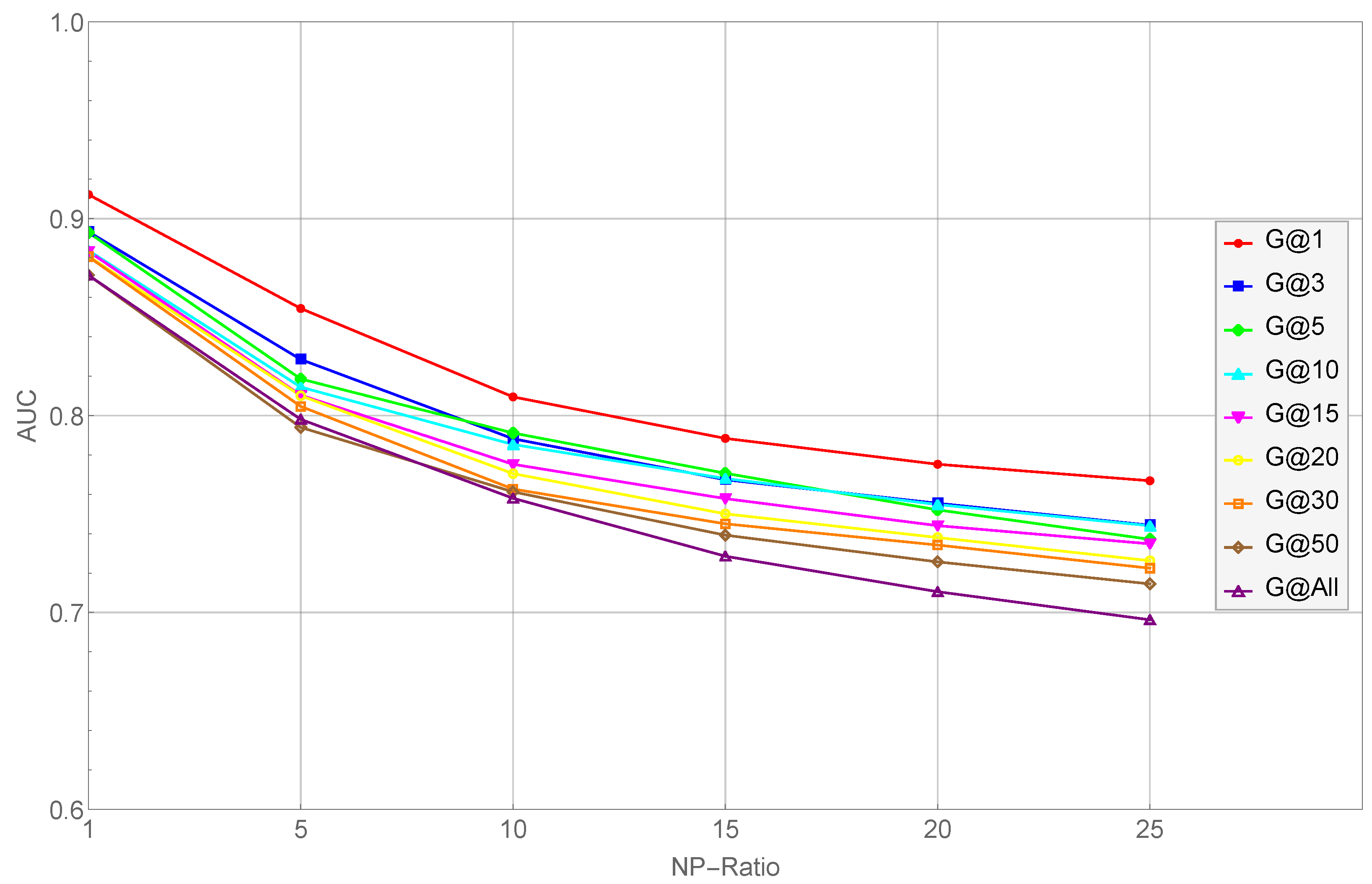
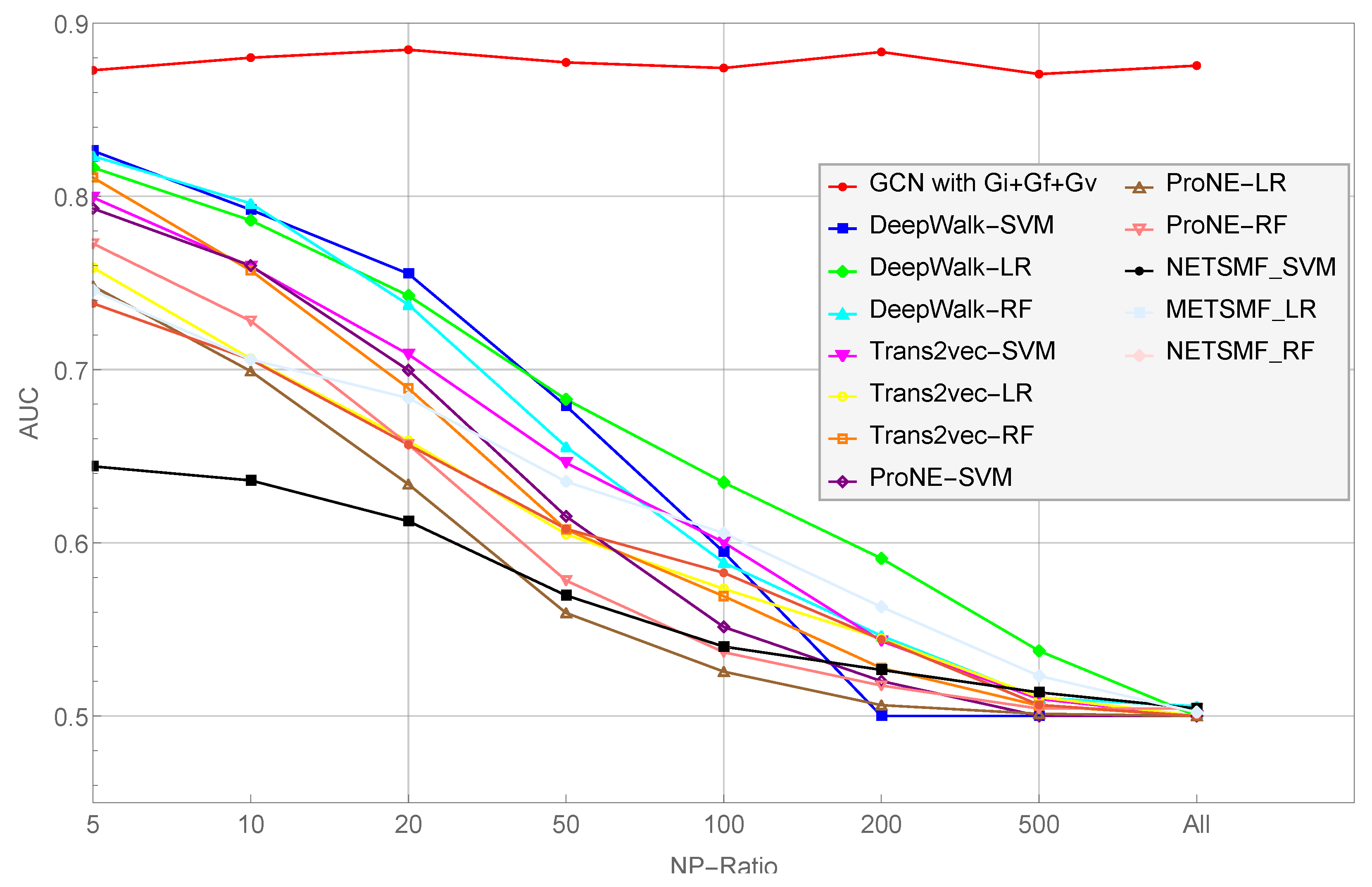
- As the NP ratio increases, the performance of their scheme decreases consistently. Specifically, the average classification AUC value of Trans2vec decreased from 0.886 to 0.732 when the NP ratio increased from 1 to 25. In other words, Trans2vec is not capable of dealing with data imbalances.
- As the network scales, the performance of their model decreases gradually. In other words, the scale of the network impacts the node representation capabilities of their scheme and degrades the classification performance (i.e., Trans2vec is not inadequate for large-scale transaction graphs).
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chainalysis Team. The 2022 Crypto Crime Report. 2022. Available online: https://blog.chainalysis.com/reports/2022-crypto-crime-report-introduction/ (accessed on 8 April 2022).
- Onyema, E.; Dinar, A.; Ghouali, S.; Merabet, B.; Merzougui, R.; Feham, M. Cyber Threats, Attack Strategy, and Ethical Hacking in Telecommunications Systems. In Security and Privacy in Cyberspace; Springer: Berlin/Heidelberg, Germany, 2022; pp. 25–45. [Google Scholar]
- Varshney, G.; Misra, M.; Atrey, P.K. A survey and classification of web phishing detection schemes: Phishing is a fraudulent act that is used to deceive users. Secur. Commun. Networks 2016, 9, 6266–6284. [Google Scholar] [CrossRef]
- Xiang, G.; Hong, J.; Rose, C.P.; Cranor, L. CANTINA+: A Feature-Rich Machine Learning Framework for Detecting Phishing Web Sites. ACM Trans. Inf. Syst. Secur. 2011, 14, 1–28. [Google Scholar] [CrossRef]
- Kausar, F.; Al-Otaibi, B.; Al-Qadi, A.; Al-Dossari, N. Hybrid client side phishing websites detection approach. Int. J. Adv. Comput. Sci. Appl. 2014, 5, 132–140. [Google Scholar] [CrossRef]
- Ramesh, G.; Krishnamurthi, I.; Kumar, K.S.S. An efficacious method for detecting phishing webpages through target domain identification. Decis. Support Syst. 2014, 61, 12–22. [Google Scholar] [CrossRef]
- Chen, T.C.; Stepan, T.; Dick, S.; Miller, J. An Anti-Phishing System Employing Diffused Information. ACM Trans. Inf. Syst. Secur. 2014, 16, 1–31. [Google Scholar] [CrossRef]
- Wu, J.; Yuan, Q.; Lin, D.; You, W.; Chen, W.; Chen, C.; Zheng, Z. Who Are the Phishers? Phishing Scam Detection on Ethereum via Network Embedding. arXiv 2019, arXiv:1911.09259. [Google Scholar] [CrossRef]
- Chen, L.; Peng, J.; Liu, Y.; Li, J.; Xie, F.; Zheng, Z. Phishing scams detection in ethereum transaction network. ACM Trans. Internet Technol. (TOIT) 2020, 21, 1–16. [Google Scholar] [CrossRef]
- Chen, W.; Guo, X.; Chen, Z.; Zheng, Z.; Lu, Y. Phishing Scam Detection on Ethereum: Towards Financial Security for Blockchain Ecosystem. In Proceedings of the 29th International Joint Conference on Artificial Intelligence, Yokohama, Japan, 7–15 January 2020; pp. 4506–4512. [Google Scholar]
- Wu, J.; Liu, J.; Zhao, Y.; Zheng, Z. Analysis of cryptocurrency transactions from a network perspective: An overview. J. Netw. Comput. Appl. 2021, 190, 103139. [Google Scholar] [CrossRef]
- Yuan, Z.; Yuan, Q.; Wu, J. Phishing Detection on Ethereum via Learning Representation of Transaction Subgraphs. Blockchain Trust. Syst. 2020, 1267, 178–191. [Google Scholar]
- Wang, J.; Chen, P.; Yu, S.; Xuan, Q. Tsgn: Transaction subgraph networks for identifying ethereum phishing accounts. In Proceedings of the International Conference on Blockchain and Trustworthy Systems, Guangzhou, China, 5–6 August 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 187–200. [Google Scholar]
- Zhang, D.; Chen, J.; Lu, X. Blockchain Phishing Scam Detection via Multi-channel Graph Classification. In Proceedings of the International Conference on Blockchain and Trustworthy Systems, Guangzhou, China, 5–6 August 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 241–256. [Google Scholar]
- Vasek, M.; Moore, T. There’s No Free Lunch, Even Using Bitcoin: Tracking the Popularity and Profits of Virtual Currency Scams. In Proceedings of the International Conference on Financial Cryptography and Data Security, San Juan, Puerto Rico, 26–30 January 2015; pp. 44–61. [Google Scholar]
- Vasek, M.; Moore, T. Analyzing the Bitcoin Ponzi Scheme Ecosystem. In International Conference on Financial Cryptography and Data Security; Springer: St. Kitts, Saint Kitts and Nevis, 2019; pp. 101–112. [Google Scholar]
- Bartoletti, M.; Carta, S.; Cimoli, T.; Saia, R. Dissecting Ponzi schemes on Ethereum: Identification, analysis, and impact. Future Gener. Comput. Syst. 2020, 102, 259–277. [Google Scholar] [CrossRef]
- Chen, W.; Zheng, Z.; Ngai, E.C.; Zheng, P.; Zhou, Y. Exploiting Blockchain Data to Detect Smart Ponzi Schemes on Ethereum. IEEE Access 2019, 7, 37575–37586. [Google Scholar] [CrossRef]
- Cai, H.; Zheng, V.W.; Chang, K.C. A Comprehensive Survey of Graph Embedding: Problems, Techniques and Applications. arXiv 2018, arXiv:1709.07604. [Google Scholar] [CrossRef]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. DeepWalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Grover, A.; Leskovec, J. Node2vec: Scalable Feature Learning for Networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Qiu, J.; Dong, Y.; Ma, H.; Li, J.; Wang, C.; Wang, K.; Tang, J. NetSMF: Large-Scale Network Embedding as Sparse Matrix Factorization. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 1509–1520. [Google Scholar]
- Zhang, J.; Dong, Y.; Wang, Y.; Tang, J.; Ding, M. ProNE: Fast and Scalable Network Representation Learning. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 4278–4284. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Chen, L.; Peng, J.; Liu, Y.; Li, J.; Xie, F.; Zheng, Z. XBLOCK Blockchain Datasets: InPlusLab Ethereum Phishing Detection Datasets. 2019. Available online: http://xblock.pro/ethereum/ (accessed on 8 April 2020).
- Team, C. Crypto Crime Series: Decoding Ethereum Scams. 2019. Available online: https://blog.chainalysis.com/reports/ethereum-scams (accessed on 8 April 2020).
- Redman, J. Data Shows Ethereum is the ‘Cryptocurrency of Choice for Scams’. 2019. Available online: https://news.bitcoin.com/data-shows-ethereum-is-the-cryptocurrency-of-choice-for-scams/ (accessed on 8 April 2020).
- Mordelet, F.; Vert, J.P. A bagging SVM to learn from positive and unlabeled examples. Pattern Recognit. Lett. 2014, 37, 201–209. [Google Scholar] [CrossRef]
- Liu, B.; Dai, Y.; Li, X.; Lee, W.S.; Yu, P.S. Building text classifiers using positive and unlabeled examples. In Proceedings of the 3rd IEEE International Conference on Data Mining, Melbourne, FL, USA, 9–12 November 2003; pp. 179–188. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scale | Node Number | Edge Number |
|---|---|---|
| 1 | 32,582 | 70,082 |
| 3 | 39,606 | 95,154 |
| 5 | 45,397 | 134,552 |
| 10 | 59,250 | 188,875 |
| 15 | 76,344 | 241,639 |
| 20 | 90,388 | 283,260 |
| 30 | 119,368 | 375,159 |
| 50 | 162,388 | 535,819 |
| All | 2,973,489 | 13,551,303 |
| Features | NP-Ratio@50 | NP-Ratio@All |
|---|---|---|
| 0.852591 | 0.851575 | |
| 0.863451 | 0.848624 | |
| 0.872630 | 0.867106 | |
| 0.861069 | 0.867045 | |
| 0.867851 | 0.855019 | |
| 0.869612 | 0.875120 | |
| 0.883325 | 0.875443 |
| NP Ratio | No Bagging | Bagging |
|---|---|---|
| 5 | 0.855752 | 0.870561 |
| 10 | 0.798114 | 0.880036 |
| 20 | 0.745765 | 0.877302 |
| 50 | 0.495823 | 0.883325 |
| NP Ratio | Restored Nodes | AUC |
|---|---|---|
| 5 | 97.6 | 0.819079 |
| 20 | 115.8 | 0.852759 |
| 50 | 123.0 | 0.858245 |
| All | 133.6 | 0.870821 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; He, T.; Chen, K.; Zhang, B.; Wang, Q.; Yuan, L. Phishing Node Detection in Ethereum Transaction Network Using Graph Convolutional Networks. Appl. Sci. 2023, 13, 6430. https://doi.org/10.3390/app13116430
Zhang Z, He T, Chen K, Zhang B, Wang Q, Yuan L. Phishing Node Detection in Ethereum Transaction Network Using Graph Convolutional Networks. Applied Sciences. 2023; 13(11):6430. https://doi.org/10.3390/app13116430
Chicago/Turabian StyleZhang, Zhen, Tao He, Kai Chen, Boshen Zhang, Qiuhua Wang, and Lifeng Yuan. 2023. "Phishing Node Detection in Ethereum Transaction Network Using Graph Convolutional Networks" Applied Sciences 13, no. 11: 6430. https://doi.org/10.3390/app13116430
APA StyleZhang, Z., He, T., Chen, K., Zhang, B., Wang, Q., & Yuan, L. (2023). Phishing Node Detection in Ethereum Transaction Network Using Graph Convolutional Networks. Applied Sciences, 13(11), 6430. https://doi.org/10.3390/app13116430