
From Discourse Relations to Network Edges: A Network Theory Approach to Discourse Analysis


Abstract
:1. Introduction
2. Discourse Relations and Discourse Units
2.1. Elementary Discourse Units
- 1.
- Yesterday evening, John had a great meal andwon a dancing competition.
- 2.
- John fell.Max pushed him.
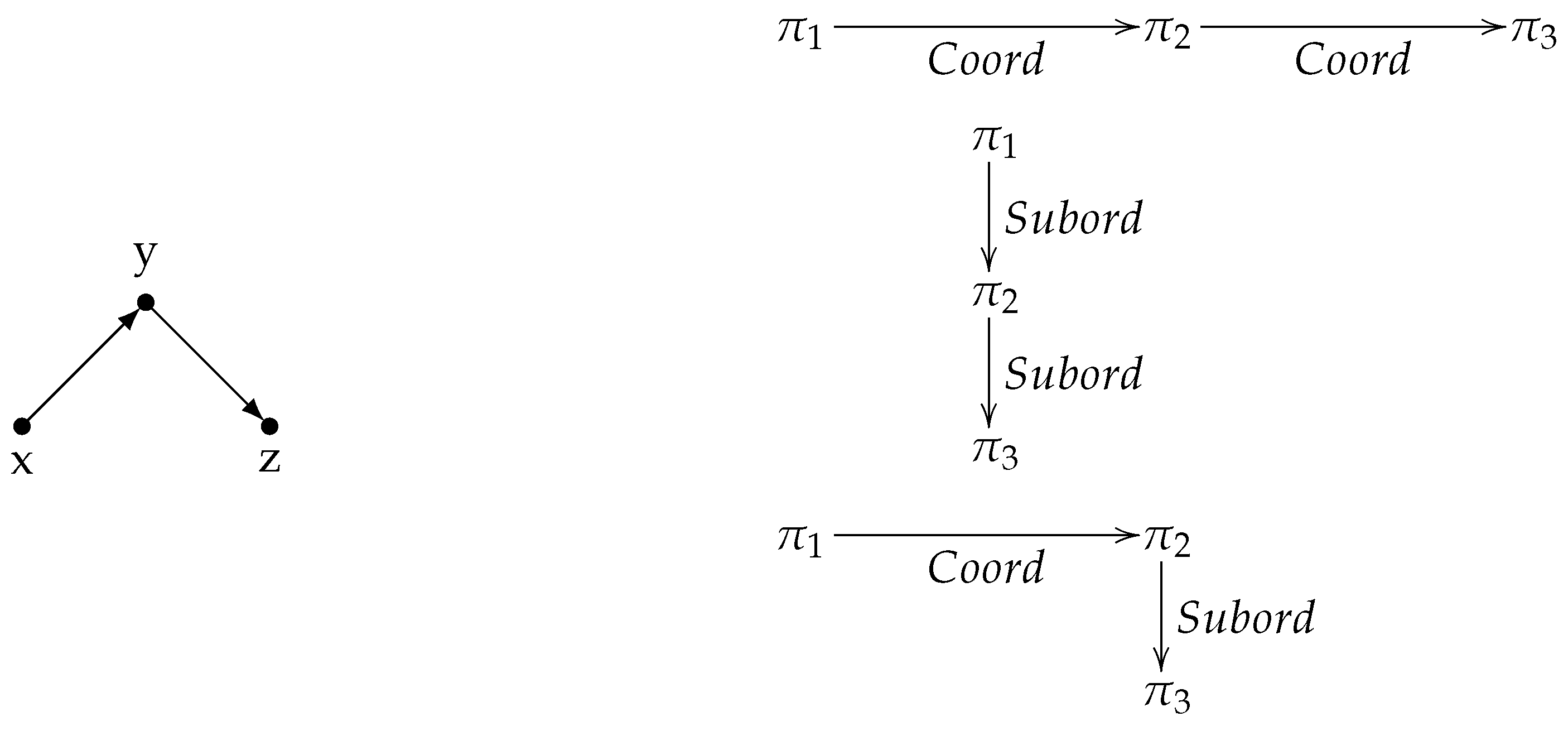
Subordinating and Coordinating Relations
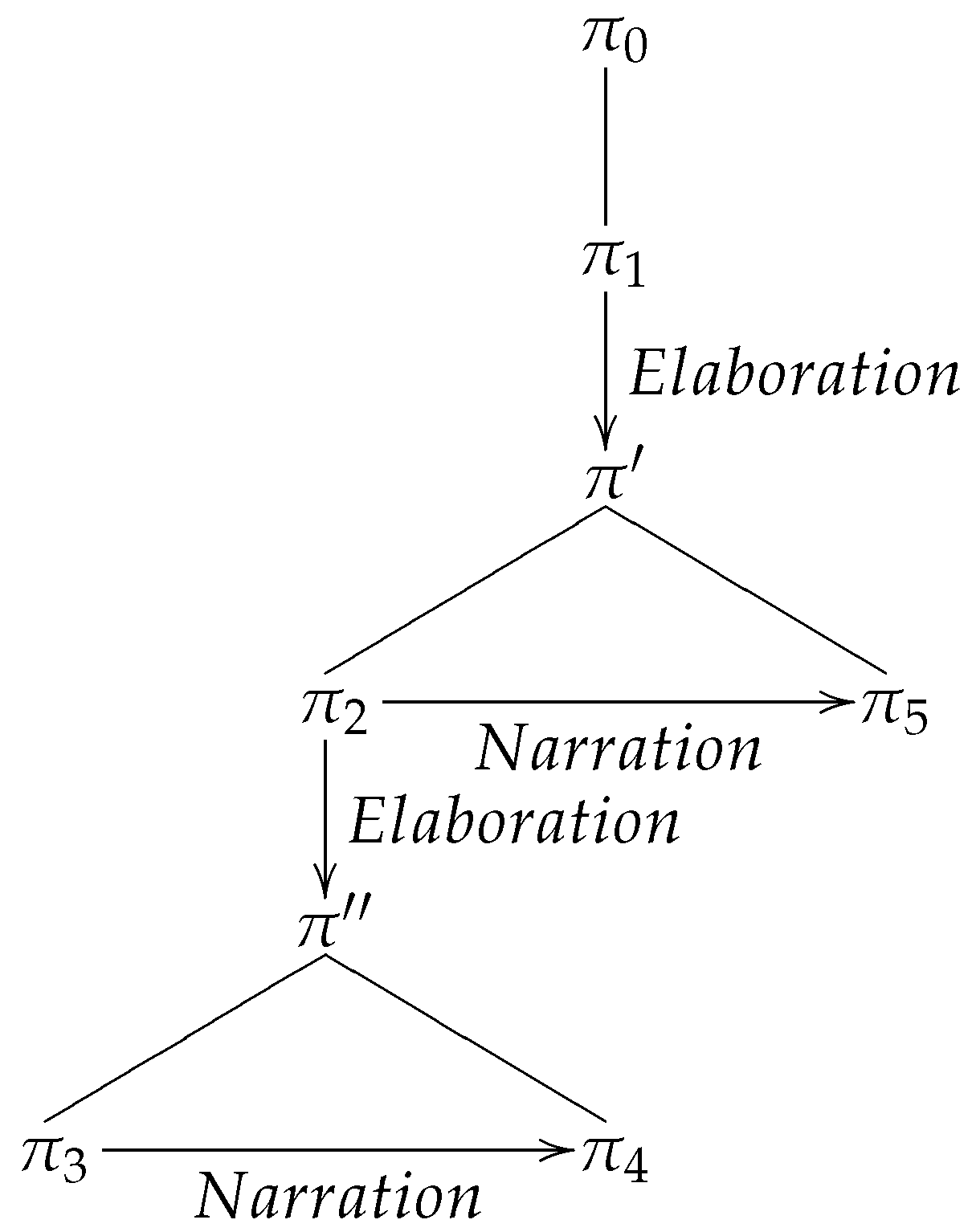
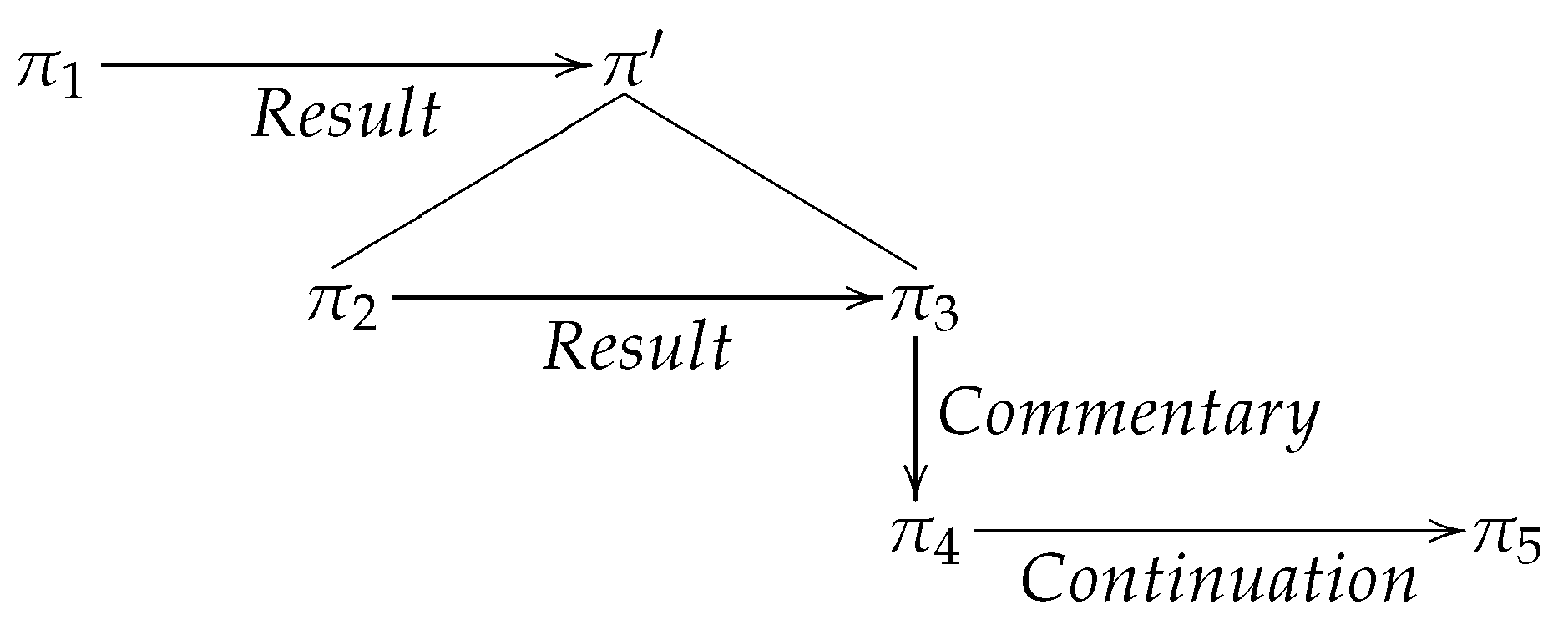
2.2. Complex Discourse Units
—Undirected unlabeled edges connect a Complex Constituent to its subconstituents, introducing recursivity in the structure.Hence, a Complex Discourse Unit or Complex Constituent is a node of the graph that has some subconstituents identified by the second kind of edge. We may write as shortcut for α is a subconstituent of π.
- 3.
- John had a great evening last night.He had a great meal.He ate salmon.He devoured lots of cheese.He won a dancing competition.
2.3. Elementary Event Units
- 4.
- william rolled a 6 and a 1 [Server].william will move the robber [UI].william stole a resource from GWFS [Server].oucho [GWFS]you can have it back for some ore. [william]
3. The Datasets
3.1. The STAC Corpus
3.2. The C58 Corpus
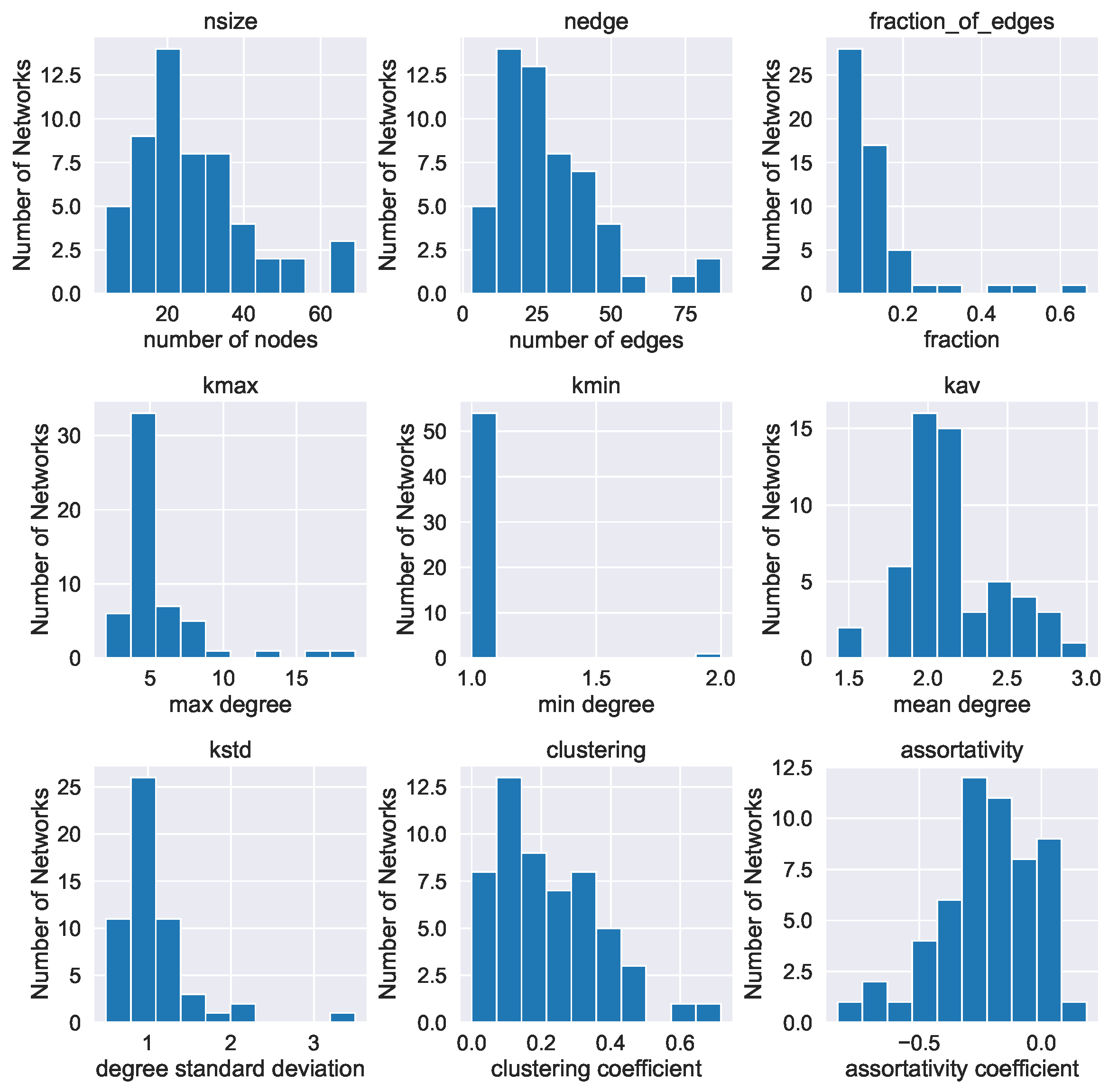
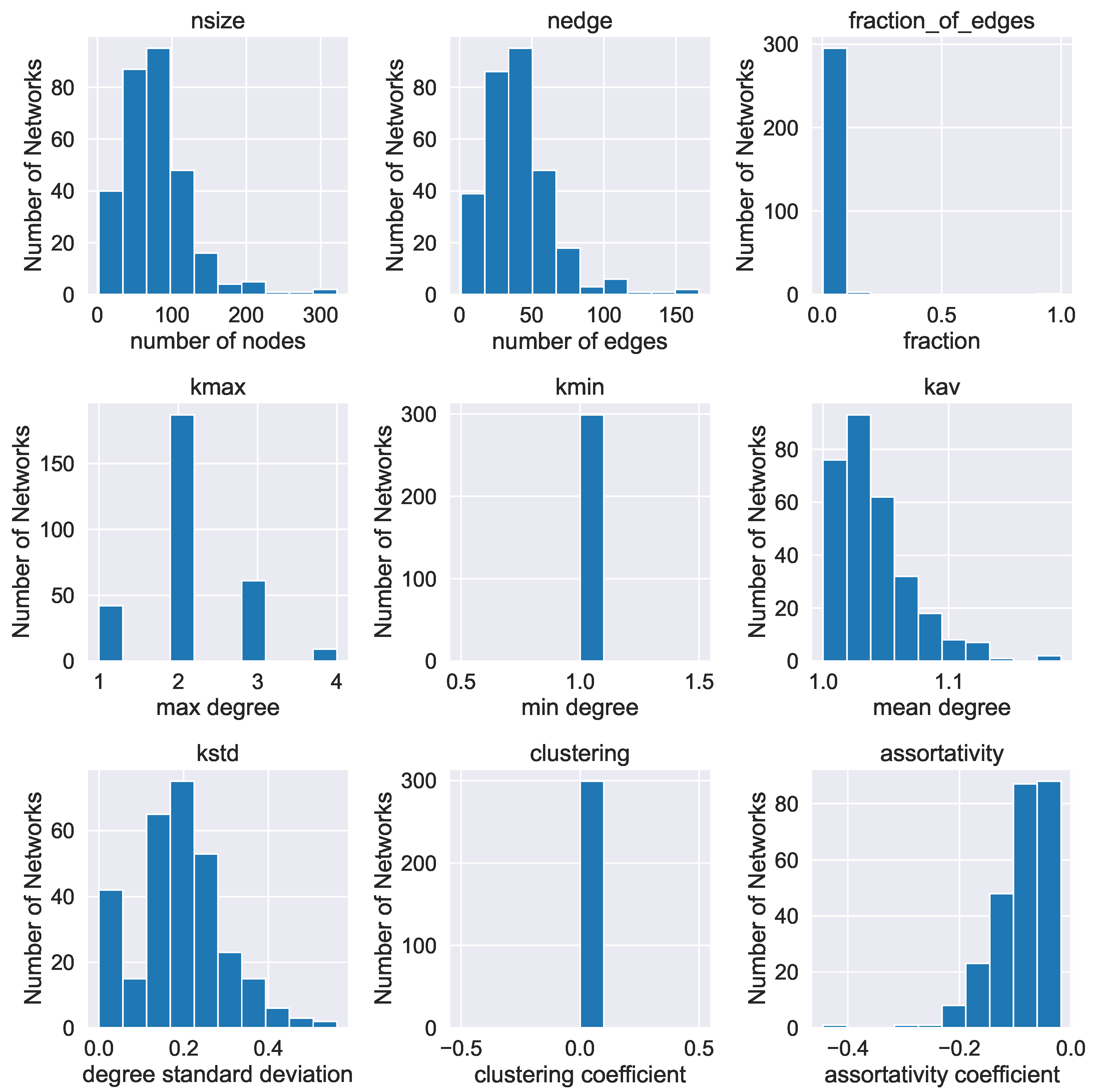
4. Networks and Connectivity
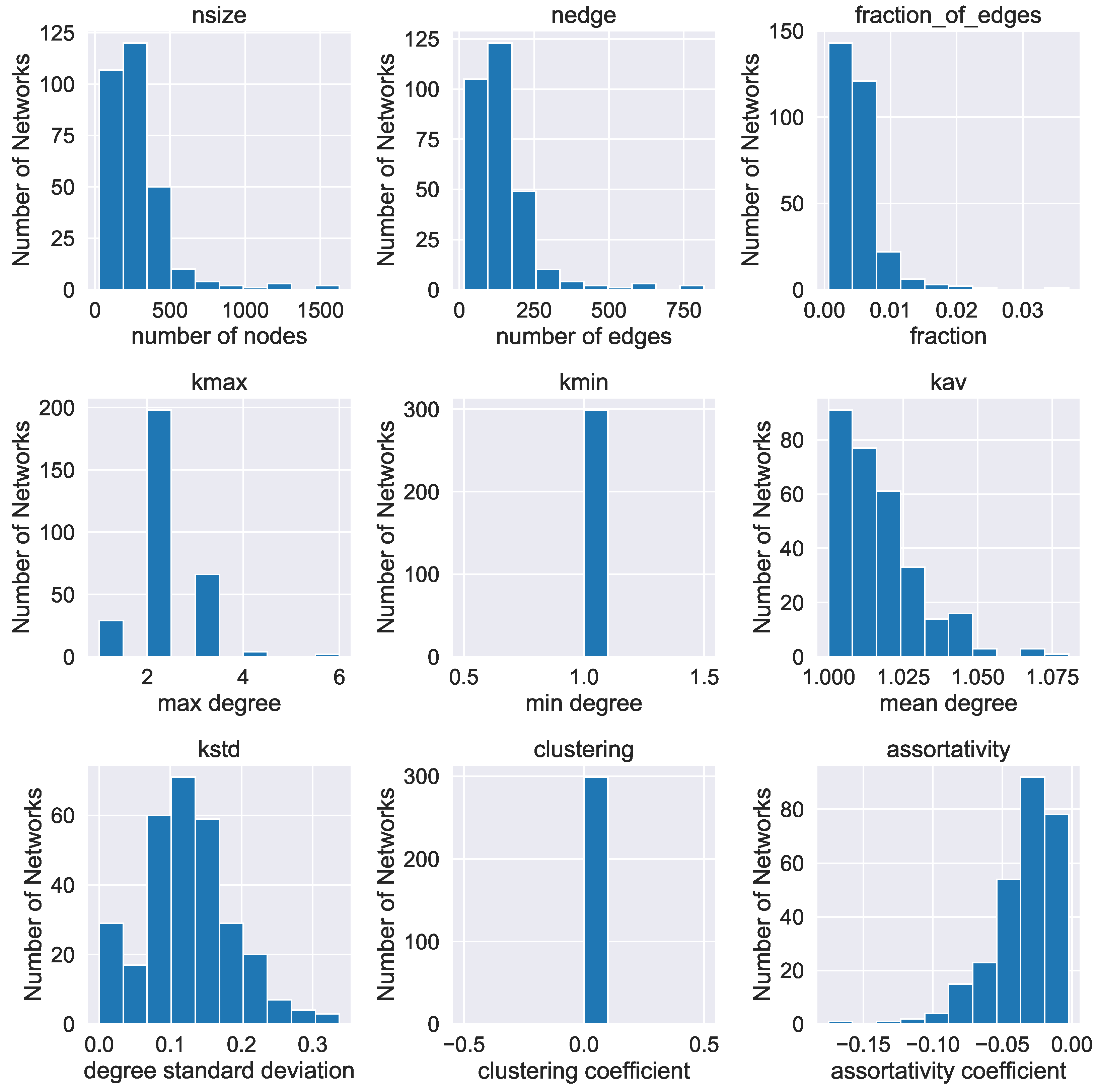
4.1. Key Network Indices and Their Relevance to Discourse
- (a)
- The number of nodes and the number of edges of the network. In terms of discourse networks, these two indices indicate the size of the network.
- (b)
- The fraction of edges , which is the ratio of the number of edges to the maximum possible number of edges , i.e.,where we use the fact that the max number of undirected edges in a network of nodes is . The fraction is a number between zero and one. In terms of discourse graphs, if is closer to 0, it can be interpreted as an indicator of low connectivity, while in the opposite case, the discourse graph can be considered to have a highly connected structure.
- (c)
- The degree centrality of a node is a non-negative integer denoting the number of edges emanating from a node. In our case, utterance labels with a high node degree can be interpreted as having high significance for the discourse evolvement. Here, we study the maximum, minimum and average degree of a network’s nodes , and , respectively, as well as the standard deviation of the degree distribution .
- (d)
- The mean clustering coefficient C. The (local) clustering coefficient of a node i in a network is defined aswhere is the number of triangles (loops of length 3) attached to this node divided by the maximum possible number of such loops ([49]). Here, we compute the average of the local clustering coefficients. It is a number in the range . Clustering coefficient values indicate that two nodes connected to a third common node have a high probability of also being connected to each other. Social networks are typically networks with a high clustering coefficient, since it is probable that individuals that have a common acquaintance know each other as well ([48,59,62]).
- (e)
- The degree assortativity coefficient r ([63]). A network is assortative when nodes of high degree tend to connect to nodes with high degree. It is disassortative when nodes of high degree tend to connect to nodes with low degree. The assortativity coefficient r lies in the range , with indicating perfect assortativity and indicating perfect disassortativity. To be more formal, the assortativity coefficient r is defined asThe term is the distribution of the remaining degree, i.e., the number of edges leaving the node, other than the one that connects the pair. This distribution can be derived from the degree distribution as ([63]). The quantity represents the joint probability distribution of the remaining degrees of the two vertices. This quantity is symmetric on a undirected graph and follows the sum rule and .
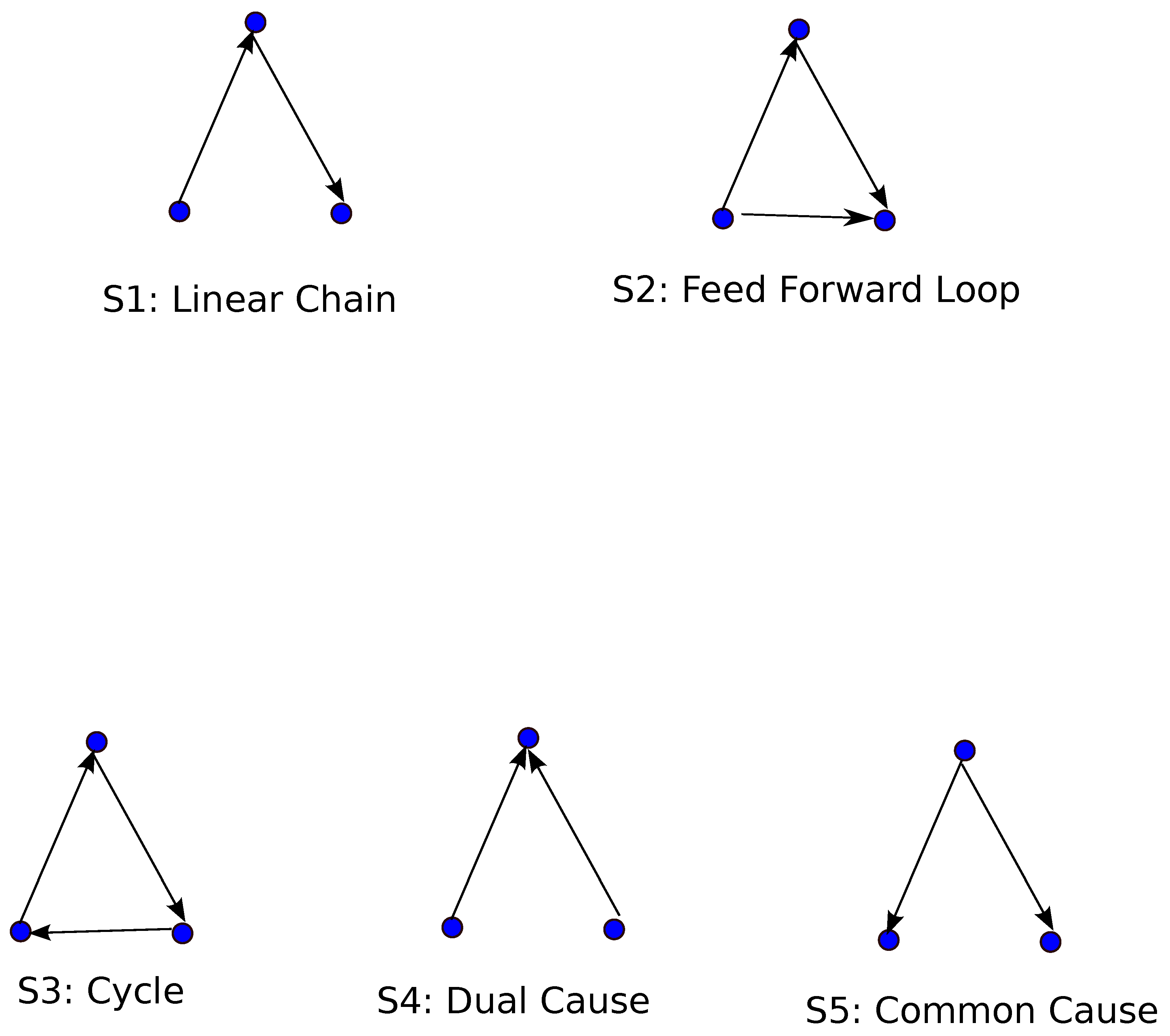
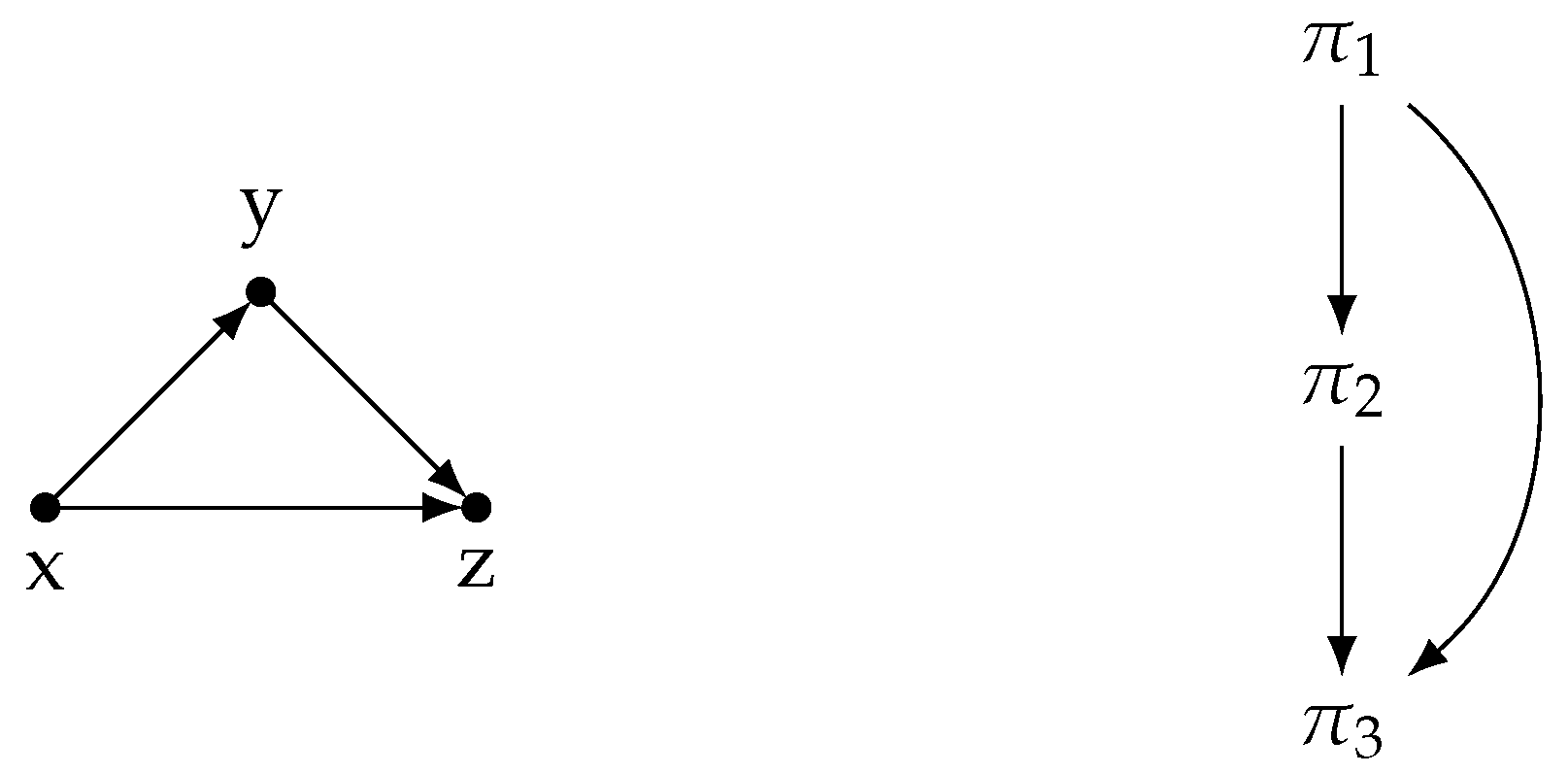
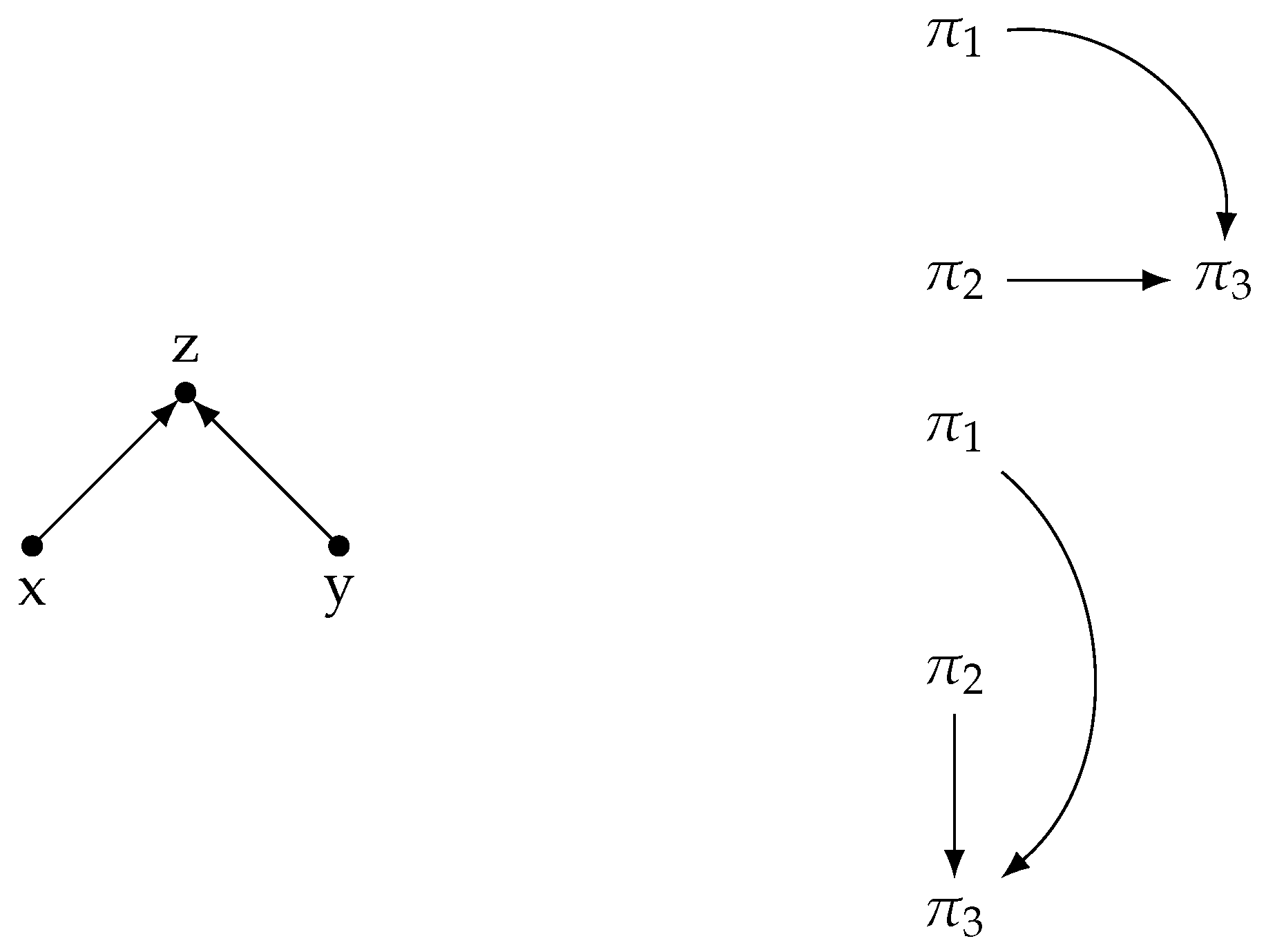
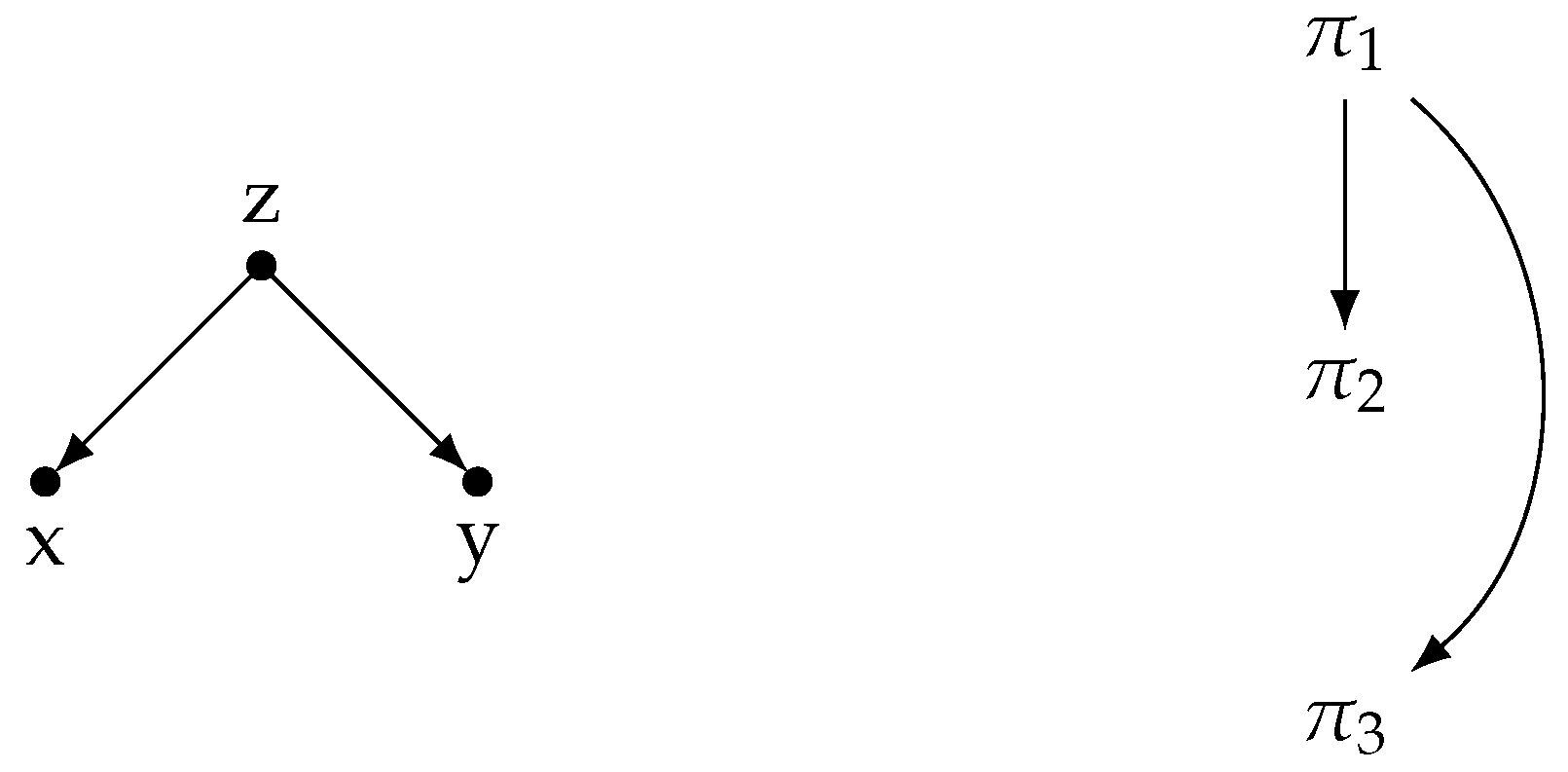
4.2. Network Motifs and Discourse Structure
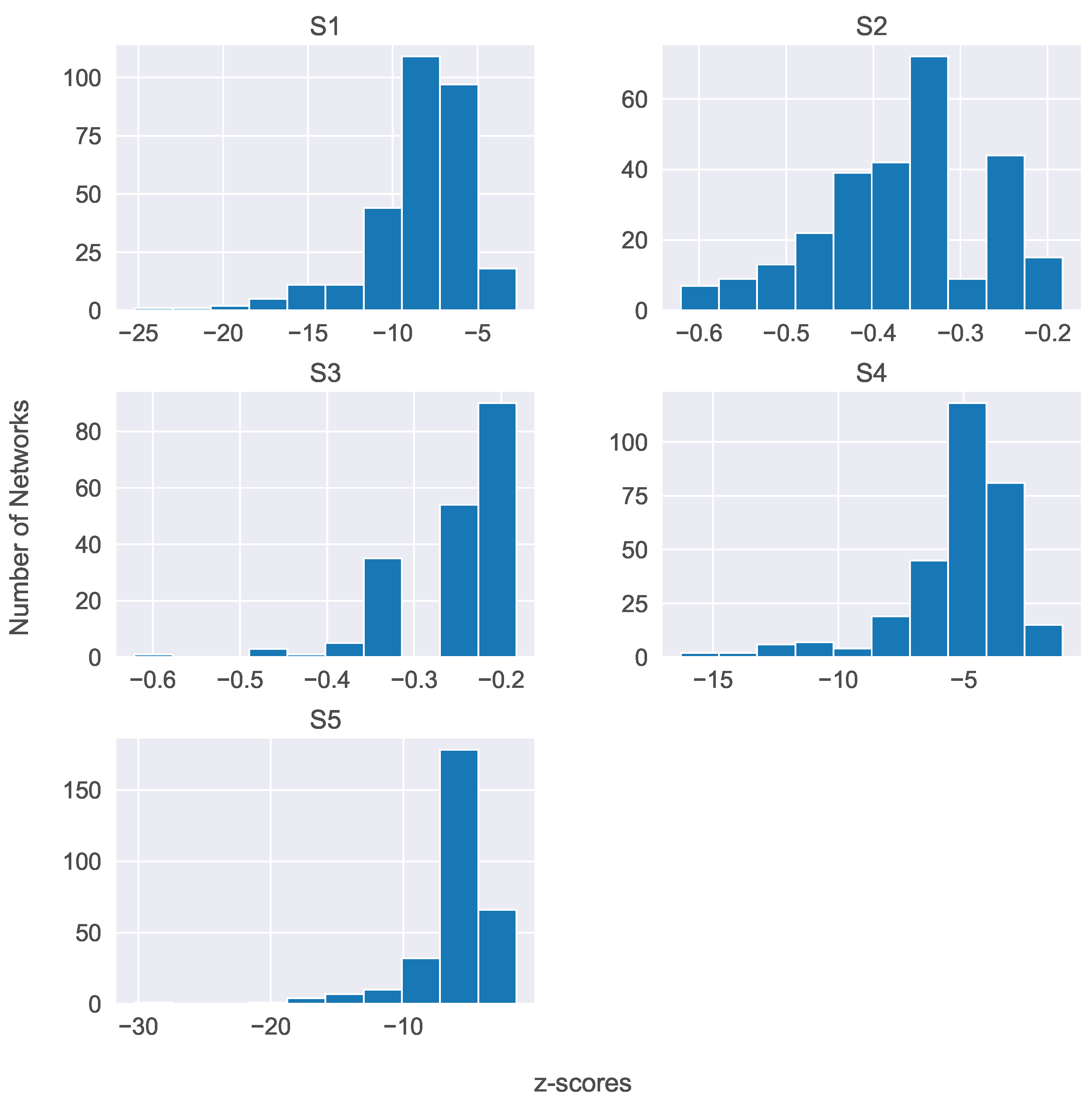
5. Interrogating the C58 and the STAC Networks
6. Discussion
- 1.
- The linear chain pattern () is not frequently observed as a motif in C58, despite the expectation that journalistic discourse would involve uninterrupted related sequences. In contrast, both versions of STAC systematically avoided the subgraph pattern, as evidenced by the absence of occurrences (see Table A2). These findings suggest that multiparty dialogue networks tend to avoid three uninterrupted related utterances, indicating that speakers do not participate in or contribute to a continuous line or chain of utterances. In C58, authors neither avoid nor prefer to establish connections between utterances in the form of a linear chain pattern.
- 2.
- The feed-forward pattern () emerges as a motif in C58, indicating a statistically significant preference for constructing fully connected three-node subgraphs in most single-author written texts. This finding highlights the strong preference for fully connected three-node subgraphs in the discourse structures of single-author written texts. On the other hand, the two STAC discourse networks do not exhibit a network motif or antimotif, although it should be noted that no occurrences of the subgraph pattern were recorded in these networks.
- 3.
- Among all three discourse networks, the dual-cause pattern () stands out as the only subgraph pattern that acts as an antimotif. In the three-node subgraphs of , there is a node with two incoming edges originating from two utterance labels, and , which are not directly related to each other but precede in the discourse.
- 4.
- The common-cause pattern () serves as an antimotif for the STAC corpora, while it does not exhibit characteristics of either a motif or an antimotif in the C58 corpus. This suggests that a commonly observed discourse strategy does not favor the scattered presentation of various aspects of an event described by an utterance. More typically, we witness a sequence of utterances that play a subordinate role to an initial utterance. It is generally avoided to circle back later in the discourse to add more aspects to that initial utterance.
- Aw Table 1 illustrates, both versions of the STAC corpus exhibit similar behavior regarding the four three-node subgraph patterns. This similarity suggests that the additional structures introduced by annotating EEUs (Embedded Event Units) and their interactions with other discourse units in the situated STAC corpus strongly avoid the same three subgraph patterns (, and ) observed in the discourse-annotated structures of the chat-only STAC corpus. This parallelism between the two STAC versions supports the argument made by [28,29,37] that EEUs introduce higher-level structures with their own complexity and idiosyncrasies. In other words, if the presence of EEUs were random and lacked systematic structure, the distribution of the corresponding subgraph patterns in the situated STAC corpus would resemble that of a randomly generated network, rendering it inconclusive for the existence of motifs or antimotifs (see Table A1).
- This study’s findings indicate that the presence of the antimotifs and in the STAC discourse networks suggests a strong restriction on establishing discourse relations between and when there is a distant discourse relation between them, and does not serve as the bridge connecting and . This restriction imposed by the discourse structure may be influenced by the distance between the two utterance labels, and , as the distance in terms of utterances is expected to impact the development of discourse in multiparty dialogue texts. However, it is important to note that the baseline approach of attaching an utterance label to the last available in the discourse, as noted by [72], fails to capture 40% of attachments in the ANNODIS corpus. This empirical fact emphasizes that there are numerous attachment candidates for a given that extend beyond its immediate vicinity, further supporting the argument for the strong restriction imposed by the discourse structure.
- A general observation related to and is that although both are considered antimotifs for the two STAC discourse networks, there is a noticeable difference between the two types, since occurrences of the pattern have been recorded in both corpora, while no occurrence has been observed for the pattern. However, as mentioned above, the presence or absence of a specific pattern, although interesting in itself, does not suffice to term a pattern as motif or antimotif. is an antimotif for the C58 discourse networks, too, as mentioned above, but since is neither a motif nor an antimotif for these discourse networks, our network analysis suggests that the above-mentioned restriction holds for both corpora but only for the dual-cause pattern, .
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. Basic Statistics for a Number of Real-World Networks

{kind=link}
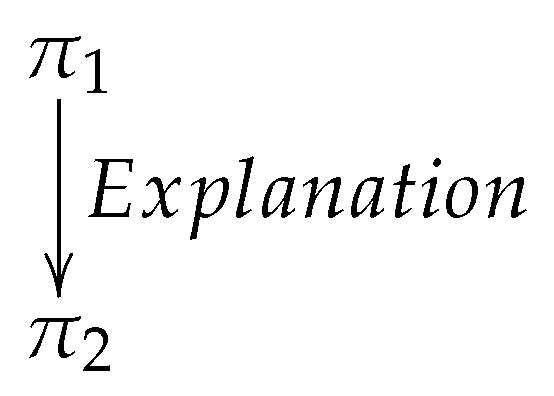{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Nsize | Nedge | C | r |
|---|---|---|---|---|
| Film actors | 449,913 | 25,516,482 | 0.78 | 0.208 |
| Company Directors | 7673 | 55,392 | 0.88 | 0.276 |
| Math coauthorship | 253,339 | 496,489 | 0.34 | 0.120 |
| Physics coauthorship | 52,909 | 245,300 | 0.56 | 0.363 |
| Biology coauthorship | 1,520,251 | 11,803,064 | 0.60 | 0.127 |
| Email address books | 16,881 | 57,029 | 0.13 | 0.092 |
| Student dating | 573 | 477 | 0.001 | −0.029 |
| WWW nd.edu | 269,504 | 1,497,135 | 0.29 | −0.067 |
| Roget’s thesaurus | 1022 | 5103 | 0.15 | 0.157 |
| Internet | 10,697 | 31,992 | 0.039 | −0.189 |
| Power grid | 4941 | 6594 | 0.080 | −0.003 |
| Train routes | 587 | 19,603 | 0.69 | −0.033 |
| Software packages | 1439 | 1723 | 0.082 | −0.016 |
| Software classes | 1376 | 213 | 0.012 | −0.119 |
| Electronic circuits | 24,097 | 53,248 | 0.030 | −0.154 |
| Peer-to-Peer network | 880 | 1269 | 0.011 | −0.366 |
| Metabolic network | 765 | 3686 | 0.67 | −0.240 |
| Protein interactions | 2115 | 2240 | 0.071 | −0.156 |
| Marine food web | 134 | 598 | 0.23 | −0.263 |
| Freshwater food web | 92 | 997 | 0.087 | −0.326 |
| Neural network | 307 | 2359 | 0.28 | −0.226 |
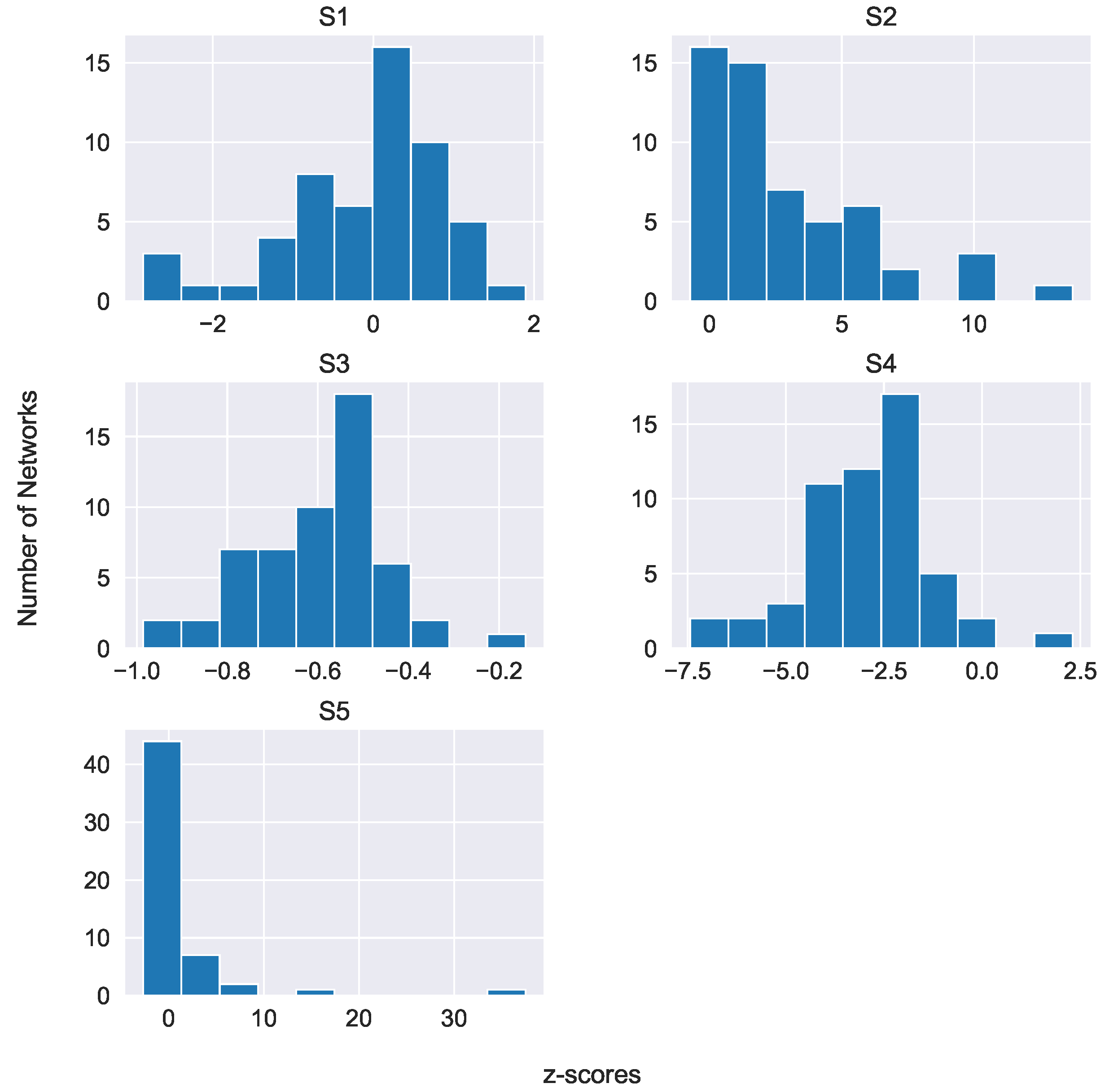
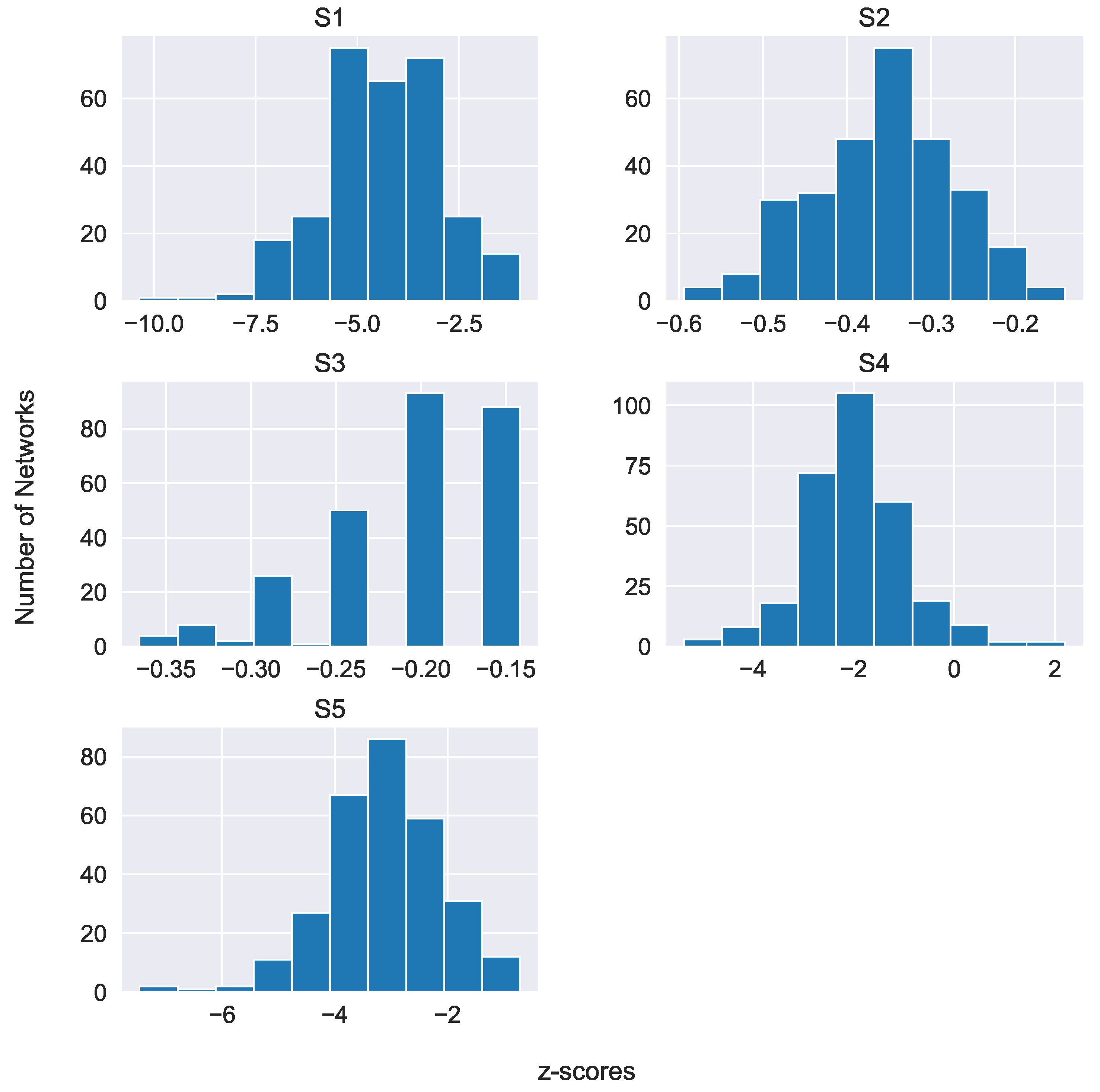
Appendix A.2. Mean Values of the S* Patterns in the Three Datasets
| Dataset | |||||
|---|---|---|---|---|---|
| C58 | 24.06 | 4.24 | 0 | 1.33 | 17.69 |
| STAC (chat-only) | 0 | 0 | 0 | 3.64 | 0 |
| STAC (situated) | 0 | 0 | 0 | 4.64 | 0 |
References
- Webber, B.; Joshi, A. Discourse Structure and Computation: Past, Present and Future. In Proceedings of the ACL-2012 Special Workshop on Rediscovering 50 Years of Discoveries, Jeju Island, Republic of Korea, 10 July 2012; pp. 42–54. [Google Scholar]
- Lai, A.; Tetreault, J. Discourse Coherence in the Wild: A Dataset, Evaluation and Methods. In Proceedings of the 19th Annual SIGdial Meeting on Discourse and Dialogue, Melbourne, Australia, 12–14 July 2018; pp. 214–223. [Google Scholar] [CrossRef]
- Narasimhan, K.; Barzilay, R. Machine Comprehension with Discourse Relations. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 26–31 July 2015; pp. 1253–1262. [Google Scholar] [CrossRef]
- Jiang, L.; Yuan, S.; Li, J. A Discourse Coherence Analysis Method Combining Sentence Embedding and Dimension Grid. Complexity 2021, 2021, 6654925. [Google Scholar] [CrossRef]
- Liu, J.; Cohen, S.B.; Lapata, M. Discourse Representation Structure Parsing with Recurrent Neural Networks and the Transformer Model. In Proceedings of the IWCS Shared Task on Semantic Parsing, Gothenburg, Sweden, 27 May 2019. [Google Scholar] [CrossRef]
- van Noord, R.; Abzianidze, L.; Toral, A.; Bos, J. Exploring Neural Methods for Parsing Discourse Representation Structures. Trans. Assoc. Comput. Linguist. 2018, 6, 619–633. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Meng, F.; Li, P.; Jian, P.; Zhou, J. Context tracking network: Graph-based context modeling for implicit discourse relation recognition. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 1592–1599. [Google Scholar]
- Ma, Y.; Zhu, J.; Liu, J. Enhanced semantic representation learning for implicit discourse relation classification. Appl. Intell. 2022, 52, 7700–7712. [Google Scholar] [CrossRef]
- Jiang, C.; Qian, T.; Liu, B. Knowledge Distillation for Discourse Relation Analysis. In Proceedings of the Companion Proceedings of the Web Conference 2022, Lyon, France, 25–29 April 2022; pp. 210–214. [Google Scholar]
- Gupta, K.; Ripberger, J.; Fox, A.; Jenkins-Smith, H.; Silva, C. Discourse Network Analysis of Nuclear Narratives. In Narratives and the Policy Process: Applications of the Narrative Policy Framework; Pressbooks: Montreal, QC, Canada, 2022. [Google Scholar]
- Wu, C.; Cao, L.; Ge, Y.; Liu, Y.; Zhang, M.; Su, J. A Label Dependence-aware Sequence Generation Model for Multi-level Implicit Discourse Relation Recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 11486–11494. [Google Scholar]
- Xiang, W.; Wang, B. A survey of implicit discourse relation recognition. ACM Comput. Surv. 2023, 55, 1–34. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Lin, T.; Wang, Y.; Liu, X.; Qiu, X. A Survey of Transformers. arXiv 2021, arXiv:2106.04554. [Google Scholar] [CrossRef]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 3982–3992. [Google Scholar] [CrossRef] [Green Version]
- Hobbs, J. On the Coherence and Structure of Discourse; Research Report 85-37; CSLI: Chicago, IL, USA, 1985. [Google Scholar]
- Grosz, B.J.; Sidner, C.L. Attention, Intentions, and the Structure of Discourse. Comput. Linguist. 1986, 12, 175–204. [Google Scholar]
- Polanyi, L.; Scha, R. A syntactic approach to discourse semantics. In Proceedings of the 10th International Conference on Computational Linguistics (COLING84), Stroudsburg, PA, USA, 2–6 July 1984; pp. 413–419. [Google Scholar]
- Polanyi, L. A theory of discourse structure and discourse coherence. In Proceedings of the Papers from the General Session at the 21st Regional Meeting of the Chicago Linguistic Society, Chicago, IL, USA, 26–28 April 1985; Eilfort, P.D.K.W.H., Peterson, K.L., Eds.; Chicago Linguistic Society: Chicago, IL, USA, 1985. [Google Scholar]
- Polanyi, L. A Formal Model of the Structure of Discourse. J. Pragmat. 1988, 12, 601–638. [Google Scholar] [CrossRef]
- Asher, N. Reference to Abstract Objects in Discourse; Springer: Berlin/Heidelberg, Germany, 1993; Available online: https://link.springer.com/book/10.1007/978-94-011-1715-9 (accessed on 12 April 2023).
- Kuppevelt, J.V. Main structure and side structure in discourse. Linguistics 1995, 33, 809–833. [Google Scholar] [CrossRef]
- Asher, N.; Lascarides, A. Logics of Conversation; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Knott, A. Coherence in natural language: Data stuctures and applications. Comput. Linguist. 2007, 33, 591–595. [Google Scholar] [CrossRef]
- Rohde, H.; Johnson, A.; Schneider, N.; Webber, B. Discourse Coherence: Concurrent Explicit and Implicit Relations. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 2257–2267. [Google Scholar] [CrossRef]
- Tantos, A.; Chatziioannidis, G.; Lykou, K.; Papatheohari, M.; Samara, A.; Vlachos, K. Corpus C58 and a data-analytic approach to the interface between intra- and inter-sentential linguistic information. In Proceedings of the 12th International Conference on Greek Linguistics, Berlin, Germany, 30 August–1 September 2017; pp. 961–976. [Google Scholar]
- Nicolas, A.; Hunter, J.; Morey, M.; Benamara, F.; Afantenos, S. Discourse structure and dialogue acts in multiparty dialogue: The STAC corpus. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016), Portoroz, Slovenia, 23–28 May 2016; pp. 2721–2727. [Google Scholar]
- Hunter, J.; Asher, N.; Lascarides, A. A formal semantics for situated conversation. Semantics and Pragmatics. Semant. Pragmat. 2018, 11, 10-EA. [Google Scholar] [CrossRef]
- Asher, N.; Hunter, J.; Thompson, K. Modelling Structures for Situated Discourse. Dialogue Discourse 2020, 11, 89–121. [Google Scholar] [CrossRef]
- Barabási, A.L. Network science. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2013, 371, 20120375. [Google Scholar] [CrossRef] [PubMed]
- Newman, M. Networks: An Introduction; Oxford University Press, Inc.: Oxford, UK, 2010. [Google Scholar]
- Barabási, A.L.; Pósfai, M. Network Science; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar]
- Mann, W.; Thompson, S. Rhetorical structure theory: Toward a functional theory of text organization. Text-Interdiscip. J. Study Discourse 1988, 8, 243–281. [Google Scholar] [CrossRef]
- Polanyi, L.; Culy, C.; van den Berg, M.; Thione, G.L.; Ahn, D. A Rule Based Approach to Discourse Parsing. In Proceedings of the 5th SIGdial Workshop on Discourse and Dialogue at HLT-NAACL 2004, Cambridge, MA, USA, 30 April–1 May 2004; pp. 108–117. [Google Scholar]
- Wolf, F.; Gibson, E. Representing Discourse Coherence: A Corpus-Based Study. Comput. Linguist. 2005, 31, 249–287. [Google Scholar] [CrossRef]
- Creswell, C.; Forbes, K.; Miltsakaki, E.; Prasad, R.; Joshi, A. Penn Discourse Treebank: Building a Large Scale Annotated Corpus Encoding DLTAG-Based Discourse Structure and Discourse Relations. In Proceedings of the Penn Discourse Treebank, 2003; p. 8. Available online: https://www.semanticscholar.org/paper/Treebank-%3A-Building-a-Large-Scale-Annotated-Corpus-Creswell-Forbes/59bde1c696ccdf902eff2c91c2e6525fd46d0b82 (accessed on 12 April 2023).
- Hunter, J.; Asher, N.; Lascarides, A. Integrating nonlinguistic Events into Discourse Structure. In Proceedings of the 11th International Conference on Computational Semantics, London, UK, 14–17 April 2015; pp. 184–194. [Google Scholar]
- Asher, N.; Vieu, L. Subordinating and coordinating discourse relations. Lingua 2005, 115, 591–610. [Google Scholar] [CrossRef]
- Webber, B.L. Discourse Deixis and Discourse Processing; University of Pennsylvania: Philadelphia, PA, USA, 1988. [Google Scholar]
- Prévot, L.; Vieu, L. The moving right frontier. In Constraints in Discourse, Pragmatics and Beyond New Series; John Benjamins Publishing Company: Amsterdam, The Netherlands, 2008; Chapter 3; pp. 53–66. [Google Scholar]
- Asher, N.; Venant, A.; Muller, P.; Afantenos, S. Complex discourse units and their semantics. In CID 2011—Constraints in Discourse; Nicholas Asher, L.D., Ed.; Agay: Saint-Raphael, France, 2011. [Google Scholar]
- Prasad, R.; Dinesh, N.; Lee, A.; Miltsakaki, E.; Robaldo, L.; Joshi, A.; Webber, B. The Penn Discourse TreeBank 2.0. In Proceedings of the Sixth International Conference on Language Resources and Evaluation (LREC’08), Marrakech, Morocco, 26 May–1 June 2008. [Google Scholar]
- Carlson, L.; Okurowski, M.E.; Marcu, D. RST Discourse Treebank, LDC2002T07. In RST Discourse Treebank, Linguistic Data Consortium; Number LDC2002T07; University of Pennsylvania: Philadelphia, PA, USA, 2002. [Google Scholar]
- Baldridge, J.; Asher, N.; Hunter, J. Annotation for and Robust Parsing of Discourse Structure on Unrestricted Texts. Z. Sprachwiss. 2007, 26, 213–239. [Google Scholar] [CrossRef]
- Afantenos, S.; Asher, N.; Benamara, F.; Bras, M.; Fabre, C.; Ho-dac, M.; Draoulec, A.L.; Muller, P.; Péry-Woodley, M.P.; Prévot, L.; et al. An empirical resource for discovering cognitive principles of discourse organisation: The ANNODIS corpus. In Proceedings of the Eighth International Conference on Language Resources and Evaluation (LREC’12), Istanbul, Turkey, 23–25 May 2012; pp. 2727–2734. [Google Scholar]
- Barabási, A.L.; Albert, R. Emergence of Scaling in Random Networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.E.J.; Strogatz, S.H.; Watts, D.J. Random graphs with arbitrary degree distributions and their applications. Phys. Rev. E 2001, 64, 026118. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.; Barabási, A.L.; Watts, D.J. The Structure and Dynamics of Networks; Princeton University Press: Princeton, NJ, USA, 2006. [Google Scholar]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of ‘small-world’networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef]
- Milo, R.; Alon, U. Network Motifs: Simple Building Blocks of Complex Networks. Science 2002, 298, 824–827. [Google Scholar] [CrossRef] [Green Version]
- Choudhury, M.; Mukherjee, A. The structure and dynamics of linguistic networks. In Dynamics on and of Complex Networks; Springer: Boston, MA, USA, 2009; pp. 145–166. [Google Scholar]
- Mehler, A.; Lücking, A.; Banisch, S.; Blanchard, P.; Job, B. Towards a Theoretical Framework for Analyzing Complex Linguistic Networks; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Mehler, A. Large text networks as an object of corpus linguistic studies. In Corpus Linguistics. An International Handbook of the Science of Language and Society; De Gruyter: Berlin, Germany, 2008; pp. 328–382. [Google Scholar]
- Song, C.; Havlin, S.; Makse, H.A. Self-similarity of complex networks. Nature 2005, 433, 392–395. [Google Scholar] [CrossRef] [Green Version]
- Song, C.; Havlin, S.; Makse, H.A. Origins of fractality in the growth of complex networks. Nat. Phys. 2006, 2, 275–281. [Google Scholar] [CrossRef] [Green Version]
- Barzel, B.; Barabási, A.L. Universality in network dynamics. Nat. Phys. 2013, 9, 673–681. [Google Scholar] [CrossRef] [Green Version]
- Lacasa, L.; Luque, B.; Ballesteros, F.; Luque, J.; Nuño, J.C. From time series to complex networks: The visibility graph. Proc. Natl. Acad. Sci. USA 2008, 105, 4972–4975. [Google Scholar] [CrossRef] [Green Version]
- D’Souza, R.M.; Gómez-Gardeñes, J.; Nagler, J.; Arenas, A. Explosive phenomena in complex networks. Adv. Phys. 2019, 68, 123–223. [Google Scholar] [CrossRef]
- Clauset, A.; Moore, C.; Newman, M.E.J. Hierarchical structure and the prediction of missing links in networks. Nature 2008, 453, 98–101. [Google Scholar] [CrossRef] [Green Version]
- Bashan, A.; Bartsch, R.P.; Kantelhardt, J.W.; Havlin, S.; Ivanov, P.C. Network physiology reveals relations between network topology and physiological function. Nat. Commun. 2012, 3, 702. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Battiston, S.; Farmer, J.D.; Flache, A.; Garlaschelli, D.; Haldane, A.G.; Heesterbeek, H.; Hommes, C.; Jaeger, C.; May, R.; Scheffer, M. Complexity theory and financial regulation. Science 2016, 351, 818–819. [Google Scholar] [CrossRef] [Green Version]
- Kitsak, M.; Gallos, L.K.; Havlin, S.; Liljeros, F.; Muchnik, L.; Stanley, H.E.; Makse, H.A. Identification of influential spreaders in complex networks. Nat. Phys. 2010, 6, 888–893. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.E. Mixing patterns in networks. Phys. Rev. E 2003, 67, 026126. [Google Scholar] [CrossRef] [Green Version]
- Shen-Orr, S.S.; Milo, R.; Mangan, S.; Alon, U. Network motifs in the transcriptional regulation network of Escherichia coli. Nat. Genet. 2002, 31, 64–68. [Google Scholar] [CrossRef]
- Alon, U. An Introduction to Systems Biology: Design Principles of Biological Circuits; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Bullmore, E.; Sporns, O. Complex brain networks: Graph theoretical analysis of structural and functional systems. Nat. Rev. Neurosci. 2009, 10, 186–198. [Google Scholar] [CrossRef]
- Boyer, L.A.; Lee, T.I.; Cole, M.F.; Johnstone, S.E.; Levine, S.S.; Zucker, J.P.; Guenther, M.G.; Kumar, R.M.; Murray, H.L.; Jenner, R.G.; et al. Core transcriptional regulatory circuitry in human embryonic stem cells. Cell 2005, 122, 947–956. [Google Scholar] [CrossRef] [Green Version]
- Barabási, A.L.; Gulbahce, N.; Loscalzo, J. Network medicine: A network-based approach to human disease. Nat. Rev. Genet. 2011, 12, 56–68. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Marr, C.; Theis, F.J.; Liebovitch, L.S.; Hütt, M.T. Patterns of subnet usage reveal distinct scales of regulation in the transcriptional regulatory network of Escherichia coli. PLoS Comput. Biol. 2010, 6, e1000836. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Klosik, D.F.; Bornholdt, S.; Hütt, M.T. Motif-based success scores in coauthorship networks are highly sensitive to author name disambiguation. Phys. Rev. E 2014, 90, 032811. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Beber, M.E.; Fretter, C.; Jain, S.; Sonnenschein, N.; Müller-Hannemann, M.; Hütt, M.T. Artefacts in statistical analyses of network motifs: General framework and application to metabolic networks. J. R. Soc. Interface 2012, 9, 3426–3435. [Google Scholar] [CrossRef]
- Afantenos, S.D.; Asher, N. Testing SDRT’s Right Frontier. In Proceedings of the COLING 2010, 23rd International Conference on Computational Linguistics, Beijing, China, 23–27 August 2010; Huang, C., Jurafsky, D., Eds.; Tsinghua University Press: Beijing, China, 2010; pp. 1–9. [Google Scholar]
- Lascarides, A.; Copestake, A.A.; Briscoe, T. Ambiguity and Coherence. J. Semant. 1996, 13, 41–65. [Google Scholar] [CrossRef] [Green Version]
- Asher, N.; Lascarides, A. Bridging. J. Semant. 1998, 15, 83–113. [Google Scholar] [CrossRef]
- Asher, N.; Lascarides, A. The Semantics and Pragmatics of Presupposition. J. Semant. 1998, 15, 239–300. [Google Scholar] [CrossRef] [Green Version]
- Hagberg, A.; Swart, P.; Chult, D.S. Exploring Network Structure, Dynamics, and Function Using NetworkX; Technical Report; Los Alamos National Lab. (LANL): Los Alamos, NM, USA, 2008. [Google Scholar]
- Treinish, M.; Carvalho, I.; Tsilimigkounakis, G.; Sá, N. retworkx: A High-Performance Graph Library for Python. arXiv 2021, arXiv:2110.15221. [Google Scholar]
- Dask Development Team. Dask: Library for Dynamic Task Scheduling; Dask Development Team: 2016. Available online: https://docs.dask.org/en/stable/ (accessed on 12 April 2023).
- Guidi, B.; Michienzi, A.; Ricci, L. A graph-based socioeconomic analysis of steemit. IEEE Trans. Comput. Soc. Syst. 2020, 8, 365–376. [Google Scholar] [CrossRef]















| Corpora | ||||
|---|---|---|---|---|
| C58 | neither | motif | antimotif | neither |
| STAC (chat-only) | antimotif | neither | antimotif | antimotif |
| STAC (situated) | antimotif | neither | antimotif | antimotif |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tantos, A.; Kosmidis, K. From Discourse Relations to Network Edges: A Network Theory Approach to Discourse Analysis. Appl. Sci. 2023, 13, 6902. https://doi.org/10.3390/app13126902
Tantos A, Kosmidis K. From Discourse Relations to Network Edges: A Network Theory Approach to Discourse Analysis. Applied Sciences. 2023; 13(12):6902. https://doi.org/10.3390/app13126902
Chicago/Turabian StyleTantos, Alexandros, and Kosmas Kosmidis. 2023. "From Discourse Relations to Network Edges: A Network Theory Approach to Discourse Analysis" Applied Sciences 13, no. 12: 6902. https://doi.org/10.3390/app13126902