1. Introduction
The intensive care unit (ICU) provides comprehensive, life-saving care for critically ill patients. It has become an essential part of hospital-based care, providing specialized technical and professional expertise to help prevent the progression of severe illness in cases of acute life-threatening organ dysfunction or injury [
1,
2]. However, the increasing demand for critical care for patients with serious health conditions limits the capacity of the ICU. This can result, for example, in a limited number of beds available for patients or excessive workloads for medical and hospital staff, leading to delays in ICU admissions and ultimately increased morbidity and mortality. The COVID-19 pandemic in early 2020 and the months that followed highlighted this problem, as it created an urgent need for hospital space, supplies, and medical personnel, and placed a significant strain on healthcare systems worldwide [
3,
4]. Such an imbalance between supply and demand has implications not only for patient care, but also for public health, with the associated socioeconomic consequences. It is therefore of great importance to understand, plan, and coordinate ICU resources in order to provide optimal care for patients with critical illnesses in the future [
5,
6].
The patient’s length of stay (LOS) in the ICU is a process measure of ICU efficiency and effectiveness that is widely used as an indicator of ICU performance and possibly quality of care [
7,
8,
9], albeit controversially [
10,
11,
12]. LOS typically refers to the length of time that a patient spends in the ICU from admission to discharge. A prolonged stay in the ICU is associated with higher care costs and resource utilization, while early discharge from the ICU can lead to medical complications and an increased risk of readmission to the ICU or even higher mortality [
13,
14]. Therefore, an accurate estimate of the patient’s LOS in the ICU, based on the patient’s initial health data, helps healthcare management in the appropriate resource allocation and better planning for the future. Healthcare research has long relied on physicians’ subjective estimates [
5,
15,
16], which have been shown to be less than accurate [
17,
18]. However, advances in machine learning (ML) algorithms, coupled with the increasing availability of larger amounts of critical care data, have paved the way for the development of more accurate predictive models of critical care outcomes [
19,
20,
21,
22,
23].
The development of ML models for predicting LOS in the ICU has been the subject of numerous studies. ML research in healthcare, however, is not without challenges and limitations [
23,
24,
25]. Practical progress in clinical ML has only been incremental and difficult to measure due to the vast diversity of clinical datasets and objectives, as well as the lack of common standard benchmarks for evaluating models [
24,
25]. Many ICU prediction models, for example, have been developed using data collected by local healthcare providers in a strictly private settings with limited external access, and are therefore not generalizable [
20,
26]. Moreover, most health data features (attributes) are highly variable across institutions, reflecting different underlying populations, clinical conditions, or even global health issues [
24]. Similarly, many models have been developed for patients with specific diseases, such as cardiac disease [
27,
28], diabetes [
29,
30], or sepsis [
31], and are therefore not easily comparable.
The predictive models of any hospital LOS are typically divided into two main groups: models developed to predict LOS with continuous outcomes, such as the actual number of days (hours) a patient stays in the ICU, are referred to as regression, while others that partition patient LOS into (coarse) discrete groups, such as short vs. long stays, are referred to as classification [
26,
32,
33]. While studies have often adopted standard laboratory measurements to predict LOS in the ICU, some have relied on physiological scores, such as the Acute Physiology and Chronic Health Evaluation (APACHE) or the Simplified Acute Physiology Score (SAPS), and achieved higher accuracy [
34,
35]. Recent work has also leveraged deep learning methods, such as recurrent neural networks (RNNs) with long short-term memory (LSTM), to incorporate the time-series embedded in electronic health records (EHRs) and provide a more accurate estimate of ICU outcomes [
36,
37].
The aim of the present study was to develop predictive models for the LOS of patients admitted to the ICU based on their initial health status. We use the publicly available Medical Information Mart for Intensive Care (MIMIC) database and only consider typical health data routinely collected on the first day of ICU admission, including demographic and administrative data as well as vital signs and laboratory measurements. We perform a binary classification to identify patients at risk for a long LOS and estimate the probability that the patient will have a short or long ICU stay. The dichotomization of LOS into short and long is based on the third quartile of the entire dataset. The unexpectedly long LOS places a significant burden on ICU performance and is associated with poor outcomes, especially in patients with chronic diseases such as diabetes [
32]. We also perform regression modeling to estimate the actual LOS in the ICU in a more practical framework. In this approach, only patient data whose LOS were predicted to be short in the initial classification are considered. Structural indicators such as the adequacy of equipment and qualifications of medical personnel are beyond the scope of this study.
The remainder of this paper is organized as follows: First, in the methods section, we introduce the dataset used in this study and then describe the data preparation, models, and evaluation metrics. Next, we present the classification and regression results and discuss the key points and challenges in the models. Finally, we summarize the main findings of the study and outline avenues for future work.
2. Methods
Here, we describe the dataset, algorithms, and experimental setup designed to predict LOS in the ICU using classification and regression models. The publicly available MIMIC dataset is utilized for the experiments by defining a cohort with specific features for modeling. Data from the first 24 h of ICU admission are included, with features of interest grouped into four categories: demographics, administrative data, vital signs, and laboratory measurements. Data cleaning and preparation are performed prior to modeling, and the model performance is finally evaluated.
2.1. MIMIC-IV Database
In this study, we use the MIMIC-IV version 2.1 database, which includes patients admitted to the BETH Israel Deaconess Medical Center during the period 2008–2019 [
38,
39]. The data contain multiple dimensions, from administrative data to laboratory results and diagnoses. Each patient in MIMIC-IV is assigned a unique identifier upon admission to the hospital. After (hospital) admission, the patient may be transferred to different departments, such as the emergency department or the ambulatory surgery unit. The patient may eventually be transferred to the ICU, with an ICU identifier, until being transferred to another department or discharged from the ICU completely. In MIMIC-IV, only 17% of the patients who visited the hospital stayed in the ICU, comprising 73,141 ICU stays for 50,934 patients.
2.2. Feature Selection
The experiments involve the selection of features from the MIMIC-IV dataset that are typically available in each ICU admission.
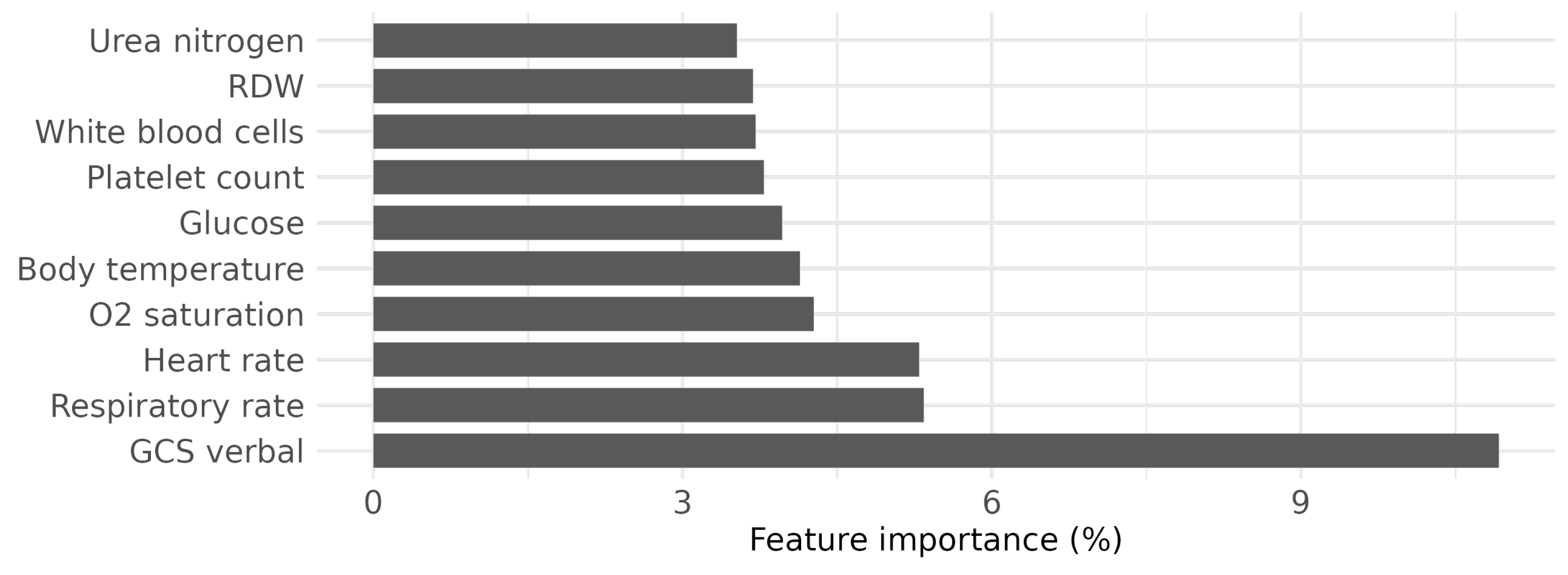
Table 1 summarizes all the features considered in the experiments, categorized into demographics, administrative, vital signs, and laboratory parameters. Demographic data include age and gender, neither of which are likely to change during hospitalization. Administrative data provide the LOS necessary for prediction as a ground truth label for each ICU stay. These data also comprise diagnoses, first care unit, admission type, and admission location, which can be viewed as structural representations of patient status specific to each hospital admission. Vital signs and laboratory parameters were measured several times during each ICU stay. We collected measurements within the first 24 h of ICU admission with the goal of developing a practical approach to classify (predict) ICU stays early after admission, while retaining data necessary for prediction. In addition, we only considered vital signs (laboratory parameters) with a completeness greater than 99% (95%) of all ICU stays, which means that, for instance, blood pressure is no longer included due to its high missing rate in the MIMIC-IV data. This ensures that fewer data are excluded due to missing values, as shown in
Figure 1 for vital signs (A) and laboratory parameters (B). However, despite a high rate of missing values, the body temperature is still included here as an important vital sign [
40].
As a result, the vital signs include heart rate, O
saturation pulse oxymetry, respiratory rate, body temperature, Glasgow Coma Scale (GCS) ocular response (eye), oral response (verbal), and motor response (motor). The selected laboratory parameters also include the anion gap, bicarbonate, chloride, creatinine, glucose, sodium, magnesium, potassium, phosphate, urea nitrogen, hematocrit, hemoglobin, mean corpuscular hemoglobin (MCH), mean corpuscular hemoglobin concentration (MCHC), mean corpuscular volume (MCV), red cell distribution width (RDW), red blood cells, white blood cells, and platelet count. All patients with at least one ICU visit are included in the cohort. Among ICU patients, we only select adults older than 18 years. In addition, we exclude patients with an LOS greater than 21 days to avoid extremely long stays, and less than one day since we consider data collected in the first 24 h for modeling. We also exclude patients who died during their stay in the ICU or who returned to the ICU within 48 h after being discharged from the ICU. To ensure the completeness of the selected data, we only consider ICU stays that have all the features required for the analysis, i.e., complete data. We finally specify a feasible range for each feature and exclude the extreme outliers outside this range to avoid, for instance, invalid negative values for heart rate. The flowchart in
Figure 2 summarizes the sequential steps for selecting data that meet these conditions, with the size of the dataset indicated at each step.
2.3. Feature Engineering
First, we consider the diagnoses in the MIMIC-IV dataset that are coded according to the International Statistical Classification of Diseases and Related Health Problems (ICD) [
41]. Approximately 55% of diagnoses are coded in ICD-9 and approximately 45% are coded in ICD-10. In order to capture diagnoses as a feature, we need to convert the ICD codes into a single version. For this purpose, we used the R package ‘touch’ (tools of utilization and cost in healthcare), which maps all ICD-9 codes to version 10 in four different cases: conversion of an ICD-9 code to (1) an ICD-10 code; (2) multiple ICD-10 codes; (3) a combination of ICD-10 codes; and (4) a non-ICD-10 code [
42]. The first and last cases give unambiguous results, covering 73.89% and 2.00% of all hospital admissions with diagnoses coded in ICD-9, respectively, while the second and third cases (with 23.26% and only 0.67% coverage) require further processing. For example, in case two, ICD-9 = 5715 is converted into ICD-10 K740, K7460, and K7469, while case three maps the ICD-9 = 8603 to S271XXA+S21309A. In the latter case, we split the resulting combination of ICD-10 codes into multiple ones, similarly to in the second case. We then reduced the number of characters in the ICD-10 codes to maintain the same character length and searched for the least common factor by keeping the last letters. Finally, we verify that all ICD-10 codes are identical and replace the ICD-9 code with the truncated ICD code. If there is no match to the ICD-10 code, the ICD code is set to non-existent. The technical details of the conversion of the ICD codes are presented in the (
Supplementary Materials). Once the ICD-9 to ICD-10 mapping is complete, we group the diagnoses into 22 chapters according to the categories specified by the WHO (
https://icd.who.int/browse10/2019/en, accessed on 3 June 2023), and represent each ICD code by its corresponding group.
Vital signs and laboratory parameters were measured several times during each ICU stay. We represent these temporal parameters by their mean value over all measurements within the first 24 h of the ICU stay. In cases where no measurements were taken during this period, the parameters are declared as not available (NA). This single representation (mean) serves to reduce the complexity of the model, although it can also affect the model performance due to the lack of detailed information. Furthermore, we dichotomized ICU stays into short and long, defining a threshold of 4 days for the classification problem. Here, we classified LOS at the third quartile into short and long, as 75.2% of the data comprised LOSs of less than 4 days. For the regression, we left the LOS as a floating point number, rounding it to one decimal place.
2.4. Data Cleaning and Missing Data Handling
Data cleaning involves a more detailed examination of the data, with categorical and numerical variables treated separately. Missing and invalid values of categorical variables were determined and then set to non-existent. For numerical variables, we set specific ranges for each measurement, which are listed in
Table 2 for vital signs. The ranges for the features were obtained from the literature or from a data-driven approach, taking into account the ranges present in the data.
For example, the maximum heart rate of 220 bpm (beats per minute) was taken as a reference [
43], and 5 bpm added to be on the safe side. Regarding the minimum heart rate, we did not observe any patients with a heart rate lower than 25 bpm, so we took this as the lower limit. For the respiratory rate, we set the lower (upper) limit inspired by literature estimates as 8 (20) breaths per minute (brpm) for a lower (upper) respiratory rate bound [
44]. We then reduced the lower limit by one unit and doubled the upper one. A patient can have an oxygen saturation of around 55% under certain conditions [
45]; therefore, the lower limit for oxygen saturation has been set to 50%, reduced by 5% to leave more room for data. There are also few values in the saturation data above 100%, most likely due to specific treatments [
46], so the upper limit was set based on the data with an (arbitrary) increase to 20%. We set the lower and upper temperature limits to 30 °C (86 °F) and 45 °C (113 °F). This is based on the observed body temperature being in the range of 33–39 °C, extended by the difference from the mean of 36.5 °C [
47]. We did not observe any extreme outliers in the laboratory measurements and did not exclude any values in this respect.
2.5. Model
Four different classification and regression models for predicting LOS in the ICU are utilized and their performances are compared. The first is the common logistic/linear regression model (for classification/regression problems), which incorporates a linear combination of all features in modeling. Support vector machine (SVM) is the second, which determines the optimal hyperplane that separates different classes of data in an N-dimensional space, where N is the number of features used. The model computes the optimal hyperplane using a crucial kernel function, here the radial basis function, which performs well in classification problems even in the presence of nonlinear dependencies between features [
29,
48]. The next is random forest, an extension of decision trees where an ensemble of many possible trees is generated and selected using an optimization procedure. Random forest is commonly used for LOS prediction and typically shows quite a good performance [
14]. The last one is the XGBoost, which is a tree-based method with an integrated end-to-end gradient boosting optimization that enables trees to optimize themselves [
49]. These models are also widely used in LOS prediction with highly accurate results [
50,
51].
2.6. Evaluation
To evaluate the models, we randomly split the selected dataset into training and test datasets at a ratio of 80 to 20 percent. Different models are trained on the training dataset, and then their performance on the test dataset is evaluated using statistical metrics. Classifier performance is evaluated using common metrics such as accuracy, balanced accuracy, F1-score, and receiver operating characteristic—area under the curve (ROC AUC)—which are widely used to evaluate any binary classification. They are calculated from the confusion matrix with actual and predicted dimensions. The matrix elements denote true positives (
) and true negatives (
) as correctly predicted long and short LOS for each ICU stay. Incorrectly predicted long and short LOS are indicated by false positives (
) and false negatives (
), respectively. The accuracy is therefore directly calculated from the confusion matrix as
, and the F1-score as
. The balanced accuracy is the (arithmetic) mean of the true positive rate (TPR) and the true negative rate (TNR) equal to
, where TPR and TNR, also called sensitivity and specificity, are expressed as
and
, respectively. Similarly, the false positive rate (FPR) and the false negative rate (FNR) can be defined as
and
, as well as the predictive positive value (PPV) and predictive negative value (PNV) by
and
. AUC provides a single value metric as the area under the ROC, which displays the TPR versus the FPR for varying the threshold in the classification. As a more meaningful single measure of the confusion matrix, we also compute the Matthew correlation coefficient (MCC):
which has the major advantage of being independent of the favorable class (i.e., positive or negative) [
52].
Regarding the regression problem, we computed several metrics for each experiment, namely the root mean square error (RMSE), the mean absolute error (MAE), the mean absolute percentage error (MAPE), and the R
. The RMSE, which is commonly measured for regression, is defined by:
where
n is the size of the (test) dataset, and
and
are the predicted and actual LOS of the model [
53]. The MAE measures the absolute error of the regression prediction as
with more applicability to normally distributed errors [
54]. The MAPE is the next metric commonly used in the evaluation of regression models, with a more intuitive interpretation in terms of the relative error given by [
55]:
and the last is R
, also called the coefficient of determination, a common statistical measure of the linear correlation between variables, which is calculated by [
56]:
where
is the average over all predicted LOS of the model [
57].
2.7. Setup
All machines employed in this study were running the Ubuntu operating system. The MIMIC-IV dataset is hosted in a PostgreSQL database, and data retrieval was performed using SQL queries. Data preparation and processing, model training, evaluation, and visualization were conducted using R. For visualization, the ggplot2 package was used [
58], and tidyR and dplyR were the data-processing/handling packages [
59,
60].
5. Conclusions
Predicting hospital length of stay (LOS) is important for clinical resources and cost management; however, it is a challenging problem because of the multiple factors involved. In this study, we performed the predictive modeling of LOS for patients admitted to the ICU of the MIMIC-IV dataset. We prepared and processed the data with typical features, including demographic and administrative data as well as vital signs and laboratory measurements collected on the first day of the ICU stay. We also considered data with LOSs of up to three weeks to avoid extremely long stays and divided them into short and long stays in the upper quartile. We then performed binary classification using different models: logistic regression, SVM, random forest, and XGBoost. The models were evaluated on several metrics, averaged over 10 different experiments using a repeated random train/test split for each model. The results demonstrate that the random forest is superior to the other algorithms, while the accuracy is moderate, as many actual long LOSs are predicted to be short.
We also performed regression models to predict the actual LOS in the ICU. The results show the poor performance of the models when the entire dataset is considered with a maximum LOS of 21 days. This is mainly due to the fact that the models only incorporated data collected on the first day of ICU admission and are therefore unlikely to correctly predict a long LOS. To conclude the study, we proposed a practical approach for a realistic situation where the actual LOS on the first day of admission is not yet known. For this purpose, we first classified LOS as short or long stay, and then predicted the actual LOS only for data with a short predicted LOS. As a result, this approach significantly improved the performance of the models, with SVM and random forest outperforming other models. To predict an LOS longer than four days, we should shift the modeling window forward and consider, for example, data from the first four days or at least the fourth day.
Future work will focus on improving the classification performance by exploiting the embedded information in diagnosis data. Profiling the diagnosis codes and the consideration of interrelated diseases will have an impact on performance. Moreover, a deep learning model that incorporates detailed information contained in temporal features can greatly improve the performance of the model and requires further investigation.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}