
A Structured Recognition Method for Invoices Based on StrucTexT Model

Abstract
:1. Introduction
2. Related Models and Optimization
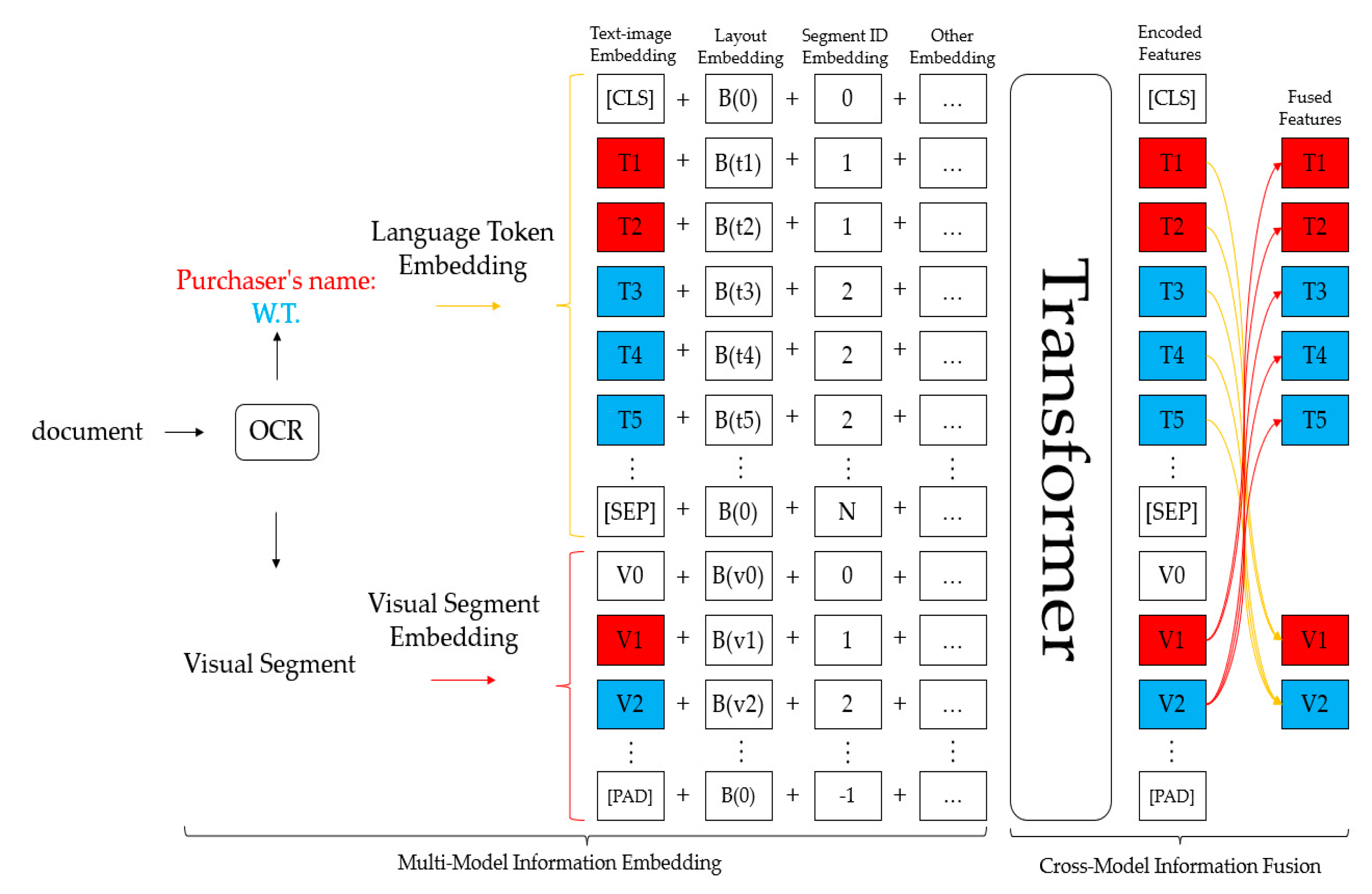
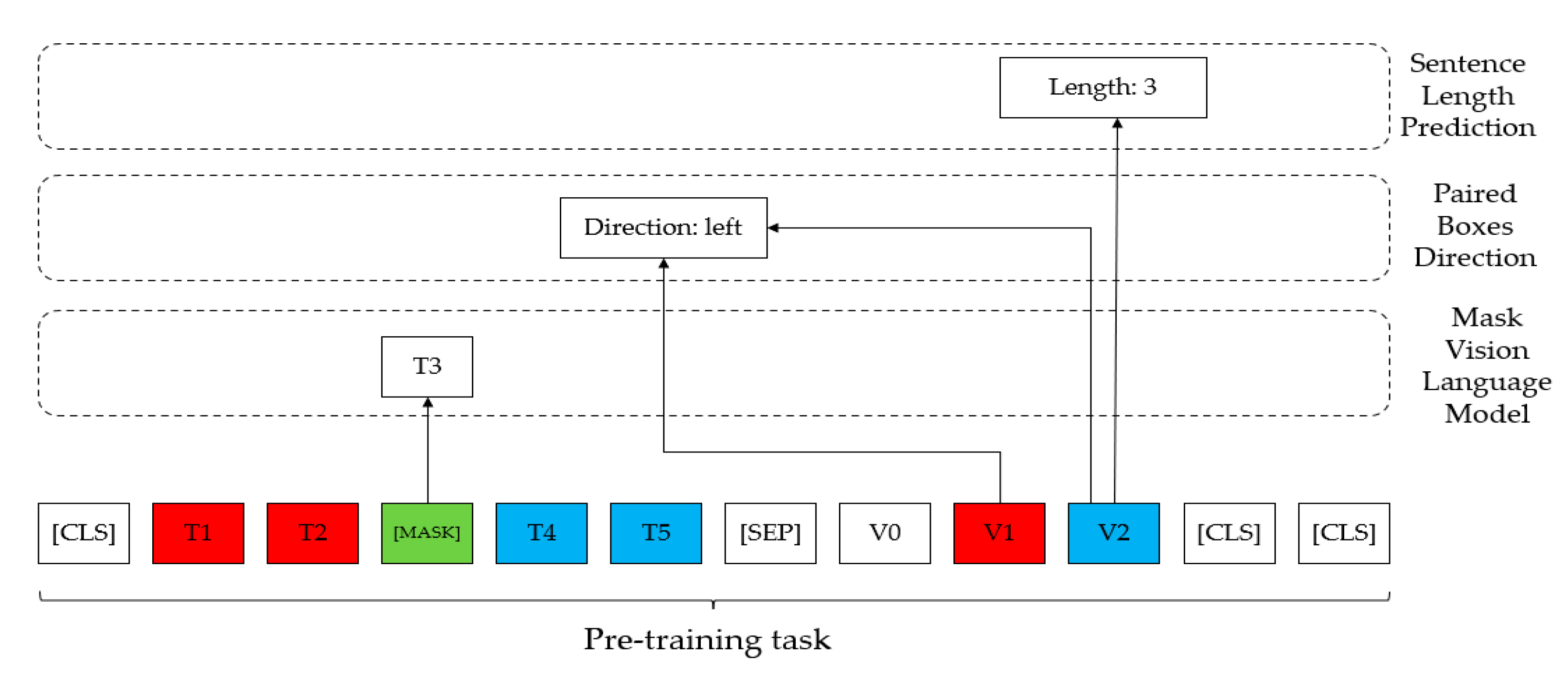
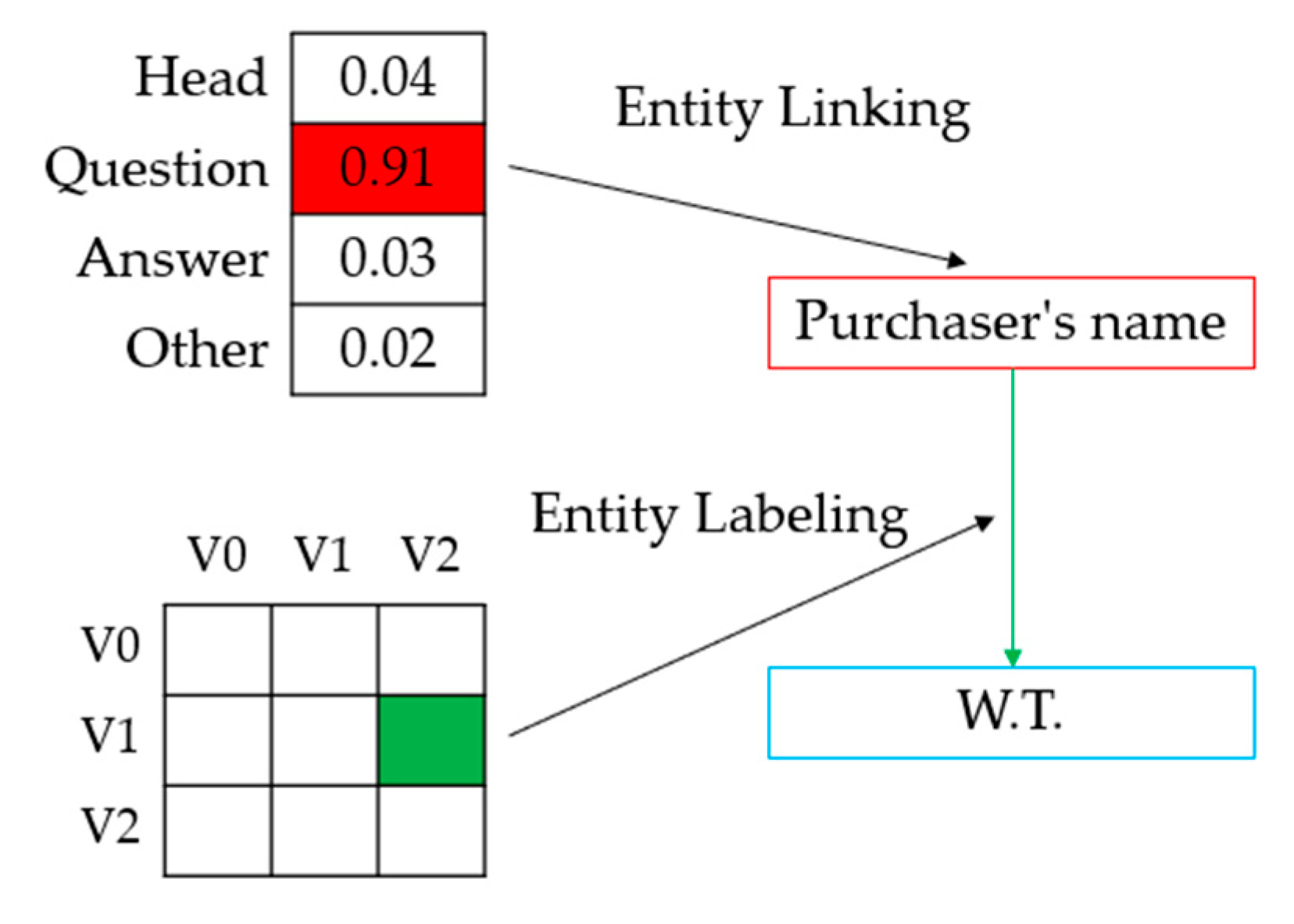
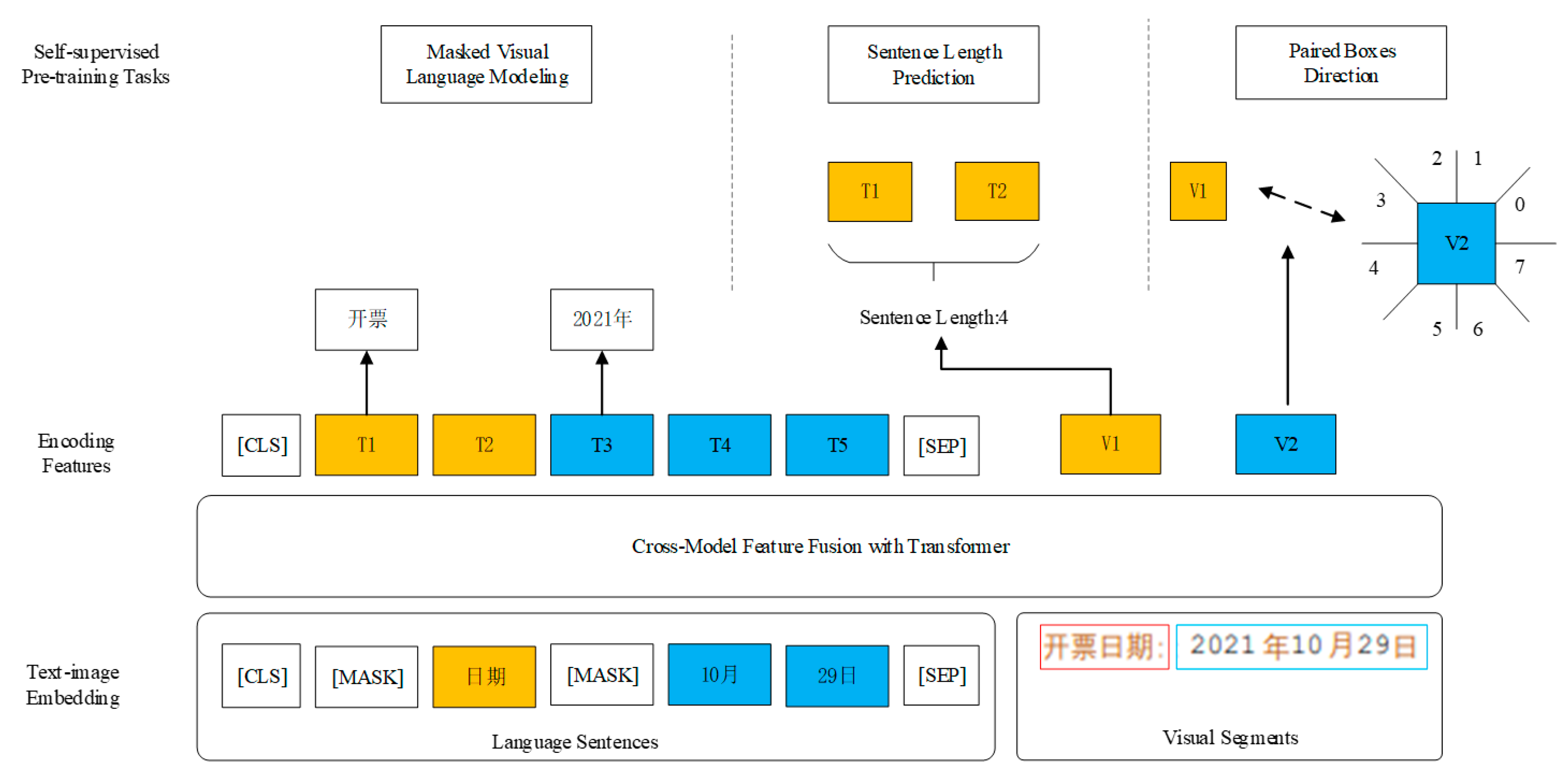
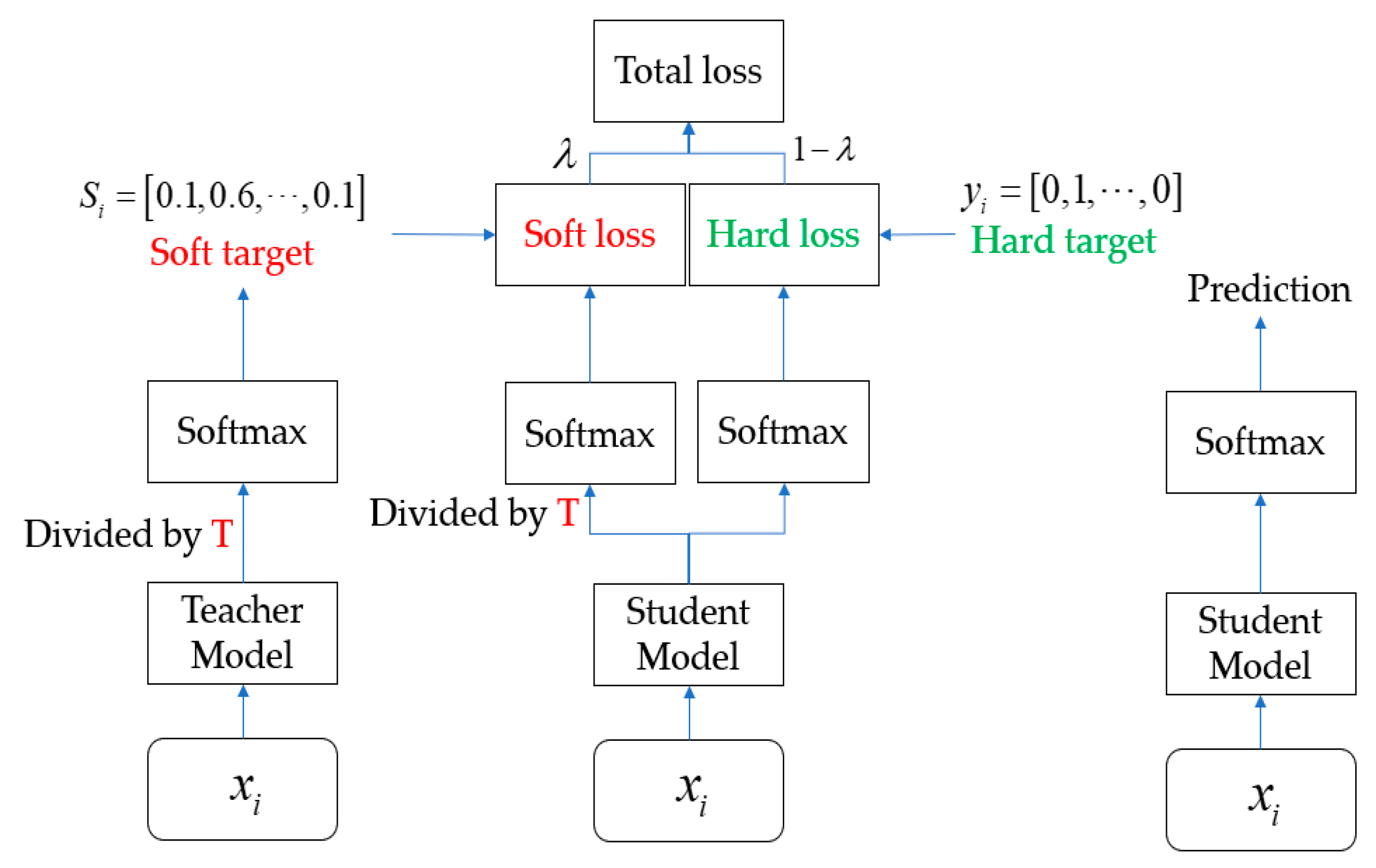
2.1. StrucTexT
2.2. Optimization
- (1)
- The CTC branch of the final output (head_out) of student and teacher, with a CTC loss of gt, weighted by 1. Here, because both sub-networks need to update their parameters, both have to calculate the loss using g.
- (2)
- The SAR branch of the student’s and teacher’s final output (head_out), with a SAR loss of gt, weighted by 1. Here, both need to calculate the loss using g, because both sub-networks need to update their parameters.
- (3)
- The DML loss between the CTC branches of the student’s and teacher’s final output (head_out), with a weight of 1.
- (4)
- The DML loss between the student and the SAR branch of the teacher’s final output (head_out), with a weight of 0.5.
- (5)
- The l2 loss between the student’s and teacher’s backbone network output (backbone_out) has a weight of 1.
3. Experiment and Analysis
3.1. Dataset
3.2. Experimental Environment and Parameter Settings
3.3. Comparison of Experimental Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tang, S.L.; Cheng, Z.Z.; Niu, Y.; Lei, M. A deep learning model for recognizing structured texts in images. J. Hangzhou Dianzi Univ. Nat. Sci. 2020, 2, 45–51. [Google Scholar]
- Tang, J.; Tang, C. Structural information recognition of VAT invoice. Comput. Syst. Appl. 2021, 12, 317–325. [Google Scholar]
- Yin, Z.J.; Jiang, B.W.; Ye, Y.Y. Research on invoice recognition based on improved LeNet-5 convolutional neural Network. Equip. Manuf. Technol. 2021, 5, 148–150+163. [Google Scholar]
- Sun, R.B.; Qian, K.; Xu, W.M.; Lu, H. Adaptive recognition of complex invoices based on Tesseract-OCR. J. Nanjing Univ. Inf. Sci. Technol. Nat. Sci. Ed. 2021, 3, 349–354. [Google Scholar]
- Li, Y.L.; Qian, Y.X.; Yu, Y.C.; Qin, X.M.; Zhang, C.Q.; Liu, Y.; Yao, K.; Han, J.Y.; Liu, J.T.; Ding, E.R. StrucTexT: Structured text understanding with multi-model transformers. In Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 21–24 October 2019; pp. 1912–1920. [Google Scholar]
- Choi, Y.; Lee, K.J. Performance Analysis of Korean Morphological Analyzer based on Transformer and BERT. J. KIISE 2020, 8, 730–741. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Sekar, A.; Perumal, V. Automatic road crack detection and classification using multi-tasking faster RCNN. J. Intell. Fuzzy Syst. 2021, 6, 6615–6628. [Google Scholar] [CrossRef]
- Huang, S.Q.; Bai, R.L.; Qin, G.E. Method of convolutional neural network model pruning based on gray correlation analysis. Laser Optoelectron. Prog. 2020, 4, 135–141. [Google Scholar]
- Zhang, F.; Huang, Y.; Fang, Z.Z.; Guo, W. Lost-minimum post-training parameter quantization method for convolutional neural network. J. Commun. 2022, 4, 114–122. [Google Scholar]
- Li, Y.; Wei, J.G.; Jiang, H.R. A review of neural network knowledge distillation methods. China CIO News 2022, 10, 128–131+136. [Google Scholar]
- Chu, Y.C.; Gong, H.; Wang, X.F.; Liu, P.S. Study on knowledge distillation of target detection algorithm based on YOLOv4. Comput. Sci. 2022, S1, 337–344. [Google Scholar]
- Xu, Y.; Li, M.; Cui, L.; Huang, S.; Wei, F.; Zhou, M. LayoutLM: Pre-training of Text and Layout for Document Image Understanding. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Virtual Event, CA, USA, 23–27 August 2020; pp. 1192–1200. [Google Scholar]
- Xu, Y.; Xu, Y.H.; Lv, T.C.; Cui, L.; Wei, F.R.; Wang, G.X.; Lu, Y.J.; Florencio, D.; Zhang, C.; Che, W.X.; et al. LayoutLMv2: Multi-modal Pre-training for Visually-rich Document Understanding. In Proceedings of the Association of Computational Linguistics, Online Event, 1–6 August 2021. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Precision | Recall | F1 | Parameters | Time |
|---|---|---|---|---|---|
| LayoutLM_BASE | 0.944 | 0.944 | 0.944 | 113 M | 4.5 s |
| LayoutLM_LARGE | 0.952 | 0.952 | 0.952 | 343 M | 2.7 s |
| LayoutLMv2_BASE | 0.963 | 0.963 | 0.963 | 200 M | 3.6 s |
| LayoutLMv2_LARGE | 0.966 | 0.966 | 0.966 | 426 M | 2.1 s |
| StrucTexT | 0.967 | 0.968 | 0.969 | 107 M | 6.7 s |
| YOLOv4 [2] | 0.954 | 0.954 | 0.954 | 145 M | 4.6 s |
| LeNet-5 [3] | 0.941 | 0.942 | 0.941 | 92 M | 5.6 s |
| Tesseract-OCR [4] | 0.957 | 0.958 | 0.957 | 101 M | 7.3 s |
| StrucTexT_slim | 0.947 | 0.948 | 0.947 | 80 M | 4.1 s |
| Model | Precision | Recall | F1 | Parameters | Time |
|---|---|---|---|---|---|
| LayoutLM_BASE | 0.760 | 0.816 | 0.787 | 113 M | 4.1 s |
| LayoutLM_LARGE | 0.760 | 0.822 | 0.790 | 343 M | 2.9 s |
| LayoutLMv2_BASE | 0.803 | 0.854 | 0.828 | 200 M | 3.7 s |
| LayoutLMv2_LARGE | 0.832 | 0.852 | 0.842 | 426 M | 2.0 s |
| StrucTexT | 0.857 | 0.810 | 0.831 | 107 M | 6.5 s |
| YOLOv4 [2] | 0.837 | 0.852 | 0.841 | 145 M | 4.8 s |
| LeNet-5 [3] | 0.821 | 0.819 | 0.825 | 92 M | 6.1 s |
| Tesseract-OCR [4] | 0.836 | 0.841 | 0.837 | 101 M | 7.5 s |
| StrucTexT_slim | 0.835 | 0.796 | 0.816 | 80 M | 3.9 s |
| Keyword | Precision |
|---|---|
| Pre-tax amount | 1 |
| Tax rate | 1 |
| Tax amount | 1 |
| Name (seller) | 0.98 |
| Taxpayer identification number (seller) | 0.99 |
| Address telephone (seller) | 0.94 |
| Bank and account number (seller) | 0.93 |
| Name (purchaser) | 0.98 |
| Taxpayer identification number (purchaser) | 0.99 |
| Address telephone (purchaser) | 0.94 |
| Bank and account number (purchaser) | 0.93 |
| Invoice code | 0.99 |
| Invoice number | 0.99 |
| Date | 1 |
| Passenger name | 0.95 |
| Departure place | 0.99 |
| Destination | 0.99 |
| Flight number | 0.98 |
| E-ticket number | 0.97 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Tian, W.; Li, C.; Li, Y.; Shi, H. A Structured Recognition Method for Invoices Based on StrucTexT Model. Appl. Sci. 2023, 13, 6946. https://doi.org/10.3390/app13126946
Li Z, Tian W, Li C, Li Y, Shi H. A Structured Recognition Method for Invoices Based on StrucTexT Model. Applied Sciences. 2023; 13(12):6946. https://doi.org/10.3390/app13126946
Chicago/Turabian StyleLi, Zhijie, Wencan Tian, Changhua Li, Yunpeng Li, and Haoqi Shi. 2023. "A Structured Recognition Method for Invoices Based on StrucTexT Model" Applied Sciences 13, no. 12: 6946. https://doi.org/10.3390/app13126946
APA StyleLi, Z., Tian, W., Li, C., Li, Y., & Shi, H. (2023). A Structured Recognition Method for Invoices Based on StrucTexT Model. Applied Sciences, 13(12), 6946. https://doi.org/10.3390/app13126946