1. Introduction
Hyperspectral imaging technology combines imaging technology with spectral technology and has achieved wide application in recent years. With the advancement of hyperspectral imaging technology, hyperspectral imaging systems can simultaneously acquire abundant spectral information and two-dimensional spatial information of a feature and then form a hyperspectral image (HSI) [
1,
2,
3]. Therefore, hyperspectral imaging technology has become a hotspot for research due to its rich spectral and spatial information. An HSI provides from tens to hundreds of continuous spectral bands [
4]. The abundance of spectral information greatly enhances the ability to distinguish objects. Therefore, an HSI is commonly used in disaster monitoring, vegetation classification, fine agriculture, and medical diagnosis due to its extremely high spectral resolution [
1,
2,
5].
As the focus of the field of hyperspectral image analysis, the HSI classification task has always received significant attention from scholars. Hyperspectral image classification aims to classify each pixel point in the image [
6]. In the early days, most HSI classification methods mainly relied on some traditional machine learning algorithms [
7] which were mainly divided into two processes: traditional manual feature engineering and classifier classification [
8]. Feature engineering aims to process data based on knowledge so that the processed features can be better used in subsequent classification algorithms. Commonly used feature engineering methods include principal component analysis (PCA), independent component analysis (ICA), and other dimensionality reduction methods.
Typical classification algorithms include the support vector machine (SVM) [
9], random forest (RF) [
10], and k-nearest neighbor (KNN) [
11], etc. [
12,
13]. The above machine learning approaches only focus on the spectral information of an HSI. It is inaccurate to use the spectral information only for the classification task, thus limiting the improvement in the classification accuracy and the gradual elimination of spectral information.
As a result of the triumph of deep learning in areas such as computer vision, many approaches based on deep learning have also been adopted for hyperspectral image classification [
14]. Among the deep learning methods, convolutional neural networks (CNNs) [
15] have become a popular method for hyperspectral image classification due to their excellent performance. Deep-learning-based methods represented by CNNs have replaced traditional machine-learning-based HSI classification methods and have become a research hotspot [
16].
Deep learning methods of 1D-CNN [
17] and 2D-CNN were first applied to hyperspectral image classification, and the performance surpassed machine learning methods. However, the above methods suffer from the underutilization of spatial and spectral information. Therefore, the 3D-CNN model [
16] was proposed, which can extract spatial–spectral features simultaneously and therefore obtain better classification results, but the model has a large computational burden. To extract richer features, some scholars have proposed a hybrid spectral CNN (HybridSN) [
18] which combines 3D-CNN and 2D-CNN to exploit the spatial–spectral features of an HSI with less computational burden than 3D-CNN.
With the purpose of finding correlations between data, highlighting important features, and ignoring irrelevant noise information, an attention mechanism has been proposed. Li et al. proposed a two-branch double attention network (DBDA) [
19] which contained two branches to extract spatial and spectral features and added an attention mechanism to obtain better classification results. In order to capture richer features, deeper network layers are needed, but the deeper network layers will lead to computational complexity and make the model training difficult. Zhong et al. introduced a residual structure based on the 3D-CNN model [
20], constructed a spectral residual module and a spatial residual module, and achieved more satisfactory classification results.
Although the classification results achieved by CNN-based classification methods have been good, there are still some limitations. First, the CNN is designed for Euclidean data, and the traditional CNN model can only convolve regular rectangular regions, so it is difficult to obtain complex topological information. Second, CNNs cannot capture and utilize the relationship between different pixels or regions in hyperspectral images; they can only extract detailed features in the local fine region, but the structure features and dependency relationship between the nodes may provide useful information for the classification process [
21,
22].
In order to obtain the relationship between objects, graph convolutional networks (GCNs) have been developed rapidly in recent years [
23]. GCNs are designed to process graph-structured data. CNNs are used for processing Euclidean data such as images, which are a regular matrix. Therefore, no matter where the convolution kernel of a CNN is located in the image, the consistency of the result of the operation is guaranteed (translational invariance). However, the graph-structured data are non-Euclidean data, and the graph structure is irregular, so it is impossible to apply the CNN on graph data. The graph convolution is designed to resolve this situation. The most important innovation of the GCN is to overcome the inapplicability of translation invariance on non-Euclidean data, so it can be applied to extract the features of the graph structure.
Kipf et al. proposed the GCN model [
24] which is able to operate on non-Euclidean data and extract the structural relationship between different nodes [
21]. Some scholars have attempted to apply the GCN to hyperspectral classification tasks [
25], and various studies have shown that the classification results are not only affected by spectral information but are also related to the spatial structure information of the pixels [
22,
26]. By treating each pixel or superpixel in the HSI as a graph node, the hyperspectral image can be converted into graph-structured data, and then the GCN can be used to obtain the spatial structure information in the image and provide a more effective information for the classification. Hong et al. [
22] proposed the MiniGCN method and constructed an end-to-end fusion network which was able to sample images in small batches, classify images as subgraphs, and achieve good classification results. Wan et al. proposed MDGCN [
27], which is different from the commonly used GCN. Working on a fixed graph model, MDGCN is able to make the graph structure update dynamically so that the two steps benefit each other. In addition, we cannot consider each pixel of an HSI as a graph node due to the limitation of computational complexity, so hyperspectral images are usually preprocessed as superpixels. The superpixel segmentation technique is applied to the construction of the graph structure, which reduces the complexity of model training significantly. However, the superpixel segmentation technique leads to another problem. Superpixel segmentation often leads to smooth edges of the classification map and a lack of local detailed information of the features. This problem restricts the improvement of the classification performance and has an impact on the analysis of the results.
To obtain the relational features of an HSI and to solve the problem of missing details due to superpixel segmentation, inspired by [
28], we designed a feature fusion of the CNN and GCN (FCGN). The algorithm consisted of two branches: the GCN branch and CNN branch. We applied the superpixel segmentation technique in the GCN branch. The superpixel segmentation technique can aggregate similar pixels into a superpixel. Then, we treated these superpixels as graph nodes. Graph convolution processes the data by aggregating the features of each node as well as its neighboring nodes. This approach can capture the structure features and dependency relationship between the nodes and thus better represent the features of the nodes. Compared with the CNN branch, the GCN branch based on superpixel segmentation can acquire structure information over a longer distance, while the CNN branch can obtain the pixel-level features of the HSI and perform a fine classification of local regions. Finally, the different features acquired by the two branches were fused to obtain richer image features by complementing their strengths. In addition, the attention mechanism and depth-wise separable convolution algorithm [
29] were applied to further optimize the classification results and network parameters.
2. Methodology
This section presents the proposed FCGN for HSI classification, which includes the overall structure of the FCGN and the function of each module in the network.
2.1. General Framework
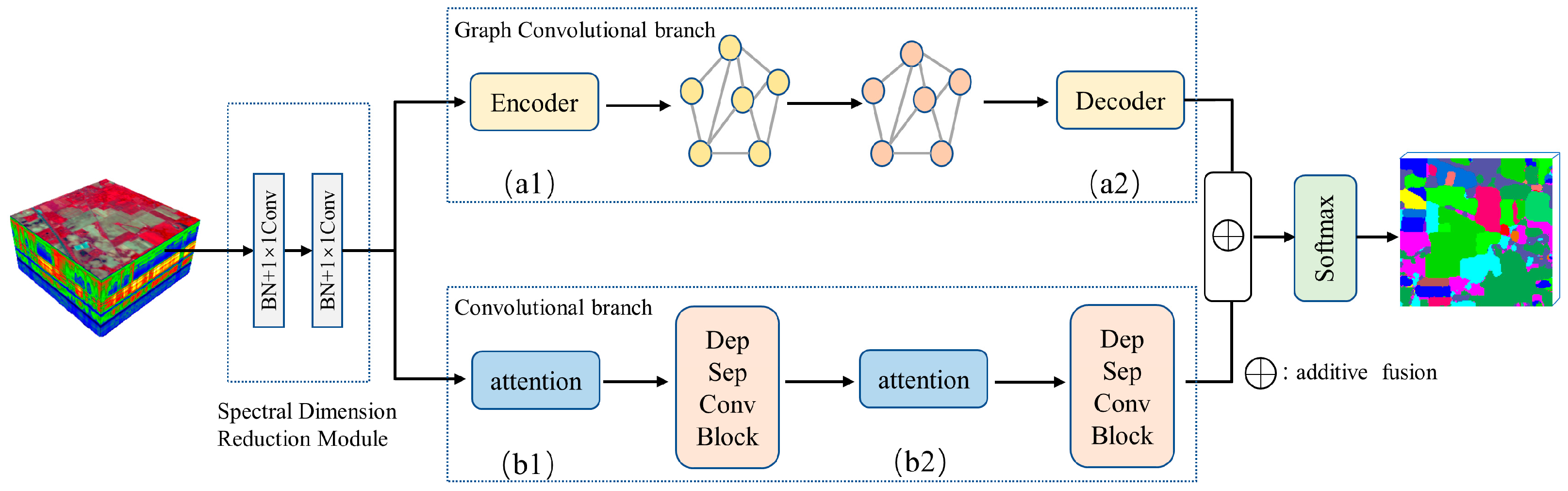
To solve the problem of missing local details in classification maps due to superpixel segmentation, we proposed a feature fusion of the CNN and GCN, as shown in
Figure 1. The proposed network framework contained a spectral dimension reduction module (see
Section 2.2 for details), a graph convolutional branch (see
Section 2.3 for details), a convolutional branch (see
Section 2.4 for details), a feature fusion module, and a Softmax classifier. It should be noted that the features extracted from convolutional neural networks were different from those of graph convolutional networks. Feature fusion methods can utilize different features of an image to complement each other’s strengths, thus obtaining more robust and accurate results. Because of that, it is possible to obtain better classification results than a single branch by fusing features from two branches.
The original HSI was handled by the spectral dimensionality reduction module first, which was used for spectral information transformation and feature dimensionality reduction. Then, we used convolutional neural networks to extract the detailed features in a local fine region. Considering the problem that the CNN-based method may induce overfitting with too many parameters and an insufficient number of training samples, we used a depth-wise separable convolution to reduce the parameters and enhance the robustness. To further improve the model, we added attention modules to the convolution branch. We used the SE attention module to optimize the proposed network [
30]. The SE module can obtain the weight matrix of different channels. Then, the weight values of each channel calculated by the SE module were multiplied with the two-dimensional matrix of the corresponding channel of the original feature map. We used graph convolutional networks to extract the superpixel-level contextual features. In this branch, we applied a graph encoder and a graph decoder to implement the transformation of pixel features and superpixel-level features (see
Section 2.5 for details). Next, the different features acquired by the two branches were fused to obtain richer image features by complementing their strengths. Finally, after the processing of the Softmax classifier, we obtained the label of each pixel. The role of Softmax is to assign a probability value to each output classification, indicating the probability of belonging to each class.
2.2. Spectral Dimension Reduction Module
There is a significant amount of redundant information in the original hyperspectral image. Using dimension reduction modules, it is possible to significantly reduce the computational cost without significant performance loss. The 1 × 1 convolutional layer has the ability to remove useless spectral information and increase nonlinear characteristics. Moreover, it is usually used as a dimension reduction module to remove computational cost, as shown in
Figure 2. In the FCGN network, hyperspectral images are first processed using two 1 × 1 convolutional blocks. Specifically, each 1 × 1 convolutional block contains a BN layer, a 1 × 1 convolution layer, and an activation function layer. The role of the BN layer is to accelerate the convergence of the network, and the activation function layer can significantly increase the network’s nonlinearity to achieve better expressiveness. The activation function in this module adopts Leaky ReLU.
We have:
where
denotes the input feature map,
denotes the batch-normalized input feature map,
denotes the output feature map,
denotes the convolution kernel of the input feature map in row x and column y,
denotes bias, and n is the number of convolution kernels.
represents the Leaky ReLU activation function.
2.3. Graph Convolution Branch
Numerous studies have shown that the classification accuracy can be effectively improved by combining the different features of images. Traditional CNN models can only convolve images in regular image regions using convolution kernels of a fixed size and weight, resulting in an inability to obtain global features and structural features of images. Therefore, it is often required to deepen the network layer to alleviate this problem. However, as the number of network layers deepens, the chance of overfitting increases subsequently, especially when processing data with a small amount of training samples such as HSIs. Such a result is unacceptable to us.
Therefore, a GCN branch based on superpixel segmentation was constructed to obtain the structural features. Different from the CNN, the GCN is a method used for the graph structure. The GCN branch can extract the structure features and dependency relationship between the nodes from images. These features are different from the neighborhood spatial features in a local fine region extracted by the CNN branch. Finally, the property of the network can be enhanced by fusing the different features extracted from the two branches. The graph structure is a non-Euclidean structure that can be defined as , where is the set of nodes and is the set of edges. and are usually encoded into a degree matrix D and node matrix A, where D records the relationship between each pixel of the hyperspectral image and A denotes the number of edges associated with each node.
Because the degree of each graph node in the graph structure is not the same, the GCN cannot directly use the same-size local graph convolution kernel for all nodes similar to the CNN. Considering that the convolution in the spatial domain is equivalent to the product in the frequency domain, researchers hope to implement the convolution operation on topological graphs with the help of the theory of graph spectra, and they have proposed the frequency domain graph convolution method [
31]. The Laplacian matrix of the graph structure is defined as
. The symmetric normalized Laplacian matrix is defined as:
The graph convolution operation can be expressed by Equation (3).
where
is the orthogonal matrix composed of the feature vectors of the Laplacian matrix L by column, and
is a diagonal matrix consisting of parameter
, representing the parameter to be learned. The above is the general form of graph convolution, but Equation (3) is computationally intensive because the complexity of the eigenvector matrix
is
. Therefore, Hammond et al. [
32] showed that this process can be obtained by fitting a Chebyshev polynomial, as in Equation (4).
where
and
are the largest eigenvalues of
.
is the vector of the Chebyshev coefficients. In order to reduce the computational effort, the literature [
33] only calculates up to K = 1.
is approximated as two; then, we have:
In addition, self-normalization is introduced:
where
,
. Finally, the graph convolution is:
2.4. SE Attention Mechanism
The attention mechanism can filter key information from the input images and enhance the accuracy of the model with a limited computational capability. Therefore, we applied the attention mechanism to the convolutional branch. For simplicity, we chose the SE attention mechanism. The purpose of the SE module is to obtain more important feature information by a weight matrix that provides different weights to different positions of the image from the perspective of the channel domain. The SE module consists of three steps. First, the compression operation performs feature compression from the spatial dimension to turn the feature of H × W × B into a 1 × 1 × B feature. Second, the excitation operation generates weights for each feature channel by introducing the w parameter. Finally, the weight outputs from the excitation block are considered as the importance of each feature channel after selection, and the weights of each channel calculated by the SE module are multiplied with the two-dimensional matrix of the corresponding channel of the original feature map to complete the rescaling of the original features in the channel dimension to highlight the important features. The SE module is shown in
Figure 3.
2.5. Superpixel Segmentation and Feature Conversion Module
The GCN can only be applied on graph-structured data, and in order to apply the GCN to hyperspectral images, the hyperspectral image needs to be constructed as a graph structure first. The simplest method is to consider each pixel of the image as each node of the graph structure, but this method leads to a huge computational cost. Therefore, it is common to first apply superpixel segmentation to the HSI.
Currently, common superpixel segmentation algorithms include SLIC [
34], QuickShift [
35], and Mean-Shift [
36]. Among them, the SLIC algorithm assigns image pixels to the nearest clustering centers to form superpixels based on the distance and color difference between pixels. This method is computationally simple and has excellent results compared with other segmentation methods.
In general, the SLIC algorithm has only one parameter: the number of superpixels K. Suppose an image with M pixel is expected to be partitioned into K superpixel blocks; then, each superpixel block contains M/K pixels. Under the assumption that the length and width of each superpixel block are uniformly distributed, the length and width of each superpixel block can be defined as S, S = sqrt (M/K).
Second, in order to avoid the seed points falling on noisy points or line edges of the image and thus affecting the segmentation results, the positions of the seed points are also adjusted by recalculating the gradient values of the pixel points in the 3 × 3 neighborhood of each seed point and setting the new seed point to the minimum gradient in that neighborhood.
Finally, the new clustering centers are calculated iteratively by clustering. The pixel points in the 2S × 2S region around the centroid of each superpixel block are traversed. After that, each pixel is divided into the superpixel blocks closest to it; thus, an iteration is completed. The coordinates of the centroid of each superpixel block are recalculated and iterated, and convergence is usually completed in 10 iterations.
Figure 4 represents the diagram of different number of superpixels in a image.
In this paper, the number of superpixel was not the same in each dataset but rather varied according to the total number of pixels in the dataset, for which the number of superpixels is specified as , where H and W are the length and width of the dataset, and is a segmentation factor to control the number of superpixels, which is 100 in this paper.
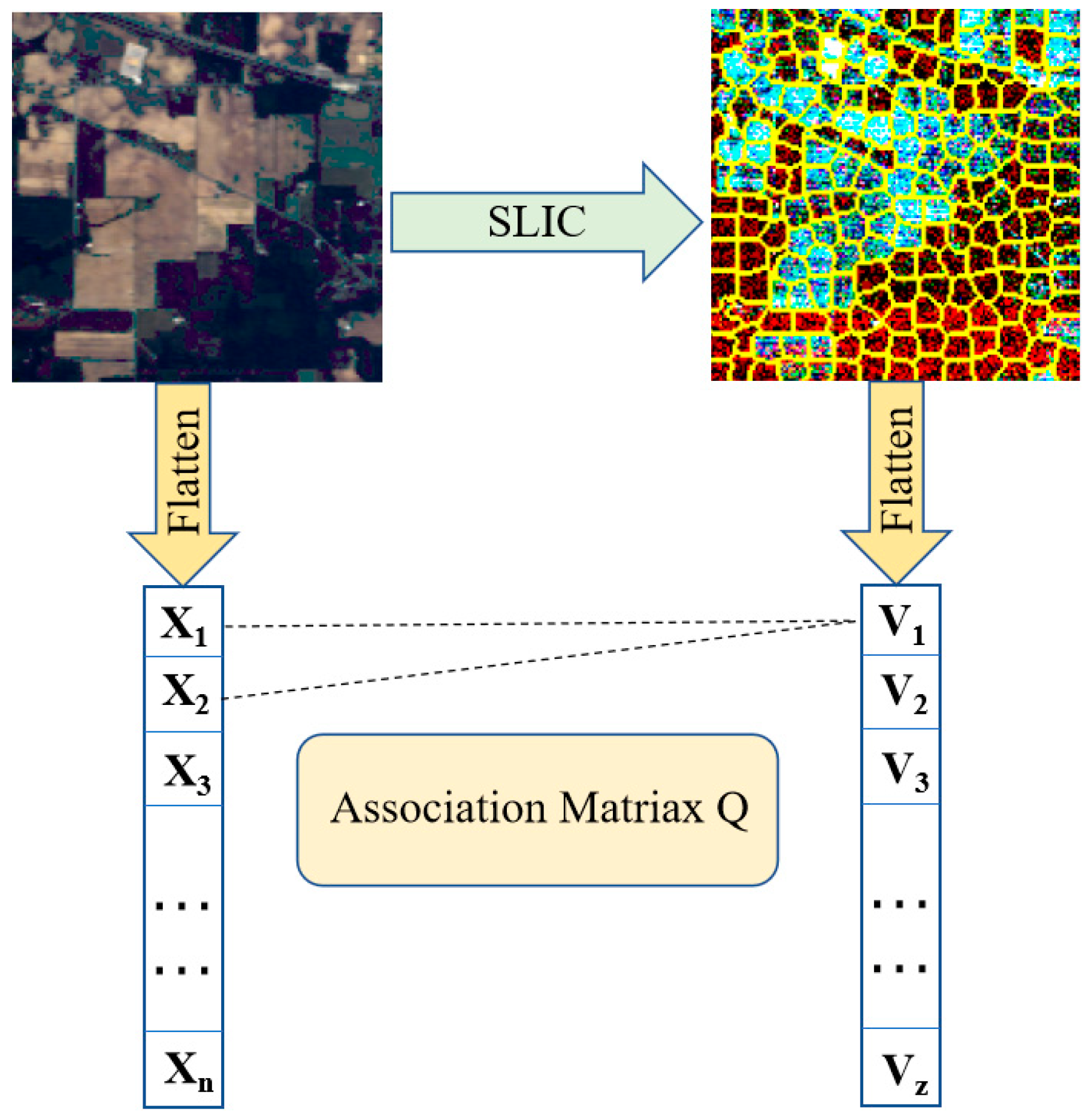
It is worth noting that since each superpixel had a different number of pixels, and because the data structures of the two branches were different, the CNN branch and the GCN branch could not be fused directly. Inspired by [
28], we applied a data transformation module that allowed the features obtained from the GCN branch to be fused with the features from the CNN branch, as shown in
Figure 5.
denotes the
i-th pixel in the flattened HSI and
denotes the average radiance of the pixels contained in the superpixels
. Let
be the association matrix between pixels and superpixels, where Z denotes the number of superpixels; then, we have:
where
,
denotes the value of
at the association matrix, and
denotes the
i-th pixel in
. Finally, the feature conversion process can be represented by:
where
denotes the normalized
by column, and
denotes restoring the spatial dimension of the flattened data.
denotes the nodes composed of superpixels and
denotes the feature converted back to Euclidean domains. In summary, features can be projected from the image space to the graph space using the graph encoder. Accordingly, the graph decoder can assign node features to pixels.
5. Conclusions
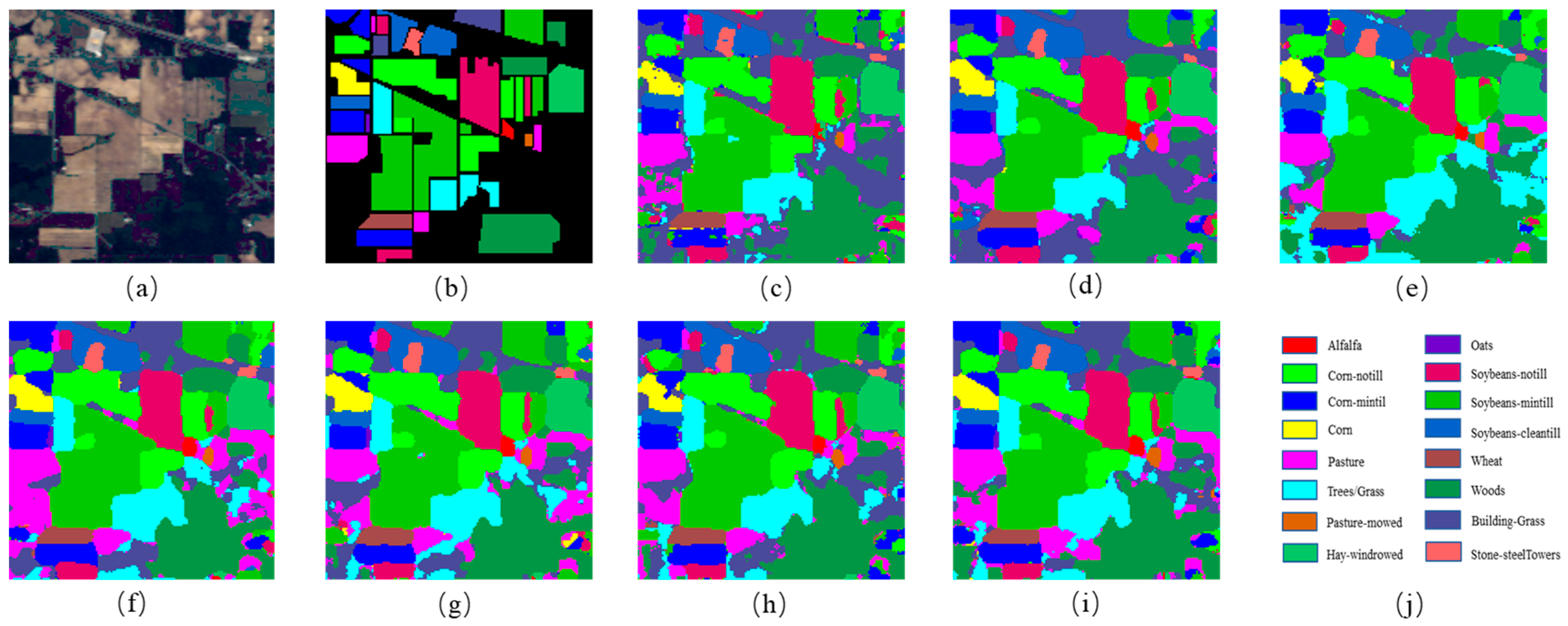
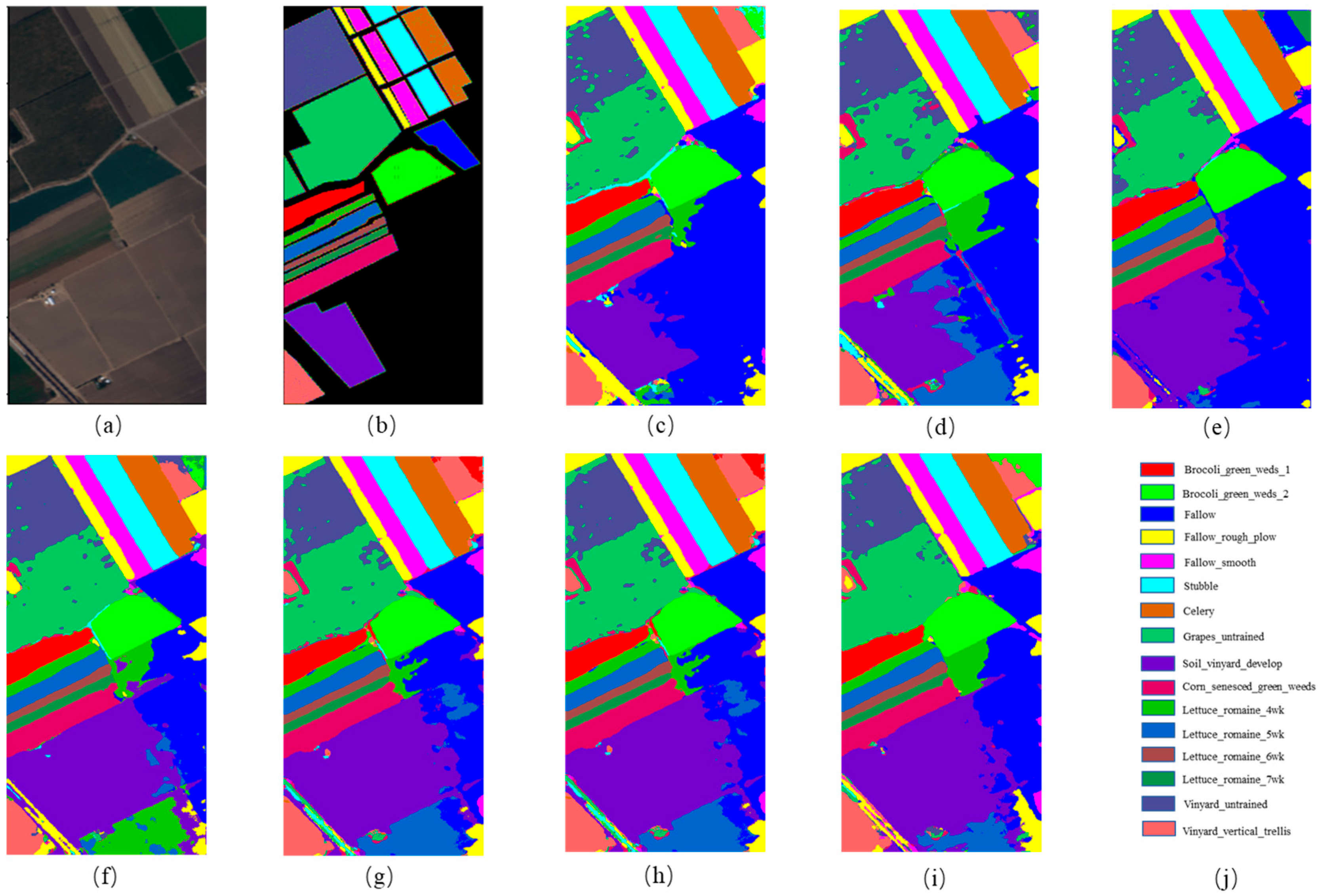
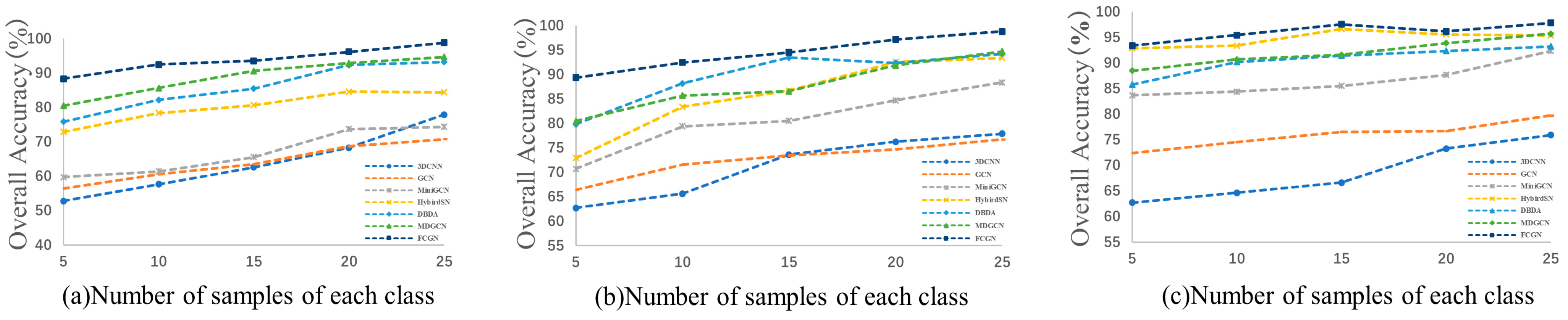
To reduce the complexity of graph structure construction, superpixel segmentation is often performed on an HSI first; however, superpixel segmentation processing leads to similar features within each superpixel node, resulting in a lack of local details in the classification map. To solve the above problems, a new hyperspectral image classification algorithm, the FCGN, was proposed in this paper, in which a graph convolutional network based on superpixel segmentation was fused with an attentional convolutional network for feature fusion, a GCN based on superpixel segmentation was used to extract superpixel-level features, an attentional convolutional network was used to extract local detail features, and, finally, the obtained complementary features were used to improve the classification results. In order to verify the effectiveness of the algorithm, experiments were conducted on three datasets and compared with some excellent algorithms. The experimental results show that the FCGN achieved a better classification performance. Although the FCGN achieved better classification results, there are still some shortcomings. In particular, this paper did not consider the variability of different neighbor nodes during the construction of the graph structure which may limit the ability of the model. In addition, only a simple feature splicing fusion method was used in this paper, so the construction of the graph structure and new fusion mechanism will be further explored in subsequent research.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}