



DABaCLT: A Data Augmentation Bias-Aware Contrastive Learning Framework for Time Series Representation

Abstract
:1. Introduction
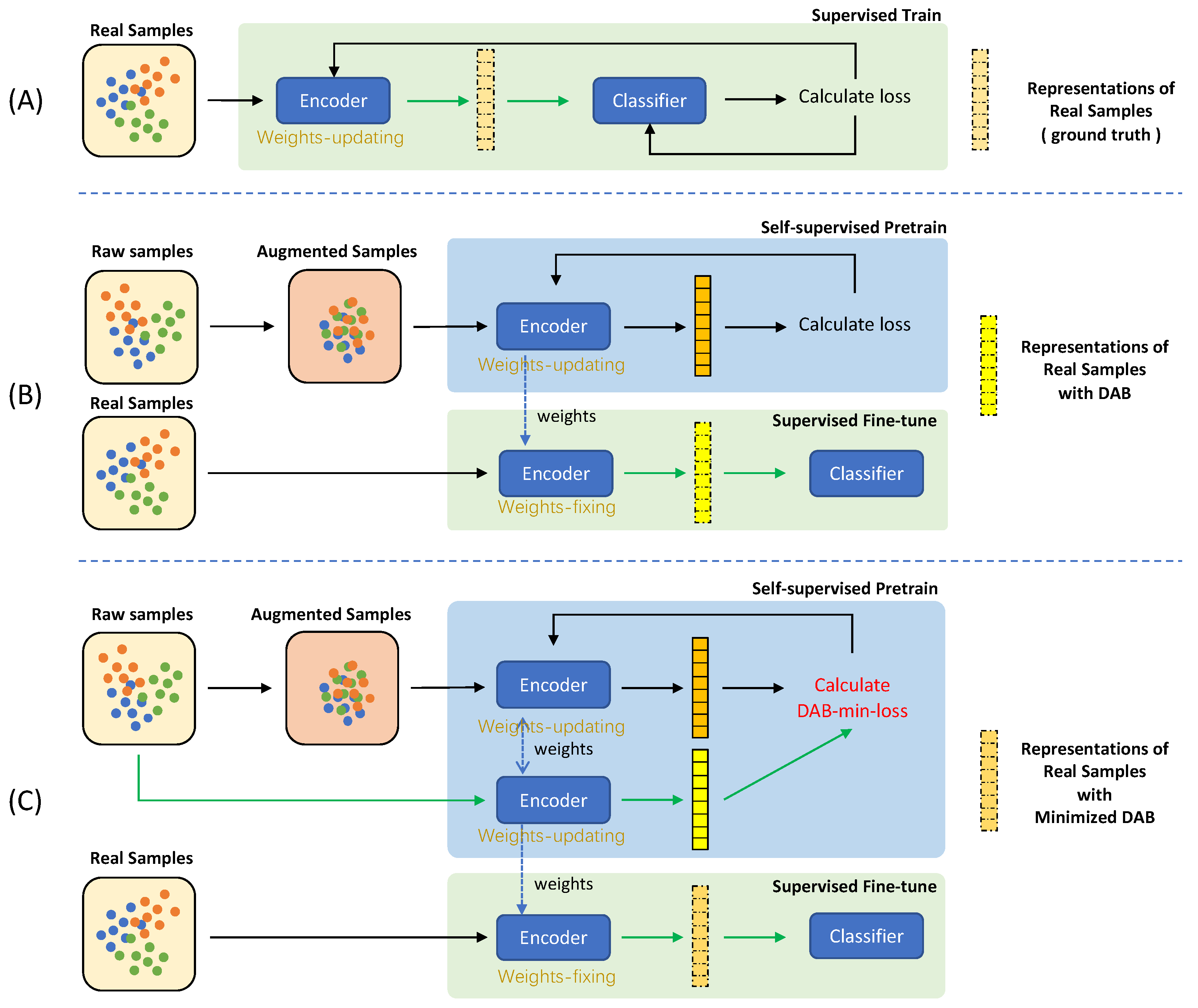
- We introduce the concept of the data augmentation bias problem (DAB) and present the DABaCLT framework to recognize and minimize DAB during the learning of time series representations. The RFS is developed as a criterion for perceiving DAB and is effectively combined with the DABFS.
- We propose DAB-minimizing contrastive loss (DABMinLoss) in the contrasting module to reduce the DAB in extracted temporal and contextual features. The complete DABMinLoss consists of five parts implemented in the DABa-TC and DABa-CC modules.
- Extensive experiments demonstrate the superiority of DABaCLT over previous works. Compared to self-supervised learning, DABaCLT achieves significant improvements ranging from 0.19% to 22.95% in sleep staging classification, 2.96% to 5.05% in human activity recognition, and 1.00% to 2.46% in epilepsy seizure prediction. The results also compete favorably with supervised methods.
2. Materials and Methods
2.1. Data Description
2.2. The Proposed Method
2.2.1. Transformation Inconsistency Augmentation
2.2.2. DAB-minimize Contrasting Learning
| Algorithm 1 DAB-aware Contrasting module algorithm. |
|
DAB-Aware Temporal Contrasting
DAB-Aware Contextual Contrasting
3. Results
Comparison with Baseline Approaches
4. Discussion
4.1. Comparisons of Time Series Augmentation Methods
4.2. Impact of Raw Features Stream
4.3. Impact of Parameter Selection
4.4. The Visualization of DAB Problem
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Experimental Setup
Appendix B. Detailed Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Precision | Sensitivity | Specificity | |
|---|---|---|---|
| ESP | 98.49 ± 0.33 | 99.29 ± 0.31 | 93.98 ± 1.39 |
| Class | Walking | Walking Upstairs | Walking Downstairs |
|---|---|---|---|
| recall | 96.57 ± 2.92 | 94.48 ± 5.91 | 97.86 ± 2.39 |
| class | standing | sitting | lying down |
| recall | 78.82 ± 2.64 | 87.41 ± 2.29 | 97.58 ± 0.39 |
| Class | W | N1 | N2 | N3 | REM |
|---|---|---|---|---|---|
| recall | 94.34 ± 1.75 | 28.84 ± 5.51 | 81.80 ± 1.93 | 87.02 ± 1.56 | 82.56 ± 2.79 |

References
- Torres, J.F.; Hadjout, D.; Sebaa, A.; Martínez-Álvarez, F.; Troncoso, A. Deep Learning for Time Series Forecasting: A Survey. Big Data 2021, 9, 3–21. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Ding, X.; Ke, H.; Xu, C.; Zhang, H. Student Behavior Prediction of Mental Health Based on Two-Stream Informer Network. Appl. Sci. 2023, 13, 2371. [Google Scholar] [CrossRef]
- Sharma, S.; Khare, S.K.; Bajaj, V.; Ansari, I.A. Improving the separability of drowsiness and alert EEG signals using analytic form of wavelet transform. Appl. Acoust. 2021, 181, 108164. [Google Scholar] [CrossRef]
- Sun, Z.; Ke, Q.; Rahmani, H.; Bennamoun, M.; Wang, G.; Liu, J. Human action recognition from various data modalities: A review. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3200–3225. [Google Scholar]
- Jana, R.; Mukherjee, I. Deep learning based efficient epileptic seizure prediction with EEG channel optimization. Biomed. Signal Process. Control 2021, 68, 102767. [Google Scholar]
- Khare, S.K.; Nishad, A.; Upadhyay, A.; Bajaj, V. Classification Of Emotions From Eeg Signals Using Time-order Representation Based On the S-transform And Convolutional Neural Network. Electron. Lett. 2020, 56, 1359–1361. [Google Scholar] [CrossRef]
- Mohsenvand, M.N.; Izadi, M.R.; Maes, P. Contrastive Representation Learning for Electroencephalogram Classification. In Proceedings of the Machine Learning for Health NeurIPS Workshop; Alsentzer, E., McDermott, M.B.A., Falck, F., Sarkar, S.K., Roy, S., Hyland, S.L., Eds.; 2020; Volume 136, pp. 238–253. Available online: proceedings.mlr.press/v136/mohsenvand20a.html (accessed on 13 May 2023).
- Jiang, X.; Zhao, J.; Du, B.; Yuan, Z. Self-supervised Contrastive Learning for EEG-based Sleep Staging. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhong, S.h.; Liu, Y. GANSER: A Self-supervised Data Augmentation Framework for EEG-based Emotion Recognition. IEEE Trans. Affect. Comput. 2022. [Google Scholar] [CrossRef]
- Levasseur, G.; Bersini, H. Time Series Representation for Real-World Applications of Deep Neural Networks. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–8. [Google Scholar] [CrossRef]
- Yang, L.; Hong, S. Unsupervised Time-Series Representation Learning with Iterative Bilinear Temporal-Spectral Fusion. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; Volume 162, pp. 25038–25054. [Google Scholar]
- Zerveas, G.; Jayaraman, S.; Patel, D.; Bhamidipaty, A.; Eickhoff, C. A transformer-based framework for multivariate time series representation learning. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Virtual Event, Singapore, 14 –18 August 2021; pp. 2114–2124. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, Virtual Event, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Rethmeier, N.; Augenstein, I. A Primer on Contrastive Pretraining in Language Processing: Methods, Lessons Learned and Perspectives. ACM Comput. Surv. 2022, 55, 1–17. [Google Scholar] [CrossRef]
- Sun, L.; Yolwas, N.; Jiang, L. A Method Improves Speech Recognition with Contrastive Learning in Low-Resource Languages. Appl. Sci. 2023, 13, 4836. [Google Scholar] [CrossRef]
- Yue, Z.; Wang, Y.; Duan, J.; Yang, T.; Huang, C.; Tong, Y.; Xu, B. TS2Vec: Towards Universal Representation of Time Series. arXiv 2021. [Google Scholar] [CrossRef]
- Ozyurt, Y.; Feuerriegel, S.; Zhang, C. Contrastive Learning for Unsupervised Domain Adaptation of Time Series. arXiv 2022, arXiv:2206.06243. [Google Scholar]
- Nonnenmacher, M.T.; Oldenburg, L.; Steinwart, I.; Reeb, D. Utilizing Expert Features for Contrastive Learning of Time-Series Representations. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; 162, pp. 16969–16989. [Google Scholar]
- Franceschi, J.Y.; Dieuleveut, A.; Jaggi, M. Unsupervised Scalable Representation Learning for Multivariate Time Series. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Zhang, X.; Zhao, Z.; Tsiligkaridis, T.; Zitnik, M. Self-supervised contrastive pre-training for time series via time-frequency consistency. arXiv 2022, arXiv:2206.08496. [Google Scholar]
- Eldele, E.; Ragab, M.; Chen, Z.; Wu, M.; Kwoh, C.K.; Li, X.; Guan, C. Time-Series Representation Learning via Temporal and Contextual Contrasting. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21, Montreal, QC, Cananda, 19–27 August 2021; pp. 2352–2359. [Google Scholar]
- Deldari, S.; Xue, H.; Saeed, A.; He, J.; Smith, D.V.; Salim, F.D. Beyond Just Vision: A Review on Self-Supervised Representation Learning on Multimodal and Temporal Data. arXiv 2022, arXiv:2206.02353. [Google Scholar]
- Goldberger, A.; Amaral, L.; Glass, L.; Hausdorff, J.; Ivanov, P.C.; Mark, R.; Mietus, J.; Moody, G.; Peng, C.; Stanley, H. PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals. Circulation 2000, 101, E215–E220. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yubo, Z.; Yingying, L.; Bing, Z.; Lin, Z.; Lei, L. MMASleepNet: A multimodal attention network based on electrophysiological signals for automatic sleep staging. Front. Neurosci. 2022, 16, 973761. [Google Scholar] [CrossRef] [PubMed]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra Perez, X.; Reyes Ortiz, J.L. A public domain dataset for human activity recognition using smartphones. In Proceedings of the 21th International European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 5–7 October 2013; pp. 437–442. [Google Scholar]
- Andrzejak, R.G.; Lehnertz, K.; Mormann, F.; Rieke, C.; David, P.; Elger, C.E. Indications of nonlinear deterministic and finite-dimensional structures in time series of brain electrical activity: Dependence on recording region and brain state. Phys. Rev. E 2001, 64, 061907. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zha, D.; Lai, K.H.; Zhou, K.; Hu, X. Towards similarity-aware time-series classification. In Proceedings of the 2022 SIAM International Conference on Data Mining (SDM), SIAM, Alexandria, VA, USA, 28–30 April 2022; pp. 199–207. [Google Scholar]
- Jastrzebska, A.; Nápoles, G.; Salgueiro, Y.; Vanhoof, K. Evaluating time series similarity using concept-based models. Knowl.-Based Syst. 2022, 238, 107811. [Google Scholar] [CrossRef]





| Dataset | #Train | #Valid | #Test | Length | #Channel | #Class |
|---|---|---|---|---|---|---|
| Sleep-EDF | 31,952 | 3551 | 6805 | 3000 | 1 | 5 |
| HAR | 6616 | 736 | 2947 | 128 | 9 | 6 |
| ESR | 8280 | 920 | 2300 | 178 | 1 | 2 |
| Method | SSC | HAR | ESP | |||
|---|---|---|---|---|---|---|
| Avg. Acc | MF1 | Avg. Acc | MF1 | Avg. Acc | MF1 | |
| supervised | 81.14 ± 0.36 | 74.07 ± 0.33 | 91.47 ± 0.75 | 91.09 ± 0.83 | 96.63 ± 0.31 | 94.56 ± 0.54 |
| simCLR | 56.58 ± 0.44 | 48.81 ± 0.13 | 86.99 ± 0.18 | 86.05 ± 0.20 | 96.00 ± 0.20 | 93.33 ± 0.35 |
| TS-TCC | 79.34 ± 0.33 | 72.92 ± 0.49 | 89.08 ± 0.19 | 88.45 ± 0.19 | 95.59 ± 0.13 | 92.62 ± 0.21 |
| TS2Vec | 73.50 ± 1.48 | 65.93 ± 0.25 | 87.91 ± 0.02 | 86.55 ± 0.22 | 97.05 ± 0.36 | 94.63 ± 0.21 |
| DABaCLT (ours) | 79.53 ± 0.11 | 73.25 ± 0.15 | 92.04 ± 0.24 | 91.52 ± 0.26 | 98.05 ± 0.10 | 96.93 ± 0.18 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, Y.; Luo, Y.; Shao, H.; Zhang, L.; Li, L. DABaCLT: A Data Augmentation Bias-Aware Contrastive Learning Framework for Time Series Representation. Appl. Sci. 2023, 13, 7908. https://doi.org/10.3390/app13137908
Zheng Y, Luo Y, Shao H, Zhang L, Li L. DABaCLT: A Data Augmentation Bias-Aware Contrastive Learning Framework for Time Series Representation. Applied Sciences. 2023; 13(13):7908. https://doi.org/10.3390/app13137908
Chicago/Turabian StyleZheng, Yubo, Yingying Luo, Hengyi Shao, Lin Zhang, and Lei Li. 2023. "DABaCLT: A Data Augmentation Bias-Aware Contrastive Learning Framework for Time Series Representation" Applied Sciences 13, no. 13: 7908. https://doi.org/10.3390/app13137908
APA StyleZheng, Y., Luo, Y., Shao, H., Zhang, L., & Li, L. (2023). DABaCLT: A Data Augmentation Bias-Aware Contrastive Learning Framework for Time Series Representation. Applied Sciences, 13(13), 7908. https://doi.org/10.3390/app13137908