





A Wasserstein Generative Adversarial Network–Gradient Penalty-Based Model with Imbalanced Data Enhancement for Network Intrusion Detection

Abstract
:1. Introduction
2. Related Research
2.1. AI-Based Network Intrusion Detection System
2.2. Data Imbalance Problem
2.3. GAN-Based Data Enhancement
3. Data Enhancement Methods
3.1. Gaussian Noise Data Enhancement
3.2. WGAN-GP Data Enhancement
3.3. SMOTE Data Enhancement
4. Data Enhancement Experimental Methodology
4.1. Two-Stage Fine-Tuning Algorithm
4.2. Data Enhancement for Rare Data in NSL-KDD
4.3. Classification Algorithms for Enhanced NSL-KDD
5. Discussion of Experimental Results
5.1. First-Stage Experimental Results
5.2. Second-Stage Experimental Results
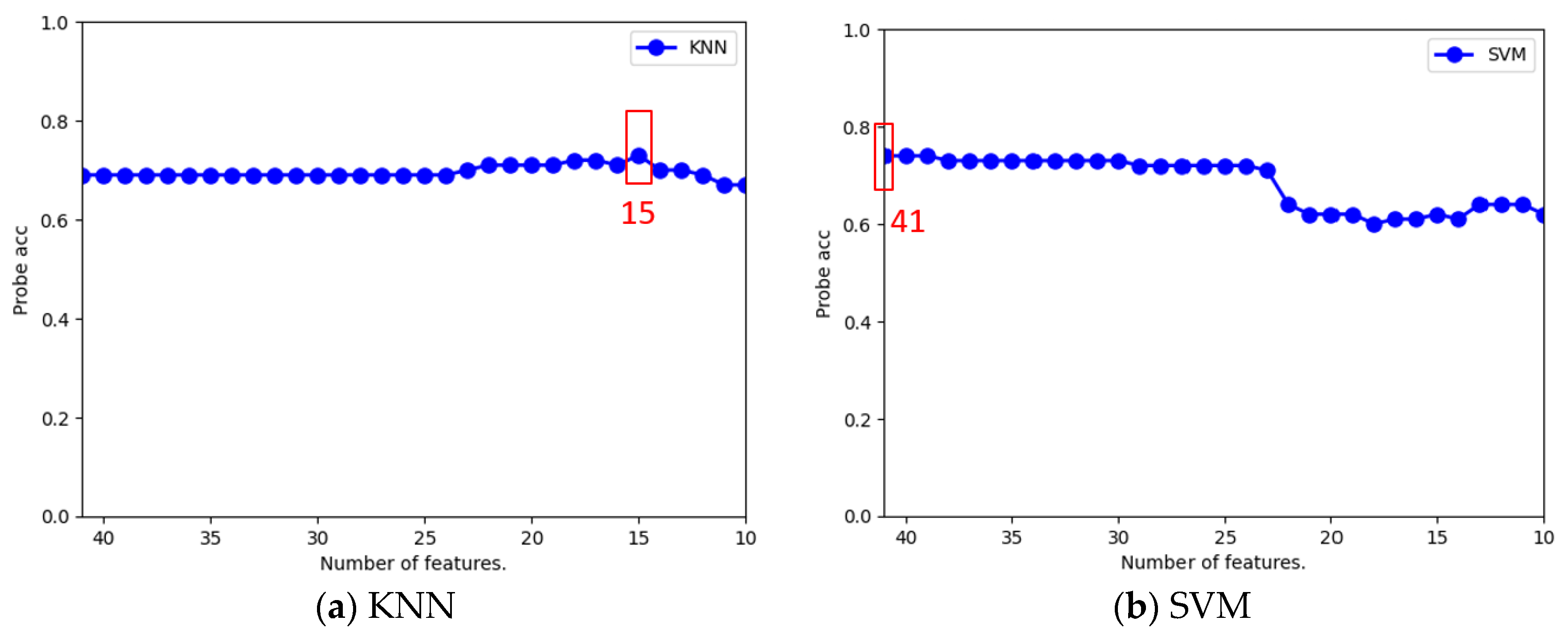
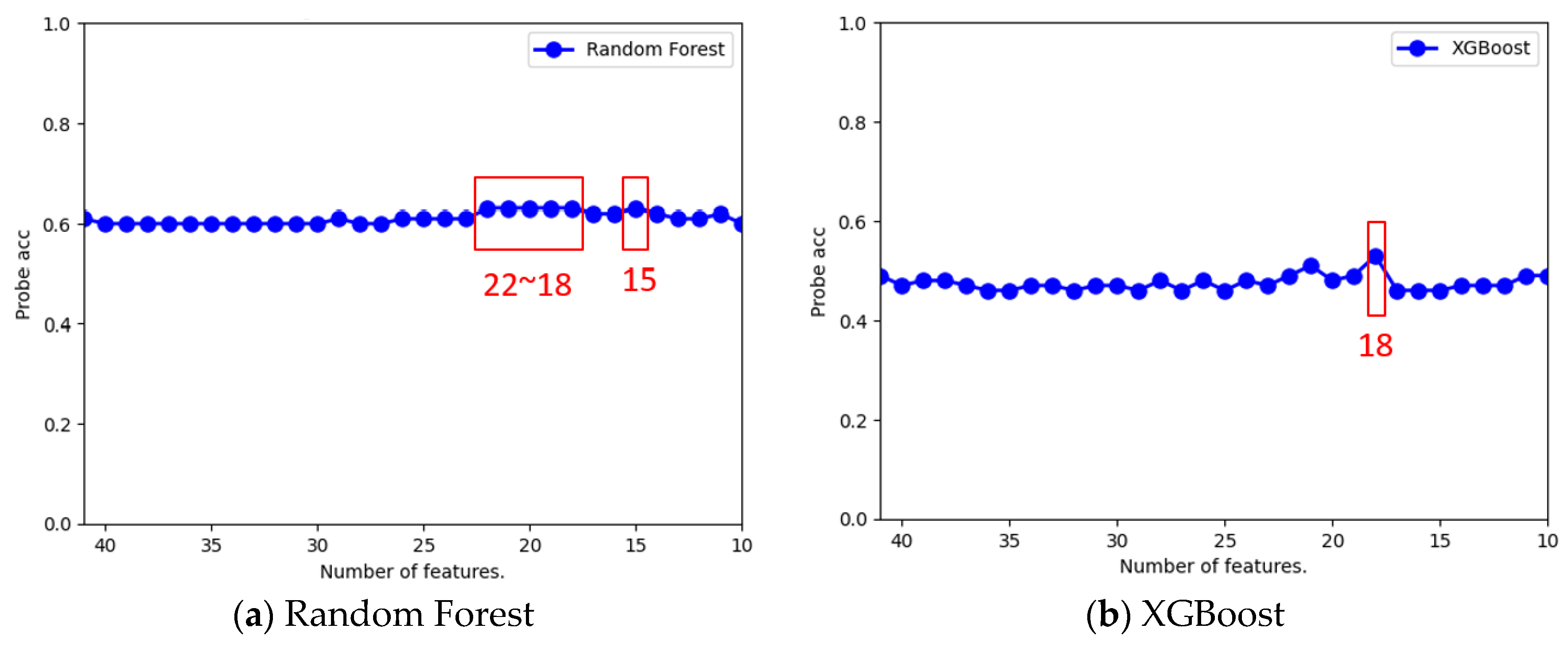
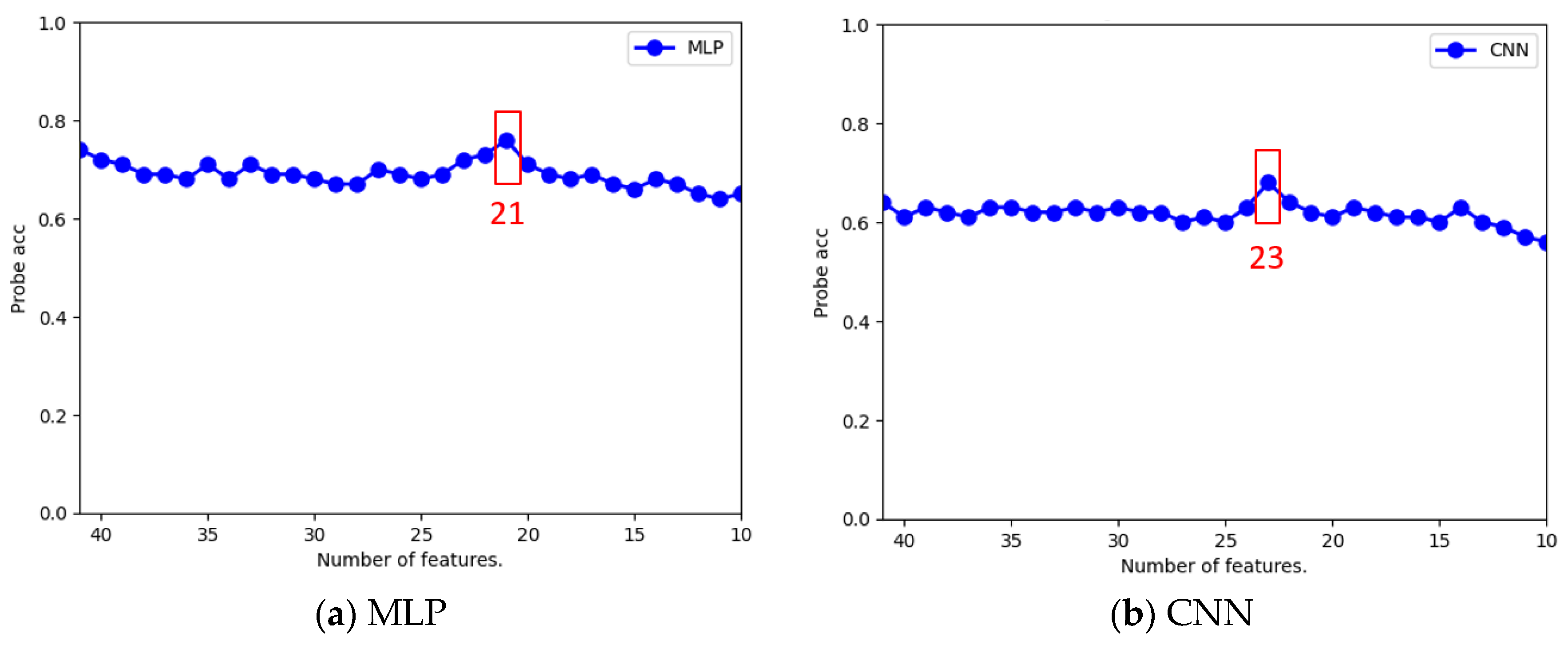
5.2.1. Analysis of Optimal Number of Features
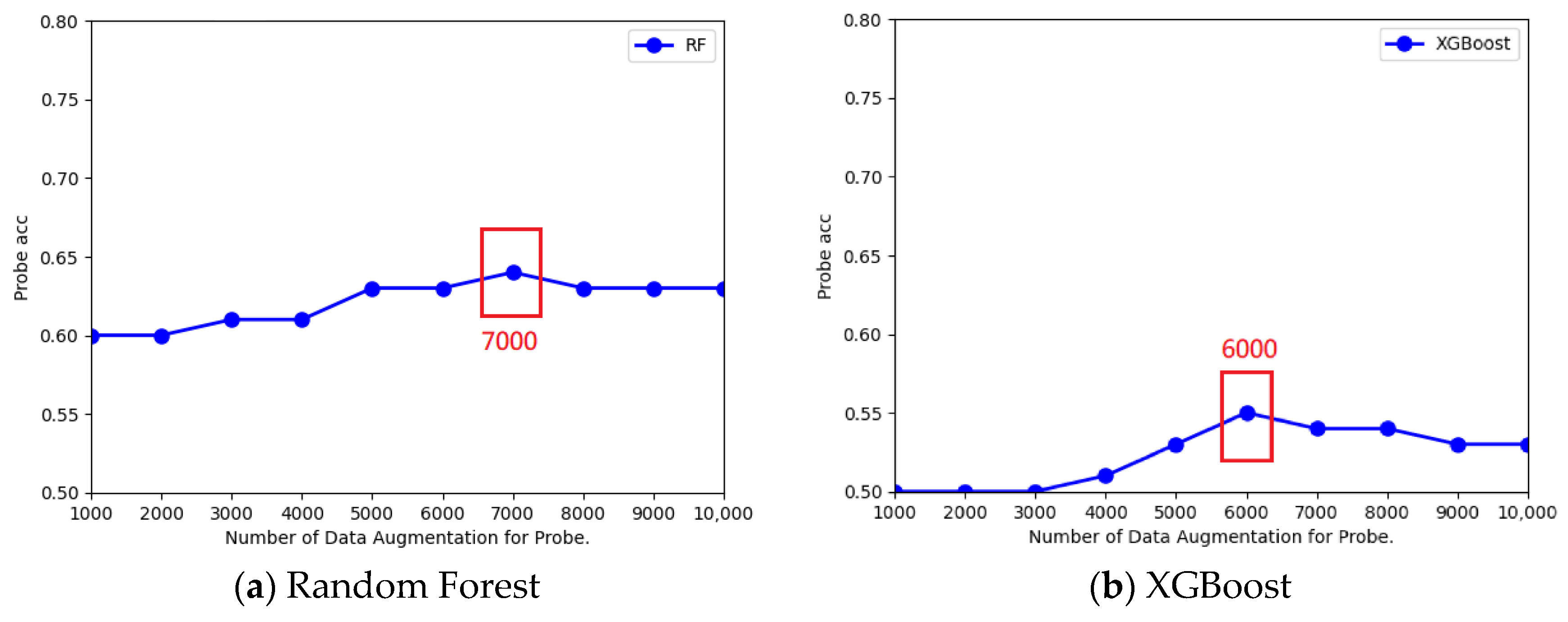
5.2.2. Analysis of Optimal Number of Data Items Enhanced
5.2.3. Analysis of Optimal Number of Model Layers
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Reddy, L.N.; Butakov, S.; Zavarsky, P. Applying ML algorithms to improve traffic classification in intrusion detection systems. In Proceedings of the 2020 IEEE 19th International Conference on Cognitive Informatics & Cognitive Computing (ICCI* CC), Beijing, China, 26–28 September 2020; pp. 1–6. [Google Scholar]
- Chopra, A.; Behal, S.; Sharma, V. Evaluating machine learning algorithms to detect and classify DDoS attacks in IoT. In Proceedings of the 2021 8th International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 17–19 March 2021; pp. 517–521. [Google Scholar]
- Dipon, T.M.; Hossain, M.S.; Narman, H.S. Detecting network intrusion through anomalous packet identification. In Proceedings of the 2020 30th International Telecommunication Networks and Applications Conference (ITNAC), Melbourne, Australia, 25–27 November 2020; pp. 1–6. [Google Scholar]
- Sadioura, J.S.; Singh, S.; Das, A. Selection of sub-optimal feature set of network data to implement machine learning models to develop an efficient NIDS. In Proceedings of the 2019 International Conference on Data Science and Engineering (ICDSE), Patna, India, 26–28 September 2019; pp. 120–125. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Yan, B.; Han, G.; Sun, M.; Ye, S. A novel region adaptive SMOTE algorithm for intrusion detection on imbalanced problem. In Proceedings of the 2017 3rd IEEE International Conference on Computer and Communications (ICCC), Chengdu, China, 13–16 December 2017; pp. 1281–1286. [Google Scholar]
- Bunkhumpornpat, C.; Sinapiromsaran, K.; Lursinsap, C. Safe-level-SMOTE: Safe-level-synthetic minority over-sampling technique for handling the class imbalanced problem. In Proceedings of the Pacific-Asia conference on knowledge discovery and data mining, Bangkok, Thailand, 27–30 April 2009; pp. 475–482. [Google Scholar]
- Gad, A.R.; Nashat, A.A.; Barkat, T.M. Intrusion detection system using machine learning for vehicular ad hoc networks based on ToN-IoT dataset. IEEE Access 2021, 9, 142206–142217. [Google Scholar] [CrossRef]
- Lee, B.-S.; Kim, J.-W.; Choi, M.-J. Experimental Comparison of Hybrid Sampling Methods for an Efficient NIDS. In Proceedings of the 2022 23rd Asia-Pacific Network Operations and Management Symposium (APNOMS), Takamatsu, Japan, 28–30 September 2022; pp. 1–4. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Ring, M.; Schlör, D.; Landes, D.; Hotho, A. Flow-based network traffic generation using generative adversarial networks. Comput. Secur. 2019, 82, 156–172. [Google Scholar] [CrossRef] [Green Version]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 7–9 August 2017; pp. 214–223. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved training of wasserstein GANs. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5769–5779. [Google Scholar]
- MShahid, R.; Blanc, G.; Jmila, H.; Zhang, Z.; Debar, H. Generative deep learning for internet of things network traffic generation. In Proceedings of the 2020 IEEE 25th Pacific Rim International Symposium on Dependable Computing (PRDC), Perth, Australia, 1–4 December 2020; pp. 70–79. [Google Scholar]
- Endres, D.M.; Schindelin, J.E. A new metric for probability distributions. IEEE Trans. Inf. Theory 2003, 49, 1858–1860. [Google Scholar] [CrossRef] [Green Version]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Heinonen, J. Lectures on Lipschitz Analysis, No. 100; University of Jyväskylä: Jyväskylä, Finland, 2005. [Google Scholar]
- Altman, N.S. An introduction to kernel and nearest-neighbor nonparametric regression. Am. Stat. 1992, 46, 175–185. [Google Scholar] [CrossRef] [Green Version]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Internal Representations by Error Propagation; California University San Diego La Jolla Institute for Cognitive Science: San Diego, CA, USA, 1985. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Raileanu, L.E.; Stoffel, K. Theoretical comparison between the gini index and information gain criteria. Ann. Math. Artif. Intell. 2004, 41, 77–93. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Discriminator Model | |
|---|---|
| Layer | Hyperparameter Values |
| Input Layer | Shape: 6, 7, 1 |
| Conv2D | Kernels: 64 Kernel size: 3, 3 Strides: 2, 2 Padding: same Use bias: true |
| Conv2D | Kernels: 128 Kernel size: 3, 3 Strides: 2, 2 Padding: same Use bias: true |
| Leaky ReLU | Alpha: 0.2 |
| Dropout | Rate: 0.3 |
| Flatten | Output shape: 512 |
| Dropout | Rate: 0.2 |
| Dense | Output shape: 1 |
| Generator Model | |
|---|---|
| Layer | Hyperparameter Values |
| Input Layer | Shape: 1024 |
| Dense | Shape: 2, 2, 256 |
| Batch Normalization | Default |
| Leaky ReLU | Alpha: 0.2 |
| Reshape | Shape: 2, 2, 256 |
| UpSampling2D | Up size: 2, 2 |
| Conv2D | Kernels: 128 Kernel size: 3, 3 Strides: 1, 1 Padding: same |
| Batch Normalization | Default |
| Leaky ReLU | Alpha: 0.2 |
| UpSampling2D | Up size: 2, 2 |
| Conv2D | Kernels: 1 Kernel size: 3, 3 Strides: 1, 1 Padding: same |
| Batch Normalization | Default |
| Sigmoid | Default |
| Cropping2D | Cropping: 1, 1, 0, 1 |
| Label | Class | Quantity | Percentage |
|---|---|---|---|
| 0 | Normal | 67,343 | 53.46% |
| 1 | Probe | 11,656 | 9.25% |
| 2 | DoS | 45,927 | 36.46% |
| 3 | U2R | 52 | 0.04% |
| 4 | R2L | 995 | 0.79% |
| All | 125,973 | 100.00% |
| Label | Class | Quantity | Percentage |
|---|---|---|---|
| 0 | Normal | 67,343 | 51.42% |
| 1 | Probe | 16,656 | 12.72% |
| 2 | DoS | 45,927 | 35.06% |
| 3 | U2R | 52 | 0.04% |
| 4 | R2L | 995 | 0.76% |
| All | 130,973 | 100.00% |
| Label | Class | Quantity | Percentage |
|---|---|---|---|
| 0 | Normal | 67,343 | 51.42% |
| 1 | Probe | 11,656 | 8.90% |
| 2 | DoS | 45,927 | 35.06% |
| 3 | U2R | 5052 | 3.59% |
| 4 | R2L | 995 | 0.76% |
| All | 130,973 | 100.00% |
| Label | Class | Quantity | Percentage |
|---|---|---|---|
| 0 | Normal | 67,343 | 51.42% |
| 1 | Probe | 10,656 | 8.90% |
| 2 | DoS | 45,927 | 35.06% |
| 3 | U2R | 52 | 0.04% |
| 4 | R2L | 5995 | 4.58% |
| All | 130,973 | 100.00% |
| KNN | SVM | Random Forest | XGBoost | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Attack Class | Original Data | Enhanced Data | Improved Rate | Original Data | Enhanced Data | Improved Rate | Original Data | Enhanced Data | Improved Rate | Original Data | Enhanced Data | Improved Rate |
| Probe | 68% | 70% | 2% | 70% | 71% | 1% | 60% | 62% | 2% | 45% | 47% | 2% |
| U2R | 0% | 0% | 0% | 7% | 11% | 4% | 1% | 7% | 6% | 2% | 6% | 4% |
| R2L | 1% | 5% | 4% | 0% | 6% | 6% | 1% | 3% | 2% | 4% | 7% | 3% |
| MLP | CNN | |||||
|---|---|---|---|---|---|---|
| Attack Class | Original Data | Enhanced Data | Improved Rate | Original Data | Enhanced Data | Improved Rate |
| Probe | 67% | 70% | 3% | 57% | 64% | 7% |
| U2R | 7% | 9% | 2% | 1% | 4% | 3% |
| R2L | 0% | 4% | 4% | 0% | 4% | 4% |
| KNN | SVM | Random Forest | XGBoost | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Attack Class | Original Data | Enhanced Data | Improved Rate | Original Data | Enhanced Data | Improved Rate | Original Data | Enhanced Data | Improved Rate | Original Data | Enhanced Data | Improved Rate |
| Probe | 68% | 68% | 0% | 70% | 74% | 4% | 60% | 61% | 1% | 45% | 49% | 4% |
| U2R | 0% | 6% | 6% | 7% | 10% | 3% | 1% | 1% | 0% | 2% | 4% | 2% |
| R2L | 1% | 4% | 3% | 0% | 1% | 1% | 1% | 1% | 0% | 4% | 6% | 2% |
| MLP | CNN | |||||
|---|---|---|---|---|---|---|
| Attack Class | Original Data | Enhanced Data | Improved Rate | Original Data | Enhanced Data | Improved Rate |
| Probe | 67% | 74% | 7% | 57% | 72% | 15% |
| U2R | 7% | 11% | 4% | 1% | 5% | 4% |
| R2L | 0% | 3% | 3% | 0% | 5% | 5% |
| KNN | SVM | Random Forest | XGBoost | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Attack Class | Original Data | Enhanced Data | Improved Rate | Original Data | Enhanced Data | Improved Rate | Original Data | Enhanced Data | Improved Rate | Original Data | Enhanced Data | Improved Rate |
| Probe | 68% | 68% | 0% | 70% | 72% | 2% | 60% | 59% | −1% | 45% | 48% | 3% |
| U2R | 0% | 14% | 14% | 7% | 10% | 3% | 1% | 1% | 0% | 2% | 3% | 1% |
| R2L | 1% | 8% | 7% | 0% | 15% | 15% | 2% | 4% | 2% | 4% | 11% | 7% |
| MLP | CNN | |||||
|---|---|---|---|---|---|---|
| Attack Class | Original Data | Enhanced Data | Improved Rate | Original Data | Enhanced Data | Improved Rate |
| Probe | 67% | 73% | 6% | 54% | 60% | 6% |
| U2R | 7% | 13% | 6% | 1% | 8% | 7% |
| R2L | 0% | 7% | 7% | 0% | 15% | 15% |
| Ranking | Features No. | Features Values | I.G. Values |
|---|---|---|---|
| 1 | 5 | src_bytes | 2.01736 |
| 2 | 3 | service | 1.73376 |
| 3 | 6 | dst_bytes | 1.58831 |
| 4 | 35 | dst_host_diff_srv_rate | 1.21264 |
| 5 | 33 | dst_host_srv_count | 1.18367 |
| 6 | 34 | dst_host_same_srv_rate | 1.17743 |
| 7 | 23 | count | 1.16354 |
| 8 | 4 | flag | 1.02447 |
| 9 | 40 | dst_host_rerror_rate | 0.99752 |
| 10 | 30 | diff_srv_rate | 0.96746 |
| 11 | 29 | same_srv_rate | 0.93054 |
| 12 | 41 | dst_host_srv_rerror_rate | 0.85818 |
| 13 | 24 | srv_count | 0.78858 |
| 14 | 1 | duration | 0.67224 |
| 15 | 27 | rerror_rate | 0.62959 |
| KNN | SVM | RF | XGBoost | MLP | CNN | |
|---|---|---|---|---|---|---|
| Best Feature Number | 15 | 41 | 15 | 18 | 21 | 23 |
| Probe Accuracy | 73% | 74% | 63% | 53% | 76% | 68% |
| KNN | SVM | RF | XGB | MLP | CNN | |
|---|---|---|---|---|---|---|
| Best Feature Number | 15 | 41 | 15 | 18 | 21 | 23 |
| Best Data-Enhanced Number | 8000 | 8000 | 7000 | 6000 | 6000 | 8000 |
| Probe Accuracy | 76% | 75% | 64% | 55% | 78% | 72% |
| MLP | CNN | |
|---|---|---|
| Best Feature Number | 21 | 23 |
| Best Data-Enhanced Number | 6000 | 8000 |
| Best Number of Model Layers | 4 | 6 |
| Accuracy of Probe Detection | 80% | 73% |
| KNN | SVM | RF | XGB | MLP | CNN | |
|---|---|---|---|---|---|---|
| Best Feature Number | 15 | 41 | 15 | 18 | 21 | 23 |
| Best Data-Enhanced Number | 8000 | 8000 | 7000 | 6000 | 6000 | 8000 |
| Best Number of Model Layers | - | - | - | - | 4 | 6 |
| Probe Accuracy | 76% | 75% | 64% | 55% | 80% | 73% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, G.-C.; Li, J.-H.; Li, Z.-Y. A Wasserstein Generative Adversarial Network–Gradient Penalty-Based Model with Imbalanced Data Enhancement for Network Intrusion Detection. Appl. Sci. 2023, 13, 8132. https://doi.org/10.3390/app13148132
Lee G-C, Li J-H, Li Z-Y. A Wasserstein Generative Adversarial Network–Gradient Penalty-Based Model with Imbalanced Data Enhancement for Network Intrusion Detection. Applied Sciences. 2023; 13(14):8132. https://doi.org/10.3390/app13148132
Chicago/Turabian StyleLee, Gwo-Chuan, Jyun-Hong Li, and Zi-Yang Li. 2023. "A Wasserstein Generative Adversarial Network–Gradient Penalty-Based Model with Imbalanced Data Enhancement for Network Intrusion Detection" Applied Sciences 13, no. 14: 8132. https://doi.org/10.3390/app13148132
APA StyleLee, G.-C., Li, J.-H., & Li, Z.-Y. (2023). A Wasserstein Generative Adversarial Network–Gradient Penalty-Based Model with Imbalanced Data Enhancement for Network Intrusion Detection. Applied Sciences, 13(14), 8132. https://doi.org/10.3390/app13148132