
Exploring the Use of Invalid Action Masking in Reinforcement Learning: A Comparative Study of On-Policy and Off-Policy Algorithms in Real-Time Strategy Games
 , , , , and
, , , , and
Abstract
:1. Introduction
- We introduce the concept of action-level masking, which is proven to be equivalent to logit-level masking. The theoretical analysis based on action-level masking demonstrates that the difference between the invalid action policy gradient and the naive invalid action policy gradient is a state-dependent gradient that impacts the probability distribution of invalid actions. This contributes to a better understanding of the impact of invalid action masking on gradients.
- We prove that the naive policy gradient is indeed a valid gradient that optimizes both the masked policy and original policy concurrently. Although this is a counter-intuitive conclusion, it ensures that we can directly use the naive policy gradient for training without causing instability. In addition, we also propose an off-policy algorithm for invalid action masking that focuses on optimizing the original policy.
- We conduct experiments based on the Gym-RTS platform [24] to compare the performance of the proposed algorithms and invalid action penalty. The results show that Off-PIAM outperforms other algorithms even if the masking is removed, and CO-IAM scales well on complex tasks. Based on these findings, we conclude that the Off-PIAM algorithm is suitable for addressing most tasks, while the CO-IAM algorithm is well-suited for handling more complex tasks.
2. Background
2.1. Reinforcement Learning
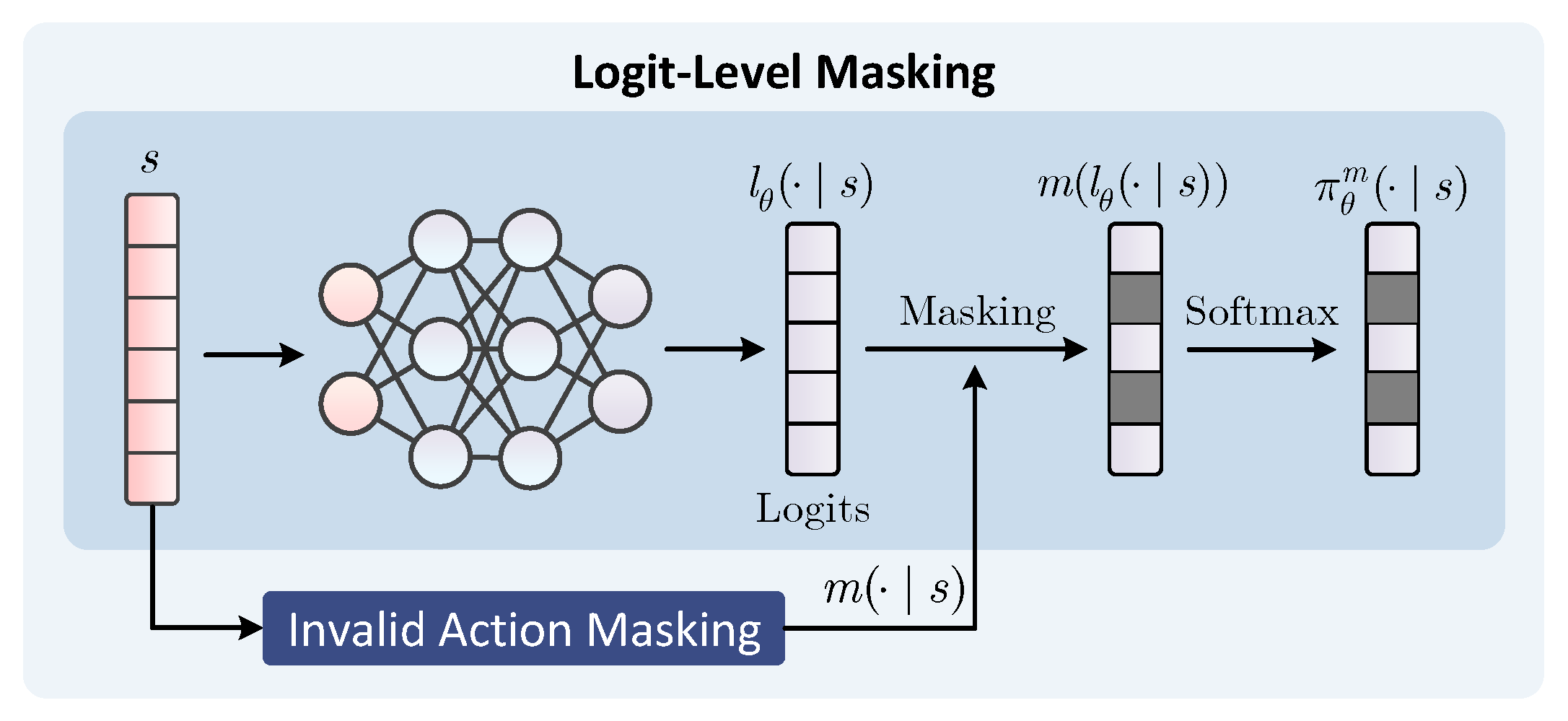
2.2. Logit-Level Masking
3. Invalid Action Masking
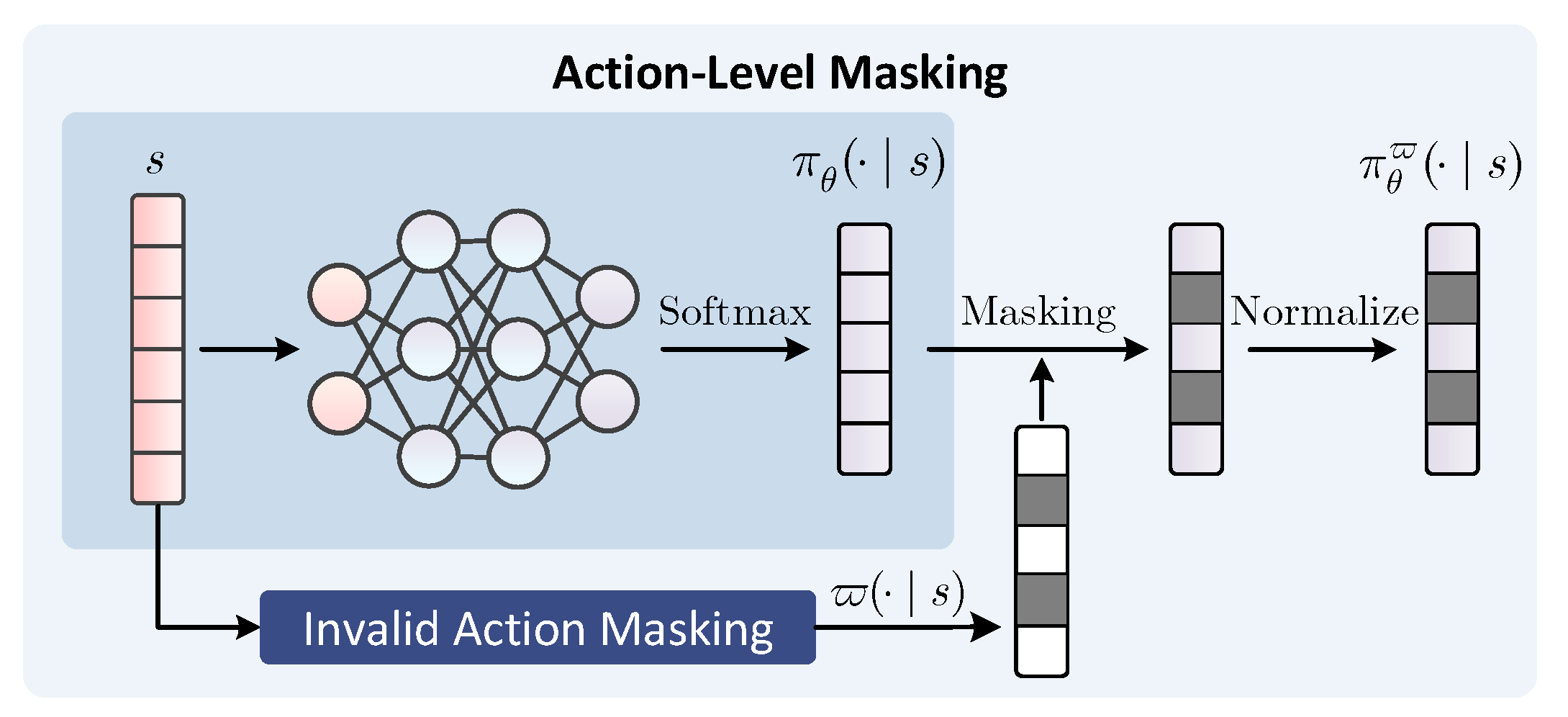
3.1. Action-Level Masking
3.2. Equivalence Verification
3.3. Masking Changes Policy Gradient
4. Practical Algorithms for Action Masking
4.1. On-Policy Algorithm
4.2. Off-Policy Algorithm
4.3. Composite Objective Algorithm
5. Empirical Analysis
5.1. Evaluation Metrics
5.2. Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Xu, Y.; Wei, Y.; Jiang, K.; Wang, D.; Deng, H. Multiple UAVs Path Planning Based on Deep Reinforcement Learning in Communication Denial Environment. Mathematics 2023, 11, 405. [Google Scholar] [CrossRef]
- Li, K.; Zhang, T.; Wang, R.; Wang, Y.; Han, Y.; Wang, L. Deep Reinforcement Learning for Combinatorial Optimization: Covering Salesman Problems. IEEE Trans. Cybern. 2022, 52, 13142–13155. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Song, J.; Luo, Y.; Zhao, M.; Hu, Y.; Zhang, Y. Fault-Tolerant Integrated Guidance and Control Design for Hypersonic Vehicle Based on PPO. Mathematics 2022, 10, 3401. [Google Scholar] [CrossRef]
- Liu, X.; Tan, Y. Attentive Relational State Representation in Decentralized Multiagent Reinforcement Learning. IEEE Trans. Cybern. 2022, 52, 252–264. [Google Scholar] [CrossRef] [PubMed]
- Liang, W.; Wang, J.; Bao, W.; Zhu, X.; Wu, G.; Zhang, D.; Niu, L. Qauxi: Cooperative multi-agent reinforcement learning with knowledge transferred from auxiliary task. Neurocomputing 2022, 504, 163–173. [Google Scholar] [CrossRef]
- Vinyals, O.; Ewalds, T.; Bartunov, S.; Georgiev, P.; Vezhnevets, A.S.; Yeo, M.; Makhzani, A.; Küttler, H.; Agapiou, J.; Schrittwieser, J.; et al. Starcraft II: A new challenge for reinforcement learning. arXiv 2017, arXiv:1708.04782. [Google Scholar]
- Berner, C.; Brockman, G.; Chan, B.; Cheung, V.; Debiak, P.; Dennison, C.; Farhi, D.; Fischer, Q.; Hashme, S.; Hesse, C.; et al. Dota 2 with large scale deep reinforcement learning. arXiv 2019, arXiv:1912.06680. [Google Scholar]
- Ye, D.; Liu, Z.; Sun, M.; Shi, B.; Zhao, P.; Wu, H.; Yu, H.; Yang, S.; Wu, X.; Guo, Q.; et al. Mastering complex control in moba games with deep reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 6672–6679. [Google Scholar]
- Csereoka, P.; Roman, B.I.; Micea, M.V.; Popa, C.A. Novel Reinforcement Learning Research Platform for Role-Playing Games. Mathematics 2022, 10, 4363. [Google Scholar] [CrossRef]
- Kalweit, G.; Huegle, M.; Werling, M.; Boedecker, J. Q-learning with Long-term Action-space Shaping to Model Complex Behavior for Autonomous Lane Changes. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 5641–5648. [Google Scholar]
- Li, P.; Wei, M.; Ji, H.; Xi, W.; Yu, H.; Wu, J.; Yao, H.; Chen, J. Deep Reinforcement Learning-Based Adaptive Voltage Control of Active Distribution Networks with Multi-terminal Soft Open Point. Int. J. Electr. Power Energy Syst. 2022, 141, 108138. [Google Scholar] [CrossRef]
- Mercado, R.; Rastemo, T.; Lindelöf, E.; Klambauer, G.; Engkvist, O.; Chen, H.; Bjerrum, E.J. Graph networks for molecular design. Mach. Learn. Sci. Technol. 2021, 2, 25023. [Google Scholar] [CrossRef]
- Zhao, Z.; Wang, Q.; Li, X. Deep reinforcement learning based lane detection and localization. Neurocomputing 2020, 413, 328–338. [Google Scholar] [CrossRef]
- Zahavy, T.; Haroush, M.; Merlis, N.; Mankowitz, D.J.; Mannor, S. Learn what not to learn: Action elimination with deep reinforcement learning. Adv. Neural Inf. Process. Syst. 2018, 31. Available online: https://proceedings.neurips.cc/paper_files/paper/2018/file/645098b086d2f9e1e0e939c27f9f2d6f-Paper.pdf (accessed on 16 July 2023).
- Dietterich, T.G. Hierarchical reinforcement learning with the MAXQ value function decomposition. J. Artif. Intell. Res. 2000, 13, 227–303. [Google Scholar] [CrossRef] [Green Version]
- Tang, C.Y.; Liu, C.H.; Chen, W.K.; You, S.D. Implementing action mask in proximal policy optimization (PPO) algorithm. ICT Express 2020, 6, 200–203. [Google Scholar] [CrossRef]
- Yang, Q.; Zhu, Y.; Zhang, J.; Qiao, S.; Liu, J. UAV air combat autonomous maneuver decision based on DDPG algorithm. In Proceedings of the 2019 IEEE 15th international conference on control and automation (ICCA), Edinburgh, UK, 16–19 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 37–42. [Google Scholar]
- Kanervisto, A.; Scheller, C.; Hautamäki, V. Action Space Shaping in Deep Reinforcement Learning. In Proceedings of the 2020 IEEE Conference on Games (CoG), Osaka, Japan, 24–27 August 2020; pp. 479–486. [Google Scholar] [CrossRef]
- Dulac-Arnold, G.; Evans, R.; Sunehag, P.; Coppin, B. Reinforcement Learning in Large Discrete Action Spaces. arXiv 2015, arXiv:1512.07679. [Google Scholar]
- Long, M.; Zou, X.; Zhou, Y.; Chung, E. Deep reinforcement learning for transit signal priority in a connected environment. Transp. Res. Part Emerg. Technol. 2022, 142, 103814. [Google Scholar] [CrossRef]
- Xiaofei, Y.; Yilun, S.; Wei, L.; Hui, Y.; Weibo, Z.; Zhengrong, X. Global path planning algorithm based on double DQN for multi-tasks amphibious unmanned surface vehicle. Ocean. Eng. 2022, 266, 112809. [Google Scholar] [CrossRef]
- Huang, S.; Ontañón, S. A Closer Look at Invalid Action Masking in Policy Gradient Algorithms. In Proceedings of the Thirty-Fifth International Florida Artificial Intelligence Research Society Conference, FLAIRS 2022, Jensen Beach, FL, USA, 15–18 May 2022. [Google Scholar] [CrossRef]
- Huang, S.; Ontañón, S.; Bamford, C.; Grela, L. Gym-μRTS: Toward Affordable Full Game Real-time Strategy Games Research with Deep Reinforcement Learning. In Proceedings of the 2021 IEEE Conference on Games (CoG), Copenhagen, Denmark, 17–20 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–8. [Google Scholar]
- Sutton, R.S.; McAllester, D.; Singh, S.; Mansour, Y. Policy gradient methods for reinforcement learning with function approximation. Adv. Neural Inf. Process. Syst. 1999, 12, 1057–1063. [Google Scholar]
- Schulman, J.; Moritz, P.; Levine, S.; Jordan, M.; Abbeel, P. High-dimensional continuous control using generalized advantage estimation. arXiv 2015, arXiv:1506.02438. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Degris, T.; White, M.; Sutton, R.S. Off-policy actor-critic. arXiv 2012, arXiv:1205.4839. [Google Scholar]
- Levine, S.; Kumar, A.; Tucker, G.; Fu, J. Offline reinforcement learning: Tutorial, review, and perspectives on open problems. arXiv 2020, arXiv:2005.01643. [Google Scholar]
- Wang, Z.; Bapst, V.; Heess, N.; Mnih, V.; Munos, R.; Kavukcuoglu, K.; de Freitas, N. Sample efficient actor-critic with experience replay. arXiv 2016, arXiv:1611.01224. [Google Scholar]
- Huang, S.; Ontañón, S. Action guidance: Getting the best of sparse rewards and shaped rewards for real-time strategy games. arXiv 2020, arXiv:2010.03956. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithms | Behavior Policy | Target Policy | Objective | Policy Gradient | PPO Ratio |
|---|---|---|---|---|---|
| On-PIAM [23] | Equation (23) | ||||
| Off-PIAM | Equation (27) | ||||
| CO-IAM | Equation (40) |
| Algorithms | Map | ||||||
|---|---|---|---|---|---|---|---|
| CO-IAM | 38.50 | – | – | – | 4.17% | 0.03% | |
| 39.30 | – | – | – | 5.46% | 0.04% | ||
| 39.30 | – | – | – | 6.21% | 0.06% | ||
| 37.20 | – | – | – | 10.10% | 0.05% | ||
| Off-PIAM | 39.98 | – | – | – | 4.57% | 0.04% | |
| 39.67 | – | – | – | 9.66% | 0.02% | ||
| 39.55 | – | – | – | 9.16% | 0.04% | ||
| 35.20 | – | – | – | 16.15% | 0.04% | ||
| On-PIAM [23] | 36.55 | – | – | – | 3.49% | 0.04% | |
| 35.40 | – | – | – | 4.50% | 0.02% | ||
| 33.58 | – | – | – | 5.40% | 0.04% | ||
| 31.85 | – | – | – | 7.09% | 0.04% | ||
| Penalty-0.01 | 39.33 | 59.62 | 1.70 | 19.38 | 6.01% | 0.07% | |
| 32.00 | 108.82 | 0.12 | 4.62 | 13.98% | 1.34% | ||
| 8.89 | 30.68 | 0.00 | 0.60 | – | 1.10% | ||
| 11.44 | 163.05 | 0.30 | 1.45 | – | 0.93% | ||
| Penalty-0.1 | 29.97 | 18.55 | 0.78 | 5.80 | 34.48% | 0.07% | |
| 0.00 | 0.00 | 0.00 | 0.00 | – | 3.74% | ||
| 7.97 | 27.72 | 0.28 | 0.75 | – | 1.29% | ||
| 0.64 | 94.70 | 0.22 | 0.88 | – | 0.57% | ||
| CO-IAM-MR | 21.37 | 0.27 | 0.00 | 152.59 | – | 0.03% | |
| 33.00 | 131.89 | 0.00 | 0.01 | – | 0.04% | ||
| 32.25 | 133.34 | 0.00 | 0.00 | – | 0.06% | ||
| 25.10 | 149.11 | 0.00 | 0.15 | – | 0.05% | ||
| Off-PIAM-MR | 39.88 | 9.53 | 17.81 | 1.31 | 7.22% | 0.04% | |
| 39.33 | 9.86 | 4.56 | 1.59 | 34.92% | 0.02% | ||
| 38.65 | 10.19 | 1.95 | 1.01 | 25.91% | 0.04% | ||
| 35.23 | 15.90 | 5.97 | 0.18 | – | 0.04% | ||
| On-PIAM-MR | 7.13 | 49.33 | 0.00 | 133.20 | – | 0.04% | |
| 0.23 | 188.20 | 0.00 | 10.89 | – | 0.02% | ||
| 0.15 | 195.66 | 0.00 | 3.90 | – | 0.04% | ||
| 0.48 | 197.64 | 0.00 | 1.37 | – | 0.04% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, Y.; Liang, X.; Zhang, J.; Yang, Q.; Yang, A.; Wang, N. Exploring the Use of Invalid Action Masking in Reinforcement Learning: A Comparative Study of On-Policy and Off-Policy Algorithms in Real-Time Strategy Games. Appl. Sci. 2023, 13, 8283. https://doi.org/10.3390/app13148283
Hou Y, Liang X, Zhang J, Yang Q, Yang A, Wang N. Exploring the Use of Invalid Action Masking in Reinforcement Learning: A Comparative Study of On-Policy and Off-Policy Algorithms in Real-Time Strategy Games. Applied Sciences. 2023; 13(14):8283. https://doi.org/10.3390/app13148283
Chicago/Turabian StyleHou, Yueqi, Xiaolong Liang, Jiaqiang Zhang, Qisong Yang, Aiwu Yang, and Ning Wang. 2023. "Exploring the Use of Invalid Action Masking in Reinforcement Learning: A Comparative Study of On-Policy and Off-Policy Algorithms in Real-Time Strategy Games" Applied Sciences 13, no. 14: 8283. https://doi.org/10.3390/app13148283