

An Interactive Learning Network That Maintains Sentiment Consistency in End-to-End Aspect-Based Sentiment Analysis

Abstract
:1. Introduction
- A new framework is proposed to address the complete ABSA in an end-to-end manner. Use the task-sharing layer to enable interaction between two subtasks and take advantage of the multi-head attention mechanism to consider the connection between aspect items;
- An auxiliary component with a gate mechanism is designed to maintain sentiment consistency within aspect items.
2. Related Work
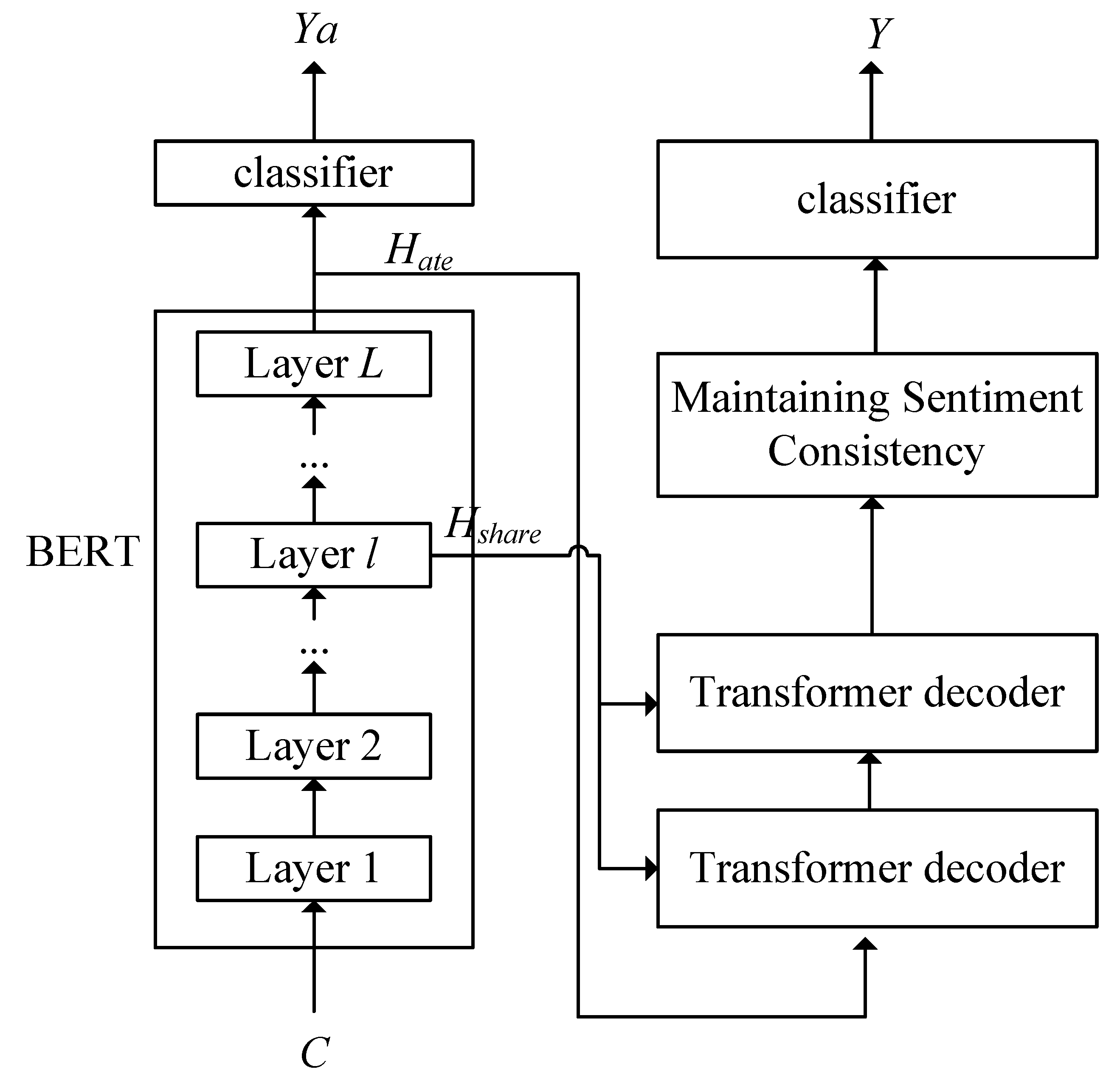
3. An Interactive Learning Network That Maintains Sentiment Consistency
3.1. Task Definition
3.2. Encoding Layer
3.3. Task-Sharing Layer
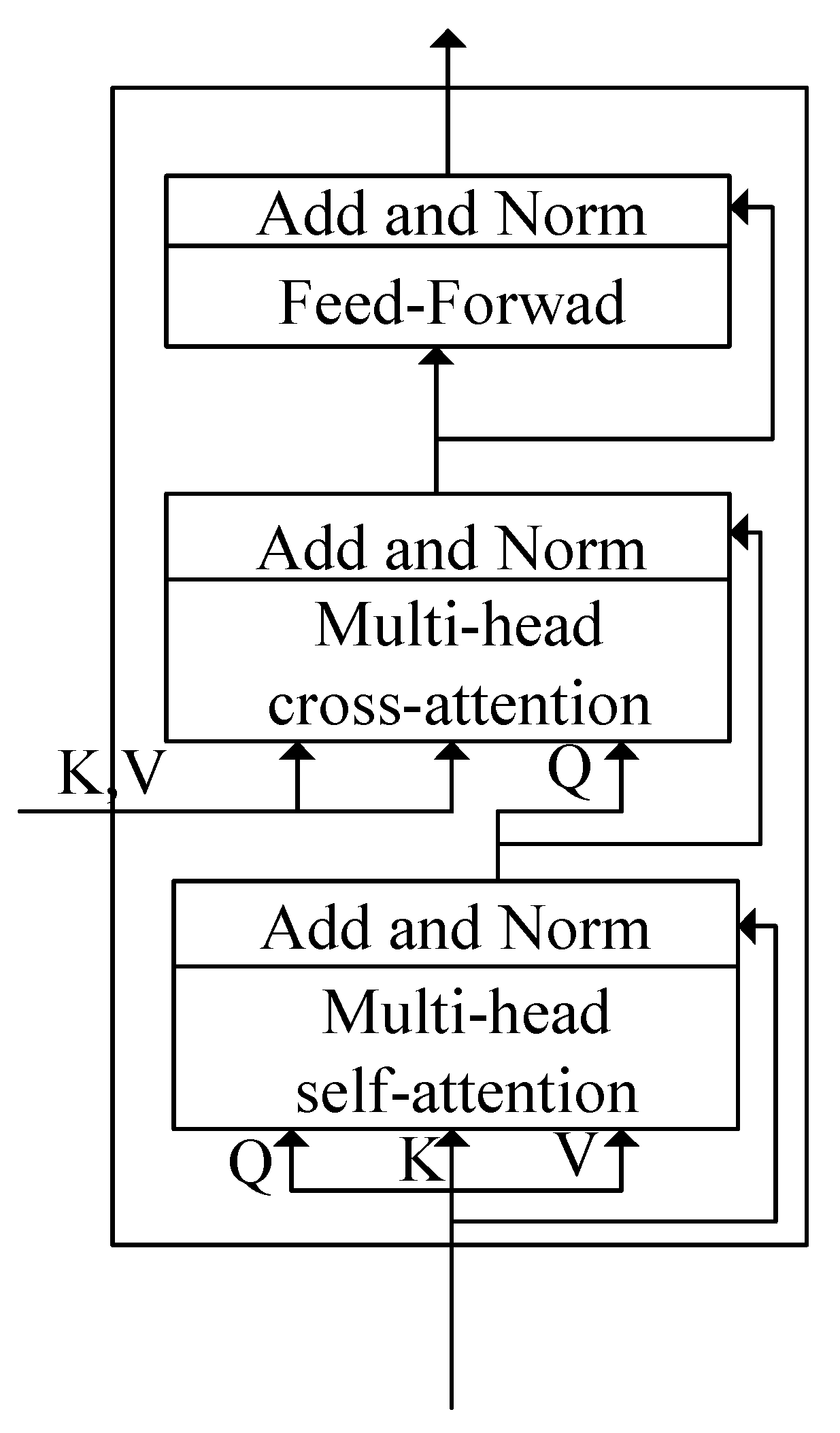
3.4. Interaction Layer
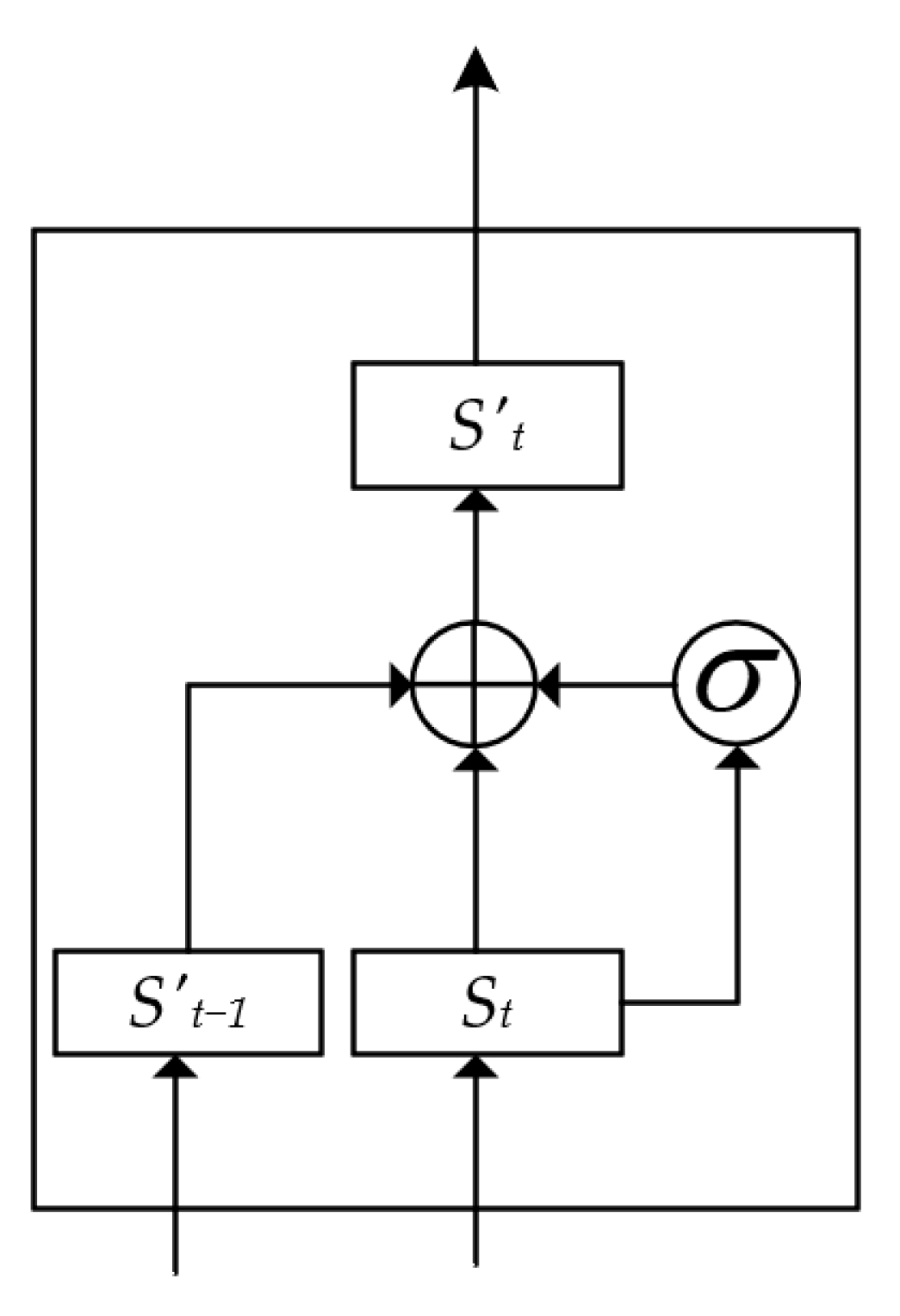
3.5. Maintaining Sentiment Consistency
3.6. Output Layer
3.7. Model Training
4. Experiment and Results Analysis
4.1. Dataset
4.2. Model Parameters
4.3. Baseline Methods
- LM-LSTM-CRF [25]: It is a language model-enhanced LSTM-CRF model, which achieved competitive results on several sequence-labeling tasks;
- E2E-TBSA [6]: Two stacked LSTMs were used to perform two tasks, target boundary detection and complete ABSA, respectively, and two auxiliary components were designed;
- DOER [13]: A double-cross shared RNN framework that jointly trains ATE and ASC for two tasks, considering the relationship between aspect and polarity;
- IMN [14]: An interactive multi-task learning model for the joint extraction of joint aspect items and opinion items, as well as ASC, and introduces a novel messaging mechanism that allows information interaction between tasks;
- BERT-E2E-ABSA [16]: Applying BERT to ABSA, they constructed a series of simple but effective neural baselines for this problem, using the best-performing BERT + GRU as a reference;
- SPAN [26]: A pipelined approach in which one model is used for ATE tasks, and then another model is used for ASC tasks;
- DREGCN [27]: An end-to-end interaction architecture based on multi-task learning relying on syntactic knowledge enhancement, the model uses well-designed dependency-embedding graph convolutional networks to make full use of syntactic knowledge and also designs a simple and effective messaging mechanism to realize multi-task learning;
- DCRAN [18]: A deeply contextualized relationship-aware network that allows implicit interaction between subtasks in a more efficient way and allows two explicit self-supervised strategies for deep context and relationship-aware learning.
4.4. Experimental Results
4.5. Ablation Study
4.6. The Number of Task-Sharing Layers
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Thakur, N. Sentiment Analysis and Text Analysis of the Public Discourse on Twitter about COVID-19 and MPox. Big Data Cogn. Comput. 2023, 7, 116. [Google Scholar] [CrossRef]
- Fellnhofer, K. Positivity and higher alertness levels facilitate discovery: Longitudinal sentiment analysis of emotions on Twitter. Technovation 2023, 122, 102666. [Google Scholar] [CrossRef]
- Truşcǎ, M.M.; Frasincar, F. Survey on aspect detection for aspect-based sentiment analysis. Artif. Intell. Rev. 2023, 56, 3797–3846. [Google Scholar] [CrossRef]
- Hu, M.; Liu, B. Mining and summarizing customer reviews. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 168–177. [Google Scholar]
- Wang, F.; Lan, M.; Wang, W. Towards a One-Stop Solution to Both Aspect Extraction and Sentiment Analysis Tasks with Neural Multi-Task Learning. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Li, X.; Bing, L.; Li, P.; Lam, W. A unified model for opinion target extraction and target sentiment prediction. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33. [Google Scholar]
- Peng, H.; Xu, L.; Bing, L.; Huang, F.; Lu, W.; Si, L. Knowing what, how and why: A near complete solution for aspect-based sentiment analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 7–12 February 2020; Volume 34, pp. 8600–8607. [Google Scholar]
- Chen, Z.; Qian, T. Relation-aware collaborative learning for unified aspect-based sentiment analysis. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Virtual, 5–10 July 2020; pp. 3685–3694. [Google Scholar]
- Mao, Y.; Shen, Y.; Yu, C.; Cai, L. A joint training dual-mrc framework for aspect based sentiment analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 13543–13551. [Google Scholar]
- Yin, Y.; Wei, F.; Dong, L.; Xu, K.; Zhang, M.; Zhou, M. Unsupervised word and dependency path embeddings for aspect term extraction. arXiv 2016, arXiv:1605.07843. [Google Scholar]
- Tang, D.; Qin, B.; Feng, X.; Liu, T. Effective LSTMs for target-dependent sentiment classification. arXiv 2015, arXiv:1512.01100. [Google Scholar]
- Zhang, M.; Zhang, Y.; Vo, D.T. Neural networks for open domain targeted sentiment. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 612–621. [Google Scholar]
- Luo, H.; Li, T.; Liu, B.; Zhang, J. DOER: Dual cross-shared RNN for aspect term-polarity co-extraction. arXiv 2019, arXiv:1906.01794. [Google Scholar]
- He, R.; Lee, W.S.; Ng, H.T.; Dahlmeier, D. An interactive multi-task learning network for end-to-end aspect-based sentiment analysis. arXiv 2019, arXiv:1906.06906. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Li, X.; Bing, L.; Zhang, W.; Lam, W. Exploiting BERT for end-to-end aspect-based sentiment analysis. arXiv 2019, arXiv:1910.00883. [Google Scholar]
- Luo, H.; Ji, L.; Li, T.; Duan, N.; Jiang, D. GRACE: Gradient harmonized and cascaded labeling for aspect-based sentiment analysis. arXiv 2020, arXiv:2009.10557. [Google Scholar]
- Oh, S.; Lee, D.; Whang, T.; Park, I.N.; Seo, G.; Kim, E.; Kim, H. Deep context-and relation-aware learning for aspect-based sentiment analysis. arXiv 2021, arXiv:2106.03806. [Google Scholar]
- Jawahar, G.; Sagot, B.; Seddah, D. What does BERT learn about the structure of language? In Proceedings of the ACL 2019–57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July 2019. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inform. Process. Syst. 2017, 30. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Pontiki, M.; Papageorgiou, H.; Galanis, D.; Androutsopoulos, I.; Pavlopoulos, J.; Manandhar, S. SemEval-2014 Task 4: Aspect Based Sentiment Analysis. SemEval 2014, 27, 2014. [Google Scholar]
- Mitchell, M.; Aguilar, J.; Wilson, T.; Benjamin, V.D. Open domain targeted sentiment. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013. [Google Scholar]
- Liu, L.; Shang, J.; Ren, X.; Xu, F.; Gui, H.; Peng, J.; Han, J. Empower sequence labeling with task-aware neural language model. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LO, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Hu, M.; Peng, Y.; Huang, Z.; Li, D.; Lv, Y. Open-domain targeted sentiment analysis via span-based extraction and classification. arXiv 2019, arXiv:1906.03820. [Google Scholar]
- Liang, Y.; Meng, F.; Zhang, J.; Chen, Y.; Xu, J.; Zhou, J. A dependency syntactic knowledge augmented interactive architecture for end-to-end aspect-based sentiment analysis. Neurocomputing 2021, 454, 291–302. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Christopher, D.M. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Datasets | Train | Dev | Test | |
|---|---|---|---|---|
| Laptop14 | POS | 881 | 104 | 339 |
| NEG | 754 | 106 | 130 | |
| NEU | 406 | 46 | 165 | |
| Restaurant14 | POS | 1956 | 213 | 728 |
| NEG | 735 | 64 | 195 | |
| NEU | 575 | 52 | 197 | |
| POS | 549 | 69 | 73 | |
| NEG | 212 | 24 | 30 | |
| NEU | 1811 | 203 | 233 |
| Model | Laptop14 | Restaurant14 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | ||
| GLOVE | LM-LSTM-CRF | 53.31 | 59.40 | 56.19 | 68.46 | 64.43 | 66.38 | 43.52 | 52.01 | 47.35 |
| E2E-TBSA | 61.27 | 54.89 | 57.90 | 68.64 | 71.01 | 66.60 | 53.08 | 43.56 | 48.01 | |
| IMN | - | - | 57.66 | - | - | 68.32 | - | - | 51.31 | |
| DOER | 61.43 | 59.31 | 60.35 | 80.32 | 66.54 | 72.78 | 55.54 | 47.79 | 51.37 | |
| BERT | BERT-E2E | 61.88 | 60.47 | 61.12 | 72.92 | 76.72 | 74.72 | 57.63 | 54.47 | 55.94 |
| SPAN | 66.19 | 58.68 | 62.21 | 71.22 | 71.91 | 71.57 | 60.92 | 52.24 | 56.21 | |
| DREGCN | - | - | 63.04 | - | - | 72.60 | - | - | - | |
| DCRAN | - | - | 65.18 | - | - | 75.77 | - | - | - | |
| Our method | 67.73 | 63.56 | 65.58 | 76.92 | 77.05 | 76.98 | 62.22 | 60.66 | 61.43 | |
| Model | Laptop14 | Restaurant14 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | |
| Full model | 67.73 | 63.56 | 65.58 | 76.92 | 77.05 | 76.98 | 62.22 | 60.66 | 61.43 |
| w/o ATI | 65.01 | 61.83 | 63.37 | 75.00 | 75.54 | 75.26 | 61.43 | 60.01 | 60.71 |
| w/o MSC | 65.78 | 62.15 | 63.90 | 76.53 | 75.71 | 76.12 | 61.95 | 60.31 | 61.12 |
| l | Laptop14 | Restaurant14 | |
|---|---|---|---|
| 1 | 65.30 | 75.41 | 60.74 |
| 2 | 64.45 | 76.21 | 60.67 |
| 3 | 64.75 | 76.08 | 60.25 |
| 4 | 64.99 | 75.92 | 61.13 |
| 5 | 63.96 | 75.78 | 60.64 |
| 6 | 65.00 | 75.94 | 60.13 |
| 7 | 65.20 | 76.36 | 60.50 |
| 8 | 63.82 | 76.01 | 60.93 |
| 9 | 64.78 | 76.19 | 61.11 |
| 10 | 65.58 | 75.44 | 61.43 |
| 11 | 64.89 | 76.98 | 60.63 |
| 12 | 65.28 | 76.03 | 60.89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, M.; Hua, Q.; Mao, Y.; Wu, J. An Interactive Learning Network That Maintains Sentiment Consistency in End-to-End Aspect-Based Sentiment Analysis. Appl. Sci. 2023, 13, 9327. https://doi.org/10.3390/app13169327
Chen M, Hua Q, Mao Y, Wu J. An Interactive Learning Network That Maintains Sentiment Consistency in End-to-End Aspect-Based Sentiment Analysis. Applied Sciences. 2023; 13(16):9327. https://doi.org/10.3390/app13169327
Chicago/Turabian StyleChen, Musheng, Qingrong Hua, Yaojun Mao, and Junhua Wu. 2023. "An Interactive Learning Network That Maintains Sentiment Consistency in End-to-End Aspect-Based Sentiment Analysis" Applied Sciences 13, no. 16: 9327. https://doi.org/10.3390/app13169327
APA StyleChen, M., Hua, Q., Mao, Y., & Wu, J. (2023). An Interactive Learning Network That Maintains Sentiment Consistency in End-to-End Aspect-Based Sentiment Analysis. Applied Sciences, 13(16), 9327. https://doi.org/10.3390/app13169327