
SJBCD: A Java Code Clone Detection Method Based on Bytecode Using Siamese Neural Network

Abstract
:1. Introduction
1.1. Terminologies
- Bytecode: Bytecode is only available in specific programming languages, such as Java, Scala, Groovy, and Kotlin. It is compiled from source code and is binary code for Java virtual machine. Unless otherwise specified, the bytecode referred to in this paper are all Java bytecode (codes compiled from Java programs).
- Opcode: An opcode is a number that represents an operation of the program on the Java virtual machine. For ease of understanding, Oracle introduced the corresponding mnemonic. For example, the mnemonic corresponding to “0x01” is “aconst_null”, which means that null is loaded to the top of the operand stack. Unless otherwise specified, the opcodes referred to in this document are the mnemonics corresponding. The operand stack is associated with a Java virtual machine.
- Java bytecode instructions (hereinafter referred to as bytecode instructions): A bytecode instruction consists of an opcode and zero or more operands. Some bytecode instructions have no operands.
- Java bytecode instruction sequence (hereinafter referred to as bytecode instruction sequence): It is a sequence composed of bytecode instructions, which are transformed from source code and corresponds to the function of source code one by one.
- Opcode sequence: The operands of a bytecode instruction sequence are removed, and the rest is the opcode sequence.
1.2. Bytecode Features Analysis
- Type-1 clones are detected easily at the bytecode level.
- Type-2 clones are easy to detect if we use the semantic information of opcodes.
- Type-3 and Type-4 clones can be detected by using bytecode.
- Opcode sequences are ordered, so RNNs can be used to extract information from them.
2. Related Works
3. Methodology
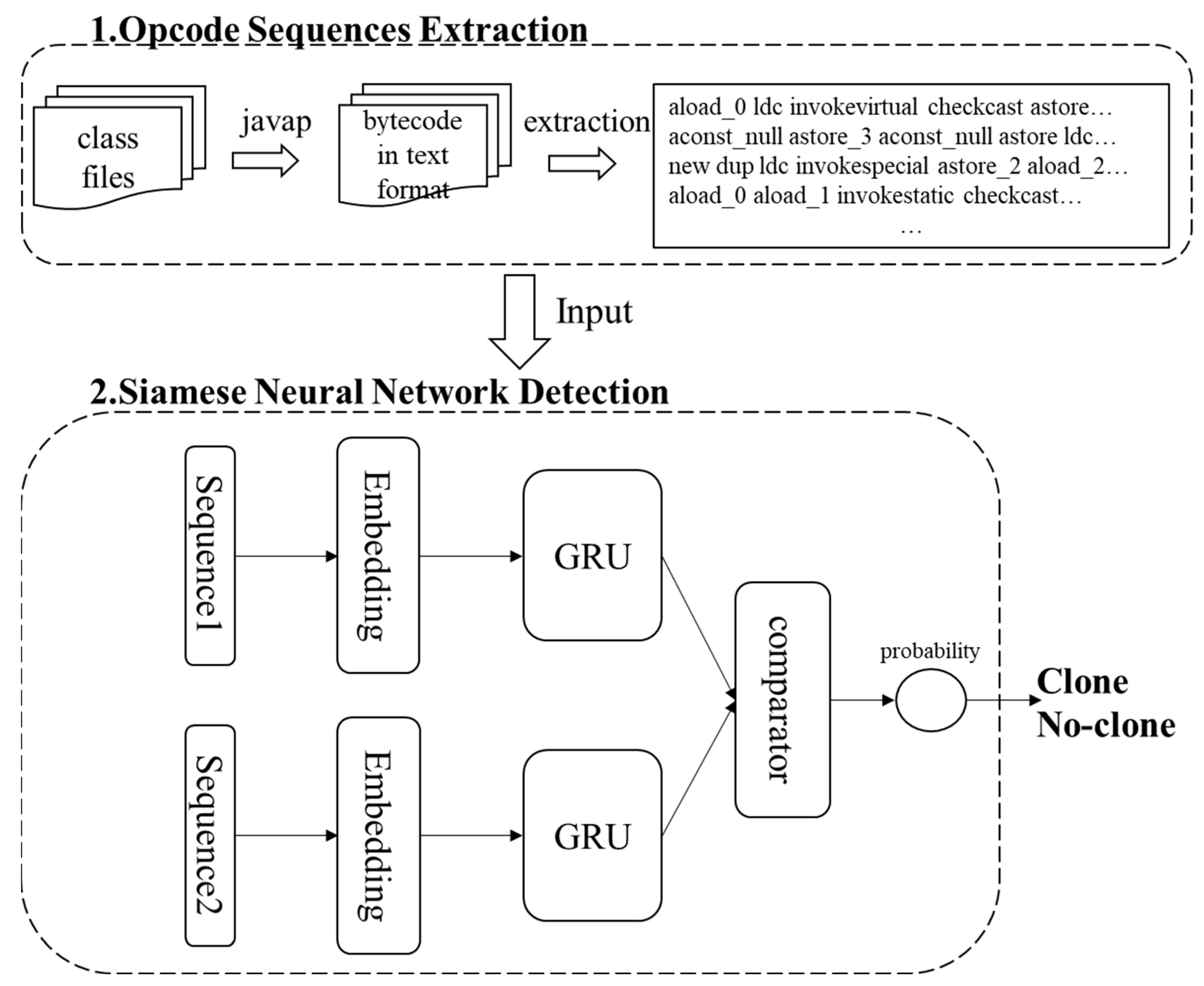
3.1. Extracting Opcode Sequences
| Algorithm 1 Opcode sequences extraction algorithm |
| Input a project that contains some class files. repeat txt file ← exec “javap -verbose -p” class file Read txt file. repeat if line is function signature then sequence.signature ← line repeat opcodes add line. until line not match (“word number” or “word”) sequence.opcodes ← opcodes sequences add sequence. end if until current line is last opcode sequences add sequences. until current class file is last Output opcode sequences. |
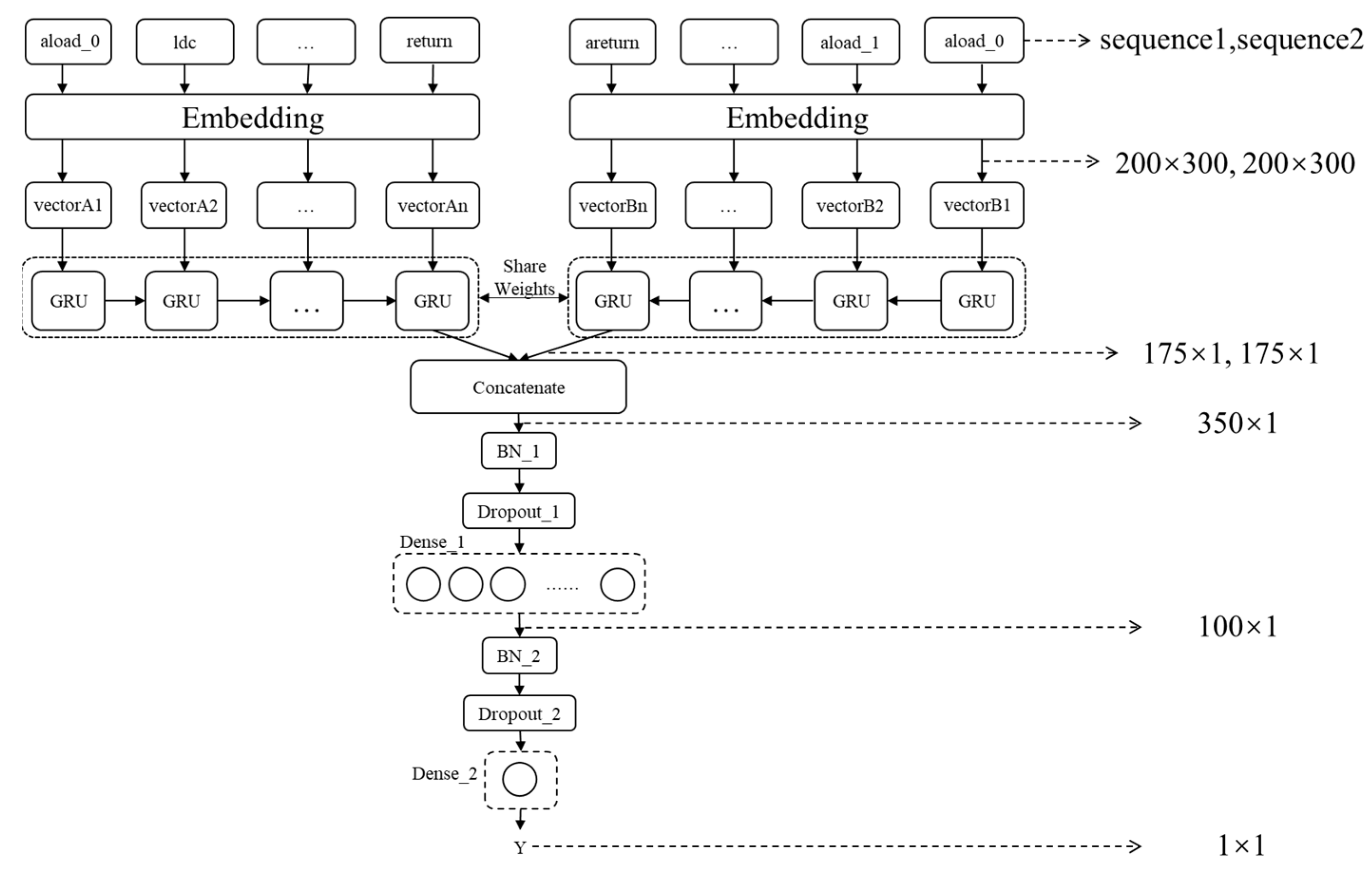
3.2. Building GRU-Based Siamese Neural Network
3.2.1. Generating Opcode Word Vector Model
3.2.2. Building Siamese Neural Network
4. Experiment
4.1. Datasets
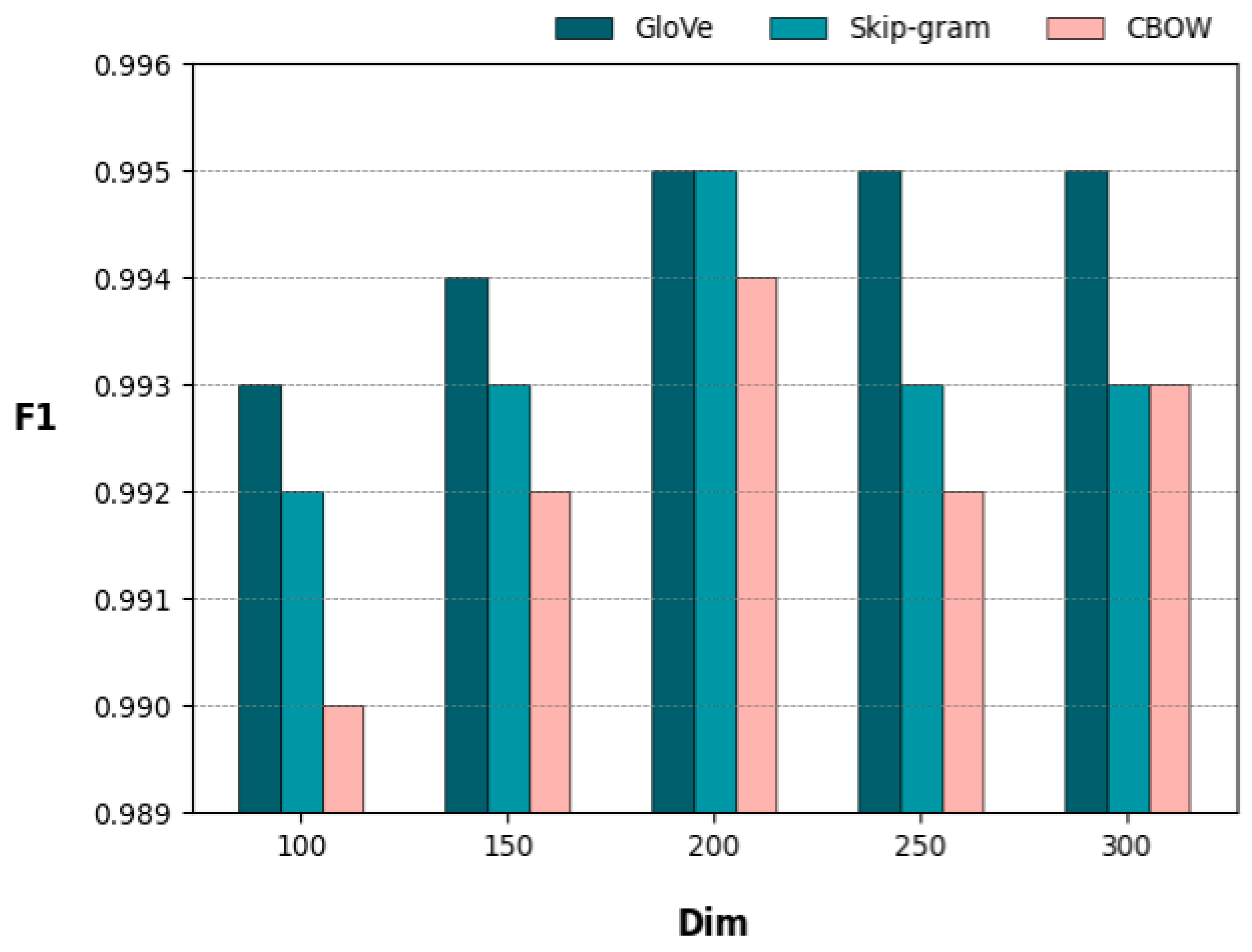
4.2. Word Vector Model Experiment
4.3. Methods Experiment and Results
- The detection effect of NICAD is much weaker than that of SJBCD and TBCCD, and its F1-score is only 0.01.
- The F1-score of SJBCD is 0.994, which is 0.006 higher than FA-AST, which is 0.988.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ain, Q.U.; Butt, W.H.; Anwar, M.W.; Azam, F.; Maqbool, B. A Systematic Review on Code Clone Detection. IEEE Access 2019, 7, 86121–86144. [Google Scholar] [CrossRef]
- Chen, C.F.; Zain, A.M.; Zhou, K.Q. Definition, approaches, and analysis of code duplication detection (2006–2020): A critical review. Neural Comput. Appl. 2022, 34, 20507–20537. [Google Scholar] [CrossRef]
- Dang, Y.; Zhang, D.; Ge, S.; Huang, R.; Chu, C.; Xie, T. Transferring Code-Clone Detection and Analysis to Practice. In Proceedings of the 2017 IEEE/ACM 39th International Conference on Software Engineering: Software Engineering in Practice Track (ICSE-SEIP), Buenos Aires, Argentina, 20–28 May 2017; pp. 53–62. [Google Scholar] [CrossRef]
- Zhang, H.; Sakurai, K. A Survey of Software Clone Detection from Security Perspective. IEEE Access 2021, 9, 48157–48173. [Google Scholar] [CrossRef]
- Bellon, S.; Koschke, R.; Antoniol, G.; Krinke, J.; Merlo, E. Comparison and Evaluation of Clone Detection Tools. IEEE Trans. Softw. Eng. 2007, 33, 577–591. [Google Scholar] [CrossRef]
- Svajlenko, J.; Roy, C.K. Evaluating clone detection tools with BigCloneBench. In Proceedings of the 2015 IEEE International Conference on Software Maintenance and Evolution (ICSME), Bremen, Germany, 29 September–1 October 2015; pp. 131–140. [Google Scholar] [CrossRef]
- Keivanloo, I.; Roy, C.K.; Rilling, J. SeByte: A semantic clone detection tool for intermediate languages. In Proceedings of the 2012 20th IEEE International Conference on Program Comprehension (ICPC), Passau, Germany, 11–13 June 2012; pp. 247–249. [Google Scholar] [CrossRef]
- Yu, D.; Wang, J.; Wu, Q.; Yang, J.; Wang, J.; Yang, W.; Yan, W. Detecting Java Code Clones with Multi-granularities Based on Bytecode. In Proceedings of the 2017 IEEE 41st Annual Computer Software and Applications Conference (COMPSAC), 4–8 July 2017; pp. 317–326. [Google Scholar] [CrossRef]
- Yu, D.; Yang, J.; Chen, X.; Chen, J. Detecting Java Code Clones Based on Bytecode Sequence Alignment. IEEE Access 2019, 7, 22421–22433. [Google Scholar] [CrossRef]
- Lindholm, T.; Yellin, F.; Bracha, G. The Java Virtual Machine Specification; Java SE 8 ed.; Pearson Education Inc.: New York, NY, USA, 2014. [Google Scholar]
- Bromley, J.; Guyon, I.; Lecun, Y.; Sackinger, E.; Shah, R. Signature verification using a “siamese” time delay neural network. Adv. Neural Inf. Process. Syst. 1994, 7, 737–744. [Google Scholar] [CrossRef]
- Svajlenko, J.; Islam, J.F.; Keivanloo, I.; Roy, C.K.; Mia, M.M. Towards a Big Data Curated Benchmark of Inter-project Code Clones. In Proceedings of the 2014 IEEE International Conference on Software Maintenance and Evolution, Victoria, BC, Canada, 28 September–3 October 2014; pp. 476–480. [Google Scholar] [CrossRef]
- Roy, C.K.; Cordy, J.R. NICAD: Accurate Detection of Near-Miss Intentional Clones Using Flexible Pretty-Printing and Code Normalization. In Proceedings of the 2008 16th IEEE International Conference on Program Comprehension, Amsterdam, The Netherlands, 10–13 June 2008; pp. 172–181. [Google Scholar] [CrossRef]
- Ducasse, S.; Rieger, M.; Demeyer, S. A language independent approach for detecting duplicated code. In Proceedings of the IEEE International Conference on Software Maintenance—1999 (ICSM’99), Oxford, UK, 30 August–3 September 1999; pp. 109–118. [Google Scholar] [CrossRef]
- Lee, S.; Jeong, I. SDD: High performance code clone detection system for large scale source code. In Proceedings of the 20th Annual ACM SIGPLAN Conference on Object-Oriented Programming, Systems, Languages, and Applications (OOPSLA ′05), New York, NY, USA, 16–20 October 2005; pp. 140–141. [Google Scholar] [CrossRef]
- Wang, P.; Svajlenko, J.; Wu, Y.; Xu, Y.; Roy, C.K. CCAligner: A Token Based Large-Gap Clone Detector. In Proceedings of the 2018 IEEE/ACM 40th International Conference on Software Engineering (ICSE), Gothenburg, Sweden, 27 May–3 June 2018; pp. 1066–1077. [Google Scholar] [CrossRef]
- Li, L.; Feng, H.; Zhuang, W.; Meng, N.; Ryder, B. CCLearner: A Deep Learning-Based Clone Detection Approach. In Proceedings of the 2017 IEEE International Conference on Software Maintenance and Evolution (ICSME), Shanghai, China, 17–22 September 2017; pp. 249–260. [Google Scholar] [CrossRef]
- Yu, H.; Lam, W.; Chen, L.; Li, G.; Xie, T.; Wang, Q. Neural Detection of Semantic Code Clones Via Tree-Based Convolution. In Proceedings of the IEEE/ACM 27th International Conference on Program Comprehension (ICPC), Montreal, QC, Canada, 25–26 May 2019; pp. 70–80. [Google Scholar] [CrossRef]
- Mehrotra, N.; Agarwal, N.; Gupta, P.; Anand, S.; Lo, D.; Purandare, R. Modeling functional similarity in source code with graph-based Siamese networks. IEEE Trans. Softw. Eng. 2022, 48, 3771–3789. [Google Scholar] [CrossRef]
- Raheja, K.; Rajkumar, T. An Emerging Approach towards Code Clone Detection: Metric Based Approach on Byte Code. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2013, 3. [Google Scholar]
- Lam, P.; Bodden, E.; Lhoták, O.; Hendren, L.J. The Soot framework for Java program analysis: A retrospective. In Proceedings of the Cetus Users and Compiler Infastructure Workshop (CETUS 2011), Galveston Island, TX, USA, 10 October 2011. [Google Scholar]
- Zhang, L.H.; Gui, S.L.; Mu, F.J.; Wang, S. Clone Detection Algorithm for Binary Executable Code with Suffix Tree. Comput. Sci. 2019, 46, 141–147. [Google Scholar] [CrossRef]
- Le, Q.Y.; Liu, J.X.; Sun, X.P.; Zhang, X.P. Survey of Research Progress of Code Clone Detection. Comput. Sci. 2021, 48, 509–522. [Google Scholar] [CrossRef]
- Zhao, G.; Huang, J. DeepSim: Deep learning code functional similarity. In Proceedings of the 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE 2018), New York, NY, USA, 4–9 November 2018; pp. 141–151. [Google Scholar] [CrossRef]
- Xue, Z.P.; Jiang, Z.J.; Huang, C.L.; Xu, R.L.; Huang, X.B.; Hu, L.M. SEED: Semantic Graph Based Deep Detection for Type-4 Clone. In Proceedings of the Reuse and Software Quality: 20th International Conference on Software and Systems Reuse (ICSR 2022), Montpellier, France, 15–17 June 2022; pp. 120–137. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, X.; Zhang, H.; Sun, H.; Wang, K.; Liu, X. A Novel Neural Source Code Representation Based on Abstract Syntax Tree. In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), Montreal, QC, Canada, 25–31 May 2019; pp. 783–794. [Google Scholar] [CrossRef]
- Wang, W.; Li, G.; Ma, B.; Xia, X.; Jin, Z. Detecting Code Clones with Graph Neural Network and Flow-Augmented Abstract Syntax Tree. In Proceedings of the 2020 IEEE 27th International Conference on Software Analysis, Evolution and Reengineering (SANER), London, ON, Canada, 18–21 February 2020; pp. 261–271. [Google Scholar] [CrossRef]
- Zhang, A.; Fang, L.; Ge, C.; Li, P.; Liu, Z. Efficient transformer with code token learner for code clone detection. J. Syst. Softw. 2023, 197, 111557. [Google Scholar] [CrossRef]
- Geoff, W. Plague: Plagiarism Detection Using Program Structure; School of Electrical Engineering and Computer Science, University of New South Wales: Kensington, NSW, Australia, 1988. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar] [CrossRef]
- Wu, Y.; Zou, D.; Dou, S.; Yang, S.; Yang, W.; Cheng, F.; Liang, H.; Jin, H. SCDetector: Software functional clone detection based on semantic tokens analysis. In Proceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering, New York, NY, USA, 21–25 December 2020; pp. 821–833. [Google Scholar] [CrossRef]
- Gupta, P.; Mehrotra, N.; Purandare, R. JCoffee: Using Compiler Feedback to Make Partial Code Snippets Compilable. In Proceedings of the 2020 IEEE International Conference on Software Maintenance and Evolution (ICSME), Adelaide, SA, Australia, 27 September–3 October 2020; pp. 810–813. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.S.; Dean, J. Efficient Estimation of Word Representations in Vector Space. In Proceedings of the International Conference on Learning Representations, Scottsdale, AZ, USA, 2–4 May 2013. [Google Scholar]
- Svajlenko, J.; Roy, C.K. The Mutation and Injection Framework: Evaluating Clone Detection Tools with Mutation Analysis. IEEE Trans. Softw. Eng. 2021, 47, 1060–1087. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Clone Type | T1 | T2 | VST3 | ST3 | MT3 | WT3/T4 |
|---|---|---|---|---|---|---|
| Percent (%) | 0.455 | 0.058 | 0.053 | 0.19 | 1.014 | 98.23 |
| Model | Dimensions | Accuracy | Recall | F1 |
|---|---|---|---|---|
| GloVe | 100 | 0.986 | 1 | 0.993 |
| GloVe | 150 | 0.989 | 1 | 0.994 |
| GloVe | 200 | 0.991 | 1 | 0.995 |
| GloVe | 250 | 0.99 | 1 | 0.995 |
| GloVe | 300 | 0.99 | 1 | 0.995 |
| Skip-gram | 100 | 0.983 | 1 | 0.992 |
| Skip-gram | 150 | 0.986 | 1 | 0.993 |
| Skip-gram | 200 | 0.99 | 1 | 0.995 |
| Skip-gram | 250 | 0.986 | 1 | 0.993 |
| Skip-gram | 300 | 0.986 | 1 | 0.993 |
| CBOW | 100 | 0.981 | 1 | 0.99 |
| CBOW | 150 | 0.985 | 1 | 0.992 |
| CBOW | 200 | 0.989 | 1 | 0.994 |
| CBOW | 250 | 0.985 | 1 | 0.992 |
| CBOW | 300 | 0.987 | 1 | 0.993 |
| Method | Precision | Recall | F1-Score |
|---|---|---|---|
| SJBCD (ours) | 0.991 | 0.997 | 0.994 |
| SJBCD-cos (ours) | 0.993 | 0.995 | 0.994 |
| TBCCD | 0.9 | 0.915 | 0.908 |
| TBCCD+token | 0.98 | 0.953 | 0.966 |
| TBCCD+token-type | 0.976 | 0.964 | 0.97 |
| TBCCD+token+PACE | 0.971 | 0.957 | 0.964 |
| NICAD | 0.636 | 0.005 | 0.01 |
| Code-Token-Learner | 0.984 | 0.933 | 0.958 |
| FA-AST | 0.988 | 0.988 | 0.988 |
| Method | Precision | Recall | F1-Score |
|---|---|---|---|
| TBCCD | 0.78 | 0.73 | 0.76 |
| TBCCD + token | 0.95 | 0.95 | 0.95 |
| TBCCD + token-type | 0.94 | 0.95 | 0.95 |
| TBCCD + token + PACE | 0.94 | 0.96 | 0.95 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wan, B.; Dong, S.; Zhou, J.; Qian, Y. SJBCD: A Java Code Clone Detection Method Based on Bytecode Using Siamese Neural Network. Appl. Sci. 2023, 13, 9580. https://doi.org/10.3390/app13179580
Wan B, Dong S, Zhou J, Qian Y. SJBCD: A Java Code Clone Detection Method Based on Bytecode Using Siamese Neural Network. Applied Sciences. 2023; 13(17):9580. https://doi.org/10.3390/app13179580
Chicago/Turabian StyleWan, Bangrui, Shuang Dong, Jianjun Zhou, and Ying Qian. 2023. "SJBCD: A Java Code Clone Detection Method Based on Bytecode Using Siamese Neural Network" Applied Sciences 13, no. 17: 9580. https://doi.org/10.3390/app13179580
APA StyleWan, B., Dong, S., Zhou, J., & Qian, Y. (2023). SJBCD: A Java Code Clone Detection Method Based on Bytecode Using Siamese Neural Network. Applied Sciences, 13(17), 9580. https://doi.org/10.3390/app13179580