1. Introduction
Power system load forecasting, which encompasses power demand and active power predictions, involves predicting future system loads based on historical data, weather conditions, and the implications of current policies and regulations [
1]. Electricity load forecasting is essential in power planning, transmission, and distribution within the grid sector. Short-term forecasts (less than two weeks) form the foundation for unit start-ups and shutdowns and scheduling and operational plans within the grid. Medium-term forecasts (spanning several months) can guide rational grid operation and maintenance decisions, ensuring consistent electricity supply for businesses and everyday life; these forecasts also offer a valuable foundation for grid operation and scheduling decisions across different industries. Long-term forecasts (looking years ahead) provide data vital for decision making concerning the grid system’s renewal and transformation, aiming to enhance societal benefits. By predicting the electrical load for businesses, large industries, specialized industries, and general industries, one can understand the operational status of each sector, which in turn aids in the resumption and subsequent growth of enterprises.
Forecasting and analyzing the power output of regional power systems allows for accurate electricity supply [
2]. By systematically analyzing electricity consumption forecast data, power supply companies can plan and allocate future electric energy more effectively, enhancing the precision and efficiency of their planning. This approach helps avoid issues like blind, transitional, or insufficient power planning. Moreover, electricity consumption can also serve as an indicator of local economic development. By utilizing electricity forecasting, government departments can obtain valuable insights into economic growth, which can subsequently inform and support the formulation of government economic policies.
Complex factors, such as volatile climate conditions, can introduce uncontrollable effects on power load forecasting, rendering traditional models’ predictions uncertain. As power systems evolve, their structural levels become more diverse, necessitating further research into the challenges of power load forecasting.
1.1. Related Works
Power load forecasting can be categorized into traditional and intelligent methods. Traditional methods typically encompass the elasticity coefficient, consumption unit, catalog, and load density methods [
3]. While these methods are not sufficiently accurate for prediction, some power companies still employ them due to practical considerations. Techniques such as regression analysis and time series analysis are also used for daily forecasting. Further details are provided below.
1.1.1. Traditional Forecasting Methods
Regression analysis involves the establishment of a regression equation to predict the future trend of the dependent variable based on the analysis of both dependent and independent variables. This model is straightforward to construct and offers quick predictions. For instance, in 2021, Gong et al. [
4] introduced a kernel function to the lasso linear regression method, applying it to nonlinear problems to address the regression analysis of non-time series data. Its accuracy improved compared to standard lasso regression, yielding enhanced results. Wang et al. [
5], in their research, introduced a hybrid support vector regression approach. They investigated the coupling and inter-dependency between the model parameters. Moreover, they optimized the hyper-parameters and altered the model’s configuration using nested strategies and state-transformation algorithms. This method was successfully applied to predict medium- and long-term electric loads in a real industry in China. The essence of the regression method is to analyze vast amounts of actual data to understand the relationship between these factors and the electric load. The goal is to use this relationship to predict the future trajectory of the electric load. These influencing factors are straightforward to analyze and understand, and the prediction accuracy is commendably high. However, these influencing factors can change due to environmental shifts, policy alterations, and other uncertainties. These elements introduce a high degree of randomness. If anomalous data are used as the foundation for prediction, they can adversely affect the accuracy of future power load forecasts.
The time series method is an illustrative approach based on historical electricity data. The amount of data required for this method allows for electricity forecasting without the need for an enormous scale. For example, In 2021, Chodakowska. E. et al. [
6] investigated the impact of noise on the inadequate identification of autoregressive integrated moving average (ARIMA) model factors and proposed a series of solutions. They experimented with actual power load samples derived from Poland, evaluating the robustness of ARIMA models to noise in predicting the time series of electric loads. Additionally, they determined the limiting noise level for predictive capability. Time series are ordered sequences of data points over time, and they predict future changes based on past electricity loads. One advantage of this model is its simplicity in understanding and execution. However, if forecasting relies solely on changes in electricity loads, achieving accurate predictions becomes challenging. This is mainly because electricity loads exhibit randomness and seasonality, making the forecast less than ideal.
1.1.2. Intelligent Forecasting Methods
Intelligent forecasting models encompass machine learning and its subfield, deep learning. Machine learning is a field of artificial intelligence, with its central idea being to allow computers to learn patterns and regularities from data, enabling tasks such as prediction, classification, and clustering. Through machine learning, computers can automatically uncover valuable information from vast amounts of data, thereby assisting in decision making, enhancing efficiency, and solving complex problems. Deep learning is a subset of machine learning and represents a significant branch. This contemporary technique builds upon traditional neural networks, offering enhanced classification and prediction accuracy. Intelligent methods are widely acknowledged in academia and industry [
7] and have applications in the electrical fields. For example, Ke et al. [
8] established a prediction model based on the genetic algorithm-backpropagation (GA-BP) neural network. They formed a continuous linear time series for training by incorporating a sliding window and other techniques. This approach mitigated the overfitting problem often seen with more traditional methods and demonstrated that the proposed framework achieved higher forecasting accuracy than conventional methods. Xia et al. [
9] designed a short-term load forecasting method for power systems based on gradient boosting trees. This method preprocesses data by quantifying short-term load-influencing factors using fuzzy probabilities, applies difference decomposition to handle short-term load data, and establishes a robust regression gradient boosting tree in the direction of the negative gradient of the loss function to obtain the load forecasting results. Tasarruf et al. [
10] proposed a hybrid approach utilizing both the Prophet and long short-term memory (LSTM) models. Initially, the Prophet model forecasts the raw load data by leveraging both linear and nonlinear data. However, some nonlinear data remain, which are then trained using the LSTM. Ultimately, the predictive outputs from both the Prophet and LSTM are trained through a backpropagation neural network (BPNN) to further enhance the prediction accuracy. Wu et al. [
11] proposed an attention-based convolutional neural network (CNN) model that combines both LSTM and bidirectional long short-term memory (BiLSTM). By utilizing CNN and the attention mechanism, we extract key factors influencing the load. Subsequently, the LSTM and BiLSTM are employed to forecast future electricity load data. Aguilar Madrid et al. [
12] proposed a set of machine learning (ML) models to enhance the accuracy of electric load forecasting, including multiple linear regression (MLR), k-nearest neighbor regressor (KNN), epsilon support vector regression (SVR), the random forest regressor (RF), and the extreme gradient boosting regressor (XGB). Experiments show that the model constructed using XGB outperforms those built with other algorithms. Lin et al. [
13] employed an attention-based LSTM network model for electric load forecasting. Firstly, they constructed a feature-based attention encoder to compute the correlation between input features at each time step and the electric load. Secondly, they developed a time-based attention decoder to delve into temporal dependencies. Subsequently, the LSTM model integrated these attention outcomes. Finally, the pinball loss function was used to obtain probabilistic forecasts. Veeramsetty et al. [
14] proposed a machine learning model that utilizes gated recurrent units (GRU) and random forest (RF). The GRU is employed for predicting power load, while the RF is used to reduce the input dimensionality of the model. This is the first time that GRU and RF have been jointly applied for short-term load forecasting. Zhang et al. [
15] introduced a predictive model based on the LSTM neural network and the light gradient boosting machine (LightGBM) integrated with variational mode decomposition (VMD). Initially, VMD is employed to decompose features into modal components representing various scales, which reduces the non-stationarity of the original sequence. Concurrently, the decomposed residuals represent the strongly nonlinear parts of the load data. By leveraging powerful algorithms, these features are predicted. Each modal component is forecasted using single-feature prediction through LSTM. Subsequently, all components are incorporated as multi-features into LightGBM for load forecasting. Fang et al. [
16] introduced a multifrequency composite electric load forecasting model that blends CNN, GRU, and multiple linear regression (MLR). Initially, the time series load data undergo ensemble empirical mode decomposition (EEMD), reconstructing it into high and low frequencies. Notably, significant meteorological factors are incorporated within the high-frequency domain, which is then predicted using the CNN-GRU model. In contrast, the low-frequency section employs multiple linear regression for forecasting. Ultimately, predictions derived from each model are superimposed, yielding the final forecasting outcome. Li et al. [
17] established a combined framework based on LSTM and XGBoost, using the inverse error method to combine both results. Wang et al. [
18] developed a time series model that combines a convolutional neural network with adaptive learning named ConvAdaRNN. This model first employs a CNN to extract relevant influencing factors of the electrical load. It then segments the dataset using its temporal characteristics based on the minor correlation in the time series. The AdaRNN model is utilized for the final prediction, and as a result, ConvAdaRNN achieves better prediction accuracy.
3. Results
The proposed CNN-BiLSTM-RF model and DCC-EL framework experiments are trained and tested on Centos 7 operating system with Intel(R) Xeon(R) Gold 6154 CPU, 128G RAM, NVIDIA TITAN V GPU and 24 G video memory, and the programming language is Python.
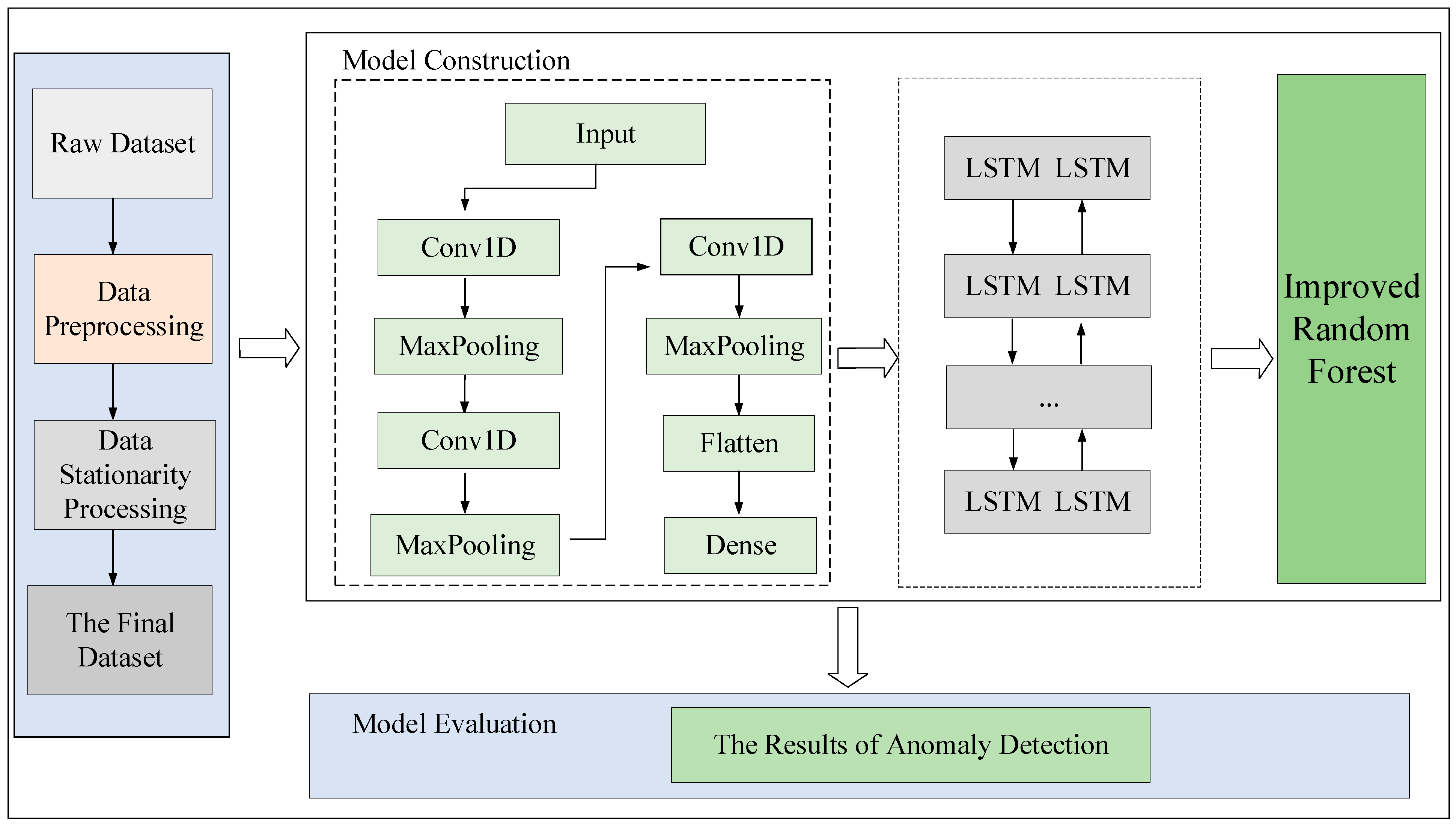
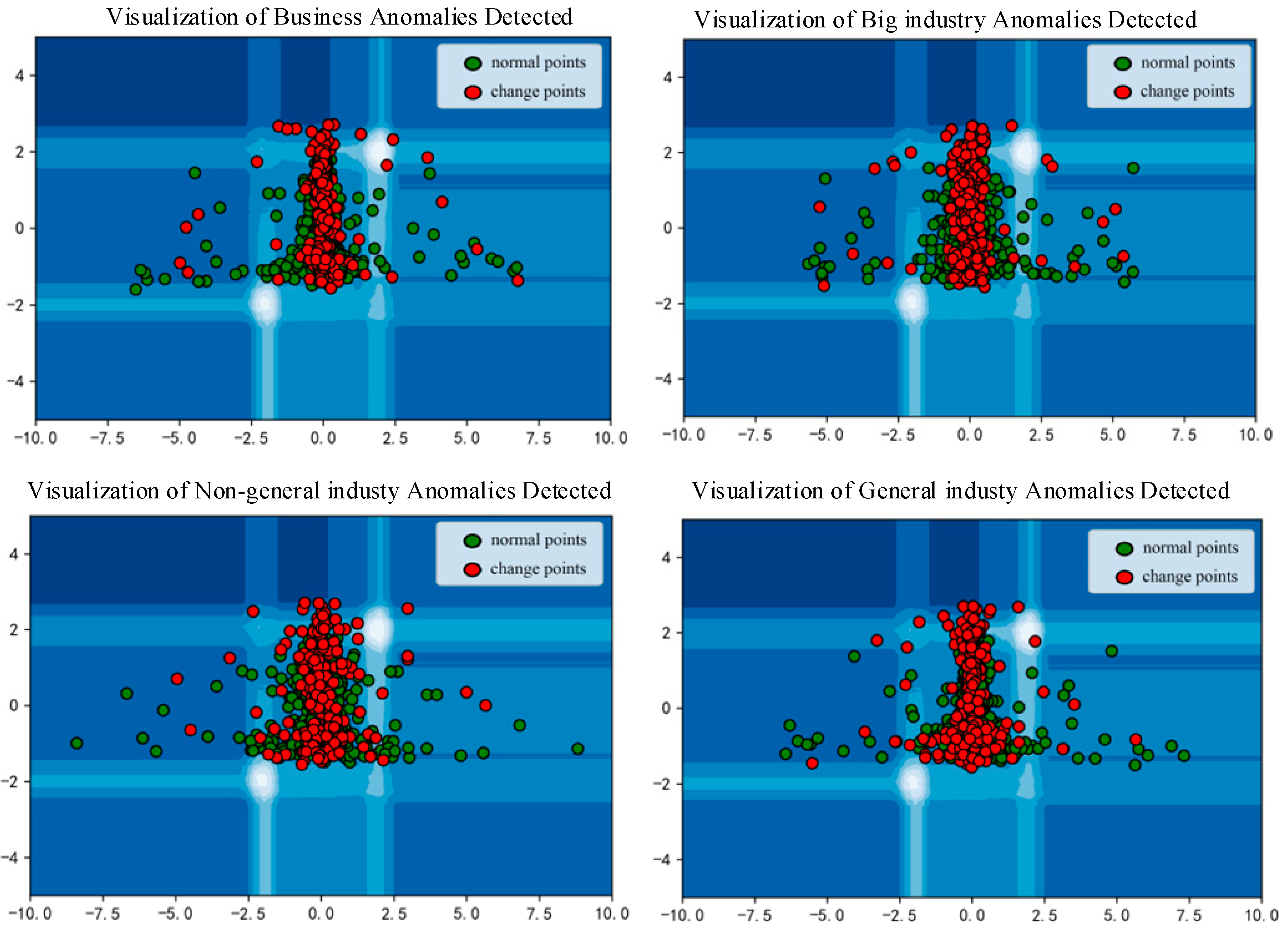
We first conducted anomaly detection on the data to prioritize essential features during the initial training. Using the CNN-BiLSTM-RF model, we detected anomalies across four major industries: commercial, large industrial, non-general industrial, and general industrial. The parameter settings for the CNN-BiLSTM-RF model are detailed in
Table 1. We then applied the 3Sigma rule, identifying data points that deviated by more than three times the historical data standard deviation as abnormal. Finally, we pinpointed change points by intersecting results from the two methods, as illustrated in
Figure 5. This visualization depicts the anomalies detected across the four major industries, further detailed in
Figure 6.
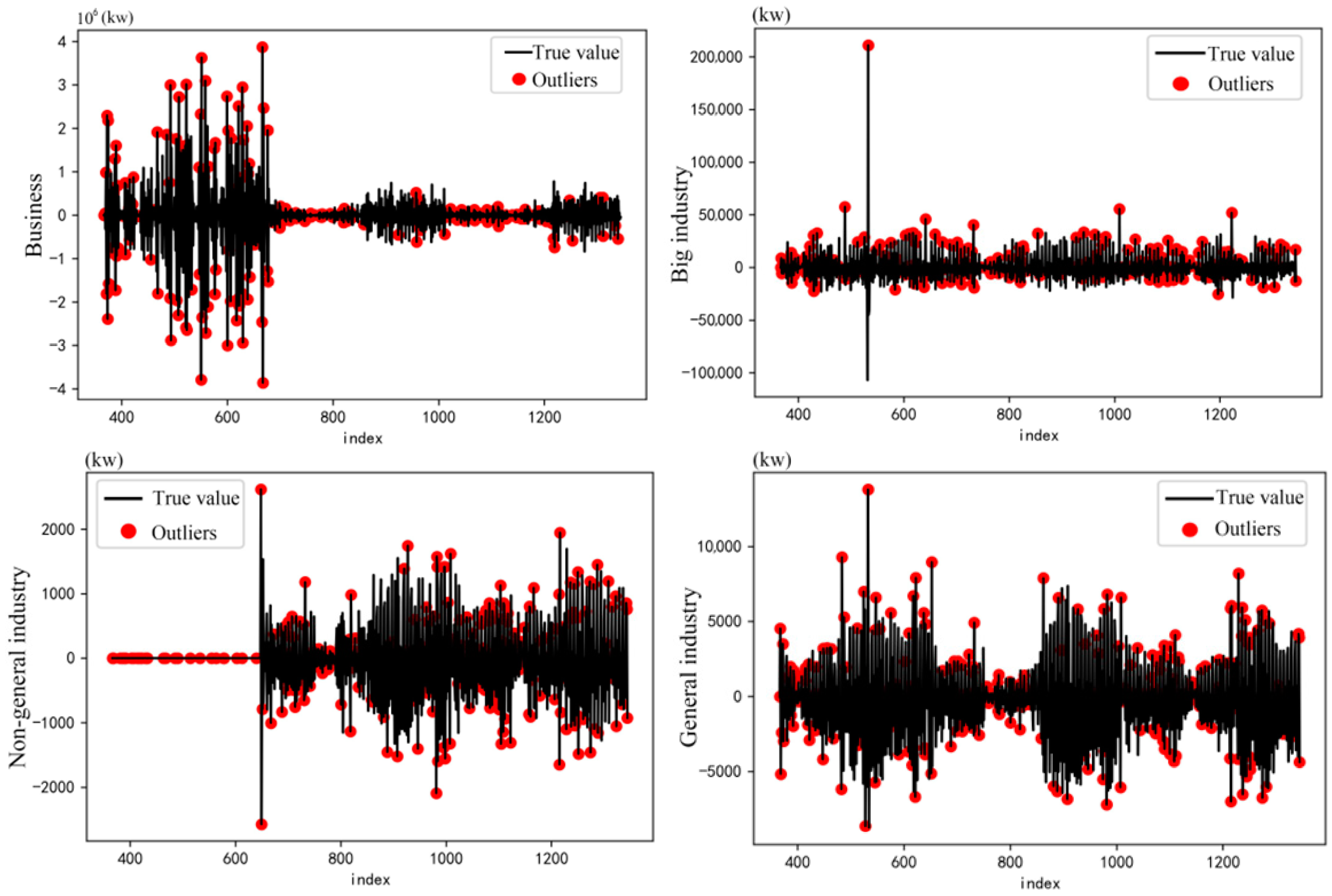
The change points represent the difference between the current change points and the load from the previous moment. These change points and their amplitudes are indicated in the series of daily maximum loads, as depicted in
Figure 5, where the red points denote the identified change points. Based on the data in
Figure 6, one can observe that within the series of daily maximum loads, the business sector exhibits the largest change amplitude at 4 × 10
6. In contrast, the industrial non-ordinary industry has the smallest amplitude, registering only at 2 × 10
3.
We use weather changes as the explanatory variable, denoting ‘unchanged’ as 0 and ‘changed’ as 1. Logistic regression (LR) is a regression method that employs maximum likelihood estimation to address problems wherein the explanatory variable is categorical:
Table 2 displays logistic regression results for the change-driving factors of key indicators across four primary industrial categories: business, big industry, non-general industry, and general industry. The first row represents the regression coefficient for each feature indicator, while the second row shows the standard error value.
From the logistic regression results presented in
Table 2 for the panel data, it is evident that the factors influencing sudden load changes differ across industries. Start_weather has the most significant influence in the business sector, whereas in the big industry sector, end_weather plays a more crucial role. The minimum temperature predominantly influences both the non-general and general industries.
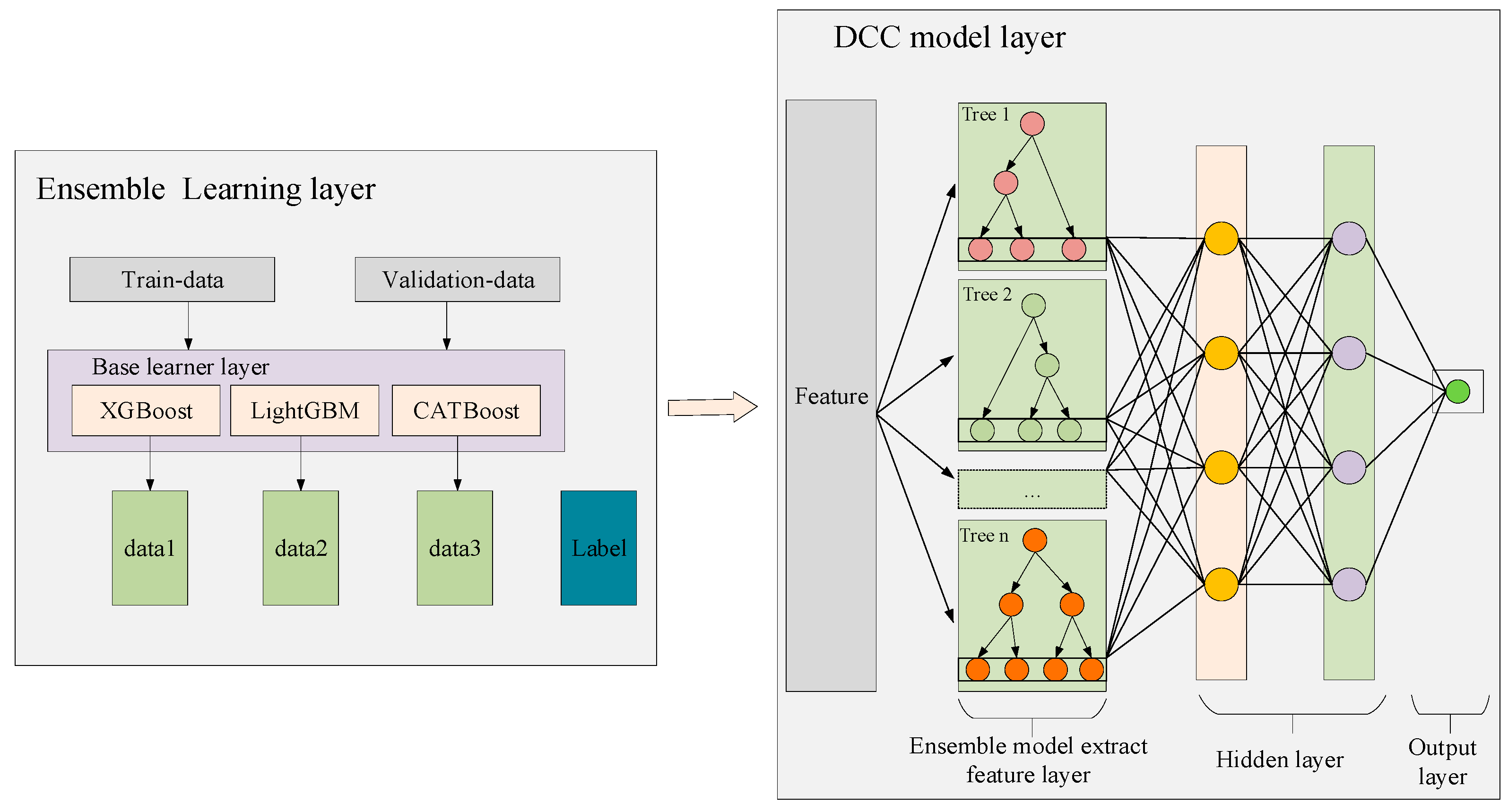
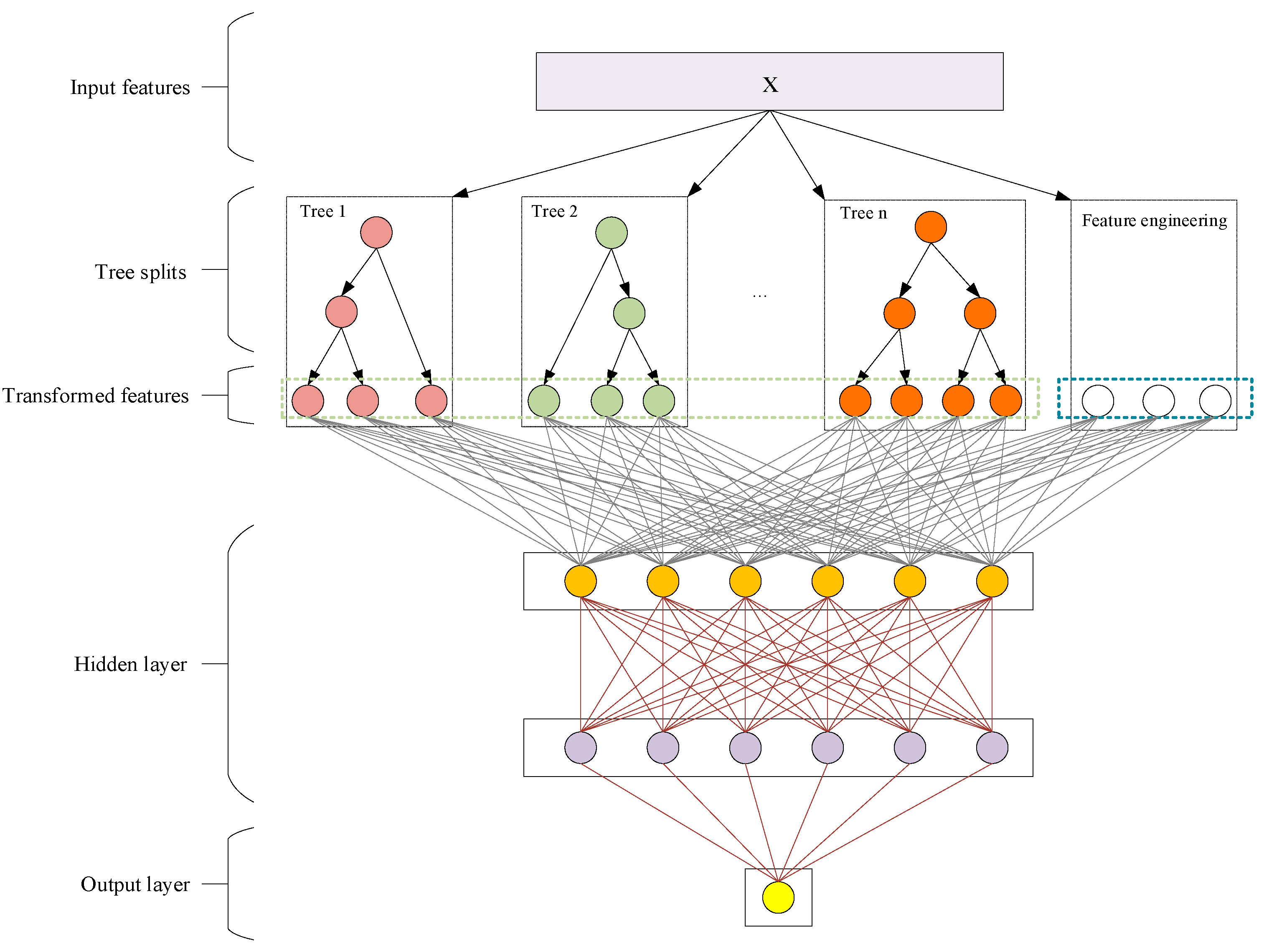
Upon ranking the features based on their significance, those of greater importance are assigned higher weights, while those of lesser significance receive lower weights. These features and their designated weights are subsequently inputted into the DCC-EL model to predict future power load values. The DCC-EL model incorporates these feature weights during its prediction process.
Table 3 details the parameter settings for the DCC-EL model.
The proposed DCC-EL model’s prediction results are compared to existing integrated learning methods. The performance of the model predictions is measured using error metrics, including mean square error (MSE), root mean square error (RMSE), mean absolute error (MAE), and mean fundamental percentage error (MAPE). The calculation methods for these four evaluation metrics are provided in Equations (38)–(41):
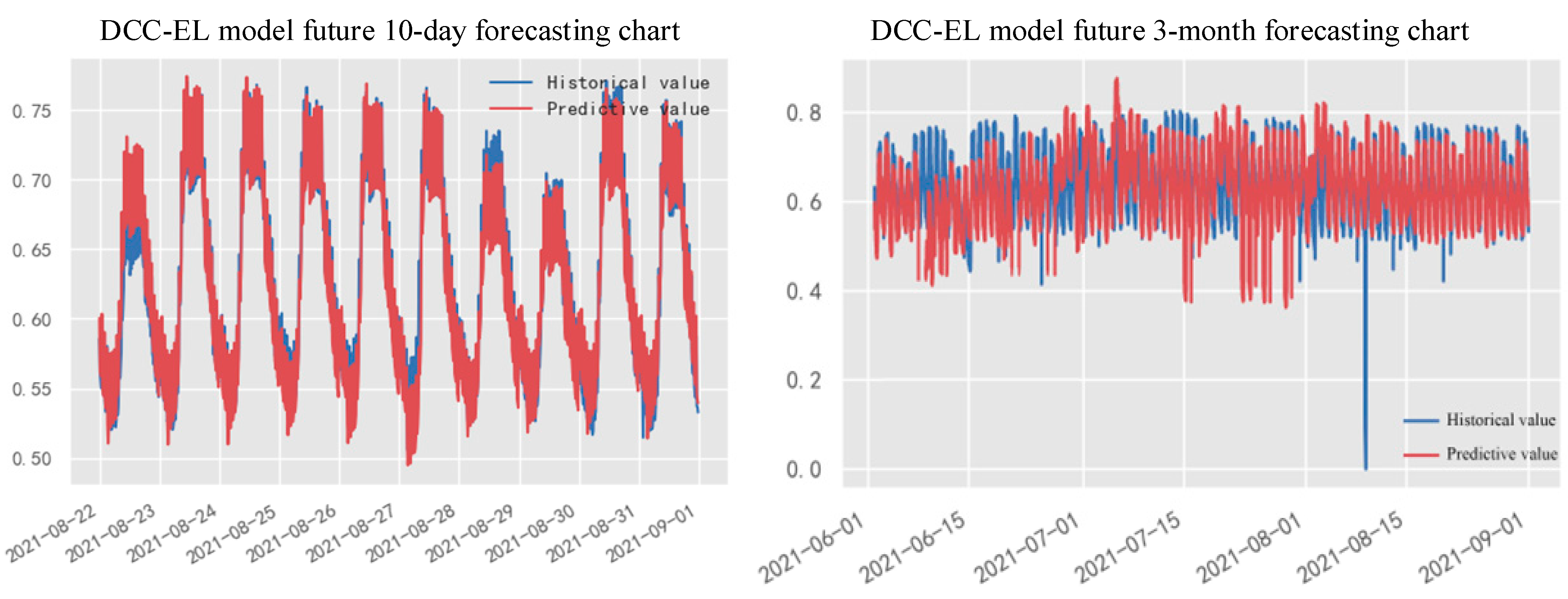
The normalized power load data were input into the DCC-EL framework for prediction, and the experimental results are illustrated in
Figure 7. These charts display the power load prediction results for time intervals of ten days and three months, respectively. The horizontal axis indicates dates, while the vertical axis represents the normalized power load data. The red line depicts the predicted values derived from the DCC-EL framework, and the blue line showcases the actual power load values. For the ten-day prediction, the visual representation of the predicted values aligns closely with the actual values. However, in the three-month forecast, some variances are noticeable between the predicted and actual values. This discrepancy arises from the time sensitivity of the DCC-EL framework in mid-term load forecasting, which occasionally results in instability. Therefore, it necessitates periodic model adjustments to accommodate data fluctuations.
Table 4 and
Table 5 present the error measurements for power load predictions across six models compared to our proposed framework for time intervals of ten days and three months, respectively. Notably, the DCC model represents the dilated causal convolutional model that has not undergone feature extraction or secondary integration by the ensemble model, explicitly used for ablation studies. The other five models, referenced in the related work section of this paper, serve as benchmarks for our control experiments.
Table 4 illustrates that the proposed method reduced RMSE by 4.96% and MAPE by 17.33% compared to the best results of the five models mentioned in the introduction.
Table 5 illustrates that the proposed method realized a 12.31% reduction in MSE for three-month interval predictions, and the power load predictions using the DCC-EL framework generally outperform the five models.
The analysis of the control experiment results is as follows:
(1) Compared with Tasarruf’s model [
10] in a control experiment, the DCC-EL model proposed in this study reduced the RMSE and MSE for predicting power loads over ten days and three months by 6.06% and 17.97%, respectively. The discrepancy in the experimental results might arise from the process of model integration, especially transitioning from Prophet to LSTM and then to BPNN. The handling and transformation of data during these stages could lead to loss or distortion of information. Such a loss can stem from various factors. For instance, each model may interpret data differently and assign varying weights to them. Minor inconsistencies might also emerge during the data conversion process between models. More critically, for such a model setup, if the outputs from the different models are not appropriately amalgamated or aligned, it could adversely impact the final prediction, especially when significant differences exist between these outputs.
(2) Compared with Wu’s model [
11] in a control experiment, the DCC-EL model reduced the RMSE and MSE for predicting power loads over ten days and three months by 7.16% and 23.66%, respectively. The reason for the discrepancies in the experimental results may be that the combination of multiple models makes the debugging of the model more complicated. When there are issues with the model or its predictive performance is unsatisfactory, it is challenging to determine which part is problematic, increasing the difficulty of debugging. The complex relationships between the various models might also result in the model performing well on the training data but poorly on unseen data. Hence, this combination of models might elevate the risk of overfitting.
(3) Compared with Veeramsetty’s model [
14] in a control experiment, the DCC-EL model reduced the RMSE and MSE for predicting power loads over ten days and three months by 7.83% and 25.35%, respectively. The reasons for the discrepancies in the experimental results may be that while RF can assign importance to features, if the GRU relies heavily on certain features, simply reducing dimensions using RF might result in the loss of crucial information. Additionally, with new data, while random forest might adapt quickly, the GRU might require retraining, potentially leading to challenges in updating the model.
(4) Compared with Zhang’s model [
15] in a control experiment, the DCC-EL model reduced the RMSE and MSE for predicting power loads over ten days and three months by 5.42% and 15.69%, respectively. The reasons for the discrepancies in the experimental results may be as follows: first, the data may need appropriate preprocessing to fit the input requirements of VMD, LSTM, and LightGBM, which could complicate implementation. Similarly, the outputs might require proper post-processing for integration and interpretation. Moreover, using VMD for feature decomposition could introduce additional uncertainties, and the model’s stability might be affected by various model integration methods.
(5) Compared with Fang’s model [
16] in a control experiment, the DCC-EL model reduced the RMSE and MSE for predicting power loads over ten days and three months by 4.96% and 12.31%, respectively. The reasons for the discrepancies in the experimental results may be: Firstly, ensemble empirical mode decomposition requires appropriate parameter settings and technical expertise for the comparison model. Otherwise, it may lead to inaccurate decomposition of high and low frequencies. Secondly, the low-frequency part might encompass nonlinear changes caused by long-term trends, periodicity, seasonality, or other intricate factors. Employing multivariate linear regression might fall short of capturing such nonlinear relationships or more complicated patterns. If these nonlinear relationships or patterns are crucial in the low-frequency section, relying solely on multivariate linear regression could result in predictive errors.
(6) The ablation experiment for DCC in the DCC-EL model showed that the performance of the DCC-EL model is far superior to that of the DCC model. This is because the DCC-EL model adopts an ensemble learning strategy, combining multiple base learners, allowing it to better integrate the characteristics and advantages of different models. This enables DCC-EL to learn a richer feature representation and better capture the complex relationships in the data, thereby improving predictive performance. Furthermore, during the prediction process, the DCC-EL model considers the weight of features, assigning weights to them based on their importance, making the model pay more attention to features that significantly impact the prediction results. This helps reduce the interference of unimportant features on prediction, enhancing the model’s stability and accuracy.
When using the proposed DCC-EL framework for power load prediction, the results surpassed those of the other six models across nearly all four evaluation metrics (MSE, RMSE, MAE, and MAPE), underscoring the efficacy of the DCC-EL framework.
4. Conclusions and Future Work
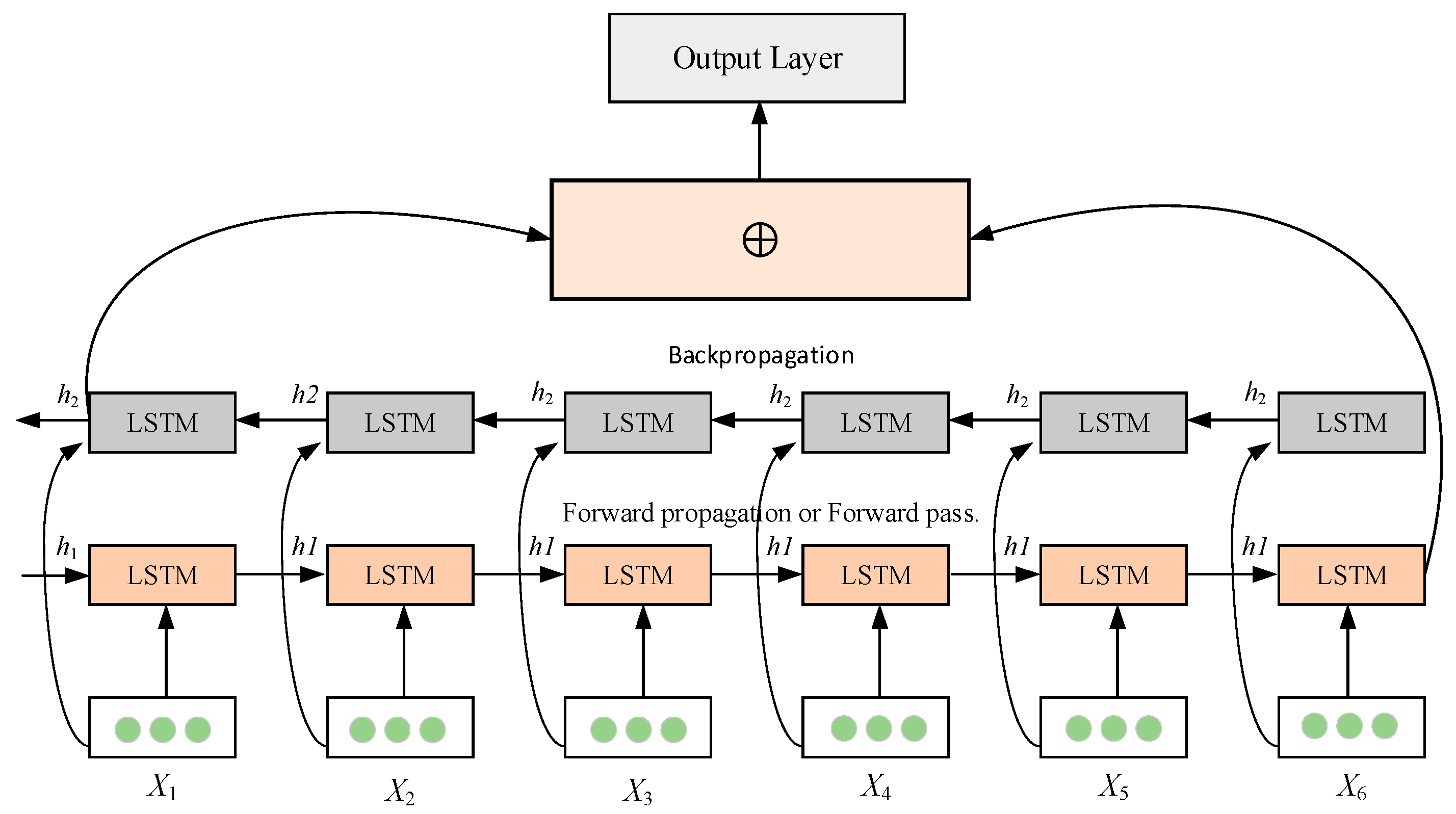
In summary, this paper introduces an innovative hybrid framework, namely CNN-BiLSTM-RF and DCC-EL, for anomaly detection in electricity load and short-to-mid-term electricity load forecasting. The proposed framework integrates the advantages of deep learning and ensemble learning. It employs CNN for feature extraction, BiLSTM to capture temporal dependencies, and improved RF for classification during the anomaly detection phase. Subsequently, the DCC-EL model is utilized to forecast future electricity load values, leveraging features extracted by the ensemble learning model.
Experimental results indicate that compared to existing models, its RMSE and MSE in short-term and mid-term electricity load forecasting are reduced by 4.96% and 12.31%. This demonstrates that our model can more accurately capture and predict the complex patterns within electricity load data, providing a reliable foundation for energy management and grid planning.
However, like any model, ours also has limitations and potential areas for improvement. Future work will focus on applying this framework to more intricate electricity load-forecasting scenarios, exploring its robustness, and enhancing prediction accuracy by integrating more advanced technologies. We also anticipate developing strategies that allow our model to adapt to data changes over time, further improving its forecasting performance.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}