1. Introduction
Advances in deep convolution neural networks (DCNNs) in the field of object recognition have surpassed human-level performance [
1,
2]. The effective functioning of DCNNs can be attributed mainly to their structures, comprising a series of convolutional layers and fully connected layers. Each layer contains numerous units equipped with diverse filters (referred to as neurons in DCNNs), mirroring the hierarchical arrangement seen in the visual stream’s ventral layers of primates [
3]. By employing this hierarchical design and utilizing supervised learning on an extensive set of object examples, DCNNs are anticipated to form intricate internal representations of external objects.
While DCNN models exhibit normal behavior on benign examples through the training process, they have a fatal disadvantage in that their performance is degraded by adversarial attacks. Adversarial examples, which are instances characterized by a small, virtually imperceptible perturbation, can cause DCNN models to make mistakes [
4,
5]. To human eyes, adversarial examples seem identical to the original and do not affect the perception of an object.
To DCNNs, however, they work almost as an optical illusion, causing them to misclassify data and make false predictions [
6]. It is interesting to note that only DCNN models that mimic the primate visual system are sensitive to adversarial attacks [
7]. Adversarial attacks reveal a serious vulnerability in deep learning systems and pose a safety challenge that cannot be ignored in AI applications [
8].
However, current research cannot find a clear cause of how adversarial attacks affect deep learning systems, and only individual defense mechanisms against specific adversarial attacks have been proposed [
9,
10,
11,
12]. Analyzing the fundamental cause of adversarial attacks can help researchers to effectively overcome the vulnerability of the DCNNs. The vulnerability of DCNNs to adversarial attacks has led to a variety of opinions. While Goodfellow et al. [
4] discovered that the effectiveness against such attacks did not show significant improvement, other researchers [
5] put forth the hypothesis that the extreme non-linearity of DCNNs is responsible for adversarial attacks.
Conversely, even in high-dimensional linear models, adversarial attacks can confidently create successful perturbations in inputs [
13]. Goodfellow et al. [
4] attributed the origin of adversarial attacks to the linear characteristics exhibited in high-dimensional space. Consequently, we know very little about the process of finding the right answer within DCNNs for even benign examples. Nor do we know what happens internally when adversarial examples are applied to DCNN models [
13,
14,
15].
Recently, an interesting study has been published related to neuronal activity in DCNNs [
16]. This study demonstrated the distribution of active neurons in layers using PSI in the normal operation of DCNNs due to benign examples. PSI is a measure that allows for the representation of the sparsity of neuron activation by observing the activation status of a given neuron in the cerebral cortex when it is stimulated [
17]. If we consider the nodes of each layer that constitute the DCNN model as neurons, measuring the PSI in each layer allows us to infer the internal dynamics of the models [
18].
In their experiments, the distribution of PSI values for the object categories in each layer of the AlexNet and VGG11 models was analyzed, and the sparseness of neuronal activities was assessed by the PSI for the object categories of the ImageNet and Catlec256 datasets on a per-layer basis, separately. While their research made a significant contribution by employing the PSI to analyze the internal dynamics of DCNN models, their experiments were limited to cases where models function correctly on datasets composed of benign examples. Separately, our focus lies in analyzing the internal behavior of DCNN models when exposed to abnormal examples, specifically adversarial examples.
Our main idea is that there will be distinct changes in the PSI analysis compared to when benign examples are applied, when the internal dynamics of DCNN models behave differently for adversarial examples. The hypothesis within our main idea implies that the neurons in each layer of DCNN models operate abnormally when subjected to adversarial examples. To test our hypothesis, we applied the same DCNN models as in the study by [
16], with the exception that we used adversarial examples instead of benign examples.
We employed three different adversarial attacks to generate adversarial examples for the experiments: FGSM attack, PGD attack, and CW attack [
19]. In our experiment, we analyzed the distribution of the PSI at each layer in DCNNs for adversarial examples. Also, we compared the experimental results in [
16] with our findings on the changes in the PSI according to the adversarial examples. In particular, we systematically assessed the layer-by-layer sparsity in the featured objects. Subsequently, we delineated the operational aspects of sparsity by investigating how sparsity correlates with performance at each layer. Lastly, we scrutinized the factors influencing the encoding scheme.
This paper is organized as follows:
Section 2 is divided into four subsections related to the experimental setup.
Section 2.1 provides descriptions of the visual image datasets used in the experiments, namely the ImageNet dataset and the Caltech256 dataset.
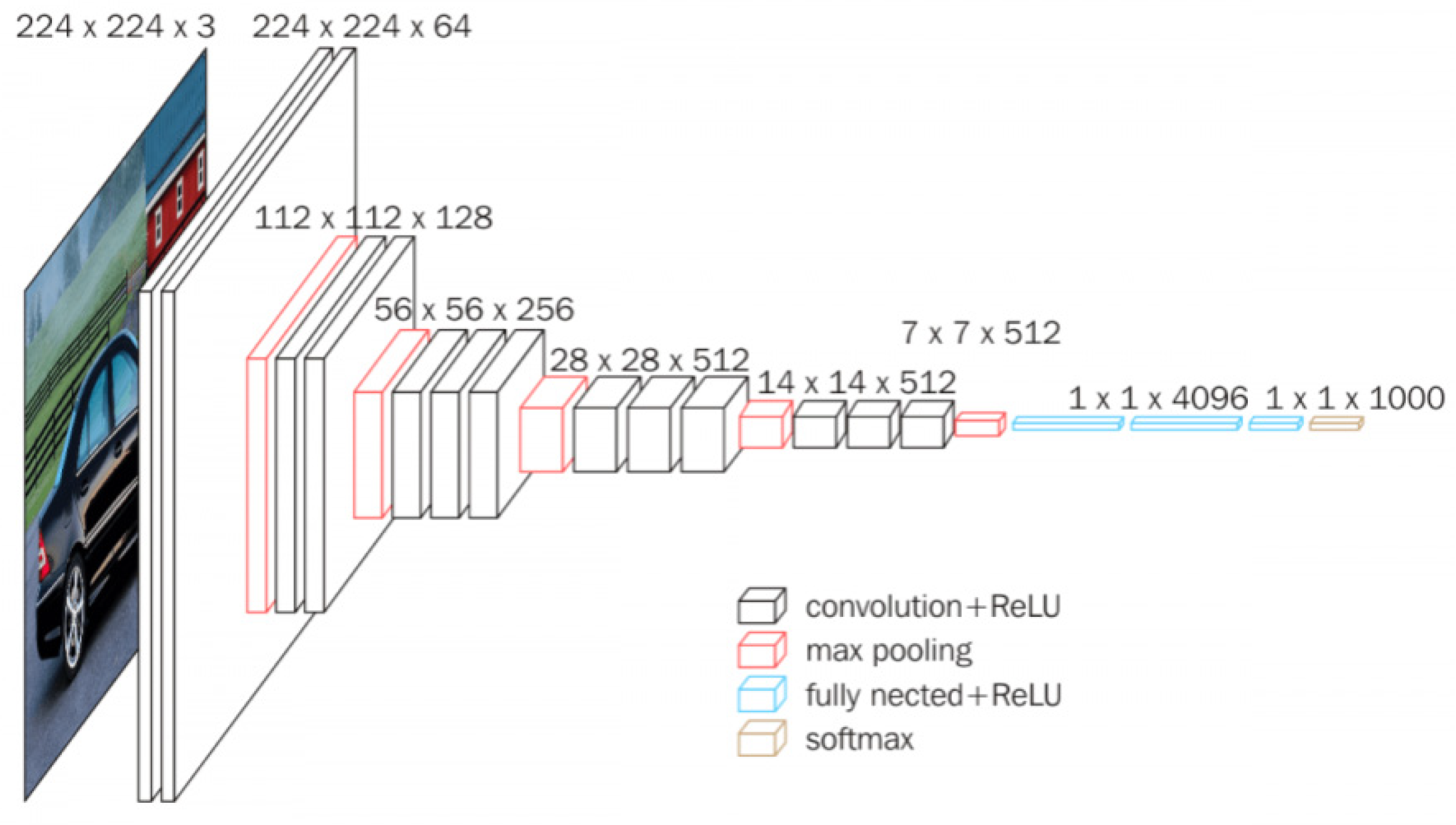
Section 2.2 explains the architectures of the two DCNN models utilized in the experiments, namely the AlexNet and VGG11 models. In
Section 2.3, we elucidate the formulation and significance of the PSI, a method employed to interpret the internal structure of DCNN models.
Section 2.4 describes the attack techniques used to generate the three types of adversarial examples employed in the experiments. In
Section 3, we conduct PSI analysis on the two DCNN models on a per-layer basis and analyze the implications of the findings. Lastly, we conclude the study, outline its limitations, and propose future research directions in
Section 4.
3. Experimental Results
To clarify the relationship between adversarial examples and the PSI, we analyzed the research contents related to the sparseness coding scheme studied by Xingyu Liu et al. [
16]. They presented significant insight regarding the PSI through the utilization of pre-trained AlexNet and VGG11 models on both the ImageNet and Caltech256 datasets. Their examination of the PSI values within the context of the ImageNet validation dataset revealed consistently modest values across all layers for every object category (median < 0.4), with the highest values not surpassing 0.6 in their conducted experiments. This observation suggests the widespread adoption of a sparse coding approach throughout all layers of the DCNNs for the purpose of object representation.
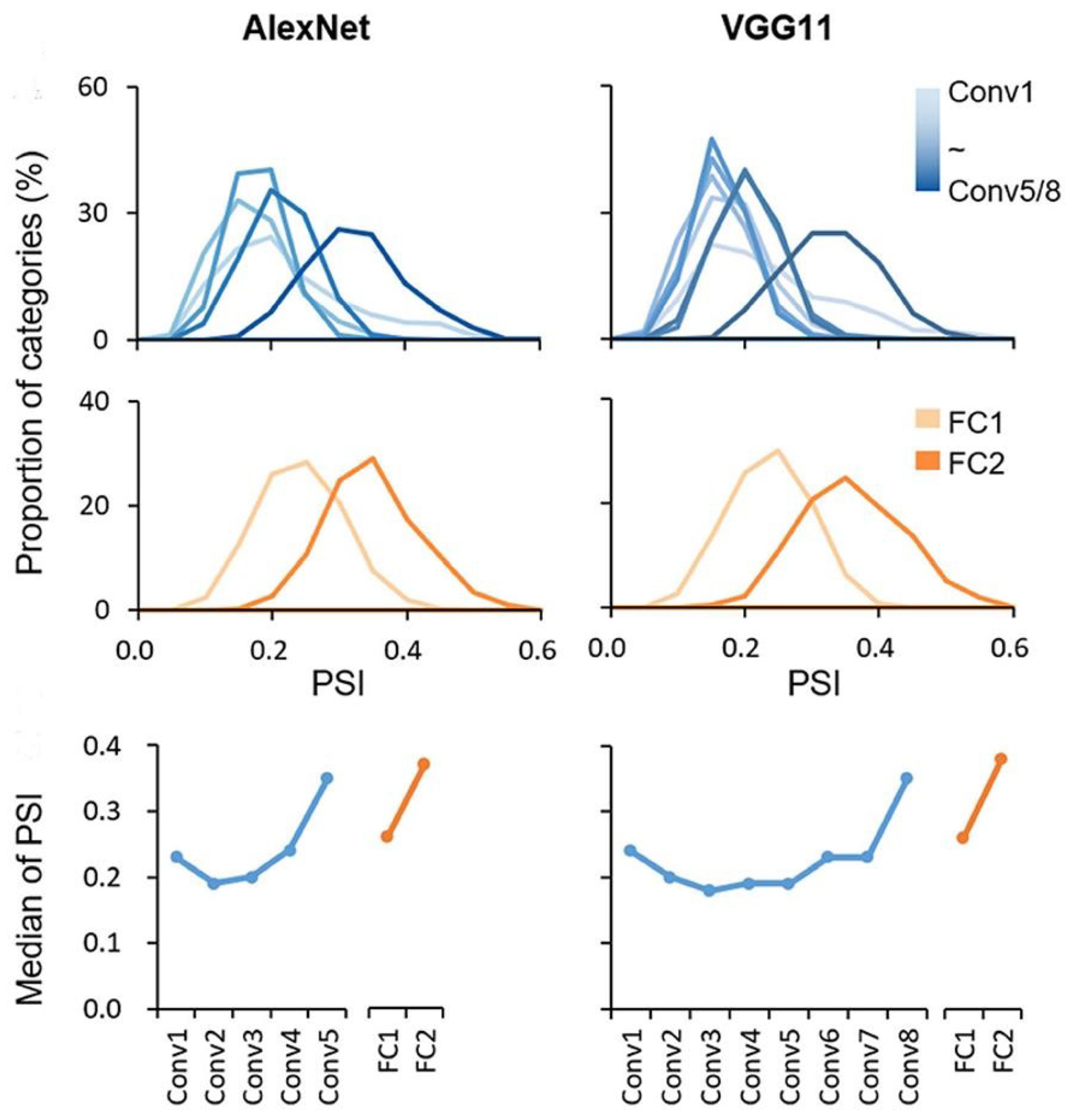
Figure 3 illustrates the experimental findings depicting variations in the PSI values based on the layer, as depicted in [
16].
Another noteworthy finding surfaced as the distributions of PSI for all categories exhibited considerable breadth (range > 0.2) across each layer, indicating pronounced variations in sparsity across distinct object categories. Notably, it was observed that the median PSI values displayed an inclination to rise progressively along the hierarchy, both in the convolutional and fully connected layers, respectively. The median PSI trajectory, however, was not strictly monotonic, with the initial layer showing slightly higher PSI than its immediate neighbors. Interestingly, despite the dissimilar number of convolutional layers between AlexNet and VGG11, a marked elevation in the median PSI was evident in the last two layers.
To investigate the relationship between adversarial examples and the PSI, we generated adversarial examples through FGSM attack on the ImageNet validation dataset. Then, the adversarial examples by FGSM attack were applied to pre-trained AlexNet and VGG11 models.
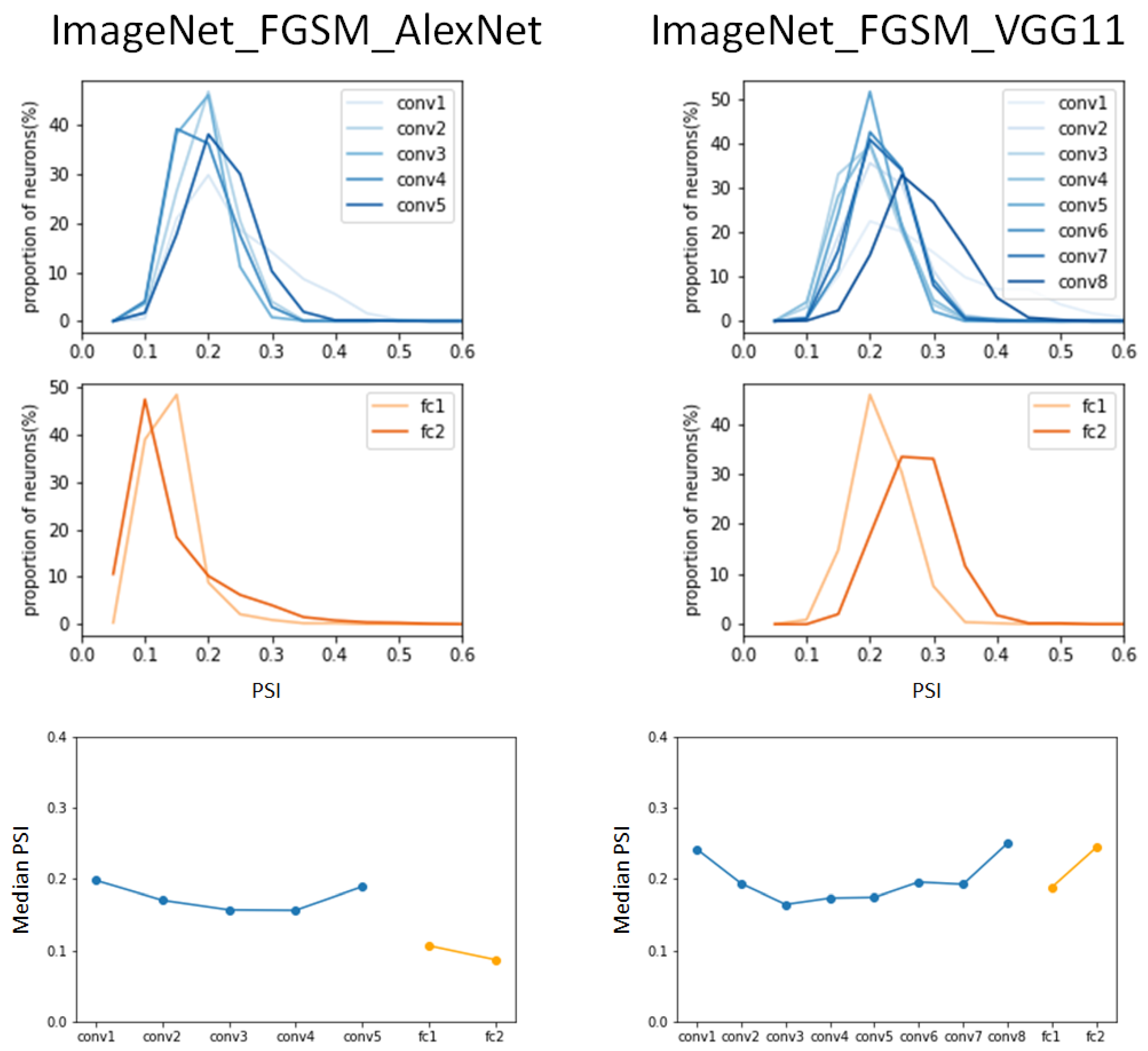
Figure 4 shows the hierarchical sparse coding for object categories by FGSM-attacked adversarial examples in AlexNet and VGG11.
It was commonly observed in AlexNet and VGG11 that the median of the PSI in the FGSM-attacked ImageNet dataset was in a lower range (median < 2.5) than the values in the benign ImageNet dataset. In the experimental results in [
16], the median of the PSI in AlexNet gradually increased after convolutional layer 2, but in the case of FGSM attack, it continuously decreased until convolutional layer 4, and then increased in the last convolutional layer. In the fully connected layer, the value of the median of the PSI rather decreased, which is opposite to the result in [
16].
In comparison to the normal validation ImageNet dataset in
Figure 3, despite the increase in the number of layers in AlexNet, the graph hardly shifted to the right; rather, a left shift was observed in the fully connected layer. From the overall observation, the change in the PSI due to FGSM attack shows that the value of the median of the PSI was lower compared to the normal case, and a right shift of the graph rarely occurred.
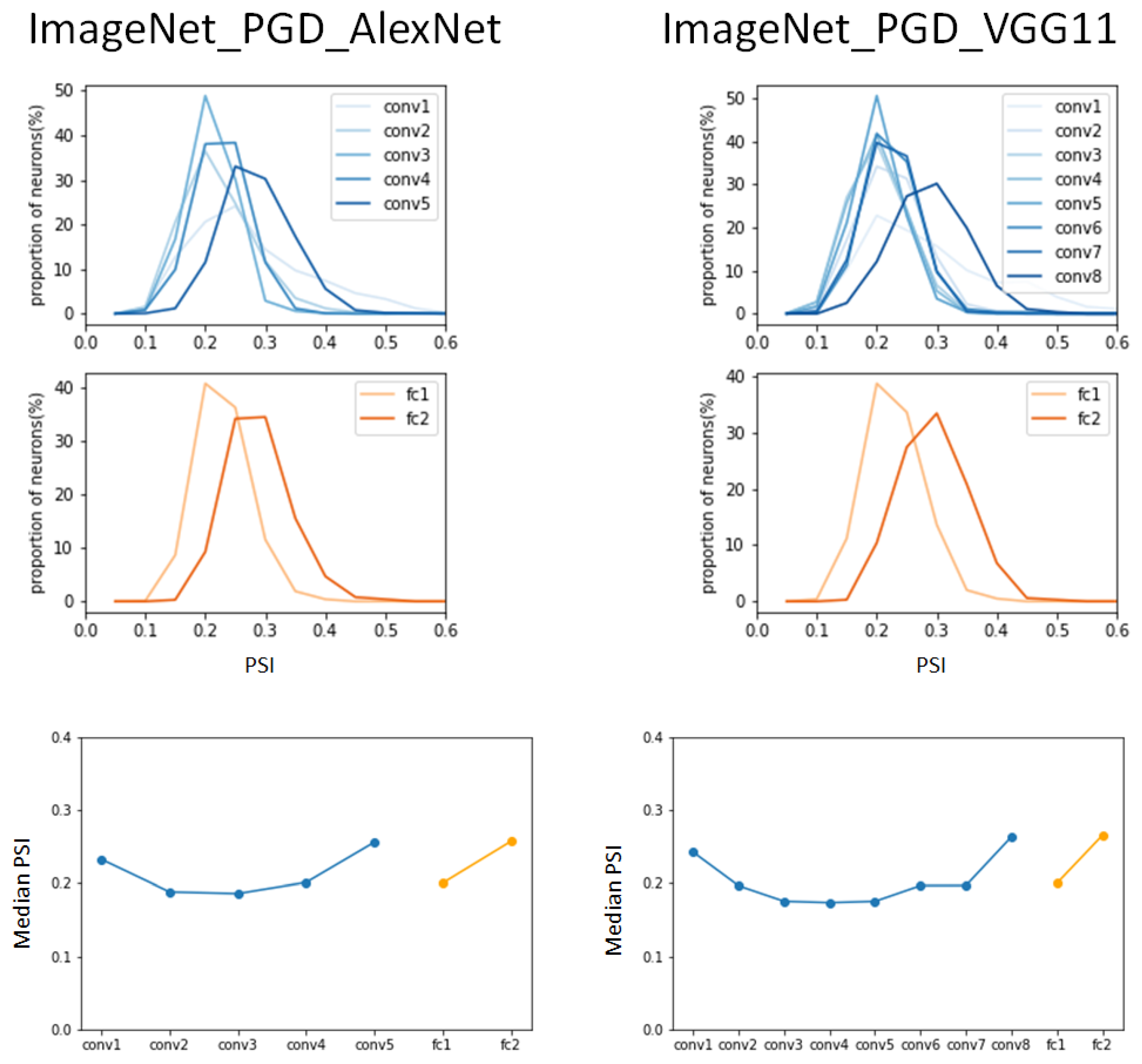
The same experiment was performed on the pre-trained AlexNet and VGG11 on adversarial examples of ImageNet attacked by PGD attack. The result of the median of the PSI was less than 0.3, which is smaller than the result from the non-attacked ImageNet validation dataset (typical dataset) shown in
Figure 5. Although the median value of the PSI in the first convolutional layer was observed to be similar to that in the typical ImageNet dataset, there was no rapid increase in the median PSI values as the hierarchy progressed. The range of change in the median PSI values at the convolution layers was 0.18 to 0.35 for the typical ImageNet dataset, 0.15 to 0.20 for the ImageNet dataset attacked by FGSM attack, and 0.19 to 0.26 for the ImageNet dataset attacked by PGD attack.
The right shifting in the convolutional layers and fully connected layers according to the hierarchy was more pronounced than in the FGSM attack. However, it did not reach the results of the typical ImageNet dataset. In the graph of the PSI versus the proportion of categories, the PGD-attacked ImageNet dataset shows a right shift, with the peak values of the PSI in the range of 0.2 to 0.3 in
Figure 5, while the FGSM-attacked ImageNet dataset had a right shift from 0.12 to 0.4 in
Figure 4, and the typical ImageNet dataset had a right shift from 0.1 to 0.25 in
Figure 3.
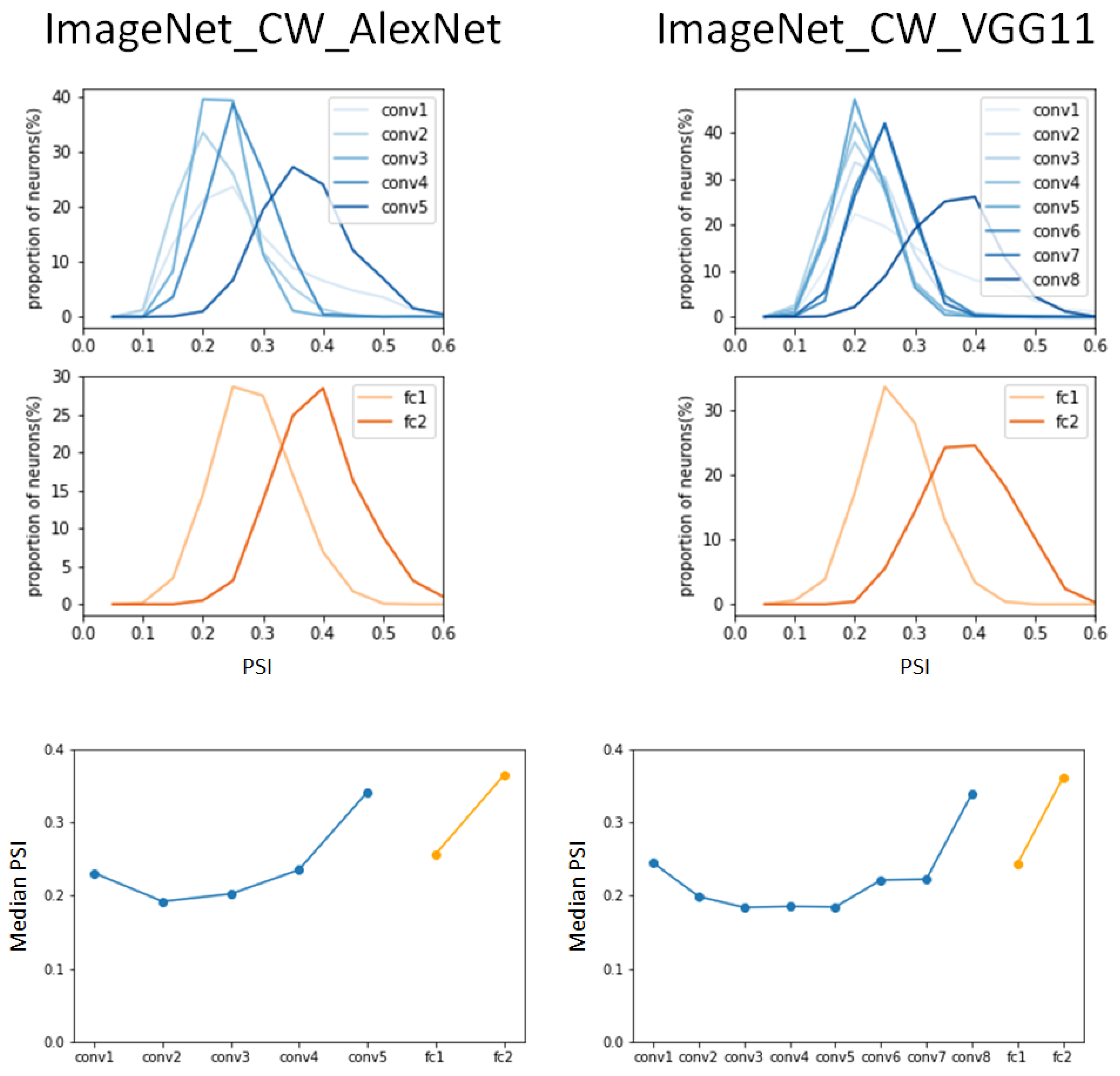
The final experiment for the hierarchical sparse coding for object categories using the ImageNet dataset was performed on the same DCNNs using the CW-attacked ImageNet dataset. The experiments with the CW-attacked ImageNet dataset had interesting results in contrast to the results of the previously described FGSM attack and PGD attack. The CW attack results in
Figure 6 are very similar to the results in
Figure 3. The range of median PSI values from 0.19 to 0.35 is very similar to the range from 0.18 to 0.38 as a result of applying the typical ImageNet dataset, and the pattern of change in the PSI according to the hierarchy is also very similar.
In the PSI versus the proportion of categories graph, the pattern of shifts to the right is such that the peaks of the PSI distribution move from 0.2 to 0.4 for AlexNet and VGG11, while for the typical ImageNet datasets, they move from 0.12 to 0.4 for AlexNet and from 0.2 to move 0.4 for VGG11.
Comparing the three attack methods, namely FGSM Attack, PGD attack, and CW attack, in terms of attack strength, CW attack is the strongest attack method and PGD Attack is the second strongest attack method based on FGSM attack [
30]. From the results of the four experiments in
Figure 6, it can be deduced that the stronger the attack and the more difficult it is to defend against it, the more difficult it is to distinguish the hierarchical sparseness from the hierarchical sparseness of the DCNN trained with a typical dataset.
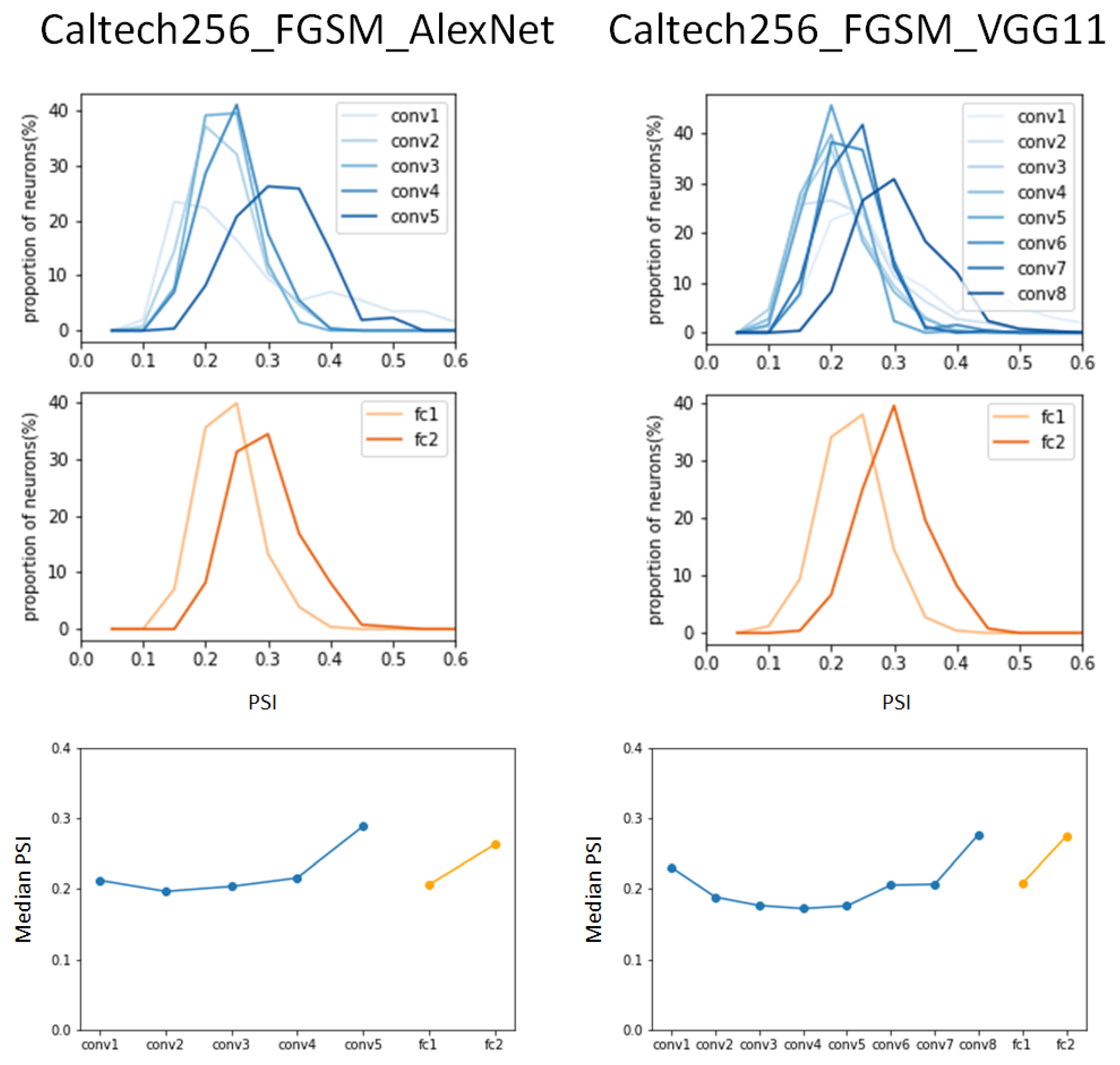
We conducted the same experiment to observe whether the same results were obtained when different datasets were applied to the same DCNN models. That is, the same experiment was carried out by applying the Caltech256 dataset to the VGG11 and the AlexNet models.
Figure 7 shows the PSI results of the VGG11 and AlexNet models for the FGSM-attacked Caltech256 dataset.
When comparing the changes in the peak values of the PSI distribution by layer in the AlexNet model, it can be observed that the FGSM-attacked dataset shows lower peak values compared to the results of the benign Caltech256 dataset. In addition, it can be seen that in the fully connected layers, significant low values are indicated. That is, the peak values of the benign Caltech256 dataset were 0.27 and 0.42 in fully connected layer 1 and fully connected layer 2, but 0.18 and 0.19 in the FGSM-attacked Caltect256 dataset.
The same results were observed in the VGG11 model. A decrease in the peak values in the PSI distribution was observed overall, and a peak value reduction of up to 50% was observed in the fully connected layers. In the median PSI comparison, the convolution layers show a pattern similar to the results of the benign Caltec256 dataset, but an increase was observed in the fully connected layers.
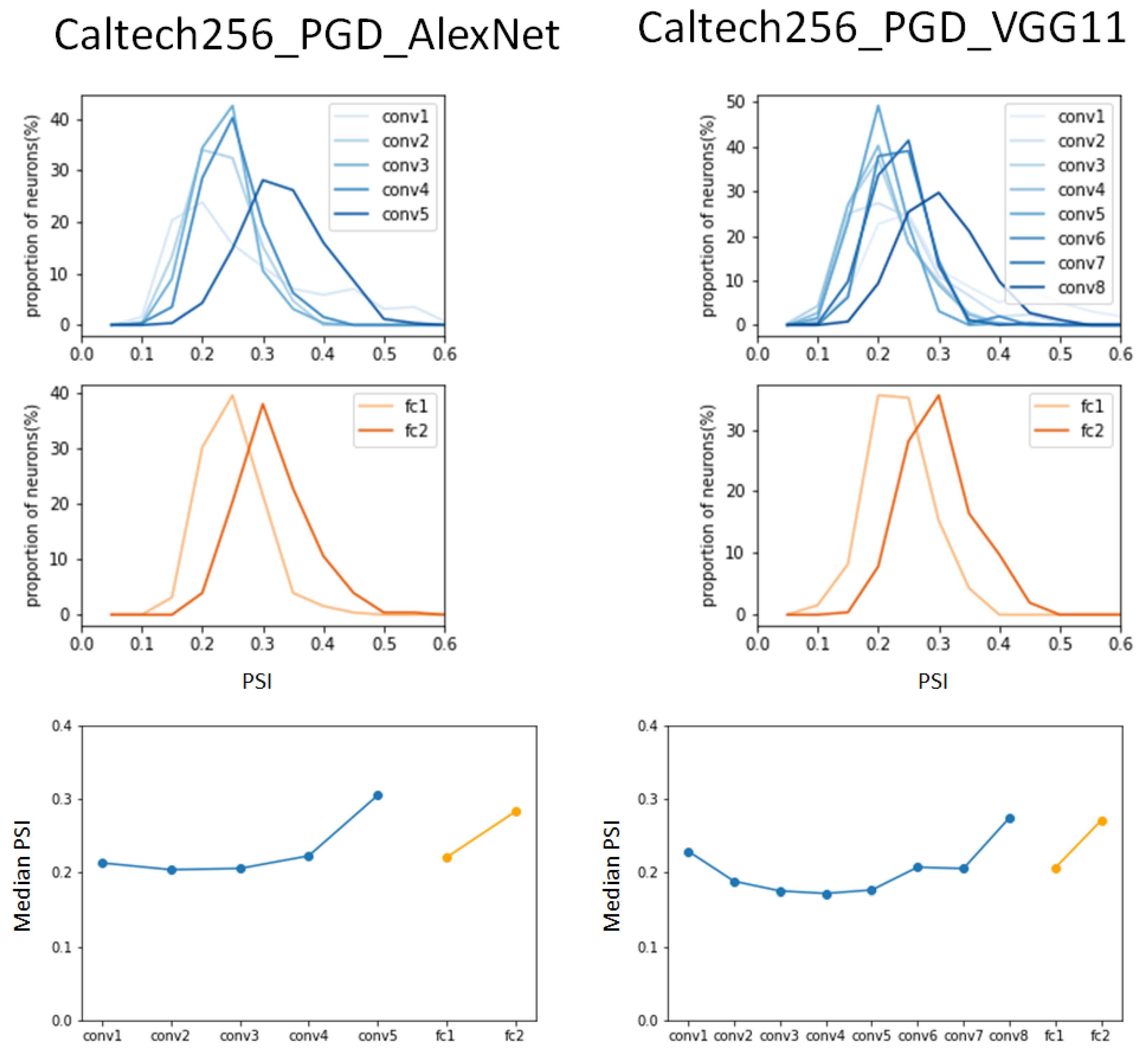
In the same experiment on the PGD-attacked Caltech356 dataset, the AlexNet model was observed to exhibit higher peak values in the PSI distribution compared to the results of the ImageNet dataset that was subjected to the same attack in
Figure 8. It is worth noting that in the PGD-attacked ImageNet dataset, the peak value of the PSI decreased as it progressed from fully connected layer 1 to fully connected layer 2, but in the PGD-attacked Caltech256 dataset, it increased, as it did in both benign datasets. The VGG11 model shows very similar results to the benign Caltech256 dataset in the convolution layers, but it was observed that the peak value of the PSI distribution decreased sharply in fully connected layer 1 and then recovered to a value similar to that of the benign dataset in fully connected layer 2.
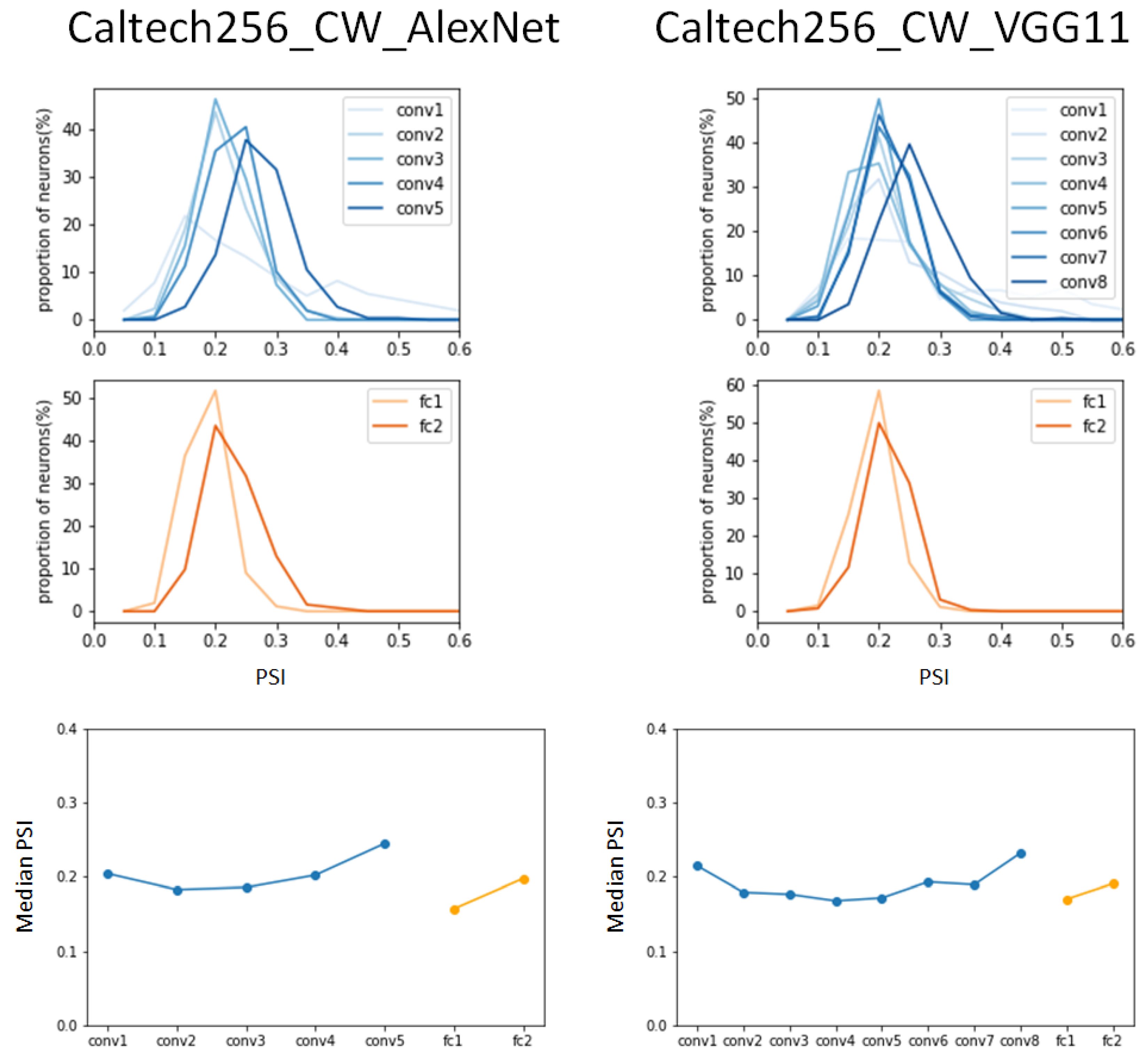
In the experiments with the CW-attacked Catech256 dataset, the AlexNet model had peak values that were similar to or slightly lower than those of the benign Caltech256 dataset in the convolution layers in
Figure 9. A slightly lower value was observed in fully connected layer 1 compared to the results of the benign dataset, but a peak value of 0.28 was observed in fully connected layer 2, which was significantly smaller than the peak value of 0.42 in the benign dataset.
In addition, the VGG11 model showed almost the same experimental results as the benign Caltech256 dataset, although convolution layer 6 showed a different peak value. In the analysis of the median PSI, it was observed that the results of the AlexNet model were almost identical to the results of the benign Caltech256 dataset, and a pattern similar to the results of the AlexNet model was found in the VGG11 model. This study involved analyzing the coding scheme across various layers of two conventional DCNNs, AlexNet and VGG11, using two attacked versions of datasets—ImageNet and Caltech256.
The results of our experiments can be summarized as shown in
Table 3 and
Table 4 for the median PSI analysis and in
Table 5 and
Table 6 for the PSI peak value analysis. These tables present the layer-specific median PSI values and PSI peak values, offering insights into the level of sparsity within each layer of conventional DCNNs, AlexNet and VGG11.
In the PSI analysis of the two DCNN models for the benign examples, it was found that the PSI, as the degree of sparseness, increased with the increase in the layers in the DCNNs. The observation that an increased median PSI at each layer aligned with greater behavioral relevance within the DCNNs implies that this phenomenon serves as a fundamental mechanism for efficiently representing a diverse range of objects.
Essentially, this suggests that in the initial stages of visual processing, a larger population of general neurons is engaged to accurately process various natural objects. As we move up the processing hierarchy, these objects are parsed into more abstract features, leading to the involvement of a smaller, yet highly specialized, group of neurons in constructing this representation. This heightened level of sparsity significantly enhances the interpretability of these representations, as the extent of sparsity appears to predict behavioral performance primarily in the higher processing stages [
16].
As shown in the median PSI values for the benign examples of the AlexNet and VGG11 models in
Table 3, the median PSI values tended to increase progressively from convolution layer 2 to convolution layer 5 in AlexNet and to convolution layer 8 in VGG11, except for convolution layer 1. In the case of the Caltech256 dataset in
Table 4, when benign examples were applied to the two models, it can be observed that the median PSI increased along the convolution layers entirely.
In addition, as shown in the study of [
16], it was observed that the last convolution layer, which corresponds to conv5 in AlexNet and conv8 in VGG11, and the last fully connected layers in the two models had a dramatical decrease in the median PSI value.
In the PSI analysis, the same tendency was observed in the adversarial examples in both DCNN model. In particular, we found that in the adversarial examples generated from FGSM and PGD attack, not only did the median PSI increase slowly according to the layer, but it also showed a lower median PSI value compared to the results of the benign examples. Interestingly, the change in the median PSI was observed to show a rate of change of 1.0–1.3 for the benign examples from fc1 to fc2, while a rate of change of 0–0.8 during the same transition layer for both attacks. These results are interpreted as affecting the behavioral performance of DCNN models since specialized groups of neurons do not work when adversarial examples are applied to DCNN models. Note that the changes in sparseness were observed in two structurally similar DCNNs in AlexNet and VGG11, and therefore, this may not be applicable to other DCNNs.
We found interesting results related to the median PSI from CW-attacked datasets. The median PSI for each layer for the CW adversarial examples generated from the ImageNet dataset, as shown in
Table 3, showed values that are almost similar to the results of the benign examples in the AlexNet and VGG11 models. Although the median PSI at fc2 was slightly smaller than the results of the benign examples, the median PSI for the entire layer was similar. The same results were also obtained in the CW-adversarial examples obtained from the Caltech256 dataset.
4. Conclusions
This study represents the coding scheme of adversarial examples generated from three adversarial attacks and provides information on how adversarial examples behave inside DCNNs. In particular, we observed that the AlexNet and VGG11 models, which have similar but different structures, exhibited similar PSI characteristics for the adversarial examples generated from each attack, and confirmed that the DCNNs behaved abnormally. A notable observation is that the median PSI values at the final fully connected layer of the two DCNN models, which ultimately determine the models’ performance, were lower when compared to the PSI values of the benign examples. This phenomenon was more pronounced in the attacked ImageNet dataset. These results suggest a perturbation in the features of samples caused by adversarial examples.
Our research can be considered from the perspective of DCNN model design and from a neurophysiological perspective. The first aspect provides a basis for revealing the internal mechanisms of DCNNs that cause malfunctions by adversarial examples. Consequently, considering the internal dynamics of DCNN models known as black boxes, it can be applied to design more robust DCNN models against adversarial attacks.
From a neurophysiological point of view, it provides a macro- and micro-perspective on how we misperceive objects. In other words, brain studies targeting non-human primates have limited spatial resolution or brain area, but DCNNs can clearly observe the activity of neuron units, so it is possible to conduct research without such limitations.
Therefore, although our study was limited to two types of DCNN models and three types of adversarial examples from two datasets, it is valuable as a new attempt to understand adversarial attacks in DCNN structures. Beyond the constraints of the models and datasets used in this experiment, investigating the internal dynamics of models using PSI for other models and datasets remains a future research task.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}