
An Improved Visual SLAM Method with Adaptive Feature Extraction


Abstract
:1. Introduction
- This paper designs the detection thresholds for AGAST based on the image’s overall grayscale information, which can be adjusted to varied situations and extract an appropriate amount of feature points with high quality.
- Image pyramids are adaptively built for images of various sizes, and feature detection is accomplished by utilizing the adaptive meshing method and AGAST algorithm. This could adapt to various inputs and decrease unnecessary calculations.
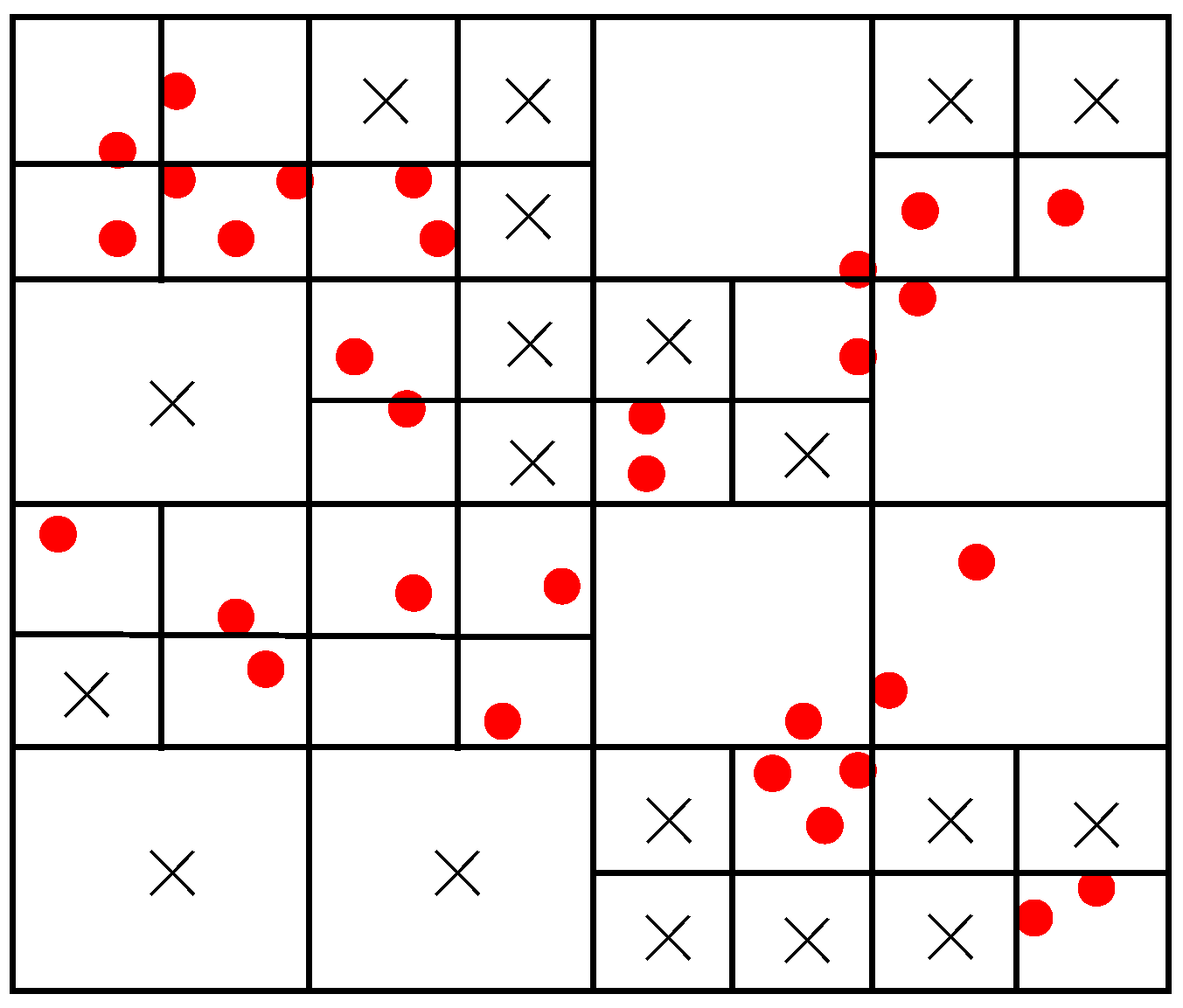
- Following the detection of feature points, we utilize the Non-Maximum Suppression (NMS) method to filter the feature points and combine the quadtree algorithm to homogenize them, which can avoid corner point clustering. We calculate the feature point orientation using the intensity centroid method to provide orientation invariance for it, which is conducive to subsequent feature matching.
2. Related Work
2.1. Visual SLAM
2.2. Image Feature Point
3. Our Method
3.1. Improved Feature Extraction Algorithm
3.1.1. Calculate Global Adaptive Threshold
3.1.2. Construct a Gaussian Pyramid
3.1.3. Adaptive Meshing of the Image Pyramid
3.1.4. AGAST Extract Feature Points
3.1.5. NMS to Filter Feature Points
3.1.6. Divide Feature Points with Quad-Tree
3.1.7. Intensity Centroid Method to Calculate the Orientation of Feature Points
3.2. SLAM Framework
4. Experiment
4.1. Experimental Datasets
4.2. Evaluation Indicators
4.3. Feature Extraction
4.4. Overall Performance
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Davison, A.J.; Reid, I.D.; Molton, N.D.; Stasse, O. MonoSLAM: Real-Time Single Camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1052–1067. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Xia, H.; Zhou, M.; Xie, L.; He, W. A Deep Learning-Based Target Recognition Method for Entangled Optical Quantum Imaging System. IEEE Trans. Instrum. Meas. 2023, 72, 1–12. [Google Scholar] [CrossRef]
- He, T.; Shen, C.H.; van den Hengel, A. Dynamic Convolution for 3D Point Cloud Instance Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 5697–5711. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Liu, G.; Tian, G.; Luo, Y.; Wang, Z.; Zhang, W.; Li, J. A Survey of Visual SLAM Based on Deep Learning. Robot 2017, 39, 889–896. [Google Scholar] [CrossRef]
- Belter, D.; Skrzypczynski, P. Precise self-localization of a walking robot on rough terrain using parallel tracking and mapping. Ind. Robot 2013, 40, 229–237. [Google Scholar] [CrossRef]
- Irani, M.; Anandan, P. About direct methods. In International Workshop on Vision Algorithms; Theory and Practice; Springer: Berlin/Heidelberg, Germany, 2000; pp. 267–277. [Google Scholar]
- Newcombe, R.A.; Lovegrove, S.J.; Davison, A.J. DTAM: Dense tracking and mapping in real-time. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2320–2327. [Google Scholar] [CrossRef]
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-Scale Direct Monocular SLAM. In Computer Vision–ECCV 2014; Springer: Cham, Switzerland, 2014; pp. 834–849. [Google Scholar] [CrossRef]
- Wang, R.; Schwörer, M.; Cremers, D. Stereo DSO: Large-Scale Direct Sparse Visual Odometry with Stereo Cameras. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3923–3931. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.M.; Tardós, J.D. ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual–Inertial, and Multimap SLAM. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Ferrera, M.; Eudes, A.; Moras, J.; Sanfourche, M.; Besnerais, G.L. OV2SLAM: A Fully Online and Versatile Visual SLAM for Real-Time Applications. IEEE Robot. Autom. Lett. 2021, 6, 1399–1406. [Google Scholar] [CrossRef]
- Moravec, H.P. Rover Visual Obstacle Avoidance. In Proceedings of the 7th International Joint Conference on Artificial Intelligence (IJCAI’81), Vancouver, BC, Canada, 24–28 August 1981; pp. 785–790. [Google Scholar]
- Low, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Gool, L.V. SURF: Speeded up robust features. In Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Volume Part I, pp. 404–417. [Google Scholar]
- Rosten, E.; Drummond, T. Machine Learning for High-Speed Corner Detection. In Computer Vision–ECCV 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 430–443. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar] [CrossRef]
- Sun, H.; Wang, P. An improved ORB algorithm based on region division. J. Beijing Univ. Aeronaut. Astronaut. 2020, 46, 1763–1769. [Google Scholar] [CrossRef]
- Mair, E.; Hager, G.D.; Burschka, D.; Suppa, M.; Hirzinger, G. Adaptive and Generic Corner Detection Based on the Accelerated Segment Test. In Proceedings of the ECCV 2010 European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010. [Google Scholar] [CrossRef]
- Xue, Y.; Gao, T. Feature Point Extraction and Matching Method Based on Akaze in Illumination Invariant Color Space. In Proceedings of the 2020 IEEE 5th International Conference on Image, Vision and Computing (ICIVC), Beijing, China, 10–12 July 2020; pp. 160–165. [Google Scholar] [CrossRef]
- Zhou, F.; Zhang, L.; Deng, C.; Fan, X. Improved Point-Line Feature Based Visual SLAM Method for Complex Environments. Sensors 2021, 21, 4604. [Google Scholar] [CrossRef] [PubMed]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. SuperPoint: Self-Supervised Interest Point Detection and Description. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 337–349. [Google Scholar] [CrossRef]
- Li, G.Q.; Yu, L.; Fei, S.M. A deep-learning real-time visual SLAM system based on multi-task feature extraction network and self-supervised feature points. Measurement 2021, 168, 108403. [Google Scholar] [CrossRef]
- Zhao, X.; Wu, X.; Miao, J.; Chen, W.; Chen, P.C.Y.; Li, Z. ALIKE: Accurate and Lightweight Keypoint Detection and Descriptor Extraction. IEEE Trans. Multimed. 2022, 25, 3101–3112. [Google Scholar] [CrossRef]
- Neubeck, A.; Gool, L.V. Efficient Non-Maximum Suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; Volume 3, pp. 850–855. [Google Scholar] [CrossRef]
- Rosin, P.L. Measuring Corner Properties. Comput. Vis. Image Underst. 1999, 73, 291–307. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar] [CrossRef]
- Burri, M.; Nikolic, J.; Gohl, P.; Schneider, T.; Rehder, J.; Omari, S.; Achtelik, M.W.; Siegwart, R. The EuRoC micro aerial vehicle datasets. Int. J. Robot. Res. 2016, 35, 1157–1163. [Google Scholar] [CrossRef]
- Forster, C.; Zhang, Z.; Gassner, M.; Werlberger, M.; Scaramuzza, D. SVO: Semidirect Visual Odometry for Monocular and Multicamera Systems. IEEE Trans. Robot. 2017, 33, 249–265. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence | ORB-SLAM 2 | ORB-SLAM 3 | Our Method | |||
|---|---|---|---|---|---|---|
| Mean Time (ms) | RMSE (m) | Mean Time (ms) | RMSE (m) | Mean Time (ms) | RMSE (m) | |
| 00 | 58.388 | 1.293 | 36.161 | 1.242 | 35.607 | 1.224 |
| 01 | 80.643 | 10.422 | 31.035 | 14.755 | 30.637 | 13.926 |
| 02 | 62.803 | 6.095 | 35.727 | 5.967 | 35.907 | 5.422 |
| 03 | 62.404 | 0.670 | 31.703 | 1.326 | 31.254 | 1.309 |
| 04 | 64.720 | 0.226 | 32.114 | 0.219 | 32.143 | 0.206 |
| 05 | 65.096 | 0.793 | 34.178 | 0.967 | 33.638 | 0.817 |
| 06 | 70.992 | 0.770 | 35.875 | 1.231 | 36.2021 | 0.945 |
| 07 | 61.913 | 0.539 | 39.554 | 0.483 | 42.281 | 0.450 |
| 09 | 62.606 | 3.056 | 32.568 | 2.049 | 32.5301 | 1.989 |
| Sequence | ORB-SLAM 3 | Our Method |
|---|---|---|
| Mean Time (ms) | Mean Time (ms) | |
| fr1/desk | 10.116 | 10.108 |
| fr1/360 | 9.199 | 9.162 |
| fr1/room | 9.906 | 9.666 |
| fr1/rpy | 9.830 | 9.779 |
| Sequence | ORB-SLAM 3 | Our Method |
|---|---|---|
| RMSE (cm) | RMSE (cm) | |
| fr1/desk | 2.073 | 1.598 |
| fr1/360 | 19.028 | 17.719 |
| fr1/room | 6.026 | 5.261 |
| fr1/rpy | 2.095 | 1.975 |
| Sequence | SVO | ORB-SLAM 2 | ORB-SLAM 3 | Our Method |
|---|---|---|---|---|
| MH01 | 4 | 3.883 | 3.717 | 3.664 |
| MH02 | 5 | 4.894 | 5.045 | 4.679 |
| MH03 | 6 | 3.940 | 5.374 | 4.791 |
| MH04 | X | 11.493 | 10.318 | 7.924 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, X.; Lyu, M.; Xia, B.; Zhang, K.; Zhang, L. An Improved Visual SLAM Method with Adaptive Feature Extraction. Appl. Sci. 2023, 13, 10038. https://doi.org/10.3390/app131810038
Guo X, Lyu M, Xia B, Zhang K, Zhang L. An Improved Visual SLAM Method with Adaptive Feature Extraction. Applied Sciences. 2023; 13(18):10038. https://doi.org/10.3390/app131810038
Chicago/Turabian StyleGuo, Xinxin, Mengyan Lyu, Bin Xia, Kunpeng Zhang, and Liye Zhang. 2023. "An Improved Visual SLAM Method with Adaptive Feature Extraction" Applied Sciences 13, no. 18: 10038. https://doi.org/10.3390/app131810038
APA StyleGuo, X., Lyu, M., Xia, B., Zhang, K., & Zhang, L. (2023). An Improved Visual SLAM Method with Adaptive Feature Extraction. Applied Sciences, 13(18), 10038. https://doi.org/10.3390/app131810038