
Modeling of Digital Twin Workshop in Planning via a Graph Neural Network: The Case of an Ocean Engineering Manufacturing Intelligent Workshop
 , and
, and
Abstract
:1. Introduction
- We design the DT workshop system architecture in detail, form a targeted five-dimensional model for OE intelligent manufacturing workshops, and create an integrated discrete operation workshop management model with “virtual-real co-drive”.
- We present a novel model for the DT workshop planning that utilizes GNN. Our method realizes generating the workshop’s master plan that exhibits good generalization capabilities. This is achieved through node embedding, graph attention network structure building, and a deep reinforcement learning-based algorithm for model training.
- Drawing upon the proposed GNN model, our research expands upon the discourse surrounding five distinct decision support techniques aimed at resolving production-related issues, with the ultimate objective of augmenting the efficacy of the planning model.
- The feasibility of the model is verified, and a demand-oriented DT system is created for workshop job execution. We optimize the limitations of the current production mode by focusing on the critical development of DT technology and the efficient use of twin data—not just the simple interaction of visual simulation models.
2. Literature Reviews
2.1. Digital Twin
2.2. Graph Neural Network
3. Architecture of DT Workshop System
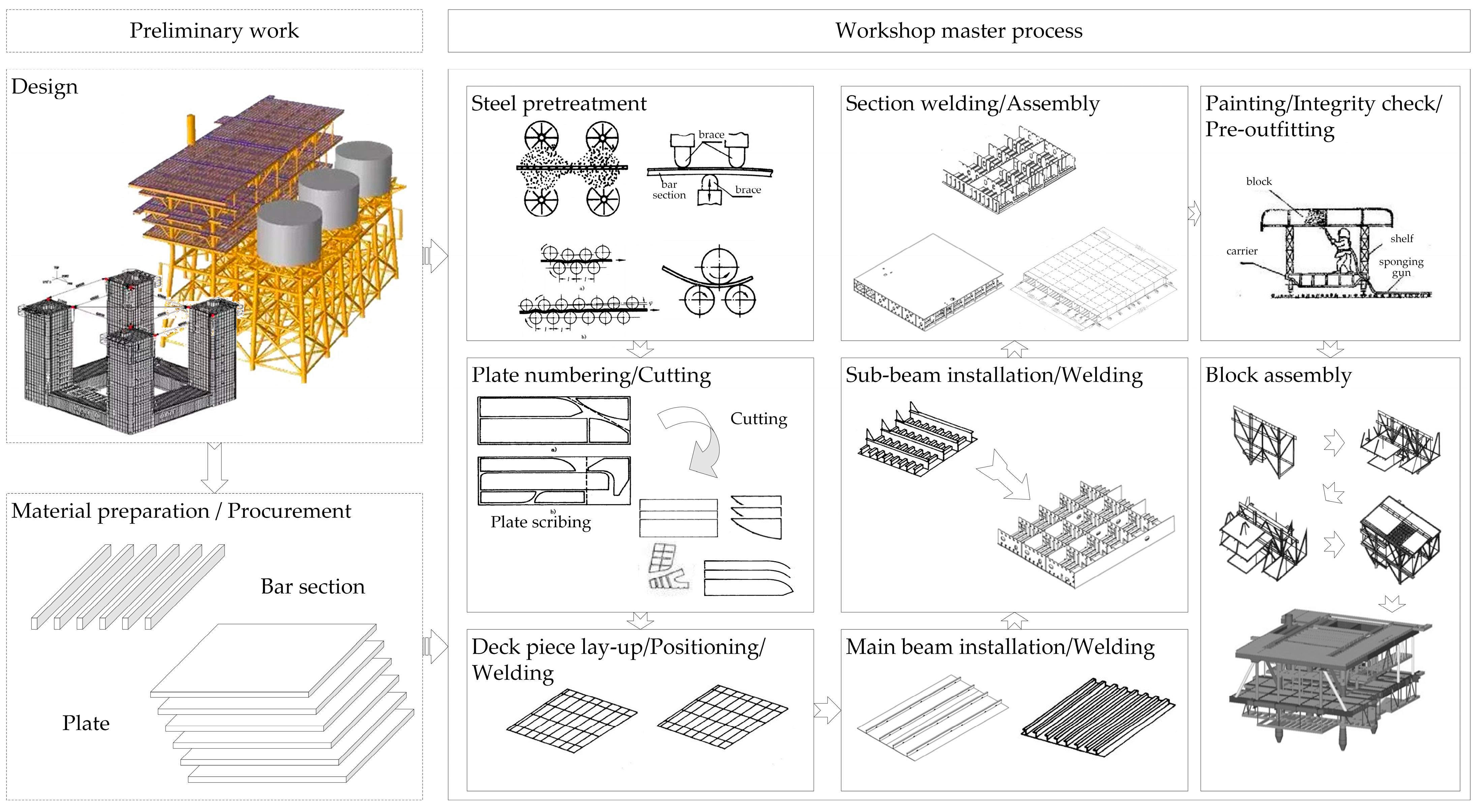
3.1. Intelligent Workshop Integrated Manufacturing Execution Mode
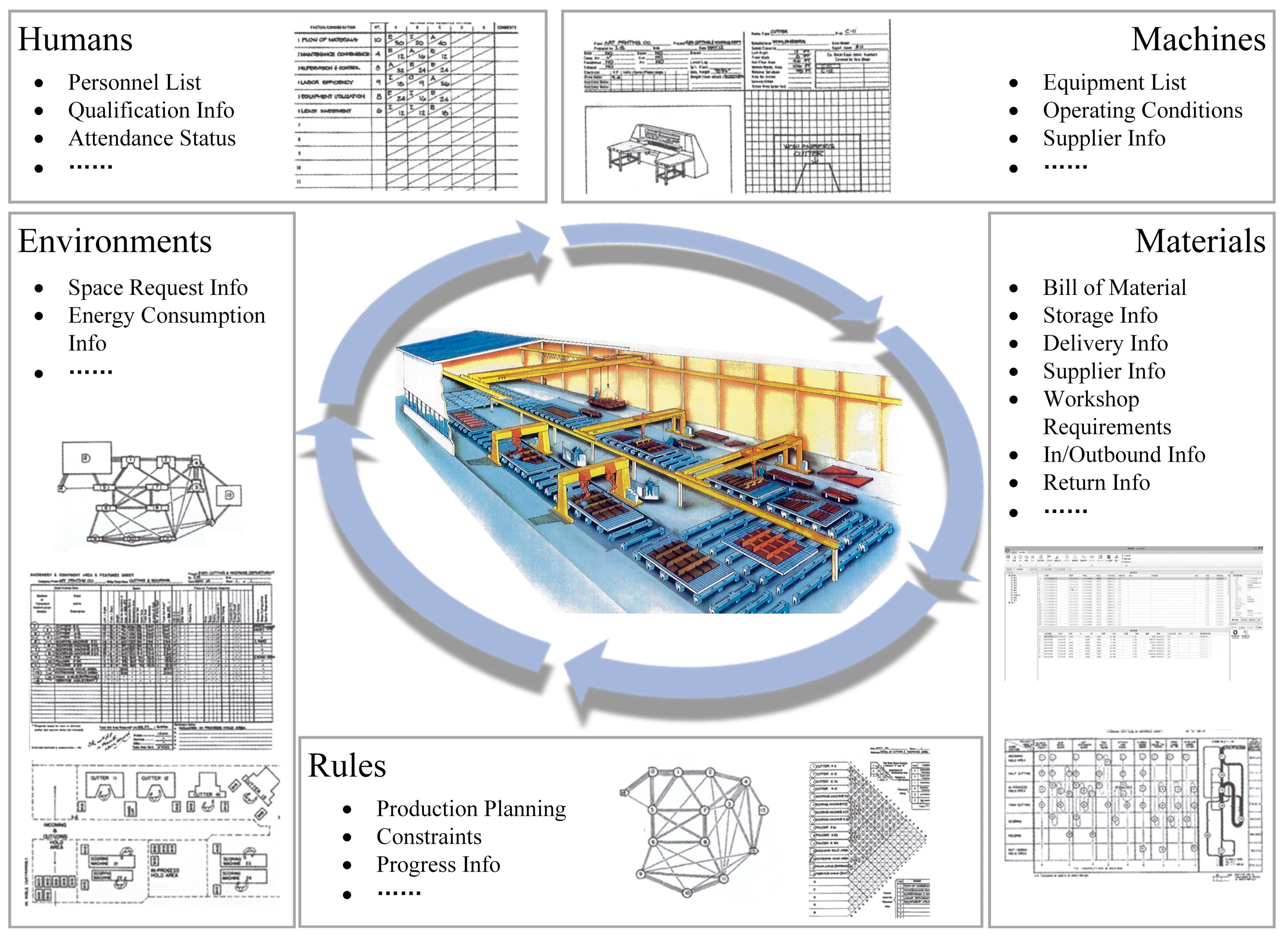
3.2. Design of DT Workshop Architecture Based on Five-Dimensional Model
- Equipment Layer
- Data Acquisition Layer
- Application Service Layer
- Digital Twin Display Layer
3.3. Transfer Rules for Manufacturing Execution Behaviors under Finite State Mechanism
3.4. Real-Time Mapping of Workshop Processes
4. DT Workshop Planning Modeling Based on GNN
4.1. Traditional Mathematical Model
- One machine operates only one process of one workpiece at the same time;
- All the equipment is available at the starting moment;
- The locations of the segments in the workshop are close to each other without considering the transfer time between different processes;
- The equipment is available at all times, regardless of breakdowns;
- The process has no other influence to interrupt the processing.
4.2. Graph Neural Network Structure
4.2.1. Disjunctive Graph
4.2.2. Markov Decision Process
4.2.3. Graph Attention Network
4.3. Model Training
| Algorithm 1: The PPO-based training procedure |
 |
5. DT Workshop Planning Model-Based Decision Support Methodology
5.1. Work Hours Forecasting
5.2. Resource Demand Forecasting
5.3. Resource Bottleneck Identification
5.4. Dynamic Job Shop Scheduling
5.5. Multi-Station Collaborative Distribution
6. Case Validation and Discussion
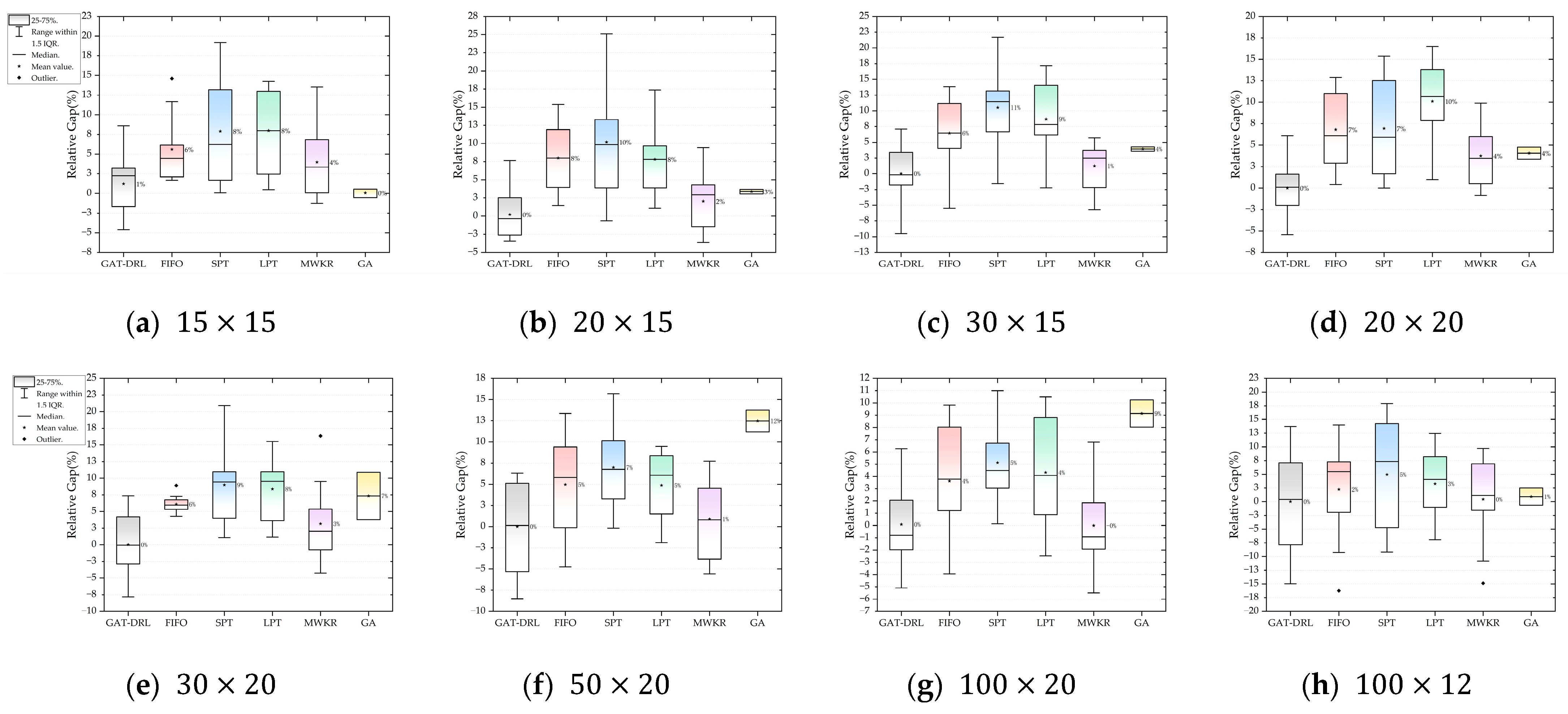
6.1. Effectiveness of GNN-Based Planning Model
6.2. Application of the Digital Twin System in Workshop
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tao, F.; Qi, Q. Make more digital twins. Nature 2019, 573, 490–491. [Google Scholar] [CrossRef] [PubMed]
- Tao, F.; Zhang, H.; Liu, A.; Nee, A. Digital twin in industry: State-of-the-art. IEEE Trans. Ind. Inform. 2018, 15, 2405–2415. [Google Scholar] [CrossRef]
- Bangsow, S. Tecnomatix Plant Simulation; Springer: Berlin/Heidelberg, Germany, 2020; pp. 103–180. [Google Scholar]
- Fourgeau, E.; Gomez, E.; Adli, H.; Fernandes, C.; Hagege, M. System Engineering Workbench for Multi-views Systems Methodology with 3DEXPERIENCE Platform. In Proceedings of the Second Asia-Pacific Conference on Complex Systems Design & Management, CSD&M Asia 2016, Singapore University of Technology, Singapore, 24–26 February 2016. [Google Scholar]
- Tao, F.; Liu, W.; Zhang, M.; Hu, T.; Qi, Q.; Zhang, H.; Sui, F.; Wang, T.; Xu, H.; Huang, Z.; et al. Five-dimension digital twin model and its ten applications. Comput. Integr. Manuf. Syst. 2019, 25, 1–18. [Google Scholar]
- Wei, Y.; Guo, L.; Chen, L.; Zhang, H.; Hu, X.; Zhou, H.; Li, G. Research and implementation of digital twin workshop based on real-time data driven. Comput. Integr. Manuf. Syst. 2021, 27, 352–363. [Google Scholar]
- Kong, T.; Hu, T.; Zhou, T.; Ye, Y. Data construction method for the applications of workshop digital twin system. J. Manuf. Syst. 2021, 58, 323–328. [Google Scholar] [CrossRef]
- Leng, J.; Zhang, H.; Yan, D.; Liu, Q.; Chen, X.; Zhang, D. Digital twin-driven manufacturing cyber-physical system for parallel controlling of smart workshop. J. Ambient Intell. Humaniz. Comput. 2019, 10, 1155–1166. [Google Scholar] [CrossRef]
- Zheng, Y.; Yang, S.; Cheng, H. An application framework of digital twin and its case study. J. Ambient Intell. Humaniz. Comput. 2019, 10, 1141–1153. [Google Scholar] [CrossRef]
- Yuan, E.; Cheng, S.; Wang, L.; Song, S.; Wu, F. Solving job shop scheduling problems via deep reinforcement learning. Appl. Soft Comput. 2023, 143, 110436. [Google Scholar] [CrossRef]
- Song, W.; Chen, X.; Li, Q.; Cao, Z. Flexible Job-Shop Scheduling via Graph Neural Network and Deep Reinforcement Learning. IEEE Trans. Ind. Inform. 2022, 19, 1600–1610. [Google Scholar] [CrossRef]
- Park, J.; Chun, J.; Kim, S.; Kim, Y.; Park, J. Learning to schedule job-shop problems: Representation and policy learning using graph neural network and reinforcement learning. Int. J. Prod. Res. 2021, 59, 3360–3377. [Google Scholar] [CrossRef]
- Lei, K.; Guo, P.; Zhao, W.; Wang, Y.; Qian, L.; Meng, X.; Tang, L. A multi-action deep reinforcement learning framework for flexible Job-shop scheduling problem. Expert Syst. Appl. 2022, 205, 117796. [Google Scholar] [CrossRef]
- Lei, K.; Guo, P.; Wang, Y.; Xiong, J.; Zhao, W. An End-to-end Hierarchical Reinforcement Learning Framework for Large-scale Dynamic Flexible Job-shop Scheduling Problem. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022. [Google Scholar]
- Chen, R.; Li, W.; Yang, H. A Deep Reinforcement Learning Framework Based on an Attention Mechanism and Disjunctive Graph Embedding for the Job-Shop Scheduling Problem. IEEE Trans. Ind. Inform. 2022, 19, 1322–1331. [Google Scholar] [CrossRef]
- Han, B.-A.; Yang, J.-J. Research on adaptive job shop scheduling problems based on dueling double DQN. IEEE Access 2020, 8, 186474–186495. [Google Scholar] [CrossRef]
- Grieves, M.W. PLM--beyond lean manufacturing. Manuf. Eng. 2003, 130, 23. [Google Scholar]
- Glaessgen, E.; Stargel, D. The digital twin paradigm for future NASA and US Air Force vehicles. In Proceedings of the 53rd AIAA/ASME/ASCE/AHS/ASC Structures, Structural Dynamics and Materials Conference, Honolulu, HI, USA, 23–26 April 2012. [Google Scholar]
- Liu, X.; Furrer, D.; Kosters, J.; Holmes, J. Vision 2040: A Roadmap for Integrated, Multiscale Modeling and Simulation of Materials and Systems; No. E-19477; NASA: Washington, DC, USA, 2018; pp. 1–168. [Google Scholar]
- Tao, F.; Xiao, B.; Qi, Q.; Cheng, J.; Ji, P. Digital twin modeling. J. Manuf. Syst. 2022, 64, 372–389. [Google Scholar] [CrossRef]
- Tao, F.; Zhang, M. Digital twin shop-floor: A new shop-floor paradigm towards smart manufacturing. IEEE Access 2017, 5, 20418–20427. [Google Scholar] [CrossRef]
- Guo, J.; Zhao, N.; Sun, L.; Zhang, S. Modular based flexible digital twin for factory design. J. Ambient Intell. Humaniz. Comput. 2019, 10, 1189–1200. [Google Scholar] [CrossRef]
- Zhang, K.; Qu, T.; Zhou, D.; Jiang, H.; Lin, Y.; Li, P.; Guo, H.; Liu, Y.; Li, C.; Huang, G. Digital twin-based opti-state control method for a synchronized production operation system. Robot. Comput. Integr. Manuf. 2020, 63, 101892. [Google Scholar] [CrossRef]
- Lee, J.; Lapira, E.; Yang, S.; Kao, A. Predictive manufacturing system-Trends of next-generation production systems. Ifac Proc. Vol. 2013, 46, 150–156. [Google Scholar] [CrossRef]
- Schleich, B.; Anwer, N.; Mathieu, L.; Wartzack, S. Shaping the digital twin for design and production engineering. CIRP Ann. 2017, 66, 141–144. [Google Scholar] [CrossRef]
- Sun, X.; Bao, J.; Li, J.; Zhang, Y.; Liu, S.; Zhou, B. A digital twin-driven approach for the assembly-commissioning of high precision products. Robot. Comput.-Integr. Manuf. 2020, 61, 101839. [Google Scholar] [CrossRef]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. AI Open 2020, 1, 57–81. [Google Scholar] [CrossRef]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Philip, S. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4–24. [Google Scholar] [CrossRef]
- Gori, M.; Monfardini, G.; Scarselli, F. A new model for learning in graph domains. In Proceedings of the 2005 IEEE International Joint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005. [Google Scholar]
- Bruna, J.; Zaremba, W.; Szlam, A.; LeCun, Y. Spectral networks and locally connected networks on graphs. arXiv 2013, arXiv:1312.6203. [Google Scholar]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. Adv. Neural Inf. Process. Syst. 2016, 29, 3844–3852. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Li, Y.; Tarlow, D.; Brockschmidt, M.; Zemel, R. Gated graph sequence neural networks. arXiv 2015, arXiv:1511.05493. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. Adv. Neural Inf. Process. Syst. 2017, 30, 1024–1034. [Google Scholar]
- Gilmer, J.; Schoenholz, S.; Riley, P.; Vinyals, O.; Dahl, G. Neural Message Passing for Quantum Chemistry. In Proceedings of the 34th International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017. [Google Scholar]
- Zhu, J.; Wu, M.; Liu, C. Research on the Application Mode of Blockchain Technology in the Field of Shipbuilding. In Proceedings of the 2020 IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), Dalian, China, 27–29 June 2020. [Google Scholar]
- Shi, J.; Liu, X.; Liu, T. Method of digital twin logic model oriented to production line simulation. Comput. Integr. Manuf. Syst. 2022, 28, 442–454. [Google Scholar]
- Rocha, M.; Simão, A.; Sousa, T. Model-based test case generation from UML sequence diagrams using extended finite state machines. Softw. Qual. J. 2021, 29, 597–627. [Google Scholar] [CrossRef]
- Wang, R.; Wang, G.; Sun, J.; Deng, F.; Chen, J. Flexible Job Shop Scheduling via Dual Attention Network Based Reinforcement Learning. arXiv 2023, arXiv:2305.05119. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Li, J.; M Sun, M.; Han, D.; Wang, J.; Mao, X.; Wu, X. A knowledge discovery and reuse method for time estimation in ship block manufacturing planning using DEA. Adv. Eng. Inform. 2019, 39, 25–40. [Google Scholar] [CrossRef]
- Su, X.; Lu, J.; Chen, C.; Yu, J.; Ji, W. Dynamic Bottleneck Identification of Manufacturing Resources in Complex Manufacturing System. Appl. Sci. 2022, 12, 4195. [Google Scholar] [CrossRef]
- Guo, H.; Li, J.; Yang, B.; Mao, X.; Zhou, Q. Green scheduling optimization of ship plane block flow line considering carbon emission and noise. Comput. Ind. Eng. 2020, 148, 106680. [Google Scholar] [CrossRef]
- Yang, B.; Yin, W.; Li, J.; Zhou, Q. A Multitime Window Parallel Scheduling System for Large-Scale Offshore Platform Project. Wirel. Commun. Mob. Comput. 2022, 2022, 2352651. [Google Scholar] [CrossRef]
- Li, J.; Yin, W.; Yang, B.; Zhou, Q. Research on Welding Quality Traceability Model of Offshore Platform Block Construction Process. CMES Comput. Model. Eng. Sci. 2023, 134, 699–730. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbols | Definition | Description |
|---|---|---|
| Total number of workpieces | ||
| Workpiece number | ||
| Process number | ||
| Equipment number | ||
| Total number of equipment | ||
| Number of all process routes for | ||
| Flexible process route number | ||
| Total number of processes planning for the process plan of | ||
| The operation of the process plan for | ||
| Workpiece manufacturing start time | Time | |
| Workpiece delivery time | Time | |
| Workpiece completion time | Time | |
| Workpiece processing time | ||
| Process route selection decision variable | ||
| Equipment selection decision variable |
| Network Structure | GNN [12] | GIN [10] | HGNN [11] | GAT |
|---|---|---|---|---|
| Characteristics | The GNN is constructed by stacking embedding layers, and the embedding graph with node features and its domain is computed from the input graph after embedding iterations. | By encoding the dis-junction graph using GIN with discriminative ability, the preprocessing of receiving data is performed, and utilizing “add arc scheme” which ignores the un-directed arc to reduce the computational complexity. | Adopting a heterogeneous graph structure, preserving the traditional set of operation node set and conjunctive arcs, adding machine nodes, and replacing the disjunction arc set with the “operation–machine” arc set. | Based on the attention mechanism, neighbor node aggregation is implemented to select high-priority “operation–machine” combinations based on adaptive weights to solve FJSP instances of different scales. |
| Contributions | By learning general JSP properties, the GNN scheduler delivers better computational performance in the arbitrary instances. | Defining strategies to predict the probability distributions of operations and machines through the encoder-decoder component. | Efficient integration of operational and machine information with superior graph density and computational efficiency. | Explicit exploration of operation scheduling and machine competition relationships in disjunction graphs is attempted. |
| Training method | Proximal Policy Optimization (PPO) | |||
| Size ) | GAT-DRL | FIFO | SPT | LPT | MWKR | GA | |
|---|---|---|---|---|---|---|---|
| 1448 | 1513 | 1546 | 1547 | 1489 | 1433 | ||
| Time | 1.11 | 0.60 | 0.74 | 0.71 | 0.71 | 46.17 | |
| Gap | 3.14% | 5.58% | 7.89% | 7.98% | 4.31% | 0.56% | |
| 1646 | 1778 | 1814 | 1775 | 1677 | 1702 | ||
| Time | 1.46 | 0.81 | 0.99 | 0.93 | 0.96 | 60.66 | |
| Gap | 2.52% | 8.00% | 10.31% | 7.82% | 3.55% | 3.37% | |
| 2189 | 2330 | 2419 | 2379 | 2216 | 2275 | ||
| Time | 2.31 | 1.48 | 1.87 | 1.79 | 1.78 | 96.20 | |
| Gap | 3.60% | 7.55% | 10.83% | 9.12% | 3.69% | 3.91% | |
| 1933 | 2065 | 2067 | 2128 | 2005 | 2012 | ||
| Time | 1.98 | 1.09 | 1.31 | 1.18 | 1.26 | 82.29 | |
| Gap | 2.17% | 6.80% | 6.93% | 10.09% | 3.94% | 4.06% | |
| 2403 | 2549 | 2619 | 2604 | 2479 | 2580 | ||
| Time | 3.57 | 1.97 | 2.46 | 2.31 | 2.34 | 148.80 | |
| Gap | 3.70% | 6.09% | 8.99% | 8.36% | 4.61% | 7.34% | |
| 3338 | 3504 | 3571 | 3501 | 3368 | 3754 | ||
| Time | 9.09 | 3.14 | 4.23 | 3.86 | 3.89 | 378.77 | |
| Gap | 4.58% | 6.32% | 7.02% | 5.25% | 4.00% | 12.46% | |
| 5845 | 6052 | 6139 | 6093 | 5840 | 6374 | ||
| Time | 43.42 | 13.20 | 21.14 | 19.14 | 19.97 | 1808.81 | |
| Gap | 3.04% | 4.81% | 5.12% | 4.82% | 2.95% | 9.14% | |
| 6782 | 6934 | 7117 | 7004 | 6811 | 6845 | ||
| Time | 25.76 | 7.93 | 12.66 | 11.52 | 12.04 | 1073.09 | |
| Gap | 6.75% | 7.72% | 9.20% | 6.09% | 5.88% | 1.56% |
| Project | Total Project Duration (Days) | Calculation Time (s) | ||
|---|---|---|---|---|
| DT | MES | DT | MES | |
| A | 246 | 261 | 783.28 | 905.45 |
| B | 242 | 254 | 780.10 | 903.89 |
| C | 239 | 251 | 757.61 | 967.77 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Yin, W.; Yang, B.; Chen, L.; Dong, R.; Chen, Y.; Yang, H. Modeling of Digital Twin Workshop in Planning via a Graph Neural Network: The Case of an Ocean Engineering Manufacturing Intelligent Workshop. Appl. Sci. 2023, 13, 10134. https://doi.org/10.3390/app131810134
Li J, Yin W, Yang B, Chen L, Dong R, Chen Y, Yang H. Modeling of Digital Twin Workshop in Planning via a Graph Neural Network: The Case of an Ocean Engineering Manufacturing Intelligent Workshop. Applied Sciences. 2023; 13(18):10134. https://doi.org/10.3390/app131810134
Chicago/Turabian StyleLi, Jinghua, Wenhao Yin, Boxin Yang, Li Chen, Ruipu Dong, Yidong Chen, and Hanchen Yang. 2023. "Modeling of Digital Twin Workshop in Planning via a Graph Neural Network: The Case of an Ocean Engineering Manufacturing Intelligent Workshop" Applied Sciences 13, no. 18: 10134. https://doi.org/10.3390/app131810134