Abstract
Aiming at the low contrast of skin lesion image and inaccurate segmentation of lesion boundary, a skin lesion segmentation method based on multi-level split receptive field and attention is proposed. Firstly, the depth feature extraction module and multi-level splitting receptive field module are used to extract image feature information; secondly, the hybrid pooling module is used to build long-term and short-term dependencies and integrate global information and local information. Finally, the reverse residual external attention module is introduced to construct the decoding part, which can mine the potential relationship between data sets and improve the network segmentation ability. Experiments on ISBI2017 and ISIC2018 data sets show that the Dice similarity coefficient and Jaccard index reach 88.67% and 91.84%, 79.25% and 81.48%, respectively, and the accuracy reaches 93.89% and 96.16%. The segmentation method is superior to the existing algorithms as a whole. Simulation experiments show that the network has a good effect on skin lesion image segmentation and provides a new method for skin disease diagnosis.
1. Introduction
Skin cancer is the most common malignant tumor in human beings, including squamous cell carcinoma, basal cell carcinoma, malignant melanoma and malignant lymphoma, among which malignant melanoma is a skin disease with high mortality [1]. If melanoma is found and treated early, the cure probability is as high as 95%. However, the cure rate of melanoma found in the late stage is extremely low, and the mortality rate is as high as 85%. Thus, the early diagnosis and treatment of skin diseases is very necessary [2]. Nowadays, many doctors determine the lesion area of patients by naked eye observation or dermatoscope diagnosis. However, because hair and blood vessels will interfere with the diagnosis, even experienced doctors find it difficult to accurately segment the lesion area. Therefore, it is very necessary to introduce a computer-aided diagnosis (CAD) system to segment skin lesions, and it is of great significance for doctors to evaluate and diagnose clinically.
Skin disease segmentation methods include traditional segmentation methods and deep learning segmentation methods. Traditional segmentation methods focus on the original information of skin disease images, including threshold segmentation [3], region segmentation [4], edge segmentation [5] and support vector machine segmentation methods [6]. However, the skin lesion image segmentation model based on deep learning can adaptively learn image features without manual intervention so as to obtain accurate segmented images. These segmentation methods are superior to traditional segmentation methods and have become the mainstream methods in the field of skin lesion segmentation. The most common model structure in the skin disease segmentation model is encoder-decoder structure. The encoder part is used to extract the features of the input image, while the decoder restores the extracted feature map to the original image size and outputs the final segmentation result map. In order to improve the performance of skin disease segmentation, many scholars will improve the encoder-decoder structure and introduce some effective mechanisms to enhance the learning performance of the network, such as attention, residual structure and so on.
Zhou et al. [7] put forward a U-Net++ network in 2018, which introduced dense connections and added more hop connection paths to make up for the lack of information between codec and decoder. Huang et al. [8]] proposed a U-Net3+ network in 2020. In view of the deficiency that U-Net++ did not extract enough information from multiple scales, U-Net3+ used full-scale jump connection and deep supervision to improve this problem. Alom et al. [9] proposed an R2U-Net network architecture, which integrated the structures of U-Net, ResNet [10] and RCNN [11] and achieved good experimental results in many medical image segmentation tasks such as blood vessels, lungs and retina. Jin et al. [12] put forward the Residual Attention Perception Network, which added an attention mechanism to the U-Net network for the first time and used an attention mechanism to fuse low-level feature information and deep feature information, so as to extract the context information of the feature map and improve the segmentation effect. Sarker et al. [13] proposed a new segmentation network model by using extended residual and pyramid pooling. The encoding part uses an extended residual network to extract image feature information, and the decoding part uses pyramid pooling to reconstruct image information to obtain a segmented image.
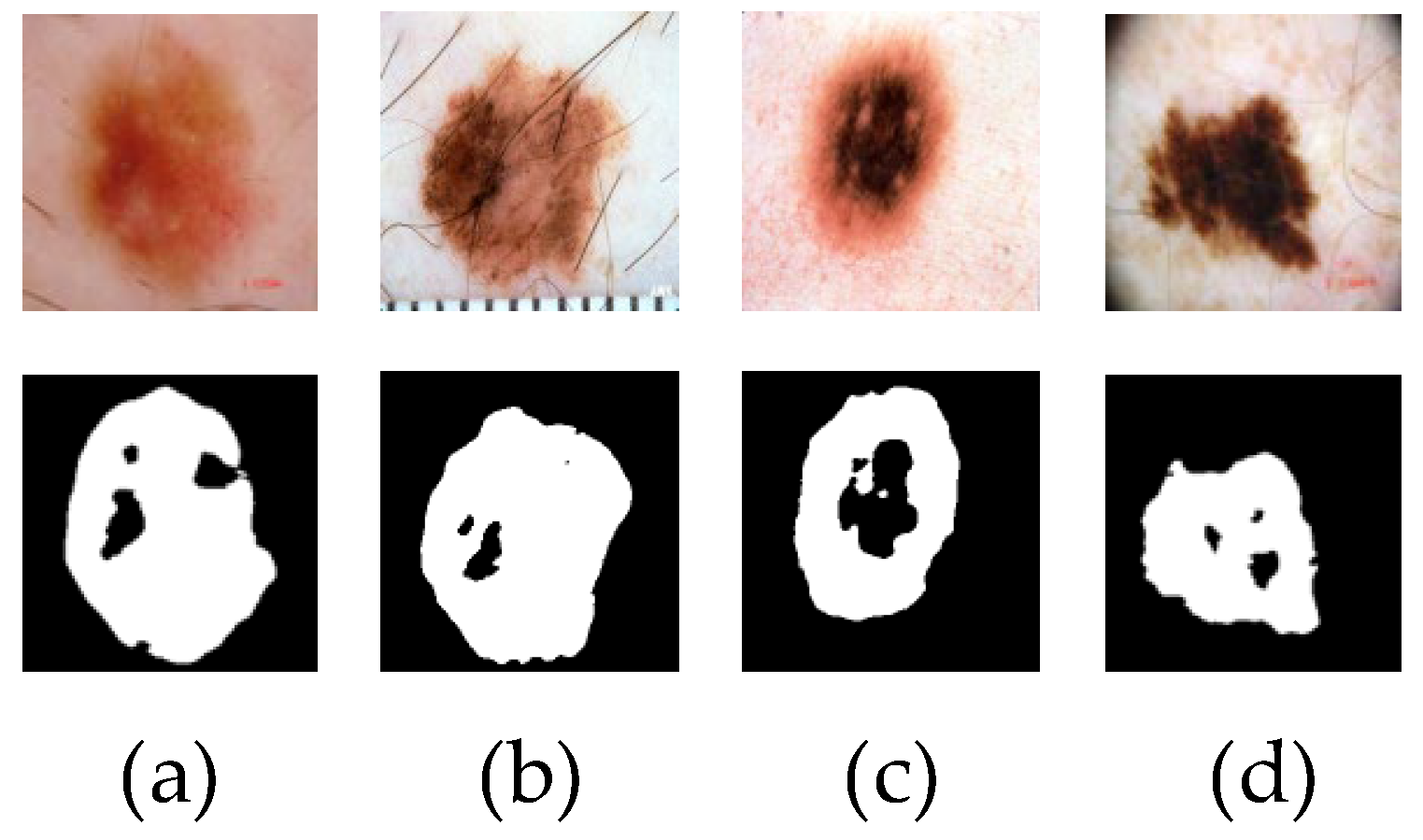
Although the above methods can effectively segment the lesion region, there are still some challenges that cannot be ignored, such as small lesions, similar lesion regions to the background, fuzzy edges and so on, which can easily cause the loss of local features of the lesion region in the segmentation process, resulting in poor segmentation results. Figure 1 shows the poor segmentation effect of skin disease images with blurred edges and similar lesion areas in some networks. Because of the lack of feature extraction ability of the input image, the network can not extract deep-level image information, resulting in the loss of feature information, which leads to inaccurate segmentation.
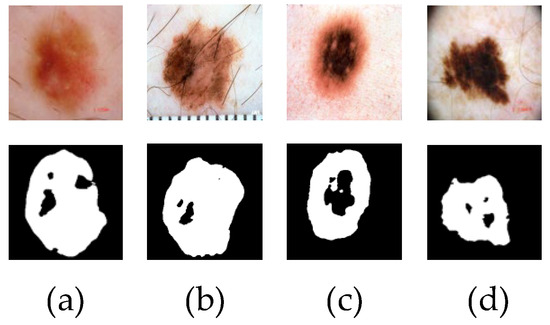
Figure 1.
The poor segmentation effect of skin disease images is displayed. Figures (a,b) are the results of poor U-Net network segmentation. Figures (c,d) are the results of poor CE-Net network segmentation.
In view of the above problems, this paper proposes an efficient skin lesion segmentation method based on multi-level split receptive field and attention. Firstly, the skin lesion images are preprocessed to remove foreign bodies such as hair and blood vessels and reduce their interference with lesion region segmentation. Secondly, the depth feature extraction module and multi-level split receptive field module are used to extract the global context information and local information of skin lesion images. Then, a hybrid pooling module is used in the bottleneck layer to aggregate the long-distance dependencies and short-distance dependencies in the image and to fuse the global information and local information of the feature map. Cascade can reduce the lack of feature map information and enhance the transmission between pixels. Finally, reverse residual external attention is introduced into the decoder to enhance the information association between samples, obtain the features of the whole data set, and recover the feature map information. The main contributions of this paper are as follows.
1. We propose an efficient skin lesion segmentation method based on a multi-level split receptive field and attention, which can segment lesion images efficiently;
2. A new depth feature extraction module and a multi-level split receptive field module are proposed to replace the traditional convolution feature map information extraction, which can extract the shallow information of the image more accurately and enhance the learning ability of the network;
3. In order to better integrate context information and local information, a hybrid pooling module is introduced;
4. A reverse residual external attention module is proposed to enhance the connection between data sets and improve the segmentation effect;
5. A large number of experiments have been carried out on the ISBI2017 data set and the ISIC2018 data set. The results show that the model can effectively segment the lesion area.
2. Related Works
Compared with deep learning, the traditional machine learning segmentation method is often cumbersome to implement, and doctors need to intervene manually according to their own prior knowledge and professional practical experience in the early feature selection process, which may lead to certain errors in doctors’ judgment due to some external factors. As a learning method based on pixel classification, the deep learning model no longer needs doctors to design features manually. The network can actively learn image-related features by selecting reasonable Loss functions and gradient descent algorithms through supervised learning. The method based on deep learning makes the segmentation results obtained by the network more objective and referential because there is not too much manual intervention.
Nowadays, deep learning networks have been widely used in medical image processing, among which convolution neural networks are the representative ones, which can be divided into two categories: traditional convolution neural networks and full convolution neural networks.
A traditional convolution neural network structure divides the input image into several image blocks and then predicts each image block through the model, whether it is inside or outside the target. Codella et al. [14] combine sparse coding, support vector machine and convolution neural network to realize accurate recognition of melanoma. However, traditional CNN has a fixed requirement for the input size of the network. Different data sets need to be preprocessed and post-processed, and a large number of parameters will be generated in the training process of the network, which occupies a large memory space. The full convolution neural network uses the convolution layer instead of the last full connection layer so that the network can accept any size input and reduce the complexity of the network. In 2015, Long et al. [15] first proposed a pixel semantic segmentation technology that allows arbitrary input size, called Fully Network (FCN). In the same year, Badrinarayanan et al. [16] proposed SegNet. Both of them are encoder-decoder segmentation methods. The encoder generates a low-resolution feature map and the decoder samples it to restore it. Finally, the Softmax classifier is used to predict the segmentation area. In 2015, Chen et al. [17] put forward Deeplab and then put forward the last three versions one after another. In view of the neglect of small objects in convolution networks and the multi-scale problems, the Deeplab series successively replaced different pre-training models, introduced extended convolution, hole convolution and ASPP layers, and finally made organic combinations. Ronneberger et al. [18] proposed a new scroll integral cut method called U-Net in 2015, which is a modification and extension of the FCN structure. The whole network has a U-shaped symmetric structure, with an encoder on the left side, including four convolution layers, and a decoder on the right side, including four upsampling layers corresponding to the encoder. The feature map of each convolution layer will pass through the skip connection layer. Nowadays, the U-Net structure has been widely used in medical image lesion segmentation tasks.
In recent years, the deep learning method has been applied to the field of skin lesion segmentation. In 2017, the improvement of the U-Net variant and U-Net encoder using pre-training appeared frequently. B.S. Lin et al. [19] give a comparison of two skin lesion segmentation methods based on a U-Net histogram equalization and C-means clustering. Y. Yuan et al. [20] used the ISBI2017 data set to propose a skin lesion segmentation method using different color spaces of dermatoscope images as training depth convolution-deconvolution neural network (CDNN). N. C. Codella et al. [21] made an integrated system combining traditional machine learning methods with deep learning methods.
Schlemper et al. [22] proposed an Attention Gate (AG), which integrates an attention mechanism into U-Net. Through attention learning, it can automatically focus on target structures in different areas, highlight prominent target areas, and reduce the influence of irrelevant background areas in input images on feature extraction. Li Haixiang et al. [23] designed a dense deconvolution network based on encoding and decoding modules.
The generated confrontation network began to play a role in the field of medical images in 2019. Bi et al. [24] proposed an automatic segmentation method of skin lesions based on antagonistic learning, which uses data enhancement methods such as rotation, masking and cropping to expand data. Then, the features extracted from the convolution operation in the encoder and decoder are deeply fused, which improves the segmentation performance of the network to a certain extent. L. Canalini et al. [25] designed a codec architecture with multiple pre-trained models as feature extractors. They explored multiple pre-trained models to initialize feature extractors without using bias-induced data sets. A codec segmentation structure is adopted to utilize each pre-trained feature extractor. Additional training data is also generated by Generating Countermeasure Network (GAN).
Semi-supervised learning will gradually expand in 2019. The purpose of semi-supervised learning is to greatly alleviate the problems caused by the lack of large-scale labeled data by allowing the model to use the available massive unlabeled data. Semi-supervised network skin detection based on mutual guidance designed by He Yaying et al. [26] and R. Dupre et al. [27] improved data set capacity and model accuracy by semi-supervised iterative self-learning. In 2021, Wu [28] et al. proposed a skin disease segmentation method based on an adaptive dual attention module and proposed a new and efficient adaptive dual attention module, which integrated two global context modeling mechanisms into the module and could extract more comprehensive and discriminating features to identify the boundaries of skin lesions. Hritam [29] et al. proposed a multifocal segmentation network for skin lesion segmentation in 2022. The final segmentation mask is calculated by using feature maps with different proportions, and the Convolutional Neural Network (CNN) Res2Net backbone is used to obtain the depth features used in the parallel partial decoder module to obtain the global mapping of the segmentation mask.
3. Materials and Methods
3.1. Data Sets
This paper uses the ISBI2017 data set [30] and the ISIC2018 data set [31] as experimental samples. The ISBI2017 data set contains 2000 training pictures, 150 verification pictures and 600 test pictures. The ISIC2018 data set contains 2594 training pictures, which are randomly divided into training set, test set and verification set according to the ratio of 7:2:1, including 1815 training set pictures, 518 test set pictures and 260 verification set pictures.
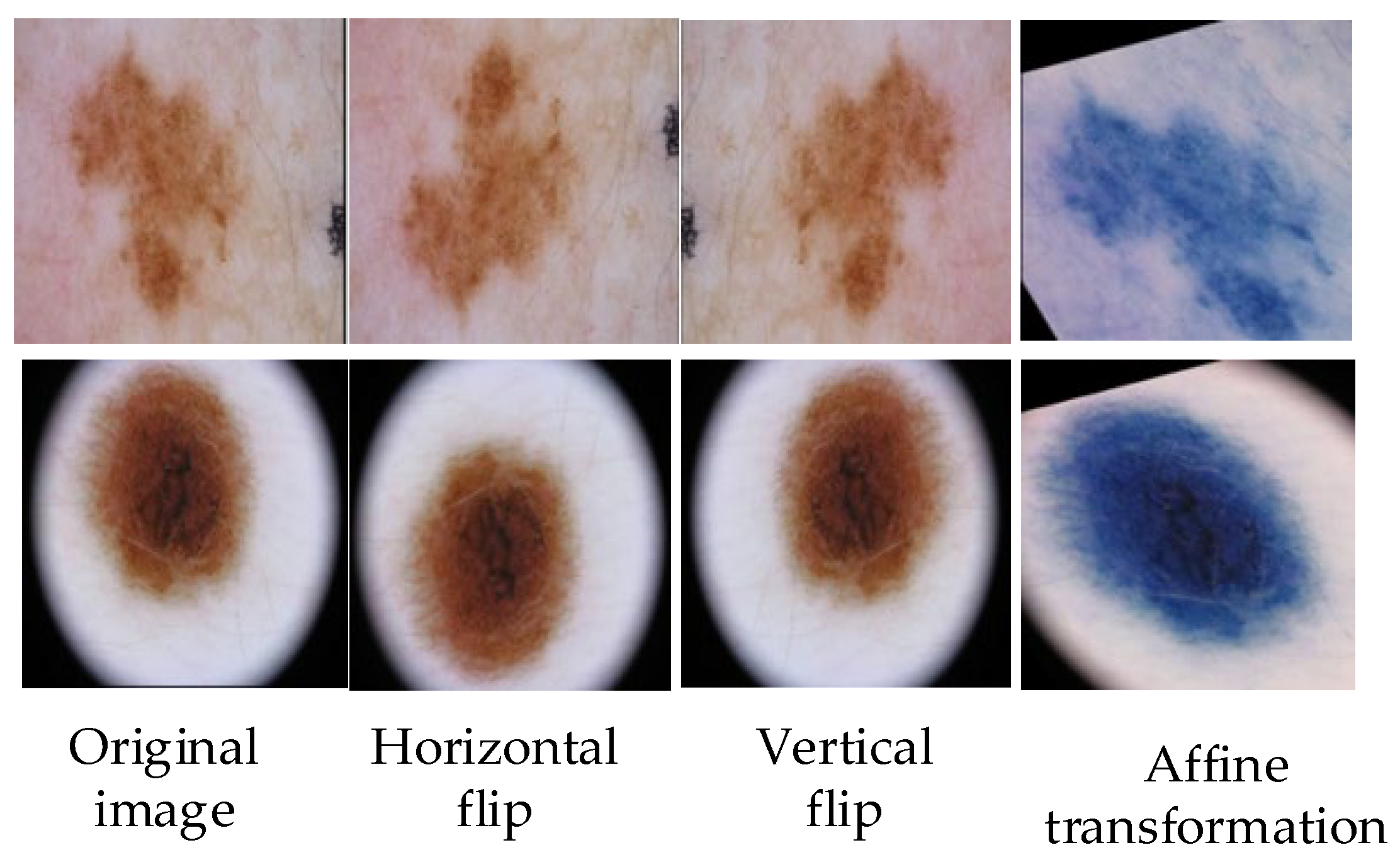
The images of skin diseases in the existing data sets are not all clear; some images will be blocked by hair vessels, and some images will have fuzzy blocks in the lesion areas, which will affect the whole training process. Because of the small number of pictures in the available data set, in order to avoid over-fitting in the training process, it is necessary to expand the existing data set for preprocessing. The methods of data set expansion include grayscale transformation, horizontal flipping, elastic transformation, vertical flipping, etc., and the input skin disease images are uniformly cut to 256 × 256 pixels [32]. The operation of the image preprocessing part is shown in Figure 2.
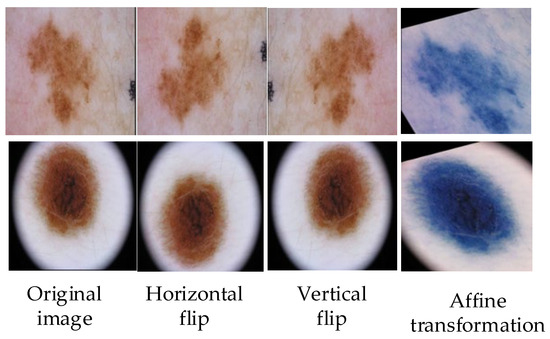
Figure 2.
Partial operation of image preprocessing, such as horizontal flipping, vertical flipping, and affine transformation.
3.2. Methods
3.2.1. Overall Network Structure
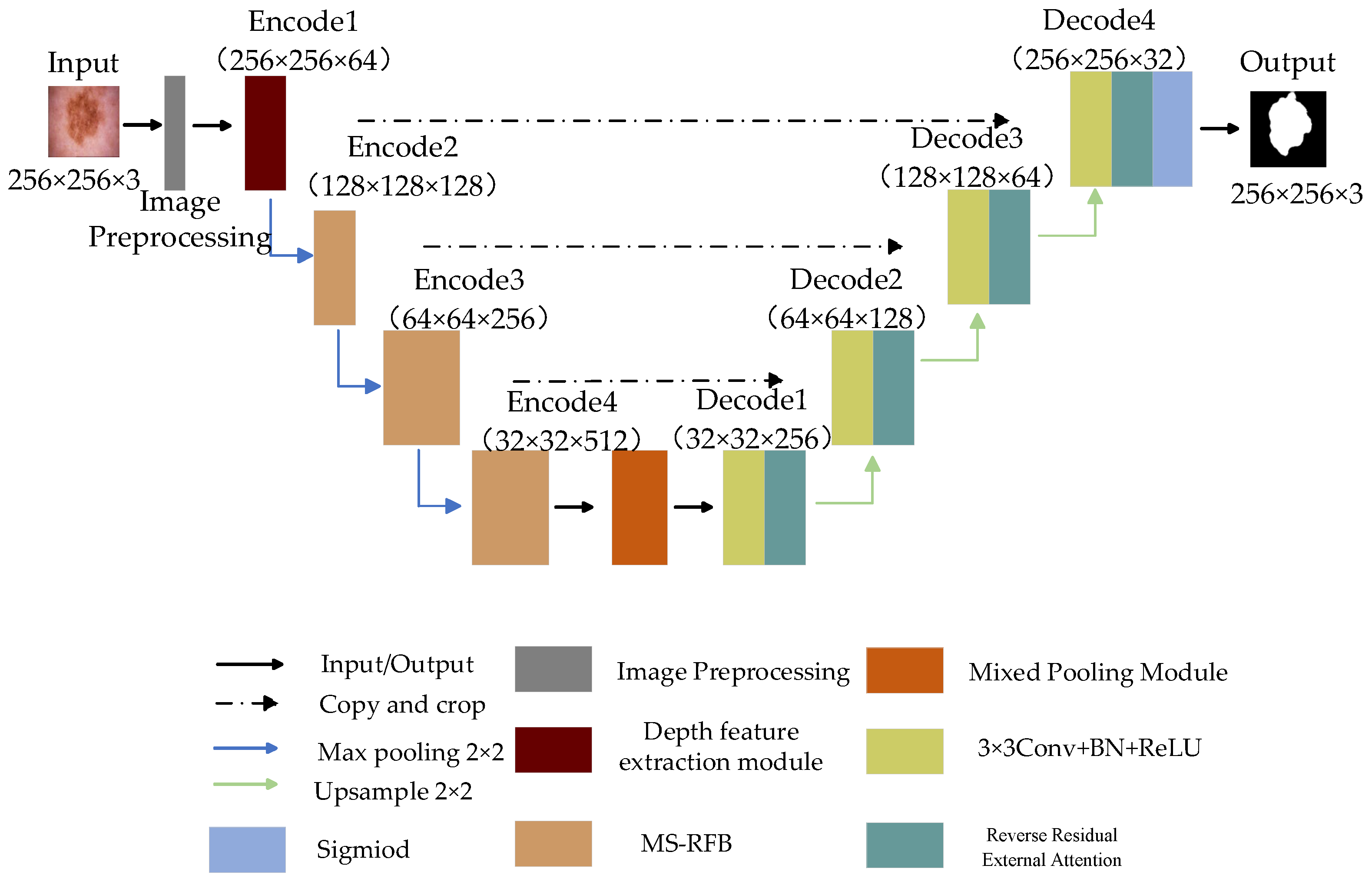
The structure of the skin disease image is complex; the image feature information is easily lost in the segmentation process, and the lesion area will be mistakenly segmented. In order to improve the segmentation accuracy, this paper proposes an efficient skin disease segmentation method based on multi-level split receptive field and attention. The network structure is shown in Figure 3.
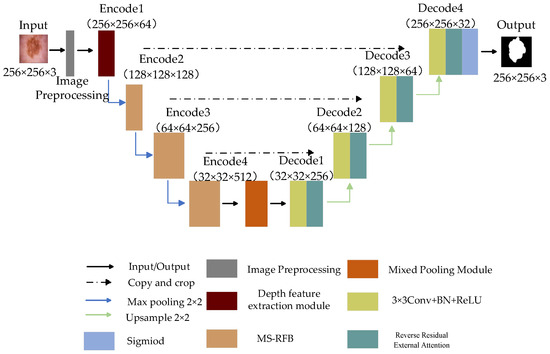
Figure 3.
The proposed network structure diagram.
The whole network consists of front-end image preprocessing, encoder, decoder and bottleneck layer. The encoder is implemented by a depth feature extraction module and multi-level splitting receptive field module. The first layer feature extraction of the encoder is realized by the depth feature extraction module, which extracts the feature information of the input picture by depth separable convolution, and the other coding parts capture the information of the feature map by multi-level split receptive field module. The introduced split block can extract more scale features, remove redundant feature information and improve the generalization ability of the model. The decoder part is used to reconstruct the feature map information, introduce reverse residual external attention to the decoder, mine the potential relationship between the whole data set, enhance the connection between samples, and obtain a clearer segmented image. The hybrid pooling module transmits the image information data between the encoder and decoder and captures the global and local information of the feature map through pyramid pooling and fringe pooling, thus forming the long-short dependence between target features. Finally, the Sigmoid activation function and Focal Tversky Loss function are used to obtain the final segmentation results.
3.2.2. Depth Feature Extraction Module
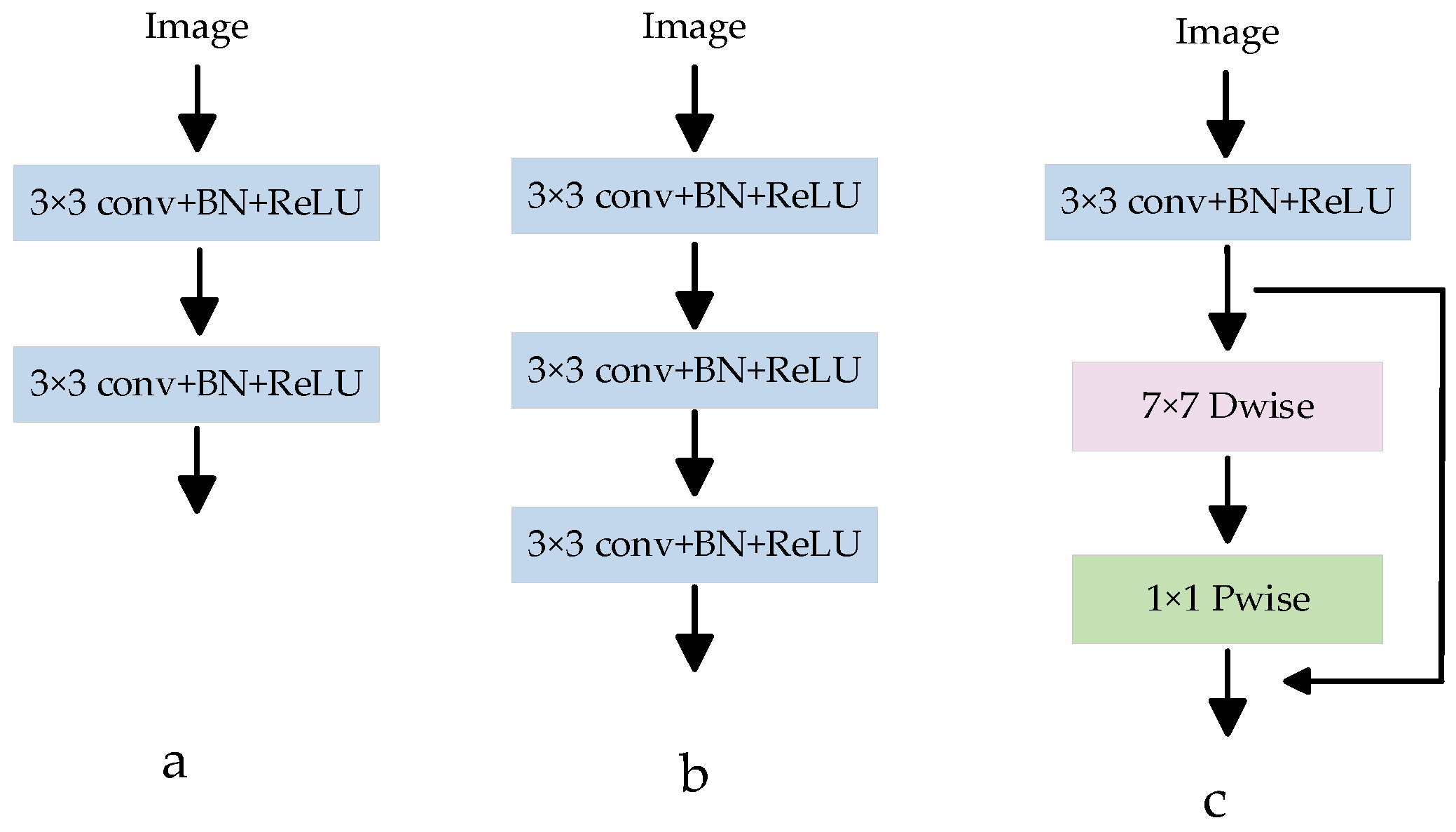
In most medical image segmentation networks, the down-sampling operation is usually used to extract low-level semantic information from images. The down-sampling operation block structure in the U-Net network has been widely used in different medical segmentation models. As shown in Figure 4a, this module is connected by two consecutive CBRs (Conv 3 × 3 + BN + ReLU), and ordinary convolution is used to extract image features. In order to obtain a larger receptive field and extract a more effective feature map, a CBR3 × 3 + BN + ReLU convolution is usually superimposed on the basis of Figure 4a, and the structure is shown in Figure 4b. However, if the convolution is stacked blindly, the effective receptive field will decrease to a certain extent, and at the same time, the number of parameters will increase, and the amount of calculation will increase. To solve this problem, a depth feature extraction module is proposed, as shown in Figure 4c. Depth separable convolution is introduced, and a new feature map with the same number of input feature channels is obtained by using 7 × 7 channel-by-channel convolution, and then the feature map output is obtained by convolution operation with the obtained new feature map through 1 × 1 point-by-point convolution [33]. Compared with ordinary convolution, depth separable convolution can extract deeper feature information and reduce the number of network parameters. At the same time, a residual connection is introduced to avoid gradient disappearance and improve network performance. The depth feature extraction module can reduce network parameters, improve network performance, and extract image semantic information more accurately.
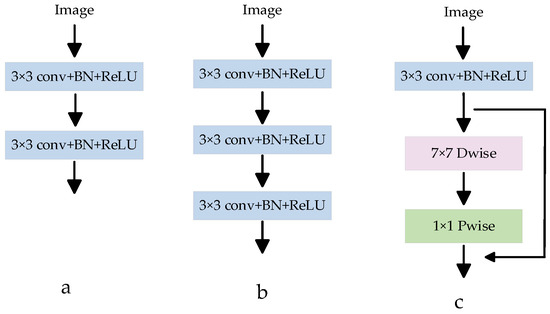
Figure 4.
Various feature extraction modules. (a) Is a common feature extraction module CBR (Conv 3 × 3 + BN + ReLU); (b) Is a CBR superimposed on A in order to extract a more effective feature map; (c) Is the proposed depth feature extraction module.
3.2.3. Multi-Level Split Receptive Field Module
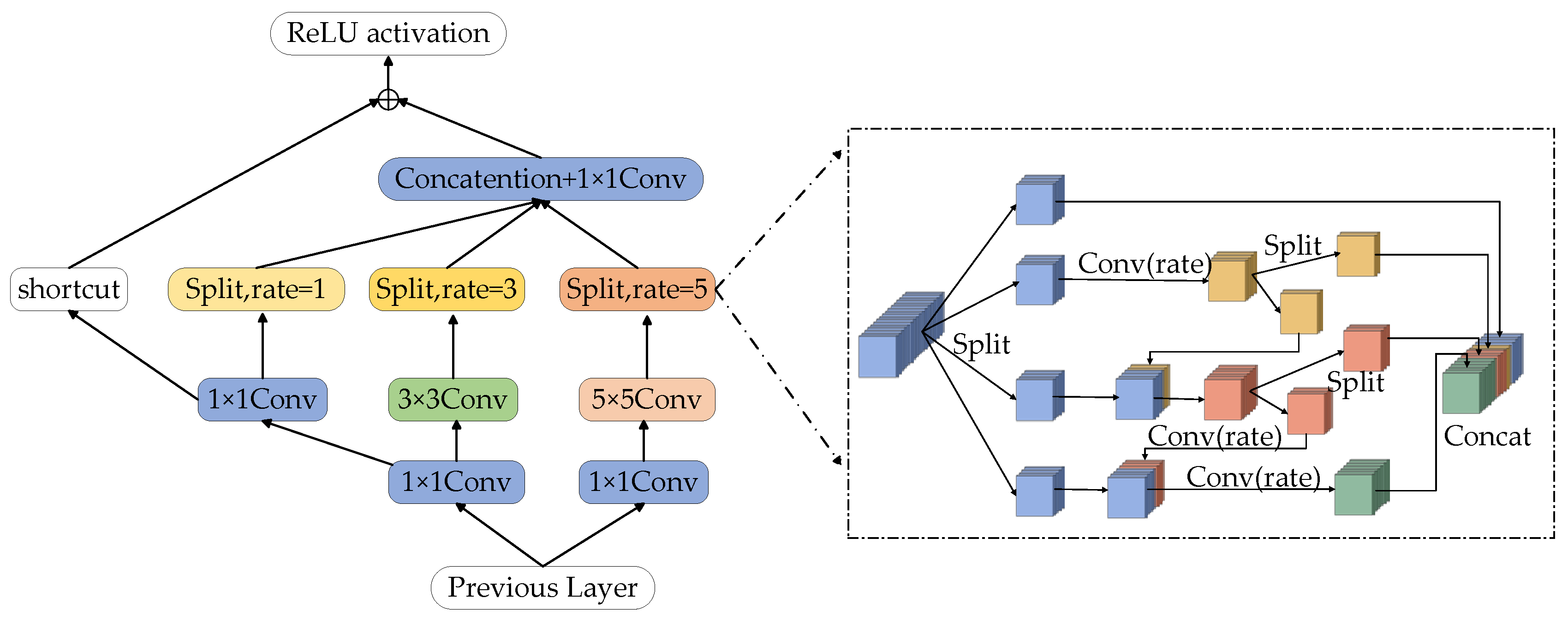
The receptive field (RFB) module is composed of convolution layers with different convolution kernel expansion speeds, which can obtain more capacity information in shallow feature maps and enhance the feature representation of the network [34]. However, the original RFB module’s real-time algorithm feature expression ability is not strong, which easily leads to poor segmentation effects. Inspired by the Ghost-Net network [35], this paper designs a multi-level Split Receptive Field Block (MS-RFB), and its structure is shown in Figure 5. The whole structure refers to the pyramid structure of convolution and pooling in empty space. Each branch is reduced by a 1 × 1 convolution layer, followed by n × n convolution, in which the 5 × 5 convolution layer is replaced by two 3 × 3 convolution layers in actual use to reduce parameters and obtain deeper nonlinear layer [36]. After the convolution layer, the multi-level split convolution with diffusivity of 1, 3 and 5 is connected to capture the feature map information, and a shortcut is adopted to avoid the loss of feature details after multiple convolutions. Finally, the output results will be spliced together by the column.
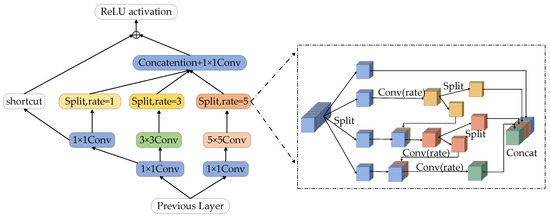
Figure 5.
Multi-level split receptive field module.
After the feature map passes through the convolution layer, the multi-level split convolution is connected to obtain the feature map information. The feature map of each branch will be divided into 4 groups and each group has w channels. The first group of feature maps is directly connected to the next layer, the second group of feature maps is extracted by a 3 × 3 convolution, and then the feature map is divided into two sub-blocks in the channel dimension. The feature mapping of one sub-group is directly connected to the next layer, while the other sub-group is connected with the next group of input feature maps in the channel dimension. The connected feature maps are operated by a set of 3 × 3 convolution filters. Repeat the above process until all input feature mappings are processed. Finally, all feature maps are connected and input into a 1 × 1 convolution to reconstruct features. The MS-RFB module can better extract the global information of the image, improve the network training efficiency and the accuracy of network segmentation.
3.2.4. Mixed Pooling Module
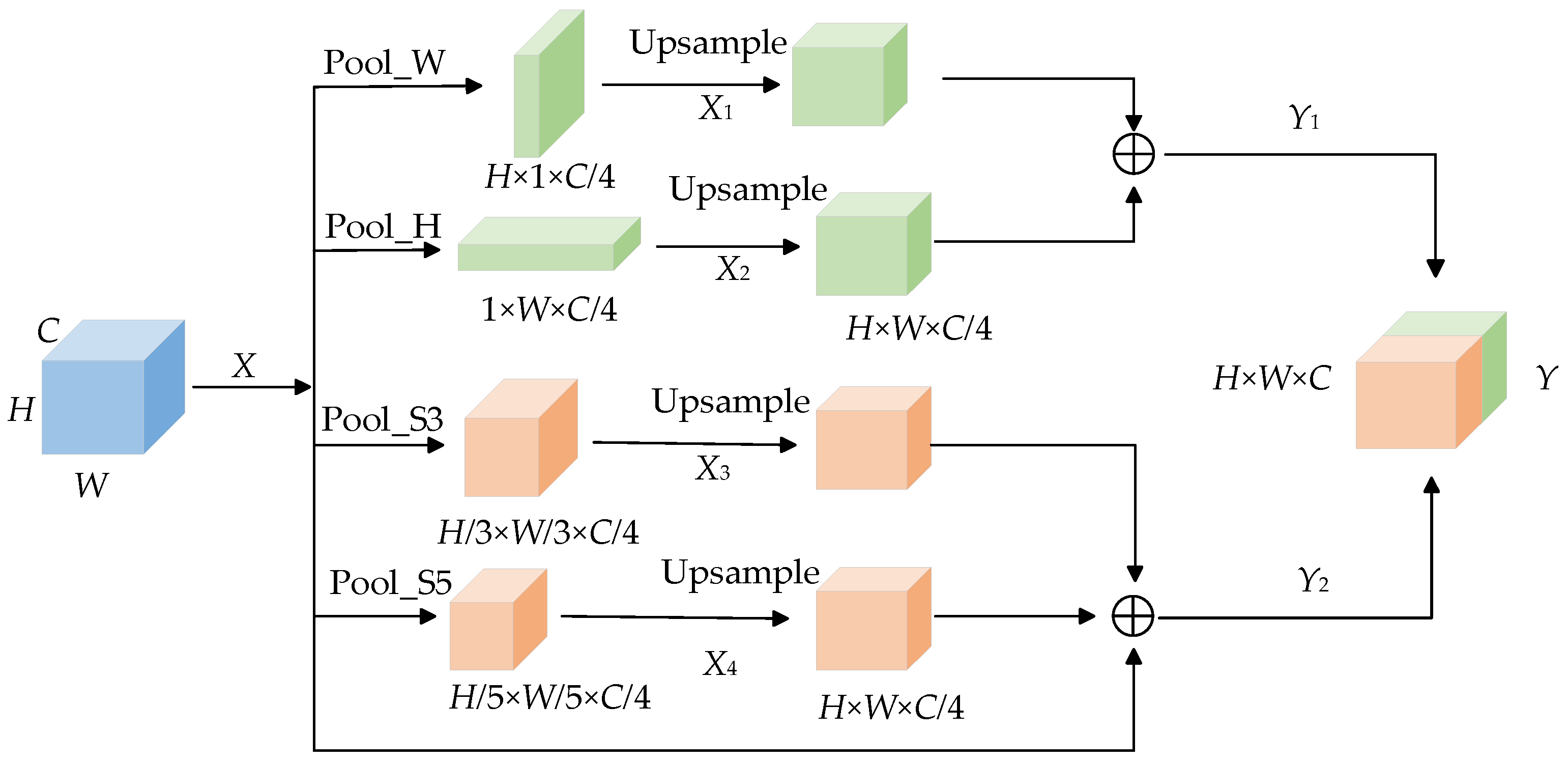
In the original U-Net network, the skin lesion image is down-sampled by the encoder and then directly input to the decoder to restore the features and obtain the segmented image. However, this kind of operation will make the deep feature map unable to obtain enough receptive field, resulting in a lack of deep information. The Mixed Pooling Module [37] (MPM), which is composed of pyramid pooling [38] and strip pooling [39], can effectively enlarge receptive fields, obtain deep semantic information and capture remote dependencies. The two sub-modules of the hybrid pooling module capture the short-distance and long-distance dependencies between different locations at the same time. Among them, the stripe pooling layer is used to capture the local context information of the feature graph and establish the long-distance dependency relationship through repeated aggregation. Pyramid pooling is used to capture global context information and establish short-distance dependencies. Figure 6 shows the structure diagram of the Mixed Pooling Module.
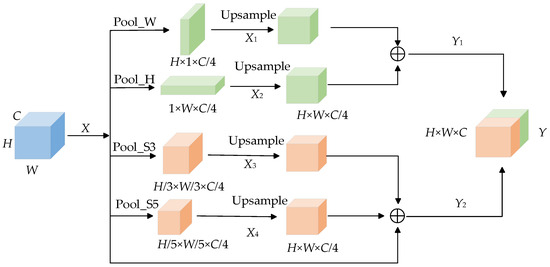
Figure 6.
Mixed Pooling Module.
In Figure 6, the skin disease feature map is , C represents the width of the feature map, H represents the height of the feature map, W represents the number of channels of the feature map, Pool_S3 and Pool_S5 represent spatial pyramid pooling with convolution kernel sizes of 3 × 3 and 5 × 5, and Pool_H and Pool_W represent horizontal pooling and vertical pooling. In order to improve the extraction of feature information, each branch of the hybrid pooling module is carried out separately. Feature map uses Pool_H and Pool_W to compress the feature map in horizontal and vertical directions, respectively, to obtain feature map and , then, restores the feature map by up-sampling, captures the long-distance dependence, and splices the two new feature maps to obtain . Feature maps and are compressed by Pool_S3 and Pool_S5. After up-sampling, the size of the feature map is reduced to obtain a new feature map and then is spliced with the original feature map. and are spliced to obtain the final output. The hybrid pooling module realizes the fusion of global information and local information of the feature map and establishes the long-short distance dependence relationship.
3.2.5. Reverse Residual External Attention
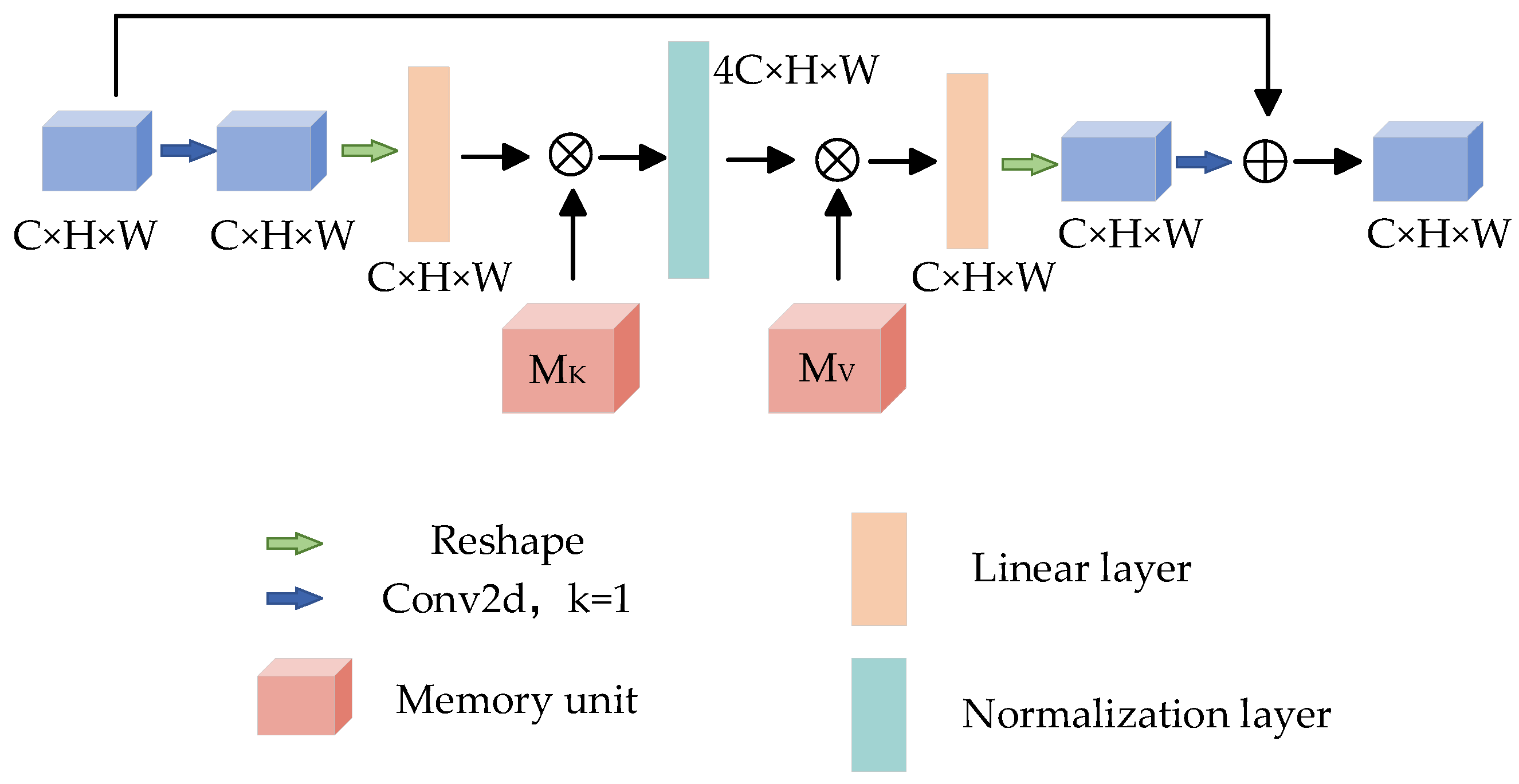
The attention mechanism has been the focus of deep learning in recent years. This method simulates the different emphases when people receive picture information and has made great breakthroughs in the field of deep learning. The attention mechanism has achieved good results in many tasks. By learning the weight of the feature map, the greater the weight, the more important the feature of the corresponding pixel. In order to obtain more accurate segmentation results, Reverse Residual External Attention (RREA) is introduced at the decoding end to mine the potential relationship between data and improve the generalization ability of the model. The structure is shown in Figure 7.
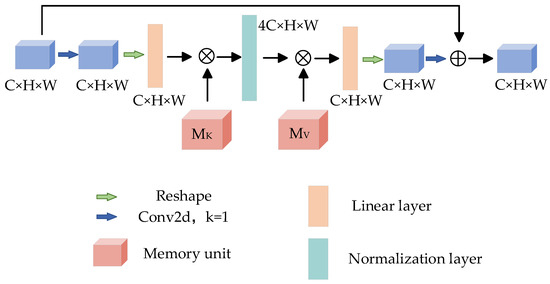
Figure 7.
Reverse residual external attention.
External memory units and are composed of two linear layers [40], which act as memories of the whole training data set, and their corresponding processes can be expressed as:
where Norm represents the standardization process; A is the attention map inferred from the data set, and the parameters in and are updated according to the similarity in A; is the module output.
Given a feature map input , after 1 × 1 convolution and shaping operation, the size of the feature map changes to , and the memory unit is used to expand the feature map 4 times to obtain , then the memory unit is used to restore the dimension, and then the reconstruction operation is carried out to restore the original feature map size. Finally, the feature map is obtained by 1 × 1 convolution, and the output feature map is obtained by residual connection [41]. It is worth noting that the number of channels between the two storage units of the reverse residual external attention module is no longer a fixed 64 channels, but a 4-fold expansion channel is adopted. Its advantage is that the memory unit maps the input to a higher dimensional space so that the memory unit can describe the overall feature information of the data set more comprehensively and implicitly consider the correlation among all data samples.
3.2.6. Focal Tversky Loss Function
The Dice Loss function [42] is often used in skin lesion segmentation tasks to alleviate the influence of imbalance between categories, but it can not optimize the weight of false negative and false positive, which leads to higher accuracy of final results and lower recall rate. The Tversky Loss function [43] can balance false negatives and false positives, and optimize the relationship between precision and recall, but some skin lesion images have a small Region of Interest (ROI), which is difficult to distinguish. Therefore, the Focal Tversky Loss function [44] based on the original Loss function is constructed by a super-parameter, which enhances the recognition degree between the lesion region and the smaller region of interest and better adapts to the segmentation task of unbalanced pixel ratio between foreground (lesion skin) and background (normal skin). The new Loss function is defined as:
where means true positive and correctly classifies the number of pixels in the skin lesion areas; means true negative and correctly classifies the number of pixels in non-skin lesion areas; denotes the number of pixels in false positive and misclassified skin lesion areas; denotes the number of pixels in false negative and misclassified non-skin lesion areas. Parameters a and b are used to adjust the weight of false negatives and false positives to alleviate the influence of imbalance between categories; the Super Parameter is used to suppress ROI interference. In the Focal Tversky Loss function, parameter α is set to 0.7, and parameter β is set to 0.3, Super Parameter Gamma is set to 0.75.
4. Results
4.1. Experimental Environment and Parameter Setting
All experiments in this paper are completed by the Windows 10 operating system and Pycharm simulation platform. The detailed experimental environment configuration is shown in Table 1. Adam (adaptive moment estimation) algorithm is selected to optimize the Focal Tversky Loss function in the training model [26], and the training batch is set to 8, the initial learning rate is set to 1 × 10−5, and the iteration times are set to 200.

Table 1.
Experimental environment configuration.
4.2. Model Evaluation Index
In order to evaluate the performance of skin disease image segmentation models in clinical settings, the usual approach is to use several standard indicators for evaluation. In our paper, the performance of this model and contrast model is evaluated by using some common indexes in the field of medical images, such as Accuracy (Acc), Dice Similarity Coefficient (Dice), Jaccard Index (Jac), Specific (Spe) and Sensitivity (Sen) [45]. Each indicator is defined as:
where , , and are true positive, true negative, false positive and false negative, respectively. Acc is the accuracy rate, which indicates the proportion of correctly segmented focus pixels and non-focus pixels in the total image pixels; Dic is the Dice coefficient, which represents the similarity between segmentation results and tags; Jac is the Jaccard coefficient, which indicates the pixel ratio of correctly segmented lesion pixels on the union of label and predicted image; Spe is Specific, which indicates the proportion of correctly segmented non-focus pixels in actual non-focus pixels; Sen is Sensitivity, which indicates the proportion of correctly segmented lesion pixels in actual lesion pixels. By calculating the five indexes of the predictive mask and the real mask for each case in the real data set, we can evaluate the performance of the proposed algorithm.
4.3. Ablation Test
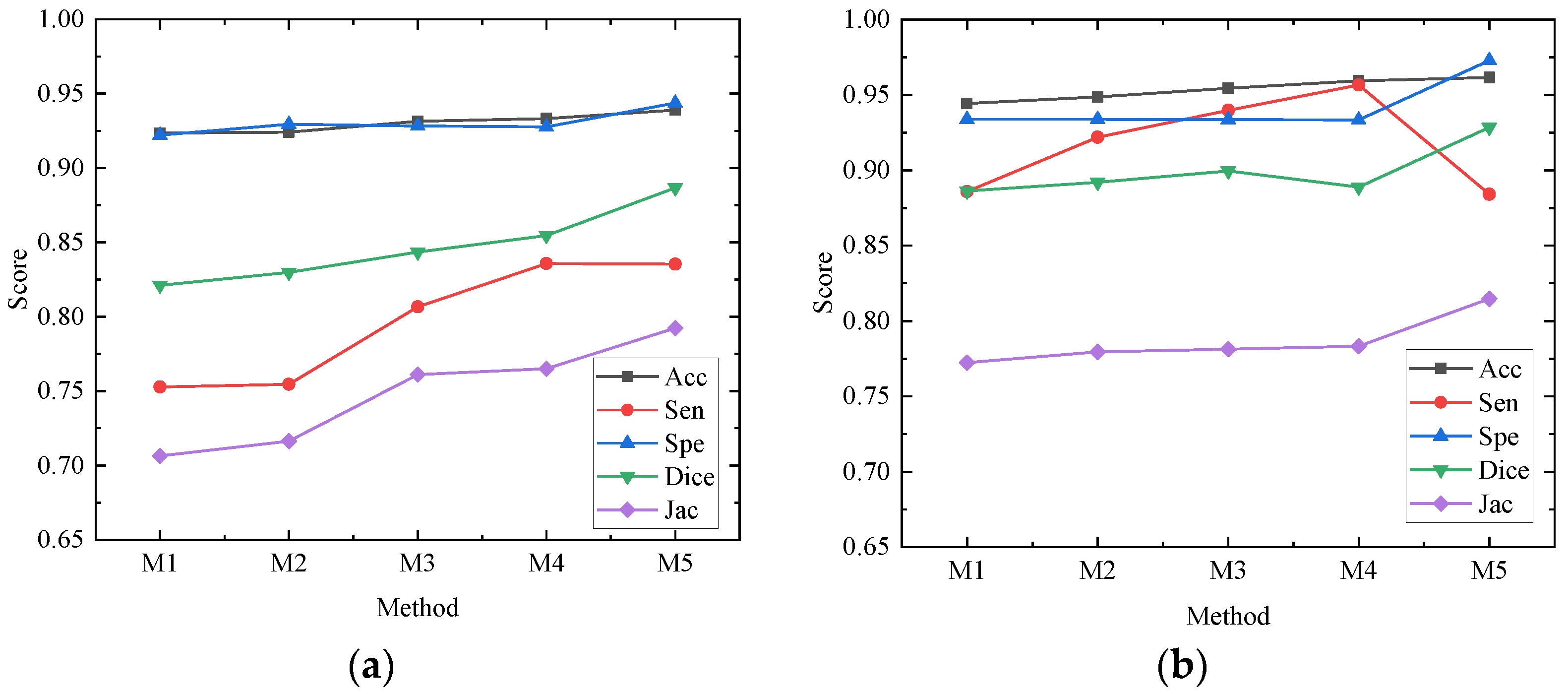
In order to better evaluate the impact of each module of the network on the whole network structure, our paper conducts ablation experiments on the ISBI2017 data set and the ISIC2018 data set, all of which are in the same environment and use 50% cross-validation. The models participating in the ablation experiment are recorded as M1, M2, M3, M4 and M5, respectively. M1 is the basic network architecture of U-Net. M2 replaces the first feature extraction layer with the depth feature extraction module shown in Figure 4c on the basis of M1; M3 replaces the feature extraction layer of the remaining layer of the encoder with the MS-RFB module on the basis of M2; M4 adds a hybrid pooling module on the basis of M3; M5 combines M4 to introduce a reverse residual external attention module on the decoder, that is, the algorithm proposed in this paper. The experimental results are shown in Table 2 and Table 3. Figure 8 draws the ablation experimental results of the ISBI2017 data set and the ISIC2018 data set into a line chart, from which we can see more accurately the performance enhancement of each module to the network.
Table 2.
Ablation experiment of each module on ISBI2017 data set.
Table 3.
Ablation experiment of each module on ISIC2018 data set.
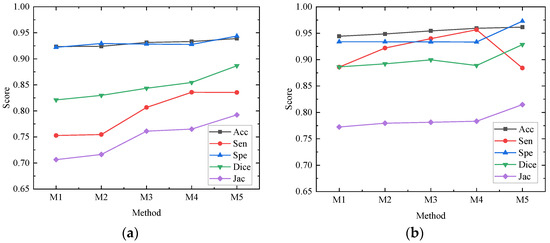
Figure 8.
Performance of each module in ablation experiment on different data sets. (a) Performance of each module of ablation experiment on ISBI2017 data set; (b) Performance of each module of ablation experiment on ISIC2018 data set.
Ablation research shows the specific role of each module, among which M1 is the result of the U-Net network, and M2 has improved various evaluation indexes, but the change is too small to achieve a better segmentation effect. Acc, Sen, Dice and Jac in the ISBI2017 and ISIC2018 data sets in M3 are improved by 0.79% and 1%, 5.39% and 5.38%, 2.25% and 1.32%, 5.47% and 0.89%, respectively; the overall performance of the network is improved, which shows that the MS-RFB module can extract the feature information of images more accurately, and the split block module can greatly increase the receptive field, reduce network computation and improve segmentation effect. The Sensitivity index of M4 is the highest among all experiments, reaching 83.58% and 95.67%, which shows that the hybrid pooling module can realize the fusion of deep information and shallow information and transmit more information to the decoder. By adding a reverse residual external attention module, M5 mines the potential relationship between data sets, enhances the information association between samples, and obtains more effective feature information. Dice similarity coefficient and Jac are greatly improved, and the segmentation accuracy reaches 93.89% and 96.16%. The results of ablation experiments show that the MS-RFB module can effectively increase the diversity of features and generalization of the model, the hybrid pooling module can improve the sensitivity of the network, and the reverse residual external attention module is used to improve the Dice similarity coefficient and Jac index.
4.4. Comparative Experiment
4.4.1. Comparison on the ISBI2017 Data Set
In order to verify the reliability and effectiveness of the proposed network for skin lesion image segmentation, we select U-Net, a semantic image segmentation encoder based on separable convolution (DeepLabv3+) [46], a context encoder network for two-dimensional medical image segmentation (CE-Net) [47], and a context pyramid fusion network for medical image segmentation (CPF-Net) [48] to compare the indexes with the proposed network.
The U-Net network structure is symmetrical. The left and right codecs are symmetrical and connected by a bottleneck layer. The encoder extracts image features by downsampling and the decoder reconstructs the feature map to restore the target size and obtain the segmentation result. Based on the U-shaped network, CE-Net proposes a context extraction module composed of dense hole convolution and residual multi-core pool blocks, which are applied to different two-dimensional medical image segmentation tasks. DeepLabv3+ combines the advantages of encoding and decoding structure and spatial pyramid pooling structure, expands the decoding module of DeepLabv3, and improves the processing ability of model boundary information. CPF-Net combines a global pyramid guidance module and a scale-aware pyramid module to fuse global context information. The above five networks are tested in the same experimental environment; the comparison results are shown in Table 4 and the optimal index is indicated in bold.
Table 4.
Different network results on ISBI2017 data set, bold denotes the best result.
Table 4 gives the performance index of this network and the other four comparison networks on the ISBI2017 data set. A comprehensive comparison shows that our algorithm has better performance. Among the five networks, our algorithm accuracy of this network is the highest, which is 93.89%. The accuracy represents the ratio of correctly estimated samples to the total number of samples, which shows that this network has the best performance for skin disease image segmentation. The Dice similarity coefficient is used to evaluate the coincidence between the segmented image and the tag image. The Dice similarity coefficients of the proposed algorithm reach 88.67%, which shows that the segmentation results of this network are more similar to the tag results. Our algorithm excels in all other metrics except for slightly lower Spe than DeepLabv3+.
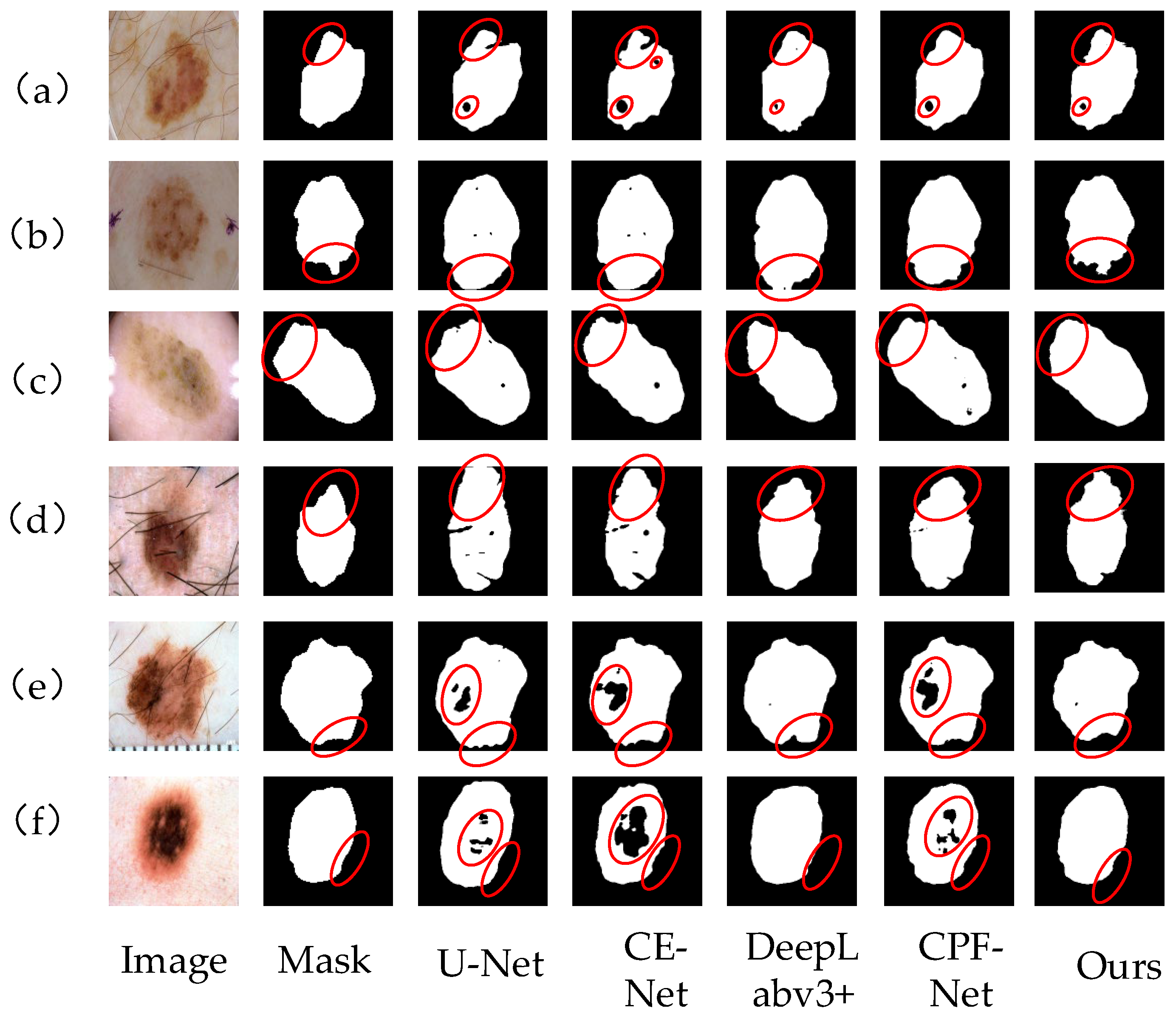
Figure 9 shows the segmentation results of skin lesion images on the ISBI2017 data set by different networks. From left to right, the images are Image, mask, U-Net segmentation results, CE-Net segmentation results, DeepLabv3+ segmentation results, CPF-Net segmentation results and the segmentation results of our algorithm. Comprehensive analysis shows that this network performs better than other networks. In Figure 9a,d,e, there are a large number of hairs and U-Net and CE-Net are affected by hairs, so the segmentation of the lesion area is not accurate enough, and the contour segmentation is poor. For Figure 9b,c, which have similar lesion regions and backgrounds, the proposed network can clearly segment their contours, better deal with the edge information, reduce the influence of hair on the segmentation effect, and have stronger robustness. In general, our method in the segmentation of various skin lesions, because of other methods, can better deal with the occlusion of hair and blood vessels and can better segment the lesion area for doctors to provide a reference for diagnosis.
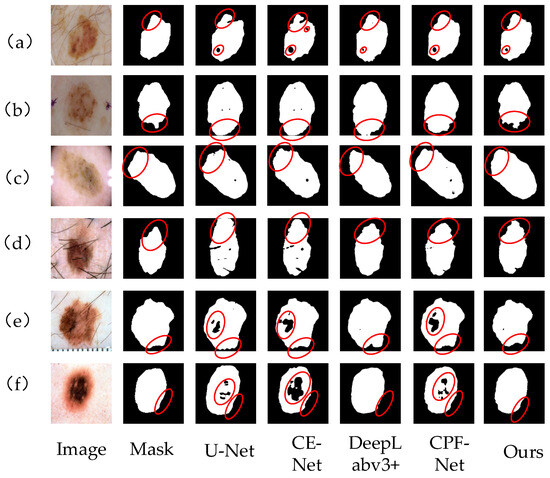
Figure 9.
Different network segmentation results on ISBI2017 data set. Images (a–f) represent 6 different images of skin diseases. From left to right, the images are Image, mask, U-Net segmentation results, CE-Net segmentation results, DeepLabv3+ segmentation results, CPF-Net segmentation results and the segmentation results of our algorithm. Details of each network partition are shown in red circles.
Table 5 is an objective comparison between this network and other reference networks on the ISBI2017 data set. In this paper, MSREA-Net is the best in Dice and Jac, and Acc ranks second. The DAGAN network uses dense extended convolution blocks to generate depth representation that retains fine-grained information. In addition, two discriminators are used to jointly determine whether the discriminator input is true or false. CMM-Net mainly fuses the global context features of multiple spatial scales at each shrinking convolution network level of U-Net. In addition, an extended convolution module is developed, which can expand the acceptance fields at different rates according to the size of feature maps in the whole network and obtain larger acceptance fields to obtain high-resolution feature maps and improve the segmentation accuracy. In this paper, the reverse residual attention of the network, by mining the potential relationship between data sets, is that the network pays more attention to the lesion area, making the Dice similarity coefficient and Jac index the highest. By comprehensive comparison, our proposed network can fully extract feature information and accurately locate the lesion area and has a better segmentation effect on skin disease images.
Table 5.
Objective comparison of different networks on ISBI2017 data set.
4.4.2. Comparison on the ISIC2018 Data Set
This section describes in detail the comparative experiments on the ISIC2018 data set to test the reliability and effectiveness of the proposed network. Table 6 shows the performance index of this network compared with the other four networks, and the best results are indicated in bold. It can be seen from the table that the MSREA-Net model has the best performance in three of the five evaluation indexes, which shows that our algorithm has better performance in skin disease segmentation and can segment the lesion area more accurately. The MSREA-Net model is the best in Acc, Spe and Dice, which are 0.9616, 0.9729 and 0.9284, respectively. Compared with the U-Net network, the MSREA-Net model is 0.0172, 0.039 and 0.042 higher than the U-Net network, respectively. Acc accuracy indicates the ratio of correctly estimated samples to the total number of samples, which shows that this network has the best performance for skin disease image segmentation. The Dice similarity coefficient is used to evaluate the coincidence between the segmented image and the tag image. The Dice similarity coefficient of the algorithm proposed in this paper reaches 0.9248, which shows that the segmentation results of this network are more similar to the tag results.
Table 6.
Different network results on ISIC2018 data set, bold denotes the best result.
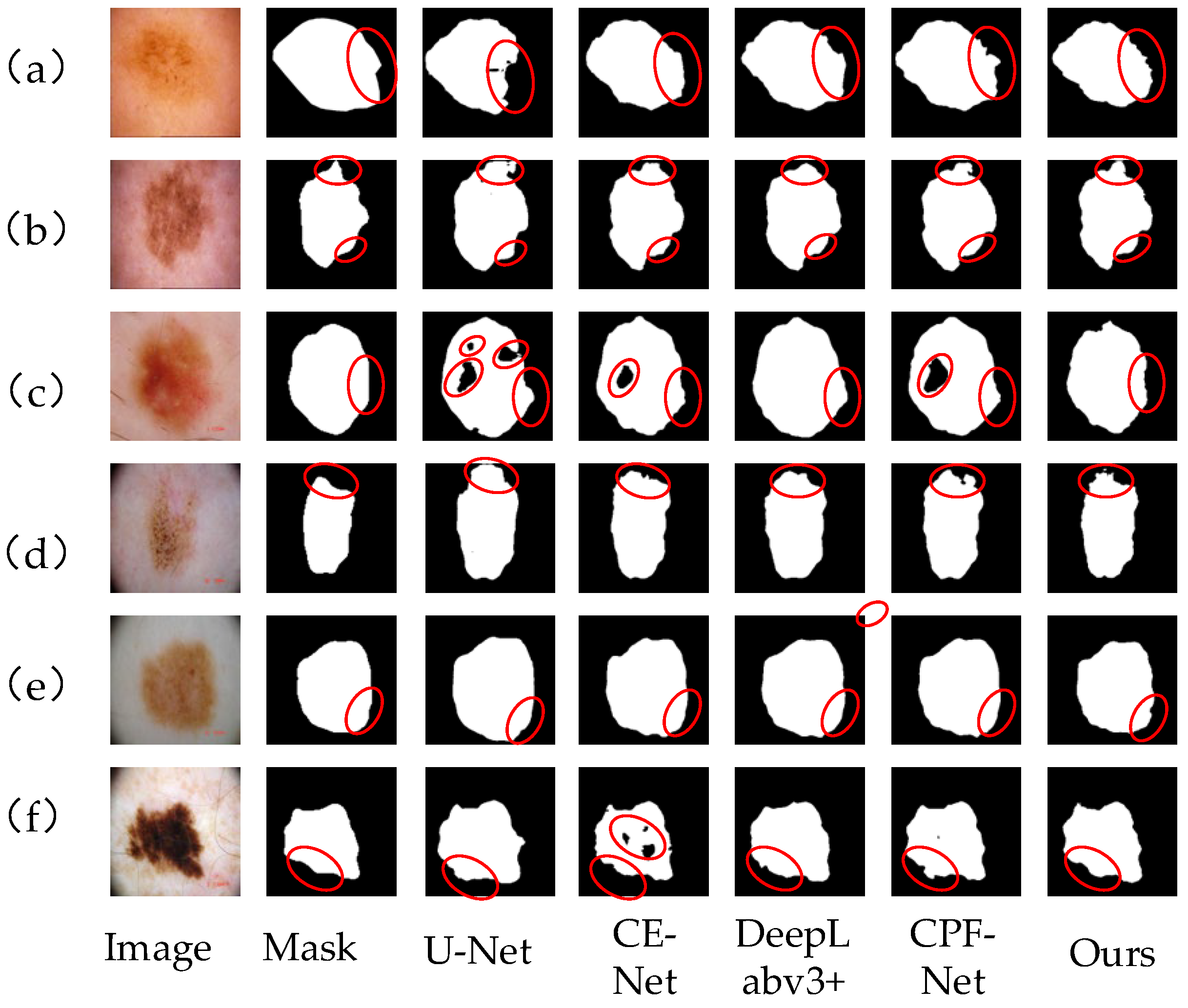
Figure 10a–f shows the segmentation results of skin lesion images on ISIC2018 data set by different networks. Compared with other networks, our algorithm is more accurate in segmenting images. In Figure 10a,b,d, the color of the skin injury area is very similar to that of normal skin, and there is no clear dividing line. For this situation, our algorithm can better segment the lesion area, and the edge contour is clear. However, U-Net and CE-Net networks can not capture the boundary information completely, which leads to a poor segmentation effect and unclear edge segmentation. Figure 10e,f has a high color contrast with normal skin, and the boundary between edge and contour is obvious. Our algorithm in this paper can extract and process edge information well and segment the lesion area correctly. In Figure 10c, there are some dark lesion areas in the skin lesion area. By comparing and analyzing the segmentation results, it can be seen that U-Net, CE-Net and CPF-Net all have lesion areas missing, and there are many dark lesion areas missing, which shows that the above networks have insufficient image feature extraction and are easy to cause information loss. The MS-RFB module in our algorithm can enrich the image features, capture the global context information, and make the segmentation results more accurate. The comparison results show that our algorithm can better extract image feature information, reduce the loss of feature information, correctly process the image edge information, and make the segmentation results from more clear contour, more detailed edges, and higher segmentation accuracy.
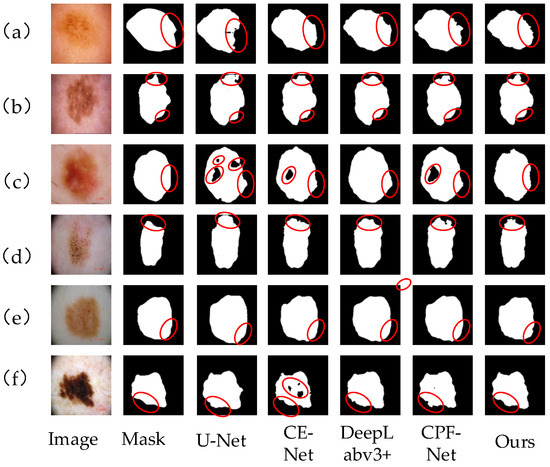
Figure 10.
Different network segmentation results on ISIC2018 data set. Images (a–f) represent 6 different images of skin diseases. From left to right, the images are Image, mask, U-Net segmentation results, CE-Net segmentation results, DeepLabv3+ segmentation results, CPF-Net segmentation results and the segmentation results of our algorithm. Details of each network partition are shown in red circles.
Table 7 gives an objective comparison of this network with other reference networks on the ISIC2018 data set. The accuracy of this network is only 0.0003 lower than that of the first MS RED network, ranking second, and other indexes are also slightly lower. The similarity coefficients of Spe and Dice reach the best, but the overall performance is still better than that of most existing models. FAT-Net adds an encoder based on Transformers to the traditional CNN encoder to capture deep-level information and global context information, making the sensitivity of the network reach the highest. The Literature MS RED network uses multi-residual decoding and fusion modules to extract features; the multi-scale residual decoding and fusion module adaptively fuses multi-scale information. At the same time, a new multi-resolution and multi-channel feature fusion module is proposed. So that the network can extract more feature information or obtain better segmentation results. Overall, the performance of the proposed network is good on the whole; it can effectively segment skin lesion images, provide a new method for medical diagnosis, and improve diagnostic efficiency.
Table 7.
Objective comparison of different networks on ISIC2018 data set.
5. Discussion
In this paper, a skin disease segmentation network based on a multi-level split receptive field and attention is proposed, which can solve the problems of low contrast of skin disease images and similar lesion areas to the background. The network adopts a U-shaped coding and decoding structure, uses a depth feature extraction layer and multi-level split receptive field module to extract feature map information to capture global context information, and realizes global information and information fusion through a hybrid module to build long-term and short-term dependency relationships. At the same time, we introduce a reverse residual attention block into the decoder to better process the feature information of the image. Experiments show that the proposed network can segment the lesion image more accurately, which provides important clinical diagnosis and treatment assistance for clinicians. Doctors can easily obtain the diagnosis results of patients through the segmentation result.
Although our research can accurately segment images with low contrast and similar color backgrounds, for images with blurred edges and small lesions, the segmentation is not accurate enough, which easily leads to the loss of feature information. In future work, we will strengthen the research of image feature extraction, optimize the calculations, improve the training speed, strengthen the processing of noise interference, repair the missing and fuzzy segmentation problems caused by the difficulty in identifying the lesion areas, improve the ability of skin disease segmentation network, and provide doctors with better medical technology. In addition, a lightweight network is also the focus of future research. A lightweight model is conducive to the deployment of applications, reduces memory footprint, and improves efficiency while also reducing space footprint and improving user experience.
6. Conclusions
In order to solve the problems of skin lesion images, such as the similarity between region and background and hair occlusion, a skin lesion segmentation method based on multi-level segmentation of receptive field and attention is proposed. In the coding part, the depth feature extraction module and MS-RFB module are used to encode, which improves the extraction of global context information of feature maps and enriches feature information of different scales. The hybrid pool module establishes long-short correlation through various forms of convolution. In addition, the reverse residual external attention module is introduced into the decoder, which enhances the connection between data sets, obtains the characteristics of the whole data set, and improves the generalization ability of the model. Experimental results show that this algorithm can improve the segmentation effect of skin lesion images, especially for images with similar backgrounds and lesion areas. The ability of edge detail processing is also improved, and the comprehensive indexes are superior to other algorithms, which is helpful to further improve the accuracy and efficiency of computer-aided skin lesion diagnosis. Compared with the classical network, our model has improved in all indexes. Therefore, this model is helpful in improving the efficiency of computer-aided diagnosis of skin diseases and provides a reference for future research.
Author Contributions
Conceptualization, G.Y. and Z.N.; methodology, G.Y. and Z.N.; software, G.Y.; validation, Z.N., J.W. and H.Y.; formal analysis, J.W. and S.Y.; investigation, H.Y. and S.Y.; resources, G.Y. and Z.N.; data curation, J.W.; writing—original draft preparation, G.Y. and Z.N.; writing—review and editing, S.Y.; visualization, J.W. and H.Y.; supervision, G.Y.; project administration, Z.N. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Science and Technology Program of Jiangxi Provincial Education Department, grant number GJJ190450, and the Science and Technology Project of the Education Department of Jiangxi Province, grant number GJJ180484.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ung, H.; Ferlay, J.; Siegel, R.L. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin. 2021, 71, 209–249. [Google Scholar]
- Wei, Z.; Shi, F.; Song, H. Attentive boundary aware network for multi-scale skin lesion segmentation with adversarial training. Multimed. Tools Appl. 2020, 79, 27115–27136. [Google Scholar] [CrossRef]
- Hu, K.; Lu, J.; Lee, D.; Xiong, D.; Chen, Z. AS-Net: Attention Synergy Network for skin lesion segmentation. Expert Syst. Appl. 2022, 201, 117112. [Google Scholar] [CrossRef]
- Tong, X.; Wei, J.; Sun, B.; Su, S.; Zuo, Z.; Wu, P. ASCU-Net: Attention gate, spatial and channel attention u-net for skin lesion segmentation. Diagnostics 2021, 11, 501. [Google Scholar] [CrossRef] [PubMed]
- Thanh, D.N.H.; Erkan, U.; Prasath, V.B.S.; Kumar, V.; Hien, N.N. A skin lesion segmentation method for dermoscopic images based on adaptive thresholding with normalization of color models. In Proceedings of the 2019 6th International Conference on Electrical and Electronics Engineering (ICEEE), Istanbul, Turkey, 16–17 April 2019; pp. 116–120. [Google Scholar]
- Hafhouf, B.; Zitouni, A.; Megherbi, A.C.; Sbaa, S. An improved and robust encoder–decoder for skin lesion segmentation. Arab. J. Sci. Eng. 2022, 47, 9861–9875. [Google Scholar] [CrossRef]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 20 September 2018; Proceedings 4; Springer International Publishing: Basel, Switzerland, 2018; pp. 3–11. [Google Scholar]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Wu, J. Unet 3+: A full-scale connected unet for medical image segmentation. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 1055–1059. [Google Scholar]
- Alom, M.Z.; Hasan, M.; Yakopcic, C.; Taha, T.M.; Asari, V.K. Recurrent residual convolutional neural network based on u-net (r2u-net) for medical image segmentation. arXiv 2018, arXiv:1802.06955. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Bharati, P.; Pramanik, A. Deep learning techniques—R-CNN to mask R-CNN: A survey. In Computational Intelligence in Pattern Recognition: Proceedings of CIPR; Springer: Berlin/Heidelberg, Germany, 2019; pp. 657–668. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Tang, X. Residual attention network for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3156–3164. [Google Scholar]
- Sarker, M.M.K.; Rashwan, H.A.; Akram, F.; Banu, S.F.; Saleh, A.; Singh, V.K.; Puig, D. SLSDeep: Skin lesion segmentation based on dilated residual and pyramid pooling networks. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2018: 21st International Conference, Granada, Spain, 16–20 September 2018; pp. 21–29. [Google Scholar]
- Codella, N.; Cai, J.; Abedini, M.; Garnavi, R.; Halpern, A.; Smith, J.R. Deep learning, sparse coding, and SVM for melanoma recognition in dermoscopy images. In Proceedings of the International Workshop on Machine Learning in Medical Imaging, Munich, Germany, 5 October 2015; pp. 118–126. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected CRFs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Lin, B.S.; Michael, K.; Kalra, S.; Tizhoosh, H.R. Skin lesion segmentation: U-nets versus clustering. In Proceedings of the IEEE Symposium Series on Computational Intelligence (SSCI), Honolulu, HI, USA, 27 November–1 December 2017; pp. 1–7. [Google Scholar]
- Yuan, Y. Automatic skin lesion segmentation with fully convolutional-deconvolutional networks. arXiv 2017, arXiv:1703.05165. [Google Scholar]
- Codella, N.C.; Nguyen, Q.B.; Pankanti, S.; Gutman, D.A.; Helba, B.; Halpern, A.C.; Smith, J.R. Deep learning ensembles for melanoma recognition in dermoscopy images. IBM J. Res. Dev. 2017, 61, 5:1–5:15. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Rueckert, D. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Li, H.; He, X.; Yu, Z.; Zhou, F.; Cheng, J.Z.; Huang, L.; Lei, B. Skin lesion segmentation via dense connected deconvolutional network. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 671–675. [Google Scholar]
- Bi, L.; Feng, D.; Kim, J. Improving automatic skin lesion segmentation using adversarial learning based data augmentation. arXiv 2018, arXiv:1807.08392. [Google Scholar]
- Canalini, L.; Pollastri, F.; Bolelli, F.; Cancilla, M.; Allegretti, S.; Grana, C. Skin lesion segmentation ensemble with diverse training strategies. In Proceedings of the Computer Analysis of Images and Patterns: 18th International Conference, CAIP 2019, Salerno, Italy, 3–5 September 2019; pp. 89–101. [Google Scholar]
- He, Y.; Shi, J.; Wang, C.; Huang, H.; Liu, J.; Li, G.; Wang, J. Semi-supervised skin detection by network with mutual guidance. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2111–2120. [Google Scholar]
- Dupre, R.; Fajtl, J.; Argyriou, V.; Remagnino, P. Improving dataset volumes and model accuracy with semi-supervised iterative self-learning. IEEE Trans. Image Process. 2019, 29, 4337–4348. [Google Scholar] [CrossRef] [PubMed]
- Wu, H.; Pan, J.; Li, Z.; Wen, Z.; Qin, J. Automated skin lesion segmentation via an adaptive dual attention module. IEEE Trans. Med. Imaging 2020, 40, 357–370. [Google Scholar] [CrossRef] [PubMed]
- Yuan, Y.; Chao, M.; Lo, Y.C. Automatic skin lesion segmentation using deep fully convolutional networks with jaccard distance. IEEE Trans. Med. Imaging 2017, 36, 1876–1886. [Google Scholar] [CrossRef]
- Ruan, J.; Xiang, S.; Xie, M.; Liu, T.; Fu, Y. MALUNet: A multi-attention and light-weight unet for skin lesion segmentation. In Proceedings of the 2022 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Las Vegas, NV, USA, 6–8 December 2022; pp. 1150–1156. [Google Scholar]
- Liu, L.; Zhang, X.; Li, Y.; Xu, Z. An Improved Multi-Scale Feature Fusion for Skin Lesion Segmentation. Appl. Sci. 2023, 13, 8512. [Google Scholar] [CrossRef]
- Liming, L.; Longsong, Z.; Feng, J. Skin lesion segmentation based on high-resolution composite network. Opt. Precis. Eng. 2022, 30, 2021–2038. [Google Scholar]
- Zou, J. Research on Skin Lesion Image Segmentation Algorithm Based on Deep Learning. Ph.D. Thesis, Jiangxi University of Sci-ence and Technology, Ganzhou, China, 2022. [Google Scholar]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–18 June 2020; pp. 1580–1589. [Google Scholar]
- Xu, J.; Hu, D.J.; Liu, X.P.; Han, L.; Yan, H.Y. Image detection of cotton impurities based on improved RFB-MobileNetV3. Acta Text. Sin. 2023, 44, 179–187. [Google Scholar]
- Wang, S.Y.; Hou, Z.Q.; Wang, N.; Li, F.C.; Pu, L.; Ma, S.G. Video object segmentation algorithm based on adaptive template updating and multi-feature fusion. Opto-Electron. Eng. 2021, 48, 210193. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Hou, Q.; Zhang, L.; Cheng, M.M.; Feng, J. Strip pooling: Rethinking spatial pooling for scene parsing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4003–4012. [Google Scholar]
- Guo, M.H.; Liu, Z.N.; Mu, T.J.; Hu, S.M. Beyond self-attention: External attention using two linear layers for visual tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 5436–5447. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Li, X.; Sun, X.; Meng, Y.; Liang, J.; Wu, F.; Li, J. Dice loss for data-imbalanced NLP tasks. arXiv 2019, arXiv:1911.02855. [Google Scholar]
- Salehi, S.S.M.; Erdogmus, D.; Gholipour, A. Tversky loss function for image segmentation using 3D fully convolutional deep networks. In Proceedings of the International Workshop on Machine Learning in Medical Imaging, Quebec City, QC, Canada, 10 September 2017; pp. 379–387. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Dai, D.; Dong, C.; Xu, S. Ms RED: A novel multi-scale residual encoding and decoding network for skin lesion segmentation. Med. Image Anal. 2022, 75, 102293. [Google Scholar] [CrossRef] [PubMed]
- Azad, R.; Asadi-Aghbolaghi, M.; Fathy, M.; Escalera, S. Attention deeplabv3+: Multi-level context attention mechanism for skin lesion segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 251–266. [Google Scholar]
- Gu, Z.; Cheng, J.; Fu, H.; Zhou, K.; Hao, H.; Zhao, Y.; Liu, J. Ce-net: Context encoder network for 2d medical image segmentation. IEEE Trans. Med. Imaging 2019, 38, 2281–2292. [Google Scholar] [CrossRef] [PubMed]
- Feng, S.; Zhao, H.; Shi, F.; Cheng, X.; Wang, M.; Ma, Y.; Chen, X. CPFNet: Context pyramid fusion network for medical image segmentation. IEEE Trans. Med. Imaging 2020, 39, 3008–3018. [Google Scholar] [CrossRef] [PubMed]
- Schlemper, J.; Oktay, O.; Schaap, M.; Heinrich, M.; Kainz, B.; Glocker, B.; Rueckert, D. Attention gated networks: Learning to leverage salient regions in medical images. Med. Image Anal. 2019, 53, 197–207. [Google Scholar] [CrossRef] [PubMed]
- Xie, Y.; Zhang, J.; Xia, Y.; Shen, C. A mutual bootstrapping model for automated skin lesion segmentation and classification. IEEE Trans. Med. Imaging 2020, 39, 2482–2493. [Google Scholar] [CrossRef] [PubMed]
- Wu, H.; Chen, S.; Chen, G.; Wang, W.; Lei, B.; Wen, Z. FAT-Net: Feature adaptive transformers for automated skin lesion segmentation. Med. Image Anal. 2022, 76, 102327. [Google Scholar] [CrossRef]
- Lei, B.; Xia, Z.; Jiang, F.; Jiang, X.; Ge, Z.; Xu, Y.; Wang, S. Skin lesion segmentation via generative adversarial networks with dual discriminators. Med. Image Anal. 2020, 64, 101716. [Google Scholar] [CrossRef]
- Al-Masni, M.A.; Kim, D.H. CMM-Net: Contextual multi-scale multi-level network for efficient biomedical image segmentation. Sci. Rep. 2021, 11, 10191. [Google Scholar] [CrossRef]
- Ramadan, R.; Aly, S. CU-net: A new improved multi-input color U-net model for skin lesion semantic segmentation. IEEE Access 2022, 10, 15539–15564. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).