1. Introduction
With the many recent improvements in global living standards, human clothing requirements now prioritize diversity and personalization with small-batch, made-to-measure fashion solutions. As such, body dimension and posture measurement prediction supported by artificial neural networks (ANNs) has become a crucial human–machine engineering field. From these tools, new computer-aided ergonomic garment design tools can be paired with three-dimensional (3D) non-contact body scanning and virtual fitting techniques that avoid the use of various calipers, tape measures, and Martin-style anthropometric measuring tools [
1]. These anthropometric methods utilize stature percentiles for body segments, which can lead to large errors in practice. Hence, the fashion industry demands more cost-effective, accurate, and efficient non-percentile anthropometric methods that cater to clothing and human-centered product designs [
2].
In recent years, research on predicting human body dimensions and shapes using artificial intelligence technologies has been widely conducted, mainly including various prediction methods such as multiple linear regression (MLR) [
3,
4,
5], back-propagation (BP) ANN [
6,
7,
8,
9], radial basis function (RBF) ANN [
2,
10,
11], and support vector regression (SVR) methods [
12,
13,
14]. Su et al. [
3] used an MLR model that incorporates easily measurable features, including the thickness/width parameters of cross-sections, with the objective of constructing additional lower-body characteristics. Galada and Baytar [
4] used the U.S. size database to train a new lasso regression method that establishes relationships between key predictor variables related to crotch length to improve the fit of bifurcated garments. Chan et al. [
5] utilized 3D anthropometric data to forecast the relevant parameters in shirt pattern design by deploying an ANN with a linear regression model to reveal the relationship between patterns and body measurements. However, the nonlinearity in the relationships between different body parts becomes more pronounced, and the MLR model struggles to accurately capture this characteristic. Liu et al. [
6] provided a back-propagation (BP) ANN that uses anthropometric data to predict human body dimensions, providing robust support for custom clothing. Furthermore, Liu et al. [
7] introduced digital clothing pressure from virtual try-ons as input parameters and employed a BPNN model to predict the fit of clothing, including tight, well-fitted, or loose. This research has expanded the potential applications of BPNN methods in the field of clothing design. However, due to the random selection of initial weights and thresholds in BPNN, the network may become stuck in local minima, thereby diminishing its fitting performance. To overcome this challenge, Cheng et al. [
8] employed a genetic algorithm to implement a GA-BP-K-means model to cluster data and enhance body shape prediction. This method involves using a genetic algorithm to optimize the initial parameters of the BPNN. Similarly, Cheng et al. [
9] addressed the issue of predicting underwear pressure using an improved GA algorithm combined with a BPNN model. The improved GA algorithm accelerated the BP neural network’s convergence speed and enhanced underwear pressure prediction accuracy. In addition to BPNN, other ANN models, such as the radial basis function neural network (RBF-NN) are also often used to estimate body sizes. For example, Liu et al. [
10] trained a model on clothing knowledge to extract key human body feature parameters using factor analysis with a combined RBF-NN and linear regression method. This enabled the prediction of detailed human body dimensions with a small number of feature parameters. Wang et al. [
11] employed an RBF-NN to estimate complex parameters to improve the comfort and adaptability needed for sportswear. The generalized regression neural network, of Wang et al. [
2], utilizes a particular RBF-NN, and demonstrated a high degree of accuracy in predicting 76 specific human body parameters, without the need for manual measurements or 3D body scanning. This model has shown remarkable predictive capabilities, in line with the growing trend of predicting human body dimensions rather than relying on direct measurements.
Support vector regression (SVR) networks comprise state-of-the-art (SOTA) ANN models, but they still fall short in prediction accuracy and computation efficiency. However, SVR models are the most suitable for nonlinear regression problems in which only small-batch samples are available, and they are robust to outliers. Li and Jing [
12] used an SVR network to construct a regression model for two-dimensional width and depth features and the corresponding circumference sizes of three important measurement parts (i.e., bust, waist, and hip) of young female samples. However, the establishment of this method relied on cross-sectional data of the human body and cannot avoid the need for 3D scanning. Rativa et al. [
13] demonstrated the possibility of superior performance over traditional linear regression methods by employing an SVR model with a Gaussian kernel for the estimation of height and weight using anthropometric data alone. While the results of this method were said to be insensitive to race and gender, in practical application, there may be other unaccounted factors that challenge the model’s robustness. Li et al. [
14] introduced a data-driven model based on particle swarm optimization (PSO) to optimize the least-squares support vector machine (LSSVM) algorithm. This model was applied to solve the problems of garment style recognition and size prediction for pattern making. Tailoring experience was used as the training basis to improve prediction accuracy. However, the ambiguity of the relationship between the variables made the aforementioned single direct prediction model unsuitable for the fashion industry, due to the diversity of body shapes and precise body dimensions. Although the prediction results exhibit a certain level of accuracy, there is ample room for improvement.
Furthermore, anthropometry found extensive applications in the field of intelligent clothing design. For instance, Wang et al. [
15] employed fuzzy logic and genetic algorithms to generate initial clothing patterns. They utilized SVR to learn about the quantitative relationships between clothing structural lines, control points, and pattern parameters. These relationships were then used to predict and adjust the pattern parameters, achieving pattern adaptability. Liu et al. [
16] proposed a machine learning framework that combines hybrid feature selection and a Bayesian search to estimate missing 3D body measurements, addressing the challenge of incomplete data in 3D body scanning. The study found that this approach leverages hybrid feature selection and the Bayesian search to enhance the performance of random forest (RF) and XGBoost 0.72, particularly in filling in missing data, where RF outperforms XGBoost. Wang et al. [
17] introduced an approach that utilizes multiple machine learning frameworks, including RBF-NN, GA, PNN (probabilistic neural network), and SVR, for interactive personalized clothing design. This method enhanced the capability of personalized clothing design by estimating body dimensions, generating customized design solutions, quantifying consumer preferences, predicting clothing fit, and self-adjusting design parameters.
The global optimization of parameters can improve prediction accuracy and generalizability, and modernized meta-heuristic swarm intelligence optimization algorithms can simulate individual and group behaviors that are suitable for complex optimization problems. They also rapidly converge with fewer parameters, and are easily implemented [
18]. However, multimodal swarm intelligence algorithms cannot conquer optimization problems caused by global exploration and local exploitation imbalances that deprive late iterations of their required data diversity [
19]. The literature provides a wealth of PSO improvements related to this via parameter weight adjustments (e.g., linear decay [
20], chaotic dynamism [
21], and S-shaped decay [
22]), population topologies (e.g., static neighborhood [
23], dynamic neighborhood [
24], and hierarchical structure particle subswarms [
25]), and evolutionary learning strategies (e.g., comprehensive learning strategy [
26], generalized opposition-based learning strategy [
27], orthogonal learning strategy [
28], and dimensional learning strategy [
29]). As stated by the no-free-lunch theorem [
30], the identification of a singular method that can be universally regarded as superior to all others for every task is not feasible. However, owing to discrepancies between the two aspects of global exploration and local exploitation, multi-swarm techniques can be used to maintain the population diversity needed to facilitate information flows within subpopulations. Hence, heterogeneous multi-subpopulation techniques have become effective in enhancing PSO algorithms [
31].
In this study, we propose a novel generalized regression forecasting network (GRFN), that combines kernel ridge regression (KRR) prediction with a new multi-strategy, multi-subswarm PSO (MMPSO)-SVR model to considerably reduce large errors in human body dimension prediction. The resulting highly accurate small-batch, data-driven human body dimension prediction scheme does not require stature percentile anthropometric measurements and 3D body reconstruction. Our hybrid model only needs a few basic body size parameters to obtain detailed body dimensions. For our experiment, we used the processes of Liu et al. [
6] to collect lower-body data from 106 women and applied principal factor analysis so that the KRR-based regression model can establish a multi-variate nonlinear correlation map of parameters. This generates preliminary prediction results as a residual sequence that can be used to fit the data linearly. To deal with nonlinear and noisy data, our model takes the residual of the predicted KRR output as input. A residual correction prediction mechanism is employed to improve the fit and predictive performance of our hybrid model, addressing the following aspects: improving prediction accuracy, accounting for unmodeled factors and making adjustments, correcting model bias, and enhancing model robustness. For further optimization, we apply teaching and co-optimization to the MMPSO algorithm, which divides the population into three role-based subgroups: teachers, students, and independent learners. The ability of the MMPSO model to search for the global optimum primarily depends on the diversity of the population. The SVR then balances exploration and exploitation using a diversity-focused multi-strategy search to avoid local optima. Finally, the estimated values of the predicted body parameters are obtained by combining the KRR results with the corrected MMPSO-SVR residuals. Thus, our hybrid model provides verifiable human body dimension predictions that can work with small-batch samples.
In summary, this study makes the following contributions:
- (1)
Our GRFN utilizes a novel KRR-based MMPSO-SVR nonlinear regression network to achieve residual correction prediction. The proposed hybrid model applies a direct approach that utilizes a few basic body measurements to predict other, more detailed human body dimensions from small-batch samples. The results clearly validate the proposed model, as it outperforms state-of-the-art (SOTA) SVR models in terms of both prediction accuracy and reliability.
- (2)
Our MMPSO model adopts a teaching–learning co-optimization scheme in which a teacher subgroup performs enhanced self-learning searching and a student subgroup constructs learning exemplars under the guidance of the teacher group via sub-swarm. The independent subgroup performs self-perceptive search behaviors, and the MMPSO algorithm enhances population diversity while preventing subswarms from becoming trapped in local optima. Competitive results are achieved in terms of optimization convergence and stability in terms of most classical benchmarks.
- (3)
Our GRFN network utilizes just a few basic body size parameters as input and obtains detailed human body dimensions and establishes correlations between key body size parameters and clothing pattern sample sizes. This model eliminates the need for anthropometric measurements and 3D body reconstructions, making it more accurate and easily implemented than existing regression models. Consequently, it offers a novel and efficient solution for clothing and human-centered product design.
The rest of this paper is arranged as follows: In
Section 2, the research methods are elaborated.
Section 3 further describes the GRFN model design alongside the MMPSO algorithm. The effective performance of the proposed hybrid KRR-based MMPSO-SVR model is then reported in
Section 4, and a discussion and conclusions for the paper are presented in
Section 5, along with directions for future research.
4. Experimental Results and Discussion
Within this section, model human body dimensions were evaluated using two experiments to assess model performance. Experiment 1 entailed the classical CEC2005 test suite for MMPSO task validation, and Experiment 2 validated the model’s human body size prediction based on real-world small-batch samples. All experiments were implemented on a 64-bit operating system, a Core i7-6500U CPU with a main frequency of 2.5 GHz, 16-GB memory, and a MATLAB 2018b programming/runtime environment.
4.1. Experimental Setup
4.1.1. Description of Experimental Data
Following Ref. [
6], Liu et al. utilized the Vitus Smart 3D body scanning device to create a dataset comprising measurements from 106 female undergraduate students, never pregnant, aged 20 to 25 years, in the northeastern region of China. The participants’ heights ranged from 151.5 to 173.2 cm, and their weights ranged from 40 to 71 kg based on intermediate sizes provided by the Chinese National Standard, GB/T 1335.2-2008: [
42] Standard Sizing Systems for Garments–Women. Prior to commencement of this study, we addressed ethical compliance issues and made relevant disclosures. Notably, all participants provided informed consent, allowing their measurement data to be obtained using a 3D body scanner in an automated manner. The final measurement dataset exclusively provided our measurement testing data, and we completely anonymized the data items. Hence, no personally identifiable participant information was retained. Furthermore, our reference few-shot anthropometric database is publicly available, as explained in appendix 1 in reference [
43]. To this end, we utilized this open-source anthropometric database to validate the efficacy of our hybrid model.
Table 1 displays the descriptive statistics of the body dimensions and relevant measures, such as mean, median, and central tendency.
4.1.2. Factor Analysis
We used maximum orthogonal factor analysis variance to extract two principal factors from 13 observation items and eliminate multicollinearity among variables. The rotated component matrix is represented in
Table 2, which lists the scores of each sample and factor. Based on the total variance explanation provided in
Table 3, the height factor and perimeter (circumference) coefficient were found to represent most of the information on lower body size.
To avoid large prediction errors caused by large differences in input data, both easy- and difficult-to-measure key human body parameters were normalized. To mitigate interference resulting from varying body shapes, the dataset was divided into distinct training and testing sets, with divisions based on variables, such as stature and waist girth. The training set underwent cross-verification k times to evaluate the results.
4.1.3. Performance Metrics
To quantitatively compare the predictive accuracies of the models, this study employed the root mean square error (
), mean absolute error (
), and coefficient of determination (
). The corresponding equations are presented as follows:
where
and
represent observed and predicted values, respectively, and the variable
denotes the average of the predicted values derived from a collection of
samples.
4.2. Comparison of PSO Variant Algorithms for Benchmark Functions
4.2.1. Benchmark Functions and Parameter Settings for PSO Variants
To evaluate the optimization performance of the proposed MMPSO, the classical CEC 2005 test suite [
44] was selected as the experimental benchmark. The test set consisted of four types of functions: F01–F05 (unimodal (UN)), F06–F12 (multimodal (MN)), F10 and F11 (rotation), F13 and F14 (expanded (EF)), and F15–F25 (hybrid composition (CF)). The test suite can comprehensively and objectively reflect the optimization performance of an algorithm. For a more comprehensive evaluation and analysis, we compared the MMPSO algorithm with seven well-known PSO variants: HIDMSPSO, HCLPSO, HCLDMSPSO, CLPSO, DMSPOS, EPSO, and FDRPSO. The PSO variants’ parameter settings were established as indicated in
Table 4.
4.2.2. Numerical Experimental Results
The performance of the MMPSO and several well-known PSO variants was evaluated using a benchmark test suite. Following the acquisition of the results from 30 independent runs of each algorithm, the evaluation metrics were determined based on the average value (mean) and standard deviation (Std) of each benchmark function. The mean reflects the overall trend of convergence and optimization ability, whereas the Std indicates the stability of the algorithm and its capacity to evade local optima.
The dimensions needed to solve the problem were 30, the upper limit for the total number of fitness evaluations was 300,000, the population size was set to 40, and the sizes of the three heterogeneous subgroups (i.e., teacher, independent learner, and student) were 12, 16, and 12, respectively. The MMPSO algorithm in F04, F06, F08, F10, F11, F14, F17–F20, and F22–F25 benchmark functions were compared with the alternative PSO variants, revealing clearly improved solution accuracy, as demonstrated in
Table 5.
Figure 3A illustrates how the MMPSO algorithm demonstrated excellent performance in terms of finding the global optimum using unimodal functions. Furthermore, the MMPSO algorithm performed well when solving multimodal functions and expanded functions, as illustrated in
Figure 3B. In terms of algorithm stability, the standard deviations of the F04, F05, F06–F08, F10, F17–F18, and F23–F25 benchmark functions exhibited superior performance over the alternative PSO variants. The final ranking algorithms are arranged based on overall averages in the following order: MMPSO, HCLDMSPSO, EPSO, HCLPSO, HIDMSPSO, DMS-PSO, FDRPSO, and CLPSO. This study’s experimental findings provide evidence that the proposed algorithm exhibits effective global convergence capability, particularly when dealing with multimodal and compound test functions. In summary, the MMPSO algorithm shows a superior optimization effect, and experimental results clearly validate that the presence of diverse populations aids in the avoidance of local optima within the model (i.e., locating the global optimum).
4.2.3. Analysis using Friedman Statistical Test
To verify the statistical differences of the full algorithm, a nonparametric Friedman test and a Nemenyi test were used [
50,
51].
Table 6 presents the Friedman test results for the eight algorithms using a significance level of
. Prior to the analysis, an average ranking of the algorithm was performed so that
would represent the average ranking of the
m-th algorithm with the
n-th benchmark function, which is expressed as follows:
where
represents the number of benchmark functions. The results demonstrate that the MMPSO algorithm ranks the highest on the benchmark test set and significantly outperforms other algorithms with unimodal, multimodal, and hybrid composition functions. In this experiment, there were 25 benchmark functions, eight algorithms, and seven degrees of freedom. The square value of the 30-dimensional Friedman test card was 47.160, and the
p-value was less than 0.05. According to the critical table of the chi-square distribution, the critical value was 14.07, and the actual chi-square value was larger than the critical value, indicating that there were obvious differences in the overall performance of each algorithm.
The Nemenyi rank sum test was used to achieve pairwise comparisons among multiple samples.
Figure 4 presents the final rank in 30 dimensions, visually indicating the Friedman statistical test’s critical difference (
CD). If the discrepancy between the mean rank of the two algorithms exceeds the value domain’s
CD, the null hypothesis is rejected at the designated level of confidence. The
CD calculation formula is built as follows:
where
= 3.031, and
represents the number of the algorithm’s critical value range
.
There were obvious differences among the performances of MMPSO, EPSO, HCLPSO, HIDMSPSO, DMSPSO, FDRPSO, and CLPSO, as shown in
Figure 4. In our qualitative analysis, there were no significant differences between the proposed algorithm and the HCLDMSPSO algorithm; however, the proposed algorithm showed superior performance according to the overall average rank.
4.3. Parameters Selection of SVR
In the context of SVR, the estimation and generalization performances were impacted by the hyperparameter pair , where the penalty factor is denoted by , and the RBF kernel function is represented by . The higher the trade-off factor , the more prone to overfitting the model becomes. The larger the , the fewer the support vectors, and vice versa, noting that this number significantly influences the speed of training and prediction processes. The fitness function is an effective measure for optimizing the SVR parameter settings to achieve the best prediction accuracy and generalization ability. First, we employed 10-fold cross-validation to train the model parameters and comprehensively assess the model’s performance. Then, the grid search method was used to search a twice enlarged/reduced range to obtain the optimized kernel function parameter range . Finally, the MMPSO algorithm was used to optimize , where the actual measured values were obtained for each body dimension, and the residual sequence was constructed based on the KRR of the RBF kernel, based on input information. To evaluate the effectiveness of the MMPSO method of enhancing the hyper-parameters of the SVR model, we selected the maximum number of iterations for the MMPSO-SVR (i.e., 1000), a population size of 50, two dimensions, and initial ranges of the variables and as and , respectively.
To analyze the influences of different training proportions, we performed another comparative test taking crotch height and knee circumference parameters as examples, as depicted in
Figure 5A,B. When the size of the training sample exceeded 40, the
and
values of the GRFN hybrid model were stable, demonstrating that it had satisfactory generalizability and performed better than SOTA models on small-batch sample prediction tasks.
4.4. Model Prediction Performance and Garment Pattern Making
Figure 6A,B depict the results of our qualitative analysis for verifying the effectiveness of our method, which seeks to demonstrate the efficacy of GRFN training on the prediction of crotch height and knee circumference. By correcting the residual errors in the training data, the best results pair
of the SVR hyperparameter optimization method were (12.1940, 0.3538) and (12.5767, 0.1852), respectively. Notably, the GRFN model had a good fit between the measured and estimated values, according to the datasets used for training and testing.
Table 7 displays the error between the estimated and ground-truth values. Among these results, the extreme of the maximum error in the testing set was 0.3720 cm, and that of the average error was 0.1182 cm, aligning with the GB/T 23698-2009 standard [
52]. Compared with the results of Liu et al. [
6], who used a BPNN-based model, the mean square error (MSE) and standard error (SE) were 2.06 ± 0.2. Using the PSO-LSSVM model, Li et al. [
14] could only predict the sleeve sizes at MSE and SE measures of 1.057 ± 0.06. As shown in
Table 7, our proposed hybrid model predicts eight difficult-to-measure lower body sizes, where the total MSE and SE were 0.0054 ± 0.07. Moreover, compared with the research conducted by Wang et al. [
2], which utilized a generalized RBF-NN regression model and yielded an average
value of 0.971 and an average
of 5.823 mm, ours achieved significantly improved results of 0.9997 and 0.6142 mm. The prediction effects from the incremental increase in the number of components/parts are displayed in
Figure 7A–D. In summary, the hybrid model clearly improved prediction accuracy and generalizability.
A subject’s stature, waist circumference, hip circumference, waist height, and hip height vectors were 161.7, 68.9, 93.7, 100.3, and 83.5, respectively, as inputs, and the ground-truth outputs were 69.55, 43.7, 53.85, 77.4, 79.2, 37.4, 20.4, and 96.6 for crotch height, knee height, thigh circumference, total crotch length, abdomen circumference, knee circumference, crotch width, and abdomen height, respectively. The outputs predicted by the GRFN hybrid model were 69.559, 43.718, 53.804, 77.501, 79.101, 37.357, 20.397, and 96.310. These predictions are exceptionally accurate and can be used to design patterns for women’s sports trousers and other lower-body garments.
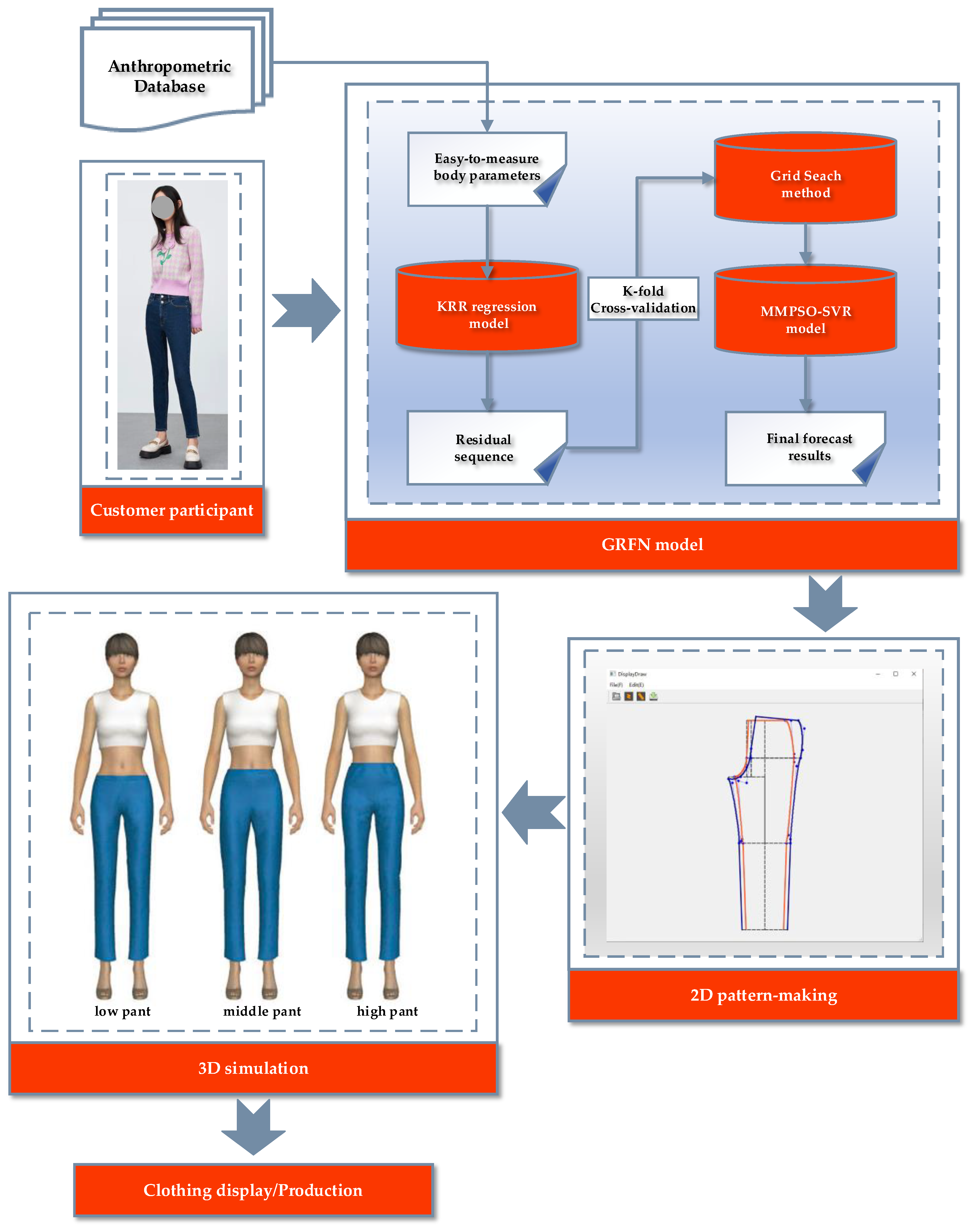
As shown in
Figure 8A, a customer participant can input a few basic body parameters and accurately predict the relevant dimensions for pattern making via the GRFN. We also provide an interactive automatic pattern generation prototype, built using Microsoft Visual Studio 2013 and the Qt 5 integrated C++ development environment.
Figure 8B depicts a screenshot of this system. During the pattern making process, a point-numbering method [
53] is used to draw the structural lines of clothing patterns. The pattern for three-quarter, seven-quarter, and long pants are shown in
Figure 8C. Utilizing the parameter settings of CLO Standalone virtual design software, a customer can effectively identify the precise measurement landmarks required based on the Chinese National Standard, namely GB 3975-1983 [
54] and GB 16160-2017 [
55], to construct an accurate human body model.
Figure 8D illustrates the effect of this 3D simulation using an avatar.
4.5. Performance Comparison with Other Single Optimization SVR Methods
To verify the MMPSO model’s performance in optimizing the SVR hyperparameters, we select HCLDMSPSO-SVR, HCLPSO-SVR, PSO-LSSVM, and BPNN models for comparison. We set the MMPSO-SVR, HCLDMSPSO-SVR, HCLPSO-SVR, and PSO-LSSVM models to the maximum iteration limit of 1000, with a population size of 50. We selected the HCLDMSPSO [
48] and HCLPSO [
46] models as representative SOTA swarm-intelligence algorithms. We built a BPNN with an input layer consisting of five nodes. The hidden layer consisted of 13 nodes, and the output layer consisted of 8 nodes. The objective function was set to the minimum fitness value, and the best optimization result was preserved during the training process. To analyze the hyperparameter influence for an SVR small-sample human body size estimation, we compared the single MMPSO-SVR optimization model enhanced with the population’s diversity to avoid local optima in subsequent iterations, thus improving overall accuracy.
Based on our quantitative analysis, we compared each model’s prediction results, as shown in
Table 8. By assessing the
statistics, we concluded that the degree of fit for a single MMPSO-SVR model was the highest in all parts, and the
and
measures were the smallest of all prediction methods. This again clearly demonstrates the effectiveness of our proposed single unmodified MMPSO-SVR global optimization model. Compared with other single optimization SVR hyperparameter methods, our method demonstrates superior efficacy by evading local optima and attaining the global optimum.
4.6. Ablation Experiments
To validate the accuracy and reliability of our proposed model, we conducted an ablation study by using two simplified models: our KRR regression version and our single direct MMPSO-SVR version.
Figure 9A–H present the performance results on the few-shot human body dimension dataset. The comparative analysis involved assessing the predictive accuracy of the GRFN model in terms of the KRR regression and the single direct MMPSO-SVR models. Compared with the
values of the single direct MMPSO-SVR model, those of the combination hybrid model increased by 97.12% maximally in crotch width, and by 91.73% maximally in abdomen circumference. The
and
values indicate that the hybrid model demonstrated superior predictive performance compared with every other model. The KRR regression model performed poorly in predicting
values across all measurement items, but the single unmodified MMPSO-SVR achieved
values above 0.9 for KH, AC, and AH predictions. However, it struggled with CW and TCL, which are particularly challenging to measure accurately, resulting in low
values. In contrast, the regression values of our hybrid model were above 0.999 for all prediction items, indicating that our method predicts body sizes relevant to garment pattern making more accurately and efficiently, effectively avoiding the shortcomings of single body dimension prediction methods.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}