



Monitoring the Quality and Perception of Service in Colombian Public Service Companies with Twitter and Descriptive Temporal Analysis

Abstract
:1. Introduction
2. Background and Previous Research
2.1. Reference Frameworks or Similar Case Studies
2.2. Benchmarking with Text Mining
2.3. Customer Perception by Using Text Mining
2.4. VOC and Text Mining
3. Materials and Methods
3.1. Data and Application Domain
3.2. Data Extraction
3.3. Preparation and Data Mining
- AFINN Dictionary: Quantifies each word on a scale of −1 to 1 according to intensity;
- Bing Dictionary: Qualifies each word between positive, neutral, and negative;
- NRC Dictionary: Quantifies each word among one or more of the 8 sentiment categories on a scale of 1 to 10;
- Emoji Dictionary: Each emoji is assigned its equivalent in hexadecimal code to convert it into a word using a search.
4. Results
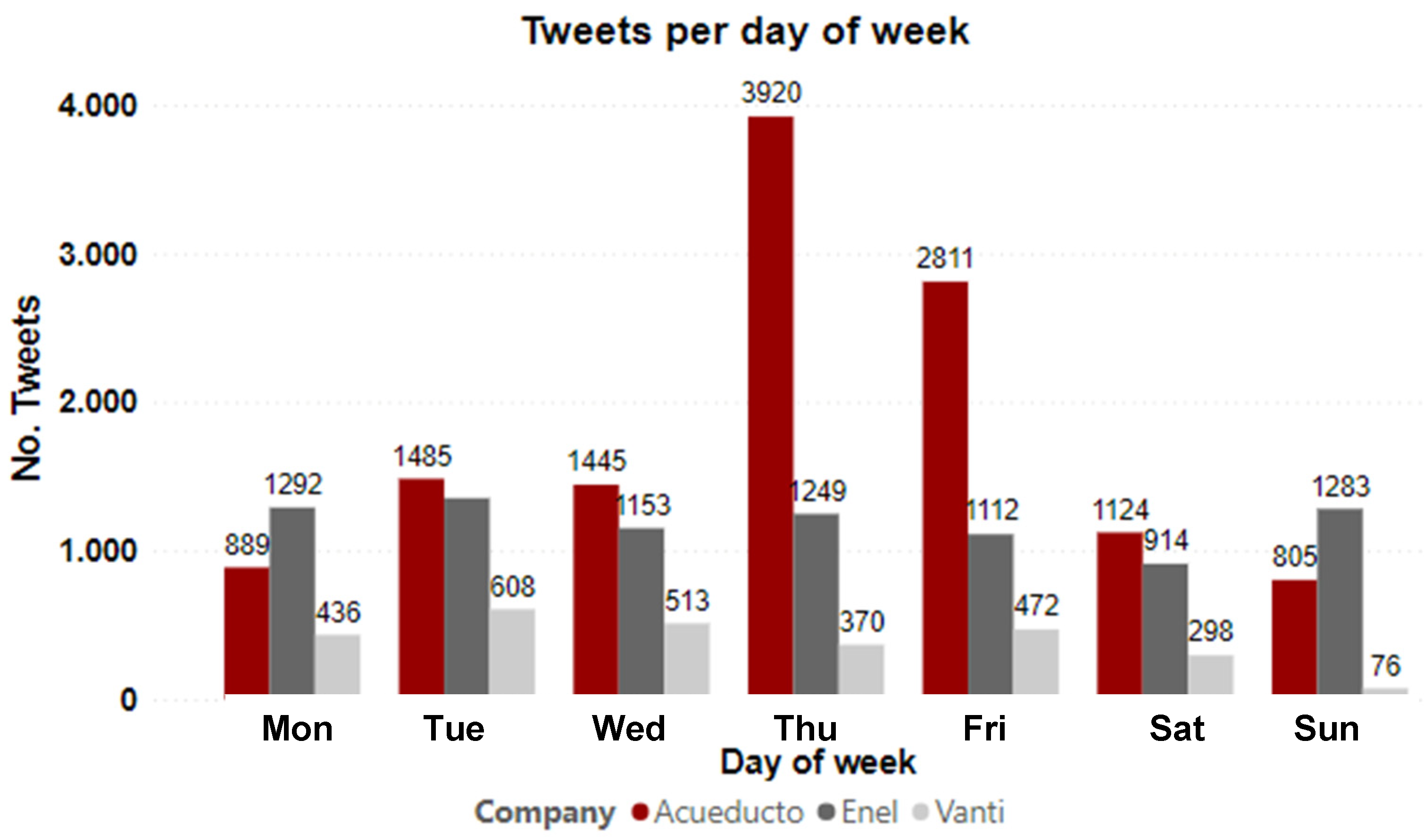
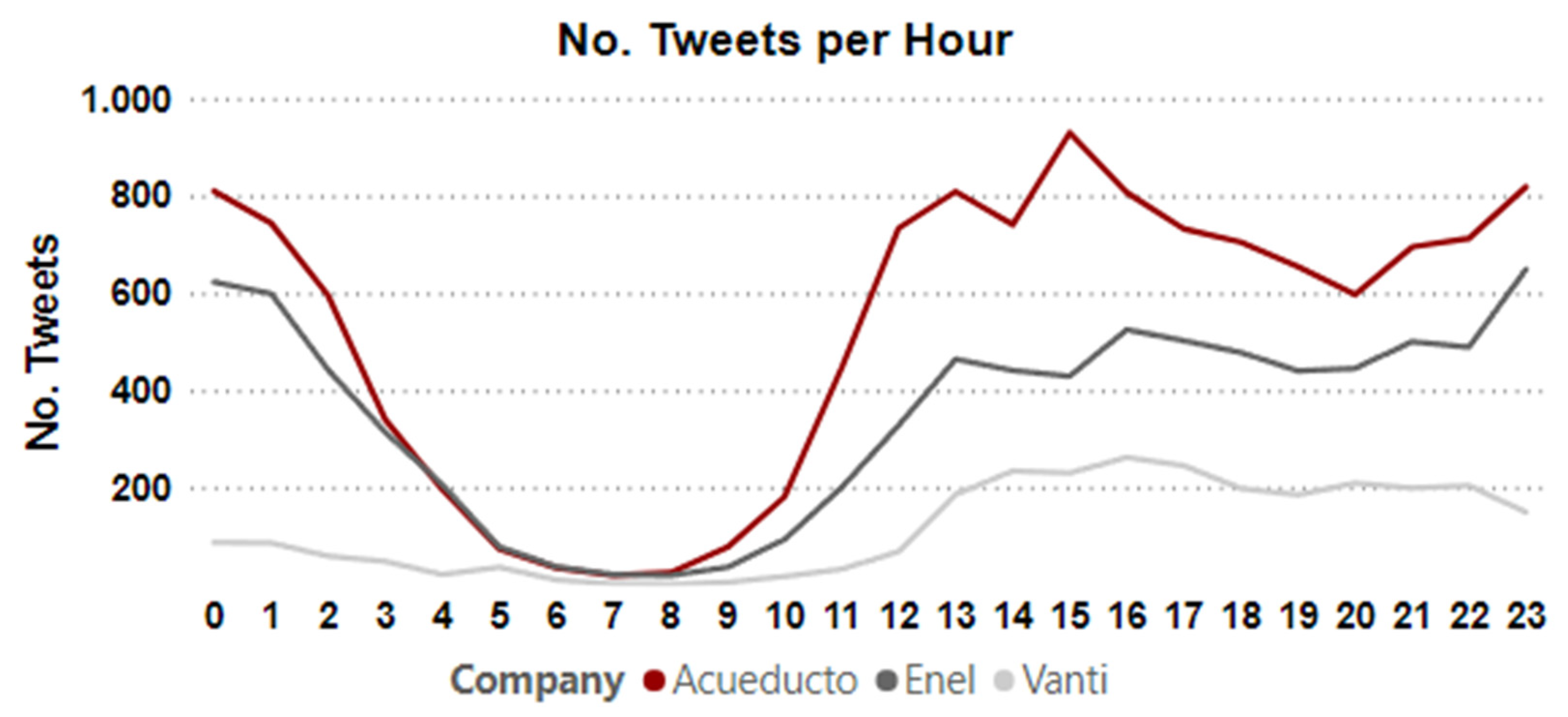
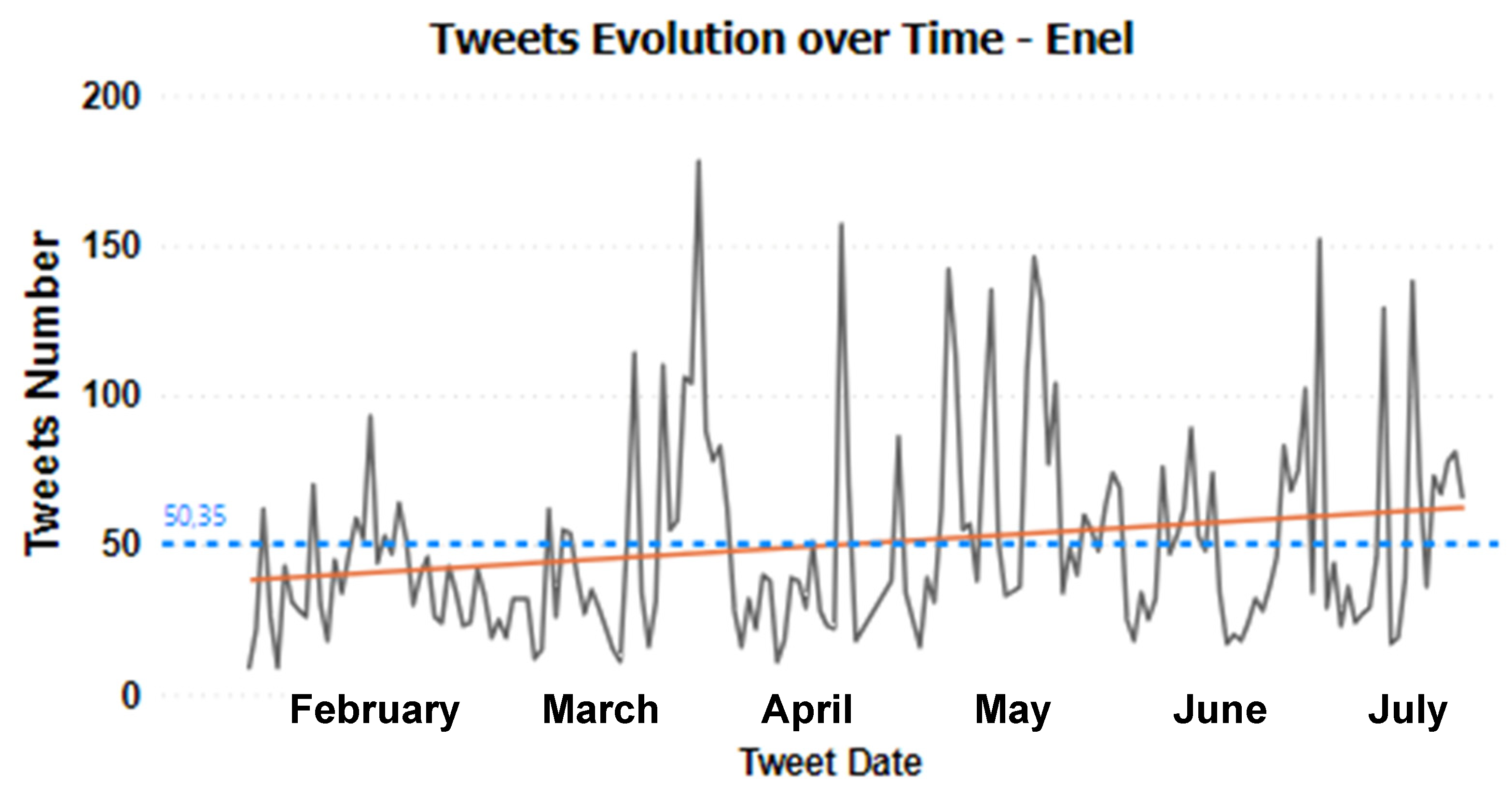
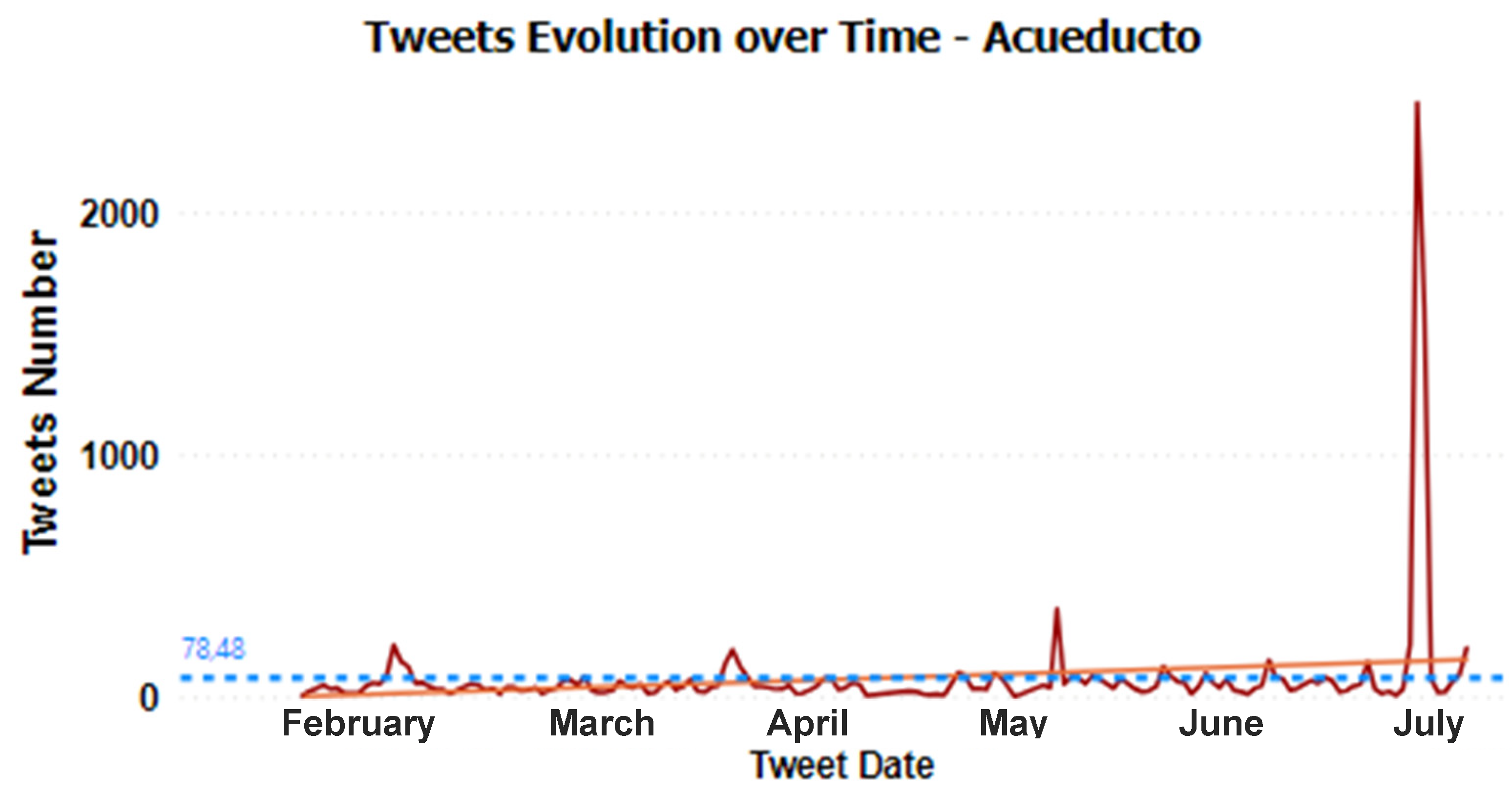
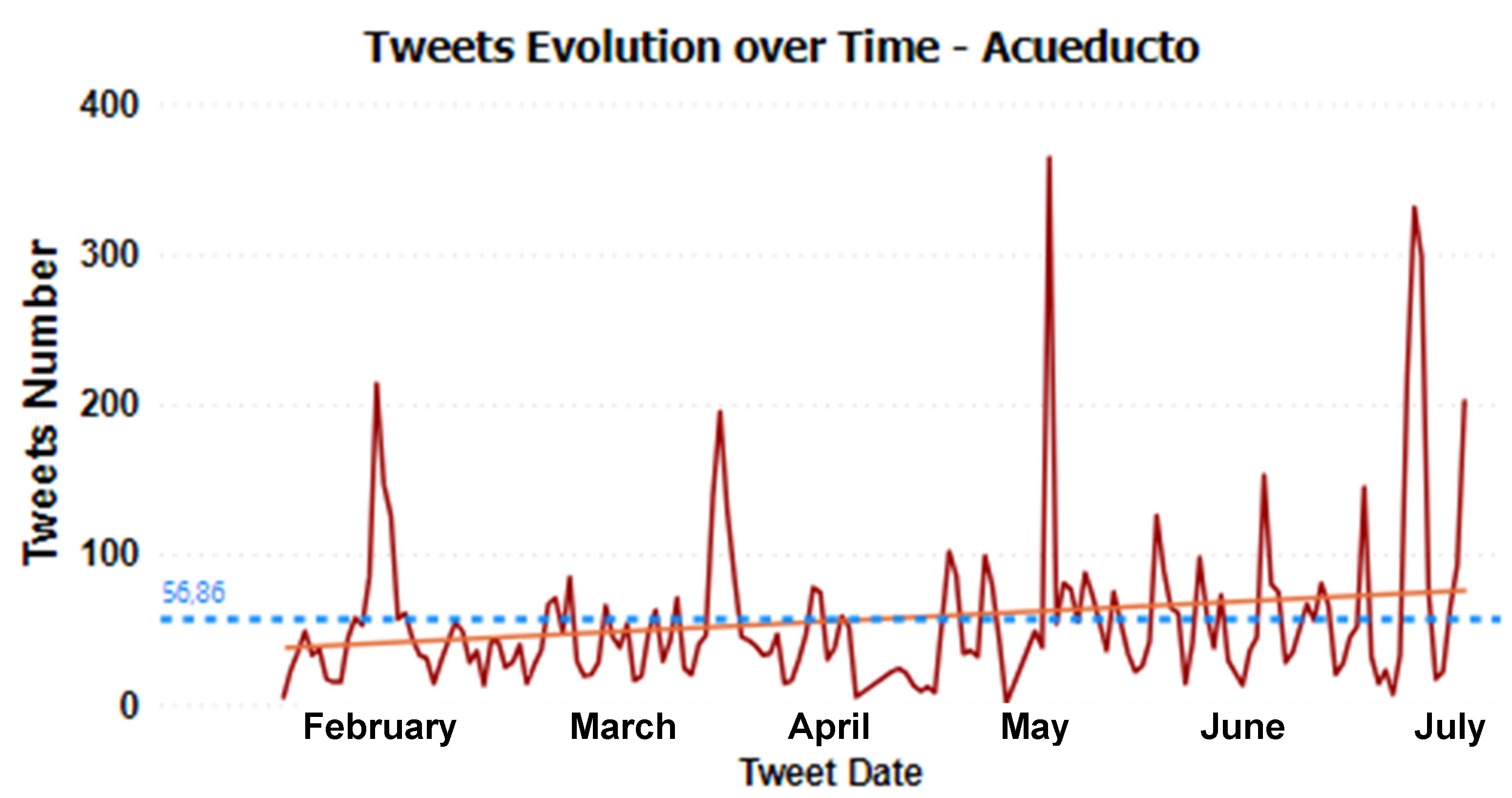
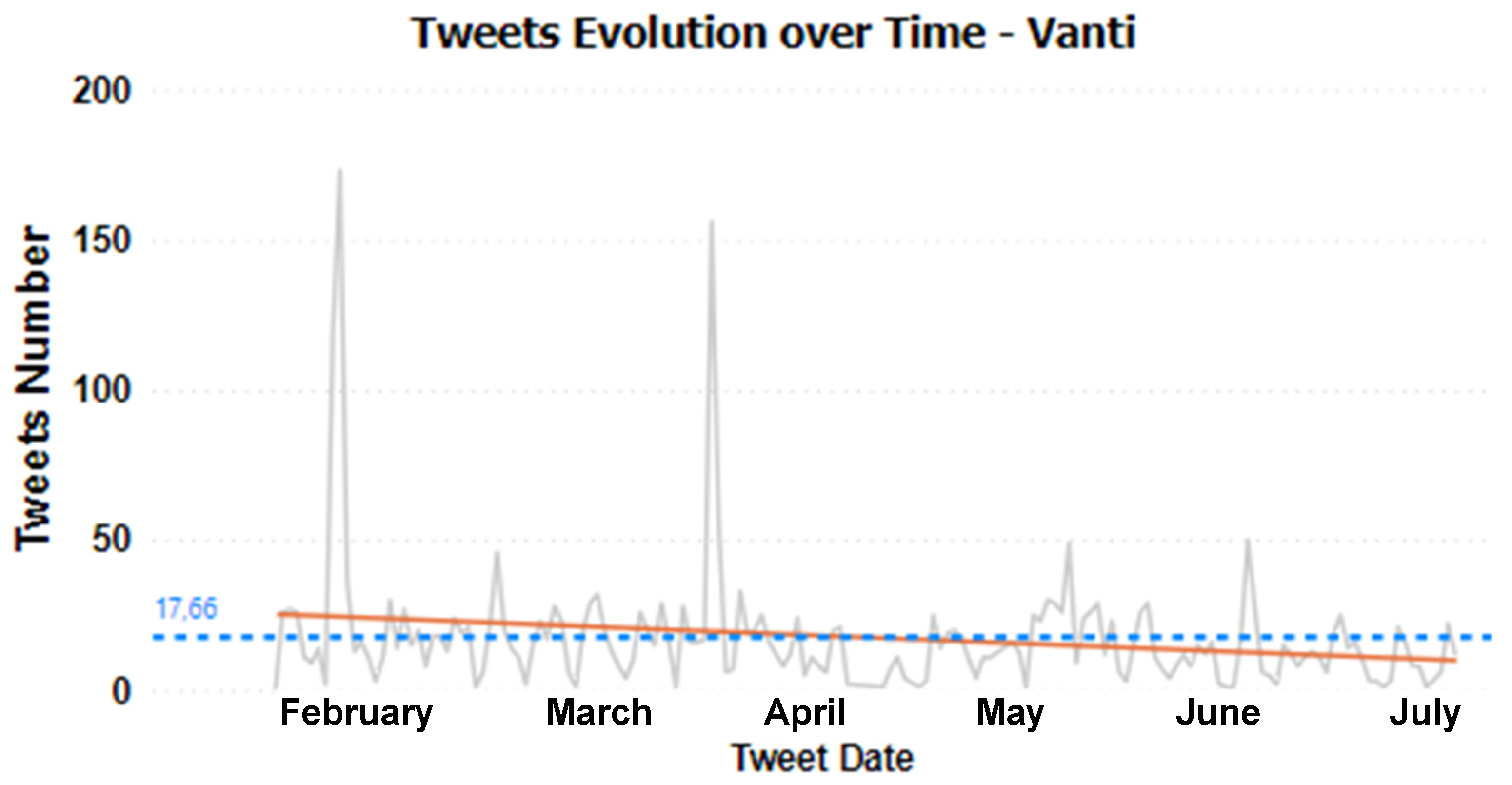
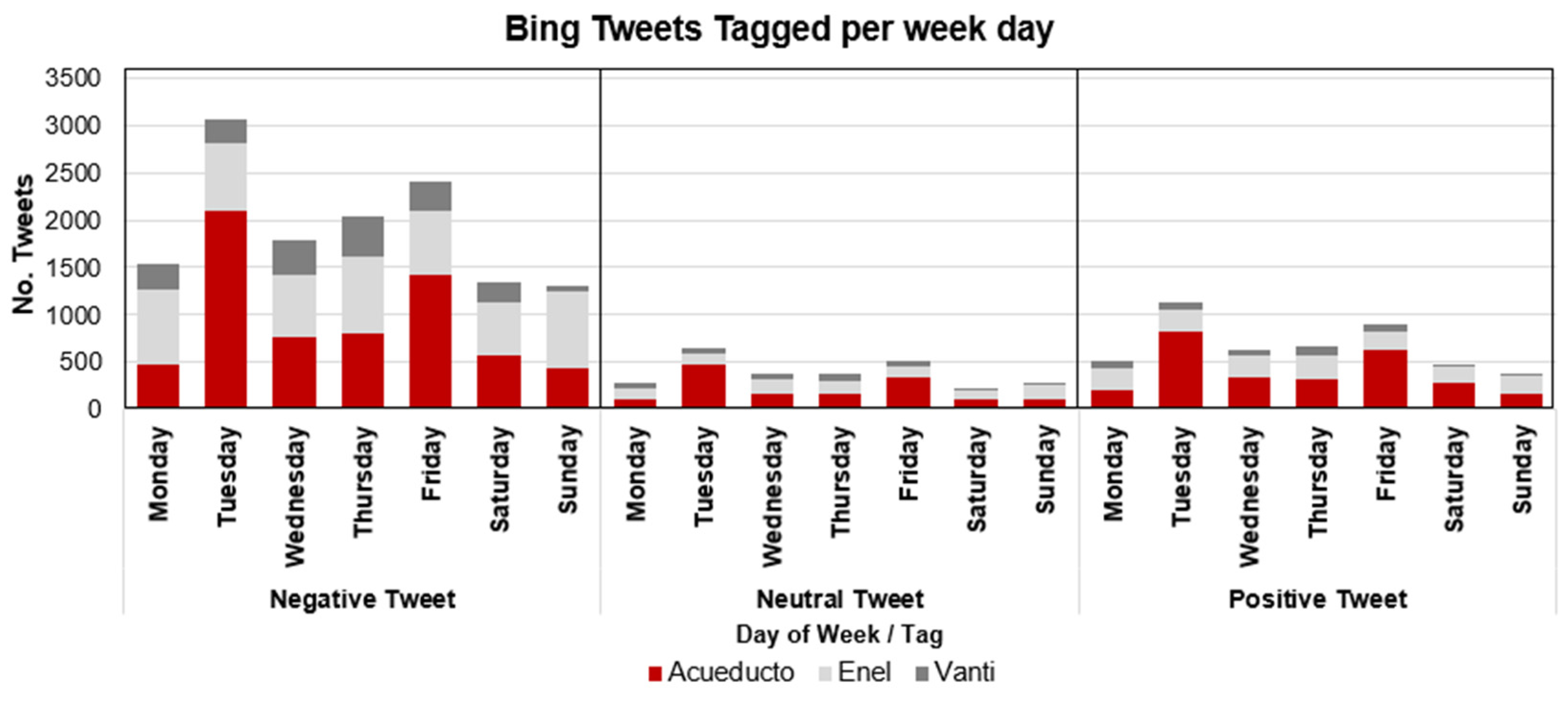
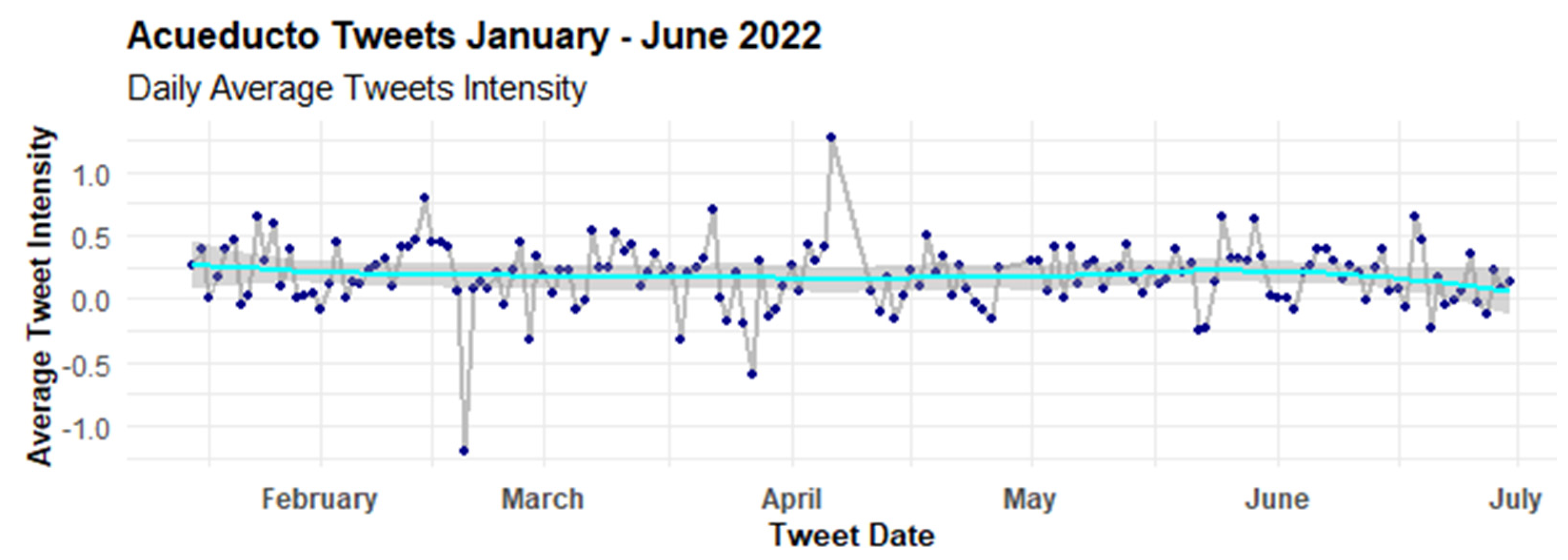
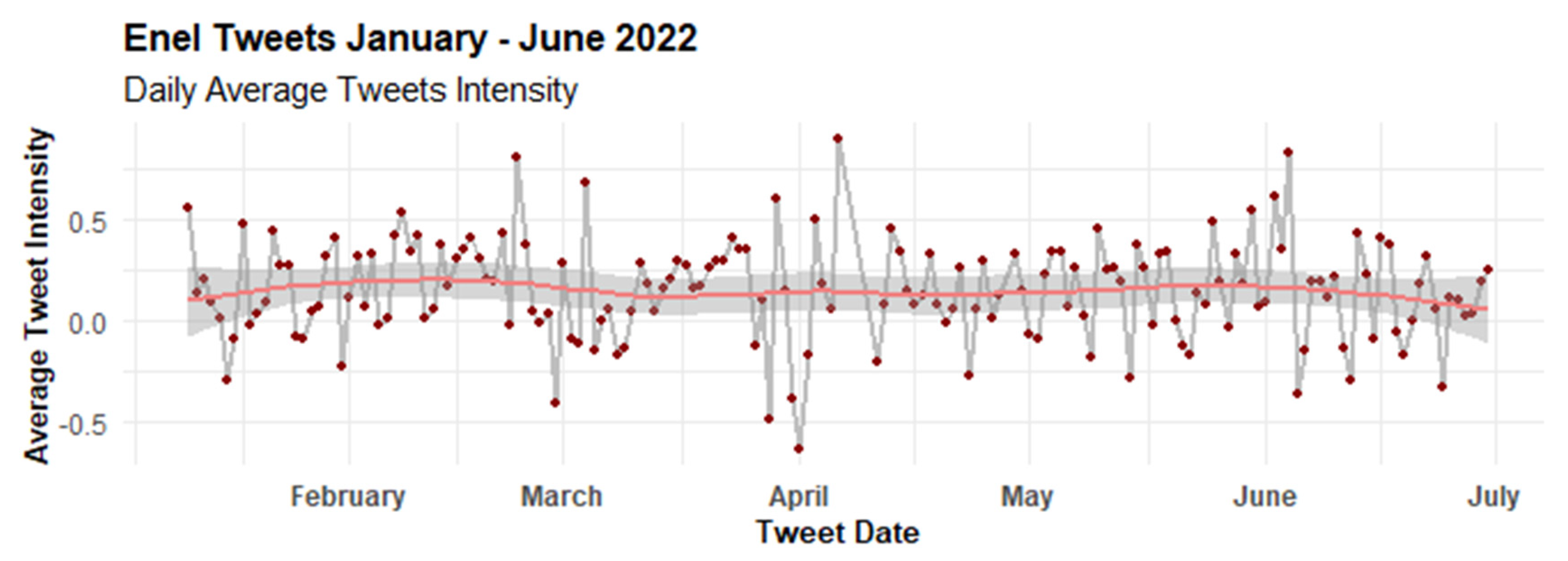
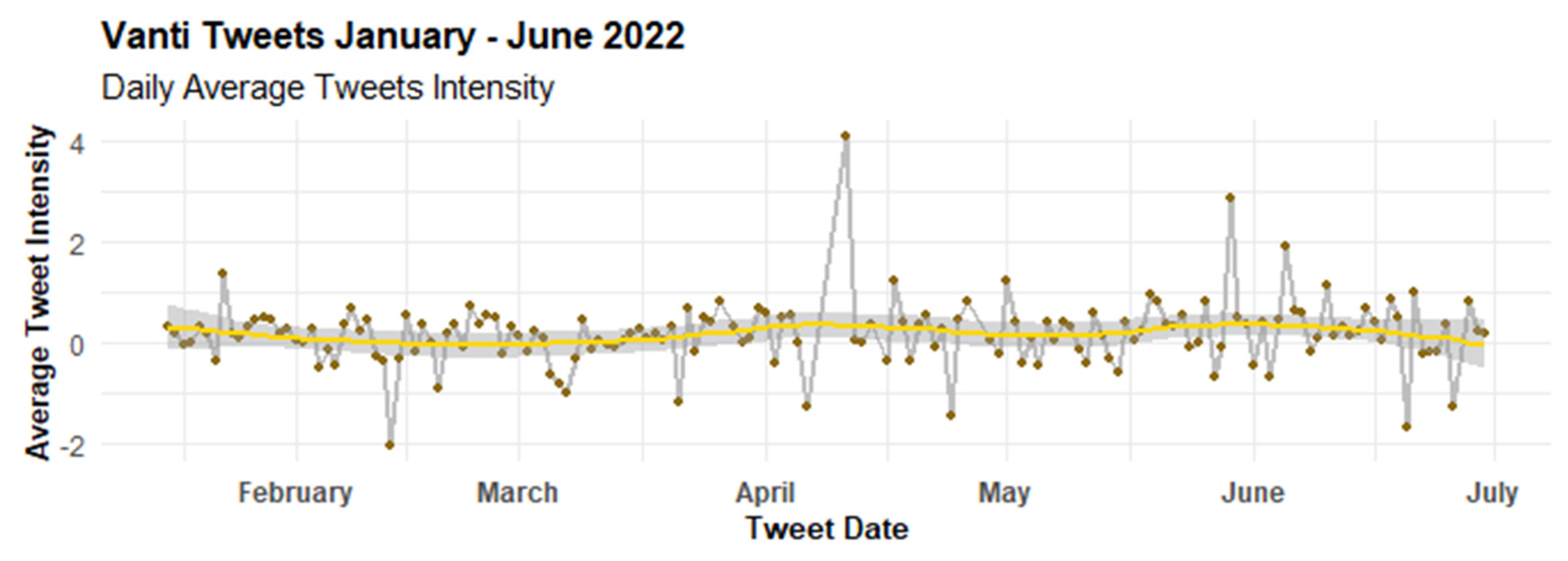
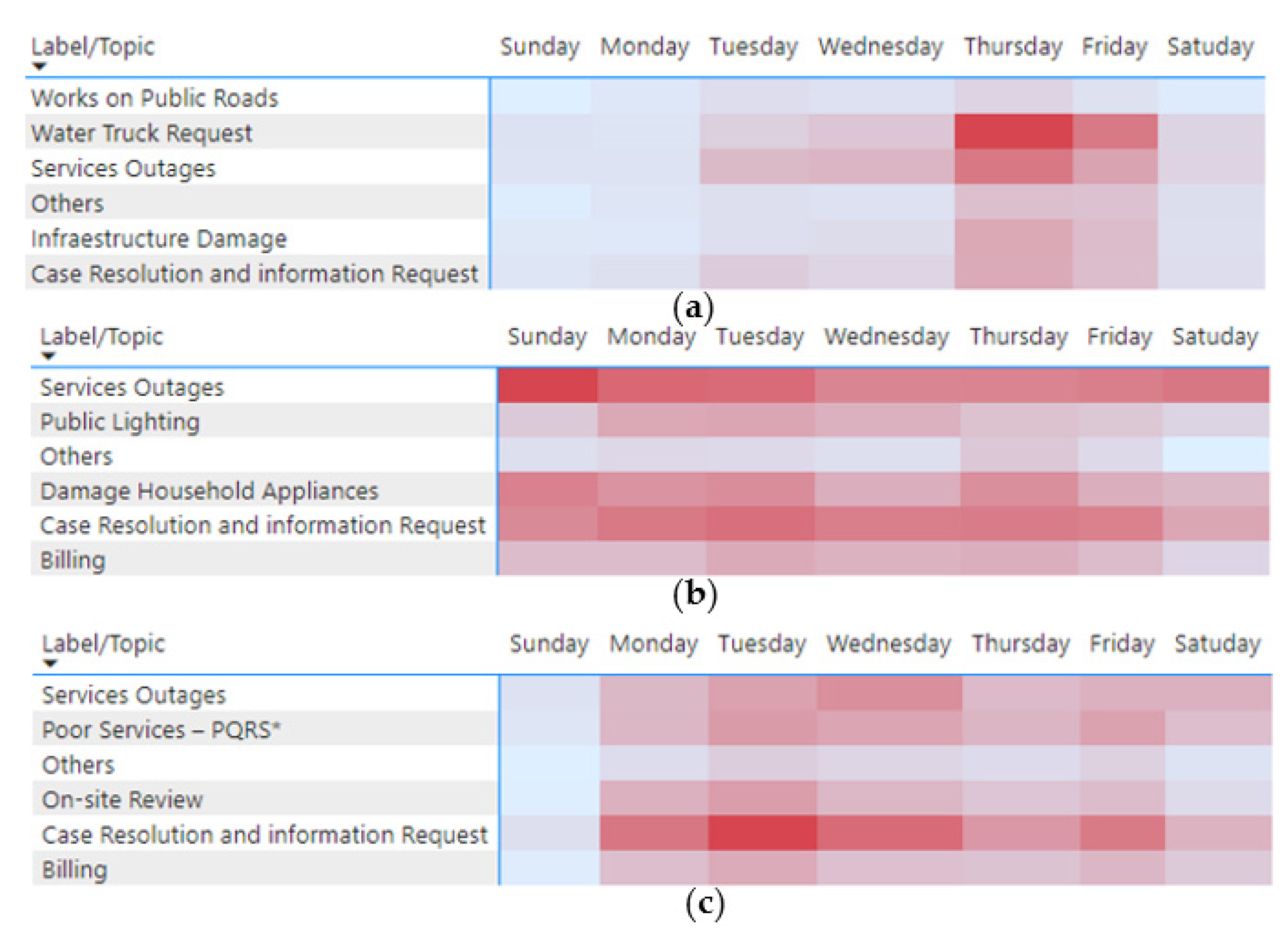
4.1. Temporal Patterns
4.2. Evolution and Trends of Sentiment Analysis
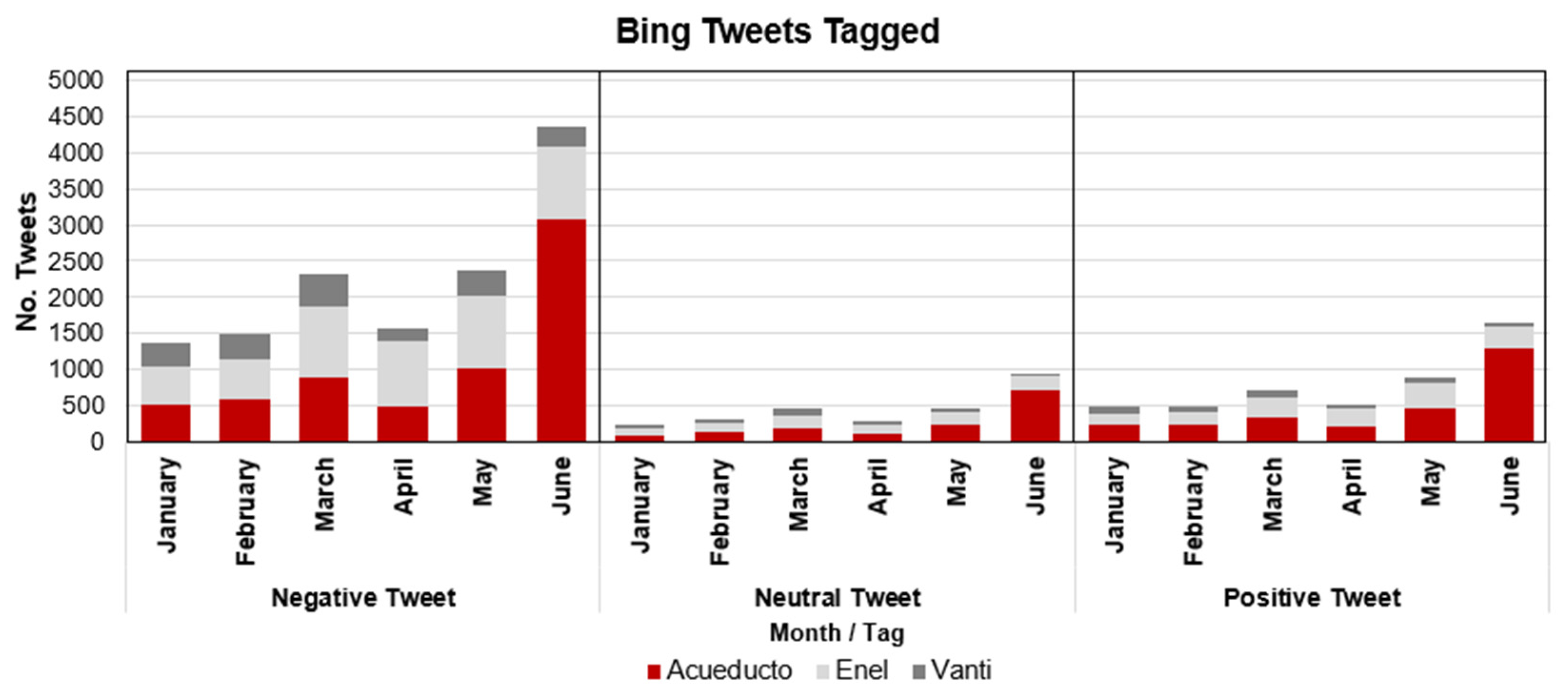
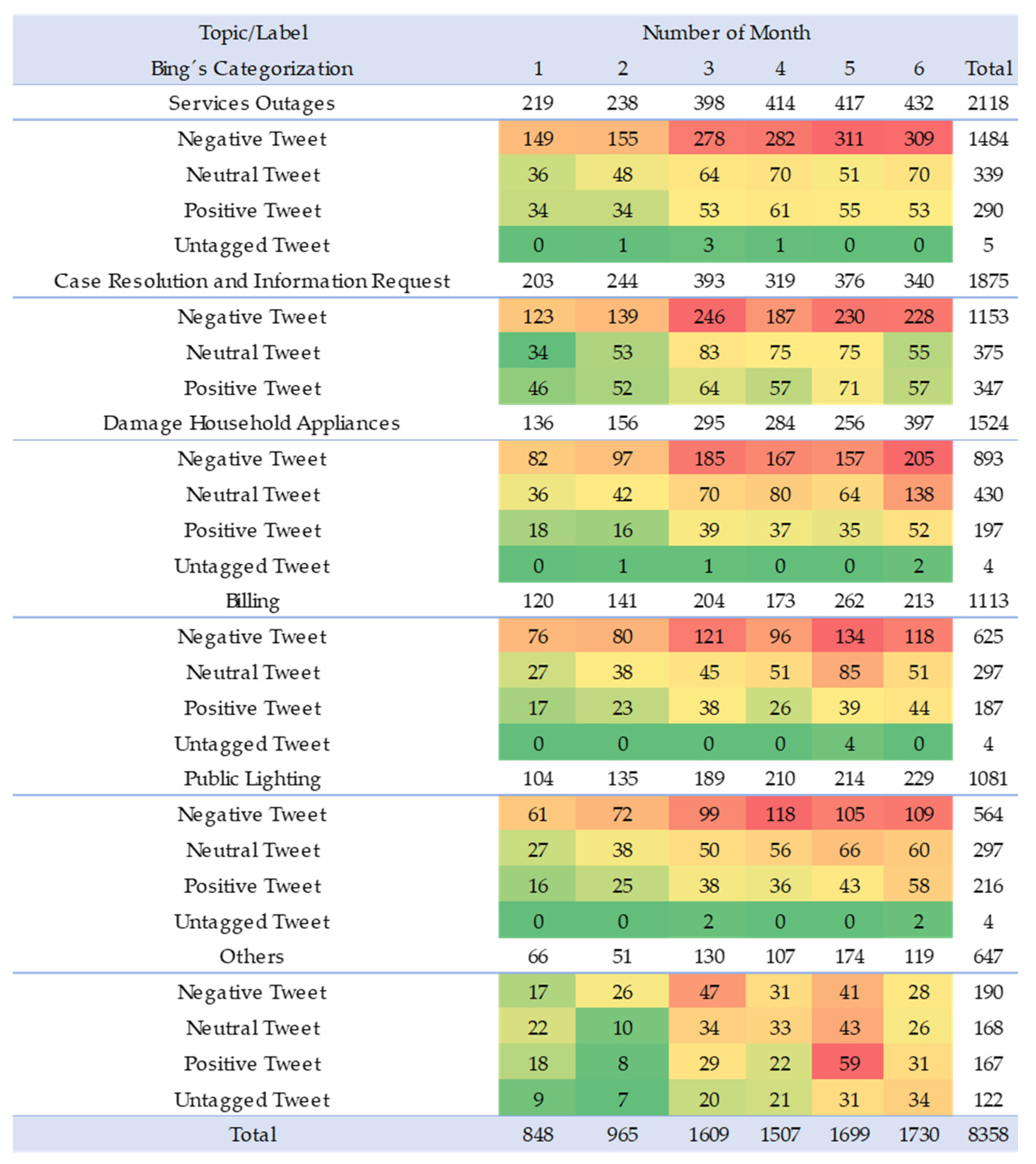
4.2.1. Evolution of Sentiment with BING
4.2.2. Evolution of Feelings with AFINN
- It is characterized by the fact that the larger the interval of the analyzed data, the smoother the resulting curve, and the better performance will be obtained by using a considerable volume of data.
- The method eliminates noise, and it helps to observe characteristics and trends in a friendly and easy manner.
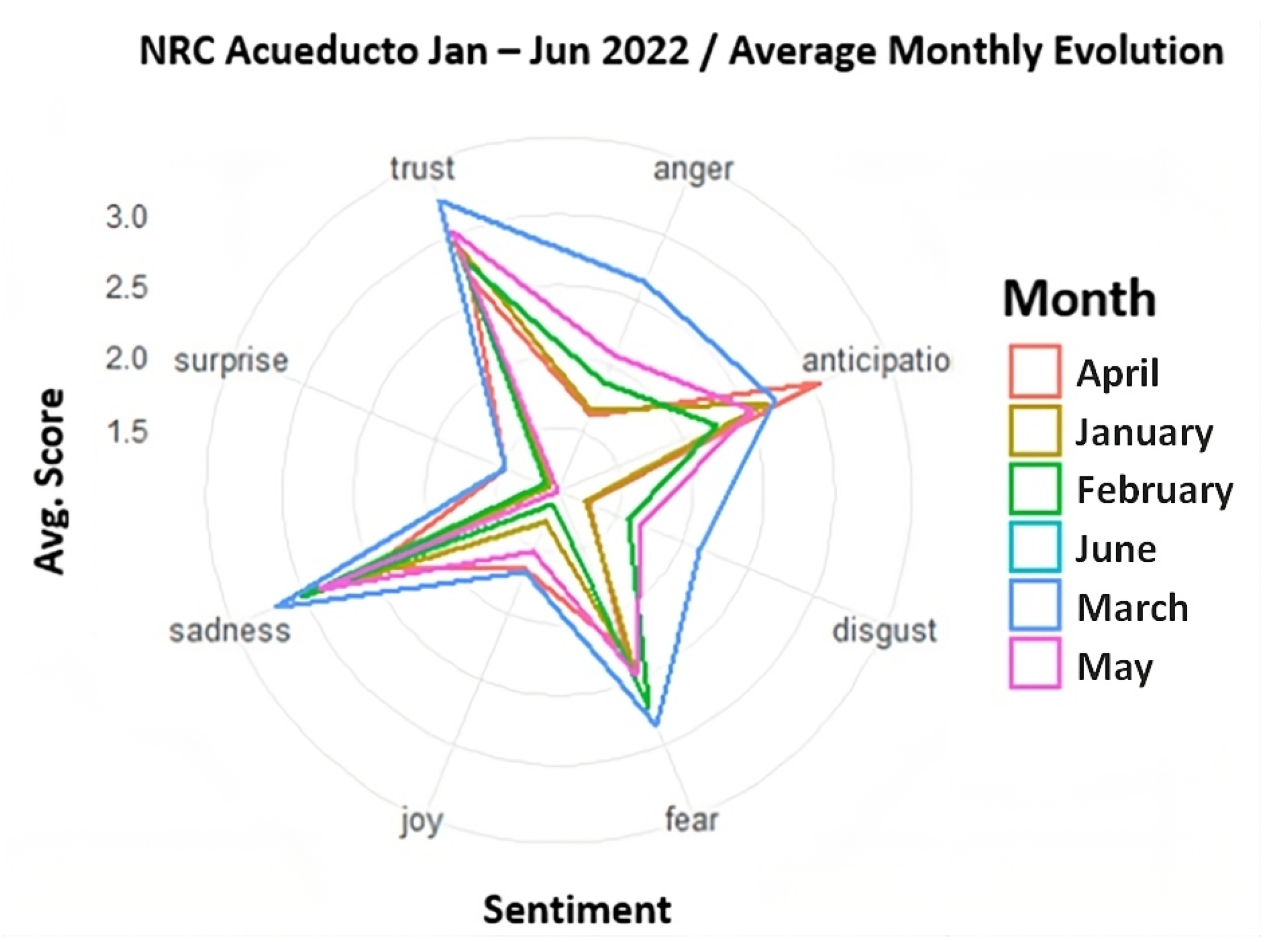
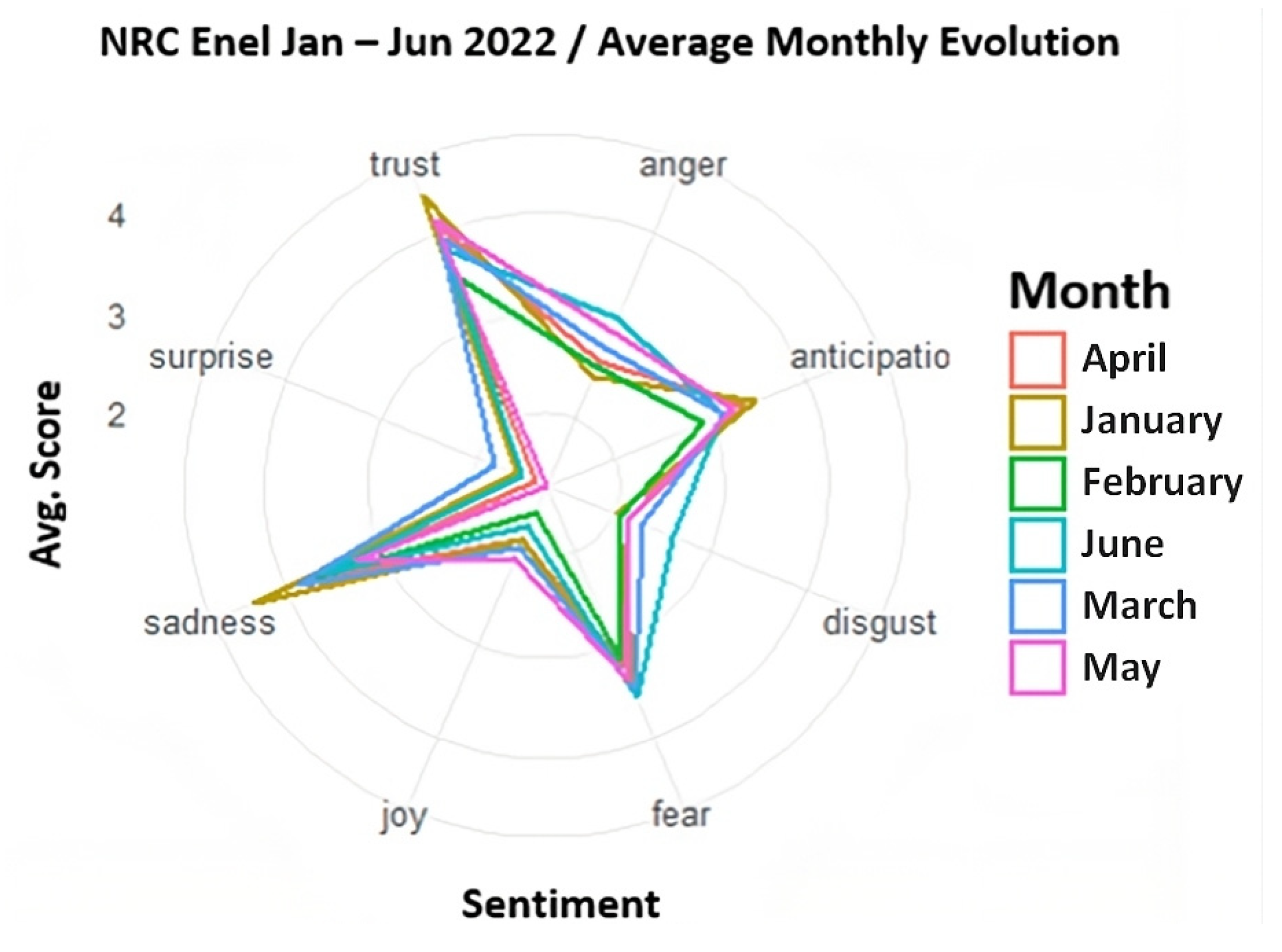
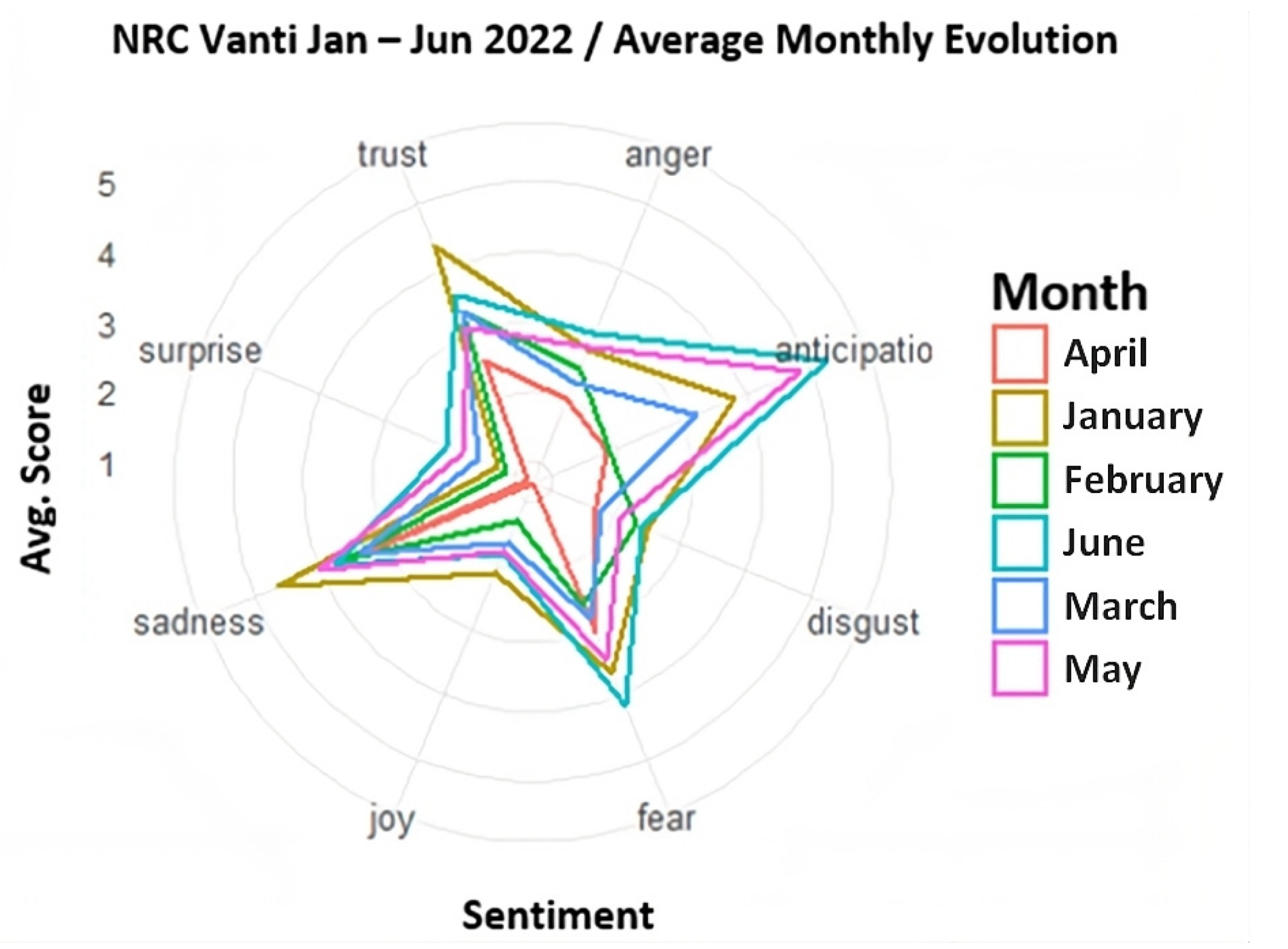
4.2.3. Evolution of Sentiments with the NRC
4.3. Topic Modeling and Trends
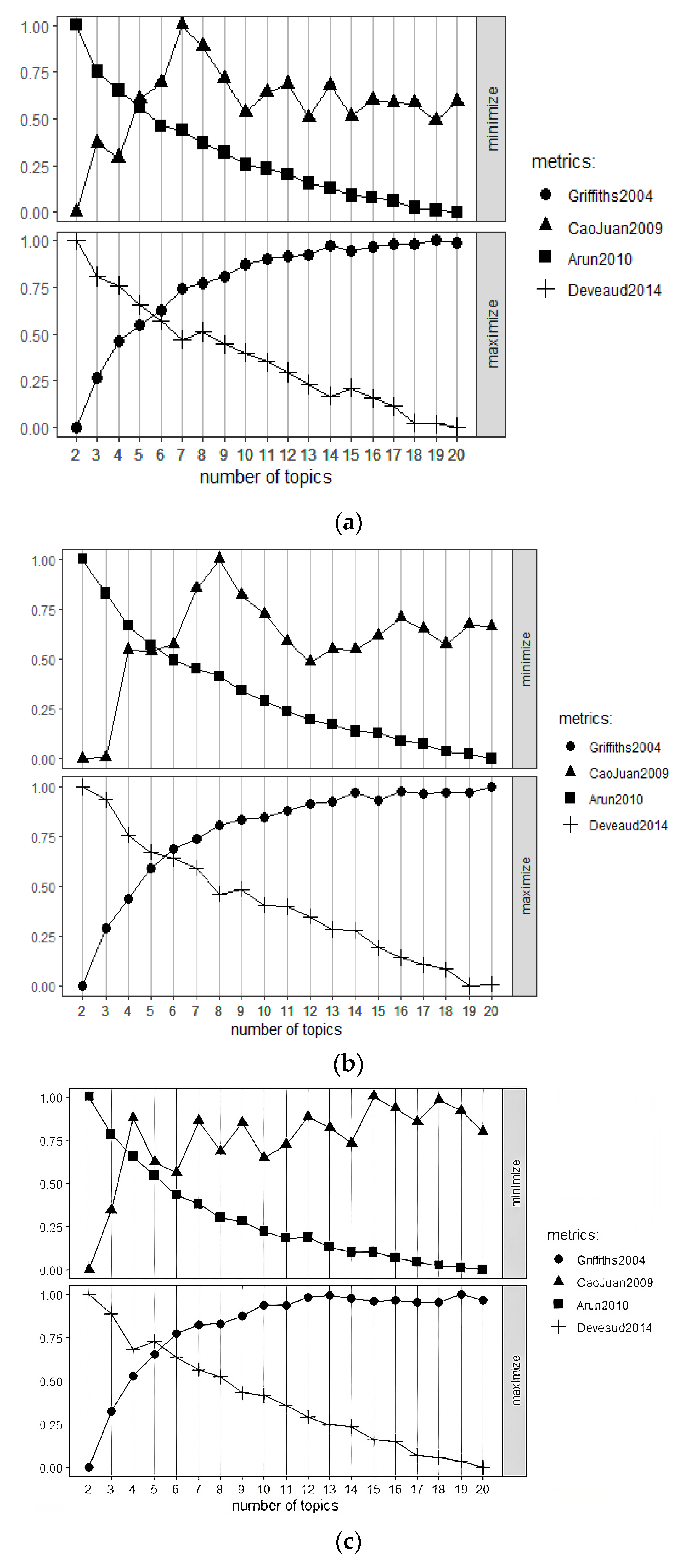
4.3.1. The Optimal Number of Topics
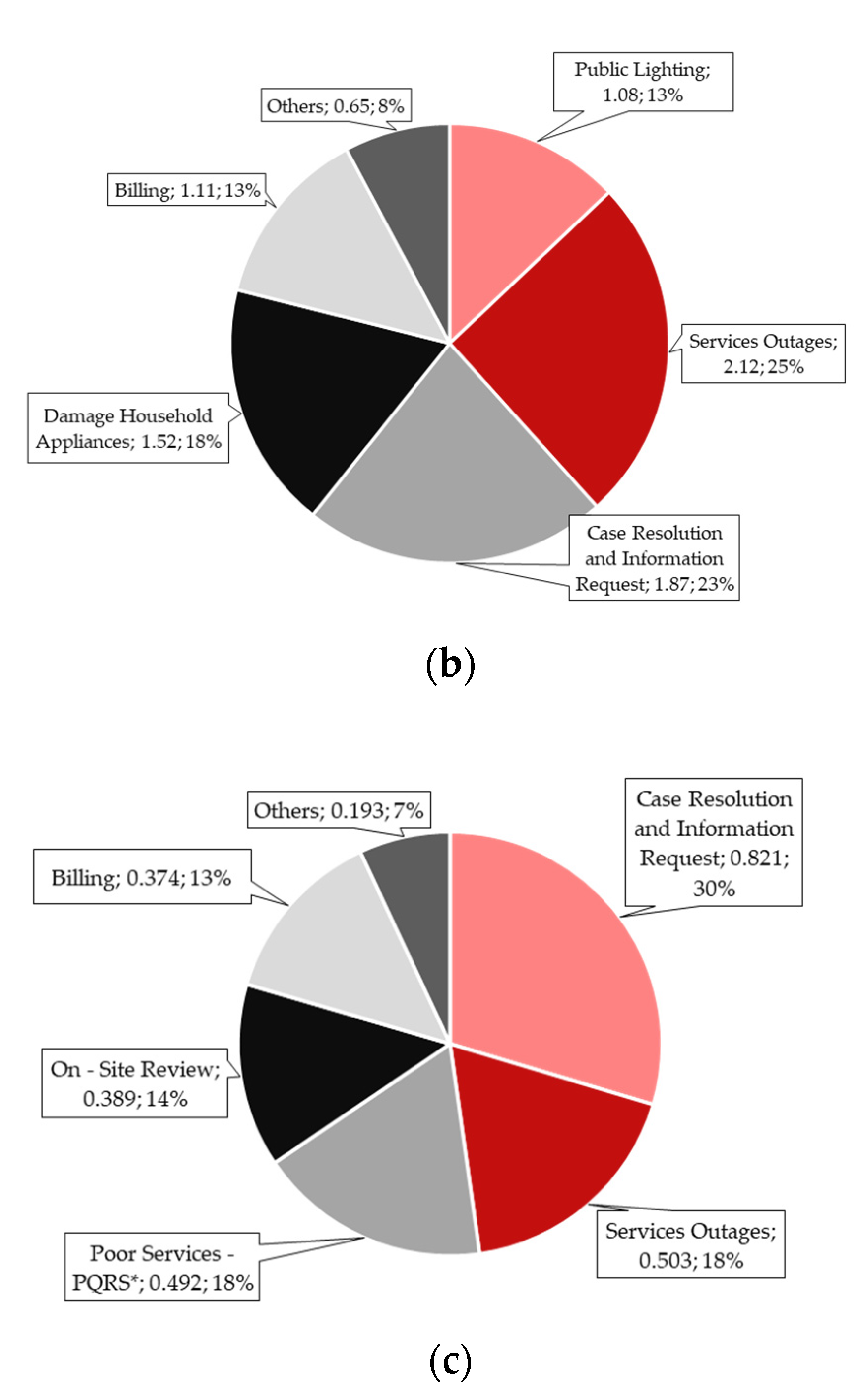
4.3.2. Main Topics
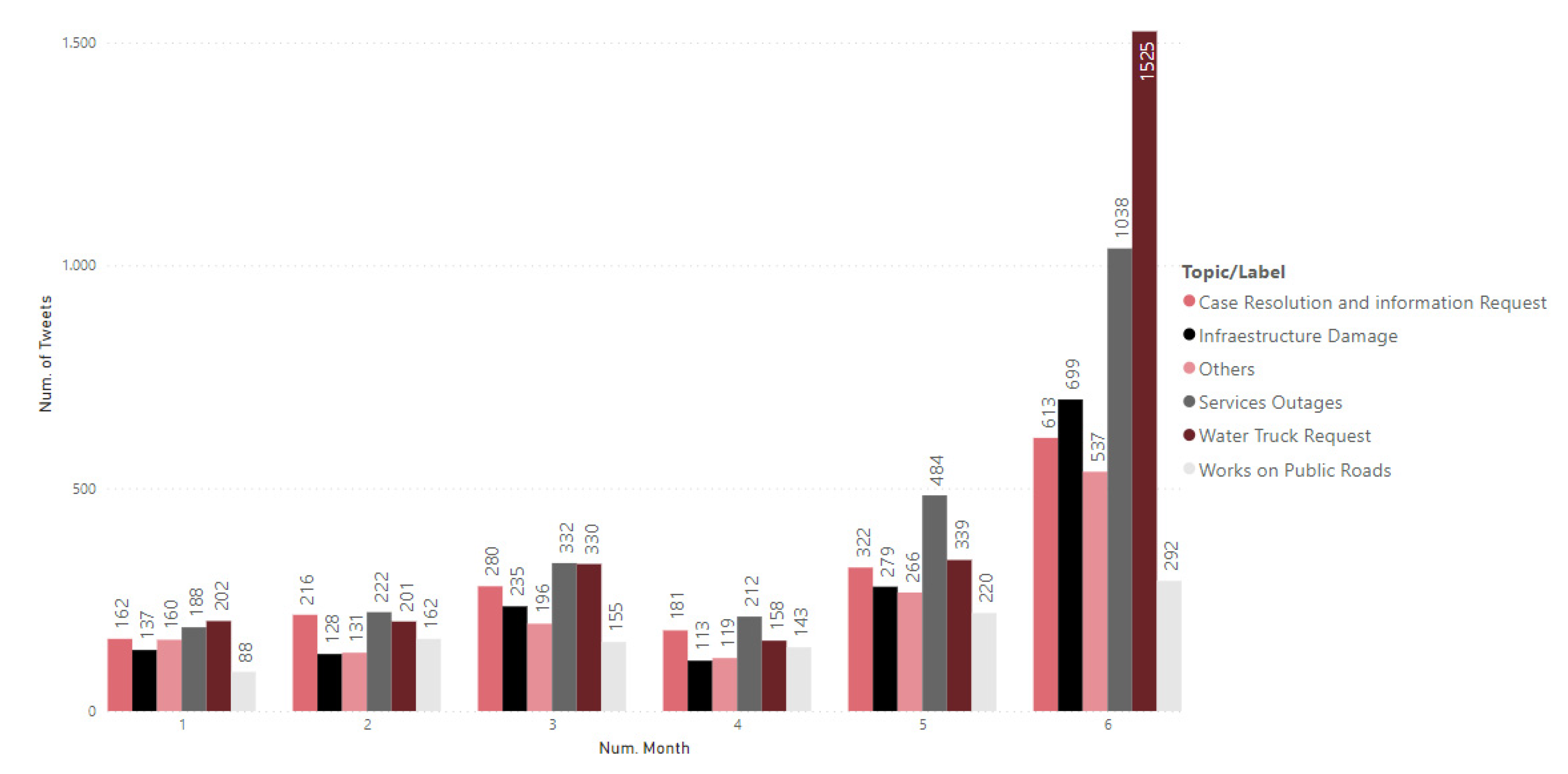
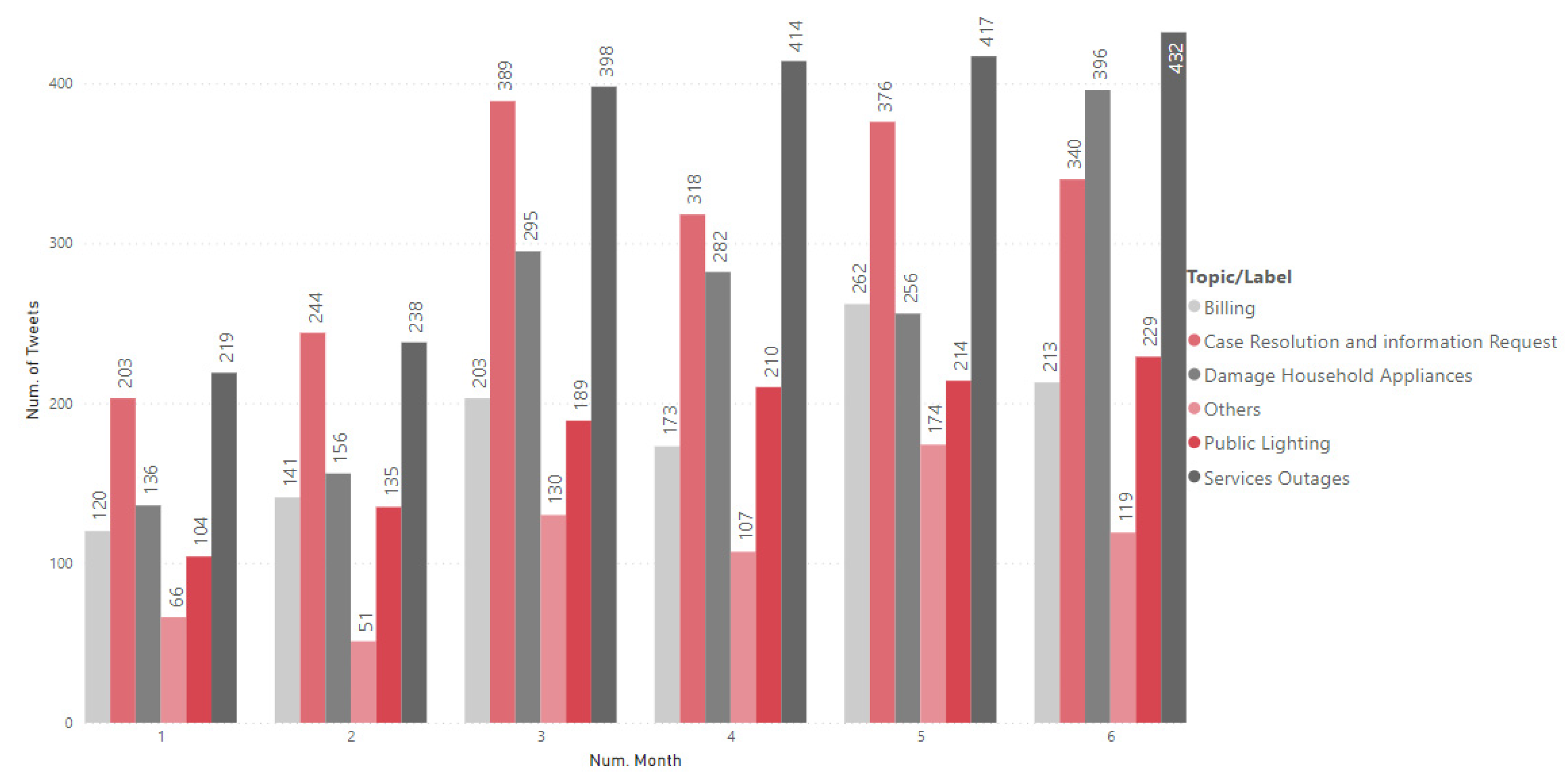
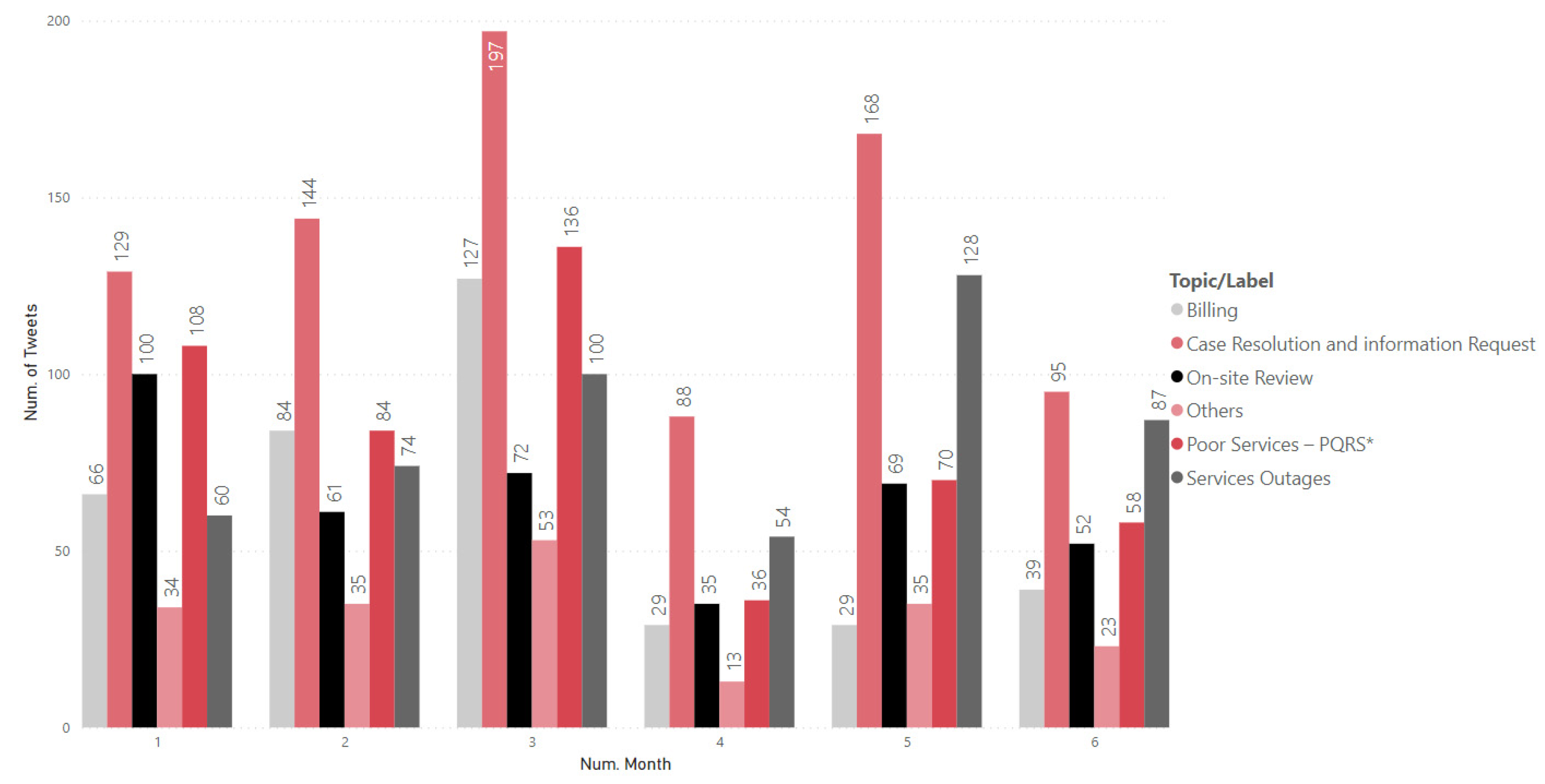
4.3.3. Temporal Evolution of Topics
4.3.4. Critical Topics
4.4. Metrics
5. Discussion
6. Future Works
- Language: enriching the dictionaries used for sentiment analysis with terms from the Latin-Spanish language will allow wider coverage of the corpus, improving the score assigned to each tweet, the tagging per word, and the homologation with the user survey scales;
- Sources of information: considering other sources of information provided by each of the companies can increase the size of the corpus, contributing to the generation of an automated model of experience management where other channels of attention are involved to identify issues of general interest as well as new knowledge that not only social networks can provide;
- Smart Cities: the use of text mining in social networks can be of potential use for projects related to smart cities since, by labeling this data, it is possible to identify social issues related to the provision of basic services and generate impact projects that improve the quality of life of users;
- Machine Learning: Considering the automation of text mining models and techniques at an unsupervised level will facilitate the creation of self-learning algorithms that can interpret according to context the message that each user transmits to each organization and create personalized attention flows. Likewise, this can be used to enrich the dictionaries used for sentiment analysis, train the algorithms to refine and improve the results of topic modeling;
- Identify irony, sarcasm, and mockery within texts: an important advance that can be made in the field of text mining to identify sentences, tweets, and messages in general is determining the irony with which the sender expresses himself or herself to obtain an objective context of the intentions of the message and what he/she wants to convey to the receiver.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Company | N° | Topic | Word Cloud | Analysis |
|---|---|---|---|---|
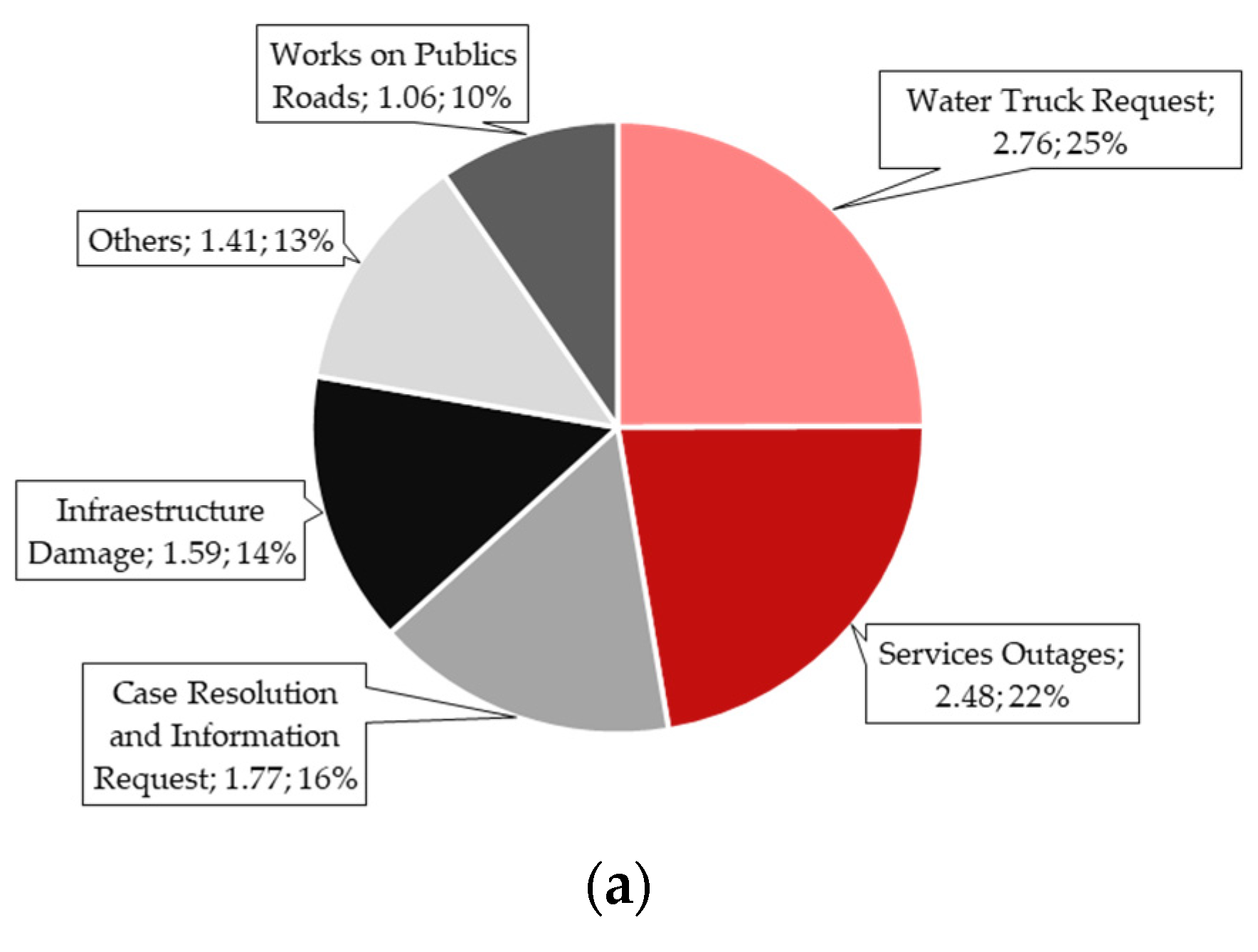
| Enel | 1 | Service Outages |  | It should be noted that for this topic the words “Cundinamarca”, “Calera”, “municipio”, and “vereda” appear, which indicates that this channel is also used at the rural level as a means of reporting failures, especially in the municipality of La Calera. Terms such as “failures”, “again”, “maintenance”, and “service” appear, which means that there are service interruptions. |
| 2 | Case Resolution and Information Request |  | For topic two, words such as “answer”, “internal”, “need”, “message”, and “response” are evidenced, which means that customers are waiting for their answers, that they have sent the data of their “cases” and that they may require an effective response to what they indicate through the channel. | |
| 3 | Billing |  | For the topic “Billing”, there is the appearance of words such as “pay”, “receipt”, “arrives”, and “invoice”, which revolve around the topic of payments and invoicing. It is evident that customers ask about the payment of their “receipts” through this network and that they may be inconvenienced since there are terms of annoyance such as “angry”. | |
| 4 | Public Lighting |  | This topic is related to power outages but directly relates to “poles” and “luminaires”. Terms such as “park”, “urgent”, “zone”, and “public” suggest that customers report public lighting failures on the social network and that, in some cases, they may be “urgent”. Terms such as “neighborhood” and “locality” show that the address of the new development is shared. | |
| 5 | Damage Household Appliances |  | As can be seen, this topic is closely related to topic one, since words such as “outages”, “damages”, and “services”, among others, appear. This indicates that, given the micro-cuts and interruptions in the electric power supply, the customers’ “electrical appliances” burn out, so the user chooses to use this channel as a means of resolution. |
Appendix B

Appendix C
| Metrics | Objective | Temporality |
|---|---|---|
| Number of tweets per hour by topic | Identify topics that may be trending within each company in advance to take corrective actions. | Per hour |
| Number of negative tweets on the critical topic by the company | Based on the identification of the topics with the highest number of negative tweets (categorized through the Bing dictionary), it is proposed to perform daily monitoring of the number of communications that are categorized within this group. As in previous cases, we can identify actions that have generated a decrease in this indicator and that can be maintained over time to generate a continuous improvement. | Daily |
| Tweet polarity score (tps) | Determine the number of positive and negative tweets according to the Bing dictionary classification. | Per hour |
| Pn Tweet polarity score (pn Tweet) | Determine the ratio between the total number of positive and negative tweets, always aiming to be greater than or equal to one. It makes it possible to quickly track the general perception of the user. | Per hour |
| User polarity score (up) | Identify the category (positive, negative, neutral, and n/a) of users from the tagging of their tweets, focusing on identifying which users have a higher amount of positive or negative tweets. It is based on the Bing dictionary | Per hour |
| Pn user polarity score (pn user) | Determine the ratio between users categorized as positive and negative according to the Bing dictionary. Like the previous metric, it shows a ratio, but this time between the number of positive and negative users, so it should aim to be at least equal to one. | Per hour |
References
- Enel. Enel Colombia Home Page. Available online: https://www.enel.com.co/es/prensa/news/d202203-inicio-enel-colombia.html (accessed on 1 March 2022).
- Vanti. Vanti Home Page. Available online: https://www.grupovanti.com/wp-content/uploads/2021/05/Informe-de-Sostenibilidad-Vanti.pdf (accessed on 18 September 2021).
- Empresa de Acueducto y Alcantarillado de Bogotá. Acueducto Bogotá Home Page. Available online: https://www.acueducto.com.co/wps/portal/EAB2/Home/la-empresa/informacion-general/!ut/p/z0/04_Sj9CPykssy0xPLMnMz0vMAfIjo8zizQKdDQwtDIz8DEyMnA0CgwOcgvxDnQ19jMz0C7IdFQFA0Q31/ (accessed on 16 September 2021).
- Super Intendencia de Servicios Públicos Domiciliarios. Super Intendencia de Servicios Públicos Home Page. Available online: https://www.superservicios.gov.co/Sala-de-prensa/noticias/en-2020-superservicios-recibio-mas-de-260-mil-tramites-y-solicitudes-de-usuarios-de-los-servicios-publicos-domiciliarios (accessed on 16 August 2021).
- Enel. Enel Colombia Home Page. Available online: https://www.enel.com.co/content/dam/enel-co/espa%C3%B1ol/sobre_enel/informes_sostenibiidad/2020/informe-de-sostenibilidad.pdf (accessed on 18 September 2021).
- Songpan, W. The Analysis and Prediction of Customer Review Rating Using Opinion Mining. In Proceedings of the 7th IEEE International Conference on Software Engineering Research, Management and Applications (SERA), London, UK, 7–9 June 2017; pp. 71–77. [Google Scholar] [CrossRef]
- Zhan, Y.; Han, R.; Tse, M.; Helmi Ali, M.; Hu, J. A social media analytic framework for improving operations and service management: A Study Of The Retail Pharmacy Industry. Technol. Forecast. Soc. Change 2021, 163, 11–14. [Google Scholar] [CrossRef]
- Bello-Orgaz, G.; Menéndez, H.; Okazaki, S.; Camacho, D. Combining social-based data mining techniques to extract collective trends from Twitter. Malays. J. Comput. Sci. 2014, 27, 95–111. [Google Scholar]
- Ngaboyamahina, M.; Sun, Y. The Impact of Sentiment Analysis on social media to Assess Customer Satisfaction: Case of Rwanda. In Proceedings of the International Conference on Big Data Analytics. In Proceedings of the IEEE 4th International Conference on Big Data Analytics (ICBDA), Suzhou, China, 15–18 March 2019; pp. 356–359. [Google Scholar]
- Kouloumpis, E.; Wilson, T.; Moore, J. Twitter Sentiment Analysis: The Good the Bad, and the OMG! In Proceedings of the International AAAI Conference on Web and Social Media, Barcelona, Spain, 17–21 July 2011; pp. 538–541. [Google Scholar]
- Avila Rodriguez, M.P. Análisis de Tweets y su Influencia en los Seguros de Vida en el Ámbito Colombiano. Master’s Thesis, Universitat Politècnica de València, Valencia, Spain, 2020. [Google Scholar]
- Innovare Pesquisa CIER. COCIER Juntos Progresamos. Available online: https://www.cocier.org/index.php/es/ (accessed on 25 October 2021).
- Chamlertwat, W.; Bhattarakosol, P.; Rungkasiri, T.; Haruechaiyasak, C. Discovering Consumer Insight from Twitter via Sentiment Analysis. J. Univers. Comput. Sci. 2018, 18, 973–992. [Google Scholar] [CrossRef]
- Ogudo, K.; Dahj Muwawa Jean, N. Sentiment Analysis Application and Natural Language Processing for Mobile Network Operators’ Support on social media. In Proceedings of the International Conference on Advances in Big Data, Computing and Data Communication Systems (icABCD), Winterton, South Africa, 5–6 August 2019; pp. 1–10. [Google Scholar]
- Ranjan, S.; Sood, S.; Verma, V. Twitter Sentiment Analysis of Real-time Customer Experience Feedback for Predicting Growth of Indian Telecom Companies. In Proceedings of the 4th International Conference on Computing Sciences (ICCS), Jalandhar, India, 30–31 August 2018; pp. 166–174. [Google Scholar] [CrossRef]
- Sari, E.Y.; Wierfi, A.D.; Setyanto, A. Sentiment Analysis of Customer Satisfaction on Transportation Network Company Using Naive Bayes Classifier. In Proceedings of the International Conference on Computer Engineering, Network and Intelligent Multimedia (CENIM), Surabaya, Indonesia, 19–20 November 2019; pp. 1–6. [Google Scholar]
- Ba, Y.; Lee, H. Sentiment Analysis of Twitter Audiences: Measuring the Positive or Negative Influence of Popular Twitterers. J. Am. Soc. Inf. Sci. Technol. 2012, 63, 2522–2535. [Google Scholar] [CrossRef]
- Kuo, W.K.; Riantama, D.; Chen, L.S. Using a Text Mining Approach to Hear Voices of Customers from social media toward the Fast-Food Restaurant Industry. Sustainability 2021, 13, 268. [Google Scholar] [CrossRef]
- Fayyad, U.; Piatetsky-Shapiro, G.; Smyth, P. The KDD Process for Extracting Useful Knowledge from Volumes of Data. Commun. ACM 1996, 39, 27–34. [Google Scholar] [CrossRef]
- Valcárcel Asencios, V. Data mining y el descubrimiento del conocimiento. Ind. Data 2004, 7, 83–86. [Google Scholar] [CrossRef]
- R Core Team. R Home Page. Available online: https://www.R-project.org/ (accessed on 1 February 2022).
- Microsoft Corporation. Microsoft Home Page. Available online: https://powerbi.microsoft.com/es-es/ (accessed on 12 October 2022).





















| Application | Author | Field | Description |
|---|---|---|---|
| Reference framework | M. Ngaboyamahina and Y. Sun | Perception of public services in Rwanda | Definition of four general states in text analysis. |
| Reference framework | Kouloumpis, E., Wilson, T., and Moore, J | Sentiment analysis | The general process of applying sentiment analysis to a large corpus. |
| Reference framework | Avila Rodriguez, | Life insurance | Neural networks and machine learning models to understand and personalize life insurance tax. |
| VOCs in social media | Songpan | After-sales tourism | Comparison of hotel reviews and ratings using Naive Bayes and decision trees. |
| VOCs in social media | Bello-Orgaz, Menéndez, Okazaki, and Camacho | Furniture and decoration | Comparison of customer reviews using the C.4.5 Tree and clustering through the Dirichlet Process algorithm. |
| VOCs in social media | Kuo, Riantama, and Chen | Fast food | Main topics in customer reviews before and after the pandemic: comparison using TD-IDF and LASSO. |
| Customer perception | Ba and Lee | Perception of public figures | Perception of public figures, comparison metrics, and analysis over time. Use of statistical analysis through regression and comparison. |
| Benchmarks | Chamlertwat, Bhattarakosol, Rungkasiri, and Haruechaiyasak | Mobile phone | Technology Products: comparison of basic characteristics to know the customers’ perception of the new products. |
| Benchmarks | Zhan, Han, Tse, Helmi Ali, and Hu | Pharmacy retail in the UK | Integration of customer pain points with operations based on sentiment analysis (Lexicon), topic modeling (LDA), and visual models (heatmap). |
| Benchmarks | Ranjan, Sood, and Verma | Telecomunications in India | Study of the impact on the followers of the pages of a new competitor in the market, applying correlation analysis and TD-IDF. |
| Benchmarks | Sari, Wierfi, and Setyanto | Public transport | Identification of the polarity of these on two Indian private transportation companies through online platforms using Naive Bayes, TF-IDF, and RapidMinker. |
| Benchmarks | Ogudo and Dahj Muwawa Jean | Mobile networks in South Africa | Determining and defining the level of potential detraction and promotion of three mobile network operators in South Africa via EDA and R. |
| Public Basic Service | Company | Twitter Account | Number of Tweets |
|---|---|---|---|
| Electricity | Enel Colombia, Colombia, Bogotá. | @ codensaservicio @EnelColombia @EnelClientesCo | 8358 |
| Natural Gas | Vanti, Colombia, Bogotá. | @grupovanti | 2773 |
| Aqueduct | Acueducto y Alcantarillado, Colombia, Bogotá. | @AcueductoBogota | 12,479 |
| Dictionary | Syuzhet Library | Merge (Assignment) | Result | ||
|---|---|---|---|---|---|
| No. Tweets Affected | % | No. Tweets Affected | % | ||
| Bing | 948 | 49.17% | 1367 | 70.9% | Assignment |
| AFINN | 728 | 37.75% | 1226 | 63.59% | Assignment |
| NRC | 845 | 43.82% | 732 | 37.97% | RStudio |
| Public Basic Service | Categorized Tweets | Unassigned Tweets | Total Tweets |
|---|---|---|---|
| Electricity | 10,802 (86.56%) | 1677 (13.43%) | 12,479 |
| Natural Gas | 7390 (88.42%) | 968 (11.58%) | 8358 |
| Aqueduct | 2623 (94.6%) | 150 (5.4%) | 2773 |
| Topic | Acueducto | Enel | Vanti |
|---|---|---|---|
| 1 | Water truck request | Services outages | Billing |
| 2 | Services outages | Case resolution and information request | Services outages |
| 3 | Infraestructure damage | Billing | On-site review |
| 4 | Works on public roads | Public lighting | Poor services—PQRS * |
| 5 | Case resolution and information request | Damage household appliances | Case resolution and information request |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Conti, D.; Gomez, C.E.; Jaramillo, J.G.; Ospina, V.E. Monitoring the Quality and Perception of Service in Colombian Public Service Companies with Twitter and Descriptive Temporal Analysis. Appl. Sci. 2023, 13, 10338. https://doi.org/10.3390/app131810338
Conti D, Gomez CE, Jaramillo JG, Ospina VE. Monitoring the Quality and Perception of Service in Colombian Public Service Companies with Twitter and Descriptive Temporal Analysis. Applied Sciences. 2023; 13(18):10338. https://doi.org/10.3390/app131810338
Chicago/Turabian StyleConti, Dante, Carlos Eduardo Gomez, Juan Guillermo Jaramillo, and Victoria Eugenia Ospina. 2023. "Monitoring the Quality and Perception of Service in Colombian Public Service Companies with Twitter and Descriptive Temporal Analysis" Applied Sciences 13, no. 18: 10338. https://doi.org/10.3390/app131810338
APA StyleConti, D., Gomez, C. E., Jaramillo, J. G., & Ospina, V. E. (2023). Monitoring the Quality and Perception of Service in Colombian Public Service Companies with Twitter and Descriptive Temporal Analysis. Applied Sciences, 13(18), 10338. https://doi.org/10.3390/app131810338