


Human Action Recognition Based on Hierarchical Multi-Scale Adaptive Conv-Long Short-Term Memory Network



Abstract
:1. Introduction
- We propose a novel HMA Conv-LSTM network, which realizes HAR that can well distinguish confusing actions of subtle processes. Extensive experiments on four public datasets of Opportunity, PAMAP2, USC-HAD, and Skoda show the effectiveness of our proposed model.
- We propose the hierarchical multi-scale convolution module, which performs finer-grained feature extraction by hierarchical architecture and multi-scale convolution on spatial information of feature vectors.
- In addition, we propose the adaptive channel feature fusion module is capable of fusing features at different scales, which improve the efficiency of the model and remove redundant information.
- For the multi-channel feature maps extracted by adaptive channel feature fusion, we propose the dynamic channel-selection-LSTM module based on the attention mechanism to extract the temporal context information.
2. Related Work
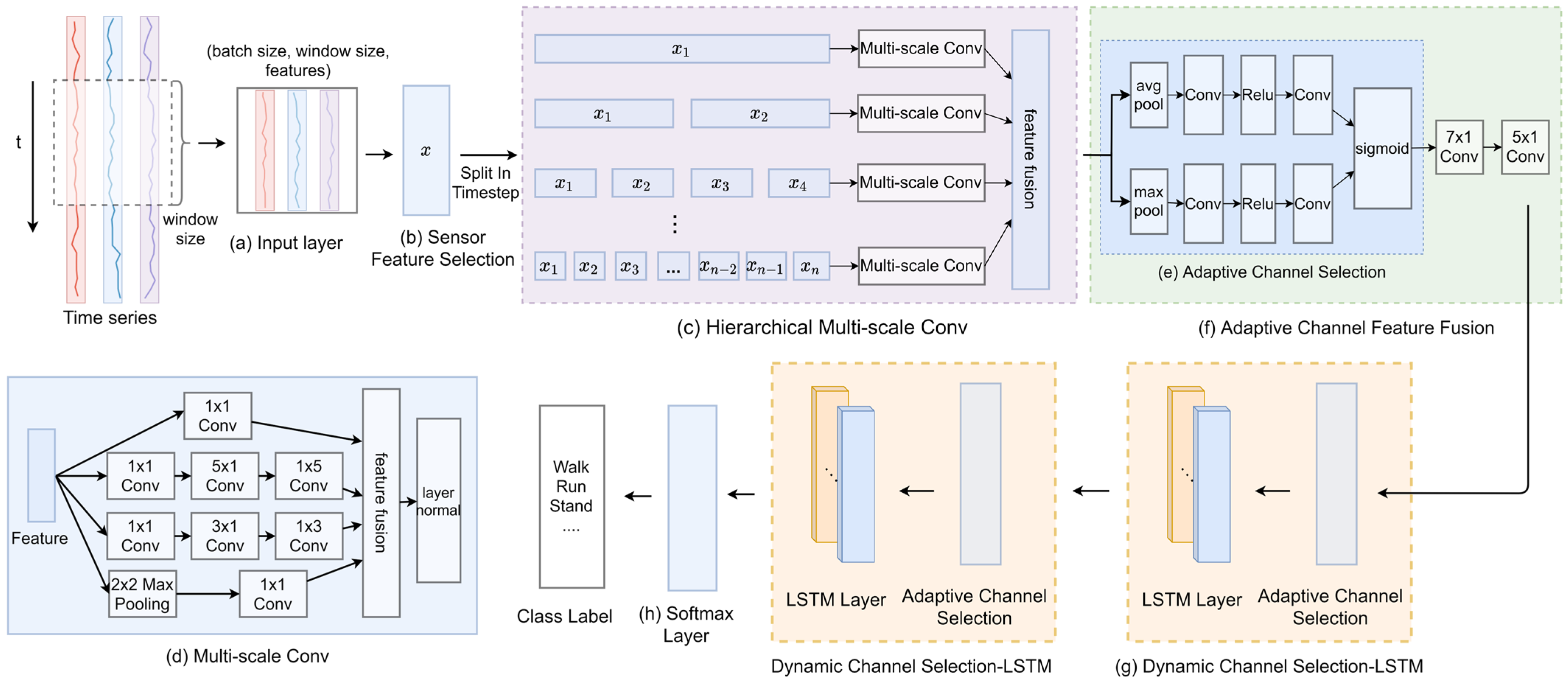
3. Proposed Method
3.1. Data Preprocess
3.1.1. Data Completion
3.1.2. Data Normalization
3.1.3. Data Segmentation and Downsampling
3.2. Sensor Feature Selection
3.3. Hierarchical Multi-Scale Convolution
3.3.1. Multi-Scale Convolution
3.3.2. Hierarchical Architecture
3.4. Adaptive Channel Feature Fusion
3.4.1. Adaptive Channel Selection
3.4.2. Multi-Scale Channel Feature Fusion
3.5. Dynamic Channel-Selection-LSTM
4. Experiments
4.1. Experimental Setup
4.2. Dataset Description
4.3. Performance Metric
4.4. Comparison with State-of-the-Art Methods
5. Ablation Study and Discussion
5.1. Parameter Selection
5.2. Effectiveness of the Proposed Modules
5.3. Comparison of Specific Actions
5.4. Visualizing Sensor Feature Selection Weights
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Anagnostis, A.; Benos, L.; Tsaopoulos, D.; Tagarakis, A.; Tsolakis, N.; Bochtis, D. Human activity recognition through recurrent neural networks for human–robot interaction in agriculture. Appl. Sci. 2021, 11, 2188. [Google Scholar] [CrossRef]
- Asghari, P.; Soleimani, E.; Nazerfard, E. Online human activity recognition employing hierarchical hidden Markov models. J. Ambient Intell. Humaniz. Comput. 2020, 11, 1141–1152. [Google Scholar] [CrossRef]
- Ramos, R.G.; Domingo, J.D.; Zalama, E.; Gómez-García-Bermejo, J.; López, J. SDHAR-HOME: A sensor dataset for human activity recognition at home. Sensors 2022, 22, 8109. [Google Scholar] [CrossRef] [PubMed]
- Khan, W.Z.; Xiang, Y.; Aalsalem, M.Y.; Arshad, Q. Mobile phone sensing systems: A survey. IEEE Commun. Surv. Tutor. 2012, 15, 402–427. [Google Scholar] [CrossRef]
- Taylor, K.; Abdulla, U.A.; Helmer, R.J.; Lee, J.; Blanchonette, I. Activity classification with smart phones for sports activities. Procedia Eng. 2011, 13, 428–433. [Google Scholar] [CrossRef]
- Zhang, S.; Wei, Z.; Nie, J.; Huang, L.; Wang, S.; Li, Z. A review on human activity recognition using vision-based method. J. Healthc. Eng. 2017, 2017, 3090343. [Google Scholar] [CrossRef]
- Dang, L.M.; Min, K.; Wang, H.; Piran, M.J.; Lee, C.H.; Moon, H. Sensor-based and vision-based human activity recognition: A comprehensive survey. Pattern Recognit. 2020, 108, 107561. [Google Scholar] [CrossRef]
- Abdel-Salam, R.; Mostafa, R.; Hadhood, M. Human activity recognition using wearable sensors: Review, challenges, evaluation benchmark. In Proceedings of the International Workshop on Deep Learning for Human Activity Recognition, Montreal, QC, Canada, 21–26 August 2021; pp. 1–15. [Google Scholar]
- Sun, Z.; Ke, Q.; Rahmani, H.; Bennamoun, M.; Wang, G.; Liu, J. Human action recognition from various data modalities: A review. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3200–3225. [Google Scholar] [CrossRef]
- Bulling, A.; Blanke, U.; Schiele, B. A tutorial on human activity recognition using body-worn inertial sensors. ACM Comput. Surv. (CSUR) 2014, 46, 1–33. [Google Scholar] [CrossRef]
- Bao, L.; Intille, S.S. Activity recognition from user-annotated acceleration data. In Proceedings of the International Conference on Pervasive Computing, Nottingham, UK, 7–10 September 2004; pp. 1–17. [Google Scholar]
- Plötz, T.; Hammerla, N.Y.; Olivier, P.L. Feature learning for activity recognition in ubiquitous computing. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011. [Google Scholar]
- Bengio, Y. Deep learning of representations: Looking forward. In Proceedings of the Statistical Language and Speech Processing, Tarragona, Spain, 29–31 July 2013; pp. 1–37. [Google Scholar]
- Islam, M.M.; Nooruddin, S.; Karray, F.; Muhammad, G. Human activity recognition using tools of convolutional neural networks: A state of the art review, data sets, challenges, and future prospects. Comput. Biol. Med. 2022, 149, 106060. [Google Scholar] [CrossRef]
- Yang, J.; Nguyen, M.N.; San, P.P.; Li, X.; Krishnaswamy, S. Deep convolutional neural networks on multichannel time series for human activity recognition. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 3995–4001. [Google Scholar]
- Ha, S.; Yun, J.-M.; Choi, S. Multi-modal convolutional neural networks for activity recognition. In Proceedings of the 2015 IEEE International Conference on Systems, Man, and Cybernetics, Hong Kong, China, 9–12 October 2015; pp. 3017–3022. [Google Scholar]
- Guan, Y.; Plötz, T. Ensembles of deep lstm learners for activity recognition using wearables. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2017, 1, 1–28. [Google Scholar] [CrossRef]
- Hammerla, N.Y.; Halloran, S.; Plötz, T. Deep, convolutional, and recurrent models for human activity recognition using wearables. arXiv 2016, arXiv:1604.08880. [Google Scholar]
- Dua, N.; Singh, S.N.; Semwal, V.B. Multi-input CNN-GRU based human activity recognition using wearable sensors. Computing 2021, 103, 1461–1478. [Google Scholar] [CrossRef]
- Zhao, Y.; Yang, R.; Chevalier, G.; Xu, X.; Zhang, Z. Deep residual bidir-LSTM for human activity recognition using wearable sensors. Math. Probl. Eng. 2018, 2018, 7316954. [Google Scholar] [CrossRef]
- Ordóñez, F.J.; Roggen, D. Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef]
- Yao, S.; Hu, S.; Zhao, Y.; Zhang, A.; Abdelzaher, T. Deepsense: A unified deep learning framework for time-series mobile sensing data processing. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 351–360. [Google Scholar]
- Nan, Y.; Lovell, N.H.; Redmond, S.J.; Wang, K.; Delbaere, K.; van Schooten, K.S. Deep learning for activity recognition in older people using a pocket-worn smartphone. Sensors 2020, 20, 7195. [Google Scholar] [CrossRef]
- Radu, V.; Tong, C.; Bhattacharya, S.; Lane, N.D.; Mascolo, C.; Marina, M.K.; Kawsar, F. Multimodal deep learning for activity and context recognition. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 1, 1–27. [Google Scholar] [CrossRef]
- Ma, H.; Li, W.; Zhang, X.; Gao, S.; Lu, S. AttnSense: Multi-level attention mechanism for multimodal human activity recognition. In Proceedings of the International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 3109–3115. [Google Scholar]
- Mahmud, S.; Tonmoy, M.; Bhaumik, K.K.; Rahman, A.M.; Amin, M.A.; Shoyaib, M.; Khan, M.A.H.; Ali, A.A. Human activity recognition from wearable sensor data using self-attention. arXiv 2020, arXiv:2003.09018. [Google Scholar]
- Murahari, V.S.; Plötz, T. On attention models for human activity recognition. In Proceedings of the 2018 ACM International Symposium on Wearable Computers, Singapore, 8–12 October 2018; pp. 100–103. [Google Scholar]
- Haque, M.N.; Tonmoy, M.T.H.; Mahmud, S.; Ali, A.A.; Khan, M.A.H.; Shoyaib, M. Gru-based attention mechanism for human activity recognition. In Proceedings of the 2019 1st International Conference on Advances in Science, Engineering and Robotics Technology (ICASERT), Dhaka, Bangladesh, 3–5 May 2019; pp. 1–6. [Google Scholar]
- Al-qaness, M.A.; Dahou, A.; Abd Elaziz, M.; Helmi, A. Multi-ResAtt: Multilevel residual network with attention for human activity recognition using wearable sensors. IEEE Trans. Ind. Inform. 2022, 19, 144–152. [Google Scholar] [CrossRef]
- Duan, F.; Zhu, T.; Wang, J.; Chen, L.; Ning, H.; Wan, Y. A Multi-Task Deep Learning Approach for Sensor-based Human Activity Recognition and Segmentation. IEEE Trans. Instrum. Meas. 2023, 72, 2514012. [Google Scholar] [CrossRef]
- Gomes, E.; Bertini, L.; Campos, W.R.; Sobral, A.P.; Mocaiber, I.; Copetti, A. Machine learning algorithms for activity-intensity recognition using accelerometer data. Sensors 2021, 21, 1214. [Google Scholar] [CrossRef] [PubMed]
- Van Kasteren, T.; Noulas, A.; Englebienne, G.; Kröse, B. Accurate activity recognition in a home setting. In Proceedings of the 10th International Conference on Ubiquitous Computing, Seoul, Republic of Korea, 21–24 September 2008; pp. 1–9. [Google Scholar]
- Tran, D.N.; Phan, D.D. Human activities recognition in android smartphone using support vector machine. In Proceedings of the 2016 7th International Conference on Intelligent Systems, Modelling and Simulation (Isms), Bangkok, Thailand, 25–27 January 2016; pp. 64–68. [Google Scholar]
- Figo, D.; Diniz, P.C.; Ferreira, D.R.; Cardoso, J.M. Preprocessing techniques for context recognition from accelerometer data. Pers. Ubiquitous Comput. 2010, 14, 645–662. [Google Scholar] [CrossRef]
- Jiang, W.; Yin, Z. Human activity recognition using wearable sensors by deep convolutional neural networks. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 1307–1310. [Google Scholar]
- Ullah, M.; Ullah, H.; Khan, S.D.; Cheikh, F.A. Stacked lstm network for human activity recognition using smartphone data. In Proceedings of the 8th European Workshop on Visual Information Processing (EUVIP), Roma, Italy, 28–31 October 2019; pp. 175–180. [Google Scholar]
- Mohsen, S. Recognition of human activity using GRU deep learning algorithm. Multimed. Tools Appl. 2023, 1–17. [Google Scholar] [CrossRef]
- Gaur, D.; Kumar Dubey, S. Development of Activity Recognition Model using LSTM-RNN Deep Learning Algorithm. J. Inf. Organ. Sci. 2022, 46, 277–291. [Google Scholar]
- Nafea, O.; Abdul, W.; Muhammad, G.; Alsulaiman, M. Sensor-based human activity recognition with spatio-temporal deep learning. Sensors 2021, 21, 2141. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Zhang, Z.; Wang, W.; An, A.; Qin, Y.; Yang, F. A human activity recognition method using wearable sensors based on convtransformer model. Evol. Syst. 2023, 1–17. [Google Scholar] [CrossRef]
- Xiao, S.; Wang, S.; Huang, Z.; Wang, Y.; Jiang, H. Two-stream transformer network for sensor-based human activity recognition. Neurocomputing 2022, 512, 253–268. [Google Scholar] [CrossRef]
- Zhao, C.; Huang, X.; Li, Y.; Yousaf Iqbal, M. A double-channel hybrid deep neural network based on CNN and BiLSTM for remaining useful life prediction. Sensors 2020, 20, 7109. [Google Scholar] [CrossRef]
- Zeng, M.; Wang, X.; Nguyen, L.T.; Wu, P.; Mengshoel, O.J.; Zhang, J. Adaptive activity recognition with dynamic heterogeneous sensor fusion. In Proceedings of the 6th International Conference on Mobile Computing, Applications and Services, Austin, TX, USA, 6–7 November 2014; pp. 189–196. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Karpathy, A.; Johnson, J.; Fei-Fei, L. Visualizing and understanding recurrent networks. arXiv 2015, arXiv:1506.02078. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Haresamudram, H.; Anderson, D.V.; Plötz, T. On the role of features in human activity recognition. In Proceedings of the 2019 ACM International Symposium on Wearable Computers, New York, NY, USA, 9–13 September 2019; pp. 78–88. [Google Scholar]
- Roggen, D.; Calatroni, A.; Rossi, M.; Holleczek, T.; Förster, K.; Tröster, G.; Lukowicz, P.; Bannach, D.; Pirkl, G.; Ferscha, A. Collecting complex activity datasets in highly rich networked sensor environments. In Proceedings of the 2010 Seventh International Conference on Networked Sensing Systems (INSS), Kassel, Germany, 15–18 June 2010; pp. 233–240. [Google Scholar]
- Reiss, A.; Stricker, D. Introducing a new benchmarked dataset for activity monitoring. In Proceedings of the 2012 16th International Symposium on Wearable Computers, Newcastle, UK, 18–22 June 2012; pp. 108–109. [Google Scholar]
- Zhang, M.; Sawchuk, A.A. USC-HAD: A daily activity dataset for ubiquitous activity recognition using wearable sensors. In Proceedings of the 2012 ACM Conference on Ubiquitous Computing, Pittsburgh, PA, USA, 5–8 September 2012; pp. 1036–1043. [Google Scholar]
- Stiefmeier, T.; Roggen, D.; Ogris, G.; Lukowicz, P.; Tröster, G. Wearable activity tracking in car manufacturing. IEEE Pervasive Comput. 2008, 7, 42–50. [Google Scholar] [CrossRef]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Their Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Zeng, M.; Gao, H.; Yu, T.; Mengshoel, O.J.; Langseth, H.; Lane, I.; Liu, X. Understanding and improving recurrent networks for human activity recognition by continuous attention. In Proceedings of the 2018 ACM international symposium on wearable computers, New York, NY, USA, 8–12 October 2018; pp. 56–63. [Google Scholar]
- Yao, S.; Zhao, Y.; Shao, H.; Liu, D.; Liu, S.; Hao, Y.; Piao, A.; Hu, S.; Lu, S.; Abdelzaher, T.F. Sadeepsense: Self-attention deep learning framework for heterogeneous on-device sensors in internet of things applications. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; pp. 1243–1251. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameters | Value |
|---|---|
| Optimizer | Adam |
| Loss function | Cross entropy |
| Batch size | 128 |
| Learning rate | 0.001 |
| Learning rate scheduler | Cosine |
| Training epoch | 80 |
| Dropout rate | 0.3 |
| Dataset | Action Number | Validation Subject ID | Test Subject ID | Sampling Rate | Downsampling | Sensors Used |
|---|---|---|---|---|---|---|
| Opportunity | 18 | 1(Run 2) | 2, 3(Run 4, 5) | 30 Hz | 100% | A, G, M |
| PAMAP2 | 12 | 105 | 106 | 100 Hz | 33% | A, G |
| USC-HAD | 12 | 11, 12 | 13, 14 | 100 Hz | 33% | A, G |
| Skoda | 11 | 1(10%) | 1(10%) | 98 Hz | 33% | A |
| Methods | Opportunity | PAMAP2 | USC-HAD | Skoda |
|---|---|---|---|---|
| SVM [53] | - | 0.71 | - | 0.82 |
| RF [54] | - | 0.74 | - | 0.83 |
| CNN [55] | 0.59 | 0.82 | 0.41 | 0.85 |
| LSTM [56] | 0.63 | 0.75 | 0.38 | 0.89 |
| b-LSTM [18] | 0.68 | 0.84 | 0.39 | 0.91 |
| DeepConvLSTM [21] | 0.67 | 0.75 | 0.38 | 0.91 |
| DeepConvLSTM + Attention [27] | 0.71 | 0.88 | - | 0.91 |
| LSTM + Continuous Attention [57] | - | 0.90 | - | 0.94 |
| ConvAE [48] | 0.72 | 0.80 | 0.46 | 0.79 |
| SADeepSense [58] | 0.66 | 0.66 | 0.49 | 0.90 |
| AttnSense [25] | 0.66 | 0.89 | 0.49 | 0.93 |
| Self-Attention * [26] | 0.63 | 0.84 | 0.51 | 0.87 |
| HMA Conv-LSTM | 0.68 | 0.91 | 0.53 | 0.96 |
| Model | Opportunity | PAMAP2 | USC-HAD | Skoda | ||||
|---|---|---|---|---|---|---|---|---|
| F1-Score | ∆ | F1-Score | ∆ | F1-Score | ∆ | F1-Score | ∆ | |
| HMA Conv-LSTM | 0.68 | - | 0.91 | - | 0.53 | - | 0.96 | - |
| -SFS | 0.65 | −0.03 | 0.87 | −0.04 | 0.51 | −0.02 | 0.93 | −0.03 |
| -ACFF (+Two Convolution Layer) | 0.65 | −0.03 | 0.89 | −0.02 | 0.50 | −0.03 | 0.94 | −0.02 |
| -DCS-LSTM (+LSTM) | 0.66 | −0.02 | 0.89 | −0.02 | 0.51 | −0.02 | 0.93 | −0.03 |
| -HMC | 0.61 | −0.07 | 0.86 | −0.05 | 0.48 | −0.05 | 0.91 | −0.05 |
| -HMC (+Multi-scale Convolution) | 0.64 | −0.04 | 0.87 | −0.04 | 0.50 | −0.03 | 0.93 | −0.03 |
| Action of Skoda Dataset | Precision | Recall | Macro F1-Score |
|---|---|---|---|
| null | 0.996 | 0.999 | 0.998 |
| write on notepad | 0.989 | 0.988 | 0.989 |
| open hood | 0.980 | 0.955 | 0.968 |
| close hood | 0.959 | 0.983 | 0.970 |
| check gaps on the front door | 0.989 | 0.989 | 0.989 |
| open left front door | 0.834 | 0.903 | 0.867 |
| close left front door | 0.890 | 0.809 | 0.848 |
| close both left door | 0.987 | 0.991 | 0.989 |
| check trunk gaps | 0.989 | 0.988 | 0.988 |
| open and close trunk | 0.988 | 0.991 | 0.989 |
| check steering wheel | 0.999 | 0.980 | 0.990 |
| Action of Opportunity Dataset | Precision | Recall | Macro F1-Score |
|---|---|---|---|
| Other | 0.949 | 0.964 | 0.956 |
| Open Door 1 | 0.842 | 0.800 | 0.821 |
| Open Door 2 | 0.844 | 0.750 | 0.794 |
| Close Door 1 | 0.944 | 0.739 | 0.829 |
| Close Door 2 | 0.750 | 0.938 | 0.833 |
| Open Fridge | 0.800 | 0.675 | 0.732 |
| Close Fridge | 0.733 | 0.746 | 0.740 |
| Open Dishwasher | 0.595 | 0.658 | 0.625 |
| Close Dishwasher | 0.486 | 0.586 | 0.531 |
| Open Drawer 1 | 0.294 | 0.385 | 0.333 |
| Close Drawer 1 | 0.539 | 0.467 | 0.500 |
| Open Drawer 2 | 0.889 | 0.500 | 0.640 |
| Close Drawer 2 | 0.636 | 0.700 | 0.667 |
| Open Drawer 3 | 0.606 | 0.769 | 0.678 |
| Close Drawer 3 | 0.560 | 0.667 | 0.609 |
| Clean Table | 0.909 | 0.526 | 0.667 |
| Drink from Cup | 0.762 | 0.647 | 0.700 |
| Toggle Switch | 0.857 | 0.450 | 0.590 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Q.; Xie, W.; Li, C.; Wang, Y.; Liu, Y. Human Action Recognition Based on Hierarchical Multi-Scale Adaptive Conv-Long Short-Term Memory Network. Appl. Sci. 2023, 13, 10560. https://doi.org/10.3390/app131910560
Huang Q, Xie W, Li C, Wang Y, Liu Y. Human Action Recognition Based on Hierarchical Multi-Scale Adaptive Conv-Long Short-Term Memory Network. Applied Sciences. 2023; 13(19):10560. https://doi.org/10.3390/app131910560
Chicago/Turabian StyleHuang, Qian, Weiliang Xie, Chang Li, Yanfang Wang, and Yanwei Liu. 2023. "Human Action Recognition Based on Hierarchical Multi-Scale Adaptive Conv-Long Short-Term Memory Network" Applied Sciences 13, no. 19: 10560. https://doi.org/10.3390/app131910560