1. Introduction
Currently, industrial Internet of Things (IoT) applications are continuously evolving towards deeper integration, where all elements of industrial processes are interconnected. Data from various sources, such as physical sensors, images, audio, and video, are constantly collected and accumulated [
1]. Real-time intelligent analysis and processing of process monitoring data are often required to achieve timely feedback and optimization control of production processes. The demand for real-time data collection and processing in industrial scenarios based on edge computing is rapidly growing [
2]. These data-intensive storage and computing tasks, carried out at the edge, heavily rely on computational and storage resources, and have stricter requirements for real-time execution of workflows [
3].
Typically, the analysis and processing of heterogeneous data from multiple sources in industrial processes involves various steps, including data acquisition, data correlation analysis, AI inference, and industrial equipment feedback control. These steps form a workflow with multiple sub-tasks that need to be executed collaboratively and in real-time [
4]. Moreover, due to the concurrent nature of real-time data processing tasks in industrial processes (e.g., device operation condition monitoring and fault diagnosis, product quality inspection, and optimization during production), edge computing platform are required to run multiple sub-tasks concurrently as part of the workflow. The real-time scheduling of these concurrent workflows on resource-constrained edge computing platforms, including computation and storage, poses a critical challenge for current industrial IoT edge computing [
3,
5].
The issue of concurrency in cloud computing or edge computing can be considered the same type of problem. In recent years, real-time scheduling of concurrent tasks and workflow scheduling on cloud computing or edge computing have received special attention from researchers [
3,
6,
7]. The optimization objectives in such studies mostly focus on resources, QoS, and time. The methods employed for scheduling are predominantly heuristic, including rule-based and search-based methods. A small portion of the research has utilized deep learning methods, primarily for assessing the effectiveness of solutions using neural networks, rather than having the neural networks make decisions. These heuristic methods often lack analysis of computation time in experiments. However, it can also be observed that researchers are gradually integrating the latest deep learning research into traditional methods for such problems.
The traditional methods for solving scheduling problems are primarily heuristic methods, which can be further classified into two categories. The first class are rule-based heuristic scheduling methods, which typically rely on predefined rules for scheduling without optimizing the scheduling results. The second class belongs to search-based heuristic algorithms. This method often utilizes various rules to search the solution space and find a feasible solution to the optimization problem within acceptable costs (time or space), which is close to the optimal solution. Up to now, there have been numerous metaheuristic works on cloud/edge computing scheduling [
8]. Examples of such methods include Particle Swarm Optimization (PSO) [
9,
10], Ant Colony Optimization (ACO) [
11], and Differential Evolution (DE) [
12], which have been adopted to optimize the makespan or cost (e.g., resource cost) while satisfying other QoS constraints. It is worth noting that the makespan and cost of executing a workflow on the cloud are two conflicting optimization objectives. For instance, reducing the makespan of the workflow requires more resources, which often leads to higher execution costs. As a result, many algorithms struggle to strike a balance between these two objectives. Furthermore, such methods often face challenges in meeting the real-time requirements of certain scenarios.
In recent years, with the development of artificial intelligence, Reinforcement Learning (RL) has become an active area of research in machine learning [
13,
14]. Its ability to address decision-making problems has inspired researchers to use RL to tackle optimization problems. Most research leverages Deep Reinforcement Learning (DRL) to learn solutions for problem-solving by designing evaluation metrics for the problem and enabling neural networks to continuously attempt and learn through trial. With the trained network, excellent solutions can be obtained in a short amount of time. Many studies have utilized Deep Reinforcement Learning to solve resource management problems [
15], workshop job scheduling problems [
16], and cloud-edge task allocation problems [
17]. While using Deep Reinforcement Learning methods can avoid designing highly complex heuristic rules and offer faster computation times, there are still challenges in designing the environment states and network models, as well as the need to balance different optimization objectives.
Many heuristic methods utilize search and neural 94 network techniques, but their computational efficiency falls short in real-time scheduling 95 environments.
Previous research has encountered several challenges: (1) Heuristic methods often require the design of overly complex rules, and scheduling rules need to be designed while satisfying problem constraints. When the constraints change, the scheduling rules may need to be modified accordingly. The methods of deep reinforcement learning become increasingly challenging to train as the problem constraints increase, leading to an increase in the required input features. (2) Many scheduling methods, while capable of producing excellent results, have computation times that are unacceptable for real-time environments. (3) Dealing with multi-objective optimization requires frequent adjustments to algorithm rules or neural networks to find a balanced point among multiple objectives. To address these issues, this paper adopts the Deep Reinforcement Learning (DRL) method and designs an intelligent scheduler to solve the sub-task scheduling problem on edge servers in industrial scenarios. The scheduler separates problem constraints from the problem-solving process, with the neural network solely responsible for solving the input problem without considering the constraints, which are controlled by the non-neural-network part. The scheduler optimizes two metrics: resource utilization and response time, with low computation time. The contributions of this paper are as follows:
An intelligent scheduler was designed to separate the parsing of the environment from the scheduling decisions. The workflow meta-data and current environment are used to generate masks and environment encoding, which are then fed back to the neural network. The neural network is trained using the PPO algorithm combined with the Self-Critic mechanism to learn how to schedule;
Based on the pointer network architecture, the neural network was designed using Transformer as the foundation. This neural network can efficiently process the features of sub-tasks, significantly improving the computation speed of the scheduler in real-time environments;
For multi-objective optimization problems, a parameter transfer strategy is applied to transfer parameters rapidly and efficiently across multiple sets of reward functions. This allows for the verification of how reward functions affect scheduling performance, leading to the selection of the optimal reward function.
The remaining sections of the article are as follows:
Section 2 will provide a detailed overview of solutions to similar problems and explore how previous research has applied deep reinforcement learning methods to address other challenges.
Section 3 will present a comprehensive description of the specific problems addressed in this study. In
Section 4, the proposed model, along with some state parameters and scheduling strategies, will be introduced. The training methodology for the model will be discussed in
Section 5.
Section 6 will provide some experimental details and present the experimental results. Finally,
Section 7 concludes.
3. Problem Description
This section will provide a detailed introduction to the proposed problem, including the structure of the scheduling scenario and the mathematical definition of the problem.
3.1. Edge Workflow Computing Platform Architecture
The edge workflow computing platform is primarily used to address collaborative work scenarios involving multiple services in edge environments. In an industrial environment, it is common practice to “embed” the execution flow of hardware or software into their respective code. This approach, on the one hand, leads to high coupling between individual hardware or software, and on the other hand, results in significant idle time for hardware or software. On the Edge Workflow Computing Platform, a variety of services are running, such as hardware control services, data storage services, and AI services. Compared to “embedding” process flows into these services, the interaction between these services is defined through workflows. In this scenario, the same service can simultaneously serve different workflows, significantly increasing service utilization. However, at the same time, the system’s complexity also increases, requiring the design of additional modules to control the execution of different workflows to ensure that tasks within the workflows are correctly processed by the corresponding service. For this purpose, a workflow design and execution platform has been developed to address this issue.
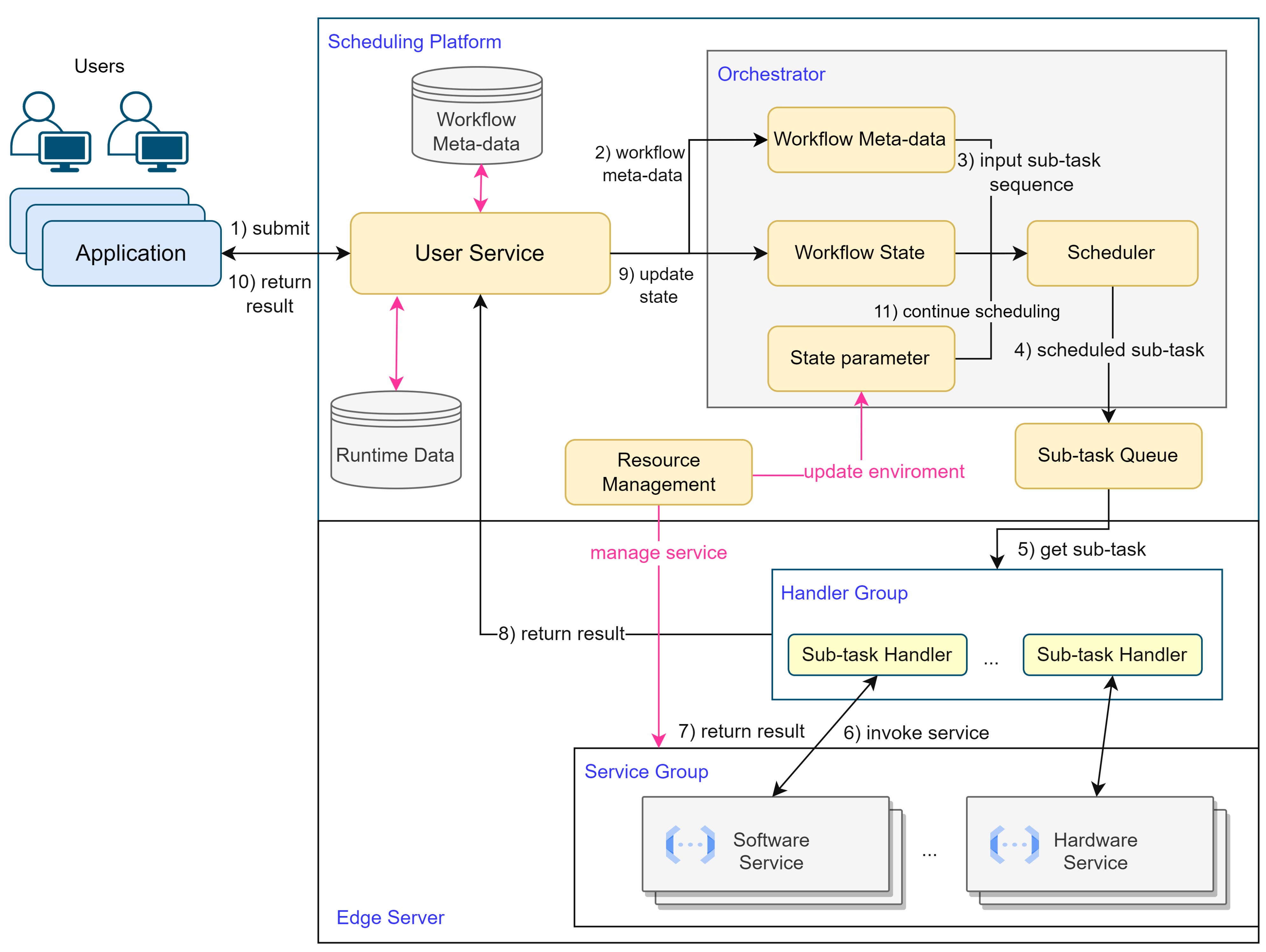
The structure of the entire system is illustrated in
Figure 1. Users design and submit workflows through the user service. The Management Service is responsible for providing real-time feedback on execution information to users and receiving workflows from users to be handed over to the Orchestrator. The Orchestrator is the designated location for running the proposed method and is responsible for deciding which tasks should be added to the task queue. The task queue holds all scheduled and pending tasks for execution. The Edge Server runs the corresponding services that handle sub-tasks. The Resource Manager is responsible for monitoring the resource usage in edge servers and providing feedback to the Orchestrator.
Services can concurrently process sub-tasks when there are sufficient computational resources available. However, adding too many sub-tasks to the task queue results in a large number of tasks that services have to handle simultaneously. This can lead to resource competition among services, causing delayed completion times for multiple sub-tasks. Therefore, the scheduling objective is to balance the execution of sub-tasks across different workflows, minimizing overall response time while avoiding resource competition, and optimizing resource utilization. The Orchestrator parses all the workflows and extracts sub-tasks as an input sequence, denoted as
, which is fed into the neural network. Based on the output results
, the sub-tasks are scheduled.
Figure 2 illustrates a case of workflow scheduling.
3.2. Entity Definitions and Constraints
In the edge workflow computing platform, there are three key entities: workflow, sub-task, and edge server. This subsection provides detailed definitions for these three entities and specifies the constraints during the scheduling process.
A workflow consists of multiple sub-tasks, where each sub-task has its predecessors and successors. The following symbols are used to describe the workflow model:
: a collection of workflows submitted by users, containing a total of N workflows. ;
: a workflow is represented as a DAG and using adjacency matrix to represent DAG;
: a sub-task in ;
: The elements in the matrix corresponding to . Specifically, if is the predecessor of , and for all other cases;
i: the index of workflow.
The workflow model is responsible for maintaining the constraints between sub-tasks, while each sub-task has its own attributes. Each sub-task can be represented as a tuple of (, , , , ).
: the Service corresponding to ;
: the execution time of ;
: the arrival time of the sub-task;
: The resource requirements of . , where d represents the number of resources. Each resource requirement lies in the range ;
: the execution priority of ;
j: the index of sub-task;
: The start time of . This parameter is obtained by scheduling result.
The parameters of the edge server constrain the scheduling of sub-tasks. The definitions of the parameters relevant to the problem are as follows:
: the resource for edge server. ;
d: the index of Resource;
t: the timestamp for edge server.
During scheduling, the parameters are subject to the following constraints:
Time constraint: , ;
Resource constraint: , when can be scheduled.
For constraint (1), the actual start time of a sub-task, denoted as , must satisfy the condition . Here, represents the set of completion times of all predecessor sub-tasks. This constraint ensures that cannot be executed before its predecessor sub-tasks have been completed.
For constraint (2), before adding a sub-task to the Sub-Task queue, it is crucial to verify that the computational resources available in the edge server can adequately meet the computational resource requirements for processing that Sub-Task.
In addition, the following constraints exist during scheduling:
There will be no relationship between sub-tasks in different workflows;
The time taken to transmit sub-tasks to the Sub-Task Queue and assemble the returned results is disregarded. The actual transmission time from the scheduling center to the edge servers can be determined through testing;
Once a Service is processing a sub-task during runtime, it cannot be preempted or suspended;
Upon completing a task, the Service can promptly release the allocated resources. Only the resources necessary for the Service to run are reserved.
3.3. Optimization Objective
In the proposed edge workflow computing platform, response time and resource consumption are the two key objectives (additional metrics can also be included), but these two objectives conflict with each other. On the one hand, the computing platform should to minimize the response time for each sub-task as much as possible. On the other hand, it should not excessively burden the system, as high loads can lead to longer execution times for all sub-tasks, rendering quick responses meaningless. Since both objectives need to be minimized, the overall scheduling objective is to find a balance point between these two objectives. As this paper employs a reinforcement learning method, the terms “reward” and “objective” are used interchangeably in the following text.
3.3.1. Average Resource Utilization
The ability of a Service to process a task is determined by its multiple resources together. Multiple resources are defined as parameters of the same type, all with values in the range [0, 1]. The total reward of the defined resources in this problem is as follows:
where
represents the usage of resource
from
to
.
represents a timestamp. d represents the total number of resource types. The proposed platform defines four resources: CPU, GPU, memory, and I/O utilization.
3.3.2. Weighted Average Response Time and Penalty
Due to the significant variation in runtime values across different sub-tasks, using makespan as the reward metric may not be ideal. In contrast, the average response time is used as a metric. The Weighted Average Response Time is calculated as follows:
where
is a function that is related to priority. This function is used to control the impact of priority on the rewards, and its parameters can be customized based on the requirements of the scenario.
The weighted average response time provides an overall measure of scheduling efficiency. However, it may not accurately reflect the appropriateness of scheduling for individual tasks. In some cases, the network may prioritize the scheduling of certain tasks while leaving others idle for extended periods.
To address this issue, a Penalty is introduced. For a timeout (e.g., k times the average response time or a user-set value) sub-task, its Penalty is defined as
. The new reward is calculated as follows:
where
represents the set of timeout sub-tasks.
6. Experimental Study
6.1. Dataset
Due to the nature of reinforcement learning, there is no requirement for annotated data, and data can be generated randomly for training purposes. Additionally, the randomly generated data can simulate various scenarios, such as scenarios with lengthy tasks or tasks that require substantial resource utilization. Within the same set of sub-tasks, the duration and resource usage are evenly generated to avoid the network being biased towards handling only short or long tasks. The execution time E for each sub-task is constrained within the range of [0.1, 5], in seconds. and it is randomly sampled. The resource usage D for each sub-task is restricted to the range of [0, 0.25]. The priority P of all sub-tasks falls within the range of [0, 4]. As a result, three sets of datasets were established, with task quantities of 20, 50, and 100, respectively, and arrival time spans of 10, 20, and 30, respectively. The arrival time of each sub-task was randomly sampled within the respective ranges. After obtaining sub-tasks, construct directed acyclic graphs based on the sub-task nodes. Select several sub-tasks with the smallest values as starting nodes for their respective workflows. Using the sub-task’s and E, randomly connect sub-task nodes to nodes within the graph, ensuring that the successor node’s is smaller than the predecessor node’s . Finally, construct adjacency matrices based on the generated directed acyclic graphs. All data are generated using the Numpy. These three sets of data correspond to different task densities. In the subsequent sections, [task quantity, arrival time span] are employed to denote these three datasets.
6.2. Experiment Parameters
The number of layers for the Attention module in the Encoder is set to N = 3. During the training process, the network is optimized using the Adam optimizer [
40] with a learning rate of
. The Exponential Baseline parameter
is set to 0.8. The significance level
for the t-test is set at 0.05.
For the Actor-Critic methods used for comparison, the networks are trained for a total of 100 epochs. Each epoch consists of 2500 batches, with a batch size of 512. However, for the [100,30] dataset, the batch size is set to 256. The network is also trained for 100 epochs by PPO method, but each epoch consists of 500 episodes. The step size (number of steps per update) for each episode is set to 512. The batch size for the mini-batch-actor is set to 64, the PPO-Epoch size is set to 5, and the batch size for the mini-batch-critic is set to 256. With this setup, the networks for different algorithms have the same number of forward passes and updates, making it easier to compare their performance.
The validation set and test set each consist of 2048 samples. The network and training algorithm are implemented using PyTorch, with PyTorch version 1.13.0 and Python version 3.10.8.
6.3. Performance of DRL Method to Network
In this section, the experimental results are analyzed. The analysis primarily examines the convergence of the network, the influence of the reward function on network performance, the performance of two scheduling strategies, and the computation time of the network.
6.3.1. Convergence Analysis
The dataset [20, 10] is used to validate the convergence of the network. The parameter combination for the reward function is (
) = (1, 0.5). The learning processes of four training methods are compared: Exponential, Critic, and Rollout baselines under the Actor-Critic method, as well as the Rollout Baseline under the PPO method. The changes in weighted reward during the training process are shown in
Figure 6.
It can be observed that among the Actor-Critic methods, the Exponential Baseline and Critic Baseline perform poorly, while the Rollout Baseline achieves the best results. All three methods converge after epoch 80. It can be observed that using an actual policy network as the Baseline yields better results compared to using the Exponential method or a Critic network for prediction. However, changes in the Baseline do not significantly affect the convergence.
When using the Actor-Critic methods, significant fluctuations are observed throughout the training process due to the lack of gradient clipping or simple value clipping. In contrast, although PPO-Rollout does not show a clear advantage over Actor-Critic Rollout in terms of final reward, training based on the PPO method achieves similar results to Actor-Critic Rollout after only 60 epochs and exhibits smaller fluctuations during training. This indicates the stability of the PPO algorithm during training.
6.3.2. The Effect of a Neighborhood-Based Parameter-Transfer Strategy
To evaluate the effectiveness of the parameter transfer strategy, a set of comparative experiments was conducted. By using the neighborhood-based parameter transfer strategy, networks for different reward weight combinations could be trained quickly. With this method, there was no longer a need to initialize the network parameters and train it for 100 epochs. Instead, parameters were transferred from a previously trained network for a neighboring sub-problem, significantly reducing the training time of the network.
Table 3 demonstrates the results of the first epoch when training with the (
) = (0.5, 1) weight combination on the [20, 10] dataset. A comparison was made between using and not using the parameter-transfer strategy. It can be observed that using the parameter-transfer strategy resulted in better performance in the first epoch.
6.3.3. Influence of Reward Function
In this part, the impact of different components of the defined reward function on the performance of the network will be analyzed.
Weight Combination Analysis
Due to the different weights of the reward function,
and
, the same
and
can result in different weighted rewards. Therefore, a direct comparison of these rewards is not possible. Instead, the comparison of
and
is performed by considering the ratio
. The comparison is conducted using the three proposed random datasets. The performance of each parameter weight combination on the same validation set is presented in
Table 4.
The result shows that when is below a certain threshold (e.g., from 0.5 to 0.02), no longer decreases significantly. In this case, the network does not prioritize scheduling orders to effectively utilize resources, leading to resource waste and causing a significant increase in . On the other hand, when is above a threshold (e.g., from 10 to 50), does not decrease significantly, and the network does not pay much attention to . As a result, the network keeps resources reserved without proper allocation, leading to ineffective scheduling.
From a practical perspective, the overall objective should be to minimize response time while not significantly increasing resource utilization. Therefore, a parameter ratio of = 2 is selected to balance both objectives. The following experiments are based on this weight combination.
Priority Function Analysis
The priority function
is simply set as a linear function (other functions can also be used), expressed as
. The effect of the coefficient
on the network is analyzed. The constant
b is fixed at 1, and the tests are conducted using the [20, 10] dataset. The experimental results are presented in
Table 5.
It was observed that as increases, exhibits larger variations. Based on the previous analysis, it is known that as the proportion of increases, the model tends to prioritize optimizing , resulting in poorer optimization of . Therefore, it can be concluded that an increase in leads to the model paying more attention to tasks with higher scheduling priorities, causing longer waiting times for sub-tasks with lower priorities and higher resource utilization. The coefficient was selected for subsequent experiments. However, in practical usage, the value of can be adjusted based on specific requirements and conditions.
Table 5.
Influence of the priority function coefficients.
Table 5.
Influence of the priority function coefficients.
| | |
|---|
| 1 | 0.413 | 0.619 |
| 0.7 | 0.410 | 0.482 |
| 0.5 | 0.410 | 0.345 |
| 0.3 | 0.404 | 0.318 |
| 0.1 | 0.394 | 0.290 |
Penalty Analysis
Concerning Penalty, sub-tasks surpassing times the average response time () are classified as timeout sub-tasks. The value of can be adjusted based on the urgency of jobs in the specific context. Here, is set to 3 (adjustable according to the actual requirements). By varying the magnitude of the Penalty, the analysis examines its impact on and the number of timeout sub-tasks.
From the results shown in
Table 6, it can be observed that setting a low value for the Penalty renders it ineffective. On the other hand, setting a high value for the Penalty significantly affects the value of
, leading to significant fluctuations in the reward during training. Additionally, if the value of the Penalty remains constant and independent of the sub-task quantity, the number of timeout tasks will inevitably increase as the task workload grows. This would have a significant impact on the value of
, making it challenging for the network to converge.
Therefore, it can be concluded that by binding the quantity of the Penalty to the input sub-task, allowing it to vary with changes in the action space, can effectively reduce the occurrence of timeout sub-tasks and mitigate the fluctuations in the value of .
Table 6.
Influence of the Penalty.
Table 6.
Influence of the Penalty.
| | Overtime Sub-Task |
|---|
| 0.285 | 5 |
| 0.290 | 3 |
| 0.314 | 2 |
| Network cannot converge | - |
6.4. The Performance of Static Scheduling
For static scheduling, the comparison is primarily made with rule-based scheduling algorithms and deep reinforcement learning-based methods. Heuristic methods were not chosen for comparison, as the deep reinforcement learning-based methods being compared have already outperformed many heuristic methods. For ease of description, the term TF-WS is used to refer to the proposed method in the following figures and tables. The methods being compared are as follows:
First Come, First Serve (FCFS): selects the sub-tasks that arrived first to be executed first;
Shortest Job First (SJF): prioritizes the execution of sub-tasks with the smallest execution time;
Highest Response Ratio Next (HRRN): considers both the waiting time and execution time of sub-tasks, and selects the task with the highest response ratio (defined as ) to be executed next;
NeuRewriter [
24]: A deep reinforcement learning method that guides local search for scheduling. It uses RL techniques to improve the search process and find better solutions;
RLPNet [
41]: A scheduler based on pointer networks and trained using RL. Although some modifications have been made to the encoder part of the network to fit our specific scenario, the overall network structure remains unchanged.
The optimization objectives are used as metrics for comparison. For clarity and understanding, in the following discussions,
will be referred to as “Resource Utilization” and
as “Response Time”.
Figure 7 and
Figure 8 present the experimental results.
For FCFS, the algorithm schedules sub-tasks based on their weighted waiting time as long as there are sufficient resources available. However, this algorithm does not take into account how resources are utilized or make optimal decisions regarding the order of long and short sub-task. As a result, it performs poorly in terms of both resource utilization and response time. For SJF, the algorithm prioritizes the execution of short sub-tasks over long tasks. This effectively reduces the waiting time for short sub-tasks. However, it may lead to long waiting times for multiple long sub-tasks, and it does not demonstrate a clear advantage in terms of response time compared to FCFS. For HRRN, the algorithm considers weighted waiting time, execution time, and task priorities. It avoids situations where a single task occupies resources for a long time, causing other tasks to wait for a significant duration. As a result, HRRN performs relatively well in terms of response time compared to FCFS and SJF.
NeuRewriter employs a method that trains a network to continuously swap sub-task nodes in order to achieve the best possible outcome. It functions as a search algorithm that can attain optimal results in terms of response time among all methods. The original reward function of NeuRewriter primarily focuses on average job slowdown, and a priority weight was introduced to incorporate task priorities. However, resource utilization was not specifically optimized in this method.
Regarding RLPNet, the original research paper considers multiple edge servers where requests are sent to the nearest server for processing, followed by scheduling the requests on the edge servers. The objective of the method is to optimize resource utilization, average waiting time, and average running time across all edge servers. In this case, the average running time was removed to make the network applicable to proposed problem.
It can be observed that all three reinforcement learning-based methods have significant advantages in terms of response time. Among them, NeuRewriter performs the best, followed by proposed method in this paper, and then RLPNet. Since all three reinforcement learning methods primarily focus on optimizing response time or solely optimizing response time, it is expected that resource consumption is higher. This is a reasonable phenomenon because idle resources should not be left unused while there are tasks that can be scheduled.
Additionally, the computation time (in milliseconds) of all methods for different sub-task quantities was analyzed. It is important to note that when testing the computation time, only a single dataset was used instead of multiple datasets. This choice was made because rule-based algorithms do not have the capability to perform parallel computation with multiple datasets, and comparing them to neural network-based methods based on a single dataset would naturally result in slower computation. The results are shown in
Table 7.
The experimental results indicate that rule-based algorithms have the shortest computation time. This is because these methods have relatively simple scheduling rules. FCFS and SJF exhibit similar computation time, as they only require simple sorting to obtain the results. On the other hand, HRRN has a longer computation time compared to FCFS and SJF due to its consideration of running time, waiting time, and priority, requiring additional computations to calculate the response ratio before making a selection.
Using reinforcement learning methods can achieve good results. Among these methods, methods that employ networks to guide local searches, such as NeuRewriter, exhibit the lowest response time. However, these methods also have relatively longer computation time. In contrast, the proposed method directly generates scheduling results, which may have poor scheduling performance time compared to NeuRewriter, but it has the advantage of shorter computation time. Compared to RLPNet, the proposed method demonstrates significant advantages in response time while only slightly increasing resource utilization. Additionally, although RLPNet also directly generates scheduling results, its use of an RNN limits parallel processing and thus leads to longer computation times.
6.5. Performance of Dynamic Scheduling
In dynamic scheduling, methods such as NeuRewriter, which utilize intelligent agents to guide local search, cannot be directly applied as they involve iterative improvements on the entire result and are not suitable for real-time environments. Therefore, no comparison is made with these methods.
Figure 9 and
Figure 10 present the experimental results. Based on the experimental results, it is observed that in the dynamic scheduling scenario, the performance of all algorithms is generally inferior to that in static scheduling. This is attributed to the reduction in candidate sub-tasks, making it challenging to achieve optimal scheduling. However, reinforcement learning-based scheduling algorithms exhibit more significant performance variations compared to other methods. It is concluded that when the algorithm lacks the ability to observe the global context, the decisions made tend to be locally optimal within the considered subset of tasks, but may not be globally optimal.
7. Conclusions and Future Work
Workflow scheduling in edge computing platforms aims to minimize resource consumption and response time for submitted workflows. With the advancements in artificial intelligence, leveraging AI techniques to address complex scheduling problems in various scenarios has become a focal point of research. In this paper, a workflow scheduling method is designed for edge workflow computing platform, where the scheduling is performed using a neural network trained with reinforcement learning, while the constraints are handled externally to the network, allowing the neural network to focus solely on scheduling the sub-tasks of the workflow without considering the constraints. Experimental results demonstrate that the proposed method exhibits good scalability. When the scheduling objective changes, only some modifications to the reword function are required to switch to the new scenario. Additionally, the computation time of the method enables its applicability in real-time environments.
However, experiments show that the proposed method is slower in computation time compared to simple rule-based scheduling algorithms. Additionally, this approach cannot be directly applied to cluster environments, as cluster environments involve considerations beyond just the resource utilization of individual machines, such as load balancing among multiple devices and other factors.
In future work, the focus will be on optimizing the aforementioned issues. Firstly, the multi-server environment will be modeled, and a two-stage scheduling algorithm will be designed. In the first stage, load balancing will be achieved based on the load and sub-task execution status of different servers, and sub-tasks will be allocated to specific machines. In the second stage, sub-task scheduling will be performed on specific servers. Secondly, in the first scheduling stage, a series of load balancing rules will be designed for the cluster environment, combining reinforcement learning with rule-based heuristic methods, enabling the neural network to self-learn scheduling strategies or select existing scheduling rules. Thirdly, more reinforcement learning algorithms will be compared and studied to improve the training results of the network.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}