
A Systematic Literature Review on Using the Encoder-Decoder Models for Image Captioning in English and Arabic Languages


Abstract
:1. Introduction
1.1. Human Captioning
1.2. Previous Surveys
1.3. Motivation and Contributions
- A systematic literature review is performed on encoder-decoder-based image captioning models from 2015 until 2023.
- We also include Arabic image captioning research in the systematic procedure.
- We discuss how the English captioning models can be adapted for image captioning to support the Arabic language.
1.4. Paper Organisation
2. Methodology
2.1. Research Questions
2.2. Exclusion Criteria
- : Only peer-reviewed articles published in English are considered. All papers written in other languages are excluded.
- : Books, notes, theses, letters, and patents are not included in this literature review.
- : Papers focusing on applying image captioning methods to languages other than English and Arabic are omitted.
2.3. Search Process
3. Methods for Image Captioning
3.1. Visual Models
- Feature Vector using Convolutional Neural Network (CNN).
- Object Detection.
3.1.1. Feature Vector Using Convolutional Neural Network (CNN)
3.1.2. Object Detection
3.2. Visual Encoding
3.2.1. Global CNN Features
3.2.2. Grid Features
3.2.3. Region-Based
3.2.4. Graph-Based Attention
3.2.5. Self-Attention Encoding
3.3. Language Models
3.3.1. Recurrent Neural Networks (RNN)
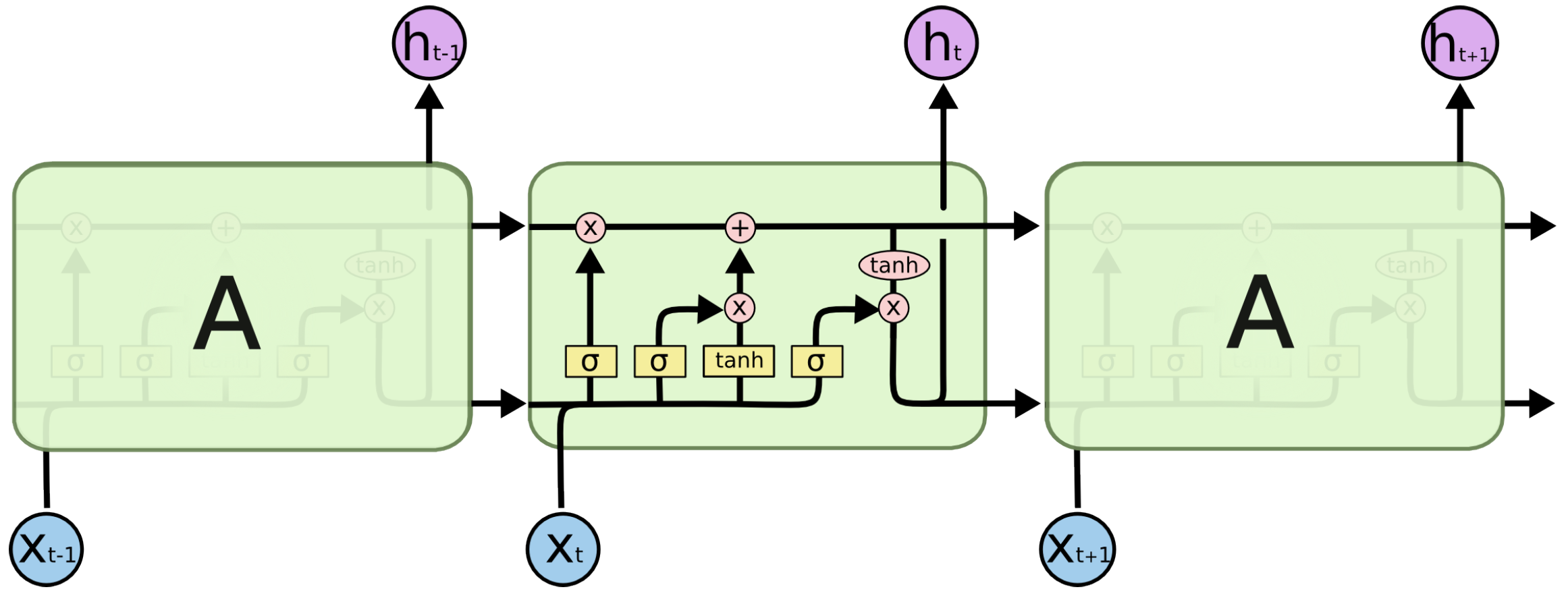
3.3.2. Long Short-Term Memory (LSTM)
3.3.3. Transformer
3.4. Loss Functions
3.4.1. Cross-Entropy (CE)
3.4.2. Self-Critical Sequence Training (SCST)
3.4.3. Kullback–Leibler Divergence (KL Divergence)
4. Available Datasets in English Image Captioning
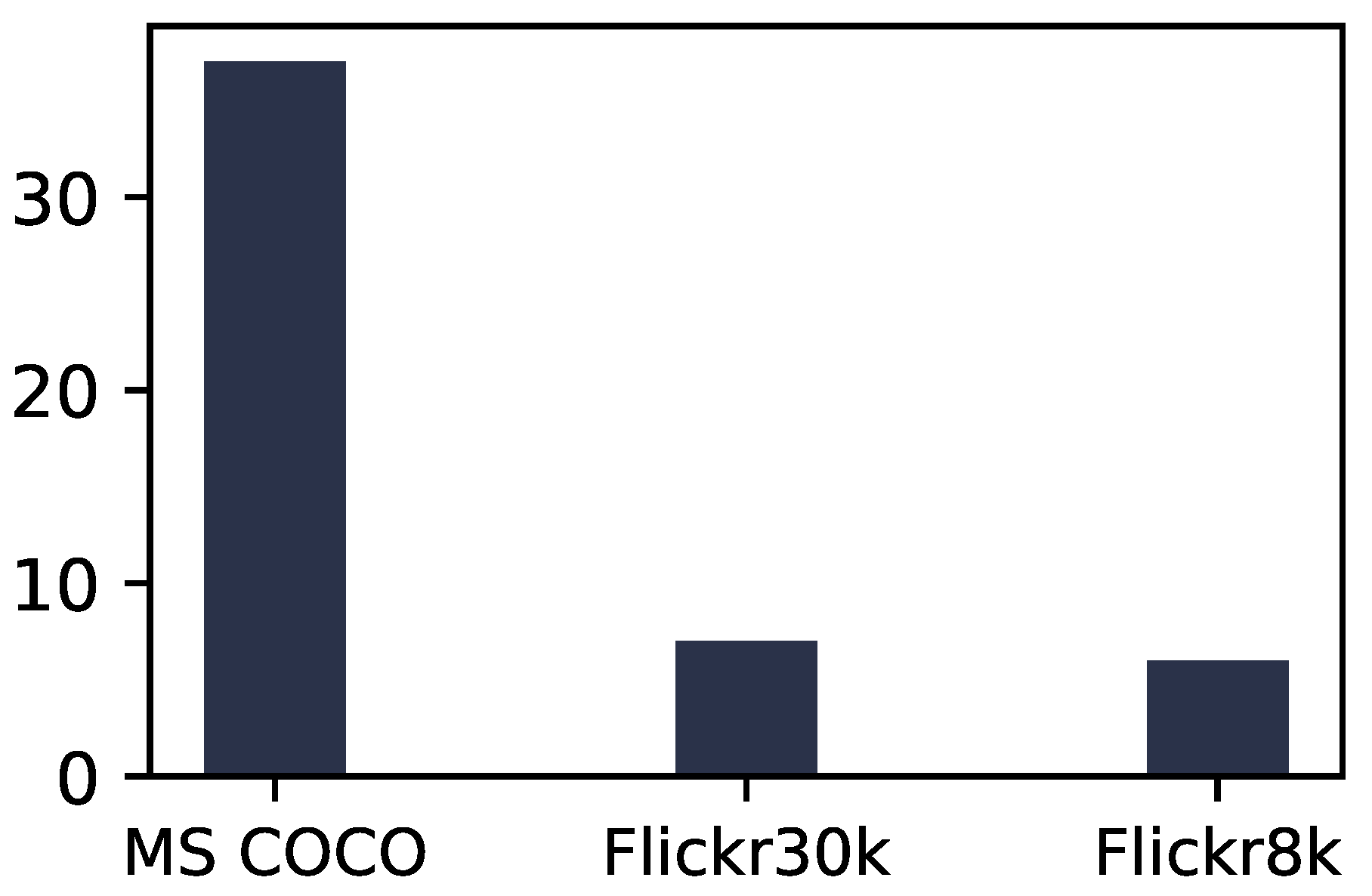
4.1. Microsoft COCO (MS COCO)
4.2. Flicker30k
4.3. Flicker8k
5. Evaluation Metrics
5.1. Bilingual Evaluation Understudy (BLEU)
5.2. METEOR
5.3. ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
5.4. CIDEr (Consensus-Based Image Description Evaluation)
5.5. SPICE (Semantic Propositional Image Caption Evaluation)
6. Arabic Image Captioning (AIC)
6.1. Model Architecture
6.2. Visual Models
6.3. Language Models
6.4. Datasets in Arabic Image Captioning
6.5. Evaluation Metrics
7. Discussion
- Size. Image captioning is a complex problem. It is a combination of two tasks requiring knowledge of handling images and text, so it requires a large amount of data for the model to generate accurate captions.
- Data quality. Having many data with low quality has a side effect on performance. The data must be of high quality so that the model can accurately detect the objects in the images.
- Diversity. To make the model generalizable to new domains, tasks, and scenarios. In particular, if they differ considerably from the training data regarding content, style, or context, the models developed using current datasets may need to perform better on unseen images or texts. For instance, a model trained on MSCOCO could not caption fashion or medical images.
- Annotation quality. Annotation of images in any dataset must be consistent, complete, accurate, and contain no spelling or grammatical errors.
- Linguistic richness. The captions for the images should be more accurate, sizable, and varied datasets that can accurately represent the diversity and richness of linguistic and visual information in the actual world.
- Complexity. To use the image captioning task for diverse applications, the dataset must contain various objects, attributes, and interactions. This means the dataset should have various objects, such as man, dog, ball, and tree; different interactions, such as standing, walking, running, and extending; and more complex interactions, such as flipping and kicking.
8. Limitations and Future Directions
- Visual aspect. The visual aspect should be developed in choosing the visual model and the appropriate encoding method so that the model can accurately extract the image objects, their properties, and the relationships between them. Since this aspect of Arabic studies has not been sufficiently developed, most studies use CNN-based features without an attention mechanism. A good feature representation should be provided by extracting the objects and their relationships, using the attention mechanism to focus on the important regions in the image, and sending them to the language model to produce better descriptions.
- Language model aspect. Focusing on the transformer model with the Arabic language, it has proven its superiority in sequence modeling, and the reason for this is due to its ability to capture the relationships between each word and another in the sequence. Additionally, using pre-trained models saves time and resources, possibly leading to better results such as BERT [111]. It has several versions, such as mBERT [112], short for Multilingual BERT, which is pre-trained in several languages, including Arabic, AraBERT [113], and ArabicBERT [114].
- Dataset aspect. Providing an open-source dataset enables people to add descriptions of images in natural and clear language to provide various descriptions of the image, as each person will give a description based on his view, resulting in a wide and varied dataset in natural language. Usually, image captioning relies on the vocabulary set from the dataset to generate the output sentence; here, we can create a learning mechanism for image captioning by asking people to name the objects not mentioned in the dataset.
- Learning mechanism aspect. With supervised methods, the focus will be on creating more diverse, realistic datasets compatible with natural language. Therefore, the focus will be on unsupervised learning and reinforcement learning in the future.
- Evaluation aspect. It is possible to use the reverse method by text-to-image models. So, an image is created from the generated caption, and then the created image is compared with the original image.
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hodosh, M.; Young, P.; Hockenmaier, J. Framing image description as a ranking task: Data, models and evaluation metrics. J. Artif. Intell. Res. 2013, 47, 853–899. [Google Scholar] [CrossRef]
- Kiros, R.; Salakhutdinov, R.; Zemel, R. Multimodal neural language models. In Proceedings of the International Conference on Machine Learning, PMLR, Beijing, China, 22–24 June 2014; pp. 595–603. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 2048–2057. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.S. Sca-cnn: Spatial and channel-wise attention in convolutional networks for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5659–5667. [Google Scholar]
- Huang, Y.; Chen, J.; Ouyang, W.; Wan, W.; Xue, Y. Image captioning with end-to-end attribute detection and subsequent attributes prediction. IEEE Trans. Image Process. 2020, 29, 4013–4026. [Google Scholar] [CrossRef]
- Zha, Z.J.; Liu, D.; Zhang, H.; Zhang, Y.; Wu, F. Context-aware visual policy network for fine-grained image captioning. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 44, 710–722. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Sharma, P.; Ding, N.; Goodman, S.; Soricut, R. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 2556–2565. [Google Scholar]
- Cornia, M.; Stefanini, M.; Baraldi, L.; Cucchiara, R. Meshed-memory transformer for image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10578–10587. [Google Scholar]
- Jindal, V. A deep learning approach for arabic caption generation using roots-words. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Jindal, V. Generating image captions in Arabic using root-word based recurrent neural networks and deep neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Al-Muzaini, H.A.; Al-Yahya, T.N.; Benhidour, H. Automatic arabic image captioning using rnn-lst m-based language model and cnn. Int. J. Adv. Comput. Sci. Appl. 2018, 9. [Google Scholar]
- Mualla, R.; Alkheir, J. Development of an Arabic Image Description System. Int. J. Comput. Sci. Trends Technol. 2018, 6, 205–213. [Google Scholar]
- ElJundi, O.; Dhaybi, M.; Mokadam, K.; Hajj, H.M.; Asmar, D.C. Resources and End-to-End Neural Network Models for Arabic Image Captioning. In Proceedings of the VISIGRAPP (5: VISAPP), Valletta, Malta, 27–29 February 2020; pp. 233–241. [Google Scholar]
- Cheikh, M.; Zrigui, M. Active learning based framework for image captioning corpus creation. In Proceedings of the International Conference on Learning and Intelligent Optimization, Athens, Greece, 24–28 May 2020; pp. 128–142. [Google Scholar]
- Afyouni, I.; Azhar, I.; Elnagar, A. AraCap: A hybrid deep learning architecture for Arabic Image Captioning. Procedia Comput. Sci. 2021, 189, 382–389. [Google Scholar] [CrossRef]
- Hejazi, H.; Shaalan, K. Deep Learning for Arabic Image Captioning: A Comparative Study of Main Factors and Preprocessing Recommendations. Int. J. Adv. Comput. Sci. Appl. 2021, 12. [Google Scholar] [CrossRef]
- Eddin Za’ter, M.; Talaftha, B. Bench-Marking And Improving Arabic Automatic Image Captioning Through The Use Of Multi-Task Learning Paradigm. arXiv 2022, arXiv:2202.05474. [Google Scholar] [CrossRef]
- Emami, J.; Nugues, P.; Elnagar, A.; Afyouni, I. Arabic Image Captioning using Pre-training of Deep Bidirectional Transformers. In Proceedings of the 15th International Conference on Natural Language Generation, Waterville, ME, USA, 18–22 July 2022; pp. 40–51. [Google Scholar]
- Lasheen, M.T.; Barakat, N.H. Arabic Image Captioning: The Effect of Text Pre-processing on the Attention Weights and the BLEU-N Scores. Int. J. Adv. Comput. Sci. Appl. 2022, 13. [Google Scholar] [CrossRef]
- Staniūtė, R.; Šešok, D. A systematic literature review on image captioning. Appl. Sci. 2019, 9, 2024. [Google Scholar] [CrossRef]
- Chohan, M.; Khan, A.; Mahar, M.S.; Hassan, S.; Ghafoor, A.; Khan, M. Image Captioning using Deep Learning: A Systematic. Image 2020, 11. [Google Scholar]
- Thorpe, S.; Fize, D.; Marlot, C. Speed of processing in the human visual system. Nature 1996, 381, 520–522. [Google Scholar] [CrossRef]
- Biederman, I. Recognition-by-components: A theory of human image understanding. Psychol. Rev. 1987, 94, 115. [Google Scholar] [CrossRef] [PubMed]
- Bracci, S.; Op de Beeck, H.P. Understanding human object vision: A picture is worth a thousand representations. Annu. Rev. Psychol. 2023, 74, 113–135. [Google Scholar] [CrossRef] [PubMed]
- Hossain, M.Z.; Sohel, F.; Shiratuddin, M.F.; Laga, H. A comprehensive survey of deep learning for image captioning. ACM Comput. Surv. (CsUR) 2019, 51, 1–36. [Google Scholar] [CrossRef]
- Stefanini, M.; Cornia, M.; Baraldi, L.; Cascianelli, S.; Fiameni, G.; Cucchiara, R. From show to tell: A survey on deep learning-based image captioning. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 539–559. [Google Scholar] [CrossRef] [PubMed]
- Xu, L.; Tang, Q.; Lv, J.; Zheng, B.; Zeng, X.; Li, W. Deep Image Captioning: A Review of Methods, Trends and Future Challenges. Neurocomputing 2023, 546, 126287. [Google Scholar] [CrossRef]
- Elhagry, A.; Kadaoui, K. A thorough review on recent deep learning methodologies for image captioning. arXiv 2021, arXiv:2107.13114. [Google Scholar]
- Luo, G.; Cheng, L.; Jing, C.; Zhao, C.; Song, G. A thorough review of models, evaluation metrics, and datasets on image captioning. IET Image Process. 2022, 16, 311–332. [Google Scholar] [CrossRef]
- Hrga, I.; Ivašić-Kos, M. Deep image captioning: An overview. In Proceedings of the 2019 42nd International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 20–24 May 2019; pp. 995–1000. [Google Scholar]
- Ghandi, T.; Pourreza, H.; Mahyar, H. Deep Learning Approaches on Image Captioning: A Review. arXiv 2022, arXiv:2201.12944. [Google Scholar] [CrossRef]
- Sharma, H.; Agrahari, M.; Singh, S.K.; Firoj, M.; Mishra, R.K. Image captioning: A comprehensive survey. In Proceedings of the 2020 International Conference on Power Electronics & IoT Applications in Renewable Energy and Its Control (PARC), Mathura, India, 28–29 February 2020; pp. 325–328. [Google Scholar]
- Attai, A.; Elnagar, A. A survey on arabic image captioning systems using deep learning models. In Proceedings of the 2020 14th International Conference on Innovations in Information Technology (IIT), Virtual Conference, 17–18 November 2020; pp. 114–119. [Google Scholar]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. Int. J. Surg. 2021, 88, 105906. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- You, Q.; Jin, H.; Wang, Z.; Fang, C.; Luo, J. Image captioning with semantic attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4651–4659. [Google Scholar]
- Deng, Z.; Jiang, Z.; Lan, R.; Huang, W.; Luo, X. Image captioning using DenseNet network and adaptive attention. Signal Process. Image Commun. 2020, 85, 115836. [Google Scholar] [CrossRef]
- Jiang, W.; Ma, L.; Jiang, Y.G.; Liu, W.; Zhang, T. Recurrent fusion network for image captioning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 499–515. [Google Scholar]
- Parameswaran, S.N.; Das, S. A Bottom-Up and Top-Down Approach for Image Captioning using Transformer. In Proceedings of the 11th Indian Conference on Computer Vision, Graphics and Image Processing, Hyderabad, India, 18–22 December 2018; pp. 1–9. [Google Scholar]
- Chu, Y.; Yue, X.; Yu, L.; Sergei, M.; Wang, Z. Automatic image captioning based on ResNet50 and LSTM with soft attention. Wirel. Commun. Mob. Comput. 2020, 2020, 8909458. [Google Scholar] [CrossRef]
- Chen, X.; Lawrence Zitnick, C. Mind’s eye: A recurrent visual representation for image caption generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2422–2431. [Google Scholar]
- Fang, H.; Gupta, S.; Iandola, F.; Srivastava, R.K.; Deng, L.; Dollár, P.; Gao, J.; He, X.; Mitchell, M.; Platt, J.C.; et al. From captions to visual concepts and back. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1473–1482. [Google Scholar]
- Jia, X.; Gavves, E.; Fernando, B.; Tuytelaars, T. Guiding the long-short term memory model for image caption generation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2407–2415. [Google Scholar]
- Li, X.; Jiang, S. Know more say less: Image captioning based on scene graphs. IEEE Trans. Multimed. 2019, 21, 2117–2130. [Google Scholar] [CrossRef]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6077–6086. [Google Scholar]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.J.; Shamma, D.A.; et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. Int. J. Comput. Vis. 2017, 123, 32–73. [Google Scholar] [CrossRef]
- Guo, L.; Liu, J.; Zhu, X.; Yao, P.; Lu, S.; Lu, H. Normalized and geometry-aware self-attention network for image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10327–10336. [Google Scholar]
- He, S.; Liao, W.; Tavakoli, H.R.; Yang, M.; Rosenhahn, B.; Pugeault, N. Image captioning through image transformer. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Pan, Y.; Yao, T.; Li, Y.; Mei, T. X-linear attention networks for image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10971–10980. [Google Scholar]
- Kumar, D.; Srivastava, V.; Popescu, D.E.; Hemanth, J.D. Dual-Modal Transformer with Enhanced Inter-and Intra-Modality Interactions for Image Captioning. Appl. Sci. 2022, 12, 6733. [Google Scholar] [CrossRef]
- Wang, Z.; Shi, S.; Zhai, Z.; Wu, Y.; Yang, R. ArCo: Attention-reinforced transformer with contrastive learning for image captioning. Image Vis. Comput. 2022, 128, 104570. [Google Scholar] [CrossRef]
- Dubey, S.; Olimov, F.; Rafique, M.A.; Kim, J.; Jeon, M. Label-attention transformer with geometrically coherent objects for image captioning. Inf. Sci. 2023, 623, 812–831. [Google Scholar] [CrossRef]
- Li, L.; Tang, S.; Deng, L.; Zhang, Y.; Tian, Q. Image caption with global-local attention. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Zhang, Y.; Shi, X.; Mi, S.; Yang, X. Image captioning with transformer and knowledge graph. Pattern Recognit. Lett. 2021, 143, 43–49. [Google Scholar] [CrossRef]
- Dong, X.; Long, C.; Xu, W.; Xiao, C. Dual graph convolutional networks with transformer and curriculum learning for image captioning. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, 20–24 October 2021; pp. 2615–2624. [Google Scholar]
- Nguyen, K.; Tripathi, S.; Du, B.; Guha, T.; Nguyen, T.Q. In defense of scene graphs for image captioning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 1407–1416. [Google Scholar]
- Yang, X.; Liu, Y.; Wang, X. Reformer: The relational transformer for image captioning. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 5398–5406. [Google Scholar]
- Herdade, S.; Kappeler, A.; Boakye, K.; Soares, J. Image captioning: Transforming objects into words. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Li, G.; Zhu, L.; Liu, P.; Yang, Y. Entangled transformer for image captioning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8928–8937. [Google Scholar]
- Song, Z.; Zhou, X.; Dong, L.; Tan, J.; Guo, L. Direction relation transformer for image captioning. In Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 15 July 2021; pp. 5056–5064. [Google Scholar]
- Ji, J.; Luo, Y.; Sun, X.; Chen, F.; Luo, G.; Wu, Y.; Gao, Y.; Ji, R. Improving image captioning by leveraging intra-and inter-layer global representation in transformer network. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 1655–1663. [Google Scholar]
- Luo, Y.; Ji, J.; Sun, X.; Cao, L.; Wu, Y.; Huang, F.; Lin, C.W.; Ji, R. Dual-level collaborative transformer for image captioning. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 2286–2293. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Understanding LSTM Networks. Available online: https://colah.github.io/posts/2015-08-Understanding-LSTMs/ (accessed on 31 May 2023).
- Lu, J.; Xiong, C.; Parikh, D.; Socher, R. Knowing when to look: Adaptive attention via a visual sentinel for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 375–383. [Google Scholar]
- Qin, Y.; Du, J.; Zhang, Y.; Lu, H. Look back and predict forward in image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, June 15 2019 to June 20 2019, Long Beach, CA, USA; 2019; pp. 8367–8375. [Google Scholar]
- Hernández, A.; Amigó, J.M. Attention mechanisms and their applications to complex systems. Entropy 2021, 23, 283. [Google Scholar] [CrossRef] [PubMed]
- Huang, L.; Wang, W.; Chen, J.; Wei, X.Y. Attention on attention for image captioning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4634–4643. [Google Scholar]
- Osolo, R.I.; Yang, Z.; Long, J. An attentive fourier-augmented image-captioning transformer. Appl. Sci. 2021, 11, 8354. [Google Scholar] [CrossRef]
- Wang, D.; Liu, B.; Zhou, Y.; Liu, M.; Liu, P.; Yao, R. Separate Syntax and Semantics: Part-of-Speech-Guided Transformer for Image Captioning. Appl. Sci. 2022, 12, 11875. [Google Scholar] [CrossRef]
- Zhou, Y.; Zhang, Y.; Hu, Z.; Wang, M. Semi-autoregressive transformer for image captioning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3139–3143. [Google Scholar]
- Rennie, S.J.; Marcheret, E.; Mroueh, Y.; Ross, J.; Goel, V. Self-critical sequence training for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7008–7024. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Karpathy, A.; Fei-Fei, L. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3128–3137. [Google Scholar]
- Plummer, B.A.; Wang, L.; Cervantes, C.M.; Caicedo, J.C.; Hockenmaier, J.; Lazebnik, S. Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 2641–2649. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the Acl Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, Michigan, 29 June 2005; pp. 65–72. [Google Scholar]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Proceedings of the Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004; pp. 74–81. [Google Scholar]
- Vedantam, R.; Lawrence Zitnick, C.; Parikh, D. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar]
- Anderson, P.; Fernando, B.; Johnson, M.; Gould, S. Spice: Semantic propositional image caption evaluation. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Part V 14. Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 382–398. [Google Scholar]
- Asian Languages—The Origin and Overview of Major Languages. Available online: https://gtelocalize.com/asian-languages-origin-and-overview/ (accessed on 18 August 2023).
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Shaalan, K.; Siddiqui, S.; Alkhatib, M.; Abdel Monem, A. Challenges in Arabic natural language processing. In Computational Linguistics, Speech and Image Processing for Arabic Language; World Scientific: Singapore, 2019; pp. 59–83. [Google Scholar]
- Shoukry, A.; Rafea, A. Preprocessing Egyptian dialect tweets for sentiment mining. In Proceedings of the Fourth Workshop on Computational Approaches to Arabic-Script-Based Languages, San Diego, CA, USA, 1 November 2012; pp. 47–56. [Google Scholar]
- PyArabic. Available online: https://pypi.org/project/PyArabic/ (accessed on 2 May 2023).
- Abdelali, A.; Darwish, K.; Durrani, N.; Mubarak, H. Farasa: A fast and furious segmenter for arabic. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations, San Diego, CA, USA, 12–17 June 2016; pp. 11–16. [Google Scholar]
- Al-Jazeera News Website. Available online: http://www.aljazeera.net (accessed on 23 May 2023).
- Collect, Clean, and Label Your Data at Scale with CrowdFlower. Available online: https://visit.figure-eight.com/People-Powered-Data-Enrichment_T (accessed on 23 May 2023).
- Ultra Edit Smart Translator. Available online: https://forums.ultraedit.com/how-to-change-the-menu-language-t11686.html (accessed on 23 May 2023).
- Google Cloud Translation API. Available online: https://googleapis.dev/python/translation/latest/index.html (accessed on 23 May 2023).
- Facebook Machine Translation. Available online: https://ai.facebook.com/tools/translate/ (accessed on 23 May 2023).
- University of Helsinki Open Translation Services. Available online: https://www.helsinki.fi/en/language-centre/translation-services-for-the-university-community (accessed on 23 May 2023).
- Arabic-COCO. Available online: https://github.com/canesee-project/Arabic-COCO (accessed on 2 May 2023).
- Yang, Y.; Cer, D.; Ahmad, A.; Guo, M.; Law, J.; Constant, N.; Abrego, G.H.; Yuan, S.; Tar, C.; Sung, Y.H.; et al. Multilingual universal sentence encoder for semantic retrieval. arXiv 2019, arXiv:1907.04307. [Google Scholar]
- Chen, C.; Mu, S.; Xiao, W.; Ye, Z.; Wu, L.; Ju, Q. Improving image captioning with conditional generative adversarial nets. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8142–8150. [Google Scholar]
- Yu, J.; Li, J.; Yu, Z.; Huang, Q. Multimodal transformer with multi-view visual representation for image captioning. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 4467–4480. [Google Scholar] [CrossRef]
- Bengio, S.; Vinyals, O.; Jaitly, N.; Shazeer, N. Scheduled sampling for sequence prediction with recurrent neural networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar]
- Ranzato, M.; Chopra, S.; Auli, M.; Zaremba, W. Sequence level training with recurrent neural networks. arXiv 2015, arXiv:1511.06732. [Google Scholar]
- Williams, R.J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Reinf. Learn. 1992, 5–32. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Multilingual BERT. Available online: https://github.com/google-research/bert/blob/master/multilingual.md (accessed on 1 June 2023).
- Antoun, W.; Baly, F.; Hajj, H. Arabert: Transformer-based model for arabic language understanding. arXiv 2020, arXiv:2003.00104. [Google Scholar]
- Safaya, A.; Abdullatif, M.; Yuret, D. Kuisail at semeval-2020 task 12: Bert-cnn for offensive speech identification in social media. In Proceedings of the Fourteenth Workshop on Semantic Evaluation, Barcelona, Spain, 12–13 December 2020; pp. 2054–2059. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Year | Visual Model | Language Model | Loss | Dataset | Metrics | Languages Coverd | Conventional/Systematic |
|---|---|---|---|---|---|---|---|---|
| [27] | 2019 | ✓ | ✓ | ✓ | ✓ | One | Conventional | |
| [22] | 2019 | ✓ | ✓ | ✓ | ✓ | One | Systematic | |
| [32] | 2019 | ✓ | ✓ | ✓ | ✓ | One | Conventional | |
| [23] | 2020 | ✓ | ✓ | ✓ | ✓ | One | Systematic | |
| [34] | 2020 | ✓ | ✓ | ✓ | ✓ | One | Conventional | |
| [35] | 2020 | ✓ | ✓ | ✓ | ✓ | One | Conventional | |
| [30] | 2021 | ✓ | ✓ | * | ✓ | ✓ | One | Conventional |
| [28] | 2022 | ✓ | ✓ | ✓ | ✓ | ✓ | One | Conventional |
| [31] | 2022 | ✓ | ✓ | * | ✓ | ✓ | One | Conventional |
| [33] | 2022 | ✓ | ✓ | * | ✓ | ✓ | One | Conventional |
| [29] | 2023 | ✓ | ✓ | ✓ | ✓ | ✓ | One | Conventional |
| ours | 2023 | ✓ | ✓ | ✓ | ✓ | ✓ | Two | Systematic |
| Question | Purpose |
|---|---|
| RQ1. How do image caption generation techniques identify the important objects in the image? | Aims to comprehend the reasons for the diversity of image models, each seeking to solve a specific problem. |
| RQ2. Comparison of deep learning techniques used for caption generation? | It aims to discover the sequence model used to generate the captions. |
| RQ3. What types of evaluation mechanisms are used for image captioning? | Finds the evaluation metrics used in image captioning to measure the performance. |
| RQ4. What types of datasets are available for image captioning? | It aims to find another factor simulating the model’s performance, i.e., the dataset’s quality used to train it. |
| RQ5. What loss functions are used to train image captioning models? | It aims to clarify and compare the loss functions used to train the image captioning modes. |
| RQ6. What are the challenges in adopting the existing methods for image captioning in Arabic? | It focuses on how authors have adopted the methods used from English to Arabic captioning. |
| Ref. | Year | CNN | Parameters |
|---|---|---|---|
| [9] | 2018 | Inception-ResNetv2 | 54 M |
| [47] | 2016 | GoogleNet | 71 M |
| [3] | 2015 | VGG19 | 138 M |
| [4] | 2015 | GoogleNet | 71 M |
| [51] | 2020 | VGG16 | 138 M |
| [51] | 2020 | ResNet50 | 21 M |
| [5] | 2017 | VGG19 | 138 M |
| [5] | 2017 | ResNet152 | 41 M |
| [48] | 2020 | DenseNet-121 | 7.9 M |
| [52] | 2015 | VGGNet | 138 M |
| [53] | 2015 | AlexNet | 62.3 M |
| [53] | 2015 | VGGNet | 138 M |
| [54] | 2015 | MatConvNet | NA |
| Dataset | Training | Validation | Testing |
|---|---|---|---|
| MSCOCO [84] | 82,783 | 40,504 | 40,775 |
| Flicker30K [86] | 29,000 | 1000 | 1000 |
| Flicker8k [1] | 6000 | 1000 | 1000 |
| Metric | Original Task | Inputs | Description | ||
|---|---|---|---|---|---|
| Pred | Refs | Image | |||
| BLEU | Translation | ✓ | ✓ | Relies on n-gram precision taking n-grams up to four. | |
| METEOR | Translation | ✓ | ✓ | The recall of matching unigrams from the predicted and reference sentences. | |
| ROUGE | Summarization | ✓ | ✓ | Taking into account the longest subsequence of tokens in both the predicted and the reference caption, and both are in the same relative order. | |
| CIDEr | Captioning | ✓ | ✓ | Evaluates how well a produced caption matches the reference captions. | |
| SPICE | Captioning | ✓ | ✓ | ✓ | Semantically captures human judgments over model-generated captions |
| Year | Study | Architecture | Attention |
|---|---|---|---|
| 2017 | [11] | Compositional | No |
| 2018 | [12] | Compositional | No |
| 2018 | [13] | Encoder-decoder | No |
| 2018 | [14] | Encoder-decoder | No |
| 2020 | [15] | Encoder-decoder | No |
| 2020 | [16] | Encoder-decoder | No |
| 2021 | [17] | Encoder-decoder | Yes |
| 2021 | [18] | Encoder-decoder | No |
| 2022 | [19] | Encoder-decoder | Yes |
| 2022 | [20] | Encoder-decoder | Yes |
| 2022 | [21] | Encoder-decoder | Yes |
| Ref. | Dataset | Access | Size | Notes |
|---|---|---|---|---|
| [11] | ImageNet dataset | Private | 10,000 images | The captions are manually written in Arabic by professional Arabic translators. |
| [11] | Al-Jazeera news website | Private | 100,000 images | A native Arabic website. |
| [12] | Flicker8k dataset | Private | 8000 images | Manually written captions in Arabic by professional Arabic translators. |
| [12] | Middle Eastern countries’ newspapers | Private | 405,000 images | Arabic |
| [13] | MSCOCO | Private | 1166 images | Human-generated captions using Crowd-Flower Crowdsourcing [99]. |
| [13] | Flicker8k | Private | 150 images | Translated by professional translator. |
| [13] | Flicker8k | Private | 2111 images | Translated by GCT, then verified by Arabic native speakers. |
| [14] | Flicker8k | Private | 2000 images | Translated using smart translator Ultra edit [100]. |
| [15] | Flicker8k | Public | 8000 images | Translated using GCT and then validated by a professional Arabic translator. |
| [16] | ArabicFlickr1K | Private | 1095 images | Framework for creating an image captioning corpus based on active learning. |
| [17] | MSCOCO | Private | 123,287 images | GCT |
| [17] | Flicker8k | Private | 8000 images | GCT |
| [19] | MS COCO | Private | 120,000 images | The translation uses a combination of GTC, Facebook Machine Translation (FMT), and translation services offered by the University of Helsinki (UH). |
| [19] | Flicker30k | Private | 32,000 images | The translation uses a combination of GTC, FMT, and UH. |
| [19] | Flicker8k | Private | 8000 images | The translation uses a combination of GTC, FMT, and UH. |
| Year | Model | Global | Grid | Region | Graph | Language Model | BLEU-4 | CIDEr |
|---|---|---|---|---|---|---|---|---|
| 2015 | DMSM [53] | ✓ | - | - | - | |||
| Mind’s Eye [52] | ✓ | RNN | 18.8 | - | ||||
| Hard-Attention [3] | ✓ | LSTM | 25.0 | - | ||||
| gLSTM [54] | ✓ | LSTM | 26.4 | 81.25 | ||||
| NIC [4] | ✓ | LSTM | 27.7 | 85.5 | ||||
| 2016 | ATT-FCN [47] | ✓ | LSTM | 30.4 | - | |||
| 2017 | SCA-CNN [5] | ✓ | LSTM | 31.1 | - | |||
| GLA [64] | ✓ | ✓ | LSTM | 31.2 | 96.4 | |||
| Adaptive Attention [76] | ✓ | LSTM | 33.2 | 108.5 | ||||
| 2018 | Sharma et al. [9] | ✓ | Transformer | - | - | |||
| Up-Down [56] | ✓ | LSTM | 36.3 | 120.1 | ||||
| Bottom-Up [50] | ✓ | ✓ | Transformer | 36.5 | 120.6 | |||
| RFNet [49] | ✓ | LSTM | 36.5 | 121.9 | ||||
| 2019 | Obj-R+Rel-A+CIDEr [55] | ✓ | LSTM | 36.3 | 120.2 | |||
| Chen et al. [106] | ✓ | LSTM | 38.3 | 123.2 | ||||
| CAVP [7] | ✓ | LSTM | 38.6 | 126.3 | ||||
| ETA [70] | ✓ | Transformer | 39.3 | 126.6 | ||||
| LBPF [77] | ✓ | LSTM | 38.3 | 127.6 | ||||
| Herdade et al. [69] | ✓ | Transformer | 38.6 | 128.3 | ||||
| AoANet [79] | ✓ | LSTM | 38.9 | 129.8 | ||||
| MT [107] | ✓ | Transformer | 40.7 | 134.1 | ||||
| 2020 | AICRL [51] | ✓ | LSTM | - | - | |||
| D-ada [48] | ✓ | LSTM | 32.6 | - | ||||
| MAD+SAP (F) [6] | ✓ | LSTM | 38.6 | 128.8 | ||||
| He et al. [59] | ✓ | Transformer | 39.5 | 130.8 | ||||
| M2 Transformer [10] | ✓ | Transformer | 39.1 | 131.2 | ||||
| X-LAN [60] | ✓ | LSTM | 39.5 | 132.0 | ||||
| NG-SAN [58] | Transformer | 39.9 | 132.1 | |||||
| X-Transformer [60] | ✓ | Transformer | 39.7 | 132.8 | ||||
| 2021 | SG2Caps [67] | ✓ | LSTM | 33.0 | 112.3 | |||
| Trans[D2GPO+MLE]+KG [65] | ✓ | Transformer | 34.39 | 112.60 | ||||
| SATIC [82] | ✓ | Transformer | 38.4 | 129.0 | ||||
| Dual-GCN+Transformer+CL [66] | ✓ | Transformer | 39.7 | 129.2 | ||||
| AFCT [80] | ✓ | Transformer | 38.7 | 130.1 | ||||
| (w/MAC) [72] | ✓ | Transformer | 39.5 | 131.6 | ||||
| DRT [71] | ✓ | Transformer | 40.4 | 133.2 | ||||
| Luo et al. [73] | ✓ | ✓ | Transformer | 39.8 | 133.8 | |||
| 2022 | Dual-Modal Transformer [61] | ✓ | ✓ | Transformer | - | - | ||
| Wang et al. [81] | ✓ | Transformer | 39.3 | 129.9 | ||||
| ReFormer [68] | ✓ | Transformer | 39.8 | 131.9 | ||||
| ArCo [62] | ✓ | Transformer | 41.4 | 139.7 | ||||
| 2023 | LATGeO [63] | ✓ | Transformer | 38.8 | 131.7 |
| Year | Ref | Test Server | |||||||
|---|---|---|---|---|---|---|---|---|---|
| B-1 | B-2 | B-3 | B-4 | M | R | C | S | ||
| 2015 | Hard-Attention [3] | 70.5 | 52.8 | 38.3 | 27.7 | 24.1 | 51.6 | 86.5 | 17.2 |
| NIC [4] | 71.3 | 54.2 | 40.7 | 30.9 | 25.4 | 53.0 | 94.3 | 18.2 | |
| Mind’s Eye [52] | - | - | - | 18.4 | 19.5 | - | 53.1 | - | |
| 2016 | ATT-FCN [47] | 73.1 | 56.5 | 42.4 | 31.6 | 25.0 | 53.5 | 94.3 | 18.2 |
| 2017 | SCA-CNN [5] | 71.2 | 54.2 | 40.4 | 30.2 | 24.4 | 52.4 | 91.2 | - |
| Adaptive Attention [76] | 74.8 | 58.4 | 44.4 | 33.6 | 26.4 | 55.0 | 104.2 | - | |
| 2018 | RFNet [49] | 80.4 | 64.9 | 50.1 | 38.0 | 28.2 | 58.2 | 122.9 | - |
| Up-Down [56] | 80.2 | 64.1 | 49.1 | 36.9 | 27.6 | 57.1 | 117.9 | 21.5 | |
| 2019 | AoANet [79] | 81.0 | 65.8 | 51.4 | 39.4 | 29.1 | 58.9 | 126.9 | - |
| Chen et al. [106] | 81.9 | 66.3 | 51.7 | 39.6 | 28.7 | 59.0 | 123.1 | - | |
| Obj-R+Rel-A [55] | 79.2 | 62.6 | 47.5 | 35.4 | 27.3 | 56.2 | 115.1 | - | |
| CAVP [7] | 80.1 | 64.7 | 50.0 | 37.9 | 28.1 | 28.1 | 121.6 | - | |
| MT [107] | 81.7 | 66.8 | 52.4 | 40.4 | 29.4 | 59.6 | 130.0 | - | |
| ETA [70] | 81.2 | 65.5 | 50.9 | 38.9 | 28.6 | 58.6 | 122.1 | - | |
| 2020 | M2 Transformer [10] | 81.6 | 66.4 | 51.8 | 39.7 | 29.4 | 59.2 | 129.3 | - |
| MAD+SAP [6] | 80.5 | 65.1 | 50.4 | 38.4 | 28.6 | 58.7 | 125.1 | - | |
| X-LAN [60] | 81.4 | 66.5 | 52.0 | 40.0 | 29.7 | 59.5 | 130.2 | - | |
| X-Transformer [60] | 81.9 | 66.9 | 52.4 | 40.3 | 29.6 | 59.5 | 131.1 | - | |
| NG-SAN [58] | 80.8 | 65.4 | 50.8 | 38.8 | 29.0 | 58.7 | 126.3 | - | |
| He et al. [59] | 81.2 | - | - | 39.6 | 29.1 | 59.2 | 127.4 | - | |
| 2021 | (w/MAC) [72] | 81.6 | 66.5 | 51.9 | 39.7 | 29.4 | 59.1 | 130.3 | - |
| DLCT [73] | 82.4 | 67.4 | 52.8 | 40.6 | 29.8 | 59.8 | 133.3 | - | |
| DRT [71] | 82.7 | 67.7 | 53.1 | 40.9 | 29.6 | 59.8 | 132.2 | - | |
| 2022 | ReFormer [68] | 82.0 | - | - | 40.1 | 29.8 | 59.9 | 129.9 | - |
| ArCo [62] | 83.4 | 68.8 | 54.3 | 42.0 | 30.6 | 60.8 | 138.5 | - | |
| 2023 | LATGeO [63] | 80.5 | 64.8 | 50.0 | 37.9 | 28.8 | 58.1 | 126.7 | - |
| Year | Ref | (Cross-Entropy Loss) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| B-1 | B-2 | B-3 | B-4 | M | R | C | S | ||
| 2015 | Hard-Attention [3] | 71.8 | 50.4 | 35.7 | 25.0 | 23.04 | - | - | - |
| Soft-Attention [3] | 70.7 | 49.2 | 34.4 | 24.3 | 23.9 | - | - | - | |
| NIC [4] | - | - | - | 27.7 | 23.7 | - | 85.5 | - | |
| Mind’s Eye [52] | - | - | - | 18.8 | 19.6 | - | - | - | |
| gLSTM [54] | 67.0 | 49.1 | 35.8 | 26.4 | 22.74 | - | 81.25 | - | |
| 2016 | ATT-FCN [47] | 0.709 | 0.537 | 0.402 | 0.304 | 0.243 | - | - | - |
| 2017 | SCA-CNN [5] | 71.9 | 54.8 | 41.1 | 31.1 | 25.0 | - | - | - |
| GLA [64] | 72.5 | 55.6 | 41.7 | 31.2 | 24.9 | 53.3 | 96.4 | ||
| Adaptive Attention [76] | 74.2 | 58.0 | 43.9 | 33.2 | 26.6 | - | 108.5 | - | |
| 2018 | RFNet [49] | 76.4 | 60.4 | 46.6 | 35.8 | 27.4 | 56.5 | 112.5 | 20.5 |
| Bottom-Up [50] | 76.2 | 60.4 | 46.8 | 36.3 | 27.9 | 56.7 | 114.6 | 20.9 | |
| Up-Down [56] | 77.2 | - | - | 36.2 | 27.0 | 56.4 | 113.5 | 20.3 | |
| 2019 | AoANet [79] | 77.4 | - | - | 37.2 | 28.4 | 57.5 | 119.8 | 21.3 |
| Obj-R+Rel-A+CIDEr. [55] | 0.767 | 0.598 | 0.453 | 0.338 | 0.262 | 0.549 | 1.103 | 0.198 | |
| MT [107] | 77.3 | - | - | 37.4 | 28.7 | 57.4 | 119.6 | - | |
| LBPF [77] | 77.8 | - | - | 37.4 | 28.1 | 57.5 | 116.4 | - | |
| ETA [70] | 77.3 | - | - | 37.1 | 28.2 | 57.1 | 117.9 | 21.4 | |
| 2020 | MAD+SAP (F) [6] | - | - | - | 37.1 | 28.1 | 57.2 | 117.3 | 21.3 |
| D-ada [48] | 73.9 | 57.0 | 42.2 | 32.6 | 27.0 | - | - | - | |
| X-LAN [60] | 78.0 | 62.3 | 48.9 | 38.2 | 28.8 | 58.0 | 122.0 | 21.9 | |
| X-Transformer [60] | 77.3 | 61.5 | 47.8 | 37.0 | 28.7 | 57.5 | 120.0 | 21.8 | |
| 2021 | Trans[D2GPO+MLE]+KG [65] | 76.24 | - | - | 34.39 | 27.71 | - | 112.60 | - |
| Dual-GCN+Transformer+CL [66] | 82.2 | 67.6 | 52.4 | 39.7 | 29.7 | 59.7 | 129.2 | - | |
| SG2Caps [67] | - | - | - | 32.6 | 26.4 | 55.0 | 106.6 | 19.8 | |
| 2022 | Wang et al. [81] | 76.6 | - | - | 36.3 | 28.2 | 56.9 | 116.1 | - |
| ReFormer [68] | 82.3 | - | - | 39.8 | 29.7 | 59.8 | 131.9 | 23.0 | |
| 2023 | LATGeO [63] | 76.5 | - | - | 36.4 | 27.8 | 56.7 | 115.8 | - |
| Year | Ref | (CIDEr Score Optimization) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| B-1 | B-2 | B-3 | B-4 | M | R | C | S | ||
| 2018 | RFNet [49] | 79.1 | 63.1 | 48.4 | 36.5 | 27.7 | 57.3 | 121.9 | 21.2 |
| Bottom-Up [50] | 78.0 | - | - | 36.5 | 28.1 | 57.2 | 120.6 | 21.6 | |
| Up-Down [56] | 79.8 | 36.3 | 27.7 | 56.9 | 120.1 | 21.4 | |||
| 2019 | AoANet [79] | 80.2 | - | - | 38.9 | 29.2 | 58.8 | 129.8 | 22.4 |
| Herdade et al. [69] | 80.5 | - | - | 38.6 | 28.7 | 58.4 | 128.3 | 22.6 | |
| Chen et al. [106] | 81.1 | 65.0 | 50.4 | 38.3 | 28.6 | 58.6 | 123.2 | 22.1 | |
| Obj-R+Rel-A+CIDEr [55] | 79.2 | 63.2 | 48.3 | 36.3 | 27.6 | - | 120.2 | - | |
| CAVP [7] | - | - | - | 38.6 | 28.3 | 58.5 | 126.3 | 21.6 | |
| MT [107] | 81.9 | - | - | 40.7 | 29.5 | 59.7 | 134.1 | - | |
| LBPF [77] | 80.5 | - | - | 38.3 | 28.5 | 58.4 | 127.6 | 22.0 | |
| ETA [70] | 81.5 | - | - | 39.3 | 28.8 | 58.9 | 126.6 | 22.7 | |
| 2020 | M2 Transformer [10] | 80.8 | - | - | 39.1 | 29.2 | 58.6 | 131.2 | 22.6 |
| MAD+SAP (F) [6] | - | - | - | 38.6 | 28.7 | 58.5 | 128.8 | 22.2 | |
| NG-SAN [58] | - | - | - | 39.9 | 29.3 | 59.2 | 132.1 | 23.3 | |
| He et al. [59] | 80.8 | - | - | 39.5 | 29.1 | 59.0 | 130.8 | 22.8 | |
| X-LAN [60] | 80.8 | 65.6 | 51.4 | 39.5 | 29.5 | 59.2 | 132.0 | 23.4 | |
| X-Transformer [60] | 80.9 | 65.8 | 51.5 | 39.7 | 29.5 | 59.1 | 132.8 | 23.4 | |
| 2021 | (w/MAC) [72] | 81.5 | - | - | 39.5 | 29.3 | 58.9 | 131.6 | 22.8 |
| DLCT [73] | 81.4 | - | - | 39.8 | 29.5 | 59.1 | 133.8 | 23.0 | |
| SATIC [82] | - | - | - | 38.4 | 28.8 | - | 129.0 | 22.7 | |
| DRT [71] | 81.7 | - | - | 40.4 | 29.5 | 59.3 | 133.2 | 23.3 | |
| SG2Caps [67] | - | - | - | 33.0 | 26.2 | 55.6 | 112.3 | 19.4 | |
| AFCT [80] | 80.5 | - | - | 38.7 | 29.2 | 58.4 | 130.1 | 22.5 | |
| 2022 | Wang et al. [81] | 80.8 | - | - | 39.3 | 29.0 | 58.9 | 129.9 | - |
| ArCo [62] | 82.8 | - | - | 41.4 | 30.4 | 60.4 | 139.7 | 24.5 | |
| 2023 | LATGeO [63] | 81.0 | - | - | 38.8 | 29.2 | 58.7 | 131.7 | 22.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alsayed, A.; Arif, M.; Qadah, T.M.; Alotaibi, S. A Systematic Literature Review on Using the Encoder-Decoder Models for Image Captioning in English and Arabic Languages. Appl. Sci. 2023, 13, 10894. https://doi.org/10.3390/app131910894
Alsayed A, Arif M, Qadah TM, Alotaibi S. A Systematic Literature Review on Using the Encoder-Decoder Models for Image Captioning in English and Arabic Languages. Applied Sciences. 2023; 13(19):10894. https://doi.org/10.3390/app131910894
Chicago/Turabian StyleAlsayed, Ashwaq, Muhammad Arif, Thamir M. Qadah, and Saud Alotaibi. 2023. "A Systematic Literature Review on Using the Encoder-Decoder Models for Image Captioning in English and Arabic Languages" Applied Sciences 13, no. 19: 10894. https://doi.org/10.3390/app131910894