Featured Application
The results of this study are applicable to systems combating misinformation and hate speech online. For example, the authorship attribution technique developed in this study is applicable to identifying people who were banned from online platforms for hate speech but started posting again under a newly registered account.
Abstract
The study investigates the task of authorship attribution on short texts in Slovenian using the BERT language model. Authorship attribution is the task of attributing a written text to its author, frequently using stylometry or computational techniques. We create five custom datasets for different numbers of included text authors and fine-tune two BERT models, SloBERTa and BERT Multilingual (mBERT), to evaluate their performance in closed-class and open-class problems with varying numbers of authors. Our models achieved an F1 score of approximately when using the dataset with the comments of the top five users by the number of written comments. Training on datasets that include comments written by an increasing number of people results in models with a gradually decreasing F1 score. Including out-of-class comments in the evaluation decreases the F1 score by approximately . The study demonstrates the feasibility of using BERT models for authorship attribution in short texts in the Slovenian language.
1. Introduction
In the field of natural language processing (NLP), authorship attribution (AA) is the task of determining the authorship of a specific piece of text. The process uses the information we can retrieve from the text itself and the information we have about the author. Stylometric or other features allow us to tell apart the texts of different authors [1]. There are two types of the AA problem: closed-class (here, we want our system to attribute some text to one person from a group of a limited size) or open-class (we want to attribute the text either to a person from a group of a limited size or predict that it does not belong to any of them) [2].
Algorithms that tackle the AA task have a wide variety of uses, ranging from plagiarism detection to forensic investigations [3]. More recently, such methods have been used to analyze the authors of online misinformation [4].
Slovenian is an Indo-European Slavic language with about million speakers, the majority of whom reside in Slovenia, a country in central Europe. In the field of natural language processing, it can be considered a less-resourced language. Various datasets and substantial language corpora have only appeared recently [5], which allow various new computational methods to be examined. Despite belonging to the Slavic language group, it features a number of peculiarities. The most notable is the use of the dual grammatical number, a very rare feature among living languages [6]. Additionally, Slovenian has at least 48 dialects, some of which can be mutually almost unintelligible, each featuring unique linguistic features. Dialects and colloquial Slovenian are used in informal speech in person or online [7], which presents a unique challenge for natural language processing tasks.
To date, most of the research on the topic of AA has been conducted using English texts. Therefore, in this study, we propose an approach to tackle this task for Slovenian texts. We collect short texts from a Slovenian news website comment section and fine-tune a number of models that differentiate between a different number of authors (5, 10, 20, 50, 100). The models are based on the monolingual SloBERTa model [8] and the multilingual BERT model [9]. We show that this technique performs well on the smaller datasets and that the F1 score gradually falls with the increasing number of users. The custom datasets we created (and the models that were fine-tuned on those datasets) are also published online (datasets (https://huggingface.co/datasets/gregorgabrovsek/RTVCommentsTop5UsersWithoutOOC) (accessed on 12 August 2023) and models (https://huggingface.co/gregorgabrovsek/SloBertAA_Top5_WithoutOOC_082023) (accessed on 25 August 2023) are available on Hugging Face) to allow further studies to compare their results.
In addition, we fine-tune the multilingual BERT model on an existing IMDb1m dataset in English to compare our approach to an existing method [10,11].
We make the following main contributions:
- We show for the first time that it is possible to perform authorship attribution on very short texts in the less-resourced Slovenian language.
- We demonstrate the difference in F1 score for models solving the authorship attribution task when they are based on multilingual and monolingual BERT models.
- We demonstrate the change in F1 score that occurs when the models are trained either for solving the open-class or closed-class authorship attribution problem.
- We present datasets of short texts in Slovenian, which further studies can utilize.
In Section 2, we first describe previous work in authorship attribution in general, some relevant recent advances in natural language processing and machine learning, and other related work. In Section 3, we introduce the data we collected, the collection and preprocessing steps that took place, and the methods we used to fine-tune the models and the rationale for choosing those base models. Section 4 displays the performance of the models in terms of the F1 score. Statistics about the training process are also shown. In Section 5, we discuss the obtained results and propose a number of potential applications of our method. Finally, in Section 6, we give an overview of the main results and contributions of our work.
2. Related Work
Researchers have long been interested in the subject of authorship attribution. With the goal of algorithmically attributing the authorship of written text to a specific person, various methods can be used. Statistical methods are already well established, but machine-learning-based methods are now becoming increasingly important [2,12]. It is possible to determine the authorship of a text algorithmically due to the difference between styles of people’s writing—they can differ in the choice and frequency of stop word usage, usage of punctuation, and sentence length, among others [13].
Recent developments in the field of language models indicated that pre-trained models can be very suitable for various natural language processing tasks, such as text classification [14]. Barlas and Stamatatos [15] were among the first to use language models to tackle the problem of authorship attribution, reaching an accuracy of around on a dataset of 21 authors. They used language models such as BERT, ELMO, and GPT-2, all of which performed rather similarly. Fabien et al. [11] proposed combining the BERT model with the use of additional stylometric features to solve the closed-class problem type on short texts, which yielded promising results. However, the authors did not evaluate the performance of their method for the open-class problem of authorship attribution.
Reisi and Mahboob Farimani [16] used deep learning (DL) methods to determine the authorship of a historical text. They used a convolutional neural network (CNN) to determine with accuracy that a certain individual was the author of the text. It is worth noting that the authors used single sentences from longer works to train the CNN, which means that training data are similar to the short texts in our problem domain.
Methods based on machine learning (ML) were also used to solve a similar problem called writer identification. Cilia et al. [17] compared DL methods against traditional ML methods for recognizing scribes from handwriting images and found that DL-based systems performed at least as well as the traditional ML methods.
Fedotova et al. [18] compared various machine learning methods to determine the authorship of Russian literary and short texts. They used classical machine learning approaches, BERT, support vector machine, genetic algorithms and more. However, despite the complexity of their methods, they reached an accuracy of for shorter social media comments. Furthermore, despite belonging to the same language group, Russian and Slovenian are mutually unintelligible. Furthermore, as described in the introduction, Slovenian has a number of rare linguistic features, so the methods may not be directly transferable.
In Slovenian, very few approaches have been published that address the problem of authorship attribution. Panker [19] tested a variety of computational approaches based on stylometry (the most effective approach was the Naive Bayes classifier), reaching an accuracy of 75%. Žejn [20] attempted to determine whether some notable Slovenian authors truly authored all of their works, but did not attempt to generalize the method or numerically quantify the results.
Limbek [21] used multivariate analysis to determine whether a literary work of unknown authorship was written by a specific Slovenian author who is rumored to have written that work. They analyzed the usage of the most common words in Slovenian with principal component analysis and discriminant analysis. They found that for the specific circumstances of their research, their methods were able to give a clear answer regarding the authorship.
However, the above-mentioned approaches focused on analyzing “long” literary works, not shorter texts.
The most notable recent progress in natural language processing (NLP) in Slovenian was the introduction of SloBERTa [8], a language model with a structure similar to RoBERTa. Up-to-date benchmarks are also being introduced, such as the Slovenian version of SuperGLUE [22]. Such developments finally allow modern methods to be tested on various NLP tasks in the less-resourced Slovenian language.
Approaches tackling the open-class type of the authorship attribution task are infrequent: a recent example was published by Venckauskas et al. [23] who used SVM as their primary method.
3. Materials and Methods
First, we constructed five datasets consisting of comments in Slovenian, each with a different number of included authors (5, 10, 20, 50, 100). When constructing a dataset that includes the comments of N most active users by the number of comments, we consider each user as a separate class for the purpose of the AA classification task. To solve the open-type variant of the AA task, we must also take into account out-of-class comments (comments not written by any of the top N users). Based on the five datasets that we have already generated, we created five more datasets that also include out-of-class comments.
Then, we fine-tuned the SloBERTa [8] and BERT Multilingual (mBERT) [9] language models using the constructed datasets. The intention of using different datasets is to compare the effect of the dataset properties on the performance of the resulting fine-tuned models.
3.1. Data Collection and Preparation
As a source of comments, we focused on the biggest news website in Slovenia, RTV SLO [24]. Commenting on the articles requires an anonymous user account, which is free to create. Statistics about race, gender, age and other such information about the users are not available. Therefore, it is hard to determine possible biases originating from the collected data.
First, we collected all comments written by users that were posted on articles written between August 2014 and December 2022. Then, we counted how many comments each user authored and sorted the users in descending order based on that amount.
For our purposes, we decided to keep only the comments of the top 200 users with the most comments written. The user with rank 1 had written comments in the observed time span, while the user with rank 200 had written 4658 (the distribution can be seen in Figure 1).
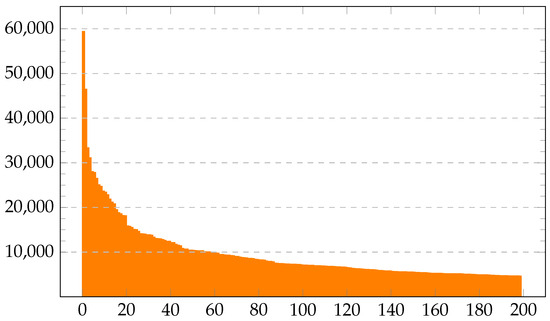
Figure 1.
The distribution of the number of comments created by 200 of the most active users on the RTV SLO platform. Users are sorted in descending order by the number of comments they posted. The x-axis denotes the ID of the user.
3.1.1. Data Preprocessing
The raw comment data obtained from RTV SLO contained a lot of unnecessary information, such as text formatting tags (for italics and bold text), hyperlinks, and metadata from other cited comments. As leaving the text formatting tags in the comments may dilute the information in the comments and therefore potentially worsen the resulting models, we decided to remove them from the texts [25,26].
Hyperlinks should also not appear in the preprocessed comments. An important reason is the fact that BERT only accepts texts/inputs consisting of 512 or fewer tokens (tokens being the output of the conversion performed by BertTokenizer). URLs may therefore waste precious space, which could be filled with the rest of the comment text—the information that actually allows us to fine-tune BERT and related language models for the task at hand. Still, the tendency of a user to include hyperlinks in their comments may be an important differentiator between them and the other users. For this reason, we decided against completely removing the hyperlinks. Instead, we simply replaced them with the string “URL”.
After cleanup, the average length of each comment was 43 words or 258 characters.
It is worth noting that the collected comments were written with various degrees of formality, as there are no restrictions on what kind of language is supposed to be used by the comment authors (though all comments have to be written in Slovenian). This means that in the dataset, one can find text written in completely correct formal Slovenian, colloquial Slovenian, and slang. Such text can include words that are otherwise rarely seen in written language, which can present a problem for natural language tasks based on existing language models.
3.1.2. Creating the Datasets
We created datasets with different amounts of comment authors to determine how changing the number of included users affects the performance. To be able to study the performance of the open-class problem type, we also randomly sampled comments written by other users.
Each data item in the dataset contained two elements: the preprocessed comment text according to Section 3.1.1 and the ID of the comment author.
We ensured that each user was represented with an equal number of texts in each dataset to prevent possible biases when fine-tuning the model. For example, when constructing the dataset of texts written by N users, and the N-th user ranked descendingly by the amount of written comments wrote C comments, we randomly sampled C comments from each of the top N users.
Each dataset was split into a training set, which included of the dataset comments, and a test set, which included the remaining .
The exact number of comments included in each dataset is displayed in Table 1. Value C is also displayed on the right side for each N.

Table 1.
The table displays the number of comments in each dataset we constructed along with the value C, which is the number of comments included for each of the N authors.
As mentioned previously, we also constructed additional datasets in order to measure the impact of including out-of-class (OOC) comments on the performance of the models. For those datasets, we repeated the same procedure as for the datasets without out-of-class comments, but we also included comments not written by the top N users. From all users who were not selected among the top N users, we randomly selected C comments. In the dataset, all OOC comments were given the same label. For example, if , the top 5 users were assigned labels from 0 to 4, and all OOC comments were assigned to label 5. All users that were not selected among the top N users were equally represented among the OOC comments.
We uploaded the resulting datasets to Hugging Face [27].
3.2. IMDb Dataset
We also compared our approach to the one proposed by Fabien et al. [11]. In order to be able to compare our results, we obtained the IMDb1m dataset created by Seroussi et al. [10], which contains reviews and posts written by a number of users of the popular website IMDb.
The dataset was not available in a processed format, so we prepared it similarly to how we did for the RTV SLO dataset. The IMDb1m dataset includes texts (posts and content reviews) written by different users. The average text length of the items in the dataset is 596 characters.
Each data item has text fields called “title” and “content”, referring to the part of the review/post that the field represents. For our purposes, we only used the “content” part for training.
For N (the number of users included in each dataset), we considered the values 5, 10, 25, 50, and 100, which were also considered by Fabien et al. [11]. The size of the datasets ranged from 9800 (N = 5) to 46,100 (N = 100) texts.
After sorting the authors by the number of reviews or posts they have written, we discovered that the person with the most written texts wrote 8151 texts or reviews, while the person with the rank 200 wrote only 251 (Figure 2).
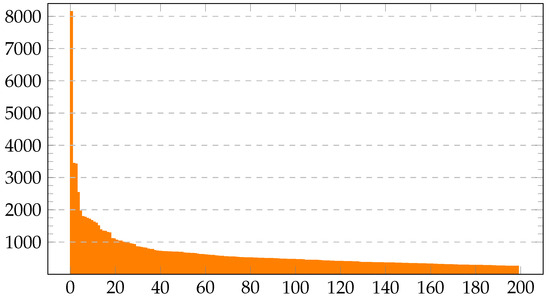
Figure 2.
The distribution of the number of comments created by 200 of the most active users from the IMDb1m dataset. Users are sorted in descending order by the number of comments they posted. The x-axis denotes the ID of the user.
In comparison with the RTV SLO comments data we collected, the IMDb text authors with the most texts written seem to have authored a lot less posts than the users on RTV SLO, though the average text length was roughly twice as long on IMDb (519 characters).
3.3. Model Training and Evaluation
To create a language model that solves the problem of AA, our approach was to fine-tune an existing language model. Fabien et al. [11] demonstrated that fine-tuning BERT is a feasible approach, so we focused on this family of language models only.
BERT is a language model based on the Transformer architecture [9,28]. Built using the attention mechanism, it uses an encoder and decoder to create a bidirectional representation of the input tokens. Due to its structure, a pre-trained model can be very useful for fine-tuning further NLP tasks without having to create custom networks from scratch.
First, we decided to use a monolingual model to achieve the best performance since monolingual models have been shown to perform better in various NLP tasks than multilingual models [29,30]. Since the texts in our dataset are written entirely in Slovenian, the base model we fine-tuned was a Slovenian monolingual model SloBERTa 2.0 [8]. SloBERTa is the first monolingual Slovenian language model. Its architecture is the same as that of RoBERTa, a model similar in design to BERT, while the tokenization model was inspired by CamemBERT [31,32].
To see the effect of using a multilingual model on our task and to compare the results, we also fine-tuned the mBERT model, which supports Slovenian and 103 other languages [9]. We fine-tuned those two models for each of the created datasets.
The training was conducted in ten epochs. The authors of the BERT’s original paper [9] recommend that the training is performed on at least five epochs for a wide variety of NLP tasks. For the AdamW optimizer, we set the weight decay parameter to and the learning rate parameter to . This value was chosen to avoid the problem of catastrophic forgetting [33]. Setting this value too high would cause the model to forget previously learned knowledge as new inputs are introduced during the training phase. Since our problem is a single-label classification problem, we chose to use the cross-entropy loss during training [34]. The full list of hyperparameters is described in Table 2. To perform the fine-tuning, we used the Hugging Face trainer [35,36].
Table 2.
Hyperparameters used during the training process.
Separately, we also fine-tuned mBERT on the IMDb1m dataset. We did not repeat the procedure with SloBERTa as the base model because all the posts in the dataset are in English.
To fine-tune the models, we used the Hugging Face Transformers Python library [35] on a system with an NVidia V100 PCIe (24 GB GDDR5 memory) graphics card, which took 2–14 h per model, depending on the size of the dataset.
After the training of each model was completed, we calculated the macro-averaged F1 scores. We also evaluated the models using out-of-class comments, which allowed us to gain insight into the potential performance drop when dealing with the open-class problem type.
To calculate the F1 score, we used the following formula:
Here, we used the following formulas for precision and recall:
means true positive, means true negative, means false positive, and means false negative.
Then, to calculate the macro-averaged F1 score, we used the following formula:
For the models fine-tuned on the IMDb1m dataset, our goal is to compare our approach to the one proposed by Fabien et al. [11]. In their work, they calculated the accuracy of each model, so we did the same for the relevant models.
To calculate the accuracy, we used the following formula:
4. Results
After the evaluation, we assembled and compared the calculated metrics. We will present them below for the RTV SLO datasets and the IMDb1m dataset separately.
4.1. RTV SLO Datasets
The evaluation of the fine-tuned models yielded F1 scores as shown in Table 3.
Table 3.
F1 scores of all calculated models based on our custom comments dataset. The results show scores for all combinations of the number of authors in the dataset and the base model used for training, as well as whether or not out-of-class (OOC) comments were considered for the evaluation.
For the AA task, the best-performing model that we trained can solve the closed-class problem of five authors with an F1 score of . For the open-class problem type, we evaluated the F1 score of the model to be , also for five authors.
The performance of the models is inversely related to the increasing number of authors included in the dataset (Figure 3). This is expected—as we increase the number of possible authors, the likelihood of two authors sharing some linguistic features also increases [15]. This is especially true in our case because comments can be exceptionally short, which further decreases the differences between various authors. At the same time, datasets with a higher number of included authors contained a smaller number of comments per user, potentially decreasing the amount of information about each author.
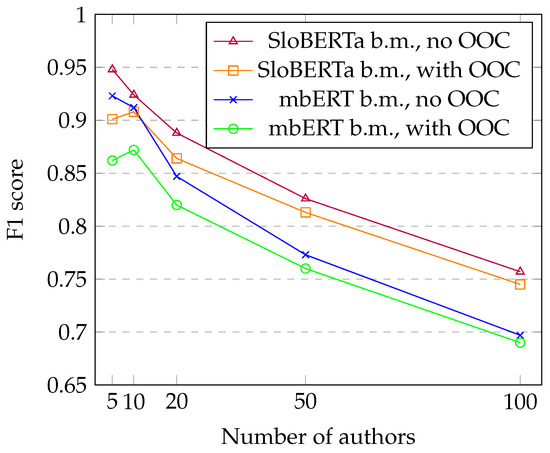
Figure 3.
The figure shows the F1 score values for the models fine-tuned on all of the different RTV SLO datasets. The different lines correspond to different base models (“b.m.”) that were used for fine-tuning. Using mBERT generates models with consistently lower F1 scores compared to models based on SloBERTa. Increasing the number of authors in the dataset gradually decreases the F1 score.
A more surprising result is the fact that the F1 score of the models that can distinguish between five and ten users is very similar where models were fine-tuned with datasets with OOC comments. The orange and green lines in Figure 3 (representing models based on SloBERTa and mBERT and fine-tuned on datasets with OOC comments) even show that there is a small increase in the F1 score of about when increasing the number of authors from 5 to 10.
Data obtained during the training of the models allow us to gain insight into the performance of the models after a certain number of epochs. Figure 4 displays the F1 score of four models. In all four cases, they were fine-tuned on datasets of the top five authors, but differ in the base model and whether or not out-of-class comments were used during training. As expected, the most significant increase in the F1 score occurs during the first 2–4 epochs. Then, in most cases, it still rises, but less noticeably.
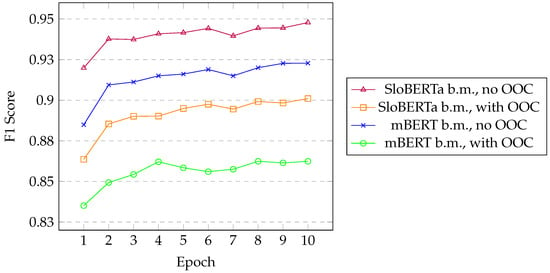
Figure 4.
The figure shows the F1 score values in each epoch for the models fine-tuned on the RTV SLO dataset for the top 5 comment authors with and without out-of-class (OOC) comments. The data are displayed for both base models (b.m.) we used for fine-tuning. The score increases noticeably in the first 2–4 epochs. In the later epochs, the increase in F1 score is lower, except for the mBERT base model with OOC comments, where it mostly stays on the same level after epoch 4.
Evaluating models with out-of-class comments also allows us to gain insight into the change in performance when solving the open-class authorship attribution task rather than the closed-class variant. Given that the open-class task is known to be the more difficult one [2], the performance we measured is in line with the expectations. Here, the decrease in the F1 score can be explained similarly to the decrease in the score when increasing the number of authors in the dataset. Out-of-class comments are essentially a collection of samples of writing authored by a wide variety of people. This means that out-of-class comments introduce into the training data a lot of text, which can contain linguistic features similar to the ones used by one or more of the N authors for which we are creating the model.
The confusion matrix of the predictions of one of the models (SloBERTa base, five authors, evaluated including out-of-class comments) seen in Table 4 can provide additional insight into the performance of models made for solving the open-class AA task. Classifying a comment as “out-of-class” resulted in the highest values for both the most false positive and false negative predictions.
Table 4.
The table shows the confusion matrix of predictions made by one of our models on a test part of the dataset. The model was fine-tuned using the SloBERTa base model and the RTV SLO dataset of the top 5 authors. The values in each cell represent the relative value of the number of predictions given the total number of comments included for each class. The color of each cell represents the relative number of predictions, with darker colors indicating higher values.
To properly understand the quality of the models, we also attempted to determine the cause of the incorrect classification. Given that the comments in the dataset can have very different lengths (in rare instances a comments can even be just a single word!), we examined the impact of the length on the F1 score. As expected, evaluating very short comments (up to about 75 characters long) causes the F1 score to drop sharply (Figure 5). On the other hand, further increasing the comment length seems to continuously improve the F1 score. Therefore, this gives an insight into both the strengths and the weaknesses of the resulting models.
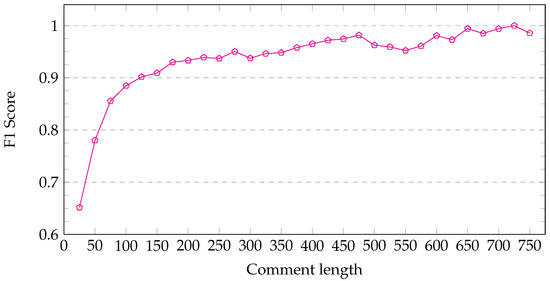
Figure 5.
The figure shows the F1 score calculated by grouping the elements by length, then calculating the F1 score for each group separately. For instance, one group included comments of length from 0 to 25 characters (shown on the figure on ), another one included comments with lengths of 25 to 50, and so on. The model was fine-tuned using the SloBERTa base model and the RTV SLO dataset of top 5 authors. As the length of the comments increases, the F1 score also gradually increases.
Given the results shown in Table 3, we can also observe that fine-tuning SloBERTa for our task gave better results than fine-tuning mBERT for the same dataset for all evaluated datasets. The most likely reason is the fact that monolingual models capture the features of a language better than multilingual models, which aligns with our expectations.
Despite the lower F1 score, fine-tuning mBERT still achieved impressive results, with the F1 score being only lower for about to . This hints at the fact that the mBERT model includes a decent representation of the Slovenian language.
4.2. IMDb1m Dataset
For the models created by fine-tuning mBERT on the IMDb1m dataset, the accuracy values of some of the resulting models were somewhat surprising. When using the dataset that included the texts from the top five authors, the resulting model reached the accuracy score of , which is comparable to measured by Fabien et al. [11] for the same dataset size.
However, increasing the number of authors in the dataset resulted in a model with much lower accuracy, the values being for and for (the full comparison of the scores can be seen in Table 5).
Table 5.
Accuracy values of our models created by fine-tuning mBERT on the IMDb1m dataset compared with values obtained by Fabien et al. [11].
Based on the confusion matrix shown in Table 6, we can attribute the sudden drop in performance for to the created model being unable to appropriately recognize one of the included authors for most of their comments in the test set. Models fine-tuned with bigger datasets did not suffer from a further drop in performance as only a single author seemed to be problematic. It is difficult to explain why Fabien et al. [11] did not come across this problem, as they did not share their processed version of the IMDb1m dataset.
Table 6.
The table shows the confusion matrix of predictions made by one of our models on a test part of the dataset. The model was fine-tuned from the mBERT base model using the IMDb dataset of the top 10 authors. The values in each cell represent the relative value of the number of predictions given the total number of comments included for each class. Label “C0” stands for “Class 0” and so on. The color of each cell represents the relative number of predictions, with darker colors indicating higher values.
5. Discussion
In this paper, we investigated the task of AA for short comments in Slovenian using the BERT language model. We created custom datasets of comments from a popular news platform and trained and evaluated two BERT models, SloBERTa and mBERT, on this dataset. Our results showed that the performance of the models was influenced by the number of authors in the dataset, with SloBERTa outperforming mBERT. Furthermore, the F1 score was lower (but still satisfactory) when taking out-of-class comments into account. Thus, we demonstrated that the AA task in Slovenian is a solvable problem for short texts both for closed-class and open-class problem types. No such work was conducted before on short texts in Slovenian, and few studies also focused on the open-class problem type.
Our results have numerous practical implications. For example, our technique could be used to quickly detect people who were banned from online platforms for hate speech but started posting again under a newly registered account. A model could be fine-tuned to recognize the text written by the banned users and alert the moderators if a newly created profile starts writing comments that could be classified as belonging to one of the banned users.
Since the F1 score decreases as the number of users included in the dataset increases, the moderators may choose to only train the models on the comments of a small number of “repeat offenders”—users who are suspected of continuously registering after being banned.
It is also important to think about the ethical considerations of implementing a system that would use our approach to authorship attribution. It is important to ensure that the users of a platform are treated fairly. In our case, this means that the used models should have a sufficiently high detection accuracy to prevent false positives. In our work, we addressed this by exploring the change in F1 score when changing the number of included authors in the dataset. Anyone implementing and using a system using our approach would therefore be informed about the potential consequences of fine-tuning a model using a dataset with too many included authors. We also addressed this ethical consideration by exploring the impact of the open-class authorship attribution task. It is important to use models that can confidently say that a text we want to know the authorship of was not authored by any of the authors we fine-tuned the model on.
Taking all of the above into account, our method for tackling the authorship attribution problem provides a solid starting point for various systems tackling the growing problem of misinformation and hate speech.
Given that our models achieved an average F1 score of approximately when using the dataset with the comments of the top five users, this indicates that fine-tuning a BERT model is a feasible technique for solving the AA problem even when dealing with very short texts. No such studies have previously been conducted on datasets containing Slovenian text, so our study provides the first baseline for further studies. The datasets we created for training and testing and the fine-tuned models are freely available on Hugging Face, allowing further studies to easily compare their results with ours.
Our study also indicates that underrepresented or less-resourced languages may still benefit from practical applications based on multilingual models if a monolingual model is not readily available.
There are also many possibilities for future studies. Based on our results, the embeddings produced by BERT could be used for unsupervised learning methods such as clustering, which has previously been shown to be effective for other NLP tasks [37]. Furthermore, studying the impact of the number of training epochs would give valuable insight into how long training has to be to achieve the best balance of speed and accuracy in practical applications.
6. Conclusions
This study successfully addressed AA for short comments in Slovenian through the use of BERT language models, specifically comparing SloBERTa and mBERT. SloBERTa showed superior performance, especially for datasets with 10 or more authors. The study proved the viability of fine-tuning BERT models for such tasks, even with brief texts. This is a pioneering effort for datasets containing Slovenian text, setting a benchmark for future research. Moreover, the datasets and models are made publicly accessible on Hugging Face, encouraging further comparative studies. The findings also suggest the potential of multilingual models for less-resourced languages. We hope that this research opens doors for future exploration, including using BERT embeddings for unsupervised learning and studying the influence of training epochs on model performance. Practical implications include the potential to detect repeat offenders of hate speech on online platforms, highlighting the broader significance of the study in addressing online misinformation and hate speech challenges, especially when less popular languages are considered.
Author Contributions
Conceptualization, G.G., P.P., Ž.E. and B.B.; methodology, G.G. and Ž.E.; software, G.G.; validation, G.G.; formal analysis, G.G.; investigation, G.G.; resources, B.B. and G.G.; data curation, G.G., B.B. and Ž.E.; writing—original draft preparation, G.G.; writing—review and editing, Ž.E., B.B. and P.P.; visualization, G.G.; supervision, Ž.E., B.B. and P.P.; project administration, Ž.E. and P.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Datasets (https://huggingface.co/datasets/gregorgabrovsek/RTVCommentsTop5UsersWithoutOOC (accessed on 12 August 2023)) and models (https://huggingface.co/gregorgabrovsek/SloBertAA_Top5_WithoutOOC_082023 (accessed on 25 August 2023) are available on Hugging Face. The code for retrieving and processing the datasets and training the models is available on https://github.com/gregorgabrovsek/Authorship-Attribution-on-Short-Texts-in-Slovenian-Language (accessed on 25 August 2023).
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AA | authorship attribution |
| b.m. | base model |
| BERT | Bidirectional Encoder Representations from Transformers |
| DL | deep learning |
| FP | false positive |
| FN | false negative |
| mBERT | multilingual BERT |
| ML | machine learning |
| NLP | natural language processing |
| OOC | out-of-class (comments) |
| TP | true positive |
| TN | true negative |
References
- Stamatatos, E. A survey of modern authorship attribution methods. J. Am. Soc. Inf. Sci. Technol. 2009, 60, 538–556. [Google Scholar] [CrossRef]
- Juola, P. Authorship attribution. Found. Trends Inf. Retr. 2006, 1, 233–334. [Google Scholar] [CrossRef]
- Stamatatos, E.; Koppel, M. Plagiarism and authorship analysis: Introduction to the special issue. Lang. Resour. Eval. 2011, 45, 1–4. [Google Scholar] [CrossRef]
- Theóphilo, A.; Pereira, L.A.; Rocha, A. A needle in a haystack? Harnessing onomatopoeia and user-specific stylometrics for authorship attribution of micro-messages. In Proceedings of the ICASSP IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 2692–2696. [Google Scholar]
- Logar, N.; Grčar, M.; Brakus, M.; Erjavec, T.; Holdt, Š.A.; Krek, S. Corpora of the Slovenian Language Gigafida, Kres, ccGigafida and ccKRES: Construction, Content, Usage; Znanstvena Založba Filozofske Fakultete: Ljubljana, Slovenia, 2020. (In Slovenian) [Google Scholar]
- Jakop, T. Use of dual in standard Slovene, colloquial Slovene and Slovene dialects. Linguistica 2012, 52, 349–362. [Google Scholar] [CrossRef]
- Greenberg, M.L. A Short Reference Grammar of Standard Slovene; SEELRC Reference Grammar Network: Durham, NC, USA, 2006. [Google Scholar]
- Ulčar, M.; Robnik-Šikonja, M. SloBERTa: Slovene monolingual large pretrained masked language model. In Proceedings of the SI-KDD within the Information Society 2021, Ljubljana, Slovenia, 4–8 October 2021; pp. 17–20. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018. [Google Scholar] [CrossRef]
- Seroussi, Y.; Zukerman, I.; Bohnert, F. Authorship attribution with topic models. Comput. Linguist. 2014, 40, 269–310. [Google Scholar] [CrossRef]
- Fabien, M.; Villatoro-Tello, E.; Motlicek, P.; Parida, S. BertAA: BERT fine-tuning for Authorship Attribution. In Proceedings of the 17th International Conference on Natural Language Processing, Patna, India, 18–21 December 2020; pp. 127–137. [Google Scholar]
- Coulthard, M.; Johnson, A.; Wright, D. An introduction to Forensic Linguistics: Language in Evidence; Routledge: New York, NY, USA, 2017. [Google Scholar]
- Lagutina, K.; Lagutina, N.; Boychuk, E.; Vorontsova, I.; Shliakhtina, E.; Belyaeva, O.; Paramonov, I.; Demidov, P. A survey on stylometric text features. In Proceedings of the 25th Conference of Open Innovations Association, Helsinki, Finland, 5–8 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 184–195. [Google Scholar]
- Howard, J.; Ruder, S. Universal language model fine-tuning for text classification. arXiv 2018. [Google Scholar] [CrossRef]
- Barlas, G.; Stamatatos, E. Cross-domain authorship attribution using pre-trained language models. In Proceedings of the 16th IFIP WG 12.5 International Conference on Artificial Intelligence Applications and Innovations, Neos Marmaras, Greece, 5–7 June 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 255–266. [Google Scholar]
- Reisi, E.; Mahboob Farimani, H. Authorship Attribution In Historical And Literary Texts By A Deep Learning Classifier. J. Appl. Intell. Syst. Inf. Sci. 2020, 1, 118–127. [Google Scholar] [CrossRef]
- Cilia, N.D.; De Stefano, C.; Fontanella, F.; Marrocco, C.; Molinara, M.; Freca, A.S.d. An Experimental Comparison between Deep Learning and Classical Machine Learning Approaches for Writer Identification in Medieval Documents. J. Imaging 2020, 6, 89. [Google Scholar] [CrossRef] [PubMed]
- Fedotova, A.; Romanov, A.; Kurtukova, A.; Shelupanov, A. Authorship attribution of social media and literary Russian-language texts using machine learning methods and feature selection. Future Internet 2021, 14, 4. [Google Scholar] [CrossRef]
- Panker, I. Automated Authorship Attribution for Slovenian Literary Texts. Bachelor’s Thesis, Faculty of Computer and Information Science, University of Ljubljana, Ljubljana, Slovenia, 2012. Available online: http://eprints.fri.uni-lj.si/1689/ (accessed on 25 August 2023). (In Slovenian).
- Žejn, A. Computational stylometric analysis of narrative prose by Janez Cigler and Christoph Von Schmid in Slovenian. Fluminensia 2020, 32, 137–158. [Google Scholar] [CrossRef]
- Limbek, M. Usage of multivariate analysis in authorship attribution: Did Janez Mencinger write the story “Poštena Bohinčeka”? Adv. Methodol. Stat. 2008, 5, 81–93. [Google Scholar] [CrossRef]
- Žagar, A.; Robnik-Šikonja, M. Slovene SuperGLUE Benchmark: Translation and Evaluation. arXiv 2022. [Google Scholar] [CrossRef]
- Venckauskas, A.; Karpavicius, A.; Damaševičius, R.; Marcinkevičius, R.; Kapočiūte-Dzikiené, J.; Napoli, C. Open class authorship attribution of lithuanian internet comments using one-class classifier. In Proceedings of the 2017 Federated Conference on Computer Science and Information Systems (FedCSIS), Prague, Czech Republic, 3–6 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 373–382. [Google Scholar]
- Javni zavod Radiotelevizija Slovenija. MMC RTV Slovenija. Available online: https://www.rtvslo.si (accessed on 10 February 2023). (In Slovenian).
- Chai, C.P. Comparison of text preprocessing methods. Nat. Lang. Eng. 2023, 29, 509–553. [Google Scholar] [CrossRef]
- Keerthi Kumar, H.; Harish, B. Classification of short text using various preprocessing techniques: An empirical evaluation. In Proceedings of the 5th ICACNI Recent Findings in Intelligent Computing Techniques, Goa, India, 1–3 June 2017; Springer: Berlin/Heidelberg, Germany, 2018; Volume 3, pp. 19–30. [Google Scholar]
- Lhoest, Q.; Villanova del Moral, A.; Jernite, Y.; Thakur, A.; von Platen, P.; Patil, S.; Chaumond, J.; Drame, M.; Plu, J.; Tunstall, L.; et al. Datasets: A Community Library for Natural Language Processing. In 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations; Association for Computational Linguistics: Punta Cana, Dominican Republic, 2021; pp. 175–184. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Ulčar, M.; Robnik-Šikonja, M. FinEst BERT and CroSloEngual BERT: Less is more in multilingual models. In Proceedings of the 23rd International Conference Text, Speech, and Dialogue, TSD 2020, Brno, Czech Republic, 8–11 September 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 104–111. [Google Scholar]
- Velankar, A.; Patil, H.; Joshi, R. Mono vs. multilingual bert for hate speech detection and text classification: A case study in marathi. In Proceedings of the IAPR Workshop on Artificial Neural Networks in Pattern Recognition, Dubai, United Arab Emirates, 24–26 November 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 121–128. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019. [Google Scholar] [CrossRef]
- Martin, L.; Muller, B.; Suá rez, P.J.O.; Dupont, Y.; Romary, L.; de la Clergerie, É.; Seddah, D.; Sagot, B. CamemBERT: A Tasty French Language Model. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Punta Cana, Dominican Republic, 2020. [Google Scholar] [CrossRef]
- Sun, C.; Qiu, X.; Xu, Y.; Huang, X. How to fine-tune bert for text classification? In Proceedings of the 18th China National Conference Chinese Computational Linguistics, Kunming, China, 18–20 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 194–206. [Google Scholar]
- Nam, J.; Kim, J.; Loza Mencía, E.; Gurevych, I.; Fürnkranz, J. Large-scale multi-label text classification—revisiting neural networks. In Proceedings of the European Conference on Machine Learning and Knowledge Discovery in Databases, Part II 14, Dublin, Ireland, 10–14 September 2018; Springer: Berlin/Heidelberg, Germany, 2014; pp. 437–452. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Conference on Empirical Methods in Natural Language Processing: System Demonstrations; Association for Computational Linguistics: Punta Cana, Dominican Republic, 2020; pp. 38–45. [Google Scholar]
- Huggingface. Trainer TrainingArguments. Available online: https://huggingface.co/docs/transformers/v4.32.0/en/main_classes/trainer#transformers.TrainingArguments (accessed on 21 August 2023).
- Reimers, N.; Schiller, B.; Beck, T.; Daxenberger, J.; Stab, C.; Gurevych, I. Classification and clustering of arguments with contextualized word embeddings. arXiv 2019. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).