1. Introduction
Although the quality of parent–child interaction (PCI) profoundly impacts a child’s cognitive and socio-emotional development, PCI can be a challenging issue [
1,
2]. Therefore, parent–child interaction therapy (PCIT), a therapeutic approach, is crafted to assist parents of children experiencing early behavior problems in enhancing their relationship with their child and effectively managing their child’s behavior [
3]. PCIT is linked to favorable outcomes for both children and families, leading to a decrease in child behavior problems and alleviation of family stress [
4,
5]. The Dyadic Parent–Child Interaction Coding System (DPICS) was developed in tandem with PCIT to monitor treatment progress. The DPICS allows for the quantification of child and parent behaviors in dyadic interaction, and DPICS has been extensively employed in the assessment of parent-child interaction quality and treatment outcomes. The DPICS is typically coded manually by a trained therapist or research staff [
6]. This can be problematic, as time spent training to code to fidelity is costly. Additionally, if large amounts of data are being collected, time spent coding can delay the research process significantly.
Artificial intelligence is an emerging trend propelled by the swift advancement of machine learning and deep learning technologies. The goal of artificial intelligence is to create intelligent agents that are capable of completing tasks in a manner similar to humans. The state-of-the-art results and superhuman achievements have been attained in many fields, including AlphaGo in the Go game, Atlas of Boston Dynamics in whole-body robots, and recent conversational dialogue agent ChatGPT. Within the realm of natural language processing, pre-trained autoregressive deep learning language models like BERT and GPT have gained growing popularity [
7,
8]. Giving computers the ability to understand human language has long been a goal of artificial intelligence in natural language processing, and pre-trained models are fed massive raw documents in the hopes of identifying relationships among words or sentences.
Labeling DPICS codes is a laborious and time-consuming task for both experts and therapists. To assist PCIT therapists, Huber et al. introduced the SpecialTime system, designed to offer parents feedback as they engage in at-home practice of PCIT skills [
9]. The developed SpecialTime system can automatically classify child-directed dialogue acts into the eight DPICS classes. Based on the SpecialTime system, we developed and implemented sentence-based classifiers to improve the DPICS code classification results and extend eight DPICS code classes to ten DPICS code classes which are Unlabeled Praise (UP), Labeled Praise (LP), Reflection (RF), Behavior Description (BD), Information Question (IQ), Descriptive Question (DQ), Indirect Commands (IC), Direct Commands (DC), Negative Talk (NTA), and Neutral Talk (TA) following the instruments of the Dyadic Parent–Child Interaction Coding System Comprehensive Manual for Research and Training, Fourth Edition (DPICS-IV) [
6]. To do that, we first collected three section datasets including 1753 instances provided by DPICS-IV manual, a total of 1952 utterances from five families, and a PCIT dataset containing 6021 utterances provided by [
9]. For comparison, we also deploy typical and popular text feature extraction methods like Word of Bag, Term Frequency–Inverse Document Frequency, and Global Vectors for Word Representation. Additionally, machine learning approaches such as logistic regression, support vector machines, and XGBoost tree were compared as downstream classifiers. In terms of pre-trained deep learning models, we utilized and fine-tuned two variants of BERT: DistilBERT and RoBERTa.
After comparing different text representations and machine learning methods, we found that RoBERTa outperformed other methods on our datasets. In particular, RoBERTa’s performance surpassed the previous best results on the public PCIT dataset.
In summary, we make the following contributions:
Introduce the state-of-the-art pre-trained language models, DistilBERT and Roberta, as deep learning approaches for automatically classifying DPICS codes, which have not been deployed in generating DPICS code classifiers before.
The results of our study demonstrate that the use of pre-trained language models, such as DistilBERT and RoBERTa, can significantly improve the accuracy of DPICS code classification compared to traditional text feature extraction methods and machine learning approaches. In particular, fine-tuning the RoBERTa model achieved the highest accuracy and outperformed other machine learning models. An advantage of pre-trained language models is that they can handle raw data without the need for extensive feature engineering. Additionally, we extended the classification to ten DPICS codes, in contrast to previous studies that used only eight classes.
Pre-trained language models offer a powerful tool for transfer learning. By using models trained on larger unrelated datasets, reasonable results can be achieved when transferring learning from one task to another. In our work, different families’ communication was evaluated and an overall accuracy of 71.0% was achieved across five families. These results demonstrate the potential of pre-trained language models for improving our understanding of communication patterns and behavior.
Boosting the performance of pre-trained language models can be achieved by training on a wider range of data, such as subject-independent data, leading to more robust and accurate sentence-based classifiers. While sentence-based classifiers have achieved acceptable performance, context-based classifiers should also be considered in future work to enhance performance. Specifically, context-based classifiers have the potential to capture the subtleties and intricacies of natural language usage.
2. Related Work
2.1. Text Feature Extraction
2.1.1. Text Representation
When working with text in machine learning models, we need to convert the text into numerical vectors so that the models can process it. Two common methods for achieving this are one-hot encoding and integer encoding. One-hot encoding generates a vector whose length matches the vocabulary size and places a “1” in the index that corresponds to the word. This approach is inefficient because most values in the resulting vector are zero. In contrast, integer encoding assigns a unique integer value to each word. While this approach creates a dense vector that can be more efficient for machine learning models, it does not capture any relationships between the words, meaning that there is no inherent similarity between the encoded values of two words. For example, the integer values assigned to “he” and “she” have no relationship to each other, despite their semantic similarity. This limitation can pose challenges for specific natural language processing tasks, especially those that require a nuanced understanding of relationships between words.
Apart from one-hot encoding and unique numbers, previous techniques such as Bag of Words (BoW) and Term Frequency–Inverse Document Frequency (TF-IDF) have been used for converting the text to numerical vectors [
10,
11]. BoW and TF-IDF are both statistical measurement methods. There are also several variants, such as n-gram models and smoothed variants of TF-IDF.
Bag of Words
The Bag of Words (BoW) technique is extensively employed as a text representation method in NLP. It involves converting a piece of text into a collection of individual words or terms, along with their respective frequencies [
10]. To create a BoW model, the text is pre-processed to remove stopwords and punctuation. Each word in the preprocessed text is then tokenized and counted, resulting in a dictionary of unique words and their respective frequencies. Ultimately, the text is represented as a vector with a length corresponding to the size of the dictionary. Despite its widespread use, BoW has several limitations. At first, BoW disregards the order and context of words in the text, potentially leading to the loss of crucial information regarding the meaning and context of individual words. Secondly, the vocabulary size can be very large, resulting in a high-dimensional vector space that can be computationally expensive and require too much memory. Thirdly, stopwords, which are common words like “the” and “a”, can dominate the frequency count and mislead the model. Finally, most documents only contain a small subset of the words in the vocabulary, resulting in sparse vectors that can make it difficult to compare documents or compute similarity measures.
Although BoW has some weaknesses, BoW is a widespread and effective technique for tasks such as text classification or sentiment analysis especially when combined with other techniques like feature selection and dimensionality reduction [
12,
13,
14,
15].
Term Frequency–Inverse Document Frequency
Term Frequency–Inverse Document Frequency (TF-IDF) is a statistical measure employed to determine the relevance of words in a text document or corpus. TF-IDF frequently serves as a weighting factor in information retrieval searches, text mining, and user modeling [
16].
TF-IDF is composed of two metrics: term frequency (TF) and inverse document frequency (IDF). The TF score measures how often words appear in a particular document. In simple words, TF counts the occurrences of words in a document. The weight of a term is directly proportional to its frequency in the document. This implies that words appearing more frequently in a document are assigned a higher weight [
11]. In contrast, IDF measures the rarity of words in the text, assigning more importance to infrequently used words in the corpus that may carry significant information. By integrating IDF, TF-IDF reduces the significance of frequently occurring terms while amplifying the importance of less common terms [
17].
TF–IDF has been one of the most widely used methods in NLP and machine learning for tasks like document classification, text summarization, sentiment classification, and spam message detection. For example, it can identify the most relevant words in a document and then apply these words as features in a classification model. A survey conducted in 2015 on text-based recommender systems found that 83% of them used TF-IDF [
18]. Furthermore, many previous studies have demonstrated the effectiveness of TF-IDF for tasks like automated text classification and sentiment analysis [
19,
20,
21,
22,
23]. However, TF-IDF has limitations. TF-IDF does not efficiently capture the semantic meaning of words in a sequence or consider the order in which terms appear. Additionally, TF-IDF can be biased towards longer documents, meaning that longer documents will generally have higher scores than shorter ones.
2.1.2. Word Embedding
Word embeddings are a form of representation learning employed in NLP, facilitating computers in comprehending the relationships between words. Humans have always excelled at understanding the relationship between words such as man and woman, cat and dog, etc. Word embedding has been developed to represent these relationships as numeric vectors in an n-dimensional space. In this context, words with similar meanings share comparable representations, implying that two related words are depicted by nearly identical vectors positioned closely in the vector space. This technique has been used effectively in various NLP tasks, such as sentiment analysis and machine translation. However, creating effective word embeddings is a significant and premier issue in NLP because the quality of word embeddings can impact the performance of downstream tasks. Moreover, ingenious word representations in a lower dimensional space can be more beneficial and train a model faster, making the creation of effective word embeddings a critical research area.
Word2Vec
Word2Vec is a popular technique for learning word embeddings using shallow neural networks, developed by [
24]. Word2Vec comprises two distinct models: Continuous Bag of Words (CBOW) and Continuous Skip-gram. The CBOW model predicts the middle word based on surrounding context words, while Skip-gram predicts the surrounding words given a target word. In CBOW, the context comprises a few words before and after the middle word [
25].
Global Vectors for Word Representation
Global Vectors for Word Representation (GloVe) is an algorithm that generates word embeddings by using matrix factorization techniques on a word-context matrix. To create the word-context matrix, a large corpus is scanned for each term, and context terms within a window defined by a window size before and after the term are counted. The resulting matrix contains co-occurrence information for each word (the rows) and its context words (the columns). To account for the decreasing importance of words as their distance from the target word increases, a weighting function is used to assign lower weights to more distant words [
26,
27].
2.1.3. Transformer
In a study by Vaswani et al. (2017), an attention-based algorithm called Transformers was introduced [
28]. Transformers are a unique type of sequence transduction model that rely solely on attention rather than recurrence. This approach allows for the consideration of more global relationships in longer input and output sequences. As a result, Transformers have recently been utilized in natural language processing to address various challenges.
DistilBERT
DistilBERT is a highly efficient and cost-effective variant of the BERT model that was developed by distilling BERT-base. With 40% fewer parameters than bert-base-uncased, DistilBERT is both small and lightweight. Additionally, it runs 60% faster than BERT while maintaining an impressive 97% performance on the GLUE language understanding benchmark [
32].
RoBERTa
Yinhan Liu et al. proposed a robust approach called the Robustly Optimized BERT-Pretraining Approach (RoBERTa) in 2019, which aims to improve upon the original BERT model for pretraining natural language processing (NLP) systems [
33]. RoBERTa shares the same architecture as BERT, but incorporates modifications to the key hyperparameters and minor embedding tweaks to increase robustness. Unlike BERT, RoBERTa does not use the next-sentence pretraining objective, and instead trains the model with much larger mini-batches and learning rates. Additionally, RoBERTa is trained using full sentences, dynamic masking, and a larger byte-level byte-pair encoding (BPE) technique. RoBERTa has been widely adopted in downstream NLP tasks and has achieved outstanding results compared to other models [
34,
35,
36].
2.2. Text Classification
Text classification is also referred to as text tagging or text categorization. The aim is to categorize and classify text into organized groups. Text classifiers can automatically analyze provided text and assign a set of pre-defined tags or categories based on its content.
While human experts are still considered the most reliable method for text classification, manual classification can be a complex, tedious, and costly task. With the advancement of NLP, text classification has become increasingly important, particularly in areas such as sentiment analysis, topic detection, and language detection. Various machine learning and deep learning methods have been employed for sentiment analysis, with Twitter being a popular data source [
37,
38,
39,
40]. Supervised methods, including decision trees, random forests, logistic regression, support vector machines (SVMs), and naive Bayes, have been used to train classifiers [
41,
42]. However, supervised approaches require labeled data, which can be expensive. To address this, unsupervised learning methods, such as that proposed by Pandarachalil et al., have been suggested [
43]. Additionally, Qaisar and Saeed Mian utilized a long short-term memory (LSTM) classifier for sentiment analysis of movie reviews [
44]. Similar to our task, a sentence is assigned to a label.
2.3. Dyadic Parent–Child Interaction Coding System and Parent–Child Interaction Therapy
The Dyadic Parent–Child Interaction Coding System, fourth edition (DPICS-IV), is a structured behavioral observation tool that assesses essential parent and child behaviors in standardized situations. DPICS-IV has proven to be a valuable adjunct to PCIT and has been used extensively to evaluate other parenting interventions and research objectives as well [
6]. Over the years, DPICS has been utilized in various studies addressing a wide range of clinical and research questions. Nelson et al. highlight the development of DPICS and discuss its current usage as a treatment process or outcome variable. The authors also provide a summary of the ways in which DPICS has been adapted and describe the process by which it is designed to undergo adaptation [
45].
The DPICS-IV scoring system is based on the frequency counts of ten main categories, Neutral Talk, Labeled Praise, Unlabeled Praise, Behavior Description, Reflection, Information Question, Descriptive Question, Direct Commands, Indirect Commands, and Negative Talk. However, in previous work, eight categories were commonly used, where Information Question and Descriptive Question were combined into a single category called Question, and Indirect Commands and Direct Commands were combined as Commands [
9,
46,
47]. Both Cañas et al. and Huber et al. have suggested that not all DPICS codes are equally important for therapy outcomes and have placed more emphasis on Negative Talk. In addition, Cañas et al. found that the DPICS Negative Talk factor demonstrated a high discriminant capacity (AUC = 0.90) between samples, and a cut-off score of 8 allowed the classification of mother–child dyads with 82% sensitivity and 89% specificity [
46].
The process of labeling DPICS codes manually for each sentence in a conversation is a time-consuming and labor-intensive task that requires trained experts. Confirmatory factor analysis is then used to verify the factor structure of the observed variables [
48]. However, Huber et al. have developed SpecialTime, an automated system that can classify transcript segments into one of eight DPICS classes. The system uses a linear support vector machine trained on text feature representations obtained using TF-IDF and part-of-speech tags. The system achieves an overall accuracy of 78%, as evaluated by the authors using an expert-labeled corpus [
9].
PCIT helps parents improve interaction quality with children with behavior problems. The therapy instructs parents to employ effective dialogue during interactions with their children [
49].
3. Methodology
The proposed approach contains the three components given below:
Feature extraction phase: This phase aims to convert utterances into numerical vector inputs for the next phase. We deploy various typical algorithms to generate different vectors.
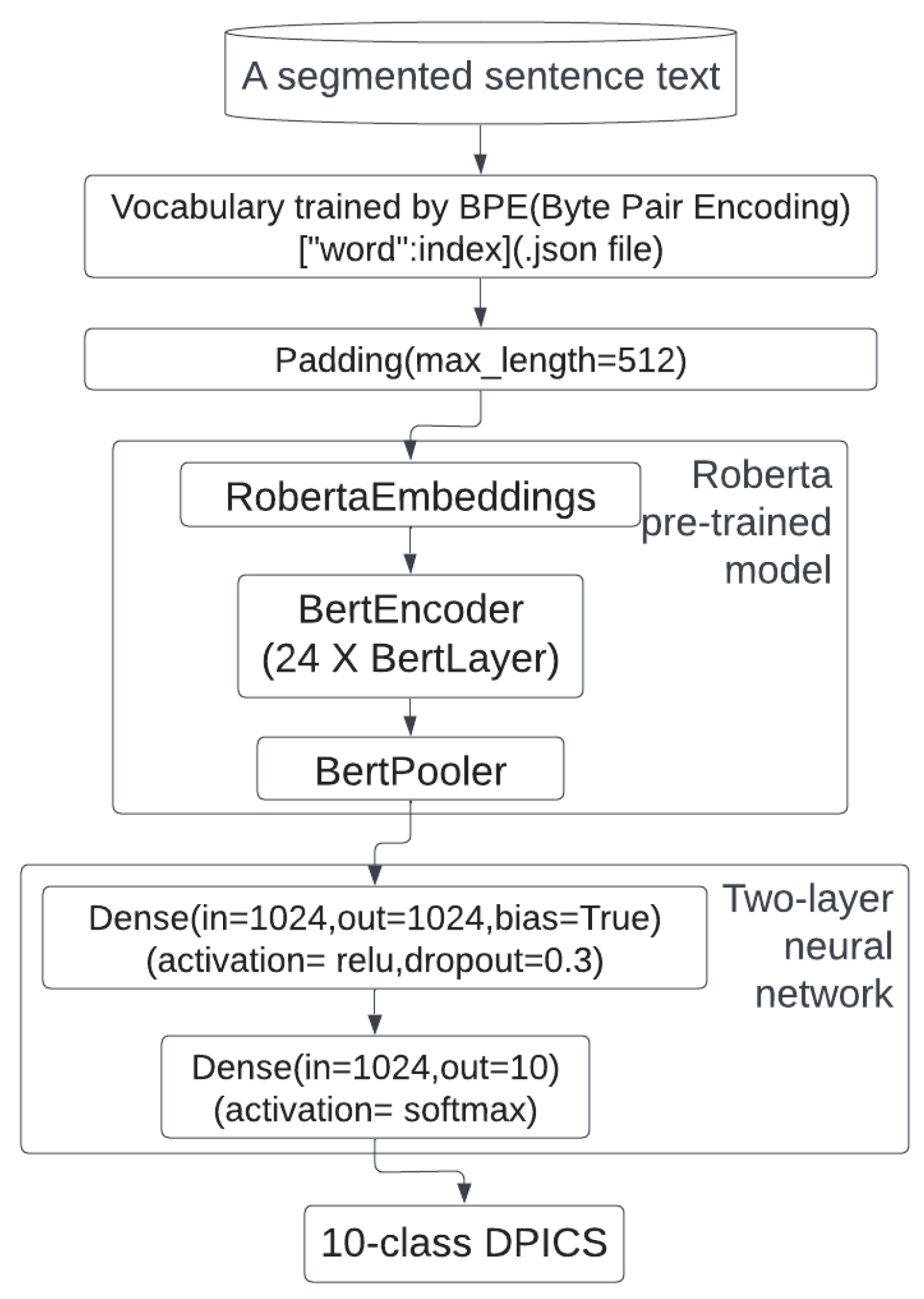
Training and fine-tuning: The generated vectors from the feature extraction phase are then used as input for machine learning algorithms to train the classifiers. In certain instances, for vectors from pre-trained models, both algorithm structures (DistillBERT and RoBERTa) are fine-tuned and then trained on the training set. We fine-tune the resulting network and append the pre-trained model using two dense layers of neural networks to do the pre-classification. Then, the results are produced either from concatenated machine learning methods or directly classified.
Automatic DPICS classification: After the classifiers are developed and trained, they can be deployed to test expert-annotated data to compare results. In this stage, parent utterances from real-life parent–child interactions are tested using the classifiers to determine which DPICS class the sentences belong to. The DPICS classification results can then be provided to parent–child interaction therapists to assist in improving the quality of parent–child interaction. It is important to note that the labels used in this work are based on DPICS-IV [
6].
To determine the most effective methods, we developed classifiers using seven widely used methods, including Bow, TF-IDF, Word2Vec, Glove, DistilBert, and RoBERTa. We then evaluated their effectiveness using classical machine learning methods such as logistic regression, support vector machines (SVMs), and XGBoosting, and compared our results to those defined by experts. Our fine-tuned RoBERTa model structure is presented in
Figure 1. To summarize, the present study includes the following three main points:
4. Experiments
4.1. Dataset
Our dataset consists of three sections. The first section includes 1753 instances of Parent Verbalizations, which were obtained from the DPICS-IV [
6]. Experts provided guided examples and rules to help human coders distinguish labels for the 10 DPICS classes in Parent Verbalizations, including Unlabeled Praise (UP), Labeled Praise (LP), Reflection (RF), Behavior Description (BD), Information Question (IQ), Descriptive Question (DQ), Indirect Commands (IC), Direct Commands (DC), Negative Talk (NTA), and Neutral Talk (TA). The data from the DPICS-IV manual was utilized directly without any processing as it is accurate and clear.
In the second section, we recorded five families engaged in daily conversations, with each family providing at least 30 min of audio recordings. These recordings were transcribed into text and labeled by trained research assistants using the 10-class DPICS coding system for Parent Verbalizations. Potential biases may arise as trained research assistants manually correct transcriptions. A local IRB committee approved the recruiting and consenting procedure.
The third section data are provided by [
9]. Bernd Huber et al. created an expert-annotated 6021 utterance sample dataset for parent–child interaction therapy. But in this PCIT dataset, the utterances are classified into eight classes so that Information Question (IQ) and Descriptive Question (DQ) are combined into Question (QU), and Indirect Commands (IC) and Direct Commands (DC) are put together as Commands (CMD).
Some DPICS instances are presented in
Table 1, and a summary of our dataset showing classes and total numbers is given in
Table 2.
4.2. Evaluation Metric
Our dataset is imbalanced, as shown in
Table 2. However, accuracy is not an appropriate performance measure for imbalanced classification problems, as models that always predict the majority class will achieve high accuracy scores even if they fail to identify samples from the minority class. For example, if a dataset contains 95% samples from the majority class and 5% samples from the minority class, a model that always predicts the majority class will achieve an accuracy score of 95%, even if it fails to correctly identify any samples from the minority class.
To evaluate the performance of our classifiers, we used precision, recall, and F-Measure metrics. Precision quantifies the number of positive class predictions that actually belong to the positive class, while recall quantifies the number of positive class predictions made out of all positive examples in the dataset. F-Measure provides a way to balance the tradeoff between precision and recall by combining both metrics into a single score. These metrics are useful for evaluating the performance of classifiers in scenarios where one class is more important than the other.
In our multi-class classification problem, we calculated both micro-average and macro-average precision, recall, and F-Measure scores. Micro-average metrics give equal weight to each example in the dataset, while macro-average metrics give equal weight to each class in the dataset. The macro-average precision and recall scores are calculated as the arithmetic mean of individual classes’ precision and recall scores, while the macro-average F1-score is calculated as the arithmetic mean of individual classes’ F1-score.
Table 3 gives formulas of all metrics used in our experimental tests where:
We consider the 10 or 8 classes equally important, while some research experts suggested that not all DPICS codes are equally influential for therapy outcomes. Five-fold cross-validation is used for the calculation of average accuracy. Torch and scikit-learn python libraries are used for training and evaluation. We fine-tuned RoBERTa models for 500 epochs with a learning rate of on an NVIDIA GeForce RTX 2080 Ti, which took more than ten hours.
5. Results
5.1. Text Representation vs. Word Embedding vs. Transformers
In this section, we used two expert-labeled datasets, DIPCS-IV and PCIT. Using two different datasets for evaluation can increase the robustness of the results by demonstrating the efficiency and accuracy of the classification across different datasets. This approach helps ensure that the results are not just specific to one particular dataset. To evaluate model performance, we employed five-fold cross-validation, using four folds for training and one fold for testing. Additionally, grid search in hyperparameter spaces is utilized to identify parameter combinations that maximize performance on the validation fold.
5.1.1. Performance on DPICS Manual
The performance results are presented in
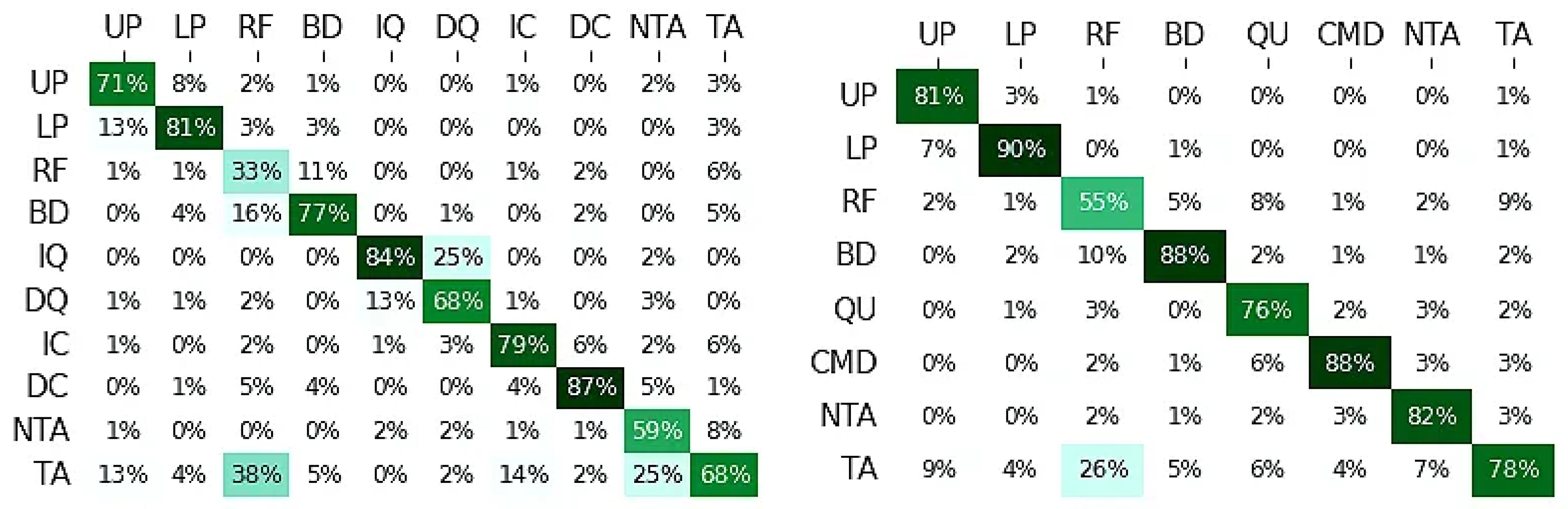
Table 4, showing the average ± standard deviation for five-fold cross-validation. The classifier developed by RoBERTa achieves the best results of 72.3% accuracy (72.3% macro-precision, 70.5% macro-recall, and 69.6% macro-F-score). The confusion matrix is presented in
Figure 2a.
5.1.2. Performance on PCIT
Using the same method as in the DPICS Manual, we evaluated the performance of the PCIT dataset.
Table 5 demonstrated that fine-tuned DistilBERT and RoBERTa models both achieved better performance compared to other methods, with RoBERTa surpassing the previous best results of 78.3% accuracy (79% precision, 77% recall) averaged over the eight DPICS classes [
9]. The previous best results were attained by Huber et al. using TF-IDF and SVM with additional feature engineering such as part-of-speech tagging. However, RoBERTa achieved an overall accuracy of 79.8% (80.4% macro-precision, 79.7% macro-recall, and 79.8% macro-F-score) and RoBERTa directly feeds raw data without any extra feature engineering. The confusion matrix is shown in
Figure 2b.
Both results demonstrate that the pre-trained models, DistilBERT and RoBERTa, tend to master the relationships between words in a sentence as a feature extraction method better than other methods.
5.2. Transfer Learning
In this section, we applied our trained DPICS models to classify parent-child interaction in real-life scenarios. The DPICS model was trained on the full DPICS-IV dataset. Then, our collected five-family dataset was evaluated. This step is important as an application to real-life data allows us to see how well our models perform outside of the controlled environment of the training and testing datasets. The results of our real-life classification are presented in
Table 6, where we report overall accuracy as the evaluation metric. This metric is intuitive and straightforward, as overall accuracy simply measures the proportion of correct classifications out of all classifications made.
According to the results presented in
Table 6, RoBERTa achieved the highest accuracy, with an average accuracy of 71.0% when applied to the five family datasets, while DistilBERT also demonstrated successful transfer learning. However, both BoW and TF-IDF did not perform well in transfer learning. Despite being widely used and recommended in previous work [
19,
20,
22], these methods require a complete and adequate corpus to produce accurate results. Our dataset was limited and expert-annotated data was expensive, which likely contributed to their poor performance. The GloVe method, which is word-based, performed better than BoW and TF-IDF but did not surpass the accuracy of DistilBERT and RoBERTa.
The results presented in our study demonstrate that transfer learning is applicable and can achieve acceptable results in DPICS code classification. The primary goal of developing DPICS classifiers is to assist and speed up the labeling process for experts. As such, it is important to consider the few-shot task in this development process. By leveraging the pre-trained models and fine-tuning them on small labeled datasets, we can efficiently classify parent–child interactions with a limited amount of annotated data.
5.3. Boosting Improvement
The DPICS-IV manual provides typical data but the amount of data is insufficient according to [
9]. Collecting data is a gradual process. In this section, we attempted to improve performance when newly labeled data is enrolled. Similarly, a special five-fold cross-validation is employed. We combined data from four families with the DPICS-IV manual as the training set and tested the model on the remaining family. This was carried out to determine whether the performance could be improved compared to using the DPICS-IV manual as the training set alone.
As
Table 7 indicates, our results showed that the accuracy of each family improved with an average accuracy of 75.5%, indicating that the sentence-level classifiers can be enhanced with the addition of more data. However, we did not observe any significant improvement in GloVe’s performance, indicating that word-based methods are not well-suited to DPICS code classification.
6. Discussion
Automated, accurate, and effective DPICS code classification can be advantageous for parent–child interaction therapists and researchers. For example, automatically classifying parent behavior and utterances into DPICS categories can facilitate streamlined data collection and analysis to accelerate the research process. From a clinical standpoint, this information can be utilized to provide personalized feedback to families who may be in treatment. This feedback can then be translated into just-in-time interventions that can be incorporated into application-based treatment. Rather than relying on manual coding of DPICS categories, which is time- and labor-intensive, leveraging artificial intelligence and machine learning can help automate this process and significantly advance behavioral treatment for families with children with elevated behavior problems (e.g., Attention-Deficit/Hyperactivity Disorder, Oppositional Defiant Disorder, or Conduct Disorder). This would be a substantial advancement given that there is a shortage of providers specializing in childhood disruptive behavior disorders according to the American Psychological Association, 2022.
There are several limitations to our work. The performance of four DPICS categories (RF, DQ, NTA, and TA) in the DPICS-IV dataset, as presented in
Figure 1 (Left), still needs improvement. Additionally, the accuracy of RF on the PCIT dataset, as presented in
Figure 1 (Right), is fair. Publicly available high-quality DPICS datasets are scarce due to privacy and security concerns. Additionally, the size of our collected and labeled data from five families is limited. Moreover, datasets are imbalanced and contain fewer instance categories due to their infrequent occurrence in daily parent–child interactions. Finally, we refrained from comparing various neural network structures and experimenting with numerous hyperparameters during downstream classification tasks because such an endeavor would be time-consuming.
After reviewing all the experimental results, we believe that the limited improvement in accuracy can be attributed to the fact that DPICS code classification requires contextual information, especially context from children’s responses and speech, as well as tone of speech and visual information. While Parent DPICS codes are currently labeled sentence by sentence, the DPICS-IV manual in
Table 1 provides examples that illustrate how a single speech sentence can be labeled with different DPICS codes depending on the situation. Given the context-dependent nature of DPICS codes, future work could also investigate the possibility of labeling DPICS codes at the level of a conversation or an interaction, rather than at the sentence level, to better capture the context and nuances of the parent–child interaction, although sentence-based DPICS code classifiers can achieve acceptable results and previous work has primarily focused on sentence-based DPICS code classifiers. To address this limitation, future studies could explore the use of context-based classifiers either alone or in combination with sentence-based classifiers. By doing so, researchers could gain a more comprehensive understanding of how children’s speech and language are related to different communication environments. In addition, the classifiers should be extended to more families when data is increasingly collected.
7. Conclusions
In our study, we proposed and compared various learning approaches to develop a sentence-based classifier for DPICS codes with 10 classes. Our results demonstrated that pre-trained language models, particularly RoBERTa, outperformed the other methods for DPICS classification and can be highly effective in accurately classifying DPICS codes, meaning utilizing a pre-trained model could be a promising method for developing a DPICS coding classifier. Specifically, RoBERTa surpassed previous results on an open-source PCIT dataset. Furthermore, word-based and statistics-based methods such as GloVe may not be suitable for DPICS code classification.
In the past, PCIT therapists had to manually label DPICS codes, a process that consumed significant time and energy. A brilliant automatic DPICS code classifier could provide valuable assistance to experts in the labeling process, leading to more labor-saving and precise labeling of parents’ speech and language. Therapists and experts can concentrate on delivering high-quality feedback and suggestions to parents without having to invest their limited time in labeling tasks.
With the advancement of Artificial Intelligence and NLP technology, the accuracy of trained automatic DPICS code classifiers can be enhanced significantly. This improvement in accuracy makes it possible for manual DPICS code labeling work to be entirely replaced by trained automatic DPICS code classifiers.
Author Contributions
Conceptualization, C.L. and O.B.; Methodology, C.L., O.B. and J.P.; Investigation, E.L.R. and K.L.; Resources, J.P., E.L.R. and K.L.; Data curation, J.P., E.L.R. and K.L.; Writing—original draft, C.L. and J.P.; Writing—review & editing, O.B., J.P. and B.M.; Supervision, O.B. and W.E.P.J.; Project administration, O.B. and W.E.P.J.; Funding acquisition, O.B. and W.E.P.J. All authors have read and agreed to the published version of the manuscript.
Funding
This material is based upon work supported by the National Science Foundation under Grant No. SCC-2125549.
Institutional Review Board Statement
The study was conducted in accordance with the Declaration of Helsinki, and approved by the Institutional Review Board of Florida International University (IRB Protocol Approval #: IRB-21-0454; IRB Approval Date: 21 October 2021).
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
DPICS-Manual dataset can be collected from [
6] and PCIT dataset can be found on [
9] the five-Family dataset is unavailable due to privacy and ethical restrictions.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Jeong, J.; Franchett, E.E.; Ramos de Oliveira, C.V.; Rehmani, K.; Yousafzai, A.K. Parenting interventions to promote early child development in the first three years of life: A global systematic review and meta-analysis. PLoS Med. 2021, 18, e1003602. [Google Scholar] [CrossRef]
- Nilsen, F.M.; Ruiz, J.D.; Tulve, N.S. A meta-analysis of stressors from the total environment associated with children’s general cognitive ability. Int. J. Environ. Res. Public Health 2020, 17, 5451. [Google Scholar] [CrossRef]
- Eyberg, S.M.; Boggs, S.R.; Algina, J. Parent-child interaction therapy: A psychosocial model for the treatment of young children with conduct problem behavior and their families. Psychopharmacol. Bull. 1995, 31, 83–91. [Google Scholar] [PubMed]
- Thomas, R.; Abell, B.; Webb, H.J.; Avdagic, E.; Zimmer-Gembeck, M.J. Parent-child interaction therapy: A meta-analysis. Pediatrics 2017, 140, e20170352. [Google Scholar] [CrossRef] [PubMed]
- Valero Aguayo, L.; Rodríguez Bocanegra, M.; Ferro García, R.; Ascanio Velasco, L. Meta-analysis of the efficacy and effectiveness of parent child interaction therapy (PCIT) for child behaviour problems. Psicothema 2021, 33, 544–555. [Google Scholar] [PubMed]
- Eyberg, S.M. Dyadic Parent-Child Interaction Coding System (DPICS): Comprehensive Manual for Research and Training; PCIT International, Incorporated: Riverside, CA, USA, 2013. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Huber, B.; Davis, R.F., III; Cotter, A.; Junkin, E.; Yard, M.; Shieber, S.; Brestan-Knight, E.; Gajos, K.Z. SpecialTime: Automatically detecting dialogue acts from speech to support parent-child interaction therapy. In Proceedings of the 13th EAI International Conference on Pervasive Computing Technologies for Healthcare, Trento Italy, 20–23 May 2019; pp. 139–148. [Google Scholar]
- Harris, Z.S. Distributional structure. Word 1954, 10, 146–162. [Google Scholar] [CrossRef]
- Luhn, H.P. A statistical approach to mechanized encoding and searching of literary information. IBM J. Res. Dev. 1957, 1, 309–317. [Google Scholar] [CrossRef]
- El-Din, D.M. Enhancement bag-of-words model for solving the challenges of sentiment analysis. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 244–252. [Google Scholar]
- HaCohen-Kerner, Y.; Miller, D.; Yigal, Y. The influence of preprocessing on text classification using a bag-of-words representation. PLoS ONE 2020, 15, e0232525. [Google Scholar] [CrossRef]
- Huang, C.R.; Lee, L.H. Contrastive approach towards text source classification based on top-bag-of-word similarity. In Proceedings of the 22nd Pacific Asia Conference on Language, Information and Computation, Cebu City, Philippines, 20–22 November 2008; pp. 404–410. [Google Scholar]
- Yan, D.; Li, K.; Gu, S.; Yang, L. Network-based bag-of-words model for text classification. IEEE Access 2020, 8, 82641–82652. [Google Scholar] [CrossRef]
- Rajaraman, A.; Ullman, J.D. Mining of Massive Datasets; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Sparck Jones, K. A statistical interpretation of term specificity and its application in retrieval. J. Doc. 1972, 28, 11–21. [Google Scholar] [CrossRef]
- Beel, J.; Gipp, B.; Langer, S.; Breitinger, C. Paper recommender systems: A literature survey. Int. J. Digit. Libr. 2016, 17, 305–338. [Google Scholar] [CrossRef]
- Christian, H.; Agus, M.P.; Suhartono, D. Single document automatic text summarization using term frequency-inverse document frequency (TF-IDF). ComTech Comput. Math. Eng. Appl. 2016, 7, 285–294. [Google Scholar] [CrossRef]
- Ghag, K.; Shah, K. SentiTFIDF–Sentiment classification using relative term frequency inverse document frequency. Int. J. Adv. Comput. Sci. Appl. 2014, 5, 36–176. [Google Scholar] [CrossRef]
- Hakim, A.A.; Erwin, A.; Eng, K.I.; Galinium, M.; Muliady, W. Automated document classification for news article in Bahasa Indonesia based on term frequency inverse document frequency (TF-IDF) approach. In Proceedings of the 2014 6th International Conference on Information Technology and Electrical Engineering (ICITEE), Yogyakarta, Indonesia, 7–8 October 2014; pp. 1–4. [Google Scholar]
- Sjarif, N.N.A.; Azmi, N.F.M.; Chuprat, S.; Sarkan, H.M.; Yahya, Y.; Sam, S.M. SMS spam message detection using term frequency-inverse document frequency and random forest algorithm. Procedia Comput. Sci. 2019, 161, 509–515. [Google Scholar] [CrossRef]
- Suhartono, D.; Purwandari, K.; Jeremy, N.H.; Philip, S.; Arisaputra, P.; Parmonangan, I.H. Deep neural networks and weighted word embeddings for sentiment analysis of drug product reviews. Procedia Comput. Sci. 2023, 216, 664–671. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26. [Google Scholar] [CrossRef]
- Mikolov, T.; Le, Q.V.; Sutskever, I. Exploiting similarities among languages for machine translation. arXiv 2013, arXiv:1309.4168. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Schütze, H.; Manning, C.D.; Raghavan, P.; Schtze, H. Relevance Feedback and Query Expansion. Introduction to Information Retrieval; Cambridge University Press: New York, NY, USA, 2008. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Gao, Z.; Feng, A.; Song, X.; Wu, X. Target-dependent sentiment classification with BERT. IEEE Access 2019, 7, 154290–154299. [Google Scholar] [CrossRef]
- Koroteev, M.V. BERT: A review of applications in natural language processing and understanding. arXiv 2021, arXiv:2103.11943. [Google Scholar]
- Müller, M.; Salathé, M.; Kummervold, P.E. COVID-twitter-bert: A natural language processing model to analyse COVID-19 content on twitter. arXiv 2020, arXiv:2005.07503. [Google Scholar] [CrossRef] [PubMed]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Adoma, A.F.; Henry, N.M.; Chen, W. Comparative analyses of bert, roberta, distilbert, and xlnet for text-based emotion recognition. In Proceedings of the 2020 17th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP), Chengdu, China, 18–20 December 2020; pp. 117–121. [Google Scholar]
- Cortiz, D. Exploring transformers in emotion recognition: A comparison of bert, distillbert, roberta, xlnet and electra. arXiv 2021, arXiv:2104.02041. [Google Scholar]
- Tarunesh, I.; Aditya, S.; Choudhury, M. Trusting roberta over bert: Insights from checklisting the natural language inference task. arXiv 2021, arXiv:2107.07229. [Google Scholar]
- Diyasa, I.G.S.M.; Mandenni, N.M.I.M.; Fachrurrozi, M.I.; Pradika, S.I.; Manab, K.R.N.; Sasmita, N.R. Twitter sentiment analysis as an evaluation and service base on python textblob. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1125, 012034. [Google Scholar] [CrossRef]
- Gupta, B.; Negi, M.; Vishwakarma, K.; Rawat, G.; Badhani, P.; Tech, B. Study of Twitter sentiment analysis using machine learning algorithms on Python. Int. J. Comput. Appl. 2017, 165, 29–34. [Google Scholar] [CrossRef]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of tricks for efficient text classification. arXiv 2016, arXiv:1607.01759. [Google Scholar]
- Wagh, R.; Punde, P. Survey on sentiment analysis using twitter dataset. In Proceedings of the 2018 Second International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 29–31 March 2018; pp. 208–211. [Google Scholar]
- Ahammed, M.T.; Gloria, A.; Oion, M.S.R.; Ghosh, S.; Balaii, P.; Nisat, T. Sentiment Analysis using a Machine Learning Approach in Python. In Proceedings of the 2022 International Conference on Communication, Computing and Internet of Things (IC3IoT), Chennai, India, 10–11 March 2022; pp. 1–6. [Google Scholar]
- Singh, J.; Tripathi, P. Sentiment analysis of Twitter data by making use of SVM, Random Forest and Decision Tree algorithm. In Proceedings of the 2021 10th IEEE International Conference on Communication Systems and Network Technologies (CSNT), Bhopal, India, 18–19 June 2021; pp. 193–198. [Google Scholar]
- Pandarachalil, P.; Sendhilkumar, S.; Mahalakshmi, G.S. Twitter sentiment analysis for large-scale data: An unsupervised approach. Cogn. Comput. 2015, 7, 254–262. [Google Scholar] [CrossRef]
- Qaisar, S.M. Sentiment analysis of IMDb movie reviews using long short-term memory. In Proceedings of the 2020 2nd International Conference on Computer and Information Sciences (ICCIS), Sakaka, Saudi Arabia, 13–15 October 2020; pp. 1–4. [Google Scholar]
- Nelson, M.M.; Olsen, B. Dyadic parent–child interaction coding system (DPICS): An adaptable measure of parent and child behavior during dyadic interactions. In Handbook of Parent-Child Interaction Therapy: Innovations and Applications for Research and Practice; Springer: Berlin/Heidelberg, Germany, 2018; pp. 285–302. [Google Scholar]
- Cañas, M.; Ibabe, I.; Arruabarrena, I.; De Paúl, J. The dyadic parent-child interaction coding system (DPICS): Negative talk as an indicator of dysfunctional mother-child interaction. Child. Youth Serv. Rev. 2022, 143, 106679. [Google Scholar] [CrossRef]
- Cotter, A.M. Psychometric Properties of the Dyadic Parent-Child Interaction Coding System (DPICS): Investigating Updated Versions Across Diagnostic Subgroups. Ph.D. Thesis, Auburn University, Auburn, AL, USA, 2016. [Google Scholar]
- Cañas Miguel, M.; Ibabe Erostarbe, I.; Arruabarrena Madariaga, M.I.; Paúl Ochotorena, J.D. Dyadic parent-child interaction coding system (Dpics): Factorial structure and concurrent validity. Psicothema 2021, 33, 328–336. [Google Scholar]
- Cotter, A.M.; Brestan-Knight, E. Convergence of parent report and child behavior using the Dyadic Parent-Child Interaction Coding System (DPICS). J. Child Fam. Stud. 2020, 29, 3287–3301. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).




{kind=link}
{kind=link}