
Performance Evaluation of Different Decision Fusion Approaches for Image Classification
 ,
,
Abstract
:1. Introduction
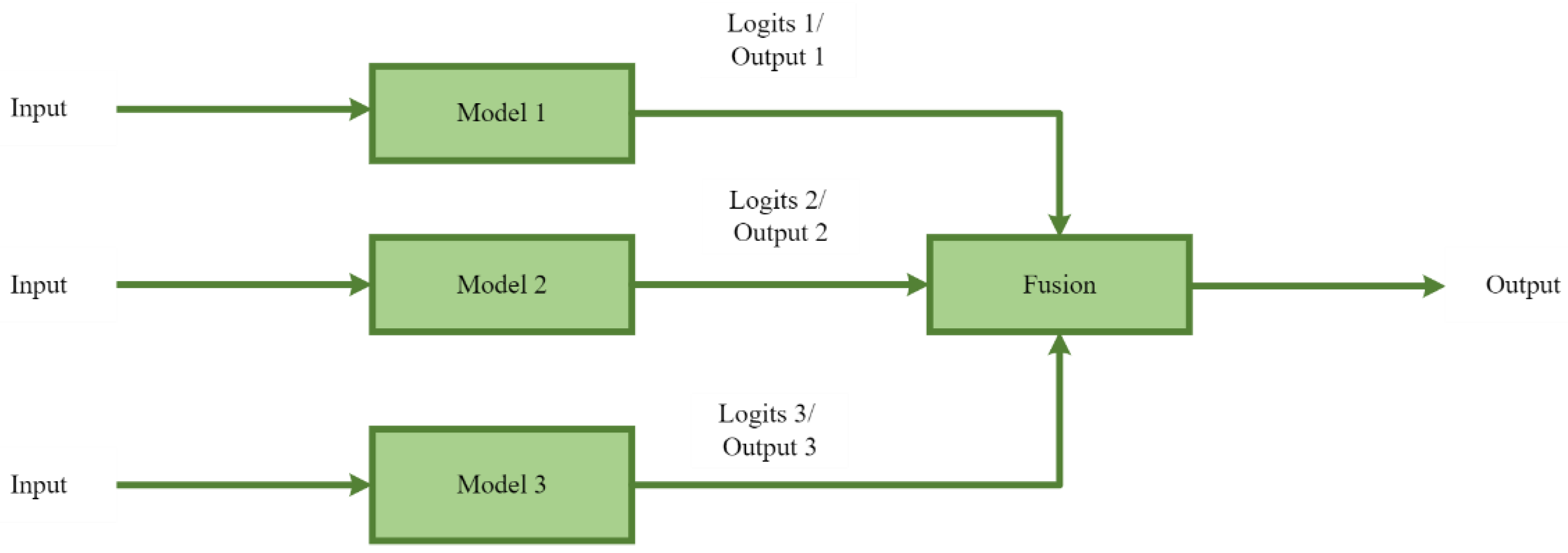
- The paper proposes and evaluates two approaches for attaining the dissimilarity between the outputs of the classifiers, which is crucial for getting good performance using decision fusion. One is using dissimilar classifiers with different architectures, and the other is using similar classifiers with similar architectures but trained with different batch-sizes.
- The paper compares the different decision fusion strategies for both of the aforementioned approaches.
- The paper investigates the correlation between the number of dissimilar outputs between the classifiers and the performance increase due to the decision fusion of these classifiers.
2. Literature Review
3. Technical Background
4. Proposed Model
5. Results and Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Camero, A.; Alba, E. Smart City and information technology: A review. Cities 2019, 93, 84–94. [Google Scholar] [CrossRef]
- Anthopoulos, L.G. Understanding the smart city domain: A literature review. In Transforming City Governments for Successful Smart Cities; Springer: Cham, Switzerland, 2015; pp. 9–21. [Google Scholar]
- Gaur, A.; Scotney, B.; Parr, G.; McClean, S. Smart city architecture and its applications based on IoT. Procedia Comput. Sci. 2015, 52, 1089–1094. [Google Scholar] [CrossRef]
- Krishnamurthi, R.; Kumar, A.; Gopinathan, D.; Nayyar, A.; Qureshi, B. An overview of IoT sensor data processing, fusion, and analysis techniques. Sensors 2020, 20, 6076. [Google Scholar] [CrossRef] [PubMed]
- Ghazal, T.M.; Hasan, M.K.; Alshurideh, M.T.; Alzoubi, H.M.; Ahmad, M.; Akbar, S.S.; Al Kurdi, B.; Akour, I.A. IoT for smart cities: Machine learning approaches in smart healthcare—A review. Future Internet 2021, 13, 218. [Google Scholar] [CrossRef]
- Kumar, A.; Krishnamurthi, R.; Nayyar, A.; Sharma, K.; Grover, V.; Hossain, E. A novel smart healthcare design, simulation, and implementation using healthcare 4.0 processes. IEEE Access 2020, 8, 118433–118471. [Google Scholar] [CrossRef]
- Zantalis, F.; Koulouras, G.; Karabetsos, S.; Kandris, D. A review of machine learning and IoT in smart transportation. Future Internet 2019, 11, 94. [Google Scholar] [CrossRef] [Green Version]
- Kelley, S.B.; Lane, B.W.; Stanley, B.W.; Kane, K.; Nielsen, E.; Strachan, S. Smart transportation for all? A typology of recent U.S. smart transportation projects in midsized cities. Ann. Assoc. Am. Geogr. 2019, 110, 547–558. [Google Scholar] [CrossRef]
- Dileep, G. A survey on smart grid technologies and applications. Renew. Energy 2019, 146, 2589–2625. [Google Scholar] [CrossRef]
- Neffati, O.S.; Sengan, S.; Thangavelu, K.D.; Kumar, S.D.; Setiawan, R.; Elangovan, M.; Mani, D.; Velayutham, P. Migrating from traditional grid to smart grid in smart cities promoted in developing country. Sustain. Energy Technol. Assess. 2021, 45, 101125. [Google Scholar] [CrossRef]
- Dutta, A.; Batabyal, T.; Basu, M.; Acton, S.T. An efficient convolutional neural network for coronary heart disease prediction. Expert Syst. Appl. 2020, 159, 113408. [Google Scholar] [CrossRef]
- Ambekar, S.; Phalnikar, R. Disease risk prediction by using convolutional neural network. In Proceedings of the 2018 Fourth International Conference on Computing Communication Control and Automation (ICCUBEA), Pune, India, 16–18 August 2018; pp. 1–5. [Google Scholar]
- Gul, M.A.; Yousaf, M.H.; Nawaz, S.; Rehman, Z.U.; Kim, H. Patient monitoring by abnormal human activity recognition based on CNN architecture. Electronics 2020, 9, 1993. [Google Scholar] [CrossRef]
- Yu, M.; Gong, L.; Kollias, S. Computer vision based fall detection by a convolutional neural network. In Proceedings of the 19th ACM International Conference on Multimodal Interaction, Glasgow, UK, 13–17 November 2017; pp. 416–420. [Google Scholar]
- Kurniawan, J.; Syahra, S.G.; Dewa, C.K.; Afiahayati. Traffic congestion detection: Learning from CCTV monitoring images using convolutional neural network. Procedia Comput. Sci. 2018, 144, 291–297. [Google Scholar] [CrossRef]
- Zhu, Z.; Liang, D.; Zhang, S.; Huang, X.; Li, B.; Hu, S. Traffic-sign detection and classification in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2110–2118. [Google Scholar]
- Ghosh, S.; Sunny, S.J.; Roney, R. Accident detection using convolutional neural networks. In Proceedings of the 2019 International Conference on Data Science and Communication (IconDSC), Bangalore, India, 1–2 March 2019; pp. 1–6. [Google Scholar]
- Naik, D.B.; Lakshmi, G.S.; Sajja, V.R.; Venkatesulu, D.; Rao, J.N. Driver’s seat belt detection using CNN. Turk. J. Comput. Math. Educ. (TURCOMAT) 2021, 12, 776–785. [Google Scholar]
- Mohammadpourfard, M.; Genc, I.; Lakshminarayana, S.; Konstantinou, C. Attack detection and localization in smart grid with image-based deep learning. In Proceedings of the 2021 IEEE International Conference on Communications, Control, and Computing Technologies for Smart Grids (SmartGridComm), Aachen, Germany, 25–28 October 2021; pp. 121–126. [Google Scholar] [CrossRef]
- Agrawal, A.; Sethi, K.; Bera, P. IoT-Based Aggregate Smart Grid Energy Data Extraction using Image Recognition and Partial Homomorphic Encryption. In Proceedings of the 2021 IEEE International Conference on Advanced Networks and Telecommunications Systems (ANTS), Hyderabad, India, 13–16 December 2021; pp. 408–413. [Google Scholar]
- Laroca, R.; Barroso, V.; Diniz, M.A.; Gonçalves, G.R.; Schwartz, W.; Menotti, D. Convolutional neural networks for automatic meter reading. J. Electron. Imaging 2019, 28, 013023. [Google Scholar] [CrossRef]
- Ahn, E.; Kumar, A.; Feng, D.; Fulham, M.; Kim, J. Unsupervised feature learning with K-means and an ensemble of deep convolutional neural networks for medical image classification. arXiv 2019, arXiv:1906.03359. [Google Scholar]
- Gifani, P.; Shalbaf, A.; Vafaeezadeh, M. Automated detection of COVID-19 using ensemble of transfer learning with deep convolutional neural network based on CT scans. Int. J. Comput. Assist. Radiol. Surg. 2020, 16, 115–123. [Google Scholar] [CrossRef]
- Ali, F.; El-Sappagh, S.; Islam, S.R.; Kwak, D.; Ali, A.; Imran, M.; Kwak, K.-S. A smart healthcare monitoring system for heart disease prediction based on ensemble deep learning and feature fusion. Inf. Fusion 2020, 63, 208–222. [Google Scholar] [CrossRef]
- Li, Y.; Song, Y.; Jia, L.; Gao, S.; Li, Q.; Qiu, M. Intelligent fault diagnosis by fusing domain adversarial training and maximum mean discrepancy via ensemble learning. IEEE Trans. Ind. Inform. 2020, 17, 2833–2841. [Google Scholar] [CrossRef]
- Sukegawa, S.; Fujimura, A.; Taguchi, A.; Yamamoto, N.; Kitamura, A.; Goto, R.; Nakano, K.; Takabatake, K.; Kawai, H.; Nagatsuka, H.; et al. Identification of osteoporosis using ensemble deep learning model with panoramic radiographs and clinical covariates. Sci. Rep. 2022, 12, 6088. [Google Scholar] [CrossRef]
- Ganaie, M.A.; Tanveer, M. Ensemble deep random vector functional link network using privileged information for Alzheimer’s disease diagnosis. IEEE/ACM Trans. Comput. Biol. Bioinform. 2022. [Google Scholar] [CrossRef]
- Li, S.; Lu, X.; Sakai, S.; Mimura, M.; Kawahara, T. Semi-supervised ensemble DNN acoustic model training. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 5270–5274. [Google Scholar] [CrossRef]
- Singla, P.; Duhan, M.; Saroha, S. An ensemble method to forecast 24-h ahead solar irradiance using wavelet decomposition and BiLSTM deep learning network. Earth Sci. Inform. 2021, 15, 291–306. [Google Scholar] [CrossRef] [PubMed]
- Wen, L.; Xie, X.; Li, X.; Gao, L. A new ensemble convolutional neural network with diversity regularization for fault diagnosis. J. Manuf. Syst. 2020, 62, 964–971. [Google Scholar] [CrossRef]
- Tsogbaatar, E.; Bhuyan, M.H.; Taenaka, Y.; Fall, D.; Gonchigsumlaa, K.; Elmroth, E.; Kadobayashi, Y. DeL-IoT: A deep ensemble learning approach to uncover anomalies in IoT. Internet Things 2021, 14, 100391. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, W.; Song, R.; Ma, L.; Li, Y. Grasp for stacking via deep reinforcement learning. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–August 2020; pp. 2543–2549. [Google Scholar]
- Kazemi, S.M.R.; Bidgoli, B.M.; Shamshirband, S.; Karimi, S.M.; Ghorbani, M.A.; Chau, K.-W.; Pour, R.K. Novel genetic-based negative correlation learning for estimating soil temperature. Eng. Appl. Comput. Fluid Mech. 2018, 12, 506–516. [Google Scholar] [CrossRef] [Green Version]
- Shi, Z.; Zhang, L.; Liu, Y.; Cao, X.; Ye, Y.; Cheng, M.M.; Zheng, G. Crowd counting with deep negative correlation learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5382–5390. [Google Scholar]
- Yang, B.; Yan, J.; Lei, Z.; Li, S.Z. Convolutional channel features. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 82–90. [Google Scholar]
- Hu, B.; Li, Q.; Hall, G.B. A decision-level fusion approach to tree species classification from multi-source remotely sensed data. ISPRS Open J. Photogramm. Remote Sens. 2021, 1, 100002. [Google Scholar] [CrossRef]
- Nadeem, M.W.; Goh, H.G.; Khan, M.A.; Hussain, M.; Mushtaq, M.F.; Ponnusamy, V.A. Fusion-based machine learning architecture for heart disease prediction. Comput. Mater. Contin. 2021, 67, 2481–2496. [Google Scholar] [CrossRef]
- Teng, S.; Chen, G.; Liu, Z.; Cheng, L.; Sun, X. Multi-sensor and decision-level fusion-based structural damage detection using a one-dimensional convolutional neural network. Sensors 2021, 21, 3950. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Conv2d(3, 64, kernel_size = (3, 3)) |
| Conv2d(64, 64, kernel_size = (3, 3)) |
| MaxPool2d |
| Conv2d(64, 128, kernel_size = (3, 3)) |
| Conv2d(128, 128, kernel_size = (3, 3)) |
| MaxPool2d |
| Conv2d(128, 256, kernel_size = (3, 3)) |
| Conv2d(256, 256, kernel_size = (3, 3)) |
| Conv2d(256, 256, kernel_size = (3, 3)) |
| MaxPool2d |
| Conv2d(256, 512, kernel_size = (3, 3)) |
| Conv2d(512, 512, kernel_size = (3, 3)) |
| Conv2d(512, 512, kernel_size = (3, 3)) |
| MaxPool2d |
| Conv2d(512, 512, kernel_size = (3, 3)) |
| Conv2d(512, 512, kernel_size = (3, 3)) |
| Conv2d(512, 512, kernel_size = (3, 3)) |
| MaxPool2d |
| Linear(512, 512) |
| Linear(512, 10) |
| Softmax |
| Conv2d(3, 64, kernel_size = (3, 3)) |
| Conv2d(64, 64, kernel_size = (3, 3)) |
| MaxPool2d |
| Conv2d(64, 128, kernel_size = (3, 3)) |
| Conv2d(128, 128, kernel_size = (3, 3)) |
| MaxPool2d |
| Conv2d(128, 256, kernel_size = (3, 3)) |
| MaxPool2d |
| Conv2d(256, 256, kernel_size = (3, 3)) |
| Conv2d(256, 256, kernel_size = (3, 3)) |
| Conv2d(256, 256, kernel_size = (3, 3)) |
| MaxPool2d |
| Conv2d(256, 512, kernel_size = (3, 3)) |
| Conv2d(512, 512, kernel_size = (3, 3)) |
| Conv2d(512, 512, kernel_size = (3, 3)) |
| Conv2d(512, 512, kernel_size = (3, 3)) |
| MaxPool2d |
| Conv2d(512, 512, kernel_size = (3, 3)) |
| Conv2d(512, 512, kernel_size = (3, 3)) |
| Conv2d(512, 512, kernel_size = (3, 3)) |
| Conv2d(512, 512, kernel_size = (3, 3)) |
| MaxPool2d |
| Linear(512, 512) |
| Linear(512, 10) |
| Softmax |
| Conv2d(3, 16, kernel_size = (3, 3)) | ×1 |
| Conv2d(16, 16, kernel_size = (3, 3)) | ×9 |
| Conv2d(16, 16, kernel_size = (3, 3)) | |
| Conv2d(16, 32, kernel_size = (3, 3)) | ×1 |
| Conv2d(32, 32, kernel_size = (3, 3)) | |
| Conv2d(16, 32, kernel_size = (3, 3)) | |
| Conv2d(32, 32, kernel_size = (3, 3)) | ×8 |
| Conv2d(32, 32, kernel_size = (3, 3)) | |
| Conv2d(32, 64, kernel_size = (3, 3)) | ×1 |
| Conv2d(64, 64, kernel_size = (3, 3)) | |
| Conv2d(32, 64, kernel_size = (3, 3)) | |
| Conv2d(64, 64, kernel_size = (3, 3)) | ×8 |
| Conv2d(64, 64, kernel_size = (3, 3)) | |
| Linear(64, 10) | ×1 |
| Softmax | |
| Hyper-Parameters | Value |
|---|---|
| Epochs | 300 |
| Learning Rate | 0.1 |
| Learning Rate Decay | 0.1 |
| Optimizer | SGD |
| Momentum | 0.9 |
| Weight Decay | 0.0005 |
| Batch-Sizes | 128, 512, 1024 |
| Loss-function | Cross-Entropy loss |
| Model | Accuracy (%) |
|---|---|
| VGG16_128 | 94 |
| VGG19_128 | 93.9 |
| ResNet56_128 | 94.14 |
| VGG16_128 + VGG19_128 + ResNet56_128 | 95.46 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alwakeel, A.; Alwakeel, M.; Hijji, M.; Saleem, T.J.; Zahra, S.R. Performance Evaluation of Different Decision Fusion Approaches for Image Classification. Appl. Sci. 2023, 13, 1168. https://doi.org/10.3390/app13021168
Alwakeel A, Alwakeel M, Hijji M, Saleem TJ, Zahra SR. Performance Evaluation of Different Decision Fusion Approaches for Image Classification. Applied Sciences. 2023; 13(2):1168. https://doi.org/10.3390/app13021168
Chicago/Turabian StyleAlwakeel, Ahmed, Mohammed Alwakeel, Mohammad Hijji, Tausifa Jan Saleem, and Syed Rameem Zahra. 2023. "Performance Evaluation of Different Decision Fusion Approaches for Image Classification" Applied Sciences 13, no. 2: 1168. https://doi.org/10.3390/app13021168