
Sentiment Analysis on Algerian Dialect with Transformers



Abstract
:1. Introduction
2. Problem Statement and Research Objectives
- Creating an extensive and specialized corpus of Algerian Arabic text samples to enhance Arabic language resources and strengthen natural language processing capabilities for this specific dialect.
- Investigate and implement pre-processing techniques that are specifically optimized for the Algerian Arabic dialect, considering the unique linguistic features and nuances of this dialect.
- Emphasize the potential of state-of-the-art deep learning models, like BERT, for natural language processing in this specific linguistic and cultural context.
- Ensure that the developed model can be applied to infer sentiment from any Algerian text, making it a practical tool for understanding the opinions and emotions of the Algerian population.
3. Data Collection and Analysis
3.1. Existing Datasets
- ASAD [23]: A public dataset extracted from Twitter intended to accelerate research in Arabic NLP in general and Arabic sentiment classification in specific.
- ATSAD [24]: A multi-dialect dataset that was automatically annotated using emojis.
- TSAC [25]: A Tunisian dialect dataset that was extracted from Facebook comments.
- SIACC [26]: Sentiment Polarity Identification on Arabic Algerian Newspaper Comments.
- Ref. [27]: 1000 reviews collected from Algerian press.
- Ref. [28]: Posts and comments collected from Algerian Facebook pages.
- TWIFIL [29]: Annotated tweets collected between 2015 and 2019 were obtained from different geo-locations in Algeria with the help of 26 annotators.
- Ref. [20]: 21,885 posts were collected from Algerian public groups on Facebook.
- SentiALG [30]: An automatically constructed Algerian sentiment corpus containing 8000 messages.
3.2. Collected Dataset’s Statistics and Properties
3.3. N-Gram Analysis
3.4. Data Preprocessing
- Removing HTML tags: When extracting comments from YouTube, some comments come with tags such as </br> and more; removing them improves our primary metrics.
- Replacing URLs, email addresses, and phone numbers: some comments include these, such as spam and promotional comments; instead of removing them, we have replaced them with a special token.
- Inserting spaces between emojis: Emojis are useful for detecting sentiment in sentences, so we did not remove them. Instead, we append and prepend white spaces between emojis, so that each is considered an individual token.
- Normalizing special Arabic characters: In this task, we have replaced several Arabic characters with other more common characters, such as converting آ, أ, and إ to ا.
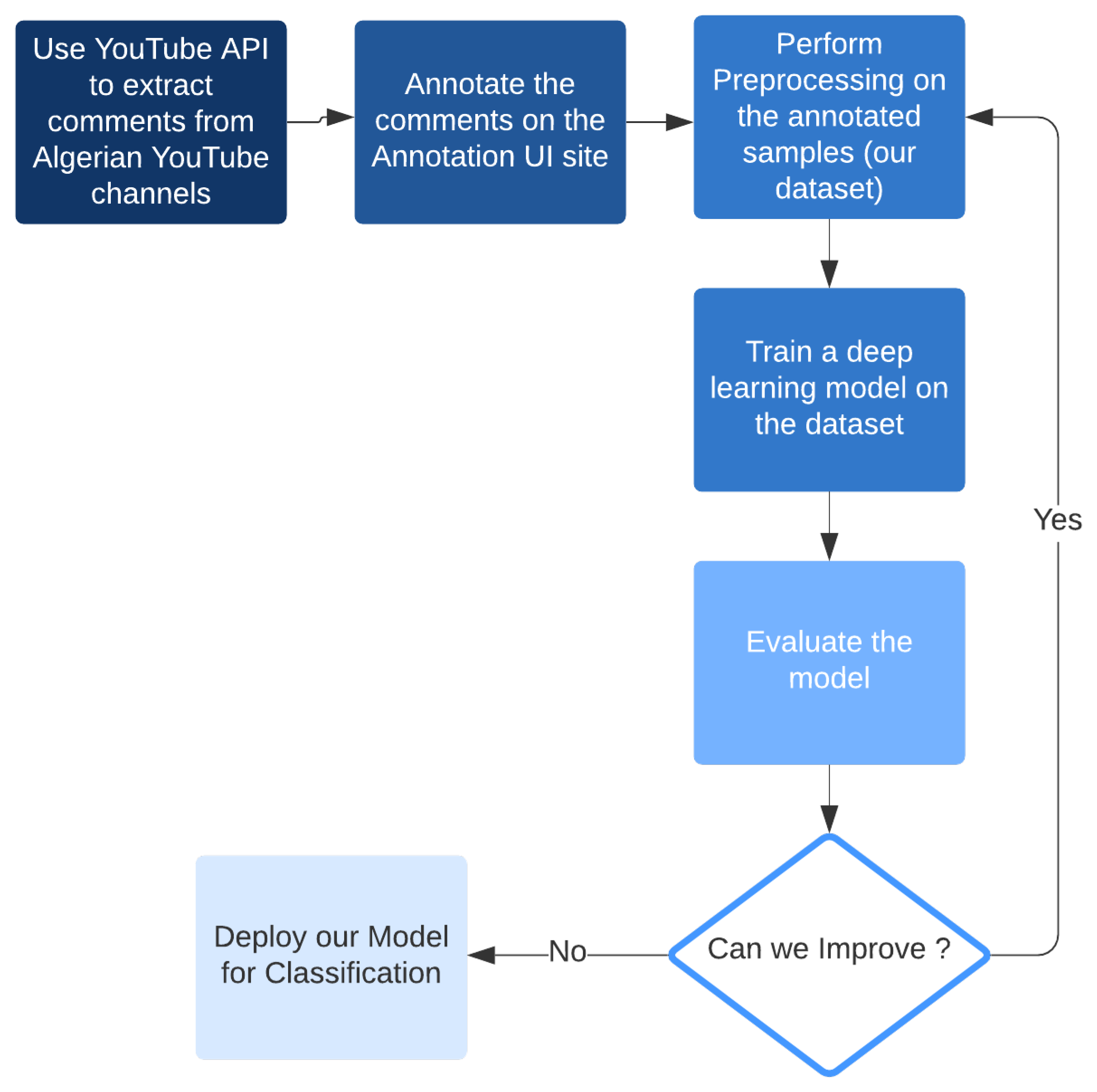
4. Classification of Algerian YouTube Comments Using Transformers
- Extracting comments from Algerian YouTube channels using YouTube API: In this stage, we used YouTube API to bring out a large number of comments into a PostgreSQL with the help of Django ORM.
- Annotating the comments on the annotation GUI site: Here, we used our GUI to manually annotate the comments into one of the three classes: negative, neutral, or positive.
- Performing preprocessing on the collected dataset: After gathering enough data, preprocessing was the next phase, where we tried to clean our text as much as we can to be understandable by our model.
- Training a deep learning model on the dataset: In this phase, we trained a deep learning model on the dataset; more detail is given in the Model Performance section.
- Evaluating the model: After we trained the model, we needed to calculate our evaluation metrics (which we will see in the next section) on the testing set to determine whether we can make improvements. If so, we can change the preprocessing technique and the way we train the model, such as changing the model architecture, weights, or training parameters, and then evaluate it once again. If we cannot improve the model further, we go on to the next stage, which is model deployment.
- Deploying our model for inference: In this stage, we deploy our model in such a way that it is ready for real-world use in a production environment; more detail on this is provided in the Model Deployment and Model Inference sections.
4.1. Evaluation Metrics
4.2. Model Performance
4.3. Model Deployment
4.4. Model Inference
5. Experimental Results and Discussions
5.1. Experiment Setting
- Sequence length: The maximum length of a sequence in the input text. We set it to 180 for our dataset, which means we truncate longer sentences into 180 tokens and pad shorter sentences with zeros on the left. More than 93% of the sentences in our dataset have at most 180 tokens. In the next section, we will experiment with this parameter too.
- Learning rate: The configurable hyperparameter used to train neural networks during the backpropagation phase. For large models like Transformers, it is often between and , and may increase or decrease depending on the model and data sizes. We ran the optuna library for more than 100 trials to obtain the best learning rate, and was chosen.
- Training epochs: An epoch trains the whole training dataset for one cycle. We chose three as our number of training epochs.
- Batch size: A hyperparameter that controls the number of samples to feed into the neural network in a single training iteration. Again, optuna chose 16.
- Warmup steps: The number of steps at the beginning of the training, where we use a very low learning rate to avoid early overfitting and also to slowly start fine-tuning the weights in the transformers. We have over 5900 total training iterations, and 800 was set as the number of warmup steps.
5.2. Results and Analysis
- Removing elongation: This task consists of removing redundant letters; words like “braaaavooooo” are transformed to “braavoo”, where 2 redundant characters is the maximum.
- Replacing URLs, phone numbers, and emails: This task is straightforward; since URLs, phone numbers, and emails do not contribute to the sentiment of the sentence, they are simply replaced by a special token.
- Removing HTML: This one removes HTML tags from all sentences.
- Removing Emojis: Removing all types of emojis from text.
- Inserting spaces between emojis: A lot of comments come with multiple emojis that are attached to each other. This task inserts spaces between them to help the WordPiece tokenizer [35] learn these emojis as individual tokens.
- Converting Latin to Arabic: As mentioned earlier, many Algerians use Latin characters to express their opinions on social media. As a result, we constructed a simple algorithm to convert Arabic words written in Latin characters into Arabic characters. Here are some examples:
- (a)
- Rbi y7fdhk → ربي يحفظك (May God protect you)
- (b)
- Ro7 khlih → روح خليه (Let him)
- Removing redundant punctuation: Some comments have multiple punctuation marks between two words. In this task, we simply allow only one punctuation mark between two words.
- Removing stop words: Arabic and some Algerian stop words were removed entirely in this task.
- Removing redundant words: Some comments are basically spam, repeating the word dozens of times. This task only allows two redundant words as a maximum.
- Balancing the dataset: As discussed in Section 3.2, 22.4% of the total labeled samples are neutral sentiments, 35.5% are negative, and 42.1% are positive; this task takes the lowest percentage to apply to all classes and discards the others so that we end up with a balanced dataset.
- Normalizing special Arabic characters: Some Arabic characters need to be normalized, such as replacing أ, آ, and إ with ا.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task ID | Preprocessing Task | F1-Score | Accuracy |
|---|---|---|---|
| / | No Preprocessing | 0.7764 | 0.8078 |
| 1 | Removing elongation | 0.7781 | 0.8086 |
| 2 | Replacing URLs, phone numbers, and emails | 0.7789 | 0.8094 |
| 3 | Removing HTML | 0.7812 | 0.8112 |
| 4 | Removing emojis | 0.7763 | 0.8074 |
| 5 | Inserting spaces between emojis | 0.7804 | 0.8107 |
| 6 | Converting Latin characters to Arabic | 0.7788 | 0.8076 |
| 7 | Removing redundant punctuation | 0.7786 | 0.8087 |
| 8 | Removing stop words | 0.6440 | 0.6881 |
| 9 | Removing redundant words | 0.7758 | 0.8072 |
| 10 | Balancing the dataset | 0.7653 | 0.7680 |
| 11 | Normalizing special Arabic characters | 0.7776 | 0.8094 |
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Medhat, W.; Hassan, A.; Korashy, H. Sentiment analysis algorithms and applications: A survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [Google Scholar] [CrossRef]
- Meena, G.; Mohbey, K.K.; Indian, A.; Khan, M.Z.; Kumar, S. Identifying emotions from facial expressions using a deep convolutional neural network-based approach. Multimed. Tools Appl. 2023, 1–22. [Google Scholar] [CrossRef]
- Mohbey, K.K.; Meena, G.; Kumar, S.; Lokesh, K. A CNN-LSTM-Based Hybrid Deep Learning Approach for Sentiment Analysis on Monkeypox Tweets. New Gener. Comput. 2023, 1–19. [Google Scholar] [CrossRef]
- Boulesnane, A.; Saidi, Y.; Kamel, O.; Bouhamed, M.M.; Mennour, R. DZchatbot: A Medical Assistant Chatbot in the Algerian Arabic Dialect using Seq2Seq Model. In Proceedings of the 2022 4th International Conference on Pattern Analysis and Intelligent Systems (PAIS), Oum El Bouaghi, Algeria, 12–13 October 2022. [Google Scholar] [CrossRef]
- Mansouri, A. Algeria between Tradition and Modernity: The Question of Language; State University of New York: Albany, NY, USA, 1991. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar] [CrossRef]
- Lin, T.; Wang, Y.; Liu, X.; Qiu, X. A survey of transformers. AI Open 2022, 3, 111–132. [Google Scholar] [CrossRef]
- Aftan, S.; Shah, H. Using the AraBERT Model for Customer Satisfaction Classification of Telecom Sectors in Saudi Arabia. Brain Sci. 2023, 13, 147. [Google Scholar] [CrossRef] [PubMed]
- Alshehri, W.; Al-Twairesh, N.; Alothaim, A. Affect Analysis in Arabic Text: Further Pre-Training Language Models for Sentiment and Emotion. Appl. Sci. 2023, 13, 5609. [Google Scholar] [CrossRef]
- Alruily, M.; Fazal, A.M.; Mostafa, A.M.; Ezz, M. Automated Arabic Long-Tweet Classification Using Transfer Learning with BERT. Appl. Sci. 2023, 13, 3482. [Google Scholar] [CrossRef]
- Almaliki, M.; Almars, A.M.; Gad, I.; Atlam, E.S. ABMM: Arabic BERT-Mini Model for Hate-Speech Detection on Social Media. Electronics 2023, 12, 1048. [Google Scholar] [CrossRef]
- Sabbeh, S.F.; Fasihuddin, H.A. A Comparative Analysis of Word Embedding and Deep Learning for Arabic Sentiment Classification. Electronics 2023, 12, 1425. [Google Scholar] [CrossRef]
- Al Shamsi, A.A.; Abdallah, S. Ensemble Stacking Model for Sentiment Analysis of Emirati and Arabic Dialects. J. King Saud Univ. -Comput. Inf. Sci. 2023, 35, 101691. [Google Scholar] [CrossRef]
- Khurana, D.; Koli, A.; Khatter, K.; Singh, S. Natural language processing: State of the art, current trends and challenges. Multimed. Tools Appl. 2022, 82, 3713–3744. [Google Scholar] [CrossRef] [PubMed]
- Stine, R.A. Sentiment Analysis. Annu. Rev. Stat. Its Appl. 2019, 6, 287–308. [Google Scholar] [CrossRef]
- Dang, N.C.; Moreno-García, M.N.; la Prieta, F.D. Sentiment Analysis Based on Deep Learning: A Comparative Study. Electronics 2020, 9, 483. [Google Scholar] [CrossRef]
- Yasen, M.; Tedmori, S. Movies Reviews Sentiment Analysis and Classification. In Proceedings of the 2019 IEEE Jordan International Joint Conference on Electrical Engineering and Information Technology (JEEIT), Amman, Jordan, 9–11 April 2019. [Google Scholar] [CrossRef]
- Oueslati, O.; Cambria, E.; HajHmida, M.B.; Ounelli, H. A review of sentiment analysis research in Arabic language. Future Gener. Comput. Syst. 2020, 112, 408–430. [Google Scholar] [CrossRef]
- Boudad, N.; Faizi, R.; Thami, R.O.H.; Chiheb, R. Sentiment analysis in Arabic: A review of the literature. Ain Shams Eng. J. 2018, 9, 2479–2490. [Google Scholar] [CrossRef]
- Boulesnane, A.; Meshoul, S.; Aouissi, K. Influenza-like Illness Detection from Arabic Facebook Posts Based on Sentiment Analysis and 1D Convolutional Neural Network. Mathematics 2022, 10, 4089. [Google Scholar] [CrossRef]
- Darwish, K. Arabic Information Retrieval. Found. Trends Inf. Retr. 2014, 7, 239–342. [Google Scholar] [CrossRef]
- Al-Wer, E.; Jong, R. Dialects of Arabic. In The Handbook of Dialectology; Wiley-Blackwell: Hoboken, NJ, USA, 2017. [Google Scholar] [CrossRef]
- Alharbi, B.; Alamro, H.; Alshehri, M.; Khayyat, Z.; Kalkatawi, M.; Jaber, I.I.; Zhang, X. ASAD: A Twitter-based Benchmark Arabic Sentiment Analysis Dataset. arXiv 2020, arXiv:2011.00578. [Google Scholar] [CrossRef]
- Kwaik, K.A.; Chatzikyriakidis, S.; Dobnik, S.; Saad, M.; Johansson, R. An Arabic Tweets Sentiment Analysis Dataset (ATSAD) using Distant Supervision and Self Training. In Proceedings of the 4th Workshop on Open-Source Arabic Corpora and Processing Tools, with a Shared Task on Offensive Language Detection, Marseille, France, 12 May 2020; pp. 1–8. [Google Scholar]
- Mdhaffar, S.; Bougares, F.; Estève, Y.; Hadrich-Belguith, L. Sentiment Analysis of Tunisian Dialects: Linguistic Ressources and Experiments. In Proceedings of the Third Arabic Natural Language Processing Workshop (WANLP), Valence, Spain, 3 April 2017; pp. 55–61. [Google Scholar] [CrossRef]
- Rahab, H.; Zitouni, A.; Djoudi, M. SIAAC: Sentiment Polarity Identification on Arabic Algerian Newspaper Comments. In Applied Computational Intelligence and Mathematical Methods; Springer International Publishing: Cham, Switzerland, 2017; pp. 139–149. [Google Scholar] [CrossRef]
- Ziani, A.; Azizi, N.; Zenakhra, D.; Cheriguene, S.; Aldwairi, M. Combining RSS-SVM with genetic algorithm for Arabic opinions analysis. Int. J. Intell. Syst. Technol. Appl. 2019, 18, 152. [Google Scholar] [CrossRef]
- Mataoui, M.; Zelmati, O.; Boumechache, M. A proposed lexicon-based sentiment analysis approach for the vernacular Algerian Arabic. Res. Comput. Sci. 2016, 110, 55–70. [Google Scholar] [CrossRef]
- Moudjari, L.; Akli-Astouati, K.; Benamara, F. An Algerian Corpus and an Annotation Platform for Opinion and Emotion Analysis. In Proceedings of the Twelfth Language Resources and Evaluation Conference, Marseille, France, 19 May 2020; pp. 1202–1210. [Google Scholar]
- Guellil, I.; Adeel, A.; Azouaou, F.; Hussain, A. SentiALG: Automated Corpus Annotation for Algerian Sentiment Analysis. In Advances in Brain Inspired Cognitive Systems; Springer International Publishing: Cham, Switzerland, 2018; pp. 557–567. [Google Scholar] [CrossRef]
- Ahmed, H.; Traore, I.; Saad, S. Detection of Online Fake News Using N-Gram Analysis and Machine Learning Techniques. In Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2017; pp. 127–138. [Google Scholar] [CrossRef]
- Symeonidis, S.; Effrosynidis, D.; Arampatzis, A. A comparative evaluation of pre-processing techniques and their interactions for twitter sentiment analysis. Expert Syst. Appl. 2018, 110, 298–310. [Google Scholar] [CrossRef]
- Grandini, M.; Bagli, E.; Visani, G. Metrics for Multi-Class Classification: An Overview. arXiv 2020, arXiv:2008.05756. [Google Scholar] [CrossRef]
- Safaya, A.; Abdullatif, M.; Yuret, D. KUISAIL at SemEval-2020 Task 12: BERT-CNN for Offensive Speech Identification in Social Media. arXiv 2020, arXiv:2007.13184. [Google Scholar] [CrossRef]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv 2016, arXiv:1609.08144. [Google Scholar] [CrossRef]






| Dataset | Size | Classes | Annotation Approach | Dialect |
|---|---|---|---|---|
| ASAD [23] | 100,000 | Negative, Neural and Positive | Manual | Multiple |
| ATSAD [24] | 36,000 | Negative and Positive | From Emojis | Multiple |
| TSAC [25] | 10,000 | Negative and Positive | Manual | Tunisian |
| SIACC [26] | 92 | Negative and Positive | Manual | Algerian |
| [27] | 1000 | / | Manual | Algerian |
| [28] | 5039 | Negative and Positive | Manual | Algerian |
| TWIFIL [29] | 9000 | Negative, Neutral and Positive | Manual | Algerian |
| [20] | 21,885 | Negative-related, Unrelated and Positive | Manual | Algerian |
| SentiALG [30] | 8000 | Negative and Positive | From sentiment lexicons | Algerian |
| Our dataset | 45,000 | Negative, Neutral and Positive | Manual | Algerian |
| Training | Validation | Test | All | |||||
|---|---|---|---|---|---|---|---|---|
| No. Samples | (%) | No. Samples | (%) | No. Samples | (%) | No. Samples | (%) | |
| Negative | 11,175 | 35.5 | 1608 | 35.7 | 3174 | 35.3 | 15,957 | 35.5 |
| Neutral | 7040 | 22.3 | 1030 | 22.9 | 2023 | 22.5 | 10,093 | 22.4 |
| Positive | 13,285 | 42.2 | 1862 | 41.4 | 3803 | 42.2 | 18,950 | 42.1 |
| Total | 31,500 | 100 | 4500 | 100 | 9000 | 100 | 45,000 | 100 |
| Total Samples | Percentage (%) | |
|---|---|---|
| Pure Arabic letters | 38,108 | 84.684 |
| Pure Latin letters | 5699 | 12.664 |
| Mixed | 1193 | 2.652 |
| Total | 45,000 | 100.0 |
| Count | Negative Class | Count | Neutral Class | Count | Positive Class | Count | Entire Dataset |
|---|---|---|---|---|---|---|---|
| 3469 | الله (God) | 1506 | الله (God) | 8843 | الله (God) | 13818 | الله (God) |
| 980 | ربي (My God) | 505 | ربي (My God) | 4264 | ربي (My God) | 5749 | ربي (My God) |
| 962 | الجزائر (Algeria) | 361 | الجزائر (Algeria) | 1024 | الجزائر (Algeria) | 2347 | الجزائر (Algeria) |
| 945 | الشعب (The people) | 209 | خويا (My brother) | 789 | يبارك (bless) | 1294 | الشعب (the people) |
| 455 | فرنسا (France) | 172 | الشعب (The people) | 751 | شكرا (Thank you) | 973 | خويا (My brother) |
| 353 | الناس (the people) | 169 | اللهم (Oh God) | 695 | خويا (My brother) | 897 | اللهم (Oh God) |
| 346 | الوكيل (The agent) | 150 | استاذ (professor) | 676 | يارب (Oh, Lord) | 874 | يارب (Oh, Lord) |
| 314 | تبون (Tebboune) | 124 | سلام (peace) | 615 | اللهم (Oh God) | 871 | شكرا (Thank you) |
| 301 | الجزائري (The Algerian) | 111 | محمد (Mohammed) | 591 | يحفظك (God keep you safe) | 836 | يبارك (bless) |
| 299 | البلاد (The country) | 109 | فضلك (Please) | 583 | الصحة (The health) | 656 | الصحة (The health) |
| Negative Class | Neutral Class | Positive Class | Entire Dataset |
|---|---|---|---|
| ونعم وكيل (The best disposer of affairs) | شاء الله (If God wants) | شاء الله (God willing) | حمد لله (Thanks God) |
| شعب جزائري (Algerian people) | حمد لله (Thanks God) | حمد لله (Thanks God) | شاء الله (God willing) |
| حسبنا الله (God suffices us) | شعب جزائري (Algerian people) | تحيا جزائر (Long live Algeria) | يعطيك صحة (God gives you health) |
| مزبلة تاريخ (History dustbin) | يارب عالمين (Lord of the Worlds) | بارك الله (God bless) | ونعم وكيل (The best disposer of affairs) |
| جزائر جديدة (New Algeria) | تحيا جزائر (Long live Algeria) | يارب عالمين (Lord of the Worlds) | شعب جزائري (Algerian people) |
| حمد لله (Thanks God) | لغة عربية (Arabic Language) | ربي يحفظك (God protect you) | تحيا جزائر (Long live Algeria) |
| وكيل فيكم (May God entrust you) | نجيب باك (I will get the baccalaureate) | يعطيك صحة (God gives you health) | يارب عالمين (Lord of the Worlds) |
| Model Version | No. of Parameters | Training Time | F1-Score | Accuracy |
|---|---|---|---|---|
| LSTM | ~4 M | 3 min | 0.7399 | 0.7445 |
| Bi-LSTM | ~4.3 M | 6 min 35 s | 0.7380 | 0.7437 |
| BERT Base | ~109.5 M | 33 min 20 s | 0.6979 | 0.7500 |
| BERT Large | ~335.1 M | 1 h 50 min | 0.6976 | 0.7484 |
| BERT Arabic Mini | ~11.6 M | 2 min 40 s | 0.7057 | 0.7527 |
| BERT Arabic Medium | ~42.1 M | 11 min 25 s | 0.7521 | 0.7860 |
| BERT Arabic Base | ~110.6 M | 34 min 19 s | 0.7688 | 0.8002 |
| BERT Arabic Large | ~336.7 M | 1 h 53 min | 0.7838 | 0.8174 |
| Sequence Length | Training Time | F1-Score | Accuracy |
|---|---|---|---|
| 140 | 1 h 40 min | 0.7744 | 0.8056 |
| 160 | 1 h 46 min | 0.7809 | 0.8114 |
| 180 | 1 h 53 min | 0.7838 | 0.8174 |
| 200 | 2 h | 0.7829 | 0.8143 |
| 220 | 2 h 8 min | 0.7799 | 0.8084 |
| Task IDs | F1-Score | Accuracy |
|---|---|---|
| 1, 2, 3, 5, 7 | 0.7804 | 0.8100 |
| 2, 3, 5 | 0.7803 | 0.8114 |
| 2, 3, 5, 11 | 0.7838 | 0.8174 |
| 1, 2, 3, 5, 11 | 0.7816 | 0.8120 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Benmounah, Z.; Boulesnane, A.; Fadheli, A.; Khial, M. Sentiment Analysis on Algerian Dialect with Transformers. Appl. Sci. 2023, 13, 11157. https://doi.org/10.3390/app132011157
Benmounah Z, Boulesnane A, Fadheli A, Khial M. Sentiment Analysis on Algerian Dialect with Transformers. Applied Sciences. 2023; 13(20):11157. https://doi.org/10.3390/app132011157
Chicago/Turabian StyleBenmounah, Zakaria, Abdennour Boulesnane, Abdeladim Fadheli, and Mustapha Khial. 2023. "Sentiment Analysis on Algerian Dialect with Transformers" Applied Sciences 13, no. 20: 11157. https://doi.org/10.3390/app132011157