
CQDFormer: Cyclic Quasi-Dynamic Transformers for Hourly Origin-Destination Estimation



Abstract
:Featured Application
Abstract
1. Introduction
- We find that the self-attention mechanism based on the quasi-dynamic assumption can estimate OD matrices accurately, and based on this, we propose the CQDFormer.
- We design a cyclic attention mechanism that suppresses unrealistic OD estimation due to distribution shift and prevents the degradation of model performance.
- We carry out experiments on a realistic road network to illustrate the validity of the proposed OD estimation method and model, and the results show that the proposed model outperforms all comparison models in the relevant metrics.
2. Literature Review
2.1. Data Sources for OD Estimation
2.2. Constrained Optimization
2.3. Iterative State Estimations
2.4. Gradient-Based Estimations
3. Problem Statement
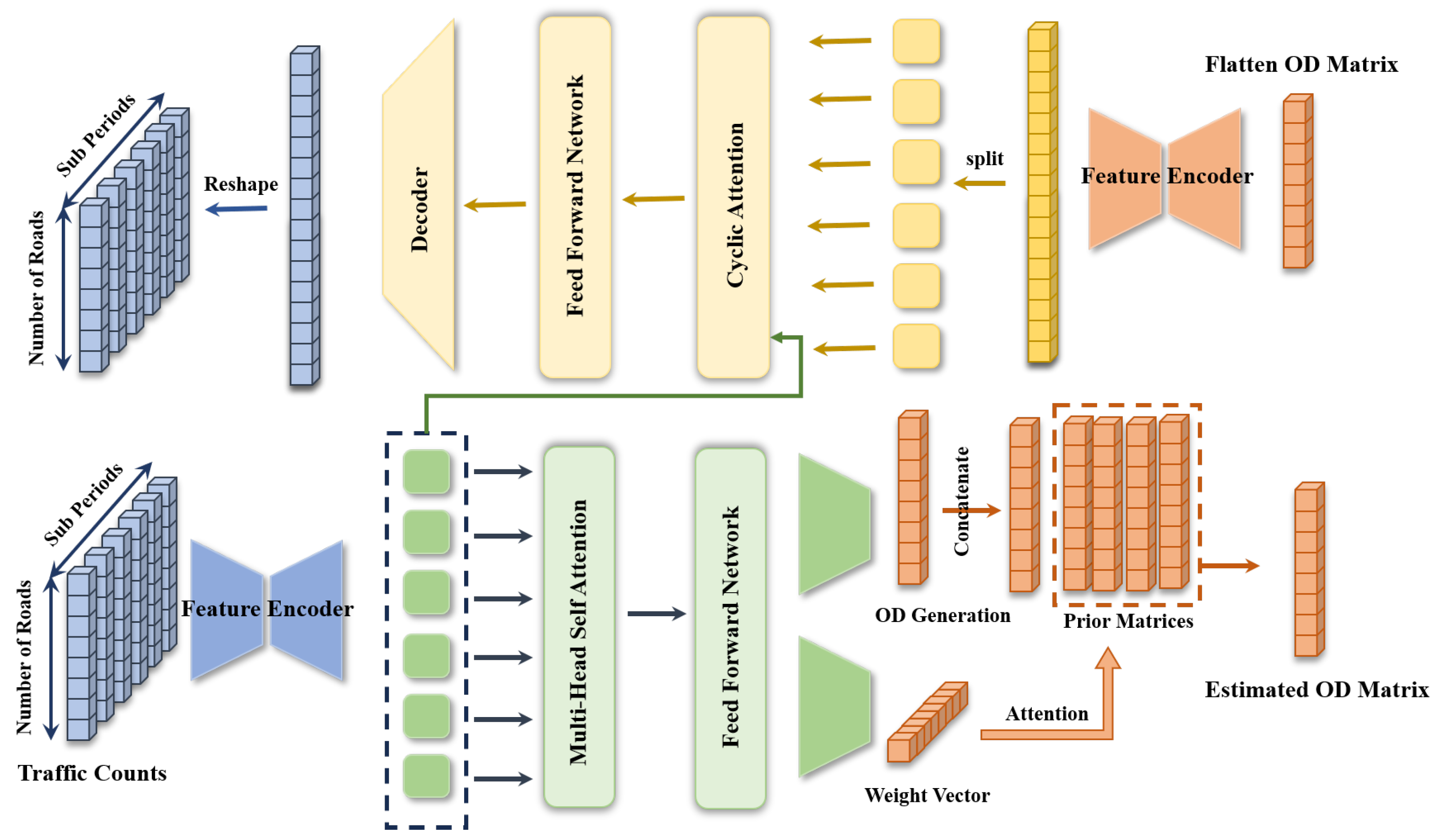
4. Methodology

- Fixed Path Selection Pattern. For some familiar travel situations, travelers will tend to choose fixed travel paths. In this path selection path, the probability that a traveler chooses each path is related to the road conditions the path passes, the urban functional areas along the road, etc., and is fixed in each round of simulation.
- N Shortest Path Selection Pattern [47]. Travelers dynamically adjust their path selection according to the traffic states, but subject to information delays, personal preferences, and other factors, ultimately travelers will choose one of the N paths with the shortest travel time, and the probability of choosing each path is related to the level of congestion perceived by the travelers.
- Roaming Path Selection Pattern. This path selection pattern is used to fill in the travel path selection pattern that cannot be described by the two above, including trips without specific purposes or travelers with multiple travel purposes, and the paths in this pattern are generated from all the candidate paths between the origin and the destination.
5. Experiments
5.1. Experiment Configuration
5.2. Evaluation Metrics
- Root Mean Square Error (RMSE)
- Mean Absolute Error (MAE)
- Mean Absolute Perceptage Error (MAPE)
- Coefficient of Determination ()
5.3. Comparison Model
- Cluster-SPSA(c-SPSA), an effective way to cope with multiple magnitudes of OD flows. Referring to [43], the number of clustering kernels is set to 3.
- Extended Kalman Filter (EKF), a non-linear extension of Kalman Filter, shows promising performance in arterial network [17].
- Multi-Layer Perceptron (MLP), a widely used neural network block, was applied to the OD estimation in [19,48]. Here, we use the encoder–decoder framework including six linear transformation layers with dimensions of , respectively, and the LeakyReLU is used as the activation function between layers. The encoder–decoder framework can realize effective feature compression and extraction through dimensionality reduction.
- Cycle Generative Adversarial Networks (CycleGAN), one of the first works to introduce the concept of cyclic consistency, with notable success in the field of stylized image generation [51]. The proposed model is inspired by and incorporates the concept of cyclic consistency, thus we use this model as a comparison model.
5.4. Results and Discussion
5.4.1. Performance Evaluation
5.4.2. Results of Traffic Assignment Simulation
5.4.3. Computational Cost
5.4.4. Result Analysis
5.4.5. Convergence
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ou, J.; Lu, J.; Xia, J.; An, C.; Lu, Z. Learn, assign, and search: Real-time estimation of dynamic origin-destination flows using machine learning algorithms. IEEE Access 2019, 7, 26967–26983. [Google Scholar] [CrossRef]
- Sun, W.; Shao, H.; Shen, L.; Wu, T.; Lam, W.H.; Yao, B.; Yu, B. Bi-objective traffic count location model for mean and covariance of origin–destination estimation. Expert Syst. Appl. 2021, 170, 114554. [Google Scholar] [CrossRef]
- Cao, Y.; Tang, K.; Sun, J.; Ji, Y. Day-to-day dynamic origin–destination flow estimation using connected vehicle trajectories and automatic vehicle identification data. Transp. Res. Part C Emerg. Technol. 2021, 129, 103241. [Google Scholar] [CrossRef]
- Guo, J.; Liu, Y.; Li, X.; Huang, W.; Cao, J.; Wei, Y. Enhanced least square based dynamic OD matrix estimation using Radio Frequency Identification data. Math. Comput. Simul. 2019, 155, 27–40. [Google Scholar] [CrossRef]
- Tang, K.; Cao, Y.; Chen, C.; Yao, J.; Tan, C.; Sun, J. Dynamic origin-destination flow estimation using automatic vehicle identification data: A 3D convolutional neural network approach. Comput.-Aided Civ. Infrastruct. Eng. 2021, 36, 30–46. [Google Scholar] [CrossRef]
- Montero, L.; Ros-Roca, X.; Herranz, R.; Barceló, J. Fusing mobile phone data with other data sources to generate input OD matrices for transport models. Transp. Res. Procedia 2019, 37, 417–424. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, S.; Lian, H. A route-planning method for long-distance commuter express bus service based on OD estimation from mobile phone location data: The case of the Changping Corridor in Beijing. Public Transp. 2021, 13, 101–125. [Google Scholar] [CrossRef]
- Yang, X.; Lu, Y.; Hao, W. Origin-destination estimation using probe vehicle trajectory and link counts. J. Adv. Transp. 2017, 2017, 4341532. [Google Scholar] [CrossRef]
- Nigro, M.; Cipriani, E.; del Giudice, A. Exploiting floating car data for time-dependent Origin–Destination matrices estimation. J. Intell. Transp. Syst. 2018, 22, 159–174. [Google Scholar] [CrossRef]
- Mitra, A.; Attanasi, A.; Meschini, L.; Gentile, G. Methodology for O-D matrix estimation using the revealed paths of floating car data on large-scale networks. IET Intell. Transp. Syst. 2020, 14, 1704–1711. [Google Scholar] [CrossRef]
- Sun, L.; Axhausen, K.W. Understanding urban mobility patterns with a probabilistic tensor factorization framework. Transp. Res. Part B Methodol. 2016, 91, 511–524. [Google Scholar] [CrossRef]
- Wu, X.; Guo, J.; Xian, K.; Zhou, X. Hierarchical travel demand estimation using multiple data sources: A forward and backward propagation algorithmic framework on a layered computational graph. Transp. Res. Part C Emerg. Technol. 2018, 96, 321–346. [Google Scholar] [CrossRef]
- Behara, K.N.; Bhaskar, A.; Chung, E. A novel methodology to assimilate sub-path flows in bi-level OD matrix estimation process. IEEE Trans. Intell. Transp. Syst. 2020, 22, 6931–6941. [Google Scholar] [CrossRef]
- Cipriani, E.; Gemma, A.; Mannini, L.; Carrese, S.; Crisalli, U. Traffic demand estimation using path information from Bluetooth data. Transp. Res. Part C Emerg. Technol. 2021, 133, 103443. [Google Scholar] [CrossRef]
- Cascetta, E.; Papola, A.; Marzano, V.; Simonelli, F.; Vitiello, I. Quasi-dynamic estimation of o–d flows from traffic counts: Formulation, statistical validation and performance analysis on real data. Transp. Res. Part B Methodol. 2013, 55, 171–187. [Google Scholar] [CrossRef]
- Bauer, D.; Richter, G.; Asamer, J.; Heilmann, B.; Lenz, G.; Kölbl, R. Quasi-dynamic estimation of OD flows from traffic counts without prior OD matrix. IEEE Trans. Intell. Transp. Syst. 2017, 19, 2025–2034. [Google Scholar] [CrossRef]
- Marzano, V.; Papola, A.; Simonelli, F.; Papageorgiou, M. A Kalman filter for quasi-dynamic od flow estimation/updating. IEEE Trans. Intell. Transp. Syst. 2018, 19, 3604–3612. [Google Scholar] [CrossRef]
- Ma, W.; Qian, Z.S. Estimating multi-year 24/7 origin-destination demand using high-granular multi-source traffic data. Transp. Res. Part C Emerg. Technol. 2018, 96, 96–121. [Google Scholar] [CrossRef]
- Lorenzo, M.; Matteo, M. OD matrices network estimation from link counts by neural networks. J. Transp. Syst. Eng. Inf. Technol. 2013, 13, 84–92. [Google Scholar] [CrossRef]
- Krishnakumari, P.; van Lint, H.; Djukic, T.; Cats, O. A data driven method for OD matrix estimation. Transp. Res. Procedia 2019, 38, 139–159. [Google Scholar] [CrossRef]
- Van Zuylen, H. A method to estimate a trip matrix from traffic volume counts. In Proceedings of the PTRC Summer Annual Meeting, Coventry, UK, 11 July 1978. [Google Scholar]
- Willumsen, L. Estimating the most likely OD matrix from traffic counts. In Proceedings of the 11th Annual Conference of Universities Transport Studies Group, University of Southampton, Southampton, UK, January 1979. [Google Scholar]
- Zhou, X.; Mahmassani, H.S. Dynamic origin-destination demand estimation using automatic vehicle identification data. IEEE Trans. Intell. Transp. Syst. 2006, 7, 105–114. [Google Scholar] [CrossRef]
- Rao, W.; Wu, Y.J.; Xia, J.; Ou, J.; Kluger, R. Origin-destination pattern estimation based on trajectory reconstruction using automatic license plate recognition data. Transp. Res. Part C Emerg. Technol. 2018, 95, 29–46. [Google Scholar] [CrossRef]
- Ma, J.; Li, H.; Yuan, F.; Bauer, T. Deriving operational origin-destination matrices from large scale mobile phone data. Int. J. Transp. Sci. Technol. 2013, 2, 183–204. [Google Scholar] [CrossRef]
- Iqbal, M.S.; Choudhury, C.F.; Wang, P.; González, M.C. Development of origin–destination matrices using mobile phone call data. Transp. Res. Part C Emerg. Technol. 2014, 40, 63–74. [Google Scholar] [CrossRef]
- Cao, P.; Miwa, T.; Yamamoto, T.; Morikawa, T. Bilevel generalized least squares estimation of dynamic origin–destination matrix for urban network with probe vehicle data. Transp. Res. Rec. 2013, 2333, 66–73. [Google Scholar] [CrossRef]
- Munizaga, M.A.; Palma, C. Estimation of a disaggregate multimodal public transport Origin–Destination matrix from passive smartcard data from Santiago, Chile. Transp. Res. Part C Emerg. Technol. 2012, 24, 9–18. [Google Scholar] [CrossRef]
- Ge, Q.; Fukuda, D. Updating origin–destination matrices with aggregated data of GPS traces. Transp. Res. Part C Emerg. Technol. 2016, 69, 291–312. [Google Scholar] [CrossRef]
- Phithakkitnukoon, S.; Horanont, T.; Lorenzo, G.D.; Shibasaki, R.; Ratti, C. Activity-aware map: Identifying human daily activity pattern using mobile phone data. In Proceedings of the International Workshop on Human Behavior Understanding, Istanbul, Turkey, 22 August 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 14–25. [Google Scholar]
- Van Zuylen, H.J.; Willumsen, L.G. The most likely trip matrix estimated from traffic counts. Transp. Res. Part B Methodol. 1980, 14, 281–293. [Google Scholar] [CrossRef]
- Ben-Akiva, M.; Macke, P.P.; Hsu, P.S. Alternative Methods to Estimate Route-Level Trip Tables and Expand on-Board Surveys; Number 1037; National Academies: Washington, DC, USA, 1985. [Google Scholar]
- Aerde, M.V.; Rakha, H.; Paramahamsan, H. Estimation of origin-destination matrices: Relationship between practical and theoretical considerations. Transp. Res. Rec. 2003, 1831, 122–130. [Google Scholar] [CrossRef]
- Cascetta, E. Estimation of trip matrices from traffic counts and survey data: A generalized least squares estimator. Transp. Res. Part B Methodol. 1984, 18, 289–299. [Google Scholar] [CrossRef]
- Bell, M.G. The estimation of origin-destination matrices by constrained generalised least squares. Transp. Res. Part B Methodol. 1991, 25, 13–22. [Google Scholar] [CrossRef]
- Xie, C.; Kockelman, K.M.; Waller, S.T. A maximum entropy-least squares estimator for elastic origin-destination trip matrix estimation. Procedia-Soc. Behav. Sci. 2011, 17, 189–212. [Google Scholar] [CrossRef]
- Ashok, K. Dynamic origin-destination matrix estimation and prediction for real-time traffic management system. In Proceedings of the 12th International Symposium on Transportation and Traffic Theory, Berkeley, CA, USA, 21–23 July 1993; pp. 465–484. [Google Scholar]
- Antoniou, C.; Ben-Akiva, M.; Koutsopoulos, H.N. Nonlinear Kalman filtering algorithms for on-line calibration of dynamic traffic assignment models. IEEE Trans. Intell. Transp. Syst. 2007, 8, 661–670. [Google Scholar] [CrossRef]
- Carrese, S.; Cipriani, E.; Mannini, L.; Nigro, M. Dynamic demand estimation and prediction for traffic urban networks adopting new data sources. Transp. Res. Part C Emerg. Technol. 2017, 81, 83–98. [Google Scholar] [CrossRef]
- Balakrishna, R.; Koutsopoulos, H.N. Incorporating within-day transitions in simultaneous offline estimation of dynamic origin-destination flows without assignment matrices. Transp. Res. Rec. 2008, 2085, 31–38. [Google Scholar] [CrossRef]
- Cipriani, E.; Florian, M.; Mahut, M.; Nigro, M. A gradient approximation approach for adjusting temporal origin–destination matrices. Transp. Res. Part C Emerg. Technol. 2011, 19, 270–282. [Google Scholar] [CrossRef]
- Balakrishna, R.; Ben-Akiva, M.; Koutsopoulos, H.N. Offline calibration of dynamic traffic assignment: Simultaneous demand-and-supply estimation. Transp. Res. Rec. 2007, 2003, 50–58. [Google Scholar] [CrossRef]
- Tympakianaki, A.; Koutsopoulos, H.N.; Jenelius, E. c-SPSA: Cluster-wise simultaneous perturbation stochastic approximation algorithm and its application to dynamic origin–destination matrix estimation. Transp. Res. Part C Emerg. Technol. 2015, 55, 231–245. [Google Scholar] [CrossRef]
- Tympakianaki, A.; Koutsopoulos, H.N.; Jenelius, E. Robust SPSA algorithms for dynamic OD matrix estimation. Procedia Comput. Sci. 2018, 130, 57–64. [Google Scholar] [CrossRef]
- Ros-Roca, X.; Montero, L.; Barceló, J.; Nökel, K. Dynamic origin-destination matrix estimation with ICT traffic measurements using SPSA. In Proceedings of the 2021 7th International Conference on Models and Technologies for Intelligent Transportation Systems (MT-ITS), Heraklion, Greece, 16–17 June 2021; IEEE: New York, NY, USA, 2021; pp. 1–8. [Google Scholar]
- Gong, Z. Estimating the urban OD matrix: A neural network approach. Eur. J. Oper. Res. 1998, 106, 108–115. [Google Scholar] [CrossRef]
- Krishnakumari, P.; Van Lint, H.; Djukic, T.; Cats, O. A data driven method for OD matrix estimation. Transp. Res. Part C Emerg. Technol. 2020, 113, 38–56. [Google Scholar] [CrossRef]
- Afandizadeh Zargari, S.; Memarnejad, A.; Mirzahossein, H. Hourly Origin–Destination Matrix Estimation Using Intelligent Transportation Systems Data and Deep Learning. Sensors 2021, 21, 7080. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 5998–6008. [Google Scholar]
- Tang, J.; Zhang, S.; Chen, X.; Liu, F.; Zou, Y. Taxi trips distribution modeling based on Entropy-Maximizing theory: A case study in Harbin city—China. Phys. A Stat. Mech. Its Appl. 2018, 493, 430–443. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232.
- Djukic, T.; Van Lint, J.; Hoogendoorn, S. Application of principal component analysis to predict dynamic origin–destination matrices. Transp. Res. Rec. 2012, 2283, 81–89. [Google Scholar] [CrossRef]
- Prakash, A.A.; Seshadri, R.; Antoniou, C.; Pereira, F.C.; Ben-Akiva, M. Improving scalability of generic online calibration for real-time dynamic traffic assignment systems. Transp. Res. Rec. 2018, 2672, 79–92. [Google Scholar] [CrossRef]
- Qurashi, M.; Ma, T.; Chaniotakis, E.; Antoniou, C. PC–SPSA: Employing dimensionality reduction to limit SPSA search noise in DTA model calibration. IEEE Trans. Intell. Transp. Syst. 2019, 21, 1635–1645. [Google Scholar] [CrossRef]
- Qurashi, M.; Lu, Q.L.; Cantelmo, G.; Antoniou, C. Dynamic demand estimation on large scale networks using Principal Component Analysis: The case of non-existent or irrelevant historical estimates. Transp. Res. Part C Emerg. Technol. 2022, 136, 103504. [Google Scholar] [CrossRef]
- Fu, H.; Lam, W.H.; Shao, H.; Kattan, L.; Salari, M. Optimization of multi-type traffic sensor locations for estimation of multi-period origin-destination demands with covariance effects. Transp. Res. Part E Logist. Transp. Rev. 2022, 157, 102555. [Google Scholar] [CrossRef]
- Djukic, T. Dynamic OD Demand Estimation and Prediction for Dynamic Traffic Management. 2014. Available online: https://www.researchgate.net/publication/269575189_Dynamic_OD_Demand_Estimation_and_Prediction_for_Dynamic_Traffic_Management (accessed on 21 July 2023).
- Behara, K.N.; Bhaskar, A.; Chung, E. A novel approach for the structural comparison of origin-destination matrices: Levenshtein distance. Transp. Res. Part C Emerg. Technol. 2020, 111, 513–530. [Google Scholar] [CrossRef]
- Katranji, M.; Kraiem, S.; Moalic, L.; Sanmarty, G.; Khodabandelou, G.; Caminada, A.; Hadj Selem, F. Deep multi-task learning for individuals origin–destination matrices estimation from census data. Data Min. Knowl. Discov. 2020, 34, 201–230. [Google Scholar] [CrossRef]
- Ma, W.; Pi, X.; Qian, S. Estimating multi-class dynamic origin-destination demand through a forward-backward algorithm on computational graphs. Transp. Res. Part C Emerg. Technol. 2020, 119, 102747. [Google Scholar] [CrossRef]
- Lu, C.C.; Zhou, X.; Zhang, K. Dynamic origin–destination demand flow estimation under congested traffic conditions. Transp. Res. Part C Emerg. Technol. 2013, 34, 16–37. [Google Scholar] [CrossRef]
- Behara, K.N.; Bhaskar, A. Can partial structural information of travel demand improve the quality of OD matrix estimates? In Proceedings of the Australasian Transport Research Forum, Brisbane, Australia, 8–10 December 2021. [Google Scholar]
- Van Hinsbergen, C.P.; Schreiter, T.; Zuurbier, F.S.; Van Lint, J.; Van Zuylen, H.J. Localized extended kalman filter for scalable real-time traffic state estimation. IEEE Trans. Intell. Transp. Syst. 2011, 13, 385–394. [Google Scholar] [CrossRef]
- Barceló Bugeda, J.; Montero Mercadé, L.; Bullejos, M.; Serch, O.; Carmona Bautista, C. A kalman filter approach for the estimation of time dependent od matrices exploiting bluetooth traffic data collection. In Proceedings of the TRB 91st Annual meeting compendium of papers DVD, Washington, DC, USA, 22–26 January 2012; pp. 1–16. [Google Scholar]
- Lu, L. W-SPSA: An Efficient Stochastic Approximation Algorithm for the Off-Line Calibration of Dynamic Traffic Assignment Models. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2013. [Google Scholar]
- Antoniou, C.; Azevedo, C.L.; Lu, L.; Pereira, F.; Ben-Akiva, M. W–SPSA in practice: Approximation of weight matrices and calibration of traffic simulation models. Transp. Res. Procedia 2015, 7, 233–253. [Google Scholar] [CrossRef]
 are variables obtained from the real traffic scenario,
are variables obtained from the real traffic scenario,  are variables generated in the simulation process, and
are variables generated in the simulation process, and  refers to the processing operations.
are variables obtained from the real traffic scenario, are variables generated in the simulation process, and refers to the processing operations.
refers to the processing operations.
are variables obtained from the real traffic scenario, are variables generated in the simulation process, and refers to the processing operations.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categories | Parameters | Values |
|---|---|---|
| Simulation for | Epoch Number for Realistic Data | 600 epoch |
| Realistic Environment | Simulation Duration for Realistic Data | 17.3 h/epoch |
| Path Selection Ratio | (0.35, 0.53, 0.12) | |
| Simulation for | Epoch Number for Paired Data Generation | 4000 epoch |
| Data Generation | Simulation Duration for Paired Data Generation | 12 h/epoch |
| Path Selection Ratio | (0.4, 0.5, 0.1) | |
| Number of Prior OD Matrices | 20 | |
| Model Parameters | Epoch Number for Training | 100 |
| Batch Size | 16 | |
| Sequence Length of Attention | 12 | |
| Head Number of Attention | 3 | |
| Dimensions of feature space | 150 | |
| Dimensions of Query, Key, Value Matrices | 50 | |
| Hidden Dimensions for forward Networks | 256 | |
| Hidden Dimensions for backward Networks | 1024 | |
| Optimizer | Adam | |
| Learning Rate | 0.0001 | |
| Decay of Learning Rate | 0.2/10 epochs |
| c-SPSA | EKF | MLP | CycleGAN | Proposed | |
|---|---|---|---|---|---|
| RMSE | 9.0643 | 22.2006 | 7.8831 | 11.1776 | 4.1796 |
| MAE | 6.9656 | 13.5181 | 5.5624 | 6.9010 | 3.0373 |
| MAPE | 24.78% | 59.44% | 14.38% | 18.99% | 10.10% |
| 0.5778 | -0.0341 | 0.6536 | 0.4793 | 0.8053 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, G.; Wu, J.; He, Y.; Li, D. CQDFormer: Cyclic Quasi-Dynamic Transformers for Hourly Origin-Destination Estimation. Appl. Sci. 2023, 13, 11257. https://doi.org/10.3390/app132011257
Li G, Wu J, He Y, Li D. CQDFormer: Cyclic Quasi-Dynamic Transformers for Hourly Origin-Destination Estimation. Applied Sciences. 2023; 13(20):11257. https://doi.org/10.3390/app132011257
Chicago/Turabian StyleLi, Guanzhou, Jianping Wu, Yujing He, and Duowei Li. 2023. "CQDFormer: Cyclic Quasi-Dynamic Transformers for Hourly Origin-Destination Estimation" Applied Sciences 13, no. 20: 11257. https://doi.org/10.3390/app132011257
APA StyleLi, G., Wu, J., He, Y., & Li, D. (2023). CQDFormer: Cyclic Quasi-Dynamic Transformers for Hourly Origin-Destination Estimation. Applied Sciences, 13(20), 11257. https://doi.org/10.3390/app132011257