
Adaptive Deep Clustering Network for Retinal Blood Vessel and Foveal Avascular Zone Segmentation

Abstract
:1. Introduction
- (1)
- Introducing the ASDC approach for the simultaneous segmentation of RV and FAZ biomarkers in an automatic and scalable manner, thus reducing the computational cost and time required for OCTA image analysis. This approach can potentially aid in early retinal disease investigation by providing more accurate and efficient segmentation.
- (2)
- Conducting a comparative analysis of both unsupervised and supervised learning methods for OCTA image segmentation, providing insights into the strengths and weaknesses of different approaches, and helping to inform future research in this area.
- (3)
- Demonstrating a thorough understanding of the current state-of-the-art in OCTA image segmentation research and introducing a scalable approach for processing OCTA data. This research contributes to developing more efficient and accurate methods for analyzing OCTA images, which can aid in diagnosing and managing retinal diseases.
2. Related Work
3. Method
3.1. K-Means Clustering and Image Processing (Unsupervised Learning)
- (1)
- Convert the given image into a grayscale image and smooth the image with a 3 × 3 kernel Gaussian blur [33] filter. Gaussian blur reduces image noise by blurring it with a Gaussian function. It is a non-uniform low-pass filter that lowers image noise and noiseless details. Reshape the image array (3D) as a vector (1D) to apply to the cluster. The effectiveness of a Gaussian blur filter is to enhance vascular contrast and connectivity, which enhances the quality of the OCTA angiograms [34].
- (2)
- We convert reshaping values to a floating point because each feature should be in a single column for K-means. Specify K-means convergence criteria, the point at which the algorithm stops iterating. Once the specified requirements are met, the algorithm terminates. The convergence criteria used in the segmentation function specifies that the K-means clustering algorithm should stop when either the desired accuracy or the maximum number of iterations is reached, whichever comes first. The maximum number of iterations is set to 10, and the desired accuracy is set to 1.0. This means that the algorithm will stop after 10 iterations or earlier if the desired accuracy is achieved. The convergence criterion is an important parameter in the K-means algorithm as it determines when the algorithm has converged to a stable solution and can be used to optimize the clustering process.
- (3)
- Apply the K-means algorithm with K = 4 to divide the OCTA en face image into four clusters. After performing K-means clustering, we extract the compactness, labels, and centers to identify the regions. Finally, it returns a list of labels corresponding to each cluster and their centers (in this case, where they are located on the original image).
- (4)
- We access the labels and convert the label array to a clustered image; every pixel represents its clustering label. Therefore, we can establish a list of the images in our clustered image, calculate the minimum and maximum values for each image, then create an empty 3-dimensional array to record each pixel’s color. Next, it loops through each image’s pixels to assign color values.
- (5)
- Specifically, the maximum pixel values are converted to 255, and the minimum pixel values are converted to 100. Other two-pixel values represent 0. Then, a smooth function is applied to remove noisy dots in the image. In summary, setting K = 4 in Step (5) allows the segmentation function to accurately capture the boundary between the foreground (RV and FAZ) and background, while considering only 3 different pixel values in the resulting image ensures that the RV and FAZ objects are not lost and that the segmentation is robust to any additional clusters that may have been created by the K-means clustering algorithm.
- (6)
- Smooth function: The goal of this step is to remove noise in the image by averaging pixel values in a small window around each pixel and returning the image with a smooth gradient. By cycling through all pixels in the original image, check if each pixel’s current value differs from the average of all values. If so, that pixel becomes black (0). After each pixel is processed, we get a smooth gradient image. Then we check how much a pixel differs from its average value over input pixels, which is set to 0.8. This ensures that no single pixel has more than 80% of its total area covered by black pixels, which would result in a very dark image, or only white pixels, which would result in an extremely bright image. Figure 2 shows the proposed K- means implementation.
3.2. Encoder–Decoder Network Architecture (Supervised Learning)
3.3. Encoder–Decoder Architecture plus K-Means Clustering OCTA Segmentation Framework
- Phase 1. In this phase, the target image is separated into RV and FAZ components as shown in Figure 3, and the test image is then fed into phase 2. In the process of preparing the data for training, we extract the regions of interest for the RV and FAZ classes by identifying the corresponding pixel values of 255 and 100, respectively, based on the histogram of the ground truth data.
- Phase 2. This phase involves feeding Model 2 (the FAZ green part), the test input image, and the FAZ part from the previous phase to train the network and predict the FAZ part and RV, respectively. A concatenation operator is used to combine the two images after predicting the two images independently to produce the final segmented output. We present the encoder-decoder architecture for OCTA segmentation in Figure 4. This architecture is then used in combination with the K-means clustering algorithm in the Encoder-decoder plus K-means clustering-based OCTA segmentation framework, which is shown in Figure 5 and provides the final output. Figure 6 illustrates the internal structure of the two models, which is comprised of the encoder-decoder architecture presented in Figure 4, followed by the K-means clustering algorithm shown in Figure 2.The key importance of the K-means clustering algorithm is to refine the output and group the pixels which belong to the RV and FAZ areas in each task.
4. Training
4.1. Hyperparameter Setting
4.2. Loss Function
4.3. Optimizer
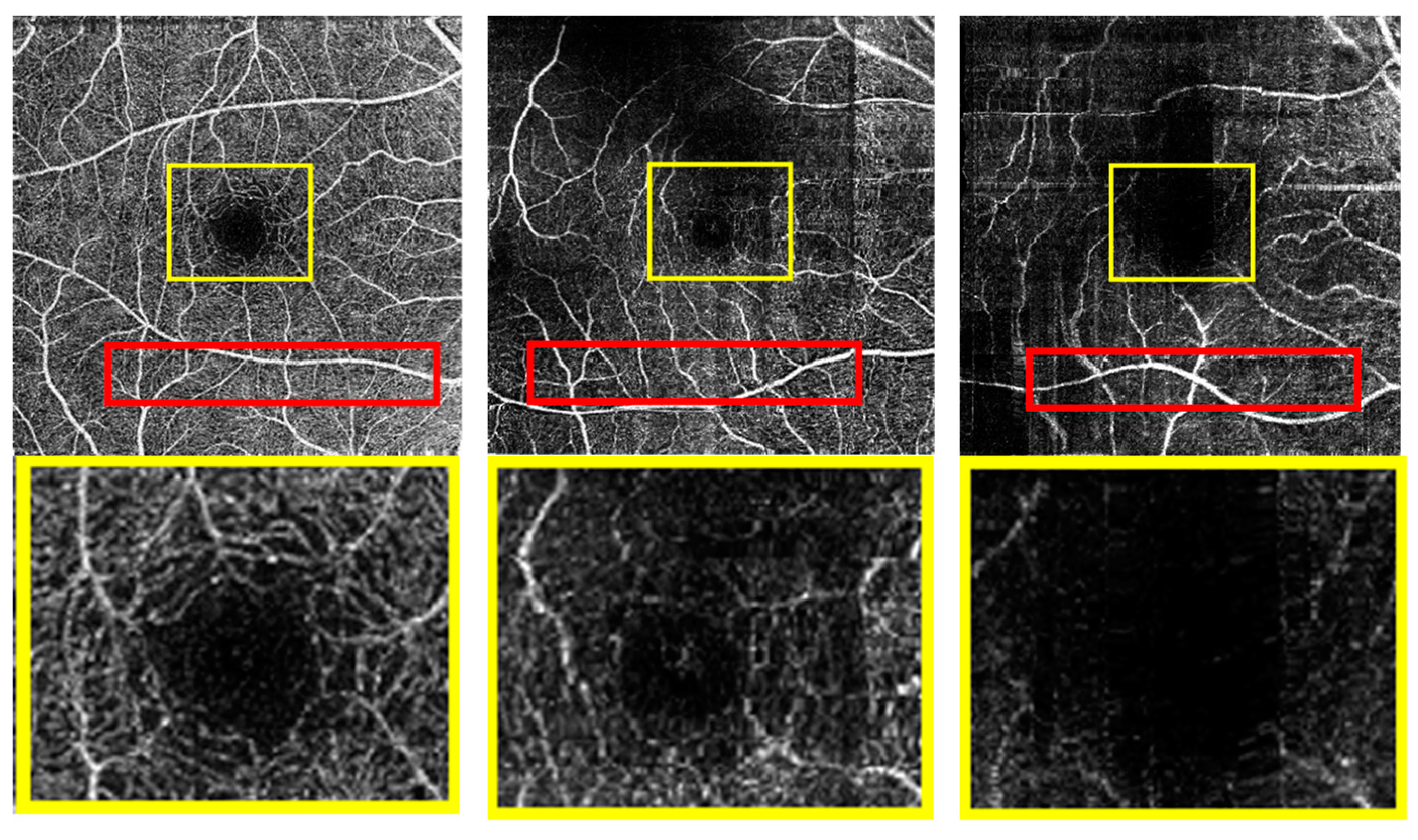
5. Results and Discussion
5.1. RV Segmentation Results
5.2. Efficiency Analysis
- FLOPs and Trainable Parameters
- Consumed Time
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Breger, A.; Goldbach, F.; Gerendas, B.S.; Schmidt-Erfurth, U.; Ehler, M. Blood vessel segmentation in en-face octa images: A frequency based method. In Proceedings of the Medical Imaging 2022: Computer-Aided Diagnosis, San Diego, CA, USA, 4 April 2022; Volume 12033, pp. 520–530. [Google Scholar]
- Eladawi, N.; Elmogy, M.; Helmy, O.; Aboelfetouh, A.; Riad, A.; Sandhu, H.; Schaal, S.; El-Baz, A. Automatic blood vessels segmentation based on different retinal maps from octa scans. Comput. Biol. Med. 2017, 89, 150–161. [Google Scholar] [CrossRef]
- Noronha, K.; Navya, K.T.; Nayak, K.P. Support system for the automated detection of hypertensive retinopathy using fundus images. In Proceedings of the International Conference on Electronic Design and Signal Processing ICEDSP, Manipal, India, 20–22 December 2012; pp. 1–5. [Google Scholar]
- Pascual-Prieto, J.; Burgos-Blasco, B.; Avila Sanchez-Torija, M.; Fernández-Vigo, J.I.; Arriola-Villalobos, P.; Barbero Pedraz, M.A.; García-Feijoo, J.; Martínez-de-la-Casa, J.M. Utility of optical coherence tomography angiography in detecting vascular retinal damage caused by arterial hypertension. Eur. J. Ophthalmol. 2020, 30, 579–585. [Google Scholar] [CrossRef] [PubMed]
- Kashani, A.H.; Chen, C.-L.; Gahm, J.K.; Zheng, F.; Richter, G.M.; Rosenfeld, P.J.; Shi, Y.; Wang, R.K. Optical coherence tomography angiography: A comprehensive review of current methods and clinical applications. Prog. Retin. Eye Res. 2017, 60, 66–100. [Google Scholar] [CrossRef] [PubMed]
- Cardoso, J.N.; Keane, P.A.; Sim, D.A.; Bradley, P.; Agrawal, R.; Addison, P.K.; Egan, C.; Tufail, A. Systematic evaluation of optical coherence tomography angiography in retinal vein occlusion. Am. J. Ophthalmol. 2016, 163, 93–107.e106. [Google Scholar] [CrossRef] [PubMed]
- Sheng, B.; Li, P.; Mo, S.; Li, H.; Hou, X.; Wu, Q.; Qin, J.; Fang, R.; Feng, D.D. Retinal vessel segmentation using minimum spanning superpixel tree detector. IEEE Trans. Cybern. 2018, 49, 2707–2719. [Google Scholar] [CrossRef] [PubMed]
- Guo, M.; Zhao, M.; Cheong, A.M.; Corvi, F.; Chen, X.; Chen, S.; Zhou, Y.; Lam, A.K. Can deep learning improve the automatic segmentation of deep foveal avascular zone in optical coherence tomography angiography? Biomed. Signal Process. Control 2021, 66, 102456. [Google Scholar] [CrossRef]
- Liang, Z.; Zhang, J.; An, C. Foveal avascular zone segmentation of octa images using deep learning approach with unsupervised vessel segmentation. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 1200–1204. [Google Scholar]
- Lin, L.; Wang, Z.; Wu, J.; Huang, Y.; Lyu, J.; Cheng, P.; Wu, J.; Tang, X. BSDA-Net: A boundary shape and distance aware joint learning framework for segmenting and classifying octa images. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 27 September–1 October 2021; pp. 65–75. [Google Scholar]
- Guo, Y.; Camino, A.; Wang, J.; Huang, D.; Hwang, T.; Jia, Y. MEDnet, a neural network for automated detection of avascular area in OCT angiography. Biomed. Opt. Express 2018, 9, 5147–5158. [Google Scholar] [CrossRef]
- Peng, L.; Lin, L.; Cheng, P.; Wang, Z.; Tang, X. Fargo: A joint framework for faz and rv segmentation from octa images. In Proceedings of the Ophthalmic Medical Image Analysis: 8th International Workshop, OMIA 2021, Held in Conjunction with MICCAI 2021, Strasbourg, France, 27 September 2021; Volume 8, pp. 42–51. [Google Scholar]
- Meiburger, K.M.; Salvi, M.; Rotunno, G.; Drexler, W.; Liu, M. Automatic segmentation and classification methods using optical coherence tomography angiography (octa): A Review and Handbook. Appl. Sci. 2021, 11, 9734. [Google Scholar] [CrossRef]
- Ma, Y.; Hao, H.; Xie, J.; Fu, H.; Zhang, J.; Yang, J.; Wang, Z.; Liu, J.; Zheng, Y.; Zhao, Y. ROSE: A retinal OCT-angiography vessel segmentation dataset and new model. IEEE Trans. Med. Imaging 2021, 40, 928–939. [Google Scholar] [CrossRef]
- Zhu, C.; Wang, H.; Xiao, Y.; Dai, Y.; Liu, Z.; Zou, B. OVS-Net: An effective feature extraction network for optical coherence tomography angiography vessel segmentation. Comput. Animat. Virtual Worlds 2022, 33, e2096. [Google Scholar] [CrossRef]
- Li, M.; Zhang, Y.; Ji, Z.; Xie, K.; Yuan, S.; Liu, Q.; Chen, Q. IPN-V2 and OCTA-500: Methodology and Dataset for Retinal Image Segmentation. arXiv 2020, arXiv:2012.07261. [Google Scholar]
- Lu, Y.; Simonett, J.M.; Wang, J.; Zhang, M.; Hwang, T.S.; Hagag, A.M.; Huang, D.; Li, D.; Jia, Y. Evaluation of automatically quantified foveal avascular zone metrics for diagnosis of diabetic retinopathy using optical coherence tomography angiography. Investig. Opthalmol. Vis. Sci. 2018, 59, 2212–2221. [Google Scholar] [CrossRef] [PubMed]
- Díaz, M.; Novo, J.; Cutrín, P.; Gómez-Ulla, F.; Penedo, M.G.; Ortega, M. Automatic segmentation of the foveal avascular zone in ophthalmological OCT-A images. PLoS ONE 2019, 14, e0212364. [Google Scholar] [CrossRef] [PubMed]
- Qin, X.; Xu, M.; Zheng, C.; He, C.; Zhang, X. Multi-scale feedback feature refinement u-net for medical image segmentation. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Saha, S.K.; Xiao, D.; Bhuiyan, A.; Wong, T.Y.; Kanagasingam, Y. Color fundus image registration techniques and applications for automated analysis of diabetic retinopathy progression: A review. Biomed. Signal Process. Control 2018, 47, 288–302. [Google Scholar] [CrossRef]
- Yasser, I.; Khalifa, F.; Abdeltawab, H.; Ghazal, M.; Sandhu, H.S.; El-Baz, A. Automated diagnosis of optical coherence tomography angiography (octa) based on machine learning techniques. Sensors 2022, 22, 2342. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.; Budak, Ü.; Şengür, A. A novel retinal vessel detection approach based on multiple deep convolution neural networks. Comput. Methods Programs Biomed. 2018, 167, 43–48. [Google Scholar] [CrossRef] [PubMed]
- Hu, K.; Zhang, Z.Z.; Niu, X.R.; Zhang, Y.; Cao, C.H.; Xiao, F.; Gao, X.P. Retinal vessel segmentation of color fundus images using multi-scale convolutional neural network with an improved cross-entropy loss function. Neurocomputing 2018, 309, 179–191. [Google Scholar] [CrossRef]
- Odstrcilik, J.; Kolar, R.; Budai, A.; Hornegger, J.; Jan, J.; Gazarek, J.; Kubena, T.; Cernosek, P.; Svoboda, O.; Angelopoulou, E. Retinal vessel segmentation by improved matched filtering: Evaluation on a new high-resolution fundus image database. IET Image Process. 2013, 7, 373–383. [Google Scholar] [CrossRef]
- Bernardes, R.; Serranho, P.; Lobo, C. Digital ocular fundus imaging: A review. Ophthalmologica 2011, 226, 161–181. [Google Scholar] [CrossRef]
- Shah, S.A.A.; Tang, T.B.; Faye, I.; Laude, A. Blood vessel segmentation in color fundus images based on regional and Hessian features. Graefe’s Arch. Clin. Exp. Ophthalmol. 2017, 255, 1525–1533. [Google Scholar] [CrossRef]
- Christodoulidis, A.; Hurtut, T.; Tahar, H.B.; Cheriet, F. A multi-scale tensor voting approach for small retinal vessel segmentation in high resolution fundus images. Comput. Med. Imaging Graph. 2016, 52, 28–43. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Jiang, X.; Ren, J. Blood vessel segmentation from fundus image by a cascade classification framework. Pattern Recognit. 2019, 88, 331–341. [Google Scholar] [CrossRef]
- Li, X.; Ding, J.; Tang, J.; Guo, F. Res2Unet: A multi-scale channel attention network for retinal vessel segmentation. Neural Comput. Appl. 2022, 34, 12001–12015. [Google Scholar] [CrossRef]
- Zhang, Y.; Lian, J.; Rong, L.; Jia, W.; Li, C.; Zheng, Y. Even faster retinal vessel segmentation via accelerated singular value decomposition. Neural Comput. Appl. 2020, 32, 1893–1902. [Google Scholar] [CrossRef]
- Li, A.; You, J.; Du, C.; Pan, Y. Automated segmentation and quantification of oct angiography for tracking angiogenesis progression. Biomed. Opt. Express 2017, 8, 5604–5616. [Google Scholar] [CrossRef] [PubMed]
- Xie, H.; Zhang, L.; Lim, C.P.; Yu, Y.; Liu, C.; Liu, H.; Walters, J. Improving k-means clustering with enhanced firefly algorithms. Appl. Soft Comput. 2019, 84, 105763. [Google Scholar] [CrossRef]
- Kim, Y.W.; Krishna, A.V. A study on the effect of canny edge detection on downscaled images. Pattern Recognit. Image Anal. 2020, 30, 372–381. [Google Scholar] [CrossRef]
- Chlebiej, M.; Gorczynska, I.; Rutkowski, A.; Kluczewski, J.; Grzona, T.; Pijewska, E.; Sikorski, B.L.; Szkulmowska, A.; Szkulmowski, M. Quality improvement of oct angiograms with elliptical directional filtering. Biomed. Opt. Express 2019, 10, 1013–1031. [Google Scholar] [CrossRef]
- Karimpouli, S.; Tahmasebi, P. Segmentation of digital rock images using deep convolutional autoencoder networks. Comput. Geosci. 2019, 126, 142–150. [Google Scholar] [CrossRef]
- Dumoulin, V.; Visin, F. A guide to convolution arithmetic for deep learning. arXiv 2016, arXiv:1603.07285. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- Panwar, H.; Gupta, P.K.; Siddiqui, M.K.; Morales-Menendez, R.; Singh, V. Application of deep learning for fast detection of COVID-19 in X-rays using nCOVnet. Chaos Solitons Fractals 2020, 138, 109944. [Google Scholar] [CrossRef]
- Gong, Q.; Wang, P.; Cheng, Z. An encoder-decoder model based on deep learning for state of health estimation of lithium-ion battery. J. Energy Storage 2022, 46, 103804. [Google Scholar] [CrossRef]
- Zhou, S.; Song, W. Concrete roadway crack segmentation using encoder-decoder networks with range images. Autom. Constr. 2020, 120, 103403. [Google Scholar] [CrossRef]
- Carneiro, T.; Da Nóbrega, R.V.M.; Nepomuceno, T.; Bian, G.B.; De Albuquerque, V.H.C.; Reboucas Filho, P.P. Performance analysis of google colaboratory as a tool for accelerating deep learning applications. IEEE Access 2018, 6, 61677–61685. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Shah, K.D.; Patel, D.K.; Patel, H.A.; Nagrani, H.R. EMED-UNet: An efficient multi-encoder-decoder based unet for chest X-ray segmentation. In Proceedings of the 2022 IEEE Region 10 Symposium (TENSYMP), Mumbai, India, 1–3 July 2022; pp. 1–6. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Layer (Type) | Input Shape | Parameters | Trainable Parameters |
|---|---|---|---|---|
| 1 | Conv2D | [1, 1, 400, 400] | 60 | 60 |
| 2 | ReLU | [1, 6, 200, 200] | 0 | 0 |
| 3 | Conv2D | [1, 6, 200, 200] | 660 | 660 |
| 4 | BatchNorm2D | [1, 12, 100, 100] | 24 | 24 |
| 5 | ReLU | [1, 12, 100, 100] | 0 | 0 |
| 6 | Conv2D | [1, 12, 100, 100] | 2616 | 2616 |
| 7 | ReLU | [1, 24, 98, 98] | 0 | 0 |
| 8 | Conv2D | [1, 24, 98, 98] | 10,416 | 10,416 |
| 9 | ReLU | [1, 48, 96, 96] | 0 | 0 |
| 10 | Conv2D | [1, 48, 96, 96] | 41,568 | 41,568 |
| 11 | ReLU | [1, 96, 94, 94] | 0 | 0 |
| 12 | Flatten | [1, 96, 94, 94] | 0 | 0 |
| Total parameters: 55,344; Trainable parameters: 55,344; Non-trainable parameters: 0 | ||||
| Number | Layer (Type) | Input Shape | Parameters | Trainable Parameters |
|---|---|---|---|---|
| 1 | Unflatten | [1, 848256] | 0 | 0 |
| 2 | ConvTranspose2D | [1, 96, 94, 94] | 41,520 | 41,520 |
| 3 | ReLU | [1, 48, 96, 96] | 0 | 0 |
| 4 | ConvTranspose2D | [1, 48, 96, 96] | 10,392 | 10,392 |
| 5 | ReLU | [1, 24, 98, 98] | 0 | 0 |
| 6 | ConvTranspose2D | [1, 24, 98, 98] | 2604 | 2604 |
| 7 | BatchNorm2D | [1, 12, 100, 100] | 24 | 24 |
| 8 | ReLU | [1, 12, 100, 100] | 0 | 0 |
| 9 | ConvTranspose2D | [1, 12, 100, 100] | 654 | 654 |
| 10 | BatchNorm2D | [1, 6, 200, 200] | 12 | 12 |
| 11 | ReLU | [1, 6, 200, 200] | 0 | 0 |
| 12 | ConvTranspose2D | [1, 6, 200, 200] | 55 | 55 |
| Total parameters: 55,261; Trainable parameters: 55,261; Non-trainable parameters: 0 | ||||
| S/N | Issue | Learning Method | Proposed Method | Projection Map | Data Set: OCTA-500 | ||
|---|---|---|---|---|---|---|---|
| Accuracy (Acc) | Precision (Pre) | Recall (Rec) | |||||
| 1 | RV and FAZ segmentation | Unsupervised | K-Means clustering | OCTA_6M ILM_OPL | 0.89 | 0.67 | 0.79 |
| 2 | Supervised | ASDC | 0.96 | 0.91 | 0.83 | ||
| 3 | RV segmentation | Supervised | ASDC | 0.97 | 0.92 | 0.91 | |
| Number | Target | Methods | Accuracy |
|---|---|---|---|
| 1 [2] | RV segmentation | Soares et al. | 0.84 |
| Nguyen et al. | 0.70 | ||
| Azzopardi et al. | 0.80 | ||
| Eladawi et al. | 0.93 | ||
| 2 [11] | FAZ segmentation | Guo et al. | 0.89 |
| 3 | RV and FAZ | Ours | 0.96 |
| Data Set | Target | Methods | Dice (%) | Jac (%) | |
|---|---|---|---|---|---|
| OCTA_6M | RV segmentation | U-Net | [15] | 86.52 | 77.32 |
| R2U-Net4 | 81.22 | 69.29 | |||
| AttU Net5 | 86.47 | 77.23 | |||
| CE-Net6 | 83.04 | 72.04 | |||
| Cs2-Net4 | 86.13 | 76.71 | |||
| FARGO | 89.15 | 80.50 | |||
| Ours | 91.60 | 85.20 | |||
| RV and FAZ | Ours | 86.64 | 79.04 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, A.; Hao, J.; Dong, Z.; Li, J. Adaptive Deep Clustering Network for Retinal Blood Vessel and Foveal Avascular Zone Segmentation. Appl. Sci. 2023, 13, 11259. https://doi.org/10.3390/app132011259
Khan A, Hao J, Dong Z, Li J. Adaptive Deep Clustering Network for Retinal Blood Vessel and Foveal Avascular Zone Segmentation. Applied Sciences. 2023; 13(20):11259. https://doi.org/10.3390/app132011259
Chicago/Turabian StyleKhan, Azaz, Jinyi Hao, Zihao Dong, and Jinping Li. 2023. "Adaptive Deep Clustering Network for Retinal Blood Vessel and Foveal Avascular Zone Segmentation" Applied Sciences 13, no. 20: 11259. https://doi.org/10.3390/app132011259