
Adaptive Test Suits Generation for Self-Adaptive Systems Using SPEA2 Algorithm

 ,
,  ,
,
Abstract
:1. Introduction
2. Related Work
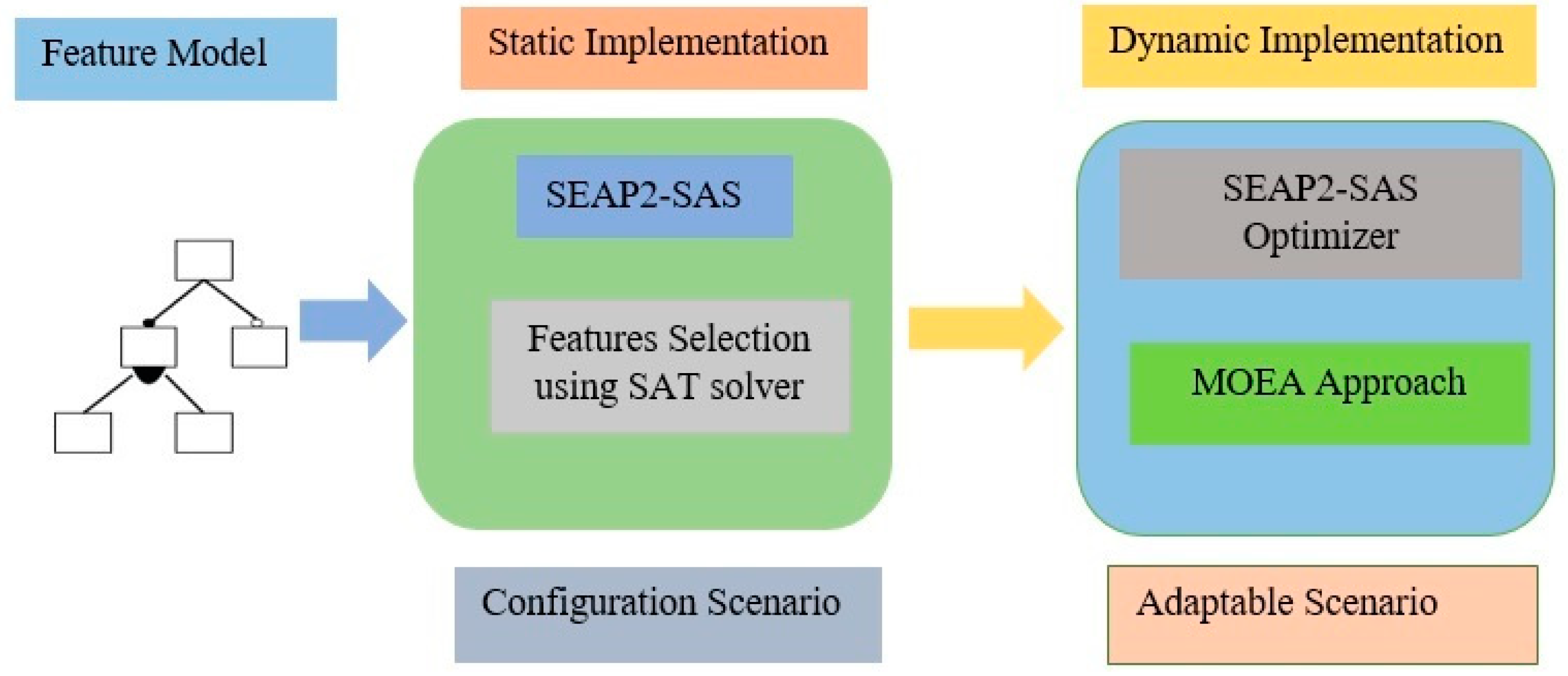
3. Proposed Approach-SPEA2-SAS
3.1. Optimizing Test Cases Generation for Large Adaptive Systems
3.2. Transforming Feature Model of SAS to Evolutionary Algorithm (SPEA2)
3.3. SAS Design Dependencies and Conflicting Objectives
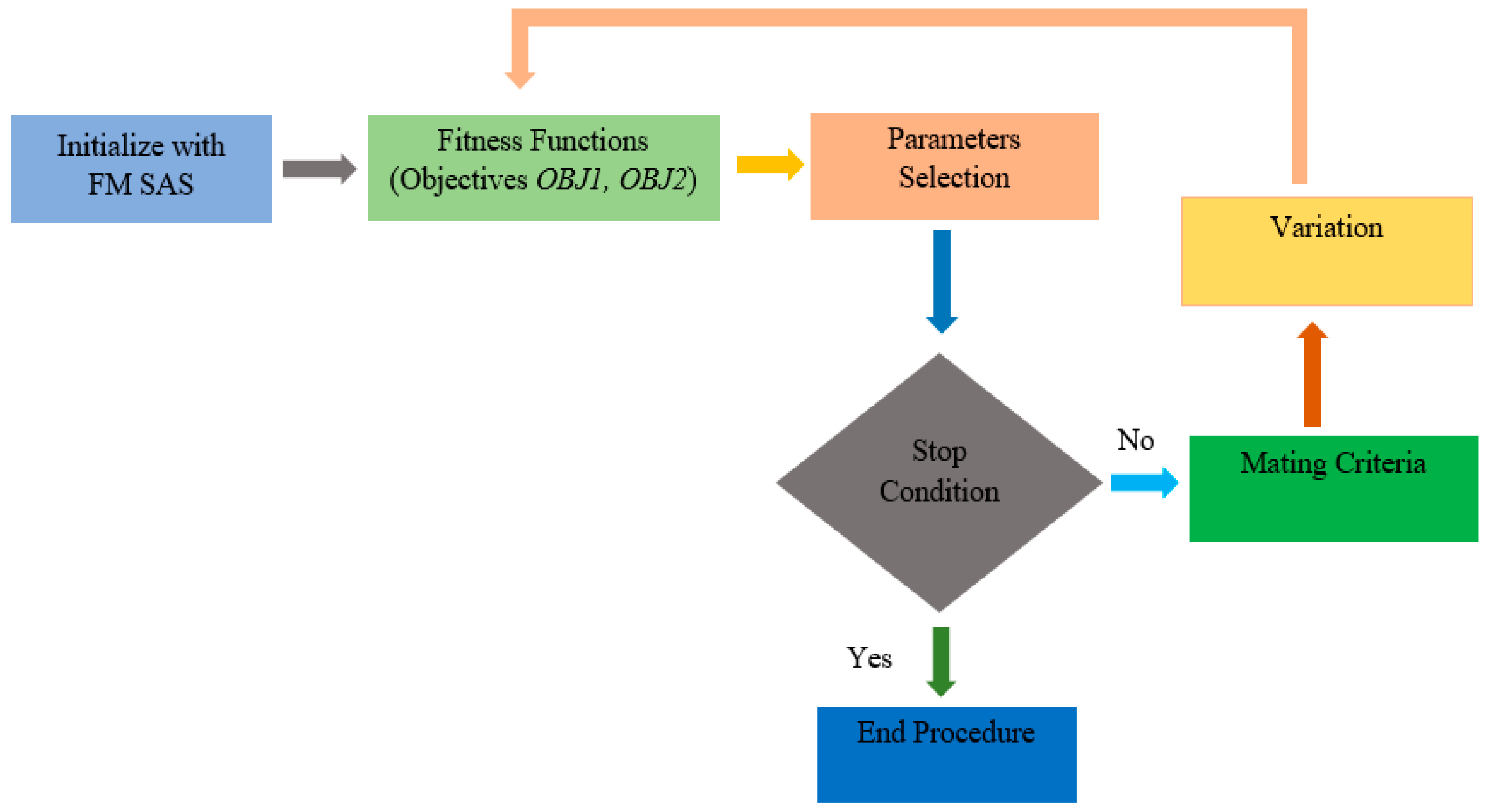
3.4. SPEA2 Approach for Optimizing the Objectives
4. Experiments and Results
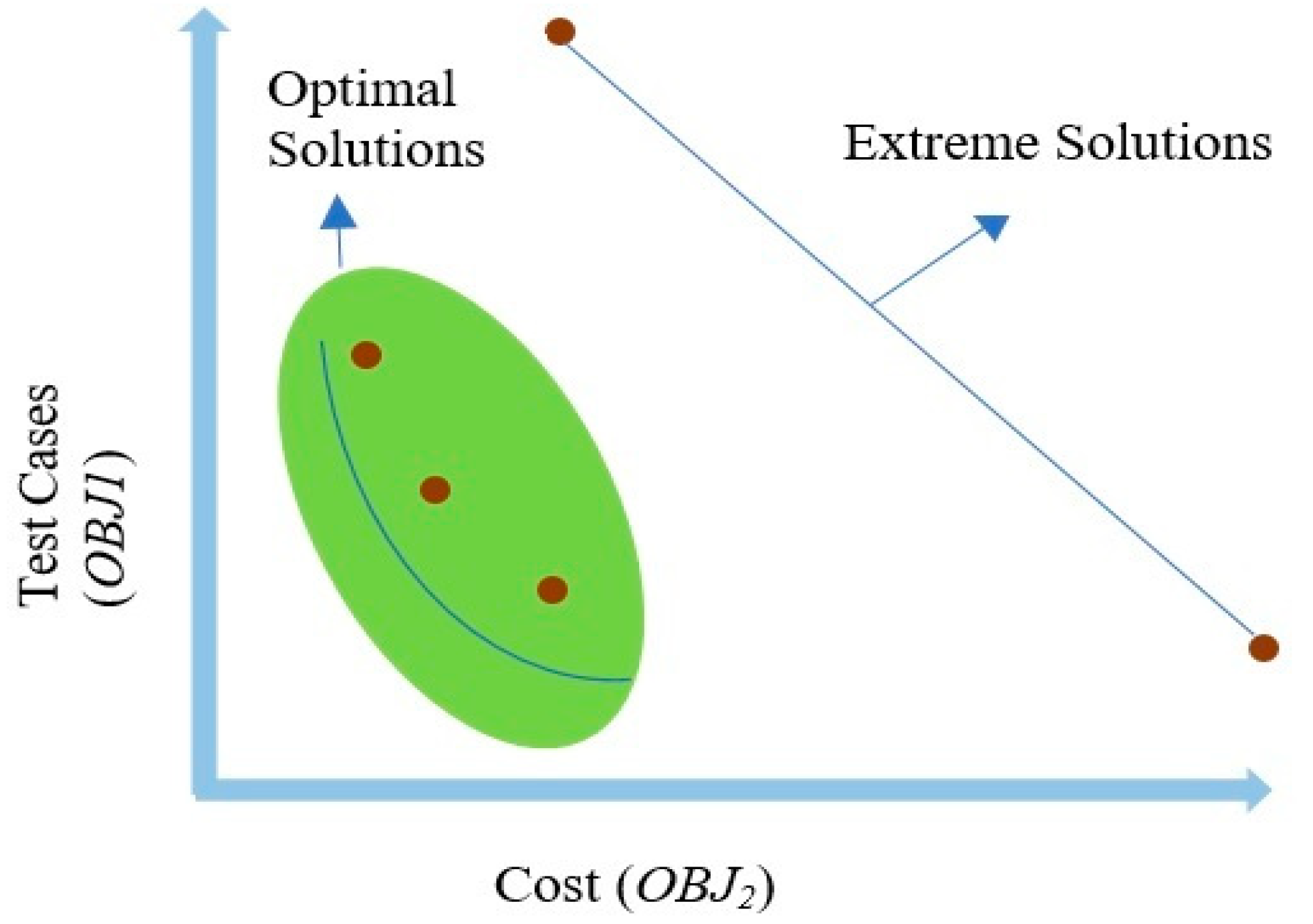
Objective Functions
- Minimizing the Test Cases (OBJ1)
- Minimizing the Cost (OBJ2)
5. Discussion
5.1. State-of-the-Art Comparison
5.2. Threats to Validity
6. Conclusions
Author Contributions
Funding
Institutional Board Review Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ismail, S.; Shah, K.; Reza, H.; Marsh, R.; Grant, E. Toward management of uncertainty in self-adaptive software systems: IoT case study. Computers 2021, 10, 27. [Google Scholar] [CrossRef]
- Arcelli, D. Exploiting queuing networks to model and assess the performance of self-adaptive software systems: A survey. Procedia Comput. Sci. 2020, 170, 498–505. [Google Scholar] [CrossRef]
- Gerostathopoulos, I.; Vogel, T.; Weyns, D.; Lago, P. How do we evaluate self-adaptive software systems?: A ten-year perspective of SEAMS. In Proceedings of the 2021 International Symposium on Software Engineering for Adaptive and Self-Managing Systems (SEAMS), Madrid, Spain, 18–24 May 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 59–70. [Google Scholar]
- Han, D.S.; Yang, Q.L.; Xing, J.C.; Ma, G.L. Easymodel: A refinement-based modeling and verification approach for self-adaptive software. J. Comput. Sci. Technol. 2020, 35, 1016–1046. [Google Scholar] [CrossRef]
- Han, D.; Ma, G.; Cai, Y.; Wang, B.; Li, A. ProbaSAS: Modeling and Decision-Making Approach for Self-Adaptive Software Systems under Uncertainty. In Proceedings of the 2022 41st Chinese Control Conference (CCC), Hefei, China, 25–27 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 5871–5876. [Google Scholar]
- Fedasyuk, D.; Lutsyk, I. Method of Modification of Self-Adaptive Software Systems Based on Ontology. In Proceedings of the 2022 IEEE 16th International Conference on Advanced Trends in Radioelectronics, Telecommunications and Computer Engineering (TCSET), Lviv-Slavske, Ukraine, 22–26 February 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 530–533. [Google Scholar]
- Apache Software Foundation. Apache Tomcat. Available online: http://tomcat.apache.org/ (accessed on 24 June 2022).
- Chen, T.; Li, K.; Bahsoon, R.; Yao, X. FEMOSAA: Feature-guided and knee-driven multi-objective optimization for self-adaptive software. ACM Trans. Softw. Eng. Methodol. 2018, 27, 1–50. [Google Scholar] [CrossRef]
- Ramirez, A.J.; Knoester, D.B.; Cheng, B.H.; McKinley, P.K. Plato: A genetic algorithm approach to run-time reconfiguration in autonomic computing systems. Clust. Comput. 2011, 14, 229–244. [Google Scholar] [CrossRef]
- Yusoh, Z.I.M.; Tang, M. Composite SaaS Placement and Resource Optimization in Cloud Computing Using Evolutionary Algorithms. In Proceedings of the 2012 IEEE 5th International Conference on Cloud Computing (CLOUD), Honolulu, HI, USA, 24–29 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 590–597. [Google Scholar] [CrossRef]
- Han, D.; Cai, Y.; Chen, W.; Cui, Z.; Li, A. Timed-SAS: Modeling and Analyzing the Time Behaviors of Self-Adaptive Software under Uncertainty. Appl. Sci. 2023, 13, 2018. [Google Scholar] [CrossRef]
- Sulaiman, R.A.; Jawawi, D.N.; Halim, S.A. Cost-effective test case generation with the hyper-heuristic for software product line testing. Adv. Eng. Softw. 2023, 175, 103335. [Google Scholar] [CrossRef]
- Zhao, X.; Li, X.; Dong, X. Research on Component-Based Embedded Spacecraft Software System Development. In Proceedings of the 2023 8th International Conference on Intelligent Computing and Signal Processing (ICSP), Xi’an, China, 23–25 September 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 248–252. [Google Scholar]
- Horcas, J.M.; Pinto, M.; Fuentes, L. Empirical analysis of the tool support for software product lines. Softw. Syst. Model. 2023, 22, 377–414. [Google Scholar] [CrossRef]
- Cardellini, V.; Casalicchio, E.; Grassi, V.; Iannucci, S.; Presti, F.L.; Mirandola, R. MOSES: A framework for QoS driven runtime adaptation of service-oriented systems. IEEE Trans. Softw. Eng. 2012, 38, 1138–1159. [Google Scholar] [CrossRef]
- Hameed, S.; Elsheikh, Y.; Azzeh, M. An optimized case-based software project effort estimation using genetic algorithm. Inf. Softw. Technol. 2023, 153, 107088. [Google Scholar] [CrossRef]
- Hierons, R.M.; Li, M.; Liu, X.; Segura, S.; Zheng, W. SIP: Optimal product selection from feature models using many-objective evolutionary optimization. ACM Trans. Softw. Eng. Methodol. 2016, 25, 1–39. [Google Scholar] [CrossRef]
- Chen, T.; Bahsoon, R. Self-adaptive trade-off decision making for autoscaling cloud-based services. IEEE Trans. Serv. Comput. 2015, 10, 618–632. [Google Scholar] [CrossRef]
- El Kateb, D.; Fouquet, F.; Nain, G.; Meira, J.A.; Ackerman, M.; Le Traon, Y. Generic Cloud Platform Multi-Objective Optimization Leveraging Models@ Run Time. In Proceedings of the 29th Annual ACM Symposium on Applied Computing, Gyeongju, Republic of Korea, 24–28 March 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 343–350. [Google Scholar]
- Fredericks, E.M. Automatically Hardening a Self-Adaptive System against Uncertainty. In Proceedings of the 11th International Symposium on Software Engineering for Adaptive and Self-Managing Systems (SEAMS’16), Austin, TX, USA, 16–17 May 2016; ACM: New York, NY, USA, 2016; pp. 16–27. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, H. MOEA/D: A Multiobjective Evolutionary Algorithm Based on Decomposition. IEEE Trans. Evol. Comput. 2017, 11, 712–731. [Google Scholar] [CrossRef]
- Fidalgo, C.G.; Sousa, M.; Mendes, D.; Dos Anjos, R.K.; Medeiros, D.; Singh, K.; Jorge, J. Manipulating Avatars and Gestures to Improve Remote Collaboration. In Proceedings of the 2023 IEEE Conference Virtual Reality and 3D User Interfaces (VR), Shanghai, China, 25–29 March 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 438–448. [Google Scholar]
- Keeton, K.; Santos, C.A.; Beyer, D.; Chase, J.S.; Wilkes, J. Designing for Disasters. FAST 2004, 4, 59–62. [Google Scholar]
- Ramirez, A.J.; Knoester, D.B.; Cheng, B.H.; McKinley, P.K. Applying Genetic Algorithms to decision Making in Autonomic Computing Systems. In Proceedings of the 6th International Conference on Autonomic Computing, Barcelona, Spain, 15–19 June 2009; Association for Computing Machinery: New York, NY, USA, 2009; pp. 97–106. [Google Scholar]
- Fredericks, E.M.; Cheng, B.H. Automated Generation of Adaptive Test Plans for Self-Adaptive Systems. In Proceedings of the 2015 IEEE/ACM 10th International Symposium on Software Engineering for Adaptive and Self-Managing Systems, Florence, Italy, 18–19 May 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 157–167. [Google Scholar]
- Benavides, D.; Segura, S.; Ruiz-Cortés, A. Automated analysis of feature models 20 years later: A literature review. Inf. Syst. 2010, 35, 615–636. [Google Scholar] [CrossRef]
- Zitzler, E.; Laumanns, M.; Thiele, L. SPEA2: Improving the Strength Pareto Evolutionary Algorithm; TIK Report; ETH Zurich, Computer Engineering and Networks Laboratory: Zurich, Switzerland, 2001; Volume 103. [Google Scholar]
- Gueorguiev, S.; Harman, M.; Antoniol, G. Software Project Planning for Robustness and Completion Time in the Presence of Uncertainty Using Multi Objective Search Based Software Engineering. In Proceedings of the 11th Annual Conference on Genetic and Evolutionary Computation, Montreal, QC, Canada, 8–12 July 2009; Association for Computing Machinery: New York, NY, USA, 2009; pp. 1673–1680. [Google Scholar]
- Coello, C.A.C. Evolutionary Algorithms for Solving Multi-Objective Problems; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Chen, T.; Bahsoon, R.; Yao, X. Online QoS Modeling in the Cloud: A Hybrid and Adaptive Multi-Learners Approach. In Proceedings of the 2014 IEEE/ACM 7th International Conference on Utility and Cloud Computing, London, UK, 8–11 December 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 327–336. [Google Scholar]
- Chen, T.; Bahsoon, R. Self-adaptive and online QoS modeling for cloud-based software services. IEEE Trans. Softw. Eng. 2017, 43, 453–475. [Google Scholar] [CrossRef]
- Roy, N.; Dubey, A.; Gokhale, A.; Dowdy, L. A Capacity Planning Process for Performance Assurance of Component-Based Distributed Systems. In Proceedings of the 2nd ACM/SPEC International Conference on Performance Engineering, Delft, The Netherlands, 12–16 March 2016; Association for Computing Machinery: New York, NY, USA, 2011; pp. 259–270. [Google Scholar]
- Fittkau, F.; Frey, S.; Hasselbring, W. CDOSim: Simulating Cloud Deployment Options for Software Migration Support. In Proceedings of the 2012 IEEE 6th International Workshop on the Maintenance and Evolution of Service-Oriented and Cloud-Based Systems (MESOCA), Trento, Italy, 24 September 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 37–46. [Google Scholar]
- Zitzler, E.; Thiele, L. Multiobjective evolutionary algorithms: A comparative case study and the strength Pareto approach. IEEE Trans. Evol. Comput. 1999, 3, 257–271. [Google Scholar] [CrossRef]
- Hadka, D. MOEA Framework—A Free and Open Source Java Framework for Multiobjective Optimization. Version 2 2015, 74. Available online: http://moeaframework.org/ (accessed on 8 October 2022).
- Mingay, S. Green IT: The new industry shock wave. Gart. RAS Res. Note G 2007, 153703. [Google Scholar]
- Wada, H.; Suzuki, J.; Yamano, Y.; Oba, K. E³: A multiobjective optimization framework for SLA-aware service composition. IEEE Trans. Serv. Comput. 2011, 5, 358–372. [Google Scholar] [CrossRef]
- Li, M.; Chen, T.; Yao, X. A Critical Review of a Practical Guide to Select Quality Indicators for Assessing Pareto-Based Search Algorithms in Search-Based Software Engineering: Essay on Quality Indicator Selection for SBSE. In Proceedings of the 40th International Conference on Software Engineering, NIER Track, Gothenburg, Sweden, 27 May–3 June 2018; IEEE: Piscataway, NJ, USA; ACM: New York, NY, USA, 2018. [Google Scholar]
- Arcuri, A.; Briand, L. A Practical Guide for Using Statistical Tests to Assess Randomized Algorithms in Software Engineering. In Proceedings of the 2011 IEEE 33rd International Conference on Software Engineering (ICSE), Honolulu, HI, USA, 21–28 May 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1–10. [Google Scholar]
- Kader, M.A.; Zamli, K.Z.; Alkazemi, B.Y. An Experimental Study of a Fuzzy Adaptive Emperor Penguin Optimizer for Global Optimization Problem. IEEE Access 2022, 10, 116344–116374. [Google Scholar] [CrossRef]
- Odili, J.B.; Noraziah, A.; Alkazemi, B.; Zarina, M. Stochastic process and tutorial of the African buffalo optimization. Sci. Rep. 2022, 12, 17319. [Google Scholar] [CrossRef] [PubMed]
- Alsewari, A.A.; Zamli, K.Z.; Al-Kazemi, B. Generating t-way test suite in the presence of constraints. J. Eng. Technol. 2015, 6, 52–66. [Google Scholar]
- Wazirali, R.; Alasmary, W.; Mahmoud, M.M.; Alhindi, A. An optimized steganography hiding capacity and imperceptibly using genetic algorithms. IEEE Access 2019, 7, 133496–133508. [Google Scholar] [CrossRef]
- Ahmad, A. Optimizing Training Data Selection for Decision Trees using Genetic Algorithms. Int. J. Comput. Sci. Netw. Secur. 2020, 20, 84. [Google Scholar]
- Jami, M.A.; Nour, M.K. Managing Software Testing Technical Debt Using Evolutionary Algorithms. Comput. Mater. Contin. 2022, 73, 735–747. [Google Scholar]
- Jamil, M.A.; Nour, M.K.; Alotaibi, S.S.; Hussain, M.J.; Hussaini, S.M.; Naseer, A. Software Product Line Maintenance Using Multi-Objective Optimization Techniques. Appl. Sci. 2023, 13, 9010. [Google Scholar] [CrossRef]
- Jamil, M.A.; Alsadie, D.; Nour, M.K.; Awang Abu Bakar, N.S. Maintain Optimal Configurations for Large Configurable Systems Using Multi-Objective Optimization. Comput. Mater. Contin. 2022, 73, 4407–4422. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Models | Features | Configurations | Number of Pairs |
|---|---|---|---|
| Smart Homev2.2 | 60 | 3.87 × 109 | 6189 |
| Coche Ecologico | 94 | 2.32 × 107 | 11,075 |
| Parameter | Values |
|---|---|
| Population Size | 250 |
| Number of Generations | 500 |
| Crossover Rate | 60% |
| Mutation Rate | 40% |
| Feature Model | Algorithm | Pareto Fronts Solutions | Generation Convergence | Elapsed Time (Millisecond) |
|---|---|---|---|---|
| Smart Home v2.2 | SPEA2 | 200 | 16 | 25,991 |
| Coche Ecologico | SPEA2 | 211 | 15 | 76,827 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jamil, M.A.; Nour, M.K.; Alotaibi, S.S.; Hussain, M.J.; Hussaini, S.M.; Naseer, A. Adaptive Test Suits Generation for Self-Adaptive Systems Using SPEA2 Algorithm. Appl. Sci. 2023, 13, 11324. https://doi.org/10.3390/app132011324
Jamil MA, Nour MK, Alotaibi SS, Hussain MJ, Hussaini SM, Naseer A. Adaptive Test Suits Generation for Self-Adaptive Systems Using SPEA2 Algorithm. Applied Sciences. 2023; 13(20):11324. https://doi.org/10.3390/app132011324
Chicago/Turabian StyleJamil, Muhammad Abid, Mohamed K. Nour, Saud S. Alotaibi, Mohammad Jabed Hussain, Syed Mutiullah Hussaini, and Atif Naseer. 2023. "Adaptive Test Suits Generation for Self-Adaptive Systems Using SPEA2 Algorithm" Applied Sciences 13, no. 20: 11324. https://doi.org/10.3390/app132011324
APA StyleJamil, M. A., Nour, M. K., Alotaibi, S. S., Hussain, M. J., Hussaini, S. M., & Naseer, A. (2023). Adaptive Test Suits Generation for Self-Adaptive Systems Using SPEA2 Algorithm. Applied Sciences, 13(20), 11324. https://doi.org/10.3390/app132011324