
YOLOv7-3D: A Monocular 3D Traffic Object Detection Method from a Roadside Perspective


Abstract
:1. Introduction
- (1)
- Spatial perception: By using 3D detection, the system can accurately perceive the precise position, size, and orientation information of vehicles, enabling accurate perception of vehicles in three-dimensional space. This helps to better understand vehicle motion behavior and spatial layout.
- (2)
- Distance estimation: 3D detection provides distance estimation between vehicles and monitoring cameras. This is crucial for evaluating key parameters such as distance, speed, and acceleration between vehicles and cameras. Such information is vital for traffic flow statistics, behavior analysis, and accident warning applications.
- (3)
- Enhanced safety: Through 3D detection, the monitoring system can more accurately identify the position and motion status of vehicles, providing more reliable traffic information. This helps in the timely detection of traffic violations, abnormal driving behaviors, and accident risks, enabling appropriate warnings and measures to be taken and improving road safety.
- (4)
- Cost-effectiveness: Compared to multi-sensor fusion solutions, monocular vision systems have lower costs. They only require a single camera to capture image information without the need for additional sensor devices, thereby reducing installation and maintenance costs.
2. Related Work
3. Proposed Method
3.1. Task Description
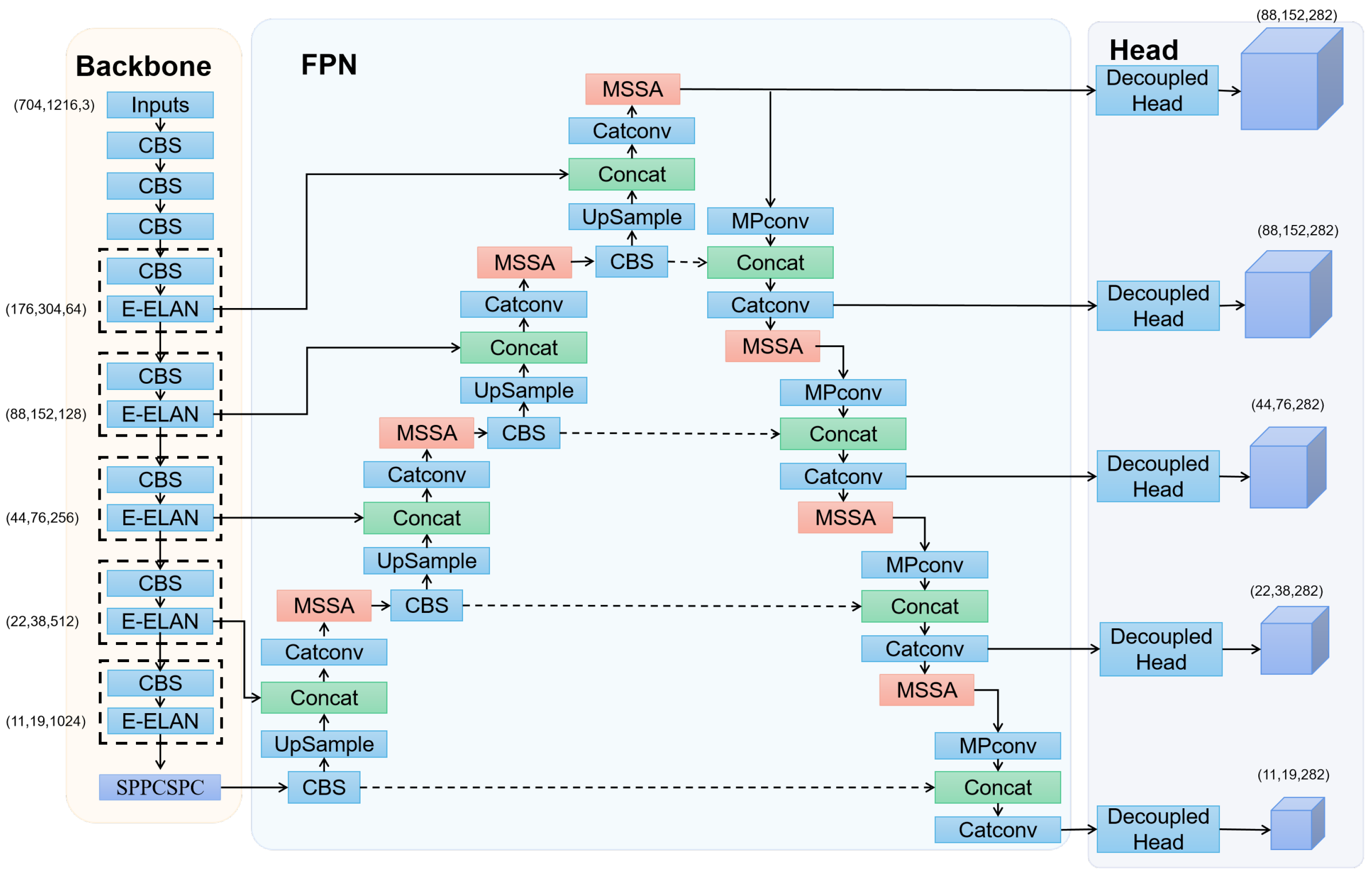
3.2. Model Structure
3.2.1. Multi-Scale Feature Pyramids
3.2.2. Multi-Scale Spatial Attention Mechanism
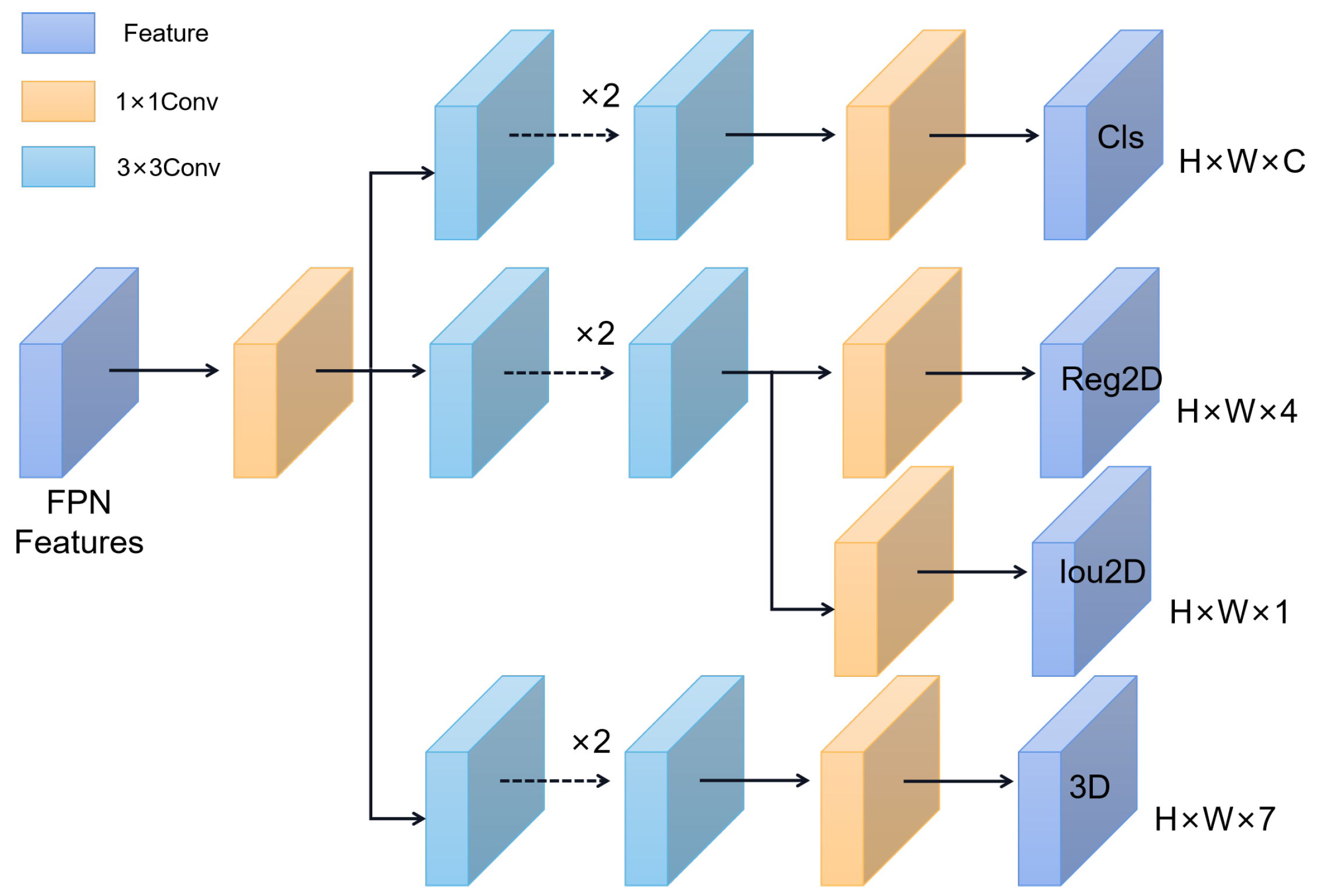
3.2.3. Multi-Branch Decoupling Detection Head
- (1)
- Reg2D(h, w, 4): Used to determine the regression parameters for each feature point, allowing adjustment of the predicted bounding boxes.
- (2)
- Obj(h, w, 1): Used to determine whether each feature point contains an object.
- (3)
- Cls(h, w, num classes): Used to determine the object class for each feature point.
- (4)
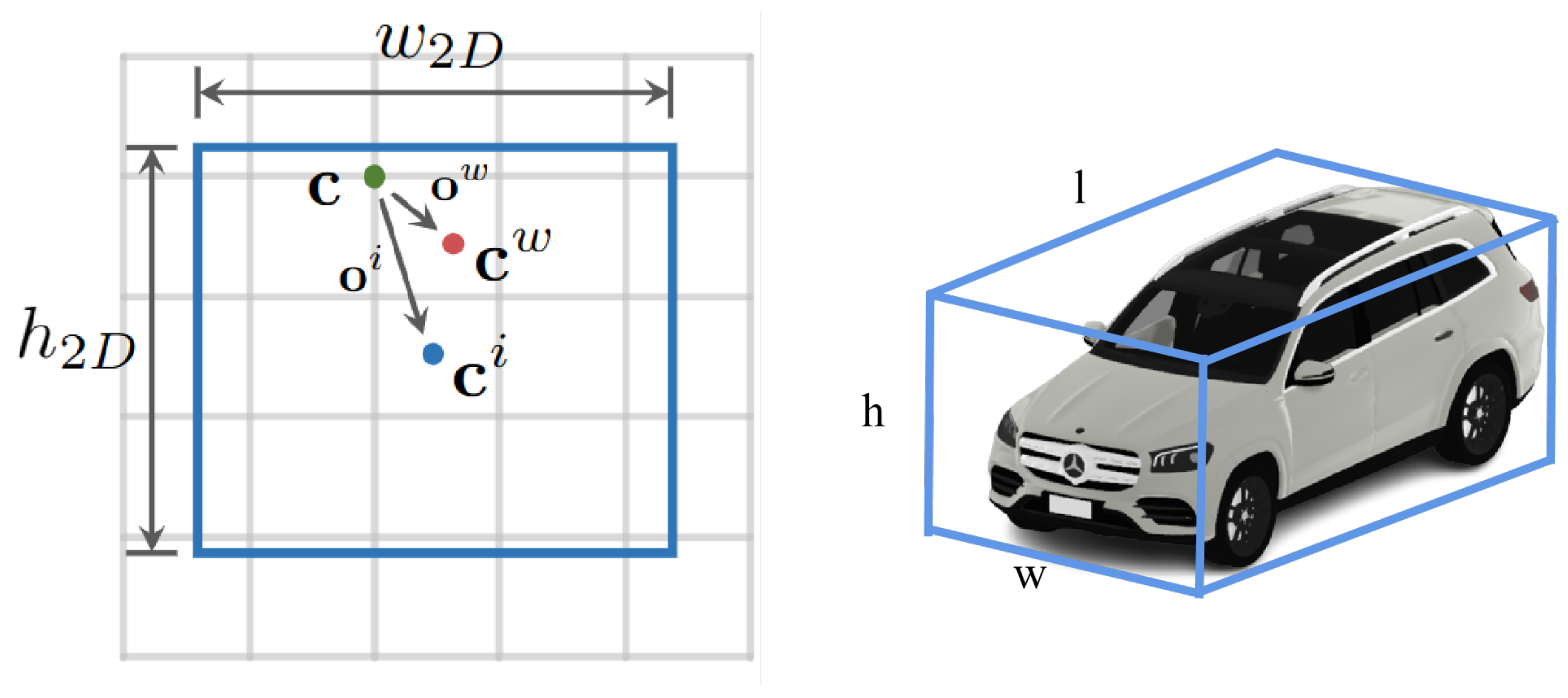
- CenterReg3D(h, w, 2): Used to determine the regression parameters for the 2D projection of the 3D object’s center point on the image.
- (5)
- Depth(h, w, 2): Used to determine the depth value and logarithmic variance for the 3D object.
- (6)
- Dim(h, w, 3): Used to determine the 3D dimensions (length, width, height) of the object.
- (7)
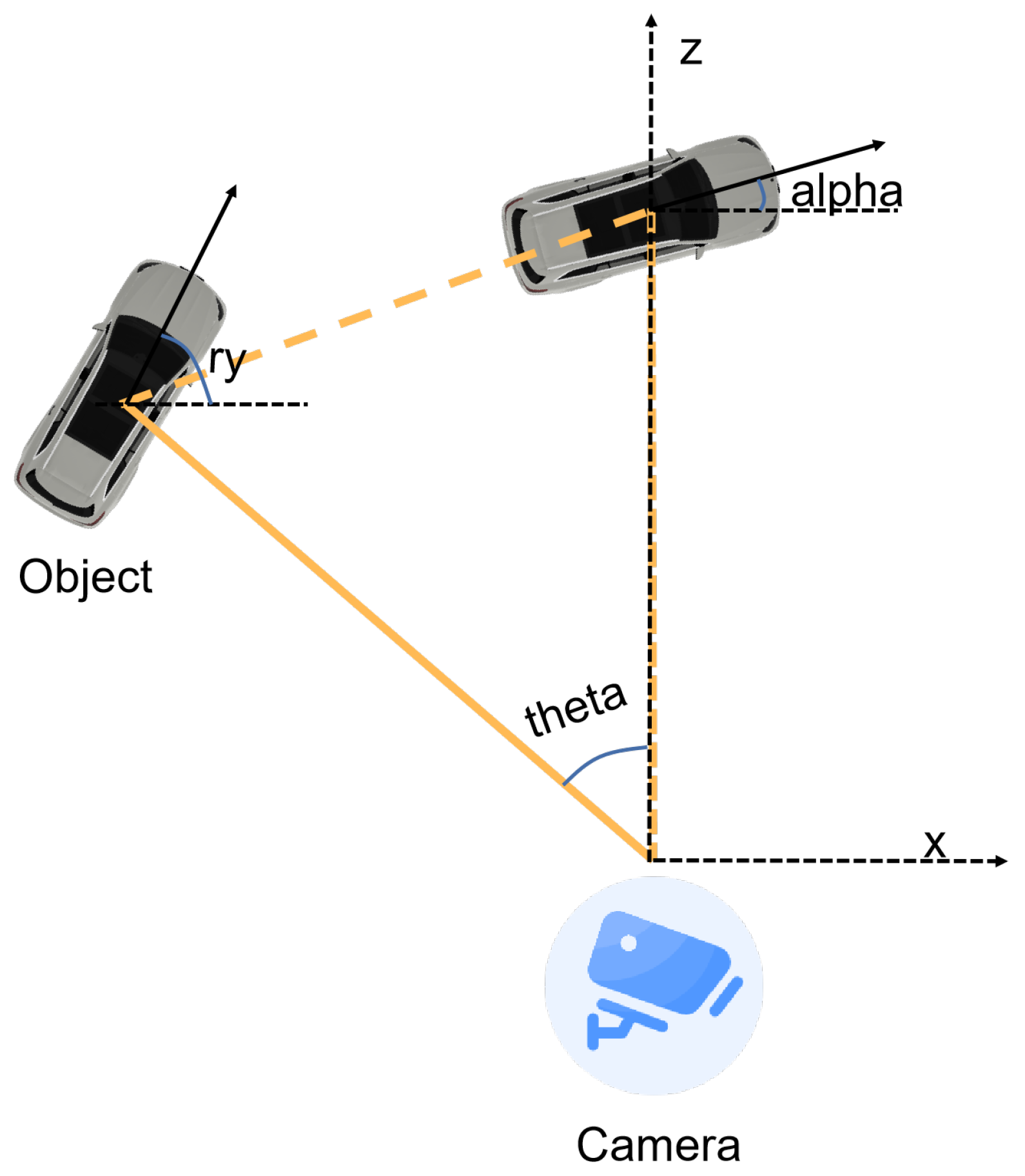
- Theta(h, w, 2): Used to determine the viewing angle of the 3D object.
3.3. Loss Function
4. Experiments
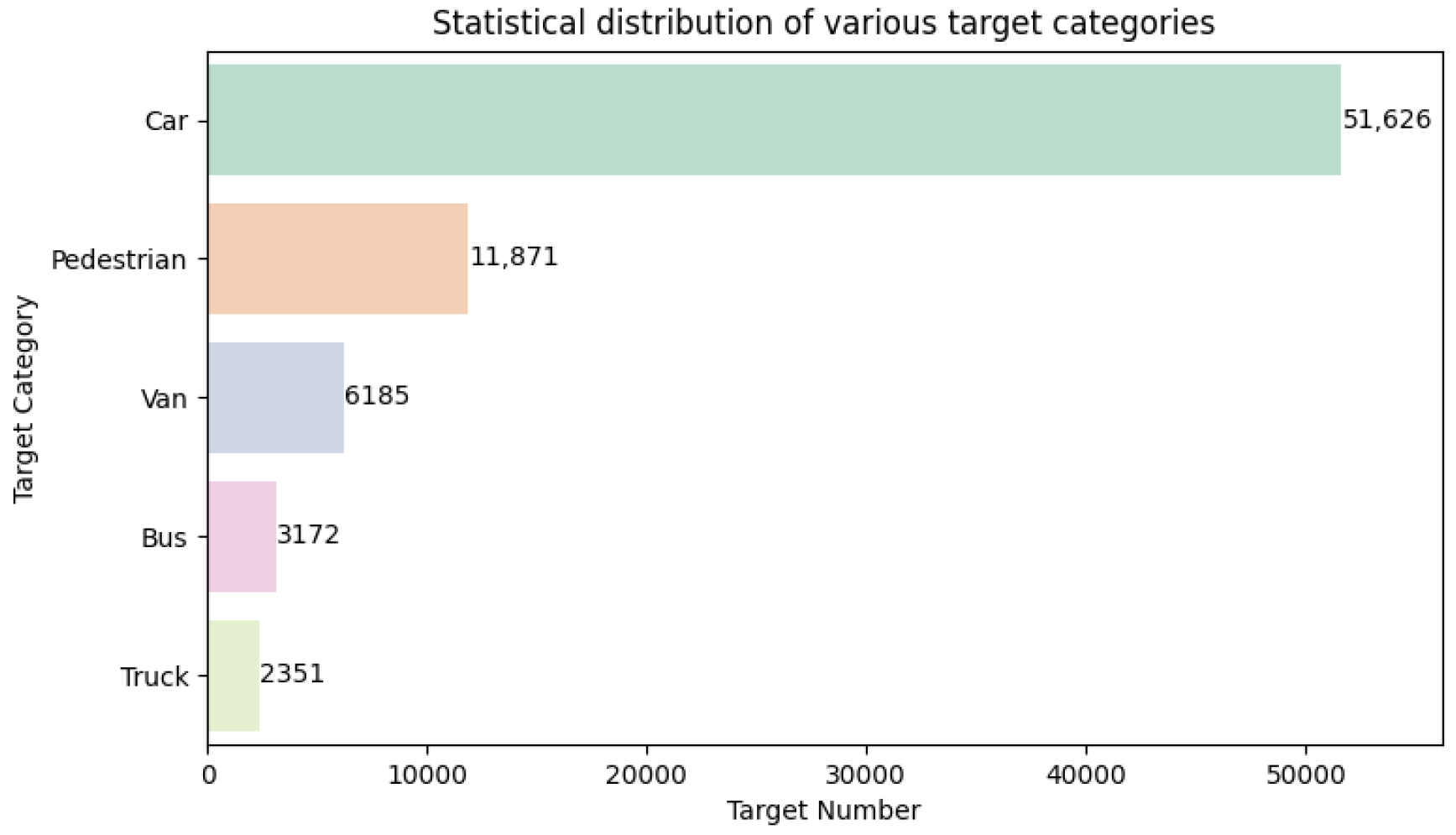
4.1. Dataset
4.2. Real-Time Data Augmentation
4.3. Experiments and Analysis
4.4. Detection Performance in Different Ranges
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cui, J.; Qiu, H.; Chen, D.; Stone, P.; Zhu, Y. Coopernaut: End-to-end driving with cooperative perception for networked vehicles. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 July 2022; pp. 17252–17262. [Google Scholar]
- Huang, J.; Huang, G.; Zhu, Z.; Ye, Y.; Du, D. Bevdet: High-performance multi-camera 3d object detection in bird-eye-view. arXiv 2021, arXiv:2112.11790. [Google Scholar]
- Yu, H.; Luo, Y.; Shu, M.; Huo, Y.; Yang, Z.; Shi, Y.; Guo, Z.; Li, H.; Hu, X.; Yuan, J.; et al. Dair-v2x: A large-scale dataset for vehicle-infrastructure cooperative 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 July 2022; pp. 21361–21370. [Google Scholar]
- Xu, R.; Xiang, H.; Tu, Z.; Xia, X.; Yang, M.H.; Ma, J. V2x-vit: Vehicle-to-everything cooperative perception with vision transformer. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 107–124. [Google Scholar]
- Adaimi, G.; Kreiss, S.; Alahi, A. Deep Visual Re-identification with Confidence. Transp. Res. Part C Emerg. Technol. 2021, 126, 103067. [Google Scholar] [CrossRef]
- Ghahremannezhad, H.; Shi, H.; Liu, C. Real-Time Accident Detection in Traffic Surveillance Using Deep Learning. In Proceedings of the 2022 IEEE International Conference on Imaging Systems and Techniques (IST), Kaohsiung, Taiwan, 21–23 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- Hu, Z.; Lam, W.H.; Wong, S.C.; Chow, A.H.; Ma, W. Turning traffic surveillance cameras into intelligent sensors for traffic density estimation. Complex Intell. Syst. 2023, 1–25. [Google Scholar] [CrossRef]
- Naphade, M.; Wang, S.; Anastasiu, D.C.; Tang, Z.; Chang, M.C.; Yao, Y.; Zheng, L.; Rahman, M.S.; Arya, M.S.; Sharma, A.; et al. The 7th AI City Challenge. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 5537–5547. [Google Scholar]
- Fernandez-Sanjurjo, M.; Bosquet, B.; Mucientes, M.; Brea, V.M. Real-Time Visual Detection and Tracking System for Traffic Monitoring; Elsevier: Amsterdam, The Netherlands, 2019; Volume 85, pp. 410–420. [Google Scholar]
- Zhang, C.; Ren, K. LRATD: A Lightweight Real-Time Abnormal Trajectory Detection Approach for Road Traffic Surveillance; Springer: Berlin/Heidelberg, Germany, 2022; Volume 34, pp. 22417–22434. [Google Scholar]
- Ghahremannezhad, H.; Shi, H.; Liu, C. Object Detection in Traffic Videos: A Survey. IEEE Trans. Intell. Transp. Syst. 2023, 24, 6780–6799. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2112.11790. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Ye, X.; Shu, M.; Li, H.; Shi, Y.; Li, Y.; Wang, G.; Tan, X.; Ding, E. Rope3d: The roadside perception dataset for autonomous driving and monocular 3d object detection task. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 July 2022; pp. 21341–21350. [Google Scholar]
- Yang, L.; Yu, K.; Tang, T.; Li, J.; Yuan, K.; Wang, L.; Zhang, X.; Chen, P. BEVHeight: A Robust Framework for Vision-based Roadside 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 21611–21620. [Google Scholar]
- Hosseiny, A.; Jahanirad, H. Hardware acceleration of YOLOv7-tiny using high-level synthesis tools. Real-Time Image Proc. 2023, 20, 75. [Google Scholar] [CrossRef]
- Chen, H.; Huang, Y.; Tian, W.; Gao, Z.; Xiong, L. Monorun: Monocular 3d object detection by reconstruction and uncertainty propagation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10379–10388. [Google Scholar]
- Ding, M.; Huo, Y.; Yi, H.; Wang, Z.; Shi, J.; Lu, Z.; Luo, P. Learning Depth-Guided Convolutions for Monocular 3D Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Reading, C.; Harakeh, A.; Chae, J.; Waslander, S.L. Categorical Depth Distribution Network for Monocular 3D Object Detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021. [Google Scholar]
- Wang, L.; Du, L.; Ye, X.; Fu, Y.; Guo, G.; Xue, X.; Feng, J.; Zhang, L. Depth-conditioned Dynamic Message Propagation for Monocular 3D Object Detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021. [Google Scholar]
- Wang, Y.; Chao, W.L.; Garg, D.; Hariharan, B.; Campbell, M.; Weinberger, K.Q. Pseudo-lidar from visual depth estimation: Bridging the gap in 3D object detection for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 8445–8453. [Google Scholar]
- Carrillo, J.; Waslander, S. Urbannet: Leveraging urban maps for long range 3D object detection. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 3799–3806. [Google Scholar]
- Weng, X.; Kitani, K. Monocular 3D Object Detection with Pseudo-LiDAR Point Cloud. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 857–866. [Google Scholar]
- Mousavian, A.; Anguelov, D.; Flynn, J.; Kosecka, J. 3D bounding box estimation using deep learning and geometry. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 7074–7082. [Google Scholar]
- Ma, X.; Liu, S.; Xia, Z.; Zhang, H.; Zeng, X.; Ouyang, W. Rethinking pseudo-lidar representation. In Computer Vision–ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 311–327. [Google Scholar]
- Ye, X.; Du, L.; Shi, Y.; Li, Y.; Tan, X.; Feng, J.; Ding, E.; Wen, S. Monocular 3D Object Detection via Feature Domain Adaptation. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; pp. 17–34. [Google Scholar]
- Brazil, G.; Liu, X. M3D-RPN: Monocular 3D Region Proposal Network for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November.
- Ma, X.; Zhang, Y.; Xu, D.; Zhou, D.; Yi, S.; Li, H.; Ouyang, W. Delving into localization errors for monocular 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 4721–4730. [Google Scholar]
- Liu, X.; Xue, N.; Wu, T. Learning Auxiliary Monocular Contexts Helps Monocular 3D Object Detection. AAAI Proc. Aaai Conf. Artif. Intell. 2022, 36, 1810–1818. [Google Scholar] [CrossRef]
- Zhang, Y.; Lu, J.; Zhou, J. Objects are Different: Flexible Monocular 3D Object Detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021. [Google Scholar]
- Zhou, X.; Koltun, V.; Krähenbühl, P. Tracking objects as points. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 474–490. [Google Scholar]
- Simonelli, A.; Bulo, S.R.; Porzi, L.; López-Antequera, M.; Kontschieder, P. Disentangling monocular 3D object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1991–1999. [Google Scholar]
- Liu, Z.; Wu, Z.; Tóth, R. Smoke: Single-stage monocular 3D object detection via keypoint estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 996–997. [Google Scholar]
- Zhou, X.; Karpur, A.; Gan, C.; Luo, L.; Huang, Q. Unsupervised domain adaptation for 3D keypoint estimation via view consistency. In Proceedings of the European Conference on Computer Vision (ECCV); Springer: Berlin/Heidelberg, Germany, 2018; pp. 137–153. [Google Scholar]
- Li, Z.; Chen, Z.; Li, A.; Fang, L.; Jiang, Q.; Liu, X.; Jiang, J. Unsupervised domain adaptation for monocular 3D object detection via self-training. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2022; pp. 245–262. [Google Scholar]
- Adam, M.G.; Piccolrovazzi, M.; Eger, S.; Steinbach, E. Bounding box disparity: 3D metrics for object detection with full degree of freedom. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1491–1495. [Google Scholar]
- Li, P.; Zhao, H.; Liu, P.; Cao, F. RTM3D: Real-time Monocular 3D Detection from Object Keypoints for Autonomous Driving. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; pp. 644–660. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision Meets Robotics: The Kitti Dataset; Sage Publications: London, UK, 2013; Volume 32, pp. 1231–1237. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | AP3D/IoU = 0.5 | Params (M) | GFlops | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Car | Van | Bus | Truck | Cyclist | Motorcyclist | Tricyclist | Pedestrian | ||||
| KM3D | ResNet34 | 8.97 | 7.77 | 3.97 | 4.94 | 11.81 | 11.35 | 10.39 | 12.61 | 26.881 | 422.276 |
| Kinematic3D | DenseNet121 | 11.42 | 10.65 | 4.02 | 4.83 | 11.35 | 15.08 | 11.24 | 14.43 | 25.913 | 296.441 |
| MonoDLE | DLA34 | 12.84 | 11.21 | 4.19 | 5.25 | 13.23 | 16.58 | 11.72 | 14.75 | 20.310 | 264.898 |
| Ours Base | CSPDarknet | 11.75 | 10.98 | 1.86 | 4.50 | 14.24 | 17.46 | 11.03 | 13.19 | 37.626 | 222.563 |
| Ours+5Head | CSPDarknet | 12.25 | 10.73 | 1.78 | 3.68 | 15.45 | 18.73 | 11.66 | 14.83 | 42.235 | 87.625 |
| Ours + MSSA | CSPDarknet | 13.02 | 11.33 | 2.44 | 4.53 | 15.69 | 19.13 | 11.77 | 14.81 | 42.957 | 88.453 |
| Method | Range (m) | Score | |||
|---|---|---|---|---|---|
| Car | Big Vehicle | Cyclist | Pedestrian | ||
| MonoDLE | all | 92.8 | 86.3 | 88.5 | 92.2 |
| 0–30 | 89.8 | 84.0 | 87.1 | 92.0 | |
| 30–60 | 91.7 | 85.3 | 88.7 | 92.7 | |
| 60–90 | 92.7 | 90.9 | 88.9 | 91.9 | |
| 90–120 | 92.89 | 89.3 | 86.2 | 91.3 | |
| Ours | all | 94.4 | 89.7 | 89.1 | 91.9 |
| 0–30 | 92.8 | 86.9 | 88.5 | 91.8 | |
| 30–60 | 94.7 | 92.0 | 89.3 | 92.5 | |
| 60–90 | 94.5 | 91.9 | 88.6 | 92.4 | |
| 90–120 | 93.7 | 90.0 | 88.8 | 90.9 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, Z.; Zhang, H.; Gu, J.; Li, X. YOLOv7-3D: A Monocular 3D Traffic Object Detection Method from a Roadside Perspective. Appl. Sci. 2023, 13, 11402. https://doi.org/10.3390/app132011402
Ye Z, Zhang H, Gu J, Li X. YOLOv7-3D: A Monocular 3D Traffic Object Detection Method from a Roadside Perspective. Applied Sciences. 2023; 13(20):11402. https://doi.org/10.3390/app132011402
Chicago/Turabian StyleYe, Zixun, Hongying Zhang, Jingliang Gu, and Xue Li. 2023. "YOLOv7-3D: A Monocular 3D Traffic Object Detection Method from a Roadside Perspective" Applied Sciences 13, no. 20: 11402. https://doi.org/10.3390/app132011402
APA StyleYe, Z., Zhang, H., Gu, J., & Li, X. (2023). YOLOv7-3D: A Monocular 3D Traffic Object Detection Method from a Roadside Perspective. Applied Sciences, 13(20), 11402. https://doi.org/10.3390/app132011402