
Multi-Path Routing Algorithm Based on Deep Reinforcement Learning for SDN


Abstract
:1. Introduction
- We present TBPPO, a multi-path routing algorithm designed specifically for SDN. This innovative approach integrates a trust value mechanism based on KL-divergence and node diversity as a key security assessment criterion. TBPPO addresses network fluctuations, enhances robustness, and mitigates congestion issues, with a primary focus on countering DDoS attacks.
- We present an enhanced PPO algorithm to optimize security and efficiency in SDN routing. This novel algorithm involves the optimization of multi-path routing, considering factors like security, network delay, and variations in multi-path delays. To address the recurrent gradient explosion issues observed during the experimental process, we introduced learning rate decay and layer normalization. Furthermore, we incorporated a trust value-based routing selection approach, resulting in enhanced security stability and a reduced delay performance.
- To avoid routing loops, we abandoned the traditional Next Hop routing mechanism and adopted a path selection approach. The improved DFS uses a path selection method to choose a set of promising routes, which are called routing groups. Then, we search for the best multi-path route within these routing groups. This enhancement significantly reduces packet loss and improves the overall efficiency and practicality of the algorithm.
- Finally, we conducted experiments using the NSFNet-14 and Germany-50 network topologies. The results demonstrate that our TBPPO technique outperforms traditional approaches in terms of both convergence and overall performance. Additionally, the obtained findings emphasize TBPPO’s potential as an effective solution for improving SDN security and routing efficiency.
2. Related Works
2.1. Trust-Based Security Mechanisms
2.2. Reinforcement Learning in SDN
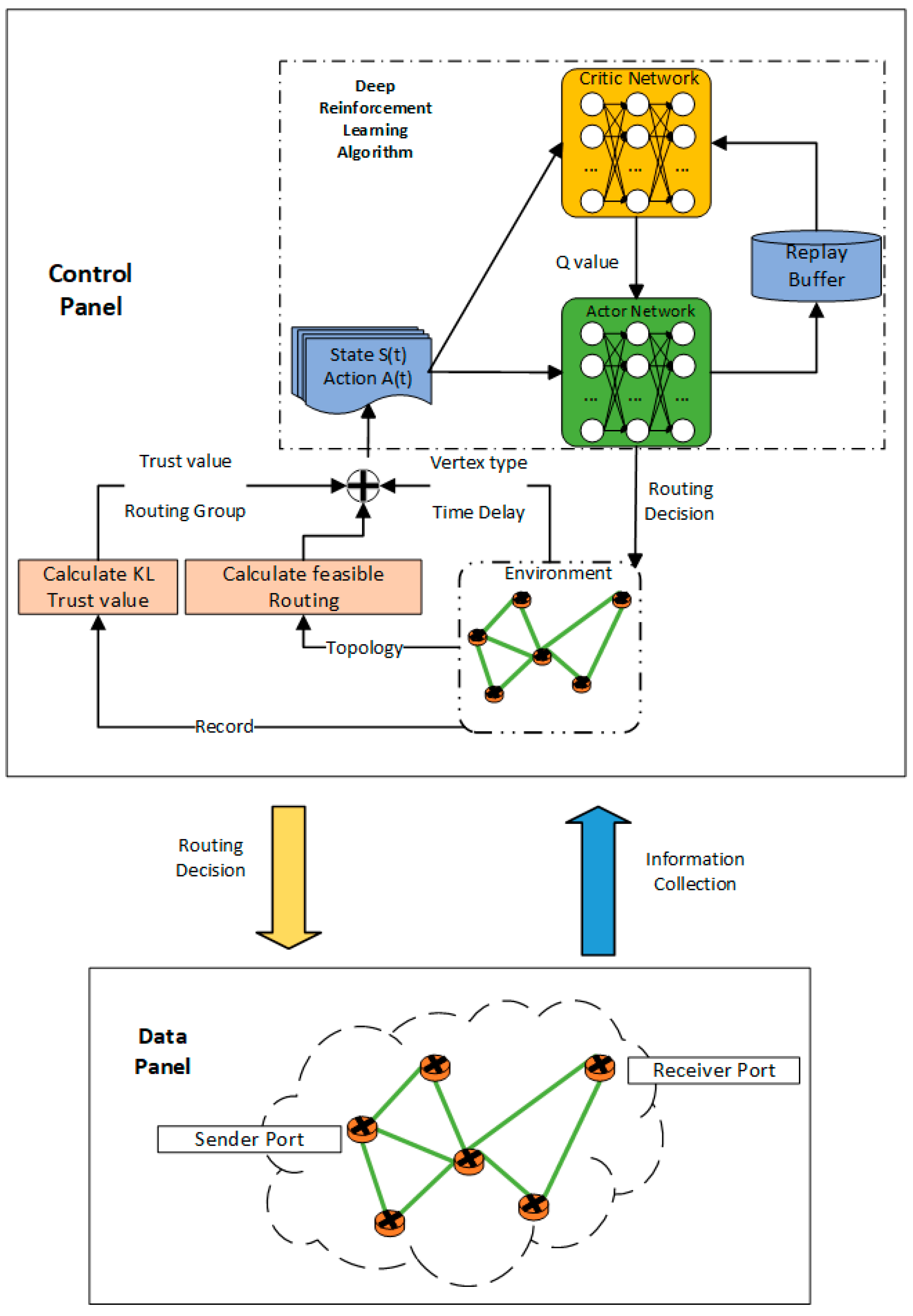
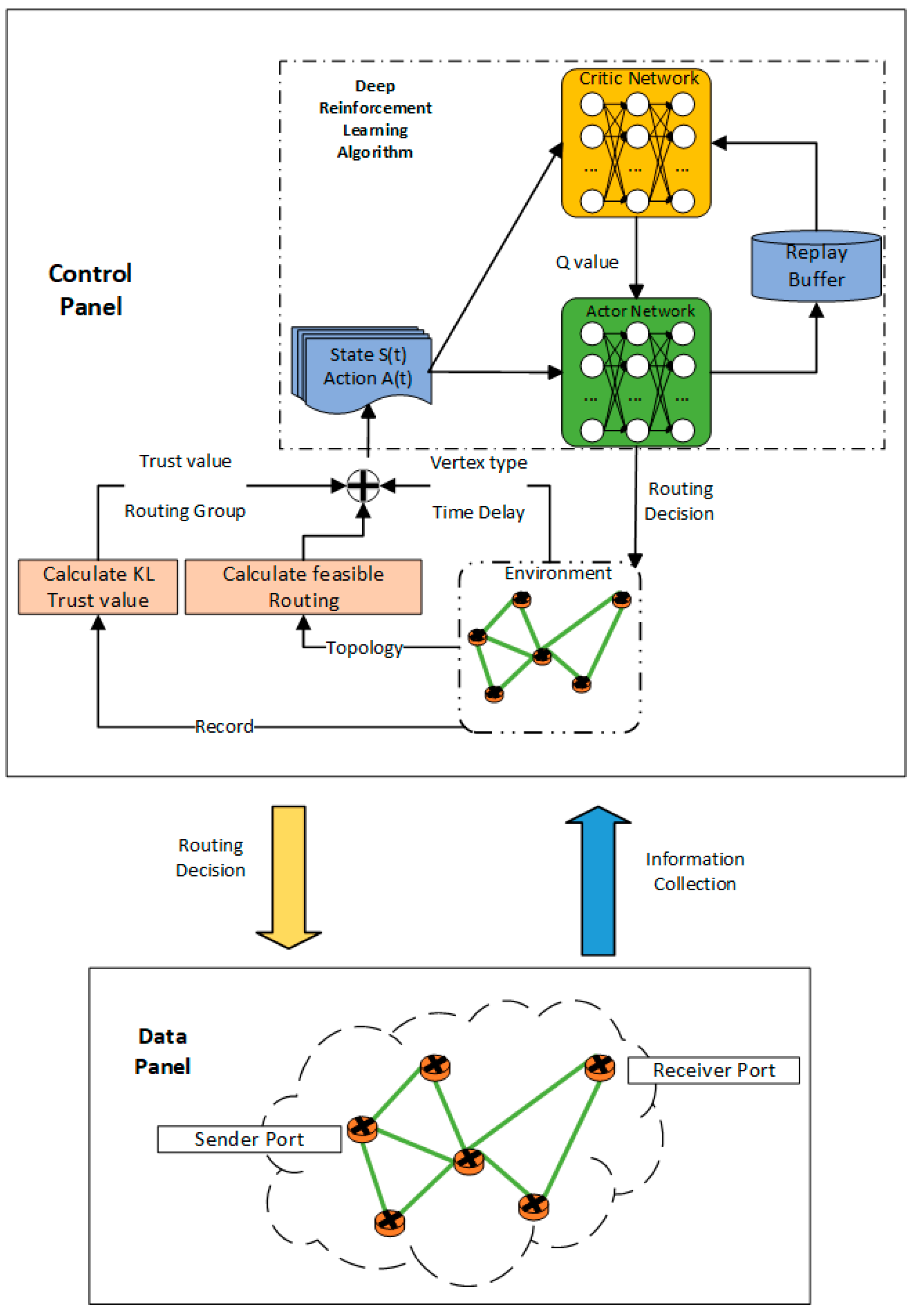
3. System Model
3.1. Network Module
3.2. Attack Module
3.3. Deep Reinforcement Learning Module
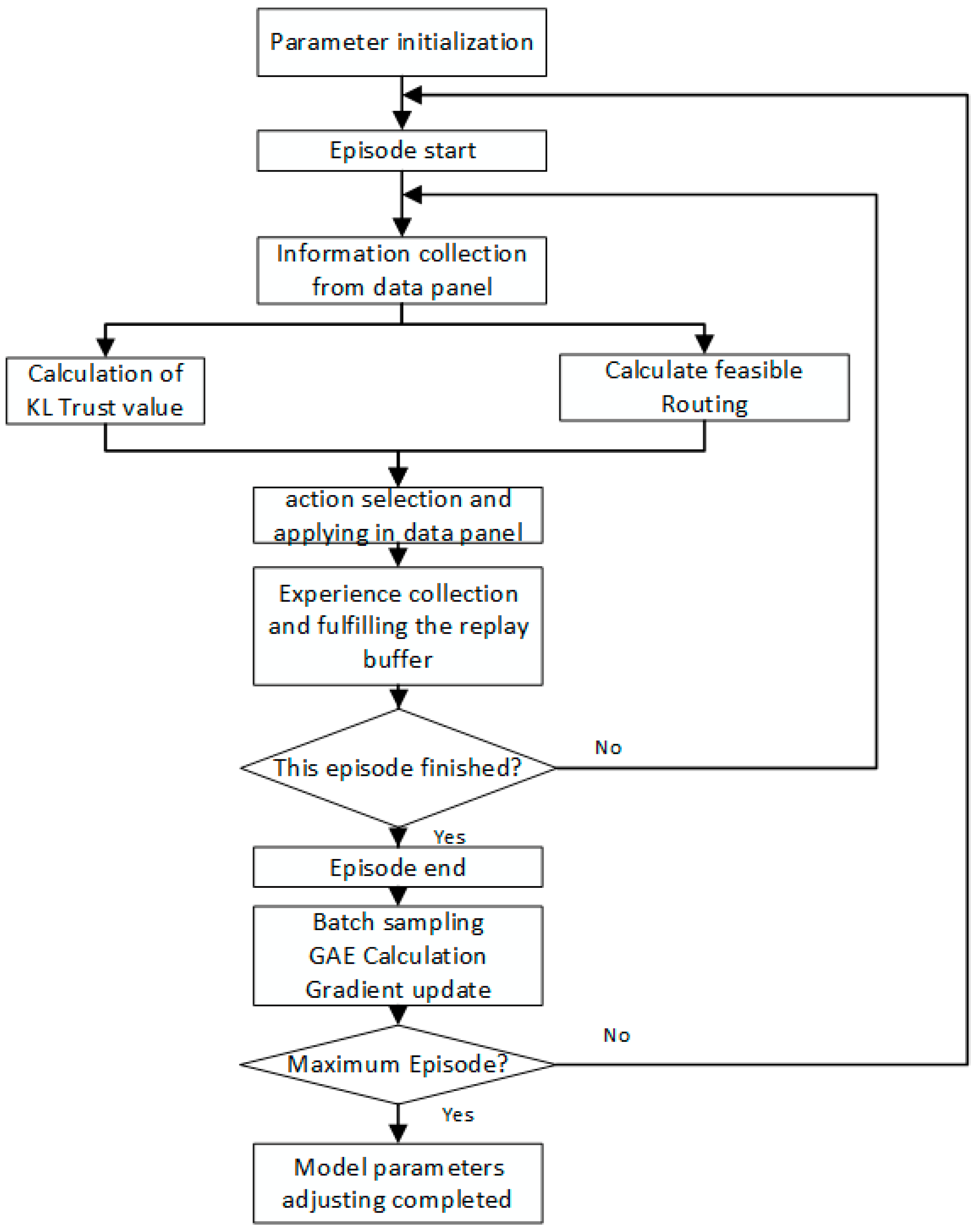
4. Trust-Based Proximal Policy Optimization (TBPPO)
4.1. The Improved DFS Module
4.2. Security Module
4.3. Markov Process Transition Module
4.4. Reward Module
4.5. Enhanced PPO Module
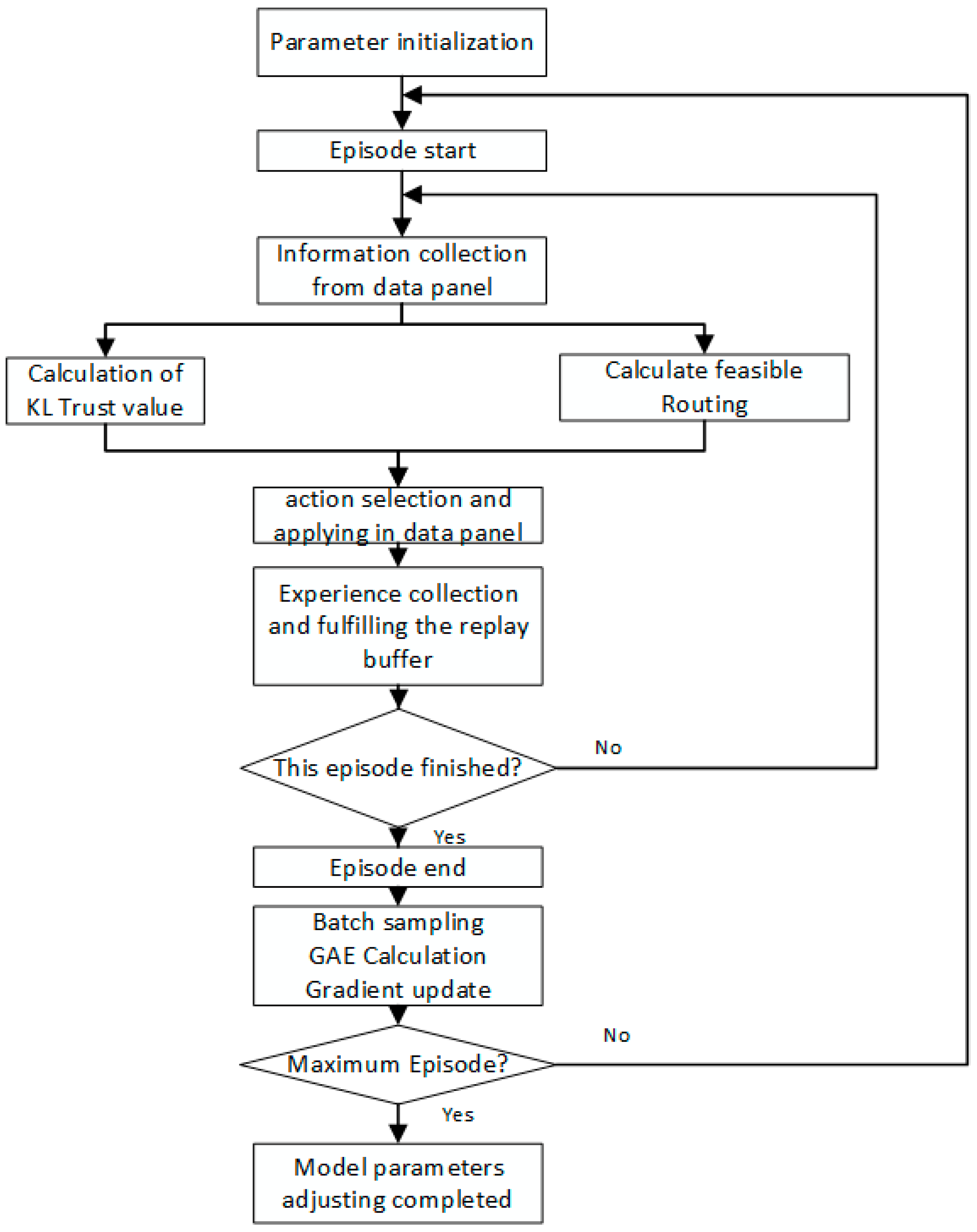
| Algorithm 1: TBPPO Routing Process |
| Input:. Output: Paths for current network. |
| Initialization:. |
| Using as input, perform the DFS algorithm to obtain the preselected path set . |
| For , ……, T do |
| Obtain from the environment under the policy . |
| Calculate trust values for all nodes using and as input. Start DRL algorithm: |
| While next state is not final state do |
| Actor network selects action |
| Calculate the reward for this action. |
| Store the current experience in the experience replay buffer. |
| End |
| Sample a batch from the experience replay buffer. |
| Calculate the TD error. |
| Calculate the advantage function |
| For epoch = 1, ……, 10 do |
| Perform proximal policy optimization |
| Update gradients for Actor and Critic networks. |
| End |
| End |
| End |
5. Results and Validation
5.1. Experiment Setup
5.2. Validation of the KL Trust Mechanism
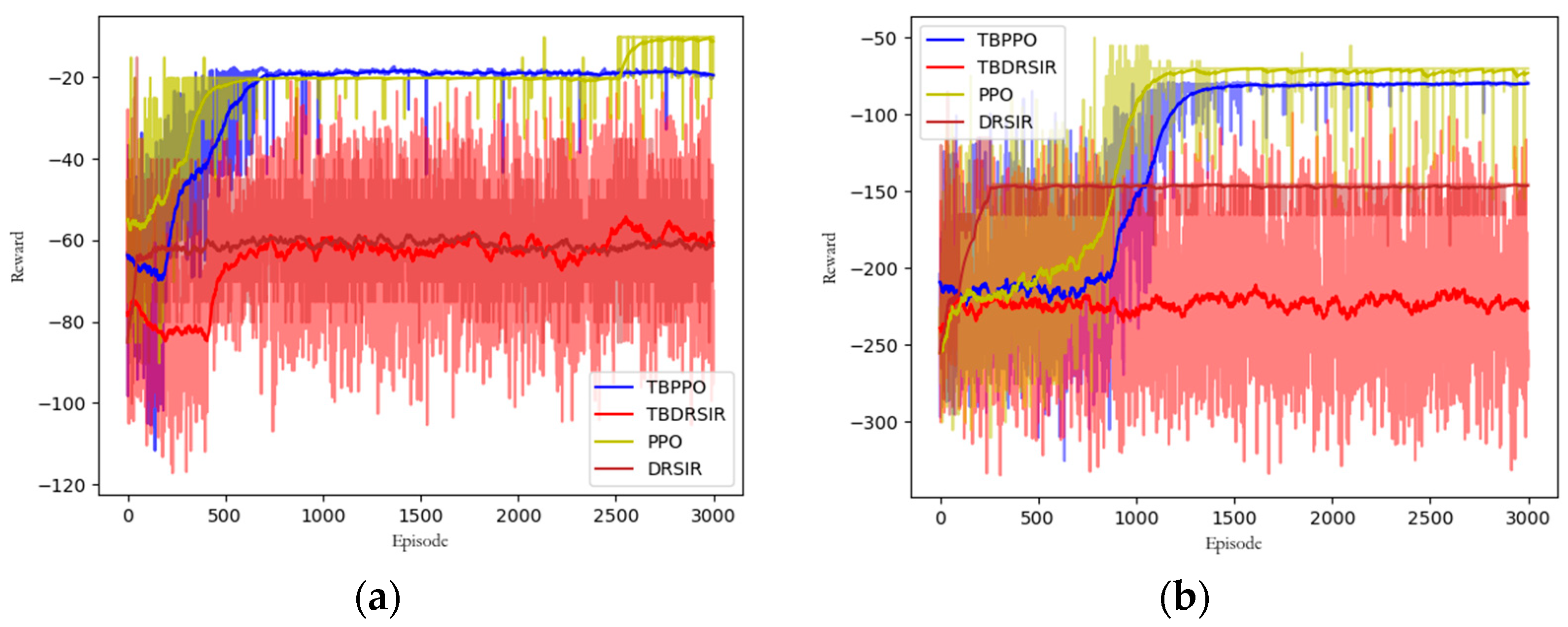
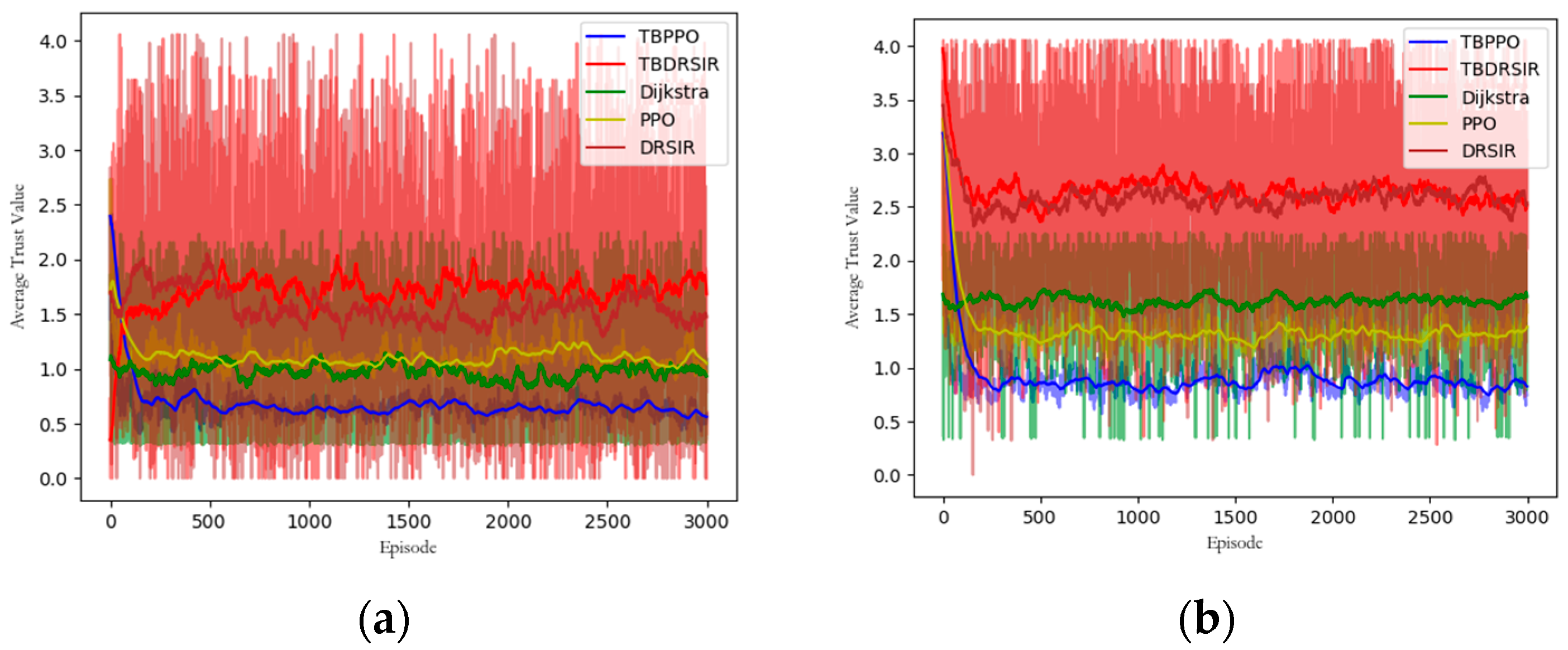
5.3. Performance Comparison
5.3.1. Baselines
- (1)
- Dijkstra Algorithm [13]: The Dijkstra algorithm is based on the weights of a graph to select paths. This algorithm is simple and feasible and is an important component of the OSPF protocol. We hope to use this algorithm to demonstrate the deviation of our algorithm’s delay portion from the theoretical optimal value and to evaluate its security performance.
- (2)
- DRSIR Algorithm [21]: The DRSIR algorithm is based on DQN’s deep reinforcement learning algorithm and its effectiveness has been thoroughly demonstrated in [21]. However, it does not explore multiple objectives. We aim to use this algorithm to showcase our algorithm’s optimization ability for multiple objectives.
- (3)
- TBDRSIR (Trust-Based DRSIR): TBDRSIR is a variant of our ablation experiment introduced to explore the performance of TBPPO. It draws inspiration from DRSIR and combines the dynamic security assessment capability we designed. We aim to test the performance of our security mechanism on other algorithms.
- (4)
- PPO Algorithm [22]: The PPO algorithm has been used to solve routing optimization problems in SDNs in [22]. Its advantage lies in its adaptability to diverse environments and good performance in terms of delay. However, the authors lacked consideration for security capabilities. Additionally, we have made improvements to PPO, enabling it to achieve a superior performance. We hope to use this algorithm as a baseline to demonstrate our algorithm’s superior security performance and better performance in terms of delay variation.
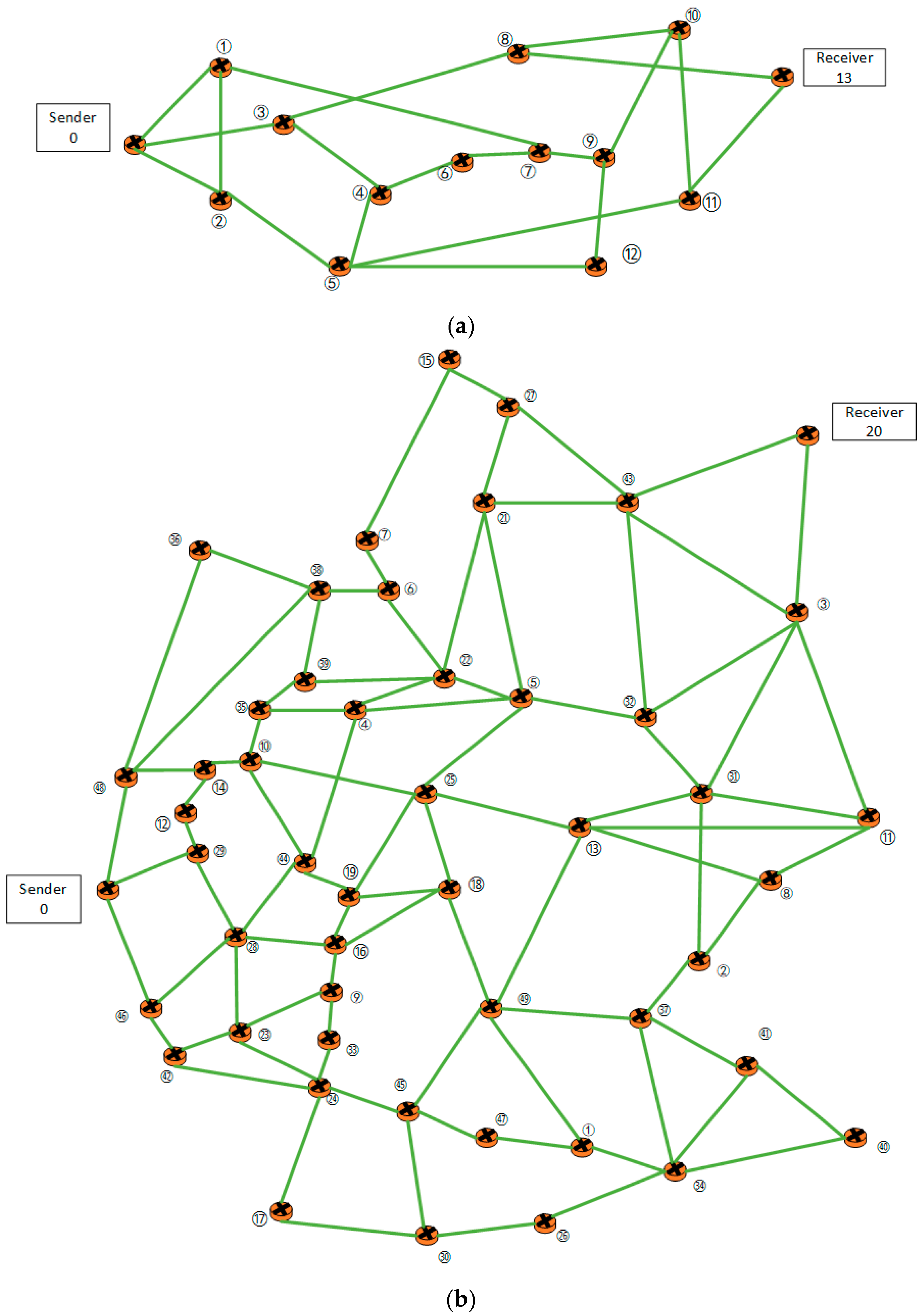
5.3.2. Network Topologies
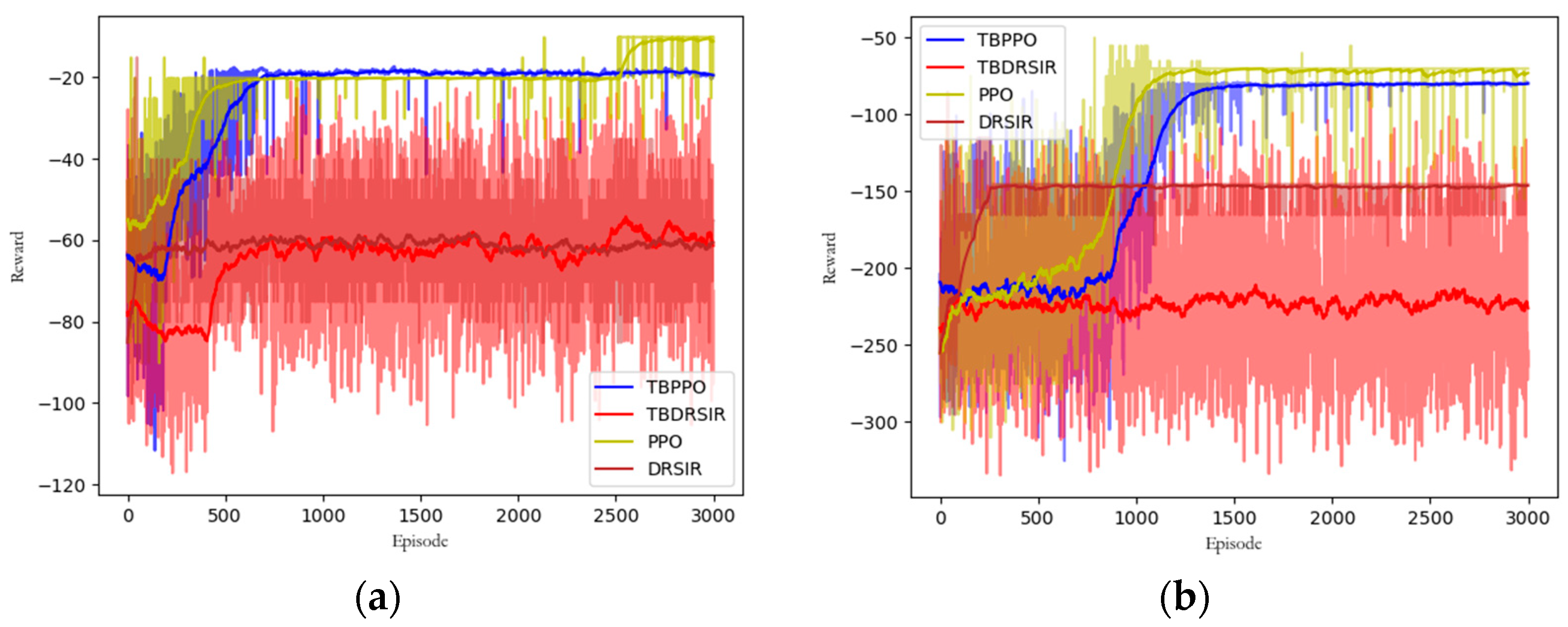
5.3.3. Convergence Comparison
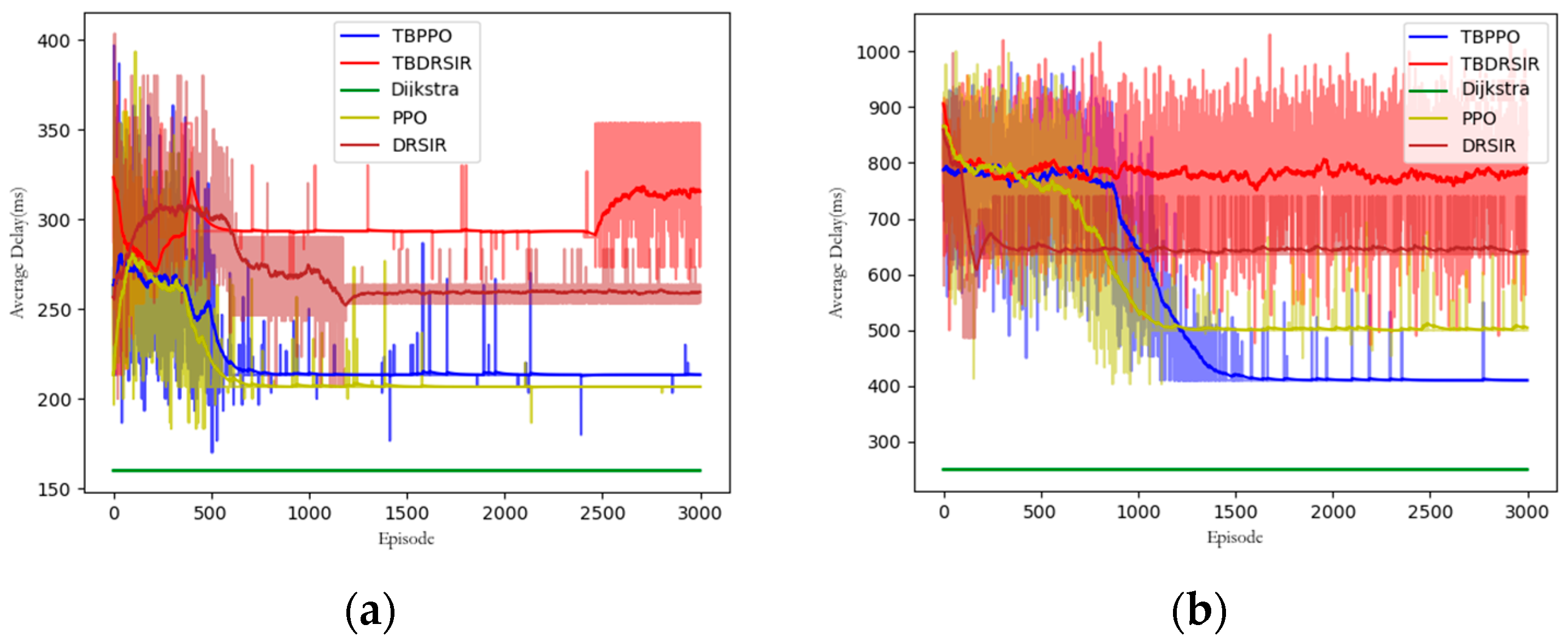
5.3.4. Delay Comparison
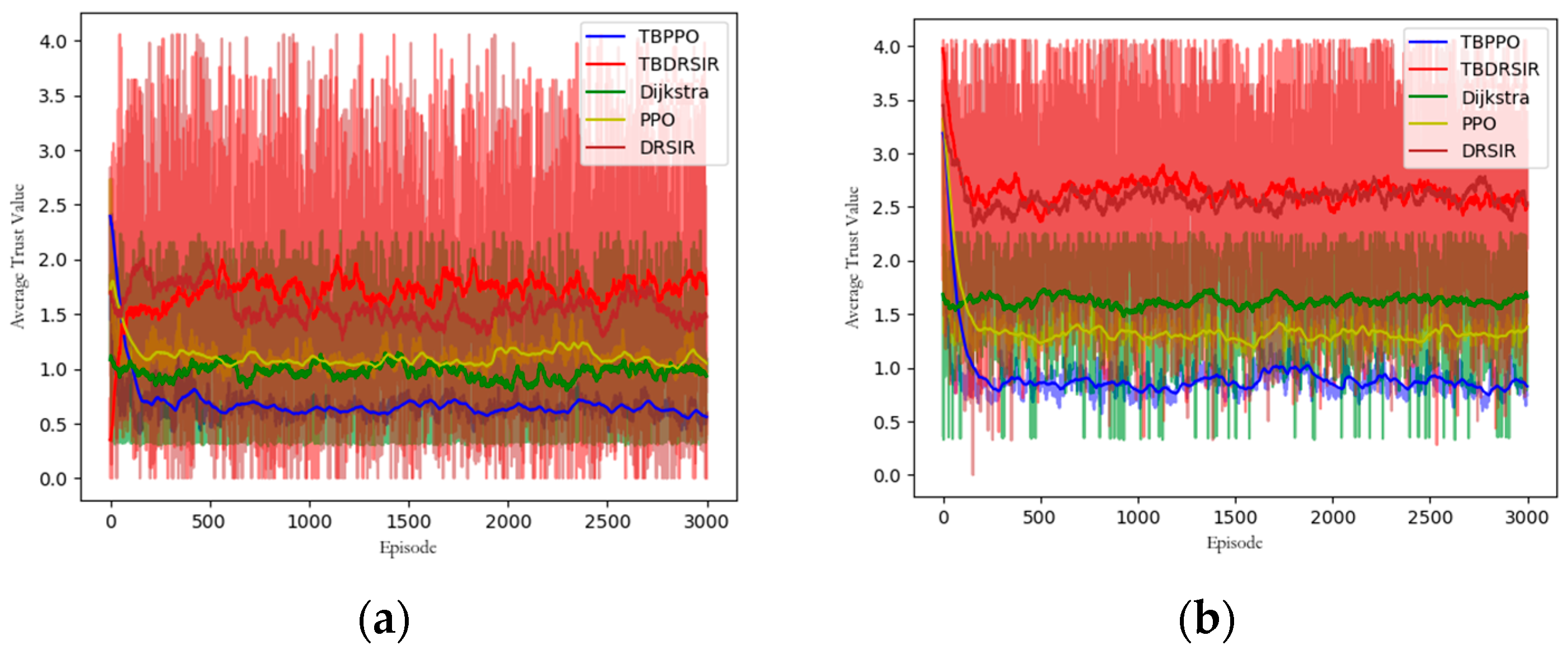
5.3.5. Trust Value Comparison
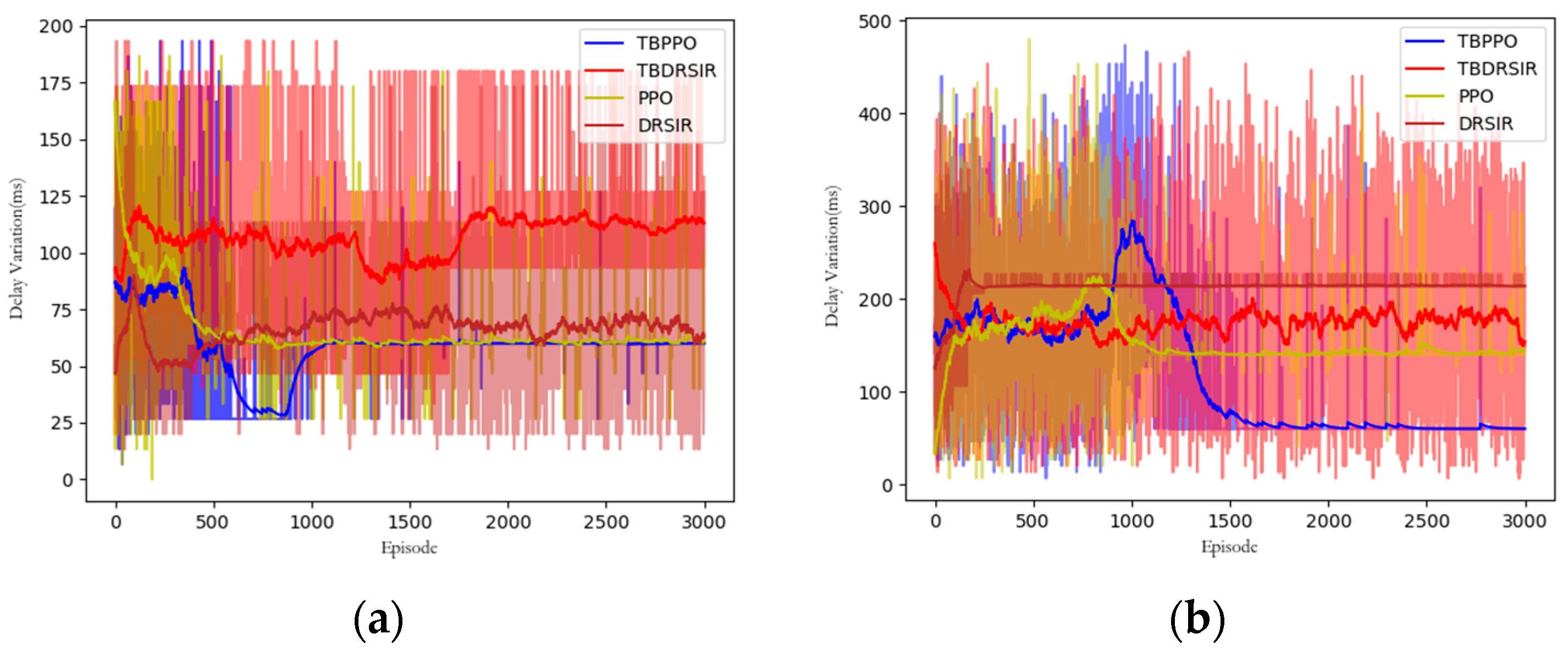
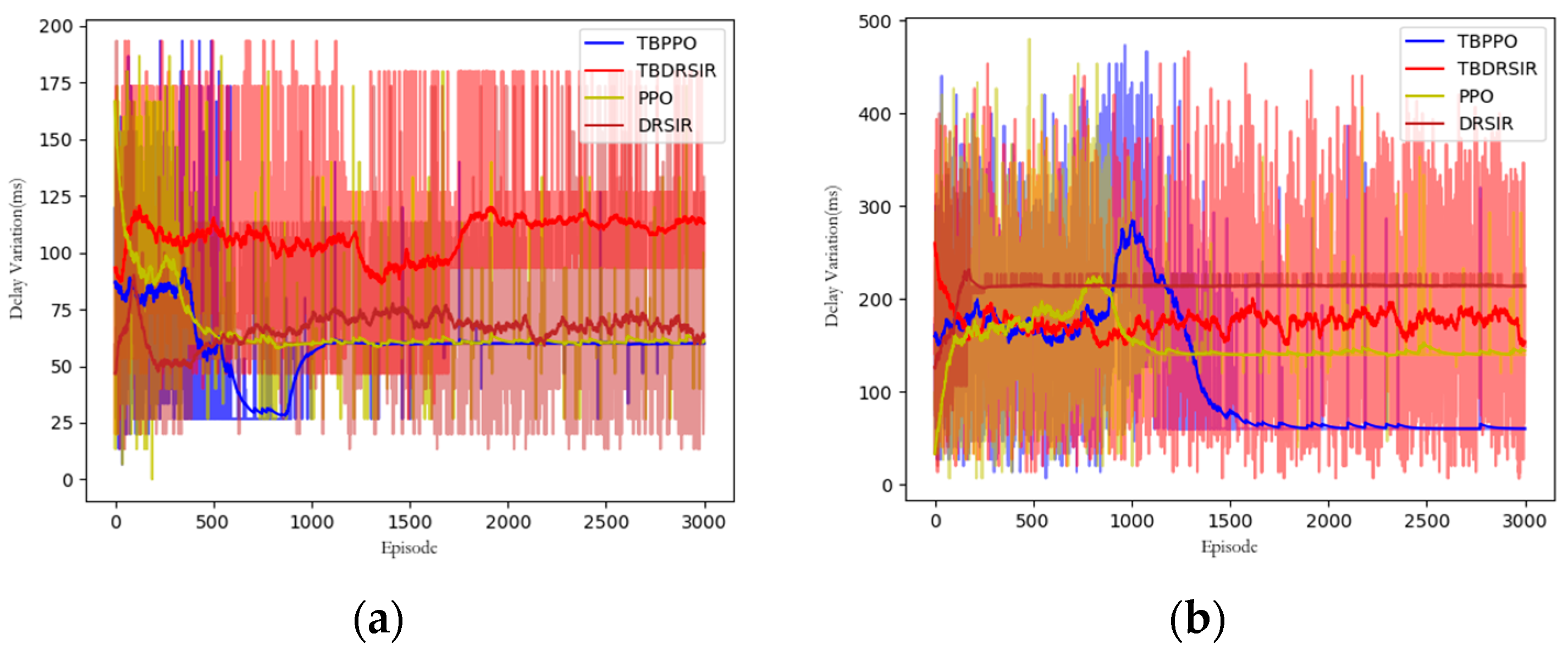
5.3.6. Delay Variation Comparison
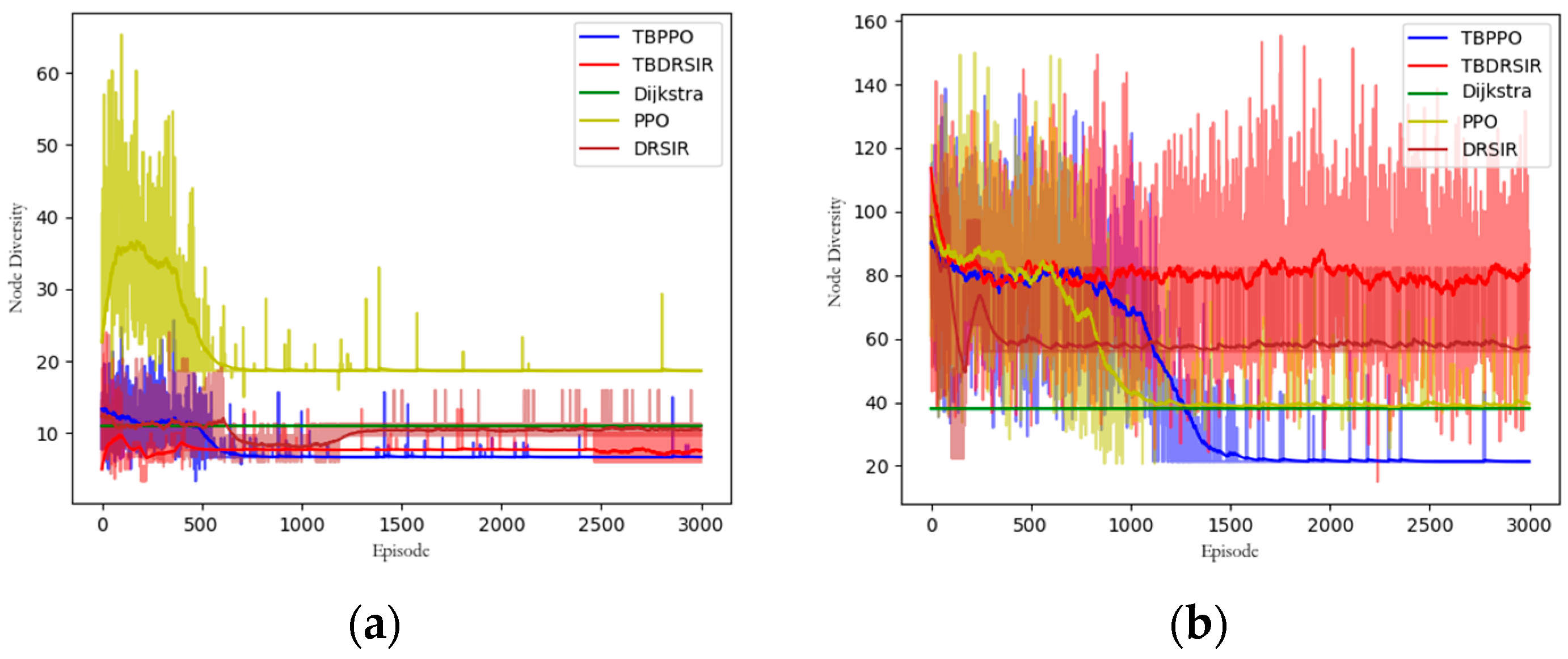
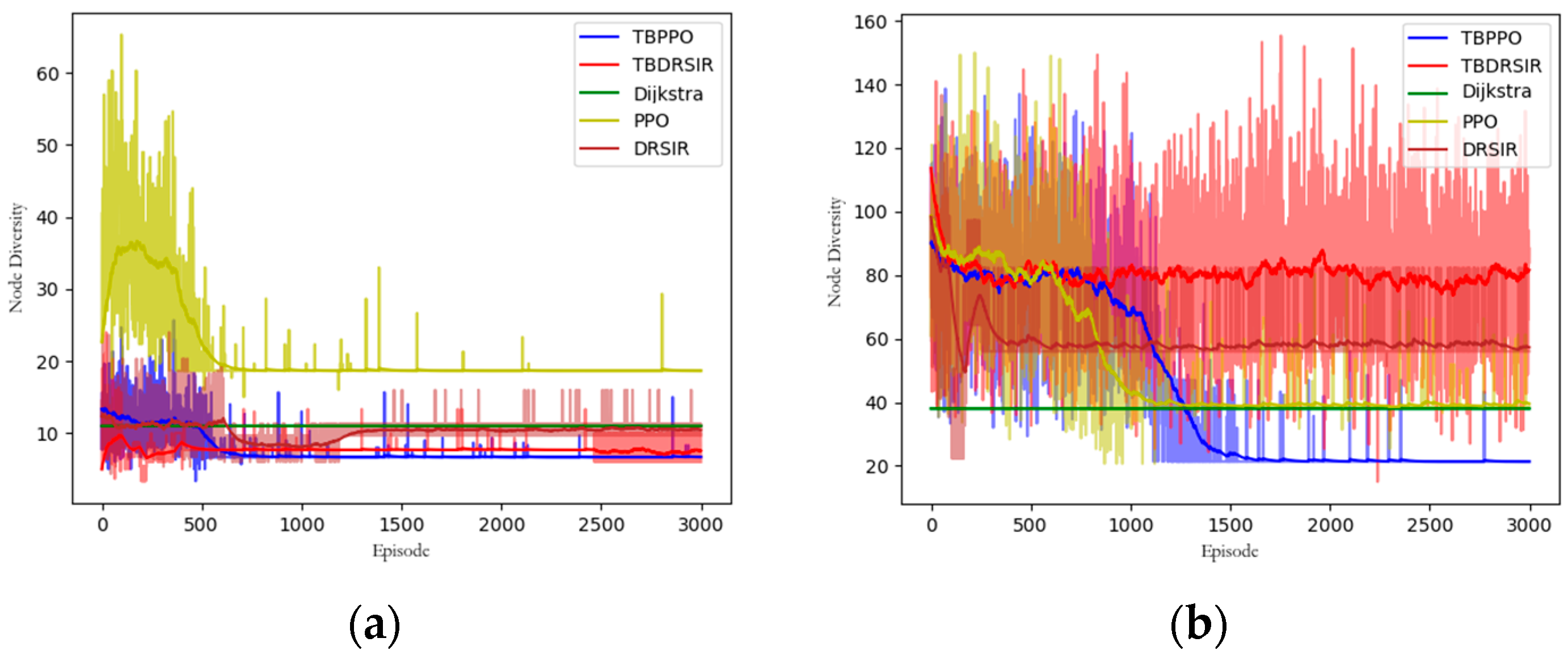
5.3.7. Node Diversity Analysis
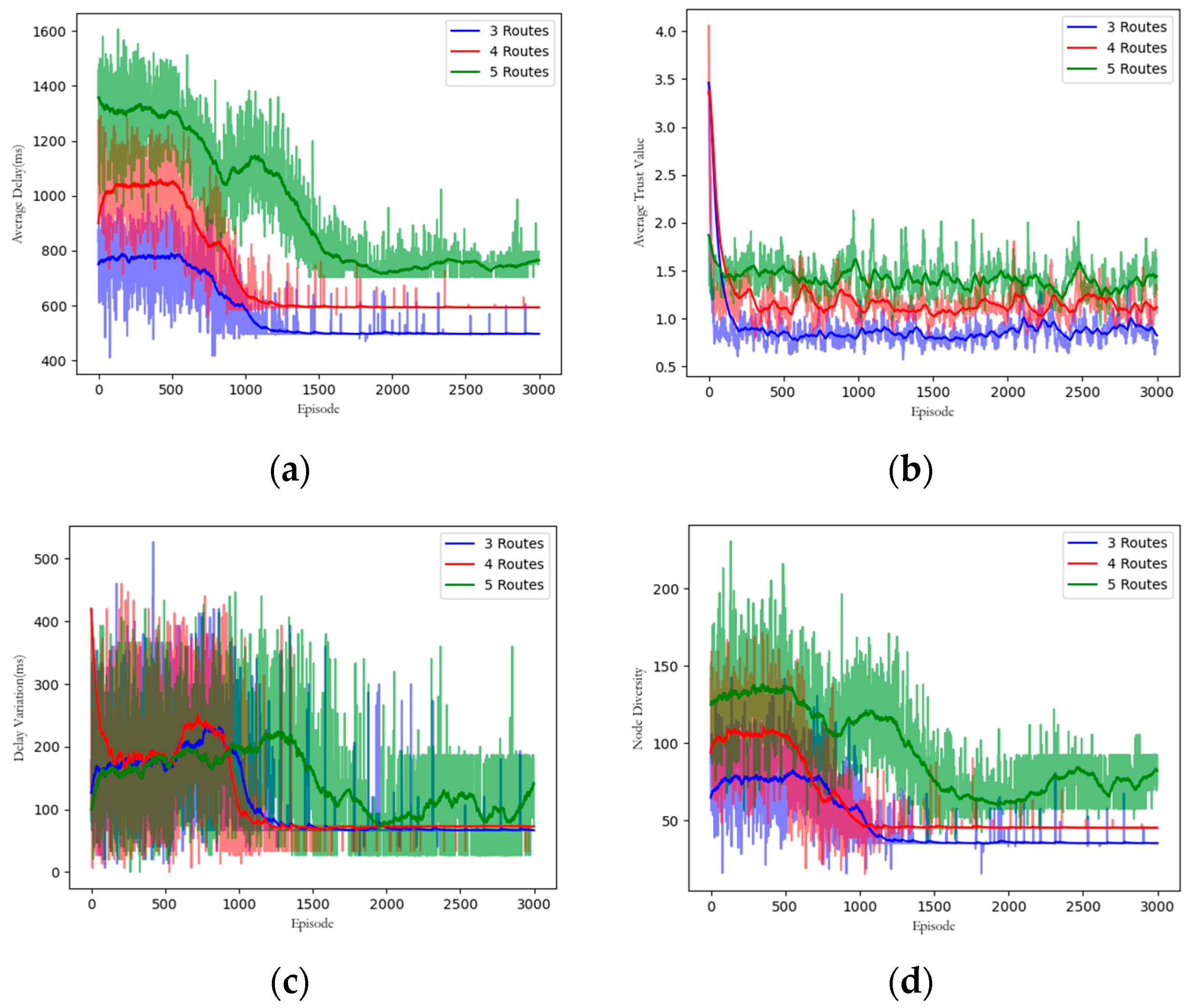
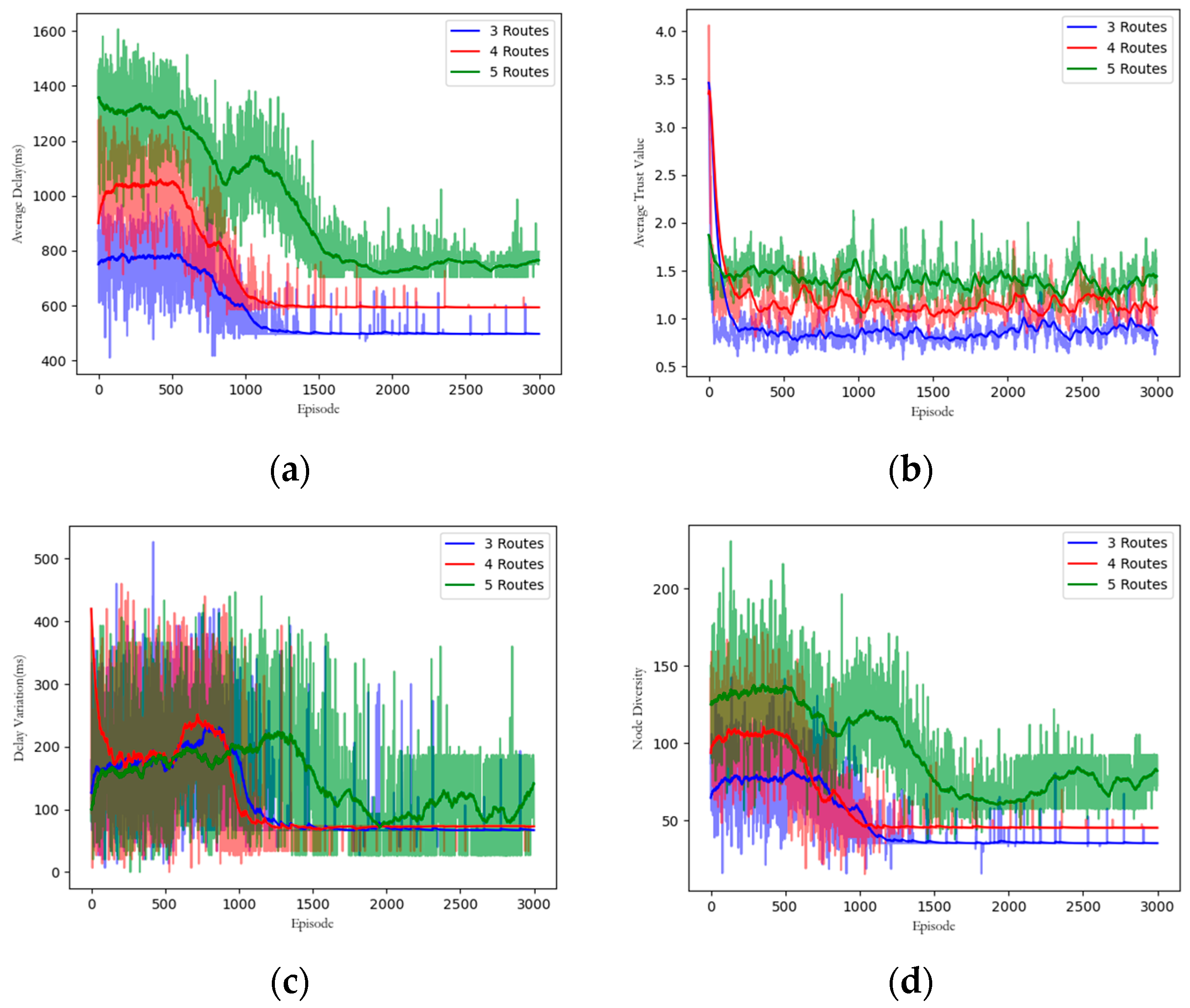
5.3.8. Multi-Path Routing Performance
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Scott-Hayward, S.; Natarajan, S.; Sezer, S. A Survey of Security in Software Defined Networks. IEEE Commun. Surv. Tutor. 2016, 18, 623–654. [Google Scholar] [CrossRef]
- Alsmadi, T.; Alqudah, N. A Survey on malware detection techniques. In Proceedings of the 2021 International Conference on Information Technology (InCIT), Amman, Jordan, 14–15 July 2021; pp. 371–376. [Google Scholar] [CrossRef]
- Yoo, Y.; Yang, G.; Lee, J.; Shin, C.; Kim, H. TeaVisor: Network Hypervisor for Bandwidth Isolation in SDN-NV. IEEE Trans Cloud Comput. 2023, 11, 2739–2755. [Google Scholar] [CrossRef]
- Pizzutti, M.; Schaeffer-Filho, A.E. An Efficient Multipath Mechanism Based on the Flowlet Abstraction and P4. In Proceedings of the IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Jin, H.; Yang, G. TALON: Tenant Throughput Allocation Through Traffic Load-Balancing in Virtualized Software-Defined Networks. In Proceedings of the International Conference on Information Networking (ICOIN), Kuala Lumpur, Malaysia, 9–11 January 2019; pp. 233–238. [Google Scholar] [CrossRef]
- Shen, L.; Wu, M.; Zhao, M. Secure Virtual Network Embedding Algorithms for a Software-Defined Network Considering Differences in Resource Value. Electronics 2022, 11, 1662. [Google Scholar] [CrossRef]
- Klöti, R.; Kotronis, V.; Smith, P. OpenFlow: A security analysis. In Proceedings of the 2013 21st IEEE International Conference on Network Protocols (ICNP), Goettingen, Germany, 7–10 October 2013; pp. 1–6. [Google Scholar] [CrossRef]
- Perrig, A.; Szewczyk, R.; Tygar, J. SPINS: Security Protocols for Sensor Networks. Wirel. Net. 2002, 8, 521–534. [Google Scholar] [CrossRef]
- Karlof, C.; Wagner, D. Secure routing in wireless sensor networks: Attacks and countermeasures. In Proceedings of the First IEEE International Workshop on Sensor Network Protocols and Applications (SNPA), Anchorage, AK, USA, 11 May 2003; pp. 113–127. [Google Scholar] [CrossRef]
- Zhou, L.; Haas, Z.J. Securing ad hoc networks. IEEE Netw. 1999, 13, 24–30. [Google Scholar] [CrossRef]
- Buchegger, S.; Boudec, J.Y.L. Performance analysis of the CONFIDANT protocol. In Proceedings of the 3rd ACM international symposium on Mobile ad hoc networking & computing (MobiHoc), New York, NY, USA, 9–11 June 2003; pp. 226–236. [Google Scholar] [CrossRef]
- Ali-Eldin, A.M.T. A cloud-based trust computing model for the social Internet of Things. In Proceedings of the 2021 International Mobile, Intelligent, and Ubiquitous Computing Conference (MIUCC), Cairo, Egypt, 9 May 2021; pp. 161–165. [Google Scholar] [CrossRef]
- Suryani, V.; Widyawan, S. A survey on trust in Internet of Things. In Proceedings of the 2016 8th International Conference on Information Technology and Electrical Engineering (ICITEE), Yogyakarta, Indonesia, 5–6 October 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Gautam, A.K.; Kumar, R. A comprehensive study on key management. Authen. Trust Manag. Tech. Wirel. Sens. Net. 2021, 3, 50. [Google Scholar] [CrossRef]
- Khan, W.Z.; Arshad, Q.; Hakak, S. Trust Management in Social Internet of Things: Architectures, Recent Advancements, and Future Challenges. IEEE Internet Things J. 2021, 8, 7768–7788. [Google Scholar] [CrossRef]
- Pourghebleh, B.; Wakil, K.; Navimipour, N.J. A Comprehensive Study on the Trust Management Techniques in the Internet of Things. IEEE Internet Things J. 2019, 6, 9326–9337. [Google Scholar] [CrossRef]
- Jiang, J.R.; Huang, H.W.; Liao, J.H.; Chen, S.Y. Extending Dijkstra’s shortest path algorithm for software defined networking. In Proceedings of the 16th Asia-Pacific Network Operations and Management Symposium (APNOMS), Hsinchu, Taiwan, 17–19 September 2014; pp. 1–4. [Google Scholar] [CrossRef]
- Wu, Y.J.; Hwang, P.C.; Hwang, W.S. Artificial Intelligence Enabled Routing in Software Defined Networking. Appl. Sci. 2020, 10, 6564. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D. Playing Atari with deep reinforcement learning. In Proceedings of the Neural Information Processing Systems Conference and Workshops (NIPS), Lake Tahoe, CA, USA, 5–10 December 2013; pp. 529–536. [Google Scholar] [CrossRef]
- Schulman, J.; Moritz, P.; Levine, S. High-Dimensional Continuous Control Using Generalized Advantage Estimation. arXiv 2015, arXiv:1506.02438. [Google Scholar] [CrossRef]
- Xiang, J.; Li, Q.; Dong, X. Continuous Control with Deep Reinforcement Learning for Mobile Robot Navigation. In Proceedings of the 2019 Chinese Automation Congress (CAC), Hangzhou, China, 22–24 November 2019; pp. 1501–1506. [Google Scholar] [CrossRef]
- Schulman, J.; Levine, S.; Moritz, P. Trust Region Policy Optimization. In Proceedings of the 32nd International Conference on International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015; pp. 1889–1897. [Google Scholar] [CrossRef]
- Du, J.; Zhang, C.; He, S. Learning-Based Congestion Control Assisted by Recurrent Neural Networks for Real-Time Communication. In Proceedings of the 2023 IEEE Symposium on Computers and Communications (ISCC), Gammarth, Tunisia, 9–12 July 2023; pp. 323–328. [Google Scholar] [CrossRef]
- Chen, J.; Xiao, Z.; Xing, H. STDPG: A Spatio-Temporal Deterministic Policy Gradient Agent for Dynamic Routing in SDN. In Proceedings of the 2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Casas-Velasco, D.M.; Rendon, O.M.C.; da Fonseca, N.L.S. DRSIR: A Deep Reinforcement Learning Approach for Routing in Software-Defined Networking. IEEE Trans. Net. Serv. Manag. 2021, 19, 4807–4820. [Google Scholar] [CrossRef]
- Alkhalaf, S.; Alturise, F. A novel method for routing optimization in software-defined networks. Comput. Mat. Cont. 2022, 73, 6393–6405. [Google Scholar] [CrossRef]
- Kullback, S.; Leibler, R.A. The Information in Distributions. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Iqbal, A.; Zubair, M.; Khan, M.A.; Ullah, I.; Ur-Rehman, G.; Shvetsov, A.V.; Noor, F. An Efficient and Secure Certificateless Aggregate Signature Scheme for Vehicular Ad hoc Networks. Future Internet 2023, 15, 266. [Google Scholar] [CrossRef]
- Abidi, R.; Azzouna, N.B. Self-adaptive trust management model for social IoT services. In Proceedings of the 2021 International Symposium on Networks, Computers and Communications (ISNCC), Dubai, United Arab Emirates, 31 October–2 November 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Magdich, R.; Jemal, H.; Nakti, C. An efficient trust related attack detection model based on machine learning for social Internet of Things. In Proceedings of the 2021 International Wireless Communications and Mobile Computing (IWCMC), Harbin City, China, 28 June–2 July 2021; pp. 1465–1470. [Google Scholar] [CrossRef]
- Amiri-Zarandi, M.; Dara, R.A.; Fraser, E. LBTM: A lightweight blockchain-based trust management system for social Internet of Things. J. Supercom. 2022, 78, 8302–8320. [Google Scholar] [CrossRef]
- Wang, X.; Zhong, X.; Li, L. TOT: Trust aware opportunistic transmission in cognitive radio social Internet of Things. Comput. Commun. 2020, 162, 1–11. [Google Scholar] [CrossRef]
- Farahbakhsh, B.; Fanian, A.; Manshaei, M.H. TGSM: Towards trustworthy group-based service management for social IoT. Internet Things 2021, 13, 100312. [Google Scholar] [CrossRef]
- Ashwin, M.; Kamalraj, S.; Azath, M. Weighted Clustering Trust Model for Mobile Ad Hoc Networks. Wirel. Pers. Commun. 2017, 94, 2203–2212. [Google Scholar] [CrossRef]
- Rajeswari, A.R.; Kulothungan, K.; Ganapathy, S. A trusted fuzzy based stable and secure routing algorithm for effective communication in mobile adhoc networks. Peer-to-Peer Net. Appl. 2019, 12, 1076–1096. [Google Scholar] [CrossRef]
- Zhang, T.; Yan, L.; Yang, Y. Trust evaluation method for clustered wireless sensor networks based on cloud model. Wirel. Net. 2016, 24, 777–797. [Google Scholar] [CrossRef]
- Mingwu, Z.; Bo, Y.; Yu, Q. Using Trust Metric to Detect Malicious Behaviors in WSNs. In Proceedings of the Eighth ACIS International Conference on Software Engineering, Artificial Intelligence, Networking, and Parallel/Distributed Computing (SNPD), Qingdao, China, 30 July–1 August 2007; pp. 104–108. [Google Scholar] [CrossRef]
- Sagar, S.; Mahmood, A.; Sheng, M. Towards a Machine Learning-driven Trust Evaluation Model for Social Internet of Things: A Time-aware Approach. In Proceedings of the 17th EAI International Conference on Mobile and Ubiquitous Systems: Computing, Networking and Services (MobiQuitous), New York, NY, USA, 7–9 December 2020; pp. 283–290. [Google Scholar] [CrossRef]
- Sagar, S.; Mahmood, A.; Sheng, Q.Z.; Zhang, W.E. Trust Computational Heuristic for Social Internet of Things: A Machine Learning-based Approach. In Proceedings of the IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Marche, C.; Nitti, M. Trust-Related Attacks and Their Detection: A Trust Management Model for the Social IoT. IEEE Trans. Net. Serv. Manag. 2020, 18, 3297–3308. [Google Scholar] [CrossRef]
- Jafarian, B.; Yazdani, N.; Haghighi, M.S. Discrimination-aware trust management for social internet of things. Comp. Net. Inter. J. Comp. Tel. Net. 2020, 178, 11. [Google Scholar] [CrossRef]
- Abdelghani, W.; Amous, I.; Zayani, C.A.; Sèdes, F. Dynamic and scalable multi-level trust management model for Social Internet of Things. J. Supercomput. 2022, 78, 8137–8193. [Google Scholar] [CrossRef]
- Abadi, A.F.E.; Asghari, S.A.; Marvasti, M.B.; Abaei, G. RLBEEP: Reinforcement-Learning-Based Energy Efficient Control and Routing Protocol for Wireless Sensor Networks. IEEE Access 2022, 10, 44123–44135. [Google Scholar] [CrossRef]
- Chen, C.; Xue, F.; Lu, Z. RLMR: Reinforcement Learning Based Multipath Routing for SDN. Wirel. Commun. Mob. Comp. 2022, 2022, 5124960. [Google Scholar] [CrossRef]
- Yao, H.; Mai, T.; Xu, X.; Zhang, P.; Li, M. NetworkAI: An intelligent network architecture for self-learning control strategies in software defined networks. IEEE Internet Things J. 2018, 5, 4319–4327. [Google Scholar] [CrossRef]
- Chen, Y.R.; Rezapour, A.; Tzeng, W.G. RL-Routing: An SDN Routing Algorithm Based on Deep Reinforcement Learning. IEEE Trans. Net. Sci. Eng. 2020, 7, 3185–3199. [Google Scholar] [CrossRef]
- Li, Z.; Wang, X.; Pan, L. Network Topology Optimization via Deep Reinforcement Learning. IEEE Trans. Commun. 2022, 71, 2847–2859. [Google Scholar] [CrossRef]
- Guo, X.; Lin, H.; Li, Z.; Peng, M. Deep-Reinforcement-Learning-Based QoS-Aware Secure Routing for SDN-IoT. IEEE Internet Things J. 2020, 7, 6242–6251. [Google Scholar] [CrossRef]
- Wang, J.; Liu, J.; Guo, H.; Mao, B. Deep Reinforcement Learning for Securing Software-Defined Industrial Networks with Distributed Control Plane. IEEE Trans. Ind. Infor. 2022, 18, 4275–4285. [Google Scholar] [CrossRef]
- Xu, Q.; Zhang, Y.; Wu, K.; Wang, J. Evaluating and Boosting Reinforcement Learning for Intra-Domain Routing. In Proceedings of the IEEE 16th International Conference on Mobile Ad Hoc and Sensor Systems (MASS), Monterey, CA, USA, 4–7 November 2019; pp. 265–273. [Google Scholar] [CrossRef]
- Douligeris, C.; Mitrokotsa, A. DDoS attacks and defense mechanisms: A classification. In Proceedings of the 3rd IEEE International Symposium on Signal Processing and Information Technology (ISSPRT), Darmstadt, Germany, 17 December 2003; pp. 190–193. [Google Scholar] [CrossRef]
- Zargar, S.T.; Joshi, J.; Tipper, D. A Survey of Defense Mechanisms Against Distributed Denial of Service (DDoS) Flooding Attacks. IEEE Commun. Sur. Tutor. 2013, 15, 2046–2069. [Google Scholar] [CrossRef]
- Vishwakarma, R.; Jain, A.K. A survey of DDoS attacking techniques and defence mechanisms in the IoT network. Telecom. Syst. 2020, 73, 3–25. [Google Scholar] [CrossRef]
- Mycek, M.; Secci, S.; Pióro, M.; Rougier, J.-L. Cooperative multi-provider routing optimization and income distribution. In Proceedings of the 7th International Workshop on Design of Reliable Communication Networks (DRCN), Washington, DC, USA, 25–28 October 2009; pp. 281–288. [Google Scholar] [CrossRef]
- Jimmy, L.B.; Jamie, R.K.; Geoffrey, E.H. Layer Normalization. arXiv 2016. [Google Scholar] [CrossRef]
- Aslansefat, K.; Khanh, N.Q.; Rastogi, O. CICIDS2017: Intrusion Detection Evaluation Dataset. 2019. Available online: https://www.kaggle.com/datasets/cicdataset/cicids2017 (accessed on 16 October 2023).
- Suárez-Varela, J. NSFNet Topology. 2019. Available online: http://knowledgedefinednetworking.org/data/datasets_v0/nsfnet.tar.gz (accessed on 16 October 2023).
- Rusek, K. Germany50 Topology. 2020. Available online: http://knowledgedefinednetworking.org/data/datasets_v1/germany50bw.tar.gz (accessed on 16 October 2023).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Description | Learning Approach | Action | Performance Metrics |
|---|---|---|---|---|
| [25] | DRSIR: A DQN-based solution for intelligent routing in SDN based on path-state metrics. | DQN | Path Selection | Delay, Loss and Throughput |
| [26] | A DRL-based method, which can maximize numerous objectives to dynamically update the routing strategy. | PPO | Next Hop | Average Delay, Maximum Delay |
| [43] | RLBeep: A RL-based method to increase the lifetime in wireless sensor networks. | Q-Learning | Next Hop | First node death time |
| [44] | RLMR: A Q-Learning based method performs routing for different flows, based on the real-time information of network state and flow characteristics. | Q-Learning | Next Hop | Forwarding Efficiency, Loss rate, |
| [45] | NetworkAI: A network architecture using network monitoring technologies and artificial intelligence for generating control policies. | DQN | Next Hop | Delay |
| [46] | RLRouting: a reinforcement learning routing algorithm solving traffic engineering (TE) problem of SDN in terms of throughput and delay. | Dueling DDQN | Next Hop | Utilization rate, Delay and CPU Usage |
| [47] | DRL-GS: A DRL-based solution to optimize topology in SDN | A2C,PPO,GNN | Parameter of GNN | Entropy Loss, Training Accuracy and Testing Accuracy |
| [48] | DQSP: A DRL-based solution concerning QoS in SDN-IoT | DDPG | Next Hop | Packet Delivery Ratio, Delay, Probablity of passing attacked nodes |
| [49] | An attack mitigation scheme based on DRL to adaptively prevent the spread of attacks. | DQN | Takeover Decision of the Switches | Request Arrival Rate |
| Parameter Name | Value |
|---|---|
| Total Episodes | 3000 |
| Discount Factorγ | 0.96 |
| Learning Rate of Actor | 1 × 10−5 |
| Learning Rate of Critic | 1 × 10−4 |
| Advantage function scaling factor | 0.90 |
| Truncation parameter | 0.2 |
| Parameter of delay reward | 0.2 |
| Parameter of variation | 4 |
| Parameter of trust value | −400 |
| Parameter of diversity | 3 |
| Parameter of repeat | −100 |
| 0.8 | 1.0 | 2.0 | 0.0001 |
| DDoS Attack Proportion | KL Trust Value |
|---|---|
| 20% | 0.069 |
| 40% | 0.167 |
| 60% | 0.298 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Qiu, L.; Xu, Y.; Wang, X.; Wang, S.; Paul, A.; Wu, Z. Multi-Path Routing Algorithm Based on Deep Reinforcement Learning for SDN. Appl. Sci. 2023, 13, 12520. https://doi.org/10.3390/app132212520
Zhang Y, Qiu L, Xu Y, Wang X, Wang S, Paul A, Wu Z. Multi-Path Routing Algorithm Based on Deep Reinforcement Learning for SDN. Applied Sciences. 2023; 13(22):12520. https://doi.org/10.3390/app132212520
Chicago/Turabian StyleZhang, Yi, Lanxin Qiu, Yangzhou Xu, Xinjia Wang, Shengjie Wang, Agyemang Paul, and Zhefu Wu. 2023. "Multi-Path Routing Algorithm Based on Deep Reinforcement Learning for SDN" Applied Sciences 13, no. 22: 12520. https://doi.org/10.3390/app132212520
APA StyleZhang, Y., Qiu, L., Xu, Y., Wang, X., Wang, S., Paul, A., & Wu, Z. (2023). Multi-Path Routing Algorithm Based on Deep Reinforcement Learning for SDN. Applied Sciences, 13(22), 12520. https://doi.org/10.3390/app132212520