1. Introduction
Developments in multimedia technology have resulted in a sharp increase in the variety of digital music and its listening volume, necessitating urgent advancements in music information retrieval (MIR), which involves utilizing computer technology to automatically analyze, recognize, retrieve, and understand music. Audio music genre classification is a MIR task that involves assigning labels to each piece of music based on characteristics such as genre [
1,
2], mood [
3,
4], and artist type [
5,
6]. Audio music genre classification enables the automatic categorization of audio music based on different styles or types, facilitating a deeper understanding and organization of music libraries.
The evolution of deep learning has profoundly affected music genre classification, ushering in an era of automatic feature learning. Convolutional neural networks (CNNs) are proficient in discerning the complex spatial features inherent in audio data [
7,
8,
9,
10]. However, they are limited in their ability to account for the long-term temporal information inherent in musical compositions. To address this limitation, convolutional recurrent neural networks (CRNNs) [
11,
12,
13], which combine the strengths of both CNNs and recurrent neural networks (RNNs), are employed in music classification. In the specific context of music genre classification, CRNNs have demonstrated a marked advantage over CNNs, proficiently discerning both localized features and short-term temporal inter-relationships. Unfortunately, CRNNs still struggle to capture the long-term temporal dependencies that are often crucial in complex musical compositions.
Transformer-based music genre classification approaches, which are fortified with attention mechanisms, have been introduced to address these issues; they have achieved success, particularly in recognizing long-term information in music. Various transformer-based models, such as MusicBERT [
14] and MidiBERT [
15], have been developed to focus on different aspects of music genre classification. MusicBERT is equipped with specialized encoding and masking techniques that capture complex musical structures, whereas MidiBERT focuses on single-track piano scores. These models can effectively recognize long-term dependencies in music, especially in the context of symbolic music data such as the Musical Instrument Digital Interface (MIDI). Most existing transformer-based models for music classification are primarily tailored for symbolic music data such as MIDI, and there is a notable lack of models that can handle continuous audio data.
A Swin transformer-based approach has emerged as a targeted solution to solve the issues of traditional transformer-based models in handling continuous high-dimensional audio data [
16]. This advanced architecture employs a pre-training strategy known as momentum contrast (MoCo), which is a form of contrastive learning. This strategy aims to create similar representations for similar data points while pushing dissimilar data points apart in the feature space by maintaining a dynamic dictionary. Unfortunately, the MoCo pre-training strategy presents its own set of challenges. First, it incurs significantly increased computational costs, owing to the need to maintain and update this large dictionary. Second, the contrastive loss function can be sensitive to hyperparameter choices, thereby complicating the model optimization process. Third, MoCo-based approaches typically suffer from low interpretability, making it difficult to understand the model decisions or identify the learned features that contributed to the classification results.
Additionally, denoising has been extensively researched. Denoising approaches based on self-supervised learning [
17,
18] via the noise-removal process can effectively capture features and learn deep representations. They have many similarities with self-supervised pre-training strategies, thus making the integration of the denoising concept into pre-training feasible.
In this paper, a novel method for audio music genre classification is proposed. The proposed method is characterized by denoising, which not only reduces computational costs compared to MoCo-based strategies but also offers a robust performance that is uninhibited by hyperparameter dependency. Uniquely, the proposed method incorporates a prior decoder, which substantially enhances the interpretability of the decision-making process. The main contributions of this method are as follows.
The proposed method includes a novel pre-trained model called Deformer and utilizes unsupervised learning to fully leverage unlabeled data for pre-training.
The proposed method design includes a prior decoder that assists Deformer in completing the pre-training effectively; it harnesses the potential of transformers in processing image-like audio data. Notably, this prior decoder improves the interpretability of the results obtained by the method.
The proposed method was experimentally proven to not only lower the computational cost but also achieve better results compared with existing approaches.
The remainder of this paper is organized as follows.
Section 2 describes related work on audio-based music genre classification, and
Section 3 introduces the proposed music-classification method based on audio data. Then,
Section 4 details the experimental process and results. Finally,
Section 5 concludes the proposed paper.
3. Denoising Transformer-Based Audio Music Genre Classification
The architecture and training strategies for the Deformer-based method are detailed next. First, the data representation techniques are discussed; then, the pre-training and fine-tuning stages are outlined.
3.1. Overview
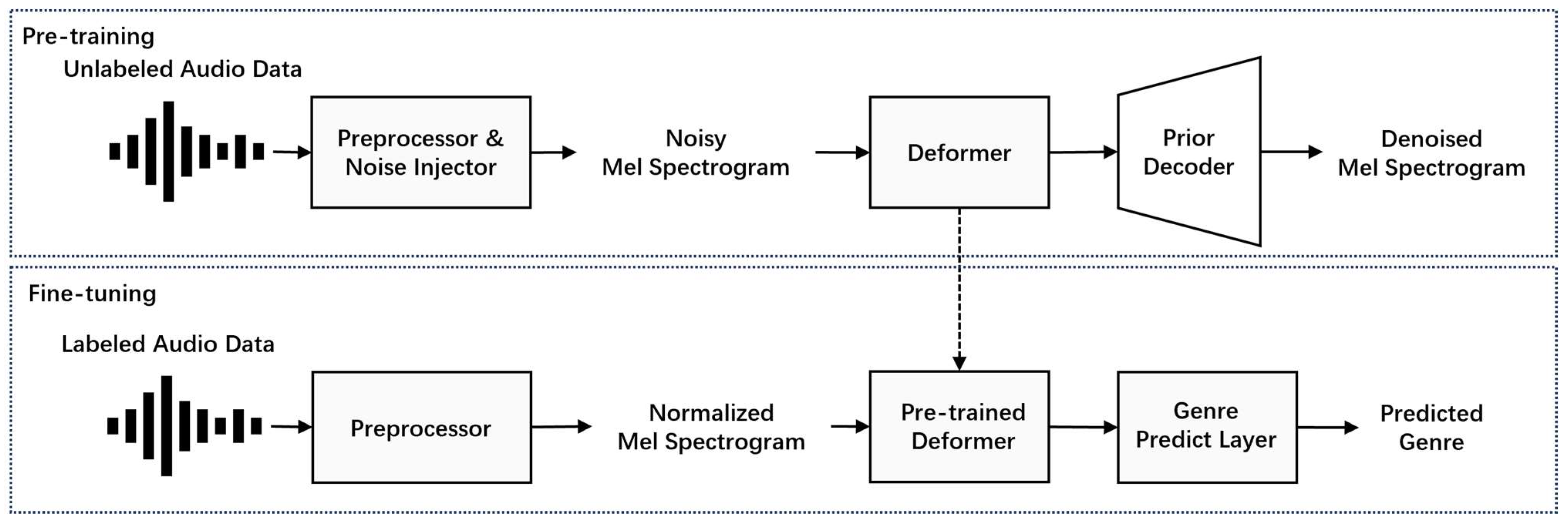
A method utilizing pre-training techniques based on Deformer was proposed for audio music genre classification. The proposed method consists of pre-training and fine-tuning stages, as shown in
Figure 1. First, unlabeled or labeled audio data are preprocessed into a normalized Mel spectrogram, and a noise-injection operation is applied in the pre-training stage, during which Deformer learns deep representations of audio music from unlabeled audio data. For this, a prior decoder is utilized to restore the denoised Mel spectrogram from the low-dimensional hidden states, which is obtained from Deformer. In the fine-tuning stage, the pre-trained Deformer and classifier are further trained using labeled audio data to perform music genre classification. The flowchart for the proposed method is shown in
Figure 2.
3.2. Preprocessing and Noise Injection
The preprocessing is employed in the pre-training and fine-tuning stages, as illustrated in
Figure 3. Initially, audio data are converted into Mel spectrograms with dimensions
and
, corresponding to time and frequency, respectively. These spectrograms are then resized using the librosa library to new dimensions,
and
, which are determined based on the experimental hardware. It is worth noting that the values of
and
should be carefully chosen; excessively large dimensions may incur a larger calculation resource usage. Finally, the resized Mel spectrograms are normalized by scaling the values to fit within a range from zero to one.
Noise injection is operated additionally only in the pre-training stage. They are divided by
equal-sized patches through a matrix-division operation. Each patch is derived by dividing the Mel spectrogram into
sections, resulting in patches with dimensions of
×
, where
and
are the width and height of the transformed spectrogram, respectively. Patches
, follow the order from left to right and top to bottom. The noise ratio,
β%, dictates the fraction of patches that receive noise. The
of patches are injected with noise
with a Gaussian distribution
; otherwise, they remain unchanged. Finally, a noisy Mel spectrogram, which is the combination of
, is obtained:
3.3. Pre-Training Stage
The objective of the pre-training stage is to enable Deformer to understand the deep representation of audio music through unsupervised denoising. The role of the prior decoder within this framework is to restore patches from low-dimensional hidden states obtained from Deformer during pre-training. An autoencoder (AE), which comprises an encoder and a decoder, was designed to train the decoder, as shown in
Figure 4. The encoder consists of max-pooling and convolutional layers, and the decoder consists of convolutional and up-sampling layers. The encoder compresses the input patches into low-dimensional vectors, and the decoder restores the low-dimensional hidden states to the original patches. The mean squared error (MSE) loss is calculated to update the AE parameters.
To complete the denoising, patches of noisy Mel spectrograms
are passed into Deformer, as shown in
Figure 5. The position embedding layer, which is trainable, utilizes absolute numerical embedding to integrate positional information into these patches. The transformer layers utilize multi-head self-attention and feed-forward neural networks to relate to this layer. Subsequently, the prior decoder restores these low-dimensional hidden states back into the restored patches
.
Then, the MSE loss is calculated based on the restored patches and original patches for training Deformer. This training strategy allows Deformer to gain a deep understanding of the contextual relationships and interdependencies among patches.
Algorithm 1 describes the pre-training stage, where Deformer(
) represents Deformer and
represents Deformer parameters.
denotes the number of training steps.
represents one of the patches from the noisy Mel spectrograms, and
is the restored patch. MSE(
) represents the loss function to calculate the loss
between
and
, where
is only generated by the injected noise
and
is the patch of the normalized Mel spectrogram without noise.
is updated based on a gradient, which is calculated as
, where
is the learning rate.
| Algorithm 1 Pre-training |
Input:
Output:
1: Initialize Deformer
2: for = 1 to do:
3: Forward pass: = Deformer (, )
4: If =
5: Compute
6: Update
7: End for |
3.4. Fine-Tuning Stage
In the fine-tuning stage, the Deformer that has already learned the deep representation of audio music is applied to music genre classification.
Figure 6 shows the process of fine-tuning the pre-trained Deformer to a classification network. Different from the pre-training stage, the fine-tuning stage is not unsupervised learning, and the prior decoder is not utilized. Normalized Mel spectrogram patches
without added noise are fed into the model, along with a classifier token (
) [
21]. The
token serves as a condensed representation of all input patches. As opposed to pre-training, which involves decoding layers, fine-tuning employs a genre prediction layer connected to the final Deformer position. This layer is a linear component that uses a SoftMax function to predict the probability distribution for the genre classes based on the
token’s hidden state. The cross-entropy loss is then computed using the predicted and target genres to fine-tune the Deformer and the genre prediction layers, enhancing Deformer’s ability to classify music genres effectively.
Algorithm 2 details the fine-tuning process, where
represents the normalized patches,
represents the target genre,
represents the predicted genre of Deformer, and
(
) calculates the loss of
and
for performing updates.
| Algorithm 2 Fine-tuning |
Input:
Output:
1: Load pre-trained Deformer
2: for = 1 to do:
3: Forward pass: = Deformer
4: Compute
5: Update
6: End for |
4. Experiments and Results
Three experiments, namely, prior decoder training, Deformer pre-training, and Deformer fine-tuning, were performed to thoroughly evaluate the effectiveness of the proposed Deformer-based method in terms of audio music genre classification. First, in the prior decoder training experiment, an autoencoder was trained to convert low-dimensional hidden states into patches of normalized Mel spectrograms. In the Deformer pre-training experiment, Deformer was pre-trained to understand musical deep representations by restoring the original Mel spectrograms from noisy Mel spectrograms. Finally, in the Deformer fine-tuning experiment, the pre-trained Deformer classified the audio music genre through supervised learning. To evaluate the performance and effectiveness of the proposed method, two baseline models are introduced for comparison. The first model [
13] utilizes a residual neural network–bidirectional gated recurrent unit (ResNet-BiGRU), while the second relies on S3T [
16]. These models serve as benchmarks, helping to underscore the advantages of the proposed technique for music genre classification.
4.1. Experimental Environment
Table 2 summarizes all the hyperparameters used in the three experiments. The autoencoder comprises an encoder and a decoder; the encoder consists of three convolutional layers utilizing the same kernels but with different channels. The Deformer hyperparameters include 196 patches, a patch size of 16 × 16, a hidden size of 768, four intermediate multiplications, 12 hidden layers, and 12 attention heads.
During the training of the three models, the resized Mel Spec
size was set to 224 × 224, which can be adjusted according to the hardware of the experimental environment. As mentioned before, noise injection was operated in pre-training. The noise injection ratio
was determined by experimental results, given that the highest classification performance was obtained when
was set to 0.75. Similarly, 0.75 was also used as the mask parameter in [
22], which similarly achieved good results. As the input to the prior decoder is a patch, it allows for a higher batch size compared to others. The parameters of the AdamW optimizer were nearly similar. When setting the learning rate, it was considered that pre-training requires warmup. Unlike other approaches that use a fixed learning rate, pre-training employed a dynamically changing learning rate based on the WarmupDecayLR scheduler.
The experiments were conducted on a system running Windows 10 with 2 Xeon(R) Silver 4310 CPUs, 4 NVIDIA GeForce RTX 3090 GPUs, and 128 GB of DDR4 RAM. The proposed method was developed in Python 3.10.12 and implemented using the PyTorch 2.0.0 platform, complemented by the DeepSpeed acceleration engine for enhanced performance.
In addition to conducting these experiments, a comparative assessment was performed with two baseline models. The first baseline model [
13] employed a hybrid approach, combining ResNet18 and Bi-GRU. ResNet18 utilizes residual connections, comprising 18 weighted layers, including an initial convolutional layer, a max-pooling layer, 4 convolutional blocks (each with 2 convolutional layers), an average pooling layer, and a fully connected layer. Bi-GRU is a recurrent neural network designed for processing sequential data, consisting of a GRU layer and a fully connected layer.
The second baseline model [
16] adopted S3T, leveraging the Swin Transformer as a feature extractor in the time–frequency domain of music. It integrates a momentum-based MoCo paradigm for enhanced performance. The feature extractor follows the Swin-T configuration, using the compact version of the Swin Transformer with a hidden channel number of 96. Each block comprises 2, 2, 6, and 2 layers, ensuring increased efficiency.
4.2. Experimental Data
Two distinct datasets, each divided into an 80% training set and a 20% test set, were employed in the genre classification experiment involving audio music data. The MAESTRO dataset [
23] was used for feature extraction via an autoencoder and for pre-training Deformer. This dataset encompasses a broad spectrum of musical instruments and styles, with contributions from both professionals and amateur musicians. Mel spectrograms derived from raw audio files were used as inputs. The training set was used for model optimization using techniques such as gradient descent, and the test set was designated for performance evaluation using metrics such as MSE. The GTZAN [
24] music dataset was exclusively used to fine-tune Deformer. Renowned in genre classification, this dataset consists of one thousand 30 s audio segments across ten distinct genres, including blues, classical, and hip hop. The audio clips were transformed into Mel spectrograms to serve as inputs for the model. The training process involved iterative Deformer updates based on loss minimization, and the test phase assessed the genre-classification capabilities of Deformer in terms of the precision and recall metrics.
4.3. Experimental Results
The results from the autoencoder training, pre-training, and fine-tuning experiments were analyzed. The initial results indicated a rapid loss function convergence, validating the effectiveness of decoder training. Further findings from the pre-training and fine-tuning processes revealed that Deformer exhibited superior performance in music data processing, outperforming the baseline models in multiple key performance metrics.
4.3.1. Prior Decoder Training Results
Figure 7 shows the prior decoder training experiment results, which involved 8000 steps. The MSE loss decreased rapidly from 0.14 to 0.02. Subsequently, the loss continued to decrease at a slower pace, eventually converging to approximately 0.001.
Figure 8 shows the test results of the prior decoder experiment and the reference for comparison.
Figure 8a shows the Mel spectrograms assembled from the patch output reconstructed by the decoder, while
Figure 8b shows the original Mel spectrograms used for comparison with the reconstructed version; subtle local differences can be observed in the areas marked with red boxes. Interestingly, the Mel spectrograms assembled from the reconstructed patches in
Figure 8a were almost indistinguishable from the original Mel spectrograms in
Figure 8b, demonstrating that the prior decoder could effectively reconstruct the Mel spectrograms from the low-dimensional hidden states.
4.3.2. Pre-Training Results
Figure 9 shows the two distinct phases in the loss curve during the model training process. Initially, the loss value rapidly decreased from a higher level to approximately 0.15, after which the rate of decline significantly decreased and eventually stabilized at approximately 0.01 after approximately 8000 steps.
Figure 10 shows the pre-training stage of Deformer using Mel spectrograms constructed from the patches.
Figure 10a shows the Mel spectrograms assembled from patches injected with noise, which served as the inputs to the model during the pre-training stage.
Figure 10b shows the Mel spectrograms assembled from the denoised patches, which are the outputs of Deformer. Finally,
Figure 10c shows the original noise-free Mel spectrograms. The principal features and trends shown in
Figure 10c are successfully captured, as shown in
Figure 10b, albeit with some loss of detail, demonstrating the capabilities of Deformer in terms of noise reduction and learning meaningful representations of music data. These observations further emphasize the effectiveness of the pre-training stage as well as the preparedness of the pre-trained Deformer for the next fine-tuning stage.
4.3.3. Fine-Tuning Results
Figure 11 shows the loss changes of Deformer during fine-tuning. The orange line (pre-trained) demonstrates a rapid decline in loss during fine-tuning, indicating a high level of learning efficiency. The blue line (without pre-training) exhibits a slower loss decrease. At 20,000 steps, the fine-tuning process based on pre-training demonstrated a significant performance advantage compared to that without pre-training.
To assess the classification efficacy of Deformer across different music genres, the confusion matrix depicted in
Figure 12 is provided. The confusion matrix presents true-positive, true-negative, false-positive, and false-negative results, providing a clear classification performance evaluation. The fact that the predicted results are clearly distributed along the diagonal of the confusion matrix indicates that most of the predictions are correct. It can be seen that Deformer exhibited exceptional performance in the “classical” and “pop” categories, achieving impeccable accuracy with zero misclassifications within these genres. This outcome highlights its acute understanding of the unique attributes associated with these music genres. However, it exhibited inaccuracies within the “rock” and “blues” genres. Specifically, a few samples falling under the “rock” category were incorrectly classified as “blues” and “metal”. Likewise, a subset of “blues” samples was inaccurately classified as “jazz” and “metal”. These misclassifications suggested potential limitations of Deformer, particularly when differentiating between genres having nuanced or overlapping traits. Analyzing the confusion matrix is vital as it paves the way for prospective refinements and emphasizes the need to improve the discriminatory capabilities of the model when classifying music belonging to closely related genres such as “rock” and “blues”.
Table 3 presents the accuracy, precision, recall, and F1 scores for the proposed pre-trained Deformer, Deformer without pre-training used for the ablation experiment, and ResNet-BiGRU and S3T as two baseline models. To complete the comparison, two additional results [
25,
26] are given, which demonstrated high accuracy in audio music genre classification. The pre-trained Deformer reached a classification accuracy of 84.5%, which is 3.4% higher than that of ResNet-BiGRU (81%), 3.3% higher than that of S3T (81.1%), 0.6% higher than that of M2D [
25] (83.9%), and 4.8% higher than that of the Jukebox model pre-trained with CALM (79.7%) [
26]. The pre-trained Deformer significantly outperformed its non-pre-trained counterpart in terms of accuracy, precision, recall, and F1 score, with the latter only achieving an accuracy and recall of 0.37, a precision of 0.3334, and an F1 score of 0.3464. This comparison highlights the importance of pre-training in enhancing the performance of Deformer for music classification. It is worth noting that all data presented in
Table 3 were obtained through testing on the GTZAN dataset.
5. Conclusions
A pre-trained model, Deformer, was introduced to address the specific challenges associated with existing Swin transformer-based approaches in music genre classification within the context of MIR. These challenges include the computational burden associated with managing large dynamic dictionaries, the finicky nature of the contrastive loss function with respect to hyperparameter choices, and the low level of model interpretability commonly observed in MoCo-based approaches. Utilizing a two-stage process of pre-training and fine-tuning, the proposed model leveraged unlabeled audio data during the pre-training stage. The experimental results underscore the significance of incorporating Deformer in the realm of deep learning architectures for audio music classification. The proposed method achieved an accuracy of 84%, outperforming the ResNet-BiGRU-based (81%) and S3T-based (81.1%) models. This highlights the substantial contribution of Deformer to superior performance in audio classification, marking a noteworthy advancement over traditional approaches.
Regarding its limitations, the proposed model was not assessed on larger or more diverse datasets, creating gaps in information regarding its generalizability. Future research directions could involve restructuring the architecture of the model to enable it to better handle genres that have subtle similarities, such as “rock” and “blues”. The focus should be on enhancing the ability of the model to distinguish between closely aligned genres. Further improvements can be made to evaluate the performance of the model across a more diverse set of music genres and use cases. By pursuing these avenues, this research would not only add to the growing literature in the domain of music genre classification but also set a strong performance standard in subsequent investigations.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}