
Foreign-Object Detection in High-Voltage Transmission Line Based on Improved YOLOv8m


Abstract
:1. Introduction
- (1)
- Based on the data provided by the Yunnan Power Science Research Institute in the Yunnan Branch of China Southern Power Grid Co., Ltd., a foreign object dataset of power transmission lines was established. This dataset includes six types of objects: trash, twigs, nests, kites, birds, and balloons. In this database, foreign objects are occluded, with multiple types, large-scale changes, and complex backgrounds. The detection accuracy of existing methods is not high.
- (2)
- We propose a foreign-object-detection model for high-voltage transmission lines based on improved YOLOv8m. The experimental results show that our model has achieved high accuracy and can meet the needs of practical applications.
2. Related Work
2.1. Object-Detection Model
2.2. Research on Target Detection for Transmission Lines
3. Datasets
4. Proposed Method
4.1. Enhanced YOLOv8m Model
4.2. GAM (Global Attention Mechanism)
4.3. SPPCSPC Module
4.4. Focal-EIoU Loss Function
5. Experiment and Analysis
5.1. Experimental Setup
5.2. Evaluation Metrics
- Precision: the proportion of predicted positive samples that are actually positive (Precision = TP/(TP + FP)).
- Recall: the proportion of actual positive samples that are predicted as positive (Recall = TP/(TP + FN)).
- mAP_0.5: precision is calculated for each class when the IoU threshold is 0.5, and the precision of each class is averaged to obtain mAP_0.5.
- mAP_0.5:0.95: average mAP across different IoU thresholds from 0.5 to 0.95 (with a step of 0.05).
- Parameter: the model’s parameter count.
- GFLOPs: model computational complexity. One GFLOPs means that the model requires billions of floating-point operations.
- Speed: the model’s detection speed. It indicates the milliseconds required for detecting a single image.
5.3. Experimental Results and Analysis
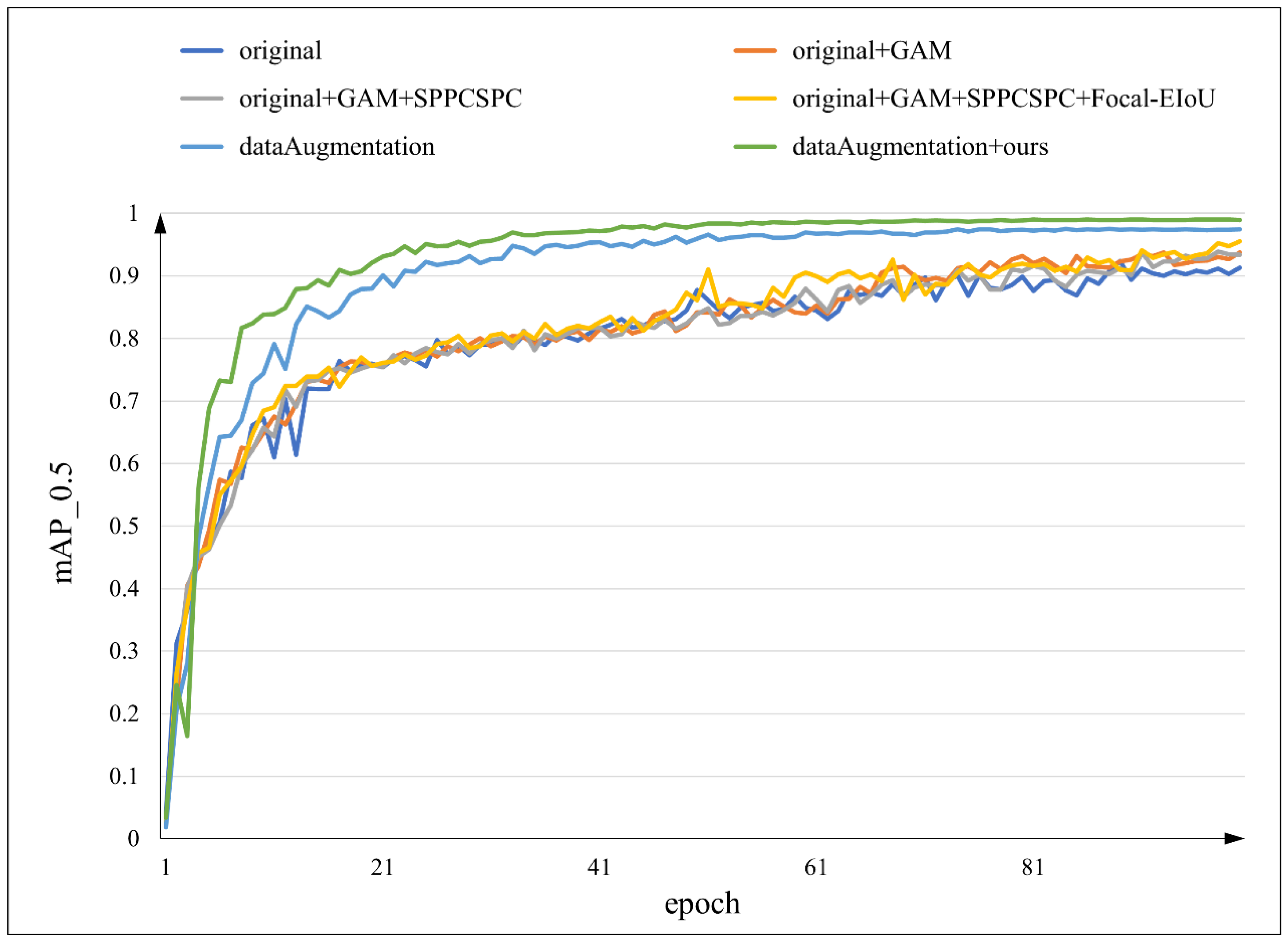
5.3.1. Model Training Comparison
5.3.2. Attention Visualization Comparison
5.3.3. Ablation Experiments
5.3.4. Comparative Experiments with Other Models
5.3.5. Foreign-Object Detection Result
5.3.6. Detection Results for Different Classes
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Deng, Y.; Tang, Z.; Li, H.; Yang, Z. Real-time Rendering Algorithm Optimization for Large-scale Power Transmission Line Scenes Based on LOD. Comput. Mod. 2017, 257, 115–118. [Google Scholar]
- Liu, Z.; Liao, X.; Chen, J.; Jiao, H. A Comprehensive Review on Intelligent Processing of Visible Light Images for Power Overhead Line Inspection. Power Syst. Technol. 2020, 44, 1057–1069. [Google Scholar]
- Zhang, H.; Zhou, H.; Li, S.; Li, P. Improving YOLOv3’s Foreign Object Detection Method for Transmission Lines. J. Laser 2022, 43, 82–87. [Google Scholar]
- Wan, D.; Zhang, J.; Guo, X. A Transmission Line Foreign Object Detection Method Based on Visual Saliency Analysis. J. Telev. Technol. 2018, 42, 106–110. [Google Scholar]
- Yu, G.; Zou, Z.; Fu, X.; Peng, J.; Shi, C. Research on Foreign Object Detection on Transmission Lines Based on UAV Aerial Images. Jiangxi Sci. 2022, 40, 223–228. [Google Scholar]
- Liao, X.; Liu, Z.; Yan, Q. A Comprehensive Review on UAV-based Smart Inspection Technology for Power Transmission Lines. J. Fuzhou Univ. 2020, 48, 198–209. [Google Scholar]
- Huang, Z.; Wang, Y.; Wang, H.; Gao, C.; Bai, C. Unmanned Aerial Vehicle Intelligent Inspection System for Power Lines Based on Cloud-Fog Edge Heterogeneous Collaboration. China Electr. Power 2020, 53, 161–168. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision and Pattern Recognition, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, k.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Cirshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A. SSD:single shot multibox detector. In Proceedings of the European Conference on Computer Vision and Pattern Recognition, Amsterdam, The Netherlands, 10–16 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO900:Better, faster, stronger. In Proceeding of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3:An incremental improve. In Proceeding of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ultralytics. YOLOv5 Object Detection. Available online: https://github.com/ultralytics/yolov5 (accessed on 24 April 2020).
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Wang, C.; Yeh, I.; Liao, H. You Only Learn One Representation: Unified Network for Multiple Tasks. arXiv 2021, arXiv:2105.04206. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. RepVGG: Making VGG-style ConvNets Great Again. In Proceeding of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 13728–13737. [Google Scholar]
- Gevorgyan, Z. SIoU Loss: More Powerful Learning for Bounding Box Regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Wang, C.; Bochkovskiy, A.; Liao, H. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceeding of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Oxford, UK, 15–17 September 2023; pp. 7464–7475. [Google Scholar]
- Wang, C.; Liao, H.; Yeh, I. Designing Network Design Strategies Through Gradient Path Analysis. arXiv 2022, arXiv:2211.04800. [Google Scholar]
- Ultralytics. YOLOv8 Object Detection. [Online]. Available online: https://ultralytics.com/yolov8 (accessed on 17 July 2023).
- Liu, Y.; Shao, Z.; Hoffmann, N. Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021. [Google Scholar]
- Wang, X.; Hu, J.; Sun, C.; Du, L. Online Monitoring of Ice Thickness on Transmission Lines using Image Edge Detection. High Volt. Appar. 2009, 45, 69–73. [Google Scholar]
- Cai, W.; Le, J.; Jin, C.; Liu, K. Real-Time Image-Identification-Based Anti-Manmade Misoperation System for Substations. IEEE Trans. Power Deliv. 2023, 27, 1748–1754. [Google Scholar] [CrossRef]
- Jin, L.; Yao, C.; Yan, S.; Zhang, W. Recognition of Foreign Objects on Transmission Lines based on Aerial Images. J. Tongji Univ. 2013, 41, 277–281. [Google Scholar]
- Wang, W.; Zhang, J.; Han, J.; Liu, L.; Zhu, M. Method for Detecting Line Breaks and Foreign Object Defects on Transmission Lines Based on Drone Images. J. Comput. Appl. 2015, 35, 2404–2408. [Google Scholar]
- Shi, P.; Zhang, C.; Zheng, X. Foreign Object Detection on High-voltage Poles based on Deep Learning. J. Chongqing Univ. Sci. Technol. 2020, 22, 83–87. [Google Scholar]
- Zhu, J.; Guo, Y.; Yue, F.; Yuan, H.; Rong, M. A Deep Learning Method to Detect Foreign Objects for Inspecting Power Transmission Lines. IEEE Access 2020, 8, 94065–94075. [Google Scholar] [CrossRef]
- Yang, J.; Qin, Z.; Pang, X.; He, Z.; Cui, C. A Method for Monitoring and Identifying Intrusions of Foreign Objects on Transmission Lines based on Deep Learning Networks. Power Syst. Prot. Control 2021, 49, 37–44. [Google Scholar]
- Yu, Y.; Qiu, Z.; Zhou, Y.; Zhu, X.; Wang, Q. Transmission Line Foreign Object Detection Based on Convolutional Neural Network and ECOC-SVM. Smart Power 2022, 50, 87–92+107. [Google Scholar]
- Yu, Y.; Qiu, Z.; Liao, H.; Wei, Z.; Zhu, X.; Zhou, Z. A Method Based on Multi-Network Feature Fusion and Random Forest for Foreign Objects Detection on Transmission Lines. Appl. Sci. 2022, 12, 4982. [Google Scholar] [CrossRef]
- Zou, H.; Jiao, L.; Zhang, Z.; Tang, B.; Liu, Z. An Improved YOLO Network for Detection of Small Foreign Objects on Transmission Lines. J. Nanjing Inst. Technol. 2022, 20, 7–14. [Google Scholar]
- Qiu, Z.; Zhu, X.; Liao, C.; Qu, W.; Yu, Y. A Lightweight YOLOv4-EDAM Model for Accurate and Real-time Detection of Foreign Objects Suspended on Power Lines. IEEE Trans. Power Deliv. 2023, 38, 1329–1340. [Google Scholar] [CrossRef]
- Wu, M.; Guo, L.; Chen, R.; Du, W.; Wang, J.; Liu, M.; Kong, X.; Tang, J. Improved YOLOX Foreign Object Detection Algorithm for Transmission Lines. Wirel. Commun. Mob. Comput. 2022, 2022, 5835693. [Google Scholar] [CrossRef]
- Yu, C.; Liu, Y.; Zhang, W.; Zhang, X.; Zhang, Y.; Jiang, X. Foreign Objects Identification of Transmission Line Based on Improved YOLOv7. IEEE Access 2023, 11, 51997–52008. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhu, T.; Xiao, S.; Yang, Z.; Zeng, H. Detection of High Voltage Transmission Line Foreign Objects based on Improved YOLOv4 Algorithm. Appl. Sci. 2023, 50, 59–65. [Google Scholar]
- Tang, C.; Dong, H.; Huang, Y.; Han, T.; Fang, M.; Fu, J. Foreign object detection for transmission lines based on Swin Transformer V2 and YOLOX. Vis. Comput. 2023, 1432–2315. [Google Scholar] [CrossRef]
- Chen, C.; Yuan, G.; Zhou, H.; Ma, Y. Improved YOLOv5s model for key components detecion of power transmission lines. Math. Biosci. Eng. 2023, 20, 7738–7760. [Google Scholar] [CrossRef]
- Cheng, Q.; Yuan, G.; Chen, D.; Xu, B.; Chen, E.; Zhou, H. Transmission Lines Small-Target Detection Algorithm Research Based on YOLOv5. Appl. Sci. 2023, 13, 9386. [Google Scholar] [CrossRef]
- Chen, C.; Yuan, G.; Zhou, H.; Ma, Y. Optimized YOLOv7-tiny model for smoke detection in power transmission lines. Math. Biosci. Eng. 2023, 20, 19300–19319. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kwoen, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Springer Conference on European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Trash | Twig | Nest | Kite | Bird | Balloon |
|---|---|---|---|---|---|---|
| Original | 667 | 64 | 2508 | 240 | 1244 | 356 |
| Data Augmentation | 2024 | 1299 | 4017 | 2133 | 2489 | 1811 |
| GAM | SPPCSPC | Focal-EIoU | mAP_0.5 (%) | mAP_0.5:0.95 (%) | Precision (%) | Recall (%) | Parameters | GFLPOS | Speed (ms) |
|---|---|---|---|---|---|---|---|---|---|
| 92.8 | 76.4 | 98.4 | 85.9 | 25.9 M | 79.1 | 32.3 | |||
| √ | 93.1 | 78.5 | 95.4 | 88.9 | 42.5 M | 85.6 | 34.5 | ||
| √ | 93.5 | 73.71 | 93.96 | 89.22 | 34 M | 92.4 | 33.7 | ||
| √ | 94.14 | 75.12 | 94.6 | 89.9 | 25.9 M | 79.1 | 32.4 | ||
| √ | √ | 93.9 | 78.3 | 93.2 | 91.5 | 50.6 M | 98.9 | 35.9 | |
| √ | √ | 93.75 | 82.1 | 98 | 90.86 | 34 M | 92.4 | 33.9 | |
| √ | √ | 94.89 | 84.5 | 97.03 | 91.09 | 42.5 M | 85.6 | 34.8 | |
| √ | √ | √ | 95.5 | 80.4 | 96.7 | 91.9 | 50.6 M | 98.9 | 35.9 |
| Model | mAP_0.5 (%) | mAP_0.5:0.95 (%) | Precision (%) | Recall (%) | Speed (ms) |
|---|---|---|---|---|---|
| Faster RCNN | 86.7 | 64.9 | 81.9 | 83.1 | 80.9 |
| Sparse RCNN | 90 | 66.4 | 93.8 | 81.1 | 79.1 |
| Cascade RCNN | 86.8 | 65.3 | 89.1 | 77.7 | 86.7 |
| YOLOv5m | 91.9 | 68.3 | 95 | 86.2 | 50.5 |
| YOLOv6m | 88.67 | 71.8 | 91.8 | 86.5 | 45.7 |
| YOLOv7 | 92 | 75.9 | 98.2 | 85.5 | 41.5 |
| YOLOv8m | 92.8 | 76.4 | 98.4 | 85.9 | 32.3 |
| Ours | 95.5 | 80.4 | 96.7 | 91.9 | 35.9 |
| Model | Foreign Object | Labels | mAP_0.5 (%) | mAP_0.5:0.95 (%) | Precision (%) | Recall (%) |
|---|---|---|---|---|---|---|
| YOLOv8m | all | 1008 | 92.8 | 76.4 | 98.4 | 85.9 |
| nest | 514 | 98.7 | 85.9 | 99.4 | 93.3 | |
| trash | 134 | 98.4 | 84.9 | 100 | 92.5 | |
| kite | 45 | 86.3 | 70.1 | 99.2 | 71.1 | |
| twig | 14 | 76.1 | 37.9 | 93.2 | 64.3 | |
| bird | 242 | 99.5 | 89.6 | 99.6 | 99.2 | |
| balloon | 59 | 97.4 | 89.9 | 99.3 | 94.9 | |
| Ours | all | 1008 | 95.5 | 80.4 | 96.7 | 91.9 |
| nest | 514 | 98.7 | 87.3 | 98.6 | 96.3 | |
| trash | 134 | 98.7 | 88.4 | 98.2 | 94.8 | |
| kite | 45 | 87.9 | 75.8 | 87.3 | 80 | |
| twig | 14 | 90.4 | 48.3 | 97.1 | 85.7 | |
| bird | 242 | 99.5 | 90.1 | 99.4 | 99.6 | |
| balloon | 59 | 97.6 | 92.8 | 99.4 | 94.9 | |
| Data Augmentation | all | 2798 | 97.4 | 86.4 | 98.6 | 94.1 |
| nest | 1004 | 99.1 | 88.4 | 99.8 | 98 | |
| trash | 255 | 93.9 | 86.1 | 97.8 | 90.5 | |
| kite | 457 | 96.1 | 81.5 | 97.1 | 90.3 | |
| twig | 246 | 99.3 | 82.3 | 98.4 | 97.1 | |
| bird | 487 | 99 | 90.4 | 98.9 | 97.2 | |
| balloon | 349 | 96.9 | 89.7 | 99.4 | 91.7 | |
| Data Augmentation + Ours | all | 2798 | 99 | 89.5 | 99.6 | 96.8 |
| nest | 1004 | 99.4 | 89.8 | 99.5 | 97.8 | |
| trash | 255 | 98 | 91 | 99.7 | 94.5 | |
| kite | 457 | 98.1 | 87.1 | 98.8 | 92.3 | |
| twig | 246 | 99.5 | 84.7 | 100 | 97.5 | |
| bird | 487 | 99.4 | 91.8 | 99.4 | 99 | |
| balloon | 349 | 99.5 | 93 | 100 | 99.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Yuan, G.; Zhou, H.; Ma, Y.; Ma, Y. Foreign-Object Detection in High-Voltage Transmission Line Based on Improved YOLOv8m. Appl. Sci. 2023, 13, 12775. https://doi.org/10.3390/app132312775
Wang Z, Yuan G, Zhou H, Ma Y, Ma Y. Foreign-Object Detection in High-Voltage Transmission Line Based on Improved YOLOv8m. Applied Sciences. 2023; 13(23):12775. https://doi.org/10.3390/app132312775
Chicago/Turabian StyleWang, Zhenyue, Guowu Yuan, Hao Zhou, Yi Ma, and Yutang Ma. 2023. "Foreign-Object Detection in High-Voltage Transmission Line Based on Improved YOLOv8m" Applied Sciences 13, no. 23: 12775. https://doi.org/10.3390/app132312775