1. Introduction
Machine learning (ML) is a subfield of artificial intelligence (AI) and an advanced form of data analysis and computation that employs the high elaboration speed and pattern recognition techniques of computers for knowledge output from data. In other words, it is a computer programming technique inspired by AI that allows computers to improve their learning abilities through data supplies or data access. This resembles the way human beings improve their intelligence in real life. There are four generalized categories of ML. To be more specific, there is supervised learning, semi-supervised learning, unsupervised learning and reinforcement learning. In supervised learning, the desired output is known by the trainer, where the trainer is the human being that can ascribe physical meaning to the data and characterize it by adding a tag or correcting system errors. The machine is trained based on inputs with tags that are connected to a corresponding output. Through this process, the machine develops a predictive model for the connection of this input to a certain output. This does not differ from the way that knowledge is learned in a classroom, with a teacher available to correct any errors.
The mode of failure of structural members, such as reinforced concrete columns, depends on several factors, such as their geometric characteristics, the longitudinal reinforcement, the efficiency of confinement through the transverse reinforcement and the loading history. Their behavior throughout the loading range is controlled by competing mechanisms of resistance such as flexure, shear, buckling of longitudinal bars when they are subjected to compressive loads and, in the case of lap splices, the lap splice mechanism of the development of reinforcing bars. Very often, a combination of such mechanisms characterizes the macroscopic behavior of the column, especially in cases of cyclic load reversals. Various predictive models have been developed in the past to determine both the strength as well as the deformation capacity of the columns, with the uncertainty being at least one order of magnitude greater in terms of deformation capacity rather than strength, as evidenced by comparisons with test results [
1,
2].
System identification and damage detection is a twofold area that utilizes ML to imitate a structural system and predict its deterministic seismic response. Laboratory tests of reinforced concrete (RC) structures have provided one source of data that enables ML methods to identify their failure modes, strength, capacities and constitutive behaviors [
3]. ML methods in which the algorithms are used to learn from the data have been used recently for risk assessment and prediction models in civil engineering [
4,
5,
6,
7,
8,
9,
10,
11]. In this regard, some studies have focused on predicting failure modes and shear strength for beam–column joints [
6,
9,
12,
13]. For instance, Mitra et al. (2011) [
12] categorized non-ductile joint shear failure versus ductile beam yielding failure for interior beam–column joints. And, Tang et al., 2022 [
14] examined the design and application of a low-cycle reciprocating loading test on 23 recycled aggregate concrete-filled steel tube columns and 3 ordinary concrete-filled steel tube columns. Moreover, in the latter study, they applied artificial intelligence to estimate the influence of parameter variation on the seismic performance of concrete columns. Specifically, random forests with hyperparameters tuned by the firefly algorithm were chosen. Similar studies with multi-objective optimization analyses are included in [
15].
In this paper, a supervised learning algorithm called the random forest is tested as a predictive model for the first time for its performance in postdicting the failure mode of RC columns against a widely used experimental database originally assembled by Berry and Eberhard (2004) [
16]. Known as the PEER structural performance database, it assembles the results of over 400 cyclic, lateral-load tests of reinforced concrete columns. The database describes tests of spiral or circular hoop-confined columns, rectangular tied columns and columns with or without lap splices of longitudinal reinforcement at the critical sections. For each test, where the information is available, the database provides the column geometry, column material properties, column reinforcing details, test configuration (including P-Delta configuration), axial load, digital lateral force displacement history at the top of the column and top displacement that preceded various damage observations.
This paper has the following contributions in the research area of ML methods in earthquake engineering:
According to the authors’ knowledge, the PEER structural performance database is employed for the first time in order to detect the failure mode of RC columns.
Rectangular RC columns are examined for the first time for their failure mode detection through the random forest ML method [
3,
17].
The influence of the main design variables on the column ductility and failure mode is also thoroughly examined.
Finally, all the performance metrics necessary for the evaluation of the ML methodology in detecting the failure mode of RC columns are provided too.
The structure of this study is the following: after the introduction which describes the initiatives of this research paper, the employed data and the performed methodology are described in
Section 2. In the latter section, the influence of the main design variables on the column ductility and failure mode is given in detail, along with the statistical representation of the database. The steps of the performed supervised ML method in Python programming language are provided here, too. Finally, the output results along with their discussion are presented in
Section 4, while the conclusions and future work are presented in
Section 5.
2. Materials and Methods
Statistics of the aforementioned PEER structural performance database are provided below for the column depth, aspect ratio, axial load ratio, longitudinal reinforcement ratio (
ρl) and transverse reinforcement ratio (
ρs) [
1,
2].
2.1. Statistical Representation of the PEER Structural Performance Database
Table 1 provides the mean values (Mean), Standard deviation (
Std) and Coefficient of variation (
CoV) of key column properties for 306 rectangular reinforced columns and 177 spiral reinforced columns. Statistics are provided for the column depth, aspect ratio, axial-load ratio, longitudinal reinforcement ratio (
ρl) and transverse reinforcement ratio (
ρs).
2.2. Influence of Main Design Variables to Column Ductility and Failure Mode
One important goal in seismic structural assessment procedures is the reliable estimation of the available capacity of structural members for inelastic deformation, as well as their available ductility. Ductility drives assessment since its magnitude underlies the general design philosophy (i.e., through the q-μ-T relationships it controls the magnitude of strength reduction from the elastic demands that may be tolerated before failure) and, in current code practice (EN 1998-1 2004 [
18] and AASHTO LRFD 2013 [
19], FEMA 440 2005 [
20]), its magnitude is reflected on the specific reinforcing requirements of members and structures.
In the experimental database report of Berry and Eberhard (2004) [
12], the nominal column failure mode was classified as (a) flexure critical, (b) flexure–shear critical, or (c) shear critical, according to the following criteria:
- -
If no shear damage was reported by the experimentalist, the column was classified as flexure critical.
- -
If shear damage (diagonal cracks) was reported, the absolute maximum effective force (: absolute maximum measured force in the experimental column response) was compared with the calculated “ideal” force corresponding to a maximum axial compressive strain in the concrete cover set equal to 0.004, which corresponds to the spalling of unconfined concrete (). The failure displacement ductility at an effective force equal to 80% maximum was determined from the experimental envelope. If the maximum effective force or if the failure displacement ductility was less than or equal to 2 (), the column was classified as shear critical. Otherwise, the column was classified as flexure–shear critical. All columns in the database are divided into two sub-groups according to cross-sectional shape (rectangular and circular section columns).
In this section, the displacement ductility value clouds—as defined by the reported experimental responses—are correlated against important design parameters and plotted in graphs to illustrate the parametric dependencies of this variable on the column failure mode.
For example, considering the concrete strength, the following points are made: (a) higher strength materials are marked by lower ultimate strain, (b) strain can be enhanced through confinement, (c) a higher concrete strength results in a lower compression zone both at yielding and at failure. In general, it can be said that higher concrete strength causes a reduction in ductility. This finding is confirmed by both groups of rectangular tied columns and by the spiral reinforced columns, as can be seen in
Figure 1 and
Figure 2. For the spiral reinforced columns, it is more clearly evident that the ductility is increased for specimens with lower concrete strengths.
During the flexural analysis of a section both at yielding and at failure, the presence of a compressive axial load increases the depth of the compressive zone, as compared to an identical section without axial force. Based on the above remark, the presence of the compressive axial load reduces the curvature ductility of a section. The experimental data confirm this tendency, with brittleness being more evident in the cases where the axial load ratios exceeded the point of balanced failure (see
Figure 3 and
Figure 4).
The shear span to depth ratio, known as the aspect ratio,
a =
Ls/
h, has a determining influence on the characteristics of shear behavior. In a column of small shear span to depth ratio, shear deformation may become appreciable, compared with flexural deformation. A dominant shear response causes a more pronounced pinching in the force-deformation (hysteresis) curve and a faster degradation of the hysteresis energy dissipation capacity. Interestingly, the experimental data show that the ductility ratio increases with a decreasing aspect ratio (
Figure 5 and
Figure 6); this perplexing result is attributed to the fact that the yield displacement increases at a quadratic rate with shear span length
Ls, whereas the ultimate displacement is linear with
Ls and thus the ductility estimate is inversely proportional to
Ls/
h or
a. The following expressions relate the flexural component of column response with aspect ratio, illustrating the source of the observations interpreting the experimental trend:
where
ℓpl is the plastic hinge length (approximated as 0.5
h in practical calculations),
εpl the nonlinear (past yielding) part of the tension reinforcement total strain and
με is the required bar strain ductility.
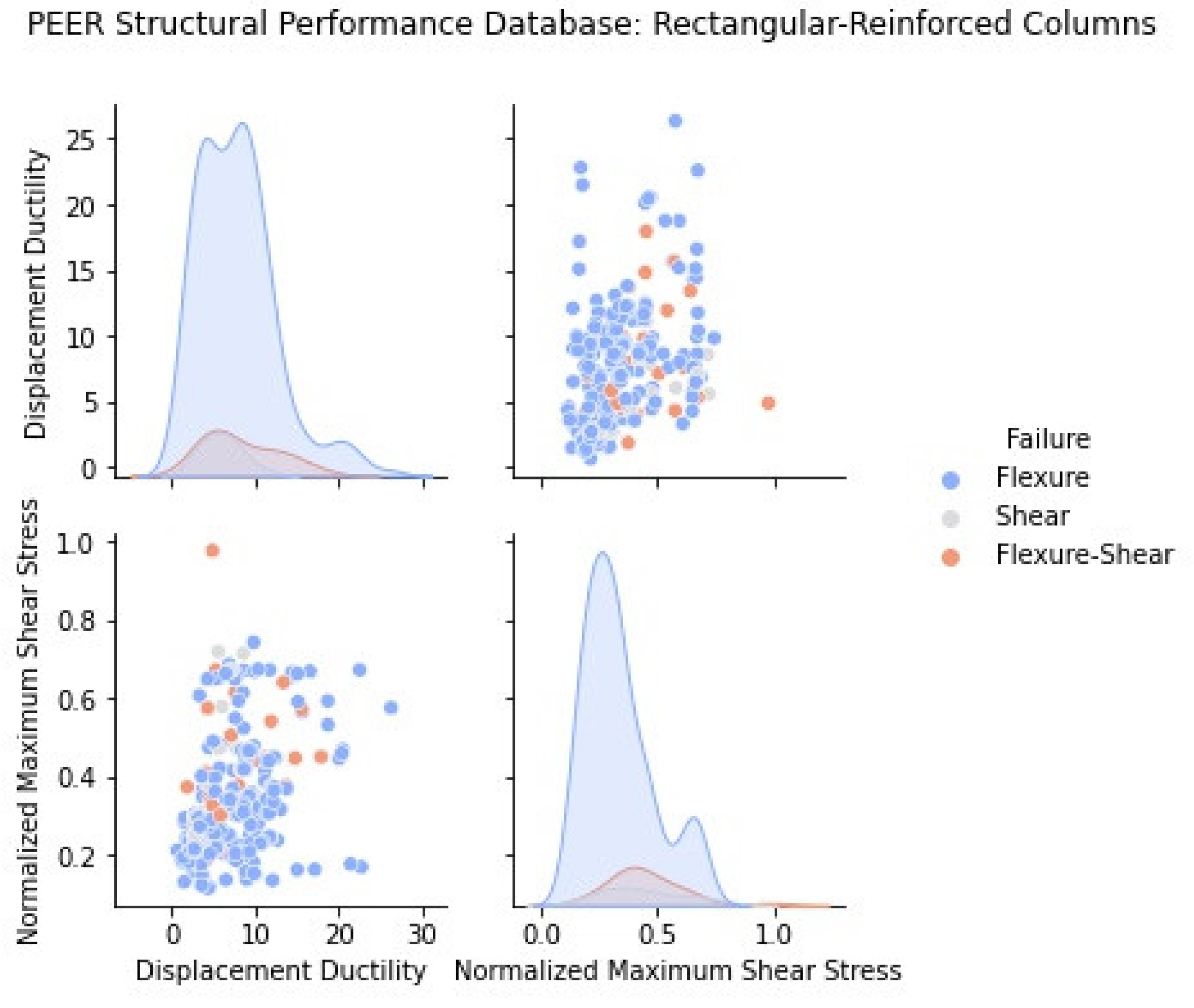
Figure 7 and
Figure 8 depict the relationship between the maximum shear stress (maximum experimental shear force divided by the gross area of the column) normalized by the square root of the concrete strength of each column and the associated displacement ductility. Columns with a higher ductility also support a higher shear force as both parameters are correlated to the same variable, i.e., the quality and quantity of detailing. The observation is also consistent with the trends of
Figure 5 and
Figure 6 which illustrate that displacement ductility is inversely proportional to aspect ratio, which, in turn, for a given member flexural resistance, is inversely proportional to shear demand (since
VEd = MEd/(
h·a)).
The database trends are also examined with reference to lateral confinement—which is generally acknowledged to enhance the deformation capacity of the column. The arrangement of confining reinforcement is important in this regard; a column with closely spaced stirrups and well-distributed longitudinal reinforcement shows very little strength decay even when being subjected to very high axial forces with magnitudes exceeding the limit of balanced failure. The plotted trends confirm this general expectation: the displacement ductility increases with the transverse reinforcement ratio, as shown in
Figure 9 and
Figure 10.
2.3. Supervised ML-Based Prediction of Column Failure Mode with Random Forests
At this point after the statistical description of the available experimental data and the examination of the influence of the main design variables to the displacement ductility of the columns along with their failure mode, it is time to introduce the methodology of the failure mode prediction of reinforced concrete columns by exploring the capabilities of ML methods. The procedure working towards the aforementioned goal of supervised ML methods, such as random forests, using a randomly assigned test set from the PEER database is described thoroughly here.
Random forests are an ensemble method and are based on the construction of many different decision trees [
21]. Every decision tree alone cannot provide an effective prediction but all together can be a more effective model. This is, therefore, the essence of ensemble methods. That is, to create models that result from the combination of many algorithms of which each one apart is not sufficiently effective.
Random forests are proposed in order to confront the overfitting problem, where decision trees are insufficient. Overfitting is a result of a very well-fitted model to the training data (the collected observations). The fitting is so effective that the models’ predictions to new data are not satisfactory. The random forest algorithm creates a set of different decision trees, each one with different characteristics that obtains the average value of the output or the resulting value of the majority of the decision trees and therefore can be considered as a majority voting algorithm. The creation of different decision trees with different characteristic sets to each tree is called bagging and it is a subcategory of ensemble methods. Another random source of the random forest is the selection of the characteristics in each tree node. There are many hyperparameters that need to be defined for the application of random forest algorithms, such as:
The estimator number that defines the number of decision trees.
The maximum feature number that defines the maximum feature number during the separation of nodes in each decision tree.
The maximum depth: the maximum depth in each decision tree.
Minimum sample points at each node separation: the minimum sample point number that should be taken into account at each node.
Likewise with decision trees, random forests do not demand any preprocessing. Moreover, they are less sensitive to overfitting in comparison to decision trees. However, random forests are slower in learning compared to decision trees with many hyperparameters. Finally, due to the fact that random forests are random, there is not a full certainty for their results since the latter could be changed.
Random Forests with Python [22]
In any machine learning problem, the following steps are taken:
The question is set and the demanded data are defined.
The data are obtained in an accessible form.
Any lack of data or uncertainty is defined and corrected accordingly.
The data are prepared for the machine learning model.
A baseline model is set that is intended to be overcome.
The model is trained with the training data.
Model predictions are made with the test data.
The predictions are compared to the known test goals and the performance metrics are computed.
If the performance is not satisfactory, we adjust the model and obtain more data or another modeling technique is tested too.
In the following section, the results of the application of the above-described methodology (see also the flowchart in
Figure 11) are given based on Python programming language and the performance metrics are provided, too. It is shown that the classification of the columns based on the latter ML method is accurate in identifying the failure mode of the collected experimental data. It should be underlined that in the following results, the random state in the random forests is set to value 42, which means that the results will be the same every time that splitting of the data to training and testing data is performed for reproducible results (random_state = 42 means that no matter how many times the code is executed, the result would be the same, i.e., the same values in training and testing datasets). Finally, the number of the trees in random forests is set to 1000.
Before presenting the results of the above-described methodology, a description of the sensitivity of the previously described hyperparameters is necessary. More details with results of this sensitivity will be given in the next section. Regarding the number of estimators, it should be underlined that more trees should be able to produce a more generalized result but by choosing a greater number of trees, the time complexity of the random forest model also increases. In addition, the maximum depth of a tree in the random forest is defined as the longest path between the root node and the leaf node. As the maximum depth of the decision tree increases, the performance of the model over the training dataset increases continuously. The same is valid for the test dataset but with a certain limit over which it decreases rapidly. In the proposed methodology, the maximum depth of the tree is selected so that nodes are expanded until all leaves are pure or until all leaves contain less than the minimum samples split. The default value of the latter hyperparameter (minimum samples split) is two and so this is the minimum number of samples required to split an internal node that was defined in the same way in the proposed methodology. However, by increasing the value of this hyperparameter, the number of splits that happen in the decision tree can be reduced and therefore prevent the model from overfitting. Finally, the maximum number of features is the maximum features provided to each tree in a random forest or else the number of features to consider when looking for the best split. It is a good convention to consider the default value of this parameter, which is one.
3. Results
After examination of the entire PEER database for circular and rectangular RC columns, it can be seen that the necessary parameters to define the control variables that affect the mode of failure and displacement ductility, as described in
Section 2.2, are not available for all the columns of the database. Therefore, firstly the data files defining all the necessary parameters like aspect ratio, axial load ratio, concrete strength, transverse reinforcement ratio and normalized maximum shear stress (see
Section 2.2) are generated and are divided into two groups according to the shape of the section, i.e., rectangular and circular RC columns (see
Appendix A).
The above-mentioned data are divided into training data and into test data for each column section type. The proportion of the dataset to include in the testing data split is defined as 25% and the training data size is automatically set to the complement of the testing data size. During training, the model is allowed to see the correct answers, in this case the failure mode of the RC columns (flexure, flexure–shear and shear), so that it can learn how to predict the failure mode from the provided features. As described previously, it is anticipated that there is a connection between all the features and the failure mode goal and the model should try to figure out this connection. After this step, the model is asked during testing to predict the failure mode of the test data having access only to the features data and not the correct answers of the failure mode. Since these answers are available to the supervisors, the accuracy of the model can be examined. Generally, when a model is trained, the random data are divided into training data and test data in order for the trainer to have a representation of the whole available data.
3.1. Rectangular RC Columns
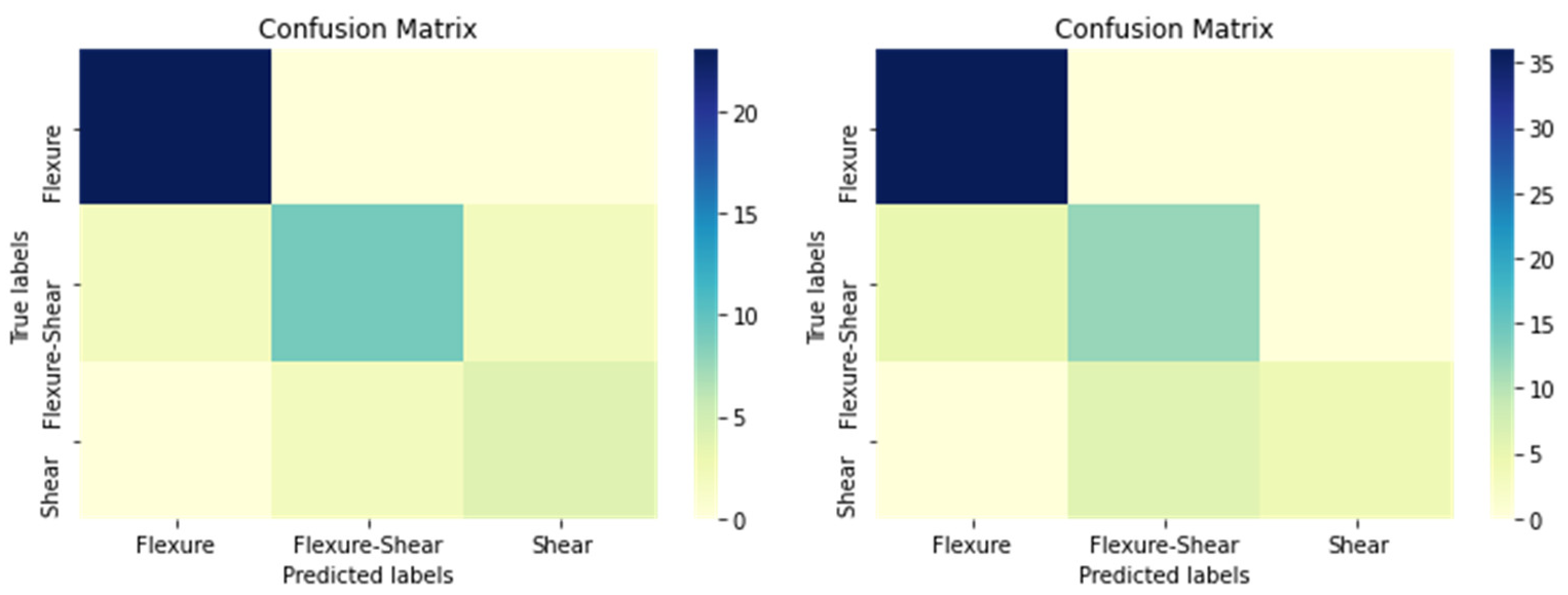
Below, the performance metrics for the case of the rectangular RC columns are provided. It can be seen that random forests have 94% accuracy in predicting the actual failure mode of the columns of the tested data. This accuracy score could be explained based on
Table 2 by dividing the sum of the diagonal matrix terms with the sum of all the terms of the table. More performance metrics are provided in
Table 3. It should be noted that by examining separately each of the influencing parameters included in the features data, the most crucial for the model’s success is the transverse reinforcement ratio which confirms that the model correctly figured out the connection between all the features and the failure mode goal. This is crucial for establishing a physical meaning-based ML method prediction model. Finally, it should be also underlined based on
Table 3 that the model is more successful in predicting the flexural and shear modes of failure compared to the other one. This makes sense since flexure-shear is more difficult also in the real engineering world to be detected in terms of seismic assessment. Finally, it should be clear that
Table 2 clarifies the conception of
Figure 12 and
Table 3 does the same for
Table 2.
3.2. Circular RC Columns
Below, the performance metrics for the case of the circular RC columns are provided.
It can be seen that random forests have 86% accuracy in predicting the actual failure mode of the columns of the tested data. This accuracy score could be explained based on
Table 4 by dividing the sum of diagonal terms with the sum of all the terms of the table. More performance metrics are provided in
Table 5. It should be noted that by examining separately each of the influencing parameters included in the features data, the most crucial for the model’s success is the transverse reinforcement ratio which confirms that the model correctly figured out the connection between all the features and the failure mode goal. This is crucial for establishing a physical meaning-based ML method prediction model. Finally, it should be also underlined based on
Table 5 that the model in the case of circular RC columns is more successful in predicting the flexural and flexural–shear modes of failure, compared to the other one, which makes sense since brittle failures further demand nonlinear structural analyses to be deterministically detected. Finally, it should be clear that
Table 4 clarifies the conception of
Figure 13 and
Table 5 does the same for
Table 4.
3.3. Parametric Sensitivity of Random Forest Algorithm
As described already, the proportion of the dataset to include in the testing data split is defined as 25% and the training data size is automatically set to the complement of the testing data size. Moreover, the estimator number that defines the number of decision trees in the forest is set to 1000. Here, the parametric sensitivity of these two parameters on the accuracy performance score of random forests in postdicting the failure mode of RC columns will be examined. The following Figures depict this sensitivity and it can be seen that the number of decision trees in the forest has no influence on the confusion matrix of the performance of the random forest algorithm (
Figure 14 and
Figure 15). Finally, as seems reasonable by increasing the testing set data (and decreasing the training data at the same time), there is a decrease in the accuracy score of rectangular RC columns and less-so in circular RC columns (
Figure 16 and
Figure 17).
4. Discussion
The state of the art in modeling the lateral load response of columns leaves a lot to be desired: improved response estimation of the behavior of columns that are susceptible to shear failure after flexural yielding; better procedures to estimate shear strength and the pattern of degradation thereof with increasing displacement ductility; the need to account for reinforcement pullout and its effects on stiffness; the shape of the hysteresis loops; the detrimental effects of axial load at large displacement limits; and the magnitude of deformation (drift ratio) associated with milestone events in the response curve of the column member. These are open issues that need to be settled before the performance-based assessment framework may be considered complete and dependable [
1,
2,
23,
24,
25,
26,
27,
28,
29,
30]. In this framework, it is evident from the current study that incorporating physical knowledge (through experimental databases) in ML methods can accurately predict the failure mode of RC columns. From the above-described results, random forests are successful in predicting the failure mode of RC columns, both circular and rectangular, especially the more ductile ones (flexural failure) and, moreover, in attributing the failure mode to the most crucial column features, like the transverse reinforcement ratio. The overall accuracy score for rectangular RC columns is 94% and for circular RC columns is 86%. The latter performances are influenced by the size of the testing and training sets of data and are independent of the number of decision trees in the forest employed in the random forest algorithm. Finally, the low precision and recall scores for brittle failures, especially for circular RC columns, are confirmed also by other studies [
3], where it is suggested that brittle failures are crucial in governing the retrofitting and operational strategies of critical infrastructures to adopt other supervised ML methods, such as Neural Networks and Deep Learning.
5. Conclusions
The prediction of the failure mode of RC columns is crucial in defining the retrofit solutions of buildings and bridges in the modern world. Current strategies include nonlinear structural analysis procedures, which demand a lot of effort and time in order to be performed accurately. This study explores the capability of incorporating physical knowledge into ML methods for predicting the failure mode of RC columns. To this end, the PEER structural performance database is employed and the influence of main design variables on the column ductility and failure mode are examined. It can be seen that supervised ML methods, such as random forests, using a randomly assigned test set from the PEER database and incorporating physical knowledge into them can classify columns’ failure modes accurately, proving that ML has great promise in revolutionizing the profession of earthquake engineering. Finally, according to the authors’ knowledge and the state of the art, the PEER structural performance database is employed for the first time in research in order to identify columns’ failure modes through supervised ML methods. The section of the column is also a variable that was not considered thoroughly and recent results refer only to circular columns. This study will be the basis for further examination of other supervised ML methods in detecting RC columns’ failure modes, such as Decision Trees, k-Nearest Neighbor, Neural Networks and Deep Learning.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}