

Underwater Image Super-Resolution via Dual-aware Integrated Network


Abstract
:1. Introduction
- We introduce a lightweight and efficient DAIN tailored for the underwater SR domain. Leveraging the DAME, which consists of an MCCB and STL, our approach demonstrates superior reconstruction performance, outperforming the majority of existing underwater SR methods.
- Our proposed DAEM adeptly integrates local and global features, enhancing the model’s capacity to capture intricate details.
- The MCCB employs multi-channel and multi-scale strategies to address the challenge of uneven color attenuation in underwater images. Notably, the incorporation of the attention mechanism further elevates the representational prowess of the network.
2. Related Work
2.1. CNN-Based Underwater Image Super-Resolution
2.2. Transformer-Based Underwater Images
3. Methods
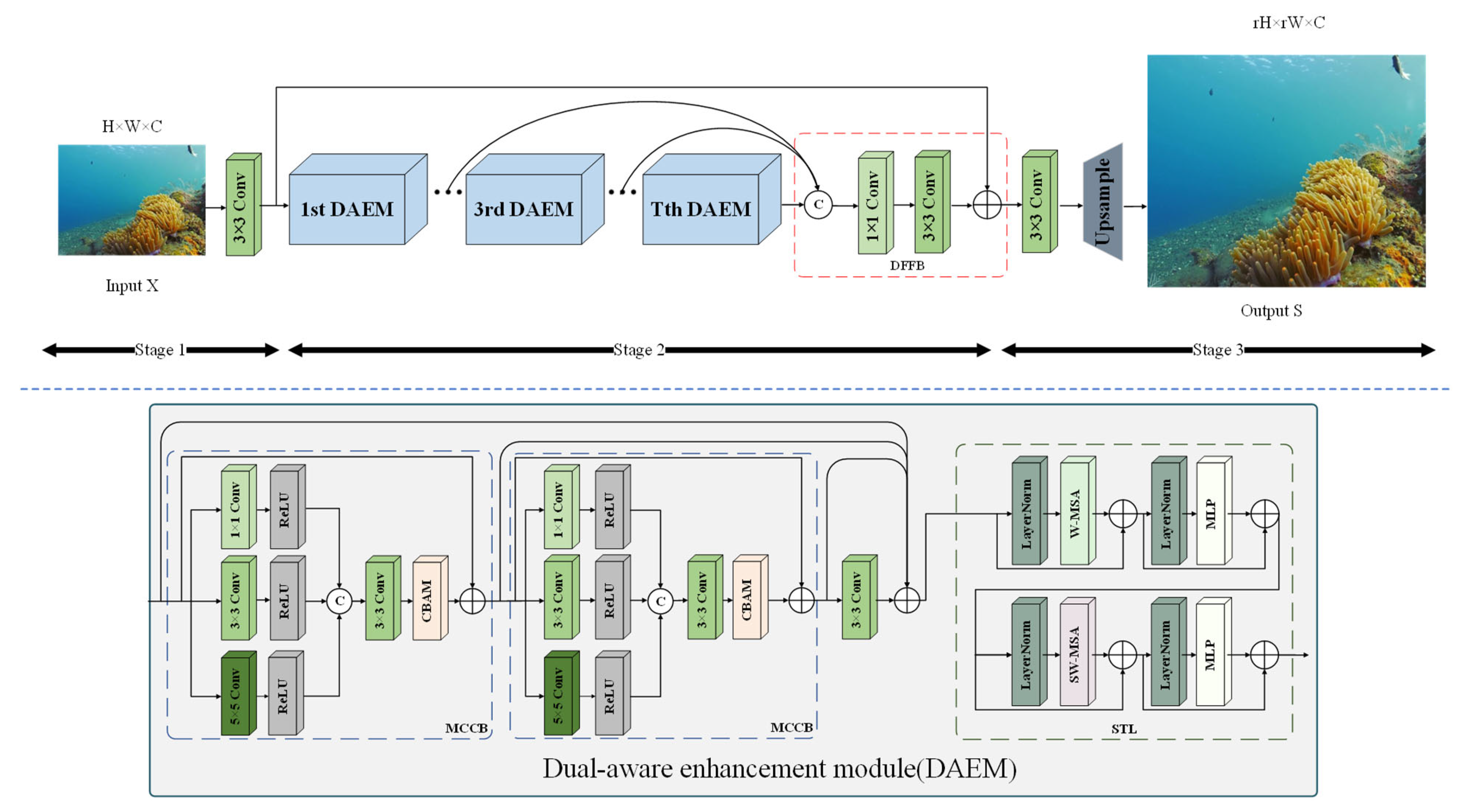
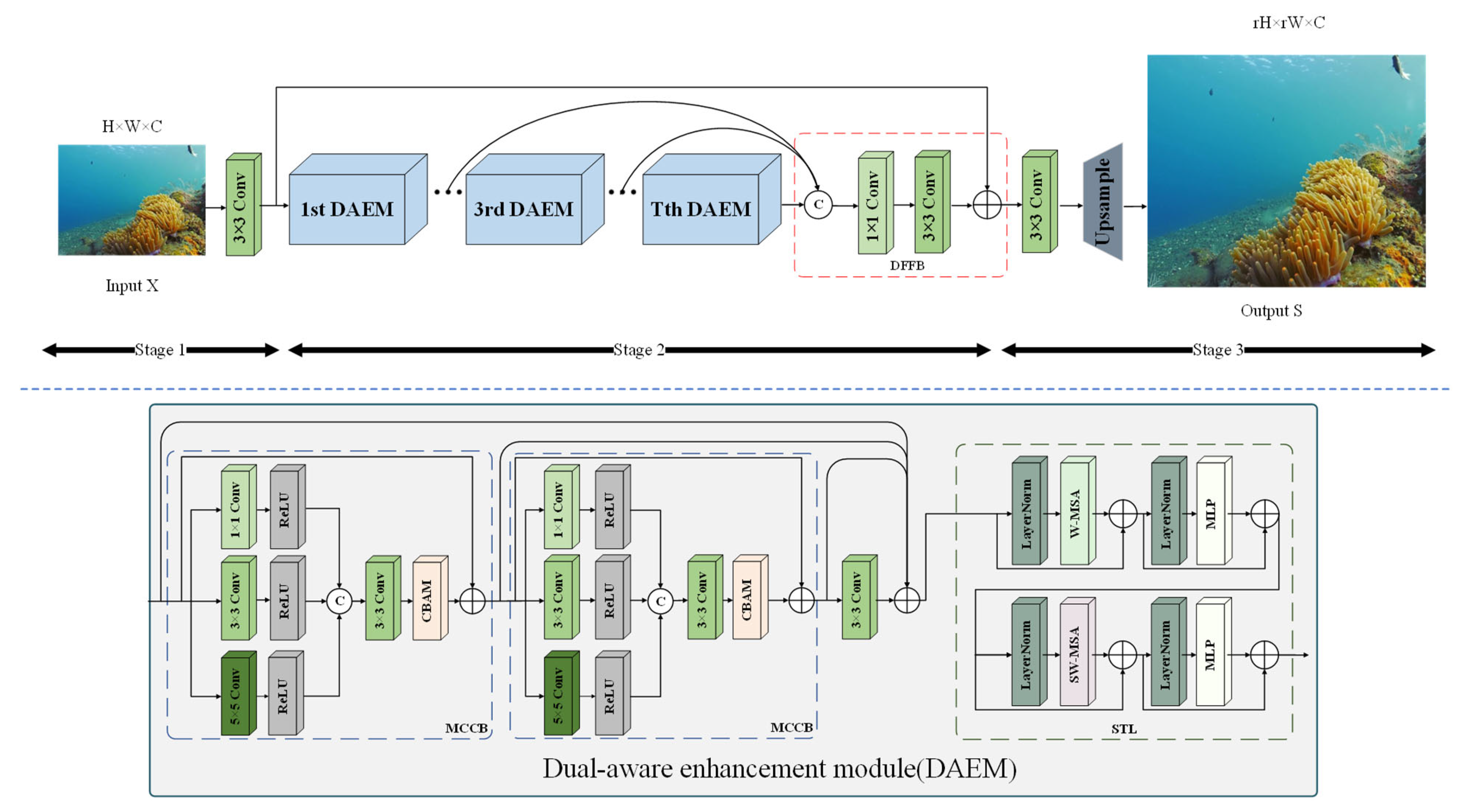
3.1. Overall Network Architecture
3.2. Dual-Aware Enhancement Module (DAEM)
3.3. Multi-Scale Color Correction Block (MCCB)
3.4. Swin Transformer Layer (STL)
4. Experiments
4.1. Experimental Setup
4.2. Experimental Evaluation on the USR-248 Dataset
4.3. Experimental Evaluation on the UFO-120 Dataset
4.4. Experimental Evaluation on the EUVP Dataset
4.5. Model Analysis
4.6. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Anwar, S.; Khan, S.; Barnes, N. A Deep Journey into Super-Resolution: A Survey. ACM Comput. Surv. 2020, 53, 60. [Google Scholar] [CrossRef]
- Yang, W.; Zhang, X.; Tian, Y.; Wang, W.; Xue, J.-H.; Liao, Q. Deep Learning for Single Image Super-Resolution: A Brief Review. IEEE Trans. Multimed. 2019, 21, 3106–3121. [Google Scholar] [CrossRef]
- Li, C.-Y.; Guo, J.-C.; Cong, R.-M.; Pang, Y.-W.; Wang, B. Underwater Image Enhancement by Dehazing with Minimum Information Loss and Histogram Distribution Prior. IEEE Trans. Image Process. 2016, 25, 5664–5677. [Google Scholar] [CrossRef] [PubMed]
- Ancuti, C.; Ancuti, C.O.; Haber, T.; Bekaert, P. Enhancing Underwater Images and Videos by Fusion. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 81–88. [Google Scholar]
- Abdul Ghani, A.S.; Mat Isa, N.A. Underwater Image Quality Enhancement through Composition of Dual-Intensity Images and Rayleigh-Stretching. SpringerPlus 2014, 3, 757. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Li, K.; Tang, J.; Liang, Y. Image Super-Resolution via Lightweight Attention-Directed Feature Aggregation Network. ACM Trans. Multimed. Comput. Commun. Appl. 2023, 19, 60. [Google Scholar] [CrossRef]
- Jobson, D.J.; Rahman, Z.; Woodell, G.A. A Multiscale Retinex for Bridging the Gap between Color Images and the Human Observation of Scenes. IEEE Trans. Image Process. 1997, 6, 965–976. [Google Scholar] [CrossRef]
- Cho, Y.; Jeong, J.; Kim, A. Model-Assisted Multiband Fusion for Single Image Enhancement and Applications to Robot Vision. IEEE Robot. Autom. Lett. 2018, 3, 2822–2829. [Google Scholar]
- Berman, D.; Levy, D.; Avidan, S.; Treibitz, T. Underwater Single Image Color Restoration Using Haze-Lines and a New Quantitative Dataset. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2822–2837. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, S.; Sun, Y.; Liu, S.; Li, X. Attention-Guided Multi-Path Cross-CNN for Underwater Image Super-Resolution. Signal Image Video Process. 2022, 16, 155–163. [Google Scholar] [CrossRef]
- Wang, H.; Wu, H.; Hu, Q.; Chi, J.; Yu, X.; Wu, C. Underwater Image Super-Resolution Using Multi-Stage Information Distillation Networks. J. Vis. Commun. Image Represent. 2021, 77, 103136. [Google Scholar] [CrossRef]
- Sharma, P.; Bisht, I.; Sur, A. Wavelength-Based Attributed Deep Neural Network for Underwater Image Restoration. ACM Trans. Multimed. Comput. Commun. Appl. 2023, 19, 2. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2018; Volume 11211, pp. 3–19, ISBN 978-3-030-01233-5. [Google Scholar]
- Wang, L.; Xu, L.; Tian, W.; Zhang, Y.; Feng, H.; Chen, Z. Underwater Image Super-Resolution and Enhancement via Progressive Frequency-Interleaved Network. J. Vis. Commun. Image Represent. 2022, 86, 103545. [Google Scholar] [CrossRef]
- Wang, Y.; Guo, J.; Gao, H.; Yue, H. UIEC^2-Net: CNN-Based Underwater Image Enhancement Using Two Color Space. Signal Process. Image Commun. 2021, 96, 116250. [Google Scholar] [CrossRef]
- Li, C.; Anwar, S.; Hou, J.; Cong, R.; Guo, C.; Ren, W. Underwater Image Enhancement via Medium Transmission-Guided Multi-Color Space Embedding. IEEE Trans. Image Process. 2021, 30, 4985–5000. [Google Scholar] [CrossRef] [PubMed]
- Liu, K.; Liang, Y. Underwater Optical Image Enhancement Based on Super-Resolution Convolutional Neural Network and Perceptual Fusion. Opt. Express 2023, 31, 9688. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar]
- Peng, L.; Zhu, C.; Bian, L. U-Shape Transformer for Underwater Image Enhancement. IEEE Trans. Image Process. 2023, 32, 3066–3079. [Google Scholar] [CrossRef] [PubMed]
- Shen, Z.; Xu, H.; Luo, T.; Song, Y.; He, Z. UDAformer: Underwater Image Enhancement Based on Dual Attention Transformer. Comput. Graph. 2023, 111, 77–88. [Google Scholar] [CrossRef]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. SwinIR: Image Restoration Using Swin Transformer. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 10–17 October 2021; pp. 1833–1844. [Google Scholar]
- Huang, Z.; Li, J.; Hua, Z.; Fan, L. Underwater Image Enhancement via Adaptive Group Attention-Based Multiscale Cascade Transformer. IEEE Trans. Instrum. Meas. 2022, 71, 5015618. [Google Scholar] [CrossRef]
- Guo, Z.; Guo, D.; Gu, Z.; Zheng, H.; Zheng, B.; Wang, G. Unsupervised Underwater Image Clearness via Transformer. In Proceedings of the OCEANS 2022—Chennai, Chennai, India, 21–24 February 2022; pp. 1–4. [Google Scholar]
- Lu, T.; Wang, Y.; Zhang, Y.; Wang, Y.; Wei, L.; Wang, Z.; Jiang, J. Face Hallucination via Split-Attention in Split-Attention Network. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, 20–24 October 2021; pp. 5501–5509. [Google Scholar]
- Zhang, D.; Shao, J.; Liang, Z.; Gao, L.; Shen, H.T. Large Factor Image Super-Resolution with Cascaded Convolutional Neural Networks. IEEE Trans. Multimed. 2020, 23, 2172–2184. [Google Scholar] [CrossRef]
- Wang, J.; Shao, Z.; Huang, X.; Lu, T.; Zhang, R.; Ma, J. Enhanced Image Prior for Unsupervised Remoting Sensing Super-Resolution. Neural Netw. 2021, 143, 400–412. [Google Scholar] [CrossRef]
- Ouyang, D.; Shao, J.; Jiang, H.; Nguang, S.K.; Shen, H.T. Impulsive Synchronization of Coupled Delayed Neural Networks with Actuator Saturation and Its Application to Image Encryption. Neural Netw. 2020, 128, 158–171. [Google Scholar] [CrossRef] [PubMed]
- Ouyang, D.; Zhang, Y.; Shao, J. Video-Based Person Re-Identification via Spatio-Temporal Attentional and Two-Stream Fusion Convolutional Networks. Pattern Recognit. Lett. 2019, 117, 153–160. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a Deep Convolutional Network for Image Super-Resolution. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Part IV 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 184–199. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the Super-Resolution Convolutional Neural Network. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Part II 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 391–407. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Lai, W.-S.; Huang, J.-B.; Ahuja, N.; Yang, M.-H. Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 624–632. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-Recursive Convolutional Network for Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Tong, T.; Li, G.; Liu, X.; Gao, Q. Image Super-Resolution Using Dense Skip Connections. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4799–4807. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image Super-Resolution via Deep Recursive Residual Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3147–3155. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Islam, M.J.; Enan, S.S.; Luo, P.; Sattar, J. Underwater Image Super-Resolution Using Deep Residual Multipliers. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 900–906. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Cherian, A.K.; Poovammal, E. A Novel AlphaSRGAN for Underwater Image Super Resolution. Comput. Mater. Contin. 2021, 69, 1537–1552. [Google Scholar] [CrossRef]
- Li, J.; Skinner, K.A.; Eustice, R.M.; Johnson-Roberson, M. WaterGAN: Unsupervised Generative Network to Enable Real-Time Color Correction of Monocular Underwater Images. IEEE Robot. Autom. Lett. 2017, 3, 387–394. [Google Scholar] [CrossRef]
- Hou, M.; Liu, R.; Fan, X.; Luo, Z. Joint Residual Learning for Underwater Image Enhancement. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4043–4047. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Li, H.; Zhang, C.; Wan, N.; Chen, Q.; Wang, D.; Song, D. An Improved Method for Underwater Image Super-Resolution and Enhancement. In Proceedings of the 2021 IEEE 4th International Conference on Electronics Technology (ICET), Chengdu, China, 7–10 May 2021; pp. 1295–1299. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wang, Z.; Cun, X.; Bao, J.; Zhou, W.; Liu, J.; Li, H. Uformer: A General u-Shaped Transformer for Image Restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17683–17693. [Google Scholar]
- Ren, T.; Xu, H.; Jiang, G.; Yu, M.; Zhang, X.; Wang, B.; Luo, T. Reinforced Swin-Convs Transformer for Simultaneous Underwater Sensing Scene Image Enhancement and Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4209616. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, D.; Zhang, Y.; Shen, M.; Zhao, W. A Two-Stage Network Based on Transformer and Physical Model for Single Underwater Image Enhancement. J. Mar. Sci. Eng. 2023, 11, 787. [Google Scholar] [CrossRef]
- Sun, K.; Meng, F.; Tian, Y. Underwater Image Enhancement Based on Noise Residual and Color Correction Aggregation Network. Digit. Signal Process. 2022, 129, 103684. [Google Scholar] [CrossRef]
- Khan, M.R.; Kulkarni, A.; Phutke, S.S.; Murala, S. Underwater Image Enhancement with Phase Transfer and Attention. In Proceedings of the 2023 International Joint Conference on Neural Networks (IJCNN), Gold Coast, Australia, 18–23 June 2023; pp. 1–8. [Google Scholar]
- Qi, Q.; Li, K.; Zheng, H.; Gao, X.; Hou, G.; Sun, K. SGUIE-Net: Semantic Attention Guided Underwater Image Enhancement with Multi-Scale Perception. IEEE Trans. Image Process. 2022, 31, 6816–6830. [Google Scholar] [CrossRef]
- Zhao, H.; Gallo, O.; Frosio, I.; Kautz, J. Loss Functions for Image Restoration with Neural Networks. IEEE Trans. Comput. Imaging 2016, 3, 47–57. [Google Scholar] [CrossRef]
- Islam, M.J.; Xia, Y.; Sattar, J. Fast Underwater Image Enhancement for Improved Visual Perception. IEEE Robot. Autom. Lett. 2020, 5, 3227–3234. [Google Scholar] [CrossRef]
- Islam, M.J.; Luo, P.; Sattar, J. Simultaneous Enhancement and Super-Resolution of Underwater Imagery for Improved Visual Perception. arXiv 2020, arXiv:2002.01155. [Google Scholar]
- Fabbri, C.; Islam, M.J.; Sattar, J. Enhancing Underwater Imagery Using Generative Adversarial Networks. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 7159–7165. [Google Scholar]
- Li, Z.; Yang, J.; Liu, Z.; Yang, X.; Jeon, G.; Wu, W. Feedback Network for Image Super-Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3867–3876. [Google Scholar]
- Mao, X.-J.; Shen, C.; Yang, Y.-B. Image Restoration Using Convolutional Auto-Encoders with Symmetric Skip Connections. arXiv 2016, arXiv:1606.08921. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Esrgan: Enhanced Super-Resolution Generative Adversarial Networks. In Proceedings of the European conference on computer vision (ECCV) workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Luo, X.; Xie, Y.; Zhang, Y.; Qu, Y.; Li, C.; Fu, Y. Latticenet: Towards Lightweight Image Super-Resolution with Lattice Block. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Part XXII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 272–289. [Google Scholar]
- Tian, C.; Yuan, Y.; Zhang, S.; Lin, C.-W.; Zuo, W.; Zhang, D. Image Super-Resolution with an Enhanced Group Convolutional Neural Network. Neural Netw. 2022, 153, 373–385. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, C.; Zhang, K.; Chen, Y.; Wang, R.; Shi, X. Underwater-Image Super-Resolution via Range-Dependency Learning of Multiscale Features. Comput. Electr. Eng. 2023, 110, 108756. [Google Scholar] [CrossRef]
- Fang, J.; Lin, H.; Chen, X.; Zeng, K. A Hybrid Network of Cnn and Transformer for Lightweight Image Super-Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1103–1112. [Google Scholar]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scale | Method | FLOPs (G) | Params (M) | PSNR (dB) | SSIM | UIQM |
|---|---|---|---|---|---|---|
| ×2 | SRCNN [29] | 21.30 | 0.06 | 26.81 | 0.76 | 2.74 |
| VDSR [31] | 205.28 | 0.67 | 28.98 | 0.79 | 2.57 | |
| DSRCNN [56] | 54.22 | 1.11 | 27.14 | 0.77 | 2.71 | |
| EDSRGAN [57] | 273.34 | 1.38 | 27.12 | 0.77 | 2.67 | |
| SRGAN [58] | 377.76 | 5.95 | 28.08 | 0.78 | 2.74 | |
| ESRGAN [59] | 4274.68 | 16.70 | 26.66 | 0.75 | 2.70 | |
| SRDRM [37] | 203.91 | 0.83 | 28.36 | 0.80 | 2.78 | |
| SRDRM-GAN [37] | 289.38 | 11.31 | 28.55 | 0.81 | 2.77 | |
| LatticeNet [60] | 56.84 | 0.76 | 29.47 | 0.80 | 2.65 | |
| Deep WaveNet [12] | 21.47 | 0.28 | 29.09 | 0.80 | 2.73 | |
| AMPCNet [10] | — | 1.15 | 29.54 | 0.80 | 2.77 | |
| RDLN [62] | 74.86 | 0.84 | 29.96 | 0.83 | 2.68 | |
| DAIN(ours) | 85.55 | 1.16 | 29.98 | 0.84 | 2.77 | |
| ×4 | SRCNN [29] | 21.30 | 0.06 | 23.38 | 0.67 | 2.38 |
| VDSR [31] | 205.28 | 0.67 | 25.70 | 0.68 | 2.44 | |
| DSRCNN [56] | 15.77 | 1.11 | 23.61 | 0.67 | 2.36 | |
| EDSRGAN [57] | 206.42 | 1.97 | 21.65 | 0.65 | 2.40 | |
| SRGAN [58] | 529.86 | 5.95 | 24.76 | 0.69 | 2.42 | |
| ESRGAN [59] | 1504.09 | 16.70 | 23.79 | 0.65 | 2.38 | |
| SRDRM [37] | 291.73 | 1.90 | 24.64 | 0.68 | 2.46 | |
| SRDRM-GAN [37] | 377.20 | 12.38 | 24.62 | 0.69 | 2.48 | |
| LatticeNet [60] | 14.61 | 0.78 | 26.06 | 0.65 | 2.43 | |
| Deep WaveNet [12] | 5.59 | 0.29 | 25.20 | 0.68 | 2.54 | |
| AMPCNet [10] | — | 1.17 | 25.90 | 0.68 | 2.58 | |
| RDLN [62] | 29.56 | 0.84 | 26.16 | 0.66 | 2.38 | |
| DAIN (ours) | 21.78 | 1.18 | 26.23 | 0.70 | 2.56 | |
| ×8 | SRCNN [29] | 21.30 | 0.06 | 19.97 | 0.57 | 2.01 |
| VDSR [31] | 205.28 | 0.67 | 23.58 | 0.63 | 2.17 | |
| DSRCNN [56] | 6.15 | 1.11 | 20.14 | 0.56 | 2.04 | |
| EDSRGAN [57] | 189.69 | 2.56 | 19.87 | 0.58 | 2.12 | |
| SRGAN [58] | 567.88 | 5.95 | 20.14 | 0.60 | 2.10 | |
| ESRGAN [59] | 811.44 | 16.70 | 19.75 | 0.58 | 2.05 | |
| SRDRM [37] | 313.68 | 2.97 | 21.20 | 0.60 | 2.18 | |
| SRDRM-GAN [37] | 399.15 | 13.45 | 20.25 | 0.61 | 2.17 | |
| LatticeNet [60] | 4.05 | 0.86 | 23.88 | 0.54 | 2.21 | |
| Deep WaveNet [12] | 1.62 | 0.34 | 23.25 | 0.62 | 2.21 | |
| AMPCNet [10] | — | 1.25 | 23.83 | 0.62 | 2.25 | |
| RDLN [62] | 18.23 | 0.84 | 23.91 | 0.54 | 2.18 | |
| DAIN (ours) | 5.99 | 1.26 | 23.97 | 0.64 | 2.20 |
| Method | Params (M) | PSNR (dB) | SSIM | UIQM | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ×2 | ×3 | ×4 | ×2 | ×3 | ×4 | ×2 | ×3 | ×4 | ×2 | ×3 | ×4 | |
| SRCNN [29] | 0.06 | 0.06 | 0.06 | 24.75 | 22.22 | 19.05 | 0.72 | 0.65 | 0.56 | 2.39 | 2.24 | 2.02 |
| SRGAN [58] | 5.95 | 5.95 | 5.95 | 26.11 | 23.87 | 21.08 | 0.75 | 0.70 | 0.58 | 2.44 | 2.39 | 2.56 |
| SRDRM [37] | 0.83 | - | 1.90 | 24.62 | - | 23.15 | 0.72 | - | 0.67 | 2.59 | - | 2.57 |
| SRDRM-GAN [37] | 11.31 | - | 12.38 | 24.61 | - | 23.26 | 0.72 | - | 0.67 | 2.59 | - | 2.55 |
| Deep WaveNet [12] | 0.28 | 0.28 | 0.29 | 25.71 | 25.23 | 25.08 | 0.77 | 0.76 | 0.74 | 2.99 | 2.96 | 2.97 |
| AMPCNet [10] | 1.15 | 1.16 | 1.17 | 25.24 | 25.73 | 24.70 | 0.71 | 0.70 | 0.70 | 2.93 | 2.85 | 2.88 |
| ESRGCNN [59] | 1.53 | 1.53 | 1.53 | 25.82 | 26.19 | 25.20 | 0.72 | 0.71 | 0.70 | 2.98 | 2.96 | 2.85 |
| LatticeNet [60] | 0.76 | 0.77 | 0.78 | 25.86 | 26.13 | 25.10 | 0.71 | 0.71 | 0.70 | 2.97 | 2.94 | 2.94 |
| HNCT [63] | 0.36 | 0.36 | 0.36 | 25.73 | 25.86 | 24.91 | 0.71 | 0.71 | 0.69 | 2.96 | 2.88 | 2.84 |
| URSCT [46] | 11.37 | - | 16.07 | 25.96 | - | 23.59 | 0.80 | - | 0.66 | - | - | - |
| RDLN [62] | 0.84 | 0.84 | 0.84 | 25.96 | 26.55 | 25.37 | 0.76 | 0.74 | 0.73 | 2.98 | 2.98 | 2.94 |
| DAIN(ours) | 1.16 | 1.17 | 1.18 | 26.38 | 26.62 | 25.56 | 0.76 | 0.76 | 0.72 | 2.97 | 2.94 | 2.92 |
| Numbers | PSNR(dB) | SSIM | UIQM |
|---|---|---|---|
| UGAN [54] | 26.45 | 0.79 | 2.87 |
| UGAN-P [54] | 26.44 | 0.79 | 2.91 |
| Funie-GAN [52] | 26.16 | 0.78 | 2.95 |
| Funie-GAN-UP [52] | 25.16 | 0.78 | 2.91 |
| Deep SESR [53] | 27.03 | 0.80 | 3.06 |
| Deep WaveNet [12] | 28.56 | 0.83 | 3.02 |
| DAIN(ours) | 29.13 | 0.85 | 3.03 |
| Numbers | FLOPs (G) | PSNR (dB) | SSIM | UIQM |
|---|---|---|---|---|
| 10 | 18.53 | 29.83 | 0.8177 | 2.7585 |
| 12 | 21.79 | 29.86 | 0.8196 | 2.7724 |
| 14 | 25.04 | 29.81 | 0.8177 | 2.7803 |
| Models | Params (M) | PSNR (dB) | SSIM | UIQM |
|---|---|---|---|---|
| DAIN w/o MCCB | 0.93 | 25.35 | 0.7132 | 2.91 |
| DAIN with PCB | 1.54 | 25.34 | 0.7143 | 2.91 |
| DAIN w/o STL | 0.67 | 25.26 | 0.6974 | 2.89 |
| DAIN w/o DFFB | 1.02 | 24.79 | 0.6961 | 2.89 |
| DAIN | 1.16 | 25.41 | 0.7161 | 2.92 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, A.; Ding, H. Underwater Image Super-Resolution via Dual-aware Integrated Network. Appl. Sci. 2023, 13, 12985. https://doi.org/10.3390/app132412985
Shi A, Ding H. Underwater Image Super-Resolution via Dual-aware Integrated Network. Applied Sciences. 2023; 13(24):12985. https://doi.org/10.3390/app132412985
Chicago/Turabian StyleShi, Aiye, and Haimin Ding. 2023. "Underwater Image Super-Resolution via Dual-aware Integrated Network" Applied Sciences 13, no. 24: 12985. https://doi.org/10.3390/app132412985
APA StyleShi, A., & Ding, H. (2023). Underwater Image Super-Resolution via Dual-aware Integrated Network. Applied Sciences, 13(24), 12985. https://doi.org/10.3390/app132412985