
Enhancing Fake News Detection in Romanian Using Transformer-Based Back Translation Augmentation



Abstract
:1. Introduction
2. Related Work
3. Methodology
- RQ1: What is the effectiveness of transformer-based data augmentation approaches, specifically using mBART, in improving the detection of fake news in Romanian?
- RQ2: How does the performance of different models compare when augmented with BT data using Google Translate and mBART?
- RQ3: What is the impact of using different target languages, such as English and French, in the BT augmentation process?
| Algorithm 1 Fake news detection pipeline with data augmentation |
| data = CollectData(“Factual.ro”) train_set, test_set = SplitDataset(data, ratio = 0.8) def PreprocessData(data): cleaned_data = [] for text in data: text = RemoveSpecialChars(text) text = ConvertToLowercase(text) tokens = Tokenize(text) tokens = RemoveStopWords(tokens) tokens = Lemmatize(tokens) cleaned_text = RejoinTokens(tokens) cleaned_data.append(cleaned_text) vectorized_data = Vectorize(cleaned_data, method = “TF–IDF”) return vectorized_data def AugmentData(train_set): augmented_data = [] for text in train_set: augmented_text = BackTranslation(text) augmented_data.append(augmented_text) return augmented_data augmented_train_set = AugmentData(train_set) def TrainEvaluate(train_data, test_data): classifier = TrainClassifier(train_data) results = EvaluateClassifier(classifier, test_data) return Results train_set = PreprocessData(train_set) test_set = PreprocessData(test_set) original_results = TrainEvaluate(train_set, test_set) augmented_train_set = PreprocessData(augmented_train_set) augmented_results = TrainEvaluate(augmented_train_set, test_set) analysis = ComparePerformance(original_results, augmented_results) |
3.1. Data Set
3.2. Augmentation
3.3. Preprocessing
3.4. Classifiers
3.5. Evaluation
- Precision is the percentage of fake news instances correctly predicted out of all those predicted as fake.
- Recall is the percentage of instances of false news correctly predicted out of all instances of actual false news.
- Accuracy is the measure of the general correctness of the predictions of the model. It calculates the ratio of correctly predicted instances (fake and non-fake news) to the total number of instances.
- The F1 score provides a balanced assessment of model performance, combining accuracy and recall.
- The area under the curve is a common method to measure the accuracy of a binary classifier system, for example, for the detection of fake news. It provides a single metric that summarizes the classifier’s performance over all possible thresholds. A high AUC value indicates the model’s capability to differentiate between fake and real news accurately.
- Cohen’s kappa score, also known as Kappa, is a statistical measure that assesses the agreement between two classifiers in identifying if a news instance is fake or not. It is calculated by comparing the observed level of agreement between the two classifiers (Po) with the level of agreement expected by chance (Pe) [35].
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Horne, B.; Adali, S. This Just in: Fake News Packs a Lot in Title, Uses Simpler, Repetitive Content in Text Body, More Similar to Satire Than Real News. In Proceedings of the International AAAI Conference on Web and Social Media, Montreal, QC, Canada, 15–18 May 2017; Volume 11, pp. 759–766. [Google Scholar] [CrossRef]
- Zhou, C.; Xiu, H.; Wang, Y.; Yu, X. Characterizing the Dissemination of Misinformation on Social Media in Health Emergencies: An Empirical Study Based on COVID-19. Inf. Process. Manag. 2021, 58, 102554. [Google Scholar] [CrossRef] [PubMed]
- Lorenz-Spreen, P.; Oswald, L.; Lewandowsky, S.; Hertwig, R. A Systematic Review of Worldwide Causal and Correlational Evidence on Digital Media and Democracy. Nat. Hum. Behav. 2023, 7, 74–101. [Google Scholar] [CrossRef] [PubMed]
- Allcott, H.; Gentzkow, M. Social Media and Fake News in the 2016 Election. J. Econ. Perspect. 2017, 31, 211–236. [Google Scholar] [CrossRef]
- Taskin, S.G.; Kucuksille, E.U.; Topal, K. Detection of Turkish Fake News in Twitter with Machine Learning Algorithms. Arab. J. Sci. Eng. 2022, 47, 2359–2379. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, I.; Yousaf, M.; Yousaf, S.; Ahmad, M.O. Fake News Detection Using Machine Learning Ensemble Methods. Complexity 2020, 2020, 8885861. [Google Scholar] [CrossRef]
- Kumar, S.; Asthana, R.; Upadhyay, S.; Upreti, N.; Akbar, M. Fake News Detection Using Deep Learning Models: A Novel Approach. Trans. Emerg. Telecommun. Technol. 2020, 31, e3767. [Google Scholar] [CrossRef]
- Wang, W.Y. “Liar, Liar Pants on Fire”: A New Benchmark Dataset for Fake News Detection. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 422–426. [Google Scholar]
- Canhasi, E.; Shijaku, R.; Berisha, E. Albanian Fake News Detection. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2022, 21, 1–24. [Google Scholar] [CrossRef]
- Bucos, M.; Țucudean, G. Text Data Augmentation Techniques for Fake News Detection in the Romanian Language. Appl. Sci. 2023, 13, 7389. [Google Scholar] [CrossRef]
- Ahuja, N.; Kumar, S. Mul-FaD: Attention Based Detection of multiLingual Fake News. J. Ambient. Intell. Hum. Comput. 2023, 14, 2481–2491. [Google Scholar] [CrossRef]
- Hlaing, M.M.M.; Kham, N.S.M. Comparative Study of Fake News Detection Using Machine Learning and Neural Network Approaches. In Proceedings of the 11th International Workshop on Computer Science and Engineering, Shanghai, China, 19–21 June 2021. [Google Scholar]
- Desamsetti, S.; Hemalatha Juttuka, S.; Mahitha Posina, Y.; Rama Sree, S.; Kiruthika Devi, B.S. Artificial Intelligence Based Fake News Detection Techniques. In Recent Developments in Electronics and Communication Systems; IOS Press: Amsterdam, The Netherlands, 2023; pp. 374–380. [Google Scholar]
- Zhang, J.; Dong, B.; Yu, P.S. FakeDetector: Effective Fake News Detection with Deep Diffusive Neural Network. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020; pp. 1826–1829. [Google Scholar]
- Murayama, T.; Wakamiya, S.; Aramaki, E.; Kobayashi, R. Modeling the Spread of Fake News on Twitter. PLoS ONE 2021, 16, e0250419. [Google Scholar] [CrossRef]
- Bayer, M.; Kaufhold, M.-A.; Reuter, C. A Survey on Data Augmentation for Text Classification. ACM Comput. Surv. 2023, 55, 146. [Google Scholar] [CrossRef]
- Li, B.; Hou, Y.; Che, W. Data Augmentation Approaches in Natural Language Processing: A Survey. AI Open 2022, 3, 71–90. [Google Scholar] [CrossRef]
- Keya, A.J.; Wadud, M.A.H.; Mridha, M.F.; Alatiyyah, M.; Hamid, M.A. AugFake-BERT: Handling Imbalance through Augmentation of Fake News Using BERT to Enhance the Performance of Fake News Classification. Appl. Sci. 2022, 12, 8398. [Google Scholar] [CrossRef]
- Salah, I.; Jouini, K.; Korbaa, O. On the Use of Text Augmentation for Stance and Fake News Detection. J. Inf. Telecommun. 2023, 7, 359–375. [Google Scholar] [CrossRef]
- Shushkevich, E.; Alexandrov, M.; Cardiff, J. Improving Multiclass Classification of Fake News Using BERT-Based Models and ChatGPT-Augmented Data. Inventions 2023, 8, 112. [Google Scholar] [CrossRef]
- Buzea, M.C.; Trausan-Matu, S.; Rebedea, T. Automatic Fake News Detection for Romanian Online News. Information 2022, 13, 151. [Google Scholar] [CrossRef]
- Busioc, C.; Dumitru, V.; Ruseti, S.; Terian-Dan, S.; Dascalu, M.; Rebedea, T. What Are the Latest Fake News in Romanian Politics? An Automated Analysis Based on BERT Language Models. In Ludic, Co-Design and Tools Supporting Smart Learning Ecosystems and Smart Education; Mealha, Ó., Dascalu, M., Di Mascio, T., Eds.; Smart Innovation, Systems and Technologies; Springer: Singapore, 2022; Volume 249, pp. 201–212. ISBN 9789811639296. [Google Scholar]
- Tucudean, G.; Bucos, M. The Use of Data Augmentation as a Technique for Improving Fake News Detection in the Romanian Language. In Proceedings of the 2022 International Symposium on Electronics and Telecommunications (ISETC), Timisoara, Romania, 10–11 Novermber 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–4. [Google Scholar]
- Raza, S.; Ding, C. Fake News Detection Based on News Content and Social Contexts: A Transformer-Based Approach. Int. J. Data Sci. Anal. 2022, 13, 335–362. [Google Scholar] [CrossRef]
- Collins, B.; Hoang, D.T.; Nguyen, N.T.; Hwang, D. Trends in Combating Fake News on Social Media—A Survey. J. Inf. Telecommun. 2021, 5, 247–266. [Google Scholar] [CrossRef]
- Liu, Y.; Gu, J.; Goyal, N.; Li, X.; Edunov, S.; Ghazvininejad, M.; Lewis, M.; Zettlemoyer, L. Multilingual Denoising Pre-Training for Neural Machine Translation. Trans. Assoc. Comput. Linguist. 2020, 8, 726–742. [Google Scholar] [CrossRef]
- Loper, E.; Bird, S. NLTK: The Natural Language Toolkit. In Proceedings of the ACL-02 Workshop on Effective Tools and Methodologies for Teaching Natural Language Processing and Computational Linguistics—Volume 1, Philadelphia, PA, USA, 7 July 2002; pp. 63–70. [Google Scholar]
- Qi, P.; Zhang, Y.; Zhang, Y.; Bolton, J.; Manning, C.D. Stanza: A Python Natural Language Processing Toolkit for Many Human Languages. arXiv 2020, arXiv:2003.07082. [Google Scholar]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely Randomized Trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Chang, C.-C.; Lin, C.-J. LIBSVM: A Library for Support Vector Machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Yu, H.-F.; Huang, F.-L.; Lin, C.-J. Dual Coordinate Descent Methods for Logistic Regression and Maximum Entropy Models. Mach. Learn. 2011, 85, 41–75. [Google Scholar] [CrossRef]
- Tufail, H.; Ashraf, M.U.; Alsubhi, K.; Aljahdali, H.M. The Effect of Fake Reviews on E-Commerce during and after COVID-19 Pandemic: SKL-Based Fake Reviews Detection. IEEE Access 2022, 10, 25555–25564. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Müller, A.; Nothman, J.; Louppe, G.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2018, 12, 2825–2830. [Google Scholar]
- Carletta, J. Assessing Agreement on Classification Tasks: The Kappa Statistic. Comput. Linguist. 1996, 22, 249–254. [Google Scholar]
- Kulkarni, M.; Chennabasavaraj, S.; Garera, N. Study of Encoder-Decoder Architectures for Code-Mix Search Query Translation. arXiv 2022, arXiv:2208.03713. [Google Scholar]
- Jawahar, G.; Nagoudi, E.M.B.; Abdul-Mageed, M.; Lakshmanan, L.V.S. Exploring Text-to-Text Transformers for English to Hinglish Machine Translation with Synthetic Code-Mixing. In Proceedings of the Fifth Workshop on Computational Approaches to Linguistic Code-Switching, Online, 11 June 2021; pp. 36–46. [Google Scholar]
- Zhang, Z.; Han, X.; Liu, Z.; Jiang, X.; Sun, M.; Liu, Q. ERNIE: Enhanced Language Representation with Informative Entities. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1441–1451. [Google Scholar]
- Kao, W.-T.; Lee, H. Is BERT a Cross-Disciplinary Knowledge Learner? A Surprising Finding of Pre-Trained Models’ Transferability. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 2195–2208. [Google Scholar]


{kind=link}
{kind=link}
| # | Attributes | Description |
|---|---|---|
| 1 | Topic | The category of the instance. This could include topics such as transport, work, politics, justice, and finance. |
| 2 | Content | The main content of the statement. |
| 3 | Date | The date the statement was published. |
| 4 | Author Name | The name of the author of the statement. |
| 5 | Affiliation | The author’s affiliation, such as their party, position, or organization. |
| 6 | Source Name | The name of the news source where the statement was published. |
| 7 | Context | Additional information or context provided in the statement. |
| 8 | Label | A label indicating whether the instance is classified as fake or real news. |
| Augmentation Type | Operation | Statement |
|---|---|---|
| None | - | Suntem singura tara care a internat persoane fara niciun simptom si am aglomerat spitalele. Am umplut spitalele cu persoane care nu aveau niciun fel de problema. Suntem singurii din Europa care au internat persoane fara niciun symptom. |
| Back Translation (Google Translate) | Translate to English | We are the only country that hospitalized people without any symptoms and we crowded the hospitals. We filled the hospitals with people who didn’t have any kind of problem. We are the only ones in Europe who have hospitalized people without any symptoms. |
| Translate back to Romanian | Suntem singura tara care a spitalizat persoanele fara simptome si am aglomerat spitalele. Am umplut spitalele cu oameni care nu aveau niciun fel de problema. Suntem singurii din Europa care au spitalizat persoane fara simptome. | |
| Back Translation (mBART) | Translate to English | We are the only country that has hospitalized people without any symptoms and we have crowded the hospitals. We filled the hospitals with people who had no problem. We are the only people in Europe who have interned people without any symptoms. |
| Translate back to Romanian | Suntem singura tara care a spitalizat oameni fara niciun simptom si am umplut spitalele. Am umplut spitalele cu oameni care nu au avut probleme. Suntem singurele persoane din Europa care au internat oameni fara niciun simptom. |
| Predicted Positive | Predicted Negative | |
| Actual Positive | True Positive (TP) | False Negative (FN) |
| Actual Negative | False Positive (FP) | True Negative (TN) |
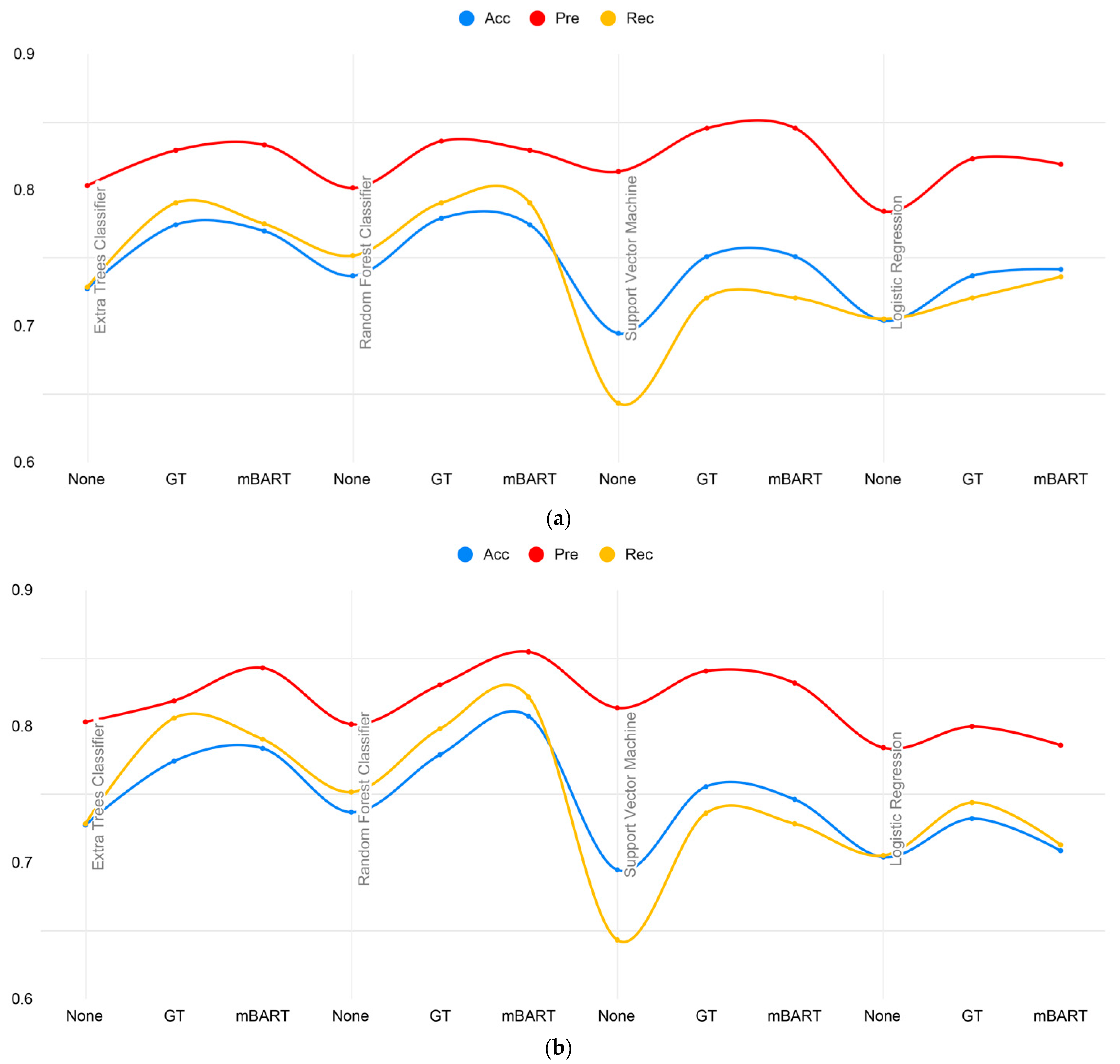
| Augmentation Type | Model Name | Acc | Pre | Rec | F1 | AUC | Kappa |
|---|---|---|---|---|---|---|---|
| None | Extra Trees Classifier | 0.7277 | 0.8034 | 0.7287 | 0.7301 | 0.8211 | 0.4438 |
| Random Forest Classifier | 0.7371 | 0.8017 | 0.7519 | 0.7389 | 0.8128 | 0.4586 | |
| Support Vector Machine | 0.6948 | 0.8137 | 0.6434 | 0.6981 | 0.7743 | 0.3950 | |
| Logistic Regression | 0.7042 | 0.7845 | 0.7054 | 0.7070 | 0.7586 | 0.3971 | |
| Back Translation (Google Translate) | Extra Trees Classifier | 0.7746 | 0.8293 | 0.7907 | 0.7759 | 0.8450 | 0.5340 |
| Random Forest Classifier | 0.7793 | 0.8360 | 0.7907 | 0.7807 | 0.8404 | 0.5447 | |
| Support Vector Machine | 0.7512 | 0.8455 | 0.7209 | 0.7539 | 0.8089 | 0.4989 | |
| Logistic Regression | 0.7371 | 0.8230 | 0.7209 | 0.7398 | 0.7770 | 0.4673 | |
| Back Translation (mBART) | Extra Trees Classifier | 0.7700 | 0.8333 | 0.7752 | 0.7716 | 0.8309 | 0.5272 |
| Random Forest Classifier | 0.7746 | 0.8293 | 0.7907 | 0.7759 | 0.8462 | 0.5340 | |
| Support Vector Machine | 0.7512 | 0.8455 | 0.7209 | 0.7539 | 0.8089 | 0.4989 | |
| Logistic Regression | 0.7418 | 0.8190 | 0.7364 | 0.7442 | 0.7720 | 0.4736 |
| Augmentation Type | Model Name | Acc | Pre | Rec | F1 | AUC | Kappa |
|---|---|---|---|---|---|---|---|
| None | Extra Trees Classifier | 0.7277 | 0.8034 | 0.7287 | 0.7301 | 0.8211 | 0.4438 |
| Random Forest Classifier | 0.7371 | 0.8017 | 0.7519 | 0.7389 | 0.8128 | 0.4586 | |
| Support Vector Machine | 0.6948 | 0.8137 | 0.6434 | 0.6981 | 0.7743 | 0.3950 | |
| Logistic Regression | 0.7042 | 0.7845 | 0.7054 | 0.7070 | 0.7586 | 0.3971 | |
| Back Translation (Google Translate) | Extra Trees Classifier | 0.7746 | 0.8189 | 0.8062 | 0.7751 | 0.8434 | 0.5302 |
| Random Forest Classifier | 0.7793 | 0.8306 | 0.7984 | 0.7804 | 0.8510 | 0.5428 | |
| Support Vector Machine | 0.7559 | 0.8407 | 0.7364 | 0.7584 | 0.8158 | 0.5054 | |
| Logistic Regression | 0.7324 | 0.8000 | 0.7442 | 0.7344 | 0.7712 | 0.4501 | |
| Back Translation (mBART) | Extra Trees Classifier | 0.7840 | 0.8430 | 0.7907 | 0.7855 | 0.8449 | 0.5553 |
| Random Forest Classifier | 0.8075 | 0.8548 | 0.8217 | 0.8084 | 0.8451 | 0.6012 | |
| Support Vector Machine | 0.7465 | 0.8319 | 0.7287 | 0.7491 | 0.8157 | 0.4863 | |
| Logistic Regression | 0.7089 | 0.7863 | 0.7132 | 0.7115 | 0.7723 | 0.4054 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bucos, M.; Drăgulescu, B. Enhancing Fake News Detection in Romanian Using Transformer-Based Back Translation Augmentation. Appl. Sci. 2023, 13, 13207. https://doi.org/10.3390/app132413207
Bucos M, Drăgulescu B. Enhancing Fake News Detection in Romanian Using Transformer-Based Back Translation Augmentation. Applied Sciences. 2023; 13(24):13207. https://doi.org/10.3390/app132413207
Chicago/Turabian StyleBucos, Marian, and Bogdan Drăgulescu. 2023. "Enhancing Fake News Detection in Romanian Using Transformer-Based Back Translation Augmentation" Applied Sciences 13, no. 24: 13207. https://doi.org/10.3390/app132413207
APA StyleBucos, M., & Drăgulescu, B. (2023). Enhancing Fake News Detection in Romanian Using Transformer-Based Back Translation Augmentation. Applied Sciences, 13(24), 13207. https://doi.org/10.3390/app132413207