1. Introduction
With the continuous development of the Internet, Internet text data is growing exponentially. Now it is an urgent problem to apply text classification technology to classify a huge number of diverse pairs of texts scientifically and effectively. As one of the most efficient natural language processing technologies, text classification has been widely used in the fields of public opinion analysis [
1], text content retrieval [
2], sentiment analysis of online comments [
3], etc. While relevant research has attracted attention, more and more people are looking for ways to make insight discoveries and improve decision-making by utilizing the ability provided by machine learning big data. Big data can be defined as “huge data sets beyond the storage, capture, management, or analysis capabilities of traditional database software” [
4]. The potential of this data depends on the ability to extract value from vast amounts of data through data analytics. Testing big data is challenging because of its diversity and complexity [
5].
Deep learning is a subfield of machine learning that enables performance improvements through data insight [
6]. Machine learning algorithms are rarely challenged by big data in acquiring knowledge. Big data provides a large amount of data and information, which can be used by machine learning algorithms to extract patterns or build analysis models [
7]. Methods based on deep neural networks, like the convolutional neural network (CNN) and the recurrent neural network (RNN), can extract deep-level features of text and have been widely known and used. The main task of the text classification method based on deep learning is to extract the features of the text and categorize the extracted text features through the neural network.
In recent years, with the in-depth study of text classification algorithms by researchers, it has been proven that deep learning methods are superior to traditional machine learning methods and have achieved good results in the field of natural language processing. However, these algorithms have some defects in the field of text classification, such as CNN’s inability to tackle the long-distance dependence problem in the text information, and RNN always reads the entire text input, resulting in a lengthy input process for longer sequences and insensitivity to key pattern information in the text. Therefore, it is imperative to solve the problems inherent in the above methods.
In this paper, a method called SA-SGRU is presented to address the shortcomings of the aforementioned methods. The SA-SGRU improves GRU and self-attention, making up for their shortcomings while effectively utilizing their advantages. In addition, the optimized CNN is effectively combined to extract richer text features and improve the performance of the model text classification.
The rest of this paper is organized as follows:
Section 2 introduces related work.
Section 3 presents the proposed method.
Section 4 describes the performance of the experiment using the proposed method.
Section 5 discusses our contributions and shortcomings, as well as future work.
Section 6 summarizes our research.
2. Related Works
The ever-increasing importance of structured data in different applications [
8] is no exception in text classification. Before using neural networks for text classification, the text needs to be transformed into a structured feature-semantic representation. Fan et al. [
9] combined the BERT and CNN algorithms to classify news texts. The core idea is to send BERT to CNN as an embedded layer. This method is superior to the simple BERT and CNN models. Zeng et al. [
10] proposed a classification method based on statement hierarchy and CNN. This method not only combines the improved TF-IDF algorithm and Word2vec technology but also uses CNN to extract text features and realize text classification. Lu [
11] used BERT and LSTM to build a keyword classification model for journal papers, and the results were significantly improved compared with traditional methods. With a deep and narrow neural network, BERT, a novel linguistic expression mode proposed by the Google team [
12], combined context in all neural network layers during training to achieve more accurate text prediction.
Deep learning has revolutionized computer vision, natural language understanding, speech recognition, information retrieval, and more [
13]. As one of the most common tasks in natural language processing, text classification is also deeply influenced by deep learning. The text deep network model based on hybrid neural network composition can extract more comprehensive, richer, and higher-level semantic information, which outperforms single networks like CNN and RNN for text classification and is the focus of recent research [
14]. Deng et al. [
15] proposed a new text classification model called attention-based BiLSTM that fused CNN with a gating mechanism (ABLG-CNN). The attention mechanism is used to derive keyword information, and BiLSTM captures context features. Based on this, CNN captures topic salient features, and a gating mechanism is introduced to assign weights to BiLSTM and CNN output features to obtain text fusion features that are favorable for classification, which achieved good results compared with the traditional models. Kejia Chen et al. [
16] proposed an optimized multichannel CNN combined with BiGRU, in which the global information extracted by BiGRU is stitched with the local features extracted by multichannel CNN and passed into the text classifier, thereby addressing the problem that a single neural network cannot obtain global semantic information and the gradient of a traditional RNN disappears. Chen Qian et al. [
17] proposed a multi-label classification of options based on the hybrid attention Seq2Seq model, where a multiheaded attention mechanism is used, replicating multiple warheads but with different weight coefficients because the initialization is different, which can better assign weights to the text. Jiming Hu et al. [
18] classified policy texts using the CNN-BILSTM-Attention model, which fully utilized the semantic features of policy texts and produced more accurate and efficient classification results than those previously models. Feng et al. [
19] proposed a multi-graph attention mechanism model (MCNN-MA) based on multi-channel convolutional neural networks. In this model, word features, part of speech features, location features, and dependency syntactic features were combined to form three new combination features, respectively, so as to better extract text features and achieve the best performance of the model. Li et al. [
20] proposed a combined model of the self-attention mechanism and BiLSTM for document-level text classification tasks, where the global semantic information of text is extracted by bi-directional LSTM and the representation of text features is improved by the self-attention mechanism. Iyad Alagha [
21] proposed a method based on knowledge-based features with multilevel attention mechanisms for short Arabic text classification, and the attention mechanism used in this method functions as a category filter, highlighting the most important features while reducing the influence of inappropriate features and improving the classification results.
Du et al. [
22] propose a novel knowledge-based Leap-LSTM framework, the core idea of which is to partially supervise the word skipping process through the manual or semi-automatic creation of in-domain keywords and other lexical resources. The jump network improves the efficiency of the model’s operation and gets more accurate prediction results. Krzystof et al. [
23] propose a text truncation method called Text Guide. The approach reduces the original text length to a predefined limit, which not only improves the performance of naive and semi-naive methods, but also keeps the computational cost low.
3. The Proposed Method
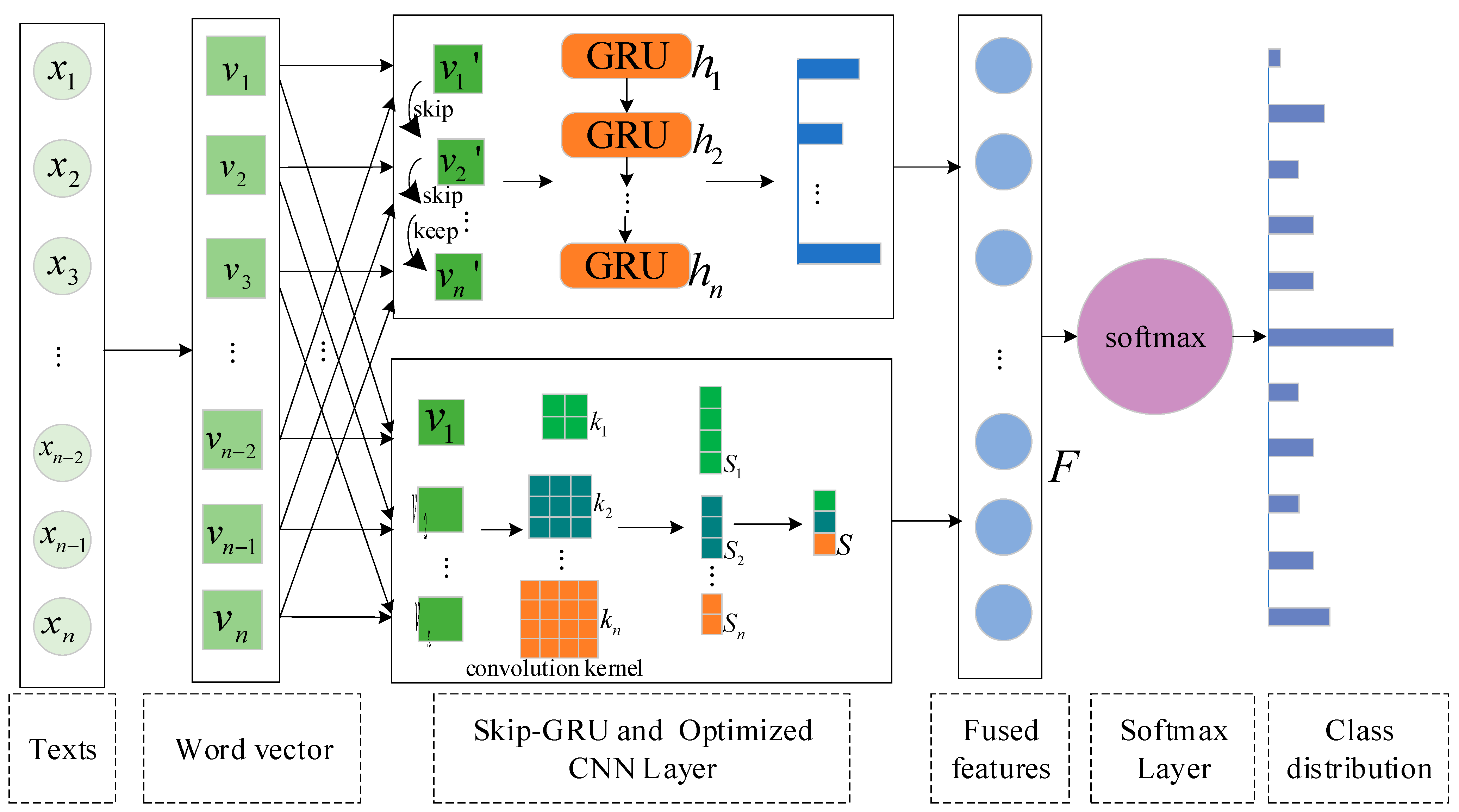
Figure 1 describes the text classification model SA-SGRU proposed in this paper. The whole framework consists of three parts: (1) Skip-GRU and an improved self-attention mechanism module; (2) an optimized CNN based on a multi-size convolutional kernel module; and (3) a reordering module.
An example illustrating the proposed framework of SA-SGRU: suppose that the input text sequence is “This is a very sad story,” denoted by the vector corresponding to the input text sequence obtained through the embedding layer. First, module (1) is used to capture global effective information on the input text, which first passes through the Skip network to obtain the vector for the more important content in the classification result (assuming that the three words “ this,” “is,” and ”a” in the sequence are skipped) and is then input into the GRU network. The feature vector with global information is obtained, and finally, the key feature information is obtained by redistributing the weight information through the improved self-attention mechanism. Second, in order to make up for the lack of sensitivity of module (1) to the local key information, module (2) is used to extract the local key information of the text with multi-size convolutional kernels. Feature vector obtained after the convolution operation of different sizes by (the value of in this paper is 2,3, and 4) and feature vector obtained after dimension reduction by the max pooling operation; Finally, module (3) is used to calculate the matching probability for the fused high-level semantics output by modules (1) and (2) to obtain the final classification result. The following sections explain each part of this method in detail.
3.1. Word Vector Based on GloVe
The traditional word feature representation method uses Word2Vec, but its shortcomings are obvious: the word and vector have a one-to-one relationship, making it difficult to solve synonyms and polysemous words. GloVe is an unsupervised technology that inherits most of the advantages of Word2Vec. It uses global statistics and global prior information and integrates the advantages of the co-occurrence window, which makes it more advantageous in the processing of synonyms and polysemous words and can contain more semantic and grammatical information. The GloVe model does not need to use a neural network for training and can directly use a corpus to calculate word vectors, which is easier to parallelize. In this paper, we used the word “vector GloVe,” pre-trained by Stanford University (
https://nlp.stanford.edu/projects/glove/ (accessed on 1 June 2022)), and the dimension of the word vector was 100.
3.2. Skip-GRU Network Module
GRU always reads the entire input contents of texts, but for the text classification task, most of the inputs are not necessary for the prediction results. When reading text, the Skip-GRU network module can skip over irrelevant information and produce more accurate predictions. The Skip-GRU model is shown in
Figure 2. The Skip-GRU network module consists of three parts: (i) Skip Network; (ii) GRU Network; (iii) Improved Self-Awareness Mechanism. Algorithm 1 shows the construction process of the skip network.
3.2.1. Skip Network
The task of the skip network is to calculate the jump probability before the word vector is input into the GRU network, determine the information to be skipped, and reserve more useful information in GRU according to the calculated jump probability. The skip network architecture is shown in
Figure 3.
The model is based on the standard GRU. Given an input sequence denoted as
,
, …,
, or
with length
. It can be denoted that
as the word embedding of the word at position
. Before inputting the text information into the GRU network, the text information needs to be input into two layers of a multi-layer perceptron, and the jump probability distribution is calculated by the perceptron. The jump probability is calculated as follows:
where
,
,
and
are the weights and biases of the two-layer multilayer perceptron.
is the state of the hidden state and
represents the probability.
3.2.2. GRU Network
GRU, a version of the conventional RNN, is a widely used gated recurrent neural network. The gradient disappearance or explosion issue can be reduced with GRU, much like LSTM, which can also successfully capture the semantic link between lengthy sequences. GRU has two gates: a reset gate and an update gate. The reset gate controls how new input data is integrated with old memory, while the update gate determines how much of the past memory is saved to the current time step.
The standard GRU reads each word sequentially and uses the update function to refresh the hidden state. The unit structure of the GRU is shown in
Figure 4. The status update for the GRU network is as follows:
where
,
, and
denotes the different weight matrices,
is the input information of the current moment,
is the hidden state of the previous moment,
is the reset gate,
is the update gate, and
is the output value of the cell.
The skip probability value
in 3.1.1 determines whether the word can be sent to the GRU network, and 0.5 is chosen as its threshold value. When
< 0.5, the input word is skipped, and the hidden layer is not updated:
when
> 0.5, it means that the word is more important to the classification result and will be sent to the GRU network. At this time, the hidden state of the GRU network will update as Equations (3)–(6). Algorithm 1 shows the construction of the skip network.
| Algorithm 1 Construction of The Skip Network |
| Input: The text sequence |
| Output: The probability of |
| 1. Do convolution operations on in to obtain word vector |
| 2.for vector in do |
| 3. |
| 4. |
| 5. if < 0.5 then |
| 6. skip this word |
| 7. else |
| 8. put into GRU network |
| 9. end if |
| 10. end for |
3.2.3. Improved Self-Attention Mechanism
In the text classification task, each word has a different degree of influence on the classification result. In order to distinguish the importance of each word, a self-attention mechanism layer is introduced to weight the output vector processed by Skip-GRU. The self-attention mechanism is a special variant of the attention mechanism. In order to better understand the principle of the self-attention mechanism, the calculation process of the attention mechanism is firstly analyzed. The attention mechanism can be understood as a mapping function composed of multiple
and
, and the calculation is shown in the following equations:
where
stands for
,
stands for
, is the vector-key value,
is the corresponding key value, and
is the weight value obtained after normalization by the
function.
The addition of the self-attention not only highlights the key features of the text but also yields a more accurate representation of the text feature. In the text classification task, the text vectors at different positions in the input sequence are considered to contribute differently to the output results. For example, the observation window for text vectors trained in the front position is narrow, and the information gained during training is limited, hence the self-attention weights generated from training are frequently larger. In order to avoid this phenomenon, the position weight parameter
is introduced to improve the self-attention mechanism. Redistribute the calculated self-attention weight probability value, suitably reduce the weight of the text vector at the front of the training position, and appropriately increase the weight of the text vector at the back of the training position, so as to further optimize the representation of text feature vectors and enhance the expression of text feature ability. The initial value of
, which is a parameter iterator and a subclass of Tensor, is 1. It is continuously optimized throughout the training phase in order to increase the weight of text characteristics in the back position while decreasing the overall weight of self-attention in the front position. The improved self-attention mechanism assigns weight information as follows:
where
is the text word length,
is the
-dimensional vector output from the GRU layer, and
denotes the adjustment factor of the function, which usually indicates the dimensionality of the input vector. The adjustment factor can adjust the inner product of
to avoid the uneven distribution of the results due to the large gap between the values obtained by the function.
3.3. Optimized CNN
CNN is the main method for extracting data features in deep learning, which has the advantage of multi-channel parallelism and setting multiple convolutional kernels to extract features. In this paper, three CNN channels are used for local feature extraction from text, and the parameters of the three channels are independent of each other. In order to enhance the learning ability of CNN and obtain richer text features, a batch normalization layer is introduced. The optimized CNNs consist of convolutional and pooling layers. Algorithm 2 shows the construction of an optimized CNN. The main working process of CNN is shown in
Figure 5.
| Algorithm 2 Construction of The Optimized CNN |
| Input: Text vectors |
| Output: Multi-granularity text features |
| 1. Text features = None |
| 2. = convolution kernel size (2,3,4) |
| 3. for in do |
| 4. = CNN(), = |
| 5. |
| 6. end for |
3.3.1. Convolutional Layer
Following the convolution layer’s acquisition of feature data from the network’s preceding layer, the convolution kernel performs convolution operations from different abstract levels, producing features with local key information. For a convolutional kernel, usually only one class of feature can be extracted, but the content of each type of text is not the same, therefore using different sizes of convolutional kernels can extract richer local features. In this paper, the kernel size of convolution is set to 2, 3, and 4, and the number of filters is set to 256.
The operation of convolution can be expressed as:
where
denotes the
th eigenvalue of the text output by the convolution operation,
is the activation function Relu,
is the dot product of two matrices,
denotes the word vector matrix that is sufficient for the
th word to be the
th word, and
is the bias.
3.3.2. Pooling Layer
There are three common pooling operations: maximum pooling, minimum pooling, and average pooling operations. The feature vector output from the convolution layer usually has a high dimensionality, which can put a large computational burden on the model. The pooling layer can do dimensionality reduction on the information obtained from the convolutional layer, which not only can alleviate the computational pressure problem but also can prevent the model from overfitting. In this paper, the maximum pooling operation is chosen at the pooling layer, which is effective in improving the computational efficiency while maintaining the most significant features as much as possible. After the pooling operation, a fixed-length vector is output:
where
is the fixed vector obtained by the pooling operation of the vector from the convolutional layer.
3.4. Connection Output Layer
Finally, the softmax classifier is used to calculate the feature vector output by the previous layer and to determine the category to which the text belongs. The probability that the classifier classifies the text into class
is:
where
is the text input,
is all the parameters in the training process, and
is the total number of text categories.
4. Experiment and Results
This section discusses the data set of the experiment, the establishment of the experimental environment, and the experimental results. First, the data sets are introduced in
Section 4.1; then, in
Section 4.2, experimental parameter settings and evaluation indexes of experimental results are introduced. The last
Section 4.3 not only shows the comparison of experimental results between the proposed model and other advanced models but also conducts ablation experiments as well as experiments on the influence of different text lengths, CNN convolution kernel sizes, and Skip-GRU hidden layer states on text classification results.
4.1. Dataset
In order to verify the effectiveness of the text classification model proposed in this paper, relevant experiments were conducted on the following 3 datasets, as shown by the statistics in
Table 1.
AGNews dataset. The AGNews dataset (
http://groups.di.unipi.it/~gulli/AG_corpus_of_news_articles.html (accessed on 1 June 2022)) is a collection of news articles collected by academic news search engine ComeToMyHead from more than 2000 news sources in 4 categories. The four categories include the world, science and technology, sports, and business. The AGNews dataset is a balanced short-text dataset, in which the number of each text category is equal, and the number of each text category is equal in the training set and the test set. There are 120,000 training samples and 7600 test samples in the dataset.
IMDB dataset. The IMDB dataset (
https://ai.stanford.edu/~amaas/data/sentiment/ (accessed on 1 June 2022)) is developed for the task of binary sentiment categorization of movie reviews with long text and paragraph form. There are an equal number of positive and negative reviews on IMDB. The two categories in the IMDB dataset are denoted “positive” and “negative.” The IMDB dataset is a balanced long-text dataset with an equal number of text categories in both the training and test sets. IMDB consists of an equal number of positive and negative reviews, which were split equally between the training set and the test set, with 25,000 comments each.
R8 dataset. The R8 dataset (
https://github.com/kk19990709/text-classifier-by-pytorch/tree/main/data (accessed on 1 June 2022)) is a subset of the Reuters news dataset and contains 8 topics. The 8 categories in the R8 data set are: ship, money-fx, grain, acq, trade, earn, crude, and interest. The R8 dataset is an unbalanced data set in which the number of each text category is equal. There are a total of 5485 training data points and 2189 testing data points.
4.2. Experimental Setup
In this paper, the Adam optimizer is used to optimize the model parameters, which uses the same learning rate for different parameters and independently adaptively adjusts the parameters during the training process to speed up the convergence of the model. The learning rate is adjusted by the warmup strategy. On the one hand, this strategy helps to reduce the early overfitting of the model to the mini-batch in the initial stage, and on the other hand, it helps to maintain the stability of the deep model. The parameter information is shown in
Table 2.
In order to verify the performance of different classification methods, this paper evaluates all classification methods based on a confusion matrix. A confusion matrix is a way of capturing and extracting the significance of predictions and true values. False positives (FP) are values that were predicted to be positive but are negative. False negatives (FN) are values that were predicted to be negative but are positive. True positives (TP) are values that are predicted to be positive and are positive. True negatives (TN) are both predicted and observed to be negative [
24]. Several indicators can be derived from these metrics, such as Acc (accuracy), P (precision), R (recall), and F1 (f1-score), which are defined as:
In summary, the variables in the metric are defined as follows:
True positive (TP): Comments that were initially categorized as positive and were projected to be positive by the classifier.
False positive (FP): Comments that were initially categorized as positive but were projected by the classifier to be negative.
True negative (TN): Comments that were initially categorized as negative and were also predicted to be negative by the classifier.
False negative (FN): Comments that were categorized as negative but were predicted as positive by the classifier.
4.3. Results Analysis
4.3.1. Performance
Taking accuracy as the evaluation index, the text classification model proposed in this paper is experimentally compared with the following various baseline models:
CNN-based models, including TextCNN [
25] and CNN-LSTM [
26].
RNN-based models, including LSTM-CNN [
27], BiLSTM [
28], and LSTM [
29].
Semi-supervised models, including SALNET [
30]. SALNET includes attention-based LSTM (SALNET1), attention-based LSTM+TextCNN (SALNET2), and attention-based LSTM+BERT (SALNET3).
Adversarial training-based models, include KATG [
31] and Lex-AT [
32]. KATG includes KATG + TextCNN(KATG1), KATG + LSTM (KATG2), and KATG + BERT (KATG3). Lex-AT includes Lex + TextCNN (Lex-AT1), Lex + LSTM (Lex-AT2), and Lex + BERT (Lex-AT3).
In-depth analysis of the experimental comparison results in
Table 3 reveals that the single network models, such as TextCNN, LSTM, and BiLSTM, do not perform very well because the single network model can only extract the single text feature.
SALNET is a semi-supervised bootstrap learning framework, and it is based on semi-supervised and attention-oriented LSTM, which is insensitive to local key pattern information and performs less well than the SA-SGRU model in terms of classification accuracy. It can be seen that BERT exhibits the best performance compared to SALNet using baseline classifiers such as attention-based LSTM and TextCNN. BERT obtains text representations using a bi-directional transformer encoder and has richer text semantic understanding than attention-based LSTM and attention-based LSTM+TextCNN. Thus, attention-based LSTM+BERT performs better in text classification tasks.
The accuracy of the models based on KATG and Lex-AT adversarial training is no less than 91.50% on AGNews and no less than 87.40% on the IMDB dataset, outperforming semi-supervised self-learning frameworks in classification results. The accuracy of the three models based on KATG adversarial training is higher than that of the three models based on Lex-AT adversarial training. KATG not only uses the previous sentence to guide the generation of adversarial sentences but also proposes a keyword bias-based sampling method to select the sentence containing the biased word as the previous sentence. Compared with the model constructed by Lex-AT, the model constructed by KATG is more capable of capturing the keyword information in the sentences, resulting in greater classification accuracy.
Compared with the above baseline models, except KATG3 and Lex-AT3, the proposed SA-SGRU outperforms the other baseline models on all three datasets.
4.3.2. Ablation Analysis
To validate the effectiveness of each part of the SA-SGRU model, we also conducted ablation experiments for each module on AGNews and IMDB datasets. There are not only comparisons between different modules and the SA-SGRU model, but also comparisons between the GRU+self-attention and CNN modules before the improvement and the corresponding Skip-GRU+improved self-attention and the optimized CNN modules after the improvement. The experimental results are shown in
Table 4.
Table 4 shows that the improved channels all have some degree of advantage in classification accuracy relative to the unimproved channels, indicating that the performance of each improved part has been improved. Multi-CNN improves by 4.52%, 1.68%, and 3.68% on three datasets in classification accuracy compared with CNN, indicating that the optimized CNN can extract multi-dimensional and richer text features by multi-dimensional convolutional kernels, which well compensates the weakness of CNN with inadequate content extraction by single convolutional kernels. Comparing the classification performances of both the Multi-CNN model and the Skip-GRU+improved self-attention model with the total model SA-SGRU, there is a certain degree of decrease in accuracy, indicating that the modules are complementary to each other. It also shows that both the improved Skip-GRU+improved self-attention module and the optimized CNN module are effective for the classification performance of SA-SGRU.
4.3.3. The Effect of Sequence Length on Model
When dealing with text sequences in text classification tasks, their length is usually fixed. However, since each sentence is of a different length and contains different information, it is important to choose an appropriate text sequence length. In this part, we will explore the impact of different text sequences on the classification of the model. The average length of data in AGNew is 45, the average length of data in IMDB is 223.27, and the average length of data in R8 is 65.72. The sentences in each dataset are set up as five groups of sequences of different lengths. If the text length is less than the predetermined processing length, the zero mark will be padded, and if the text exceeds the predetermined processing length, it will be truncated.
Figure 6 shows the three datasets with different text sequence lengths and the corresponding experimental results.
The results are shown in
Figure 6. It can be seen from
Figure 6a,b that, based on the average length of the sequence in the two short text datasets AGNews and R8, appropriately increasing the length of the text sequence can improve the classification performance of Skip-GRU. Too long text sequences will not only not improve the classification performance, but too long sentence sequences will also cause words with less semantic connection to participate in the derivation of keywords, affect the weight of keyword assignment, and may also lead to degradation of classification performance and an increase in running time. From
Figure 6c, we can see that when the sequence length does not reach the average length, the model classification effect increases with the sequence length. When the length of the text sequence exceeds the average length, the classification effect of the model is improved to a certain extent, but the improvement effect is not obvious.
4.3.4. The Effect of CNN Convolutional Kernel Size on Model
In order to verify the influence of convolution kernel size on the final text classification effect, the control variable method was adopted in the setting of model parameters. The hidden layer dimension of Skid-GRU was set to a fixed value of 128 dimensions, and then 5 groups of convolution kernels with different sizes were selected for experimentation. The five groups of convolution kernel data of different sizes selected in the experiment are shown in
Table 5, and the experimental results are shown in
Figure 7.
As shown in
Figure 7, from
Figure 7a, it can be seen that when the convolution kernel size is group A and group B, the model performs better on the AGNews dataset than the other groups; from
Figure 7b, it can be seen that when the convolution kernel size is the 5 groups of data in
Table 5, although the performance of the model on IMDB data is not much different, it performs best in group C; and from
Figure 7c, it can be seen that when the convolution kernel size is group A, group C, group D, and group E, the performance of the model on the R8 dataset is not much different, but the model performance is the best in group C. This also proves that there is no fixed set of model parameters applicable to all datasets.
4.3.5. The Effect of Skip-GRU Hidden State Dimension on Model
In this section, we will study the impact of different hidden states of skip GRU on classification. Similar to the size of the CNN convolution kernel, we explore the changes in the classification performance of the model when the hidden layer state dimensions of the skip GRU are set to different sizes. The size of the CNN convolution kernel is fixed at (2, 3, and 4), and the hidden layer state dimension of the skip GRU is adjusted from 32 dimensions; four values of 32, 64, 128, and 256 are selected for experiments. The experimental results are shown in
Figure 8. In
Figure 8, (a) shows the variation of the accuracy of the model with the hidden layer value on the three datasets, and (b) shows the average time required for the model to train 1 epoch on the training set under different dimensions.
As can be seen from
Figure 8a in
Figure 8, with the increase of the hidden layer value, the text classification effect of the model on the three datasets is significantly improved. However, when the dimension reaches 128 dimensions and continues to increase the dimension value, the classification accuracy of the model on the AGNews, IMDB, and R8 datasets is only improved by 0.19, 0.64, and 0.61, respectively. At this time, the classification effect is not significantly improved compared to the 128-dimensional model. From
Figure 8b,
Figure 8b shows that when the dimension is greater than 128, the model training time increases significantly while the performance remains stable.
5. Discussion
Overall, the above experimental results show that our proposed SA-SGRU model can maintain a high level of accuracy in text classification while skipping unimportant information in the text. Compared with other advanced models, the SA-SGRU model reduces model computation and improves model operation efficiency when skipping text information.
Moreover, the SA-SGRU model is simple to implement. In the SA-SGRU model, the standard GRU and self-attention mechanisms are improved, CNN is optimized, and the advantages of the three are combined to make up for each other’s shortcomings: (1) For Skip-GRU, GRU is adopted as the semantic analysis module, which can not only overcome the problem of the gradient explosion of RNNs but also capture semantic information at a greater distance. Since GRU network always reads all the input content of text, and for text classification tasks, most of the input is not necessary for the prediction results, a jump mechanism is set before GRU network, which can skip irrelevant information when reading text and improve the semantic reading efficiency of GRU network. (2) At present, the self-attention mechanism focuses on exploring the influence of each word in a sentence on the semantic level of the sentence and assigning attention weight to each word. However, considering the different contributions of text vectors at different positions in the input sequence to the output results, for example, text vectors trained in the front position have relatively limited information in the training process due to the small observation window. Therefore, the overall weight of self-attention obtained by training will be greater. In order to avoid this phenomenon, the positional parameter is introduced to change the self-attention mechanism. In order to further optimize the representation of text feature vectors and enhance the expression ability of text features, the calculated probability value of self-attention weight should be redistributed to appropriately reduce the weight of the text vector at the front of the training position and appropriately increase the weight of the text vector at the back of the training position. (3) In order to make up for the insensitivity of local key information in the Skip-GRU module, CNN with a multi-size convolution kernel is introduced. Usually, only one type of feature can be extracted from a convolution kernel, but the contents of various texts are different. Therefore, CNN with convolution kernels of different sizes can extract richer local features and improve the learning ability of the model.
Both the comparison and ablation experiments with baseline models show that the SA-SGRU model proposed in this paper has certain advantages in performance. However, when BERT is combined with the baseline model, BERT adopts a bidirectional transformer encoder to obtain text feature representation. Compared with GRUs, it has a more powerful text semantic understanding ability. In addition, the effects of text sequence length, CNN convolution kernel size, and Skip-GRU hidden layer dimension on the classification performance of the SA-SGRU model are also discussed.
In our future work, we will mainly focus on the following aspects: (1) designing a parallel computing method to reduce the time spent by the model in extracting features from the word context when the classification accuracy is comparable; (2) combining BERT and deep learning to fully play the role of BERT in text classification; and (3) applying our model to other language datasets besides English.
6. Conclusions
For text classification, when reading text, especially long text, a large number of words are irrelevant and can be skipped. Therefore, we started with improving GRU and self-attention mechanisms and proposed a text classification model combining skip-GRU and improved self-attention mechanisms. The model not only includes an improved GRU network and self-attention mechanism but also optimizes CNN to further extract richer text features. Different from the traditional model feature extraction method, we use a jump network mechanism to directly skip the information that is not important to the classification results from the text and then transfer the retained important information into the GRU network, which can effectively capture the semantic association between long text sequences. Considering that the GRU network is not sensitive to key pattern information, we use improved self-attention to reassign weight information to the information captured by the GRU network to enhance the expression ability of text features. Simultaneously, in order to further enrich the text’s features, optimized CNN is used to extract the text’s local key information.
We tested the performance of the SA-SGRU model on three public data sets and obtained good experimental results. We also compared the SA-SGRU model with some of the most advanced text classification models based on deep learning. In addition to the KATG3 and Lex-AT3 models, the SA-SGRU model proposed in this paper is superior to other comparison models on the three data sets. After an in-depth study, it was found that BERT, which has stronger textual semantic understanding ability, is used in both the KATG3 and Lex-AT3 models in the text vectorization part, while the SA-SGRU model proposed by us uses GloVe in the text vectorization part. Compared with the BERT model, the SA-SGRU model’s text semantic understanding ability in the text vectorization part is not so good, resulting in the final performance of the model being slightly worse than the KATG3 and Lex-AT3 models. In order to enhance the semantic understanding ability of the SA-SGRU model in the text vectorization part, we plan to combine the jump network proposed in this paper with BERT. However, considering the large amount of computation in the BERT model, improving the BERT model and reducing the amount of computation will be the focus of our research.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}