
Self-Attentive Subset Learning over a Set-Based Preference in Recommendation

Abstract
:1. Introduction
- -
- We propose a novel method, self-attentive subset learning model (SaSLM), to study the problem of set-based preference learning (SPL), which is important to efficiently reveal users’ preferences towards items with indirect supervision and protect their privacy as well. To the best of our knowledge, this is the first work to tackle set-based preference learning problem in an end-to-end manner.
- -
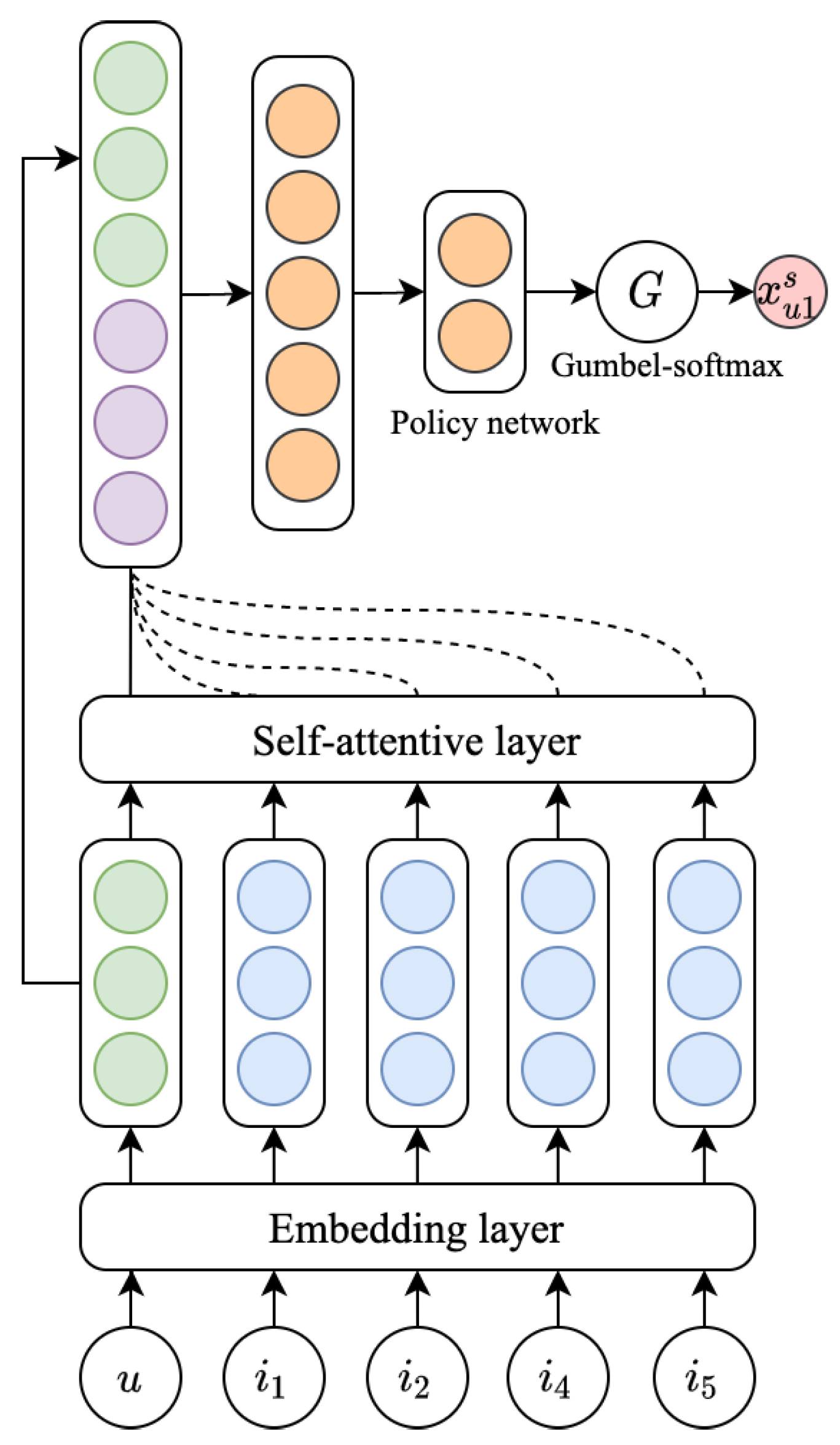
- We introduce a policy network to select a representative subset for each item set. By this means, the extent to which users’ preferences are influenced by different items is fully considered. Our proposed subset selection strategy is more flexible.
- -
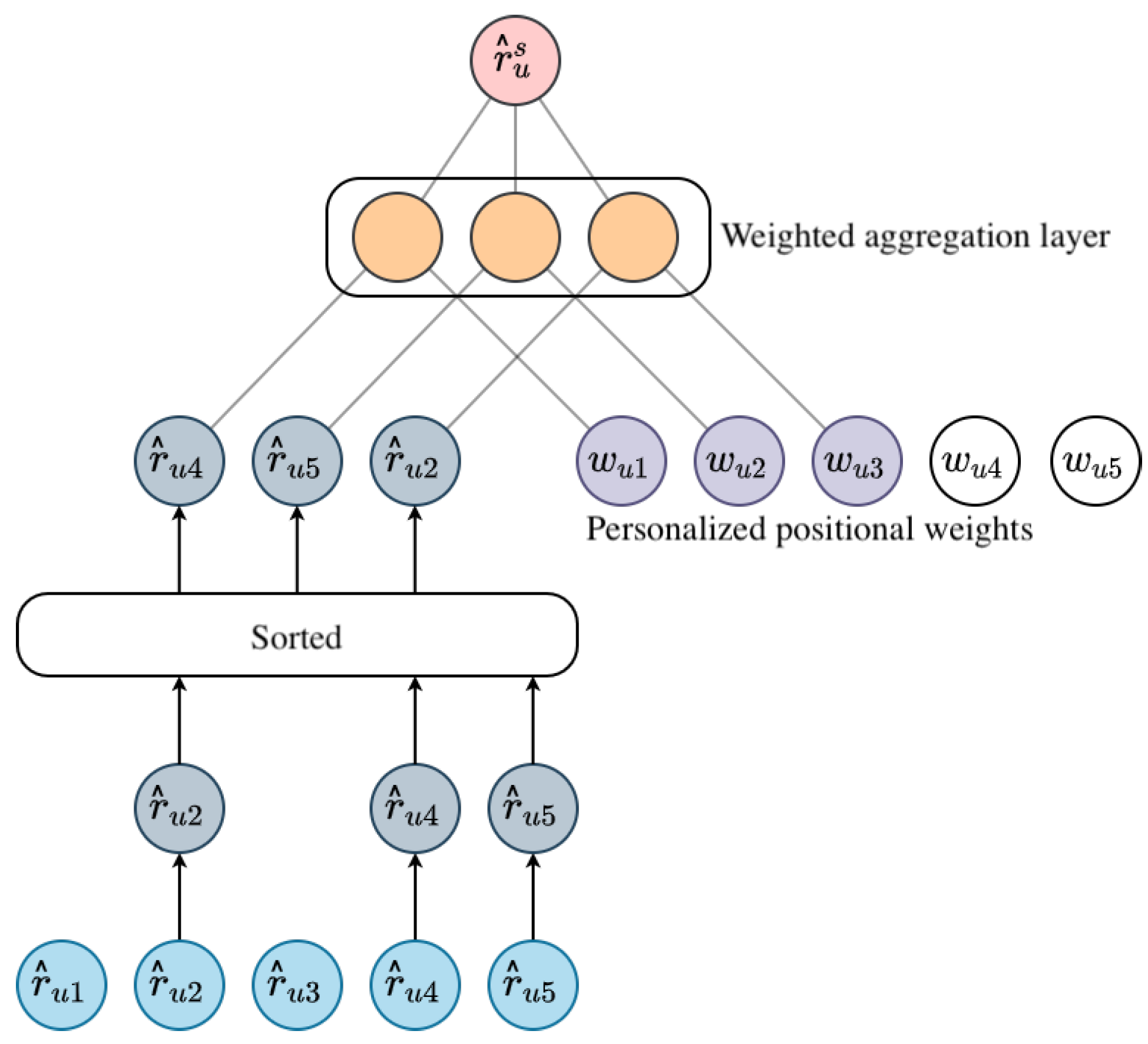
- We propose a novel personalized aggregation method to turn item-level predictions into set-level predictions by user-specific personalized positional weights, which is more efficient and has few parameters.
- -
- Through extensive empirical evaluation, the effectiveness of SaSLM at predicting item-level preferences under set-based preference supervision has been confirmed.
2. Related Work
2.1. Set-Preference Learning
- *
- average rating model (ARM) [5] assumes that a set-based rating reflects users’ average ratings for all the items. The estimated rating of user u for set S is given by the average of all predicted item ratings:
- *
- variance offset average rating model (VOARM) [5] captures the preference diversity of items in the set. Besides estimating the mean of the set rating, it also estimates the variance. Therefore, the final prediction is given by:where is the personalized factor; is mentioned in Equation (1) as the mean of the ratings of all items, and is the standard deviation of the ratings of items in the set S, which is given by:
- *
- extremal subset average rating model (ESARM) [5] estimates the ratings of extremal subsets and predicts set rating with weighted aggregation:where is the average rating of the i-th extremal subset.
2.2. Bundle Recommendation
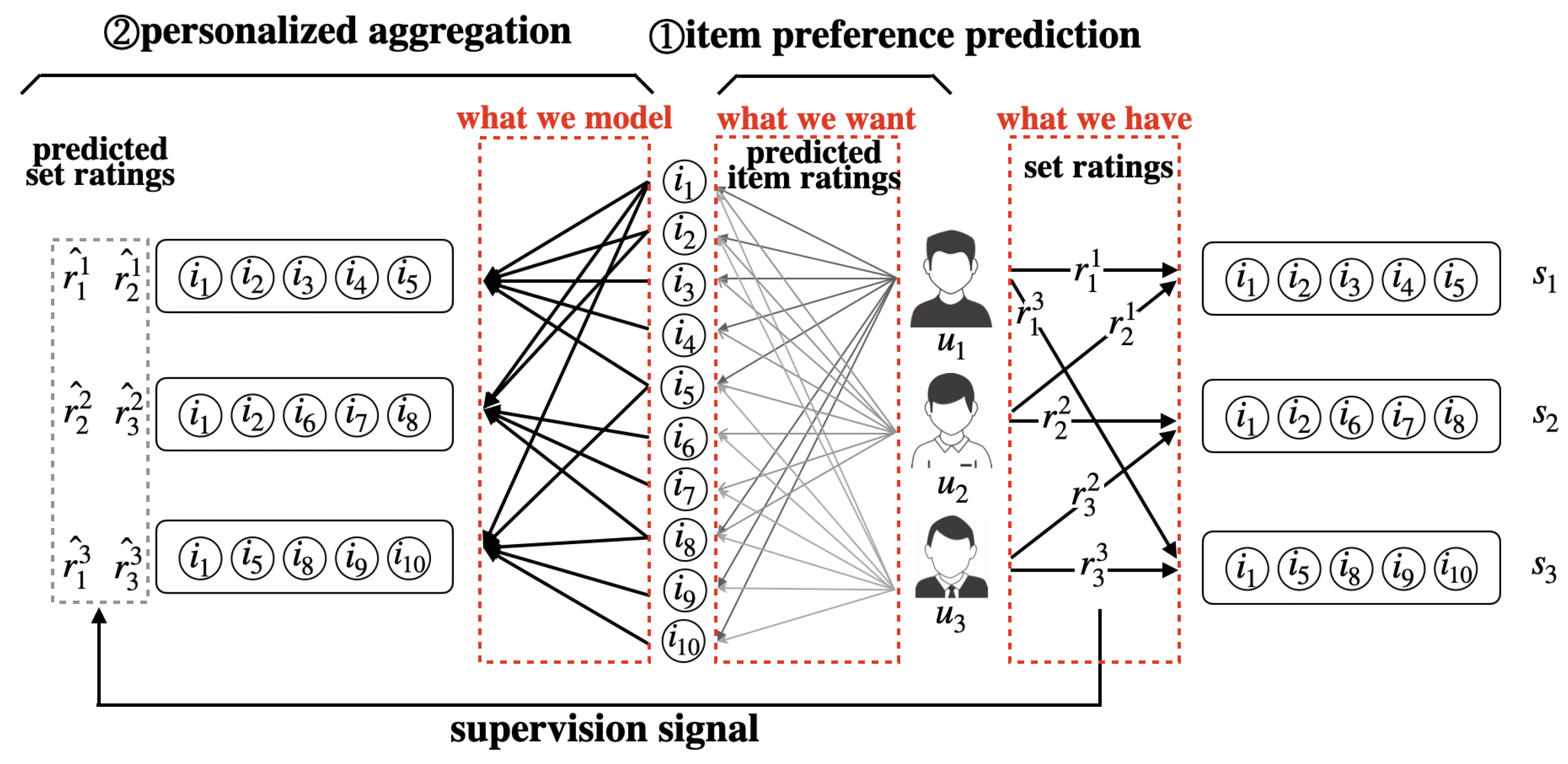
3. Preliminaries
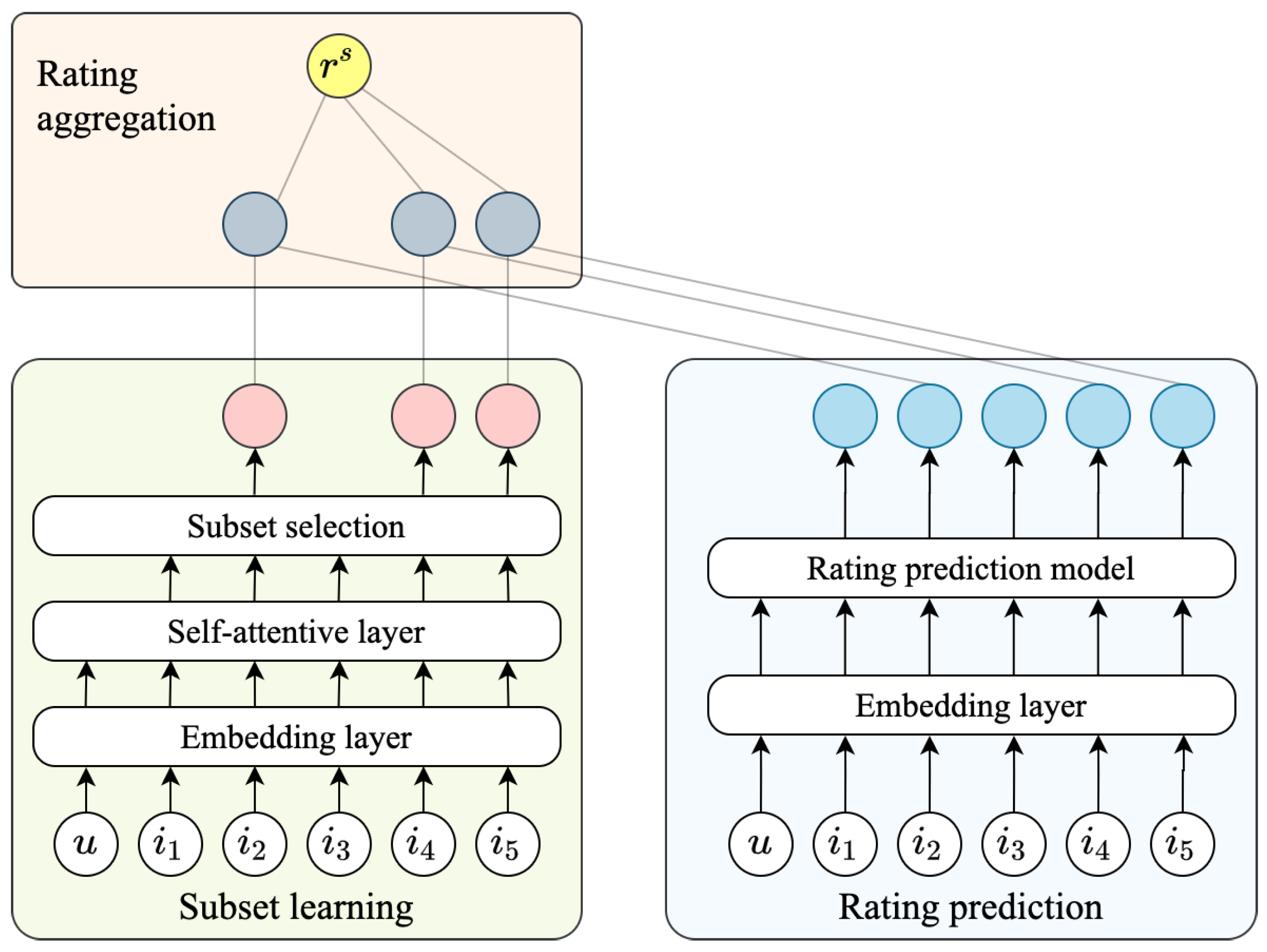
4. Model Description
4.1. Rating Prediction
4.2. Self-Attentive Subset Learning
4.3. Position-Aware Rating Aggregation
4.4. Model Learning
5. Experimental Setup
5.1. Dataset
- -
- RealSet: The dataset was collected from the MovieLens platform by [5]. Users were selected if they were active, since January 2015, and rated at least 25 movies. The set ratings were collected by sending emails to users. The movie sets were created by randomly selecting five movies without replacement from those they had already rated before.
- -
- NetEase: This is a dataset collected from the largest music platform in China by [19]. It enables users to create song bundles or thumbs-up any bundles created by others. We use NetEase as the dataset for SPL by treating the music bundle as the item set.
- -
- YouShu: This dataset was constructed by [20] from YouShu, a Chinese book review site. Similarly to NetEase, every bundle is a list of users’ desired books. We treat the book list as the item set.
5.2. Baselines
- -
- matrix factorization on set rating (MFSet): This is the personalized baseline compared in the experiments of [5]. It assumes that if a user rates a set, he/she will give all contained items the same ratings. The MFSet is the matrix factorization (MF) method with same set ratings assigned to all items.
- -
- -
- -
- -
- bundle collaborative filtering (BCF): The simple CF method that considers user-bundle interactions for bundle recommendation. BCF aggregates item embeddings to represent the bundle by simply adding all the embeddings. Therefore, the rating of user u on set s is given by:
- -
- bundle graph convolutional network (BGCN): The state-of-the-art method for bundle recommendation [21], which relies on graph convolutional network (GCN) [42] for embedding aggregation. Note that for SPL, we do not use user–item interactions for training. Therefore, for BGCN we only construct a user-bundle graph for embedding propagation.
5.3. Evaluation
6. Experimental Results
- RQ1
- Does the subset assumption—users’ feedback for sets is affected by subsets of items, not the whole set—hold?
- RQ2
- What is the overall performance of SaSLM for the task of SPL? How does SaSLM perform compared with existing SPL methods?
- RQ3
- How do different learning modules in SaSLM affect the performance of SPL?
- RQ4
- How does the pre-training of SaSLM affect the performance of SPL?
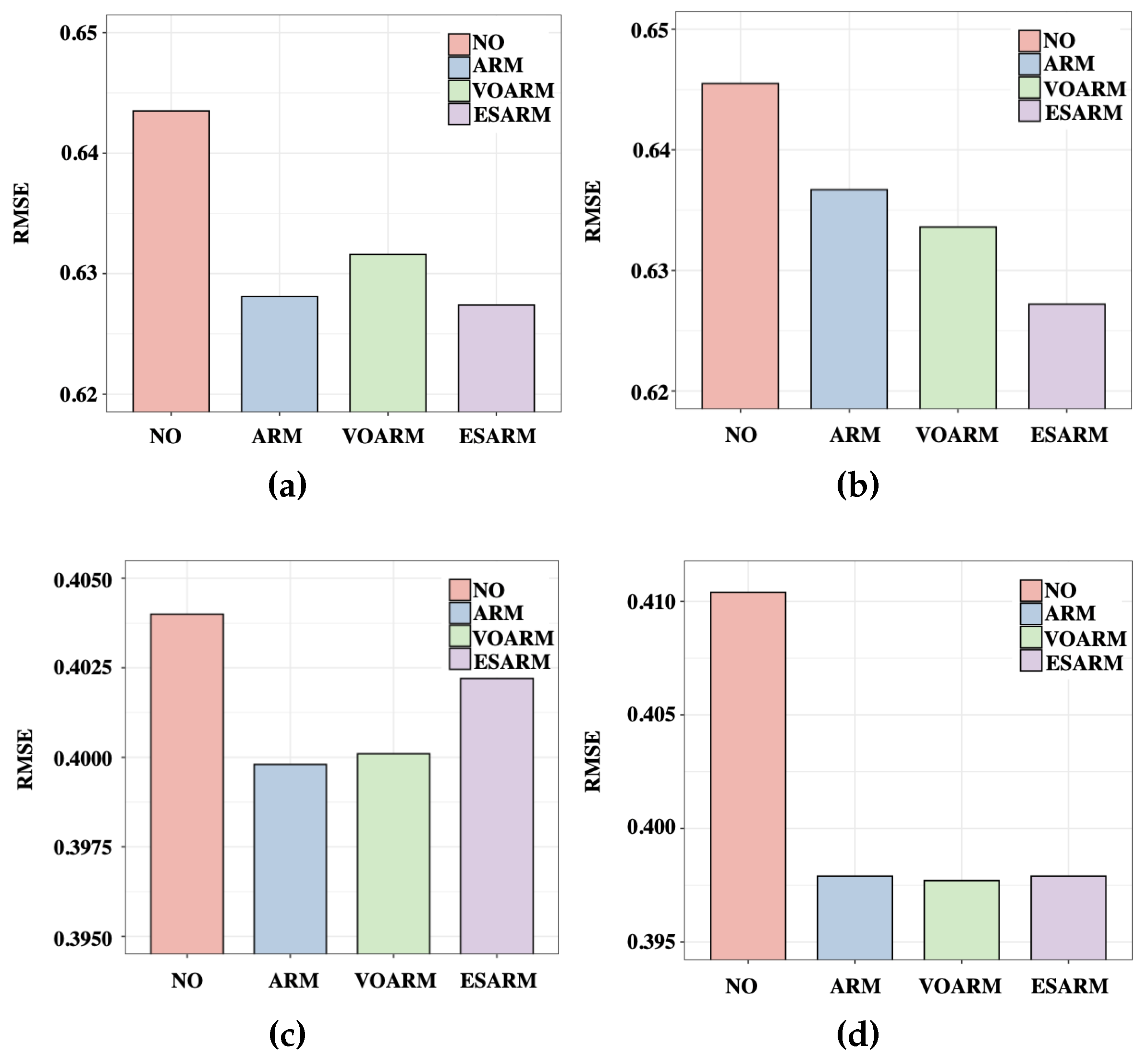
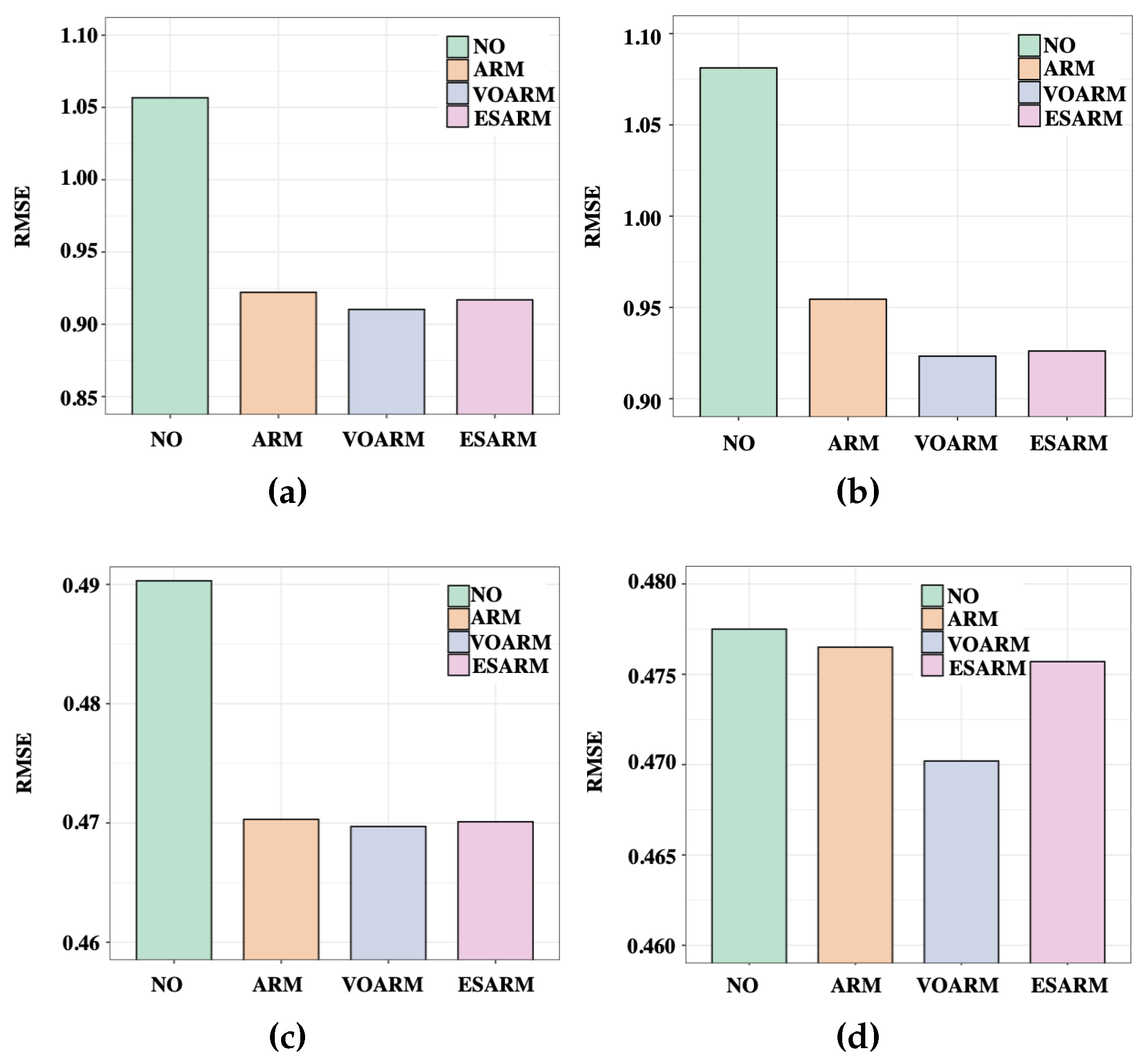
6.1. Feasibility of Subset Assumption
6.2. Overall Performance of SaSLM
6.2.1. Performance with RealSet
6.2.2. Performance for Bundle Sets
6.3. Ablation Study
6.4. Impact of Pre-Training
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Aggarwal, C.C. Recommender Systems; Springer International Publishing: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Koren, Y.; Bell, R.M.; Volinsky, C. Matrix Factorization Techniques for Recommender Systems. IEEE Comput. 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Hu, Y.; Koren, Y.; Volinsky, C. Collaborative Filtering for Implicit Feedback Datasets. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 263–272. [Google Scholar]
- Himeur, Y.; Sohail, S.S.; Bensaali, F.; Amira, A.; Alazab, M. Latest trends of security and privacy in recommender systems: A comprehensive review and future perspectives. Comput. Secur. 2022, 118, 102746. [Google Scholar] [CrossRef]
- Sharma, M.; Harper, F.M.; Karypis, G. Learning from Sets of Items in Recommender Systems. Ksii Trans. Internet Inf. Syst. 2019, 9, 19. [Google Scholar] [CrossRef] [Green Version]
- des Jardins, M.; Eaton, E.; Wagstaff, K. Learning user preferences for sets of objects. In Proceedings of the Machine Learning, Twenty-Third International Conference (ICML 2006), Pittsburgh, PA, USA, 25–29 June 2006; pp. 273–280. [Google Scholar]
- Brafman, R.I.; Domshlak, C.; Shimony, S.E.; Silver, Y. Preferences over Sets. In Proceedings of the Twenty-First National Conference on Artificial Intelligence and the Eighteenth Innovative Applications of Artificial Intelligence Conference, Boston, MA, USA, 16–20 July 2006; pp. 1101–1106. [Google Scholar]
- Brewka, G.; Truszczynski, M.; Woltran, S. Representing Preferences Among Sets. In Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2010, Atlanta, GA, USA, 11–15 July 2010. [Google Scholar]
- Chang, S.; Harper, F.M.; Terveen, L. Using Groups of Items for Preference Elicitation in Recommender Systems. In Proceedings of the 18th ACM Conference on Computer Supported Cooperative Work & Social Computing, CSCW’15; Association for Computing Machinery: New York, NY, USA, 2015; pp. 1258–1269. [Google Scholar]
- Aizenberg, N.; Koren, Y.; Somekh, O. Build your own music recommender by modeling internet radio streams. In Proceedings of the 21st International Conference on World Wide Web 2012, Lyon, France, 16–20 April 2012; pp. 1–10. [Google Scholar]
- Chen, S.; Moore, J.L.; Turnbull, D.; Joachims, T. Playlist prediction via metric embedding. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 714–722. [Google Scholar]
- Liu, Q.; Chen, E.; Xiong, H.; Ge, Y.; Li, Z.; Wu, X. A Cocktail Approach for Travel Package Recommendation. IEEE Trans. Knowl. Data Eng. 2014, 26, 278–293. [Google Scholar] [CrossRef]
- Liu, Q.; Ge, Y.; Li, Z.; Chen, E.; Xiong, H. Personalized Travel Package Recommendation. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining, Vancouver, BC, Canada, 11–14 December 2011; pp. 407–416. [Google Scholar]
- Hu, H.; He, X. Sets2Sets: Learning from Sequential Sets with Neural Networks. In Proceedings of the KDD 2019, Anchorage, AK, USA, 4–8 August 2019; pp. 1491–1499. [Google Scholar]
- Liu, Y.; Xie, M.; Lakshmanan, L.V.S. Recommending user generated item lists. In Proceedings of the 8th ACM Conference on Recommender Systems, Silicon Valley, CA, USA, 6–10 October 2014; pp. 185–192. [Google Scholar]
- Eksombatchai, C.; Jindal, P.; Liu, J.Z.; Liu, Y.; Sharma, R.; Sugnet, C.; Ulrich, M.; Leskovec, J. Pixie: A System for Recommending 3+ Billion Items to 200+ Million Users in Real-Time. In Proceedings of the 2018 World Wide Web Conference on World Wide Web, WWW 2018, Lyon, France, 23–27 April 2018; pp. 1775–1784. [Google Scholar]
- Greene, D.; Reid, F.; Sheridan, G.; Cunningham, P. Supporting the Curation of Twitter User Lists. arXiv 2011, arXiv:1110.1349. [Google Scholar]
- Pathak, A.; Gupta, K.; McAuley, J.J. Generating and Personalizing Bundle Recommendations on Steam. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Shinjuku, Tokyo, Japan, 7–11 August 2017; Kando, N., Sakai, T., Joho, H., Li, H., de Vries, A.P., White, R.W., Eds.; ACM: New York, NY, USA, 2017; pp. 1073–1076. [Google Scholar]
- Cao, D.; Nie, L.; He, X.; Wei, X.; Zhu, S.; Chua, T. Embedding Factorization Models for Jointly Recommending Items and User Generated Lists. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 585–594. [Google Scholar]
- Chen, L.; Liu, Y.; He, X.; Gao, L.; Zheng, Z. Matching User with Item Set: Collaborative Bundle Recommendation with Deep Attention Network. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI 2019, Macao, China, 10–16 August 2019; pp. 2095–2101. [Google Scholar]
- Chang, J.; Gao, C.; He, X.; Li, Y.; Jin, D. Bundle Recommendation with Graph Convolutional Networks. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 25–30 July 2020. [Google Scholar]
- Yu, L.; Sun, L.; Du, B.; Liu, C.; Xiong, H.; Lv, W. Predicting Temporal Sets with Deep Neural Networks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 6–10 July 2020. [Google Scholar]
- Yu, F.; Liu, Q.; Wu, S.; Wang, L.; Tan, T. A Dynamic Recurrent Model for Next Basket Recommendation. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2016, Pisa, Italy, 17–21 July 2016; pp. 729–732. [Google Scholar]
- Wang, P.; Guo, J.; Lan, Y.; Xu, J.; Wan, S.; Cheng, X. Learning Hierarchical Representation Model for NextBasket Recommendation. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 403–412. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Schmidt-Thieme, L. Factorizing personalized Markov chains for next-basket recommendation. In Proceedings of the 19th International Conference on World Wide Web, WWW 2010, Raleigh, NC, USA, 26–30 April 2010; pp. 811–820. [Google Scholar]
- Bai, T.; Zhang, S.; Egleston, B.L.; Vucetic, S. Interpretable Representation Learning for Healthcare via Capturing Disease Progression through Time. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2018, London, UK, 19–23 August 2018; pp. 43–51. [Google Scholar]
- Choi, E.; Bahadori, M.T.; Schuetz, A.; Stewart, W.F.; Sun, J. Doctor AI: Predicting Clinical Events via Recurrent Neural Networks. In Proceedings of the 1st Machine Learning in Health Care, MLHC 2016, Los Angeles, CA, USA, 19–20 August 2016; pp. 301–318. [Google Scholar]
- Benson, A.R.; Kumar, R.; Tomkins, A. Sequences of Sets. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2018, London, UK, 19–23 August 2018; pp. 1148–1157. [Google Scholar]
- Sarwar, B.M.; Karypis, G.; Konstan, J.A.; Riedl, J. Item-based collaborative filtering recommendation algorithms. In Proceedings of the Tenth International World Wide Web Conference, WWW 10, Hong Kong, China, 1–5 May 2001; pp. 285–295. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T. Neural Collaborative Filtering. In Proceedings of the 26th International Conference on World Wide Web, WWW 2017, Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]
- Koren, Y. Factorization meets the neighborhood: A multifaceted collaborative filtering model. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 426–434. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Jang, E.; Gu, S.; Poole, B. Categorical Reparameterization with Gumbel-Softmax. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008.
- He, Y.; Wang, J.; Niu, W.; Caverlee, J. A Hierarchical Self-Attentive Model for Recommending User-Generated Item Lists. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, CIKM 2019, Beijing, China, 3–7 November 2019; pp. 1481–1490. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR ’16, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Paisley, J.W.; Blei, D.M.; Jordan, M.I. Variational Bayesian Inference with Stochastic Search. In Proceedings of the 29th International Conference on Machine Learning, ICML 2012, Edinburgh, Scotland, UK, 26 June–1 July 2012. [Google Scholar]
- Williams, R.J. Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning. Mach. Learn. 1992, 8, 229–256. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. In Proceedings of the 2nd International Conference on Learning Representations, ICLR ’14, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian Personalized Ranking from Implicit Feedback. In Proceedings of the UAI 2009, the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence, Montreal, QC, Canada, 18–21 June 2009; pp. 452–461. [Google Scholar]
- Yuan, F.; Guo, G.; Jose, J.M.; Chen, L.; Yu, H.; Zhang, W. BoostFM: Boosted Factorization Machines for Top-N Feature-based Recommendation. In Proceedings of the 22nd International Conference on Intelligent User Interfaces, IUI 2017, Limassol, Cyprus, 13–16 March 2017; pp. 45–54. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| collection of users | |
| collection of items | |
| collection of item sets | |
| one set of items | |
| number of users, i.e., | |
| number of items, i.e., | |
| maximum length of item sets | |
| d | dimension of embeddings |
| collection of rating scores s | |
| the rating score that user u provided to set s | |
| the predicted score of user u to set s | |
| the predicted score of user u to item i | |
| the variable to indicate whether item i in the set S will be selected in the subset for user u | |
| embedding of user u | |
| embedding of item i | |
| personalized positional weights of user u | |
| embeddings of all users for item-level preference modelling | |
| embeddings of all items for item-level preference modelling | |
| embeddings of all users for subset selection | |
| embeddings of all items for subset selection | |
| personalized positional weights |
| Name | #Users | #Items | #Sets | #Ratings |
|---|---|---|---|---|
| RealSet | 853 | 13012 | 29516 | 29516 |
| YouShu | 8039 | 32770 | 4368 | 38977 |
| NetEase | 18528 | 123628 | 22864 | 302303 |
| Method | RealSet-Explicit | RealSet-Implicit |
|---|---|---|
| ARM | 0.5860968222869417 | 0.4042457595898088 |
| VOARM | 0.5250460857901433 | 0.38602755285412577 |
| ESARM | 0.5176173066578836 | 0.3741966704129639 |
| SaSLM | 0.5151 | 0.3712 |
| Method | Set-Level | Item-Level | |||
|---|---|---|---|---|---|
| RMSE | p-Value | RMSE | p-Value | ||
| RealSet-Explicit | MFSet | 0.6340 | – | 0.9369 | – |
| BCF | 0.6285 | – | 0.9296 | – | |
| ARM-MF | 0.6294 | 0.2633 | 0.9274 | 0.0 | |
| VOARM-MF | 0.6333 | 0.4071 | 0.9152 | 8.3 × 10−69 | |
| ESARM-MF | 0.6268 | 0.2230 | 0.9240 | 6.6 × 10−54 | |
| SaSLM-MF | 0.6316 | – | 0.9103 | – | |
| ARM-NCF | 0.6 | 0.6 | 0.9 | 0.0 | |
| VOARM-NCF | 0.6343 | 0.6 | 0.9325 | 0.0 | |
| ESARM-NCF | 0.6340 | 0.5 | 0.9246 | 0.0 | |
| SaSLM-NCF | 0.6336 | – | 0.9233 | – | |
| RealSet-Implicit | MFSet | 0.3967 | – | 0.4841 | – |
| BCF | 0.3970 | – | 0.4795 | – | |
| ARM-MF | 0.4 | 9.8 × 10−6 | 0.5 | 0.0 | |
| VOARM-MF | 0.3964 | 1.8 × 10−32 | 0.5 | 0.0 | |
| ESARM-MF | 0.4 | 4.5 × 10−26 | 0.5 | 0.0 | |
| SaSLM-MF | 0.4 | – | 0.4697 | – | |
| ARM-NCF | 0.4 | 2.9 × 10−14 | 0.5 | 0.0 | |
| VOARM-NCF | 0.4 | 4.9 × 10−15 | 0.5 | 6.6 × 10−40 | |
| ESARM-NCF | 0.4 | 3.4 × 10−12 | 0.5 | 0.0 | |
| SaSLM-NCF | 0.3977 | – | 0.4702 | – | |
| Method | Set-Level RMSE | Item-Level RMSE | |
|---|---|---|---|
| YouShu | MFSet | 0.46900 | 0.56802 |
| BCF | 0.4216 | 0.70448 | |
| BGCN | 0.446738426 | 0.70823738 | |
| ARM-MF | 0.49794 | 0.5013 | |
| VOARM-MF | 0.499981817 | 0.50175 | |
| SaSLM-MF | 0.49790 | 0.5000 | |
| ARM-NCF | 0.434325186 | 0.608324406 | |
| VOARM-NCF | 0.4184 | 0.779389501 | |
| SaSLM-NCF | 0.55863 | 0.51330 | |
| NetEase | MFSet | 0.48808 | 0.51281 |
| BCF | 0.4074 | 0.70347 | |
| BGCN | 0.63054 | 0.70729 | |
| ARM-MF | 0.49854 | 0.5002 | |
| VOARM-MF | 0.49530 | 0.50048 | |
| SaSLM-MF | 0.498504793 | 0.5001 | |
| ARM-NCF | 0.451660696 | 0.65352902 | |
| VOARM-NCF | 0.4456 | 0.720008123 | |
| SaSLM-NCF | 0.446088125 | 0.605812113 |
| Method | Set-Level RMSE | Item-Level RMSE | |
|---|---|---|---|
| RealSet-explicit | SLM | 0.6583 | 0.9181 |
| SLM | 0.6342 | 0.9160 | |
| SLM | 0.6588 | 0.9188 | |
| SaSLM | 0.6316 | 0.9103 | |
| RealSet-implicit | SLM | 0.4181 | 0.4701 |
| SLM | 0.4003 | 0.4698 | |
| SLM | 0.4180 | 0.4702 | |
| SaSLM | 0.4001 | 0.4697 | |
| YouShu | SLM | 0.54549 | 0.53326 |
| SLM | 0.56692 | 0.50067 | |
| SLM | 0.5025 | 0.4887 | |
| SaSLM | 0.4979 | 0.5000 | |
| NetEase | SLM | 0.58791 | 0.50008 |
| SLM | 0.58790 | 0.50014 | |
| SLM | 0.4985 | 0.50010 | |
| SaSLM | 0.58761 | 0.50011 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, K.; Chen, Y.; Tang, J.; Huang, H.; Liu, L. Self-Attentive Subset Learning over a Set-Based Preference in Recommendation. Appl. Sci. 2023, 13, 1683. https://doi.org/10.3390/app13031683
Liu K, Chen Y, Tang J, Huang H, Liu L. Self-Attentive Subset Learning over a Set-Based Preference in Recommendation. Applied Sciences. 2023; 13(3):1683. https://doi.org/10.3390/app13031683
Chicago/Turabian StyleLiu, Kunjia, Yifan Chen, Jiuyang Tang, Hongbin Huang, and Lihua Liu. 2023. "Self-Attentive Subset Learning over a Set-Based Preference in Recommendation" Applied Sciences 13, no. 3: 1683. https://doi.org/10.3390/app13031683
APA StyleLiu, K., Chen, Y., Tang, J., Huang, H., & Liu, L. (2023). Self-Attentive Subset Learning over a Set-Based Preference in Recommendation. Applied Sciences, 13(3), 1683. https://doi.org/10.3390/app13031683