
A Kitchen Standard Dress Detection Method Based on the YOLOv5s Embedded Model

 ,
,
Abstract
:1. Introduction
2. The Standard Dress Detection System
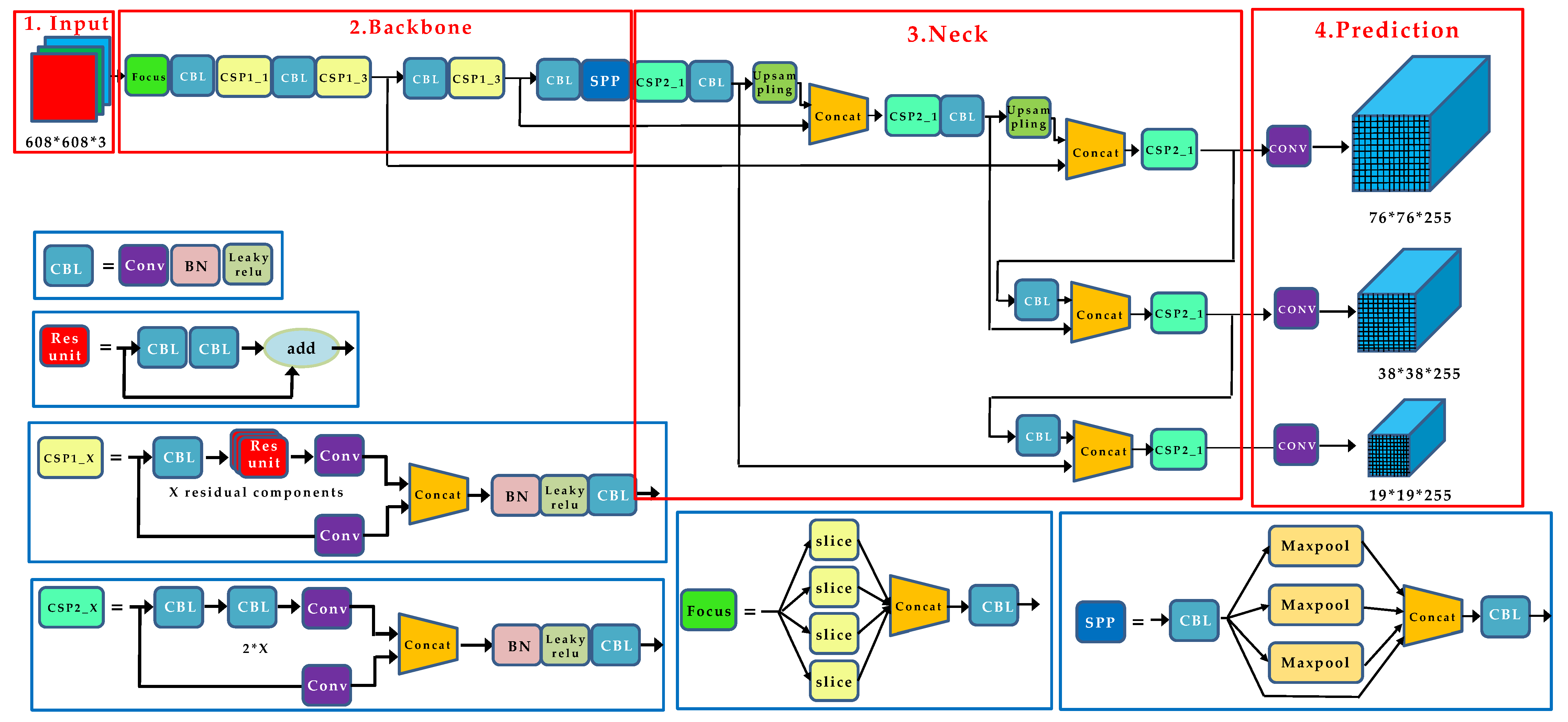
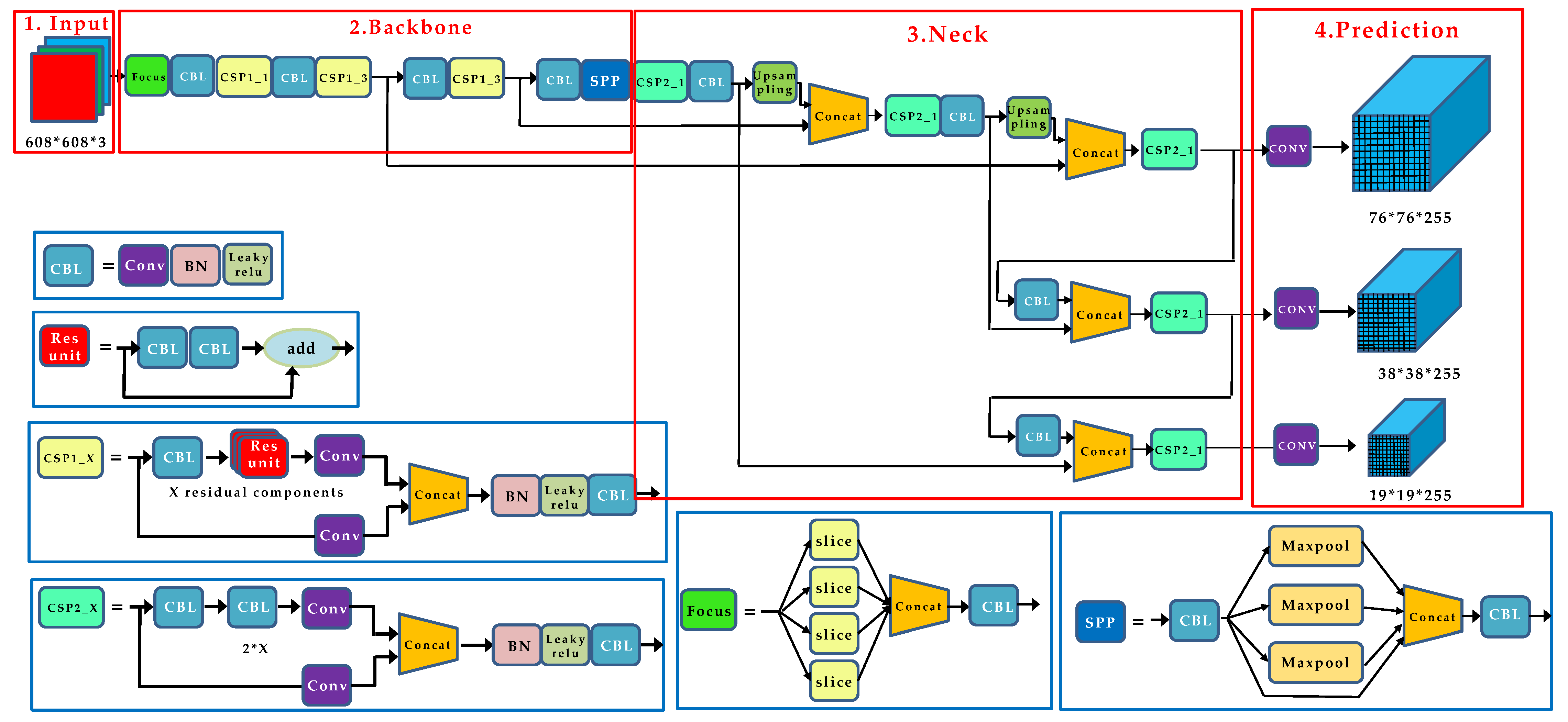
2.1. Detection Model Training Stage
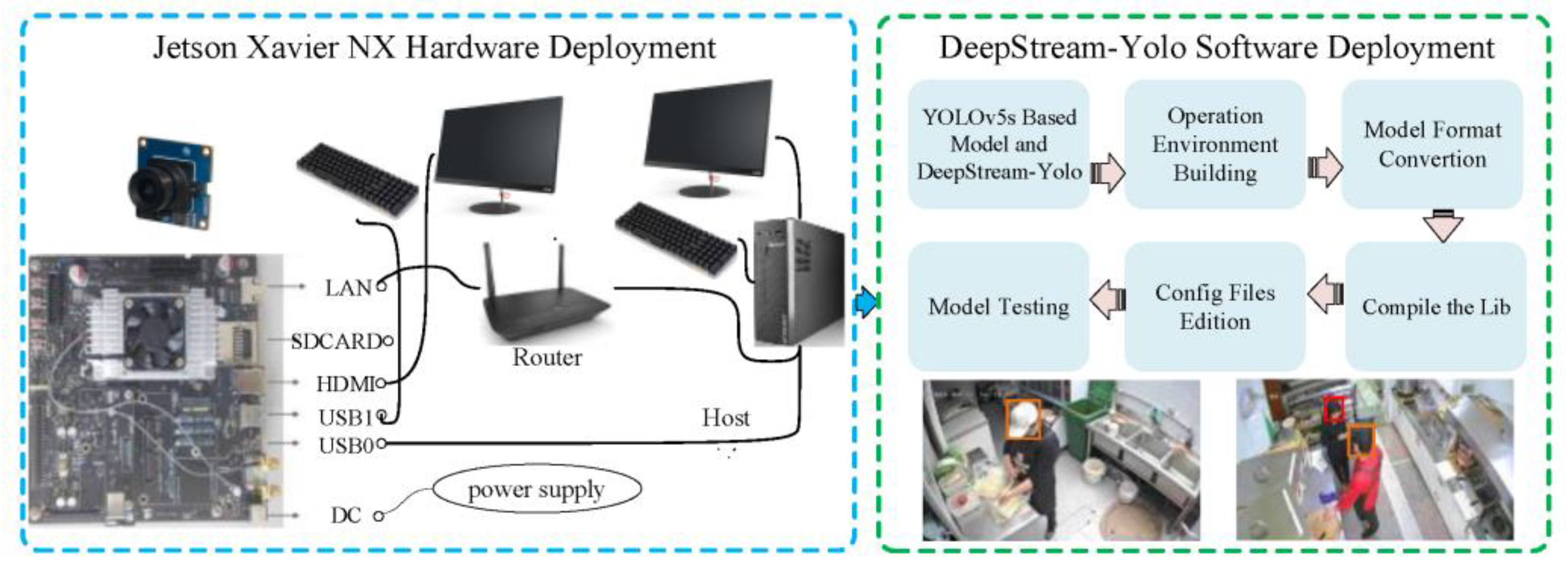
2.2. Model Deployment and Application Stage Based on Jetson Xavier NX
3. Experiments and Discussion
3.1. Experiment Setup and Data Preparation
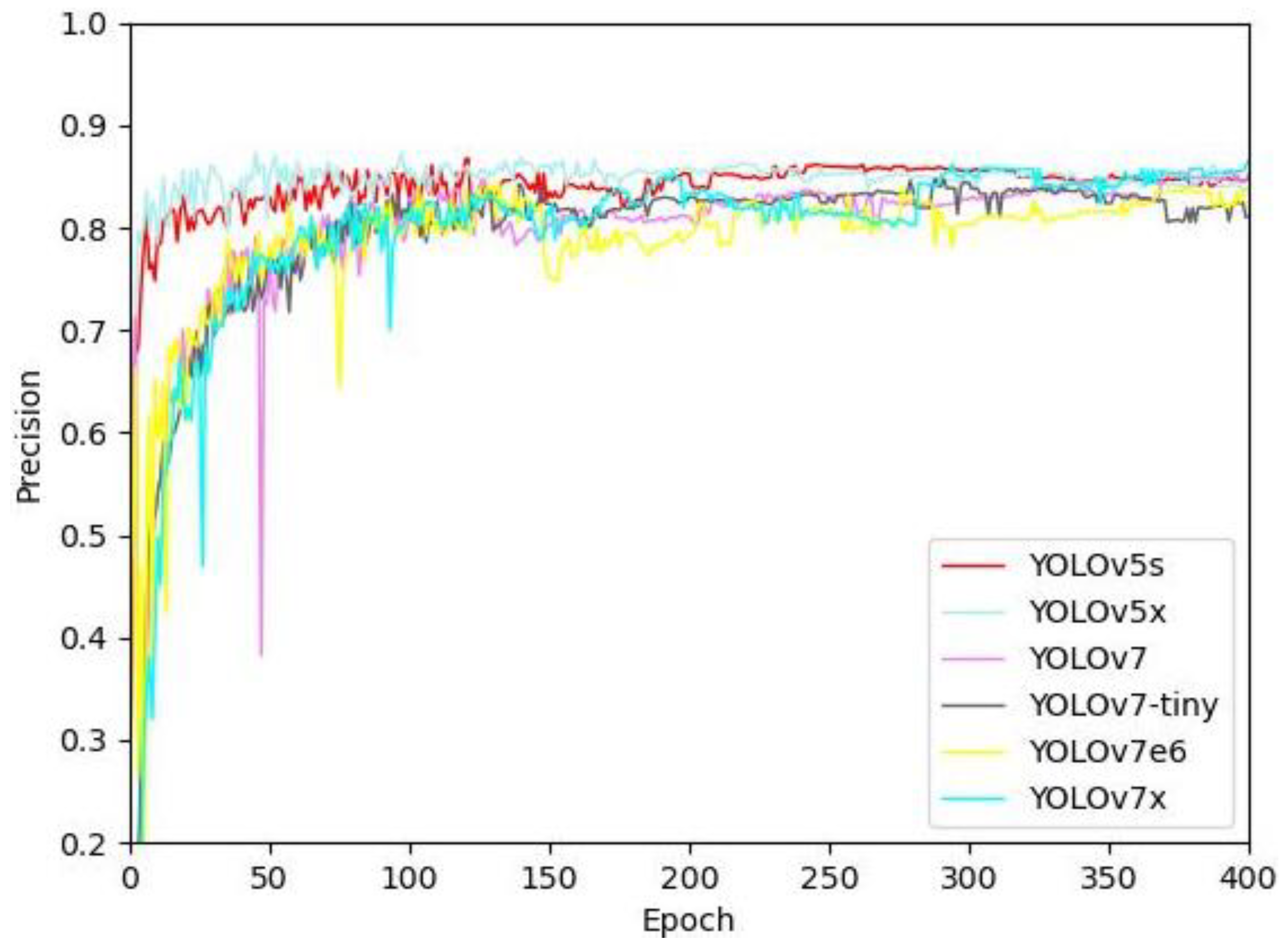
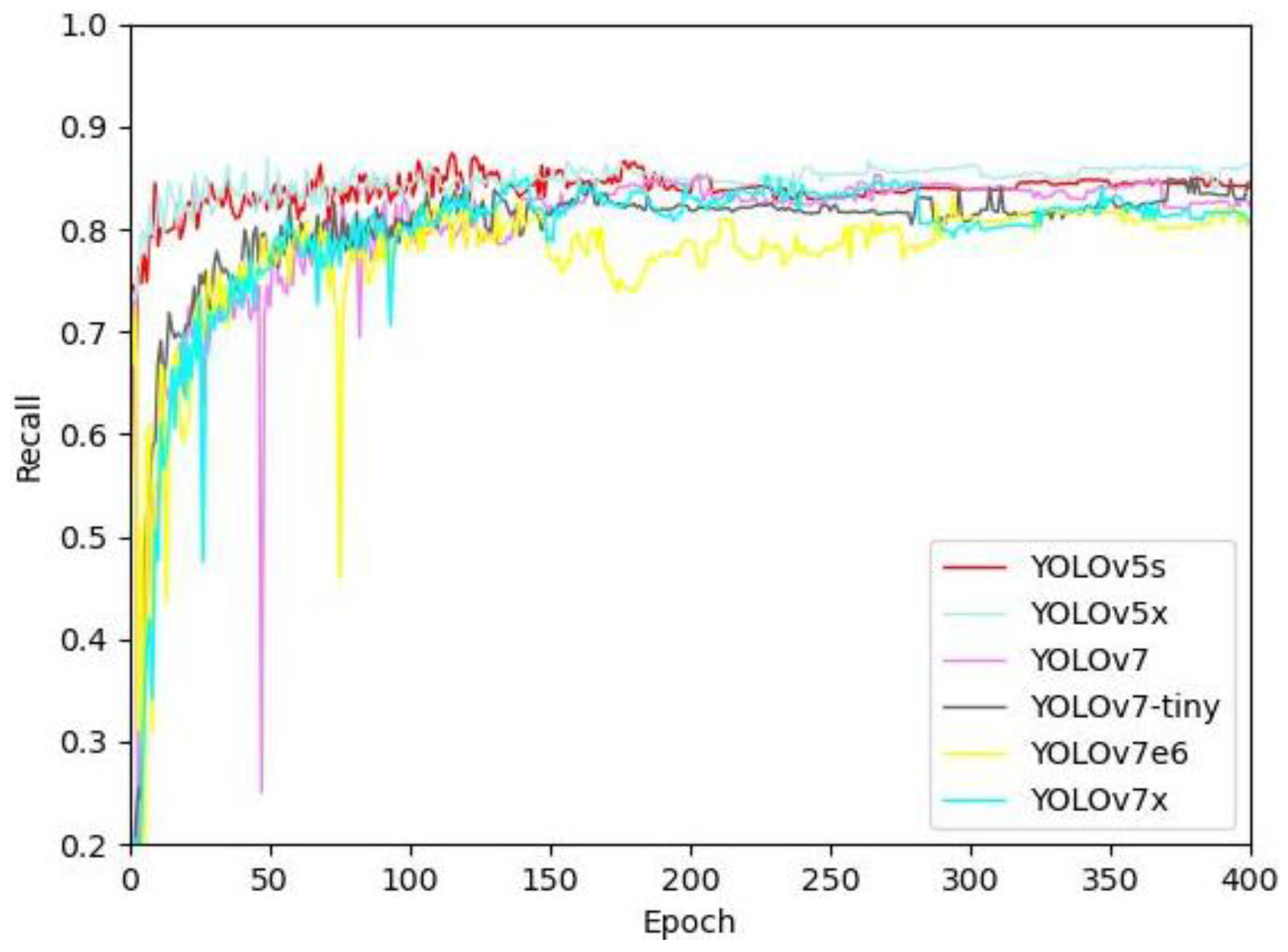
3.2. Performance Comparison with Existing Methods
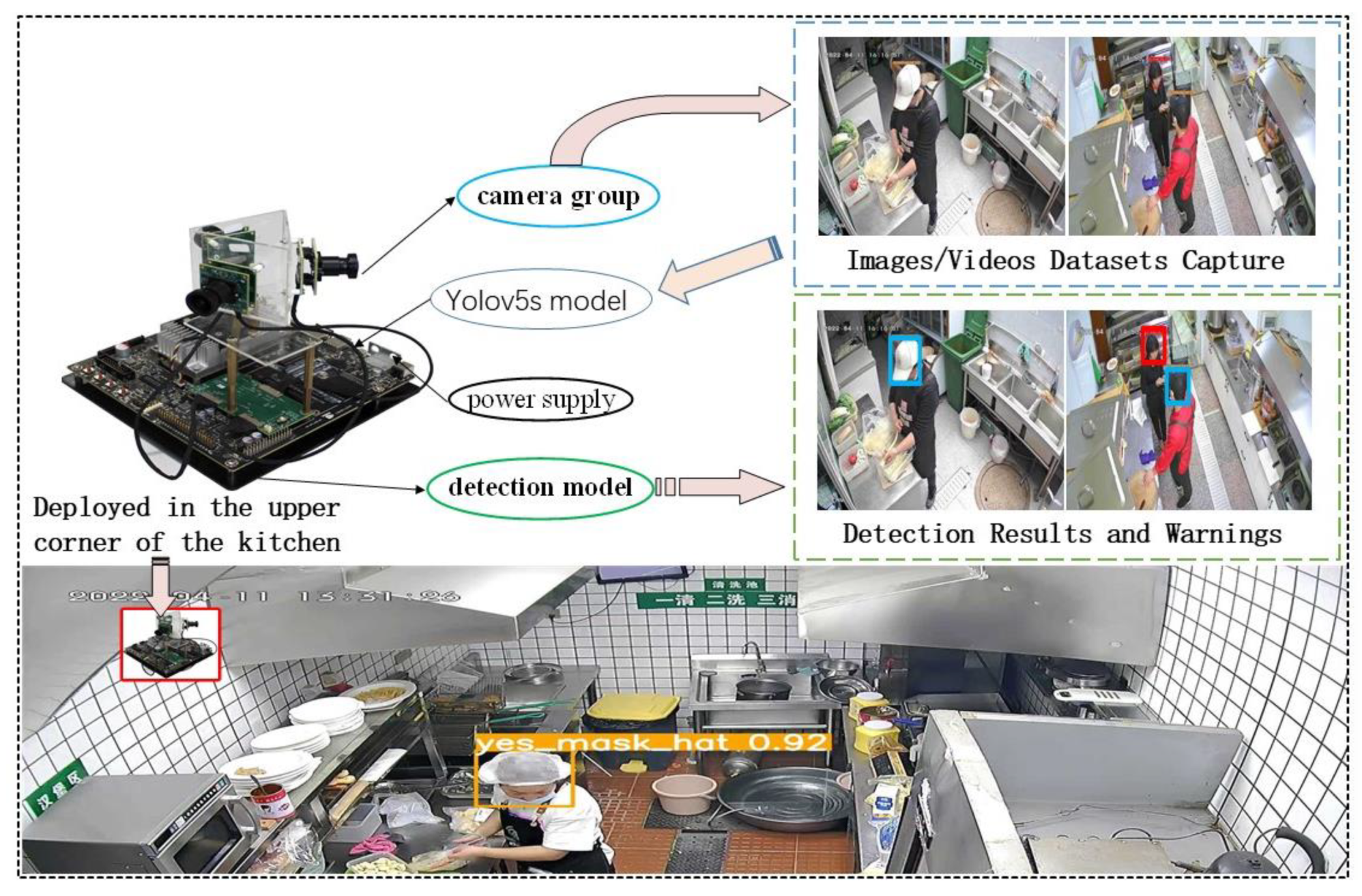
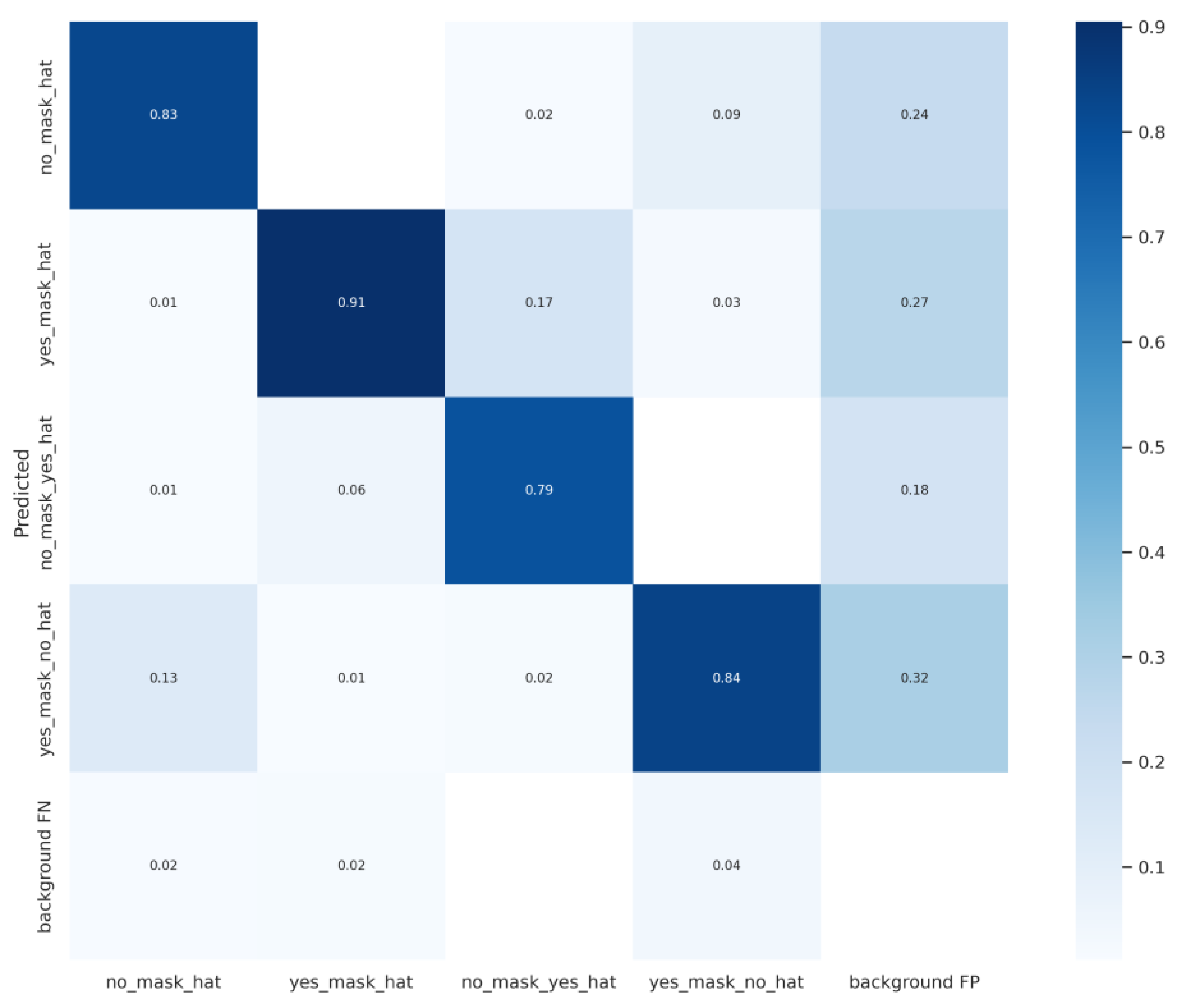
3.3. Results in the Kitchen
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sheng, Q.; Sheng, H.; Gao, P.; Li, Z.; Yin, H. Real-Time Detection of Cook Assistant Overalls Based on Embedded Reasoning. Sensors 2021, 21, 8069. [Google Scholar] [CrossRef] [PubMed]
- Ventrella, J.; MacCarty, N. Monitoring impacts of clean cookstoves and fuels with the Fuel Use Electronic Logger (FUEL): Results of pilot testing. Energy Sustain. Dev. 2019, 52, 82–95. [Google Scholar]
- Geng, S.; Liu, X.; Beachy, R. New Food Safety Law of China and the special issue on food safety in China. J. Integr. Agric. 2015, 14, 2136–2141. [Google Scholar] [CrossRef]
- Mihalache, O.A.; Møretrø, T.; Borda, D.; Dumitraşcu, L.; Neagu, C.; Nguyen-The, C.; Maître, I.; Didier, P.; Teixeira, P.; Lopes Junqueira, L.O.; et al. Kitchen layouts and consumers’ food hygiene practices: Ergonomics versus safety. Food Control 2022, 131, 108433. [Google Scholar] [PubMed]
- Chang, H.; Capuozzo, B.; Okumus, B.; Cho, M. Why cleaning the invisible in restaurants is important during COVID-19: A case study of indoor air quality of an open-kitchen restaurant. Int. J. Hosp. Manag. 2021, 94, 102854. [Google Scholar] [CrossRef]
- Jewitt, S.; Smallman-Raynor, M.; K C, B.; Robinson, B.; Adhikari, P.; Evans, C.; Karmacharya, B.M.; Bolton, C.E.; Hall, I.P. Domesticating cleaner cookstoves for improved respiratory health: Using approaches from the sanitation sector to explore the adoption and sustained use of improved cooking technologies in Nepal. Soc. Sci. Med. 2022, 308, 115201. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 39, 1137–1149. [Google Scholar]
- Ahmed, M.D.F.; Mohanta, J.C.; Sanyal, A. Inspection and identification of transmission line insulator breakdown based on deep learning using aerial images. Electr. Power Syst. Res. 2022, 211, 108199. [Google Scholar]
- Guo, X.; Zuo, M.; Yan, W.; Zhang, Q.; Xie, S.; Zhong, I. Behavior monitoring model of kitchen staff based on YOLOv5l and DeepSort techniques. In Proceedings of the MATEC Web of Conferences, Xiamen, China, 29–30 December 2021; pp. 1–7. [Google Scholar]
- Lin, Y.; Chen, T.; Liu, S.; Cai, Y.; Shi, H.; Zheng, D.; Lan, Y.; Yue, X.; Zhang, L. Quick and accurate monitoring peanut seedlings emergence rate through UAV video and deep learning. Comput. Electron. Agric. 2022, 197, 106938. [Google Scholar] [CrossRef]
- Tao, L.; Ruixia, W.; Biao, C.; Jianlin, Z. Implementation of kitchen food safety regulations detection system based on deep learning. In Proceedings of the 2021 6th International Conference on Intelligent Informatics and Biomedical Sciences (ICIIBMS), Oita, Japan, 25–27 November 2021; pp. 59–62. [Google Scholar]
- Ramadan, M.; El-Jaroudi, A. Action detection and classification in kitchen activities videos using graph decoding. Vis. Comput. 2022, 1–14. [Google Scholar] [CrossRef]
- van Staden, J.; Brown, D. An Evaluation of YOLO-Based Algorithms for Hand Detection in the Kitchen. In Proceedings of the 2021 International Conference on Artificial Intelligence, Big Data, Computing and Data Communication Systems (icABCD), Durban, South Africa, 5–6 August 2021; pp. 1–7. [Google Scholar]
- Yan, J.; Wang, Z. YOLO V3 + VGG16-based automatic operations monitoring and analysis in a manufacturing workshop under Industry 4.0. J. Manuf. Syst. 2022, 63, 134–142. [Google Scholar] [CrossRef]
- Lu, M.; Chen, L. Efficient object detection algorithm in kitchen appliance scene images based on deep learning. Math. Probl. Eng. 2020, 2020, 6641491. [Google Scholar] [CrossRef]
- Jiang, Q.; Jia, M.; Bi, L.; Zhuang, Z.; Gao, K. Development of a core feature identification application based on the Faster R-CNN algorithm. Eng. Appl. Artif. Intell. 2022, 115, 105200. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, S.; Zhao, S.; Lu, J.; Wang, Y.; Li, D.; Zhao, R. Fast detection of cannibalism behavior of juvenile fish based on deep learning. Comput. Electron. Agric. 2022, 198, 107033. [Google Scholar]
- Li, J.; Zhao, X.; Zhou, G.; Zhang, M. Standardized use inspection of workers' personal protective equipment based on deep learning. Saf. Sci. 2022, 150, 105689. [Google Scholar] [CrossRef]
- Tan, Y.; Yu, D.; Hu, Y. An application of an improved FCOS algorithm in detection and recognition of industrial instruments. Procedia Comput. Sci. 2021, 183, 237–244. [Google Scholar]
- Deshmukh, P.; Satyanarayana, G.S.R.; Majhi, S.; Sahoo, U.K.; Das, S.K. Swin transformer based vehicle detection in undisciplined traffic environment. Expert Syst. Appl. 2023, 213, 118992. [Google Scholar] [CrossRef]
- Ying, Z.; Lin, Z.; Wu, Z.; Liang, K.; Hu, X. A modified-YOLOv5s model for detection of wire braided hose defects. Measurement 2022, 190, 110683. [Google Scholar]
- Li, Y.; Wang, J.; Wu, H.; Yu, Y.; Sun, H.; Zhang, H. Detection of powdery mildew on strawberry leaves based on DAC-YOLOv4 model. Comput. Electron. Agric. 2022, 202, 107418. [Google Scholar] [CrossRef]
- Han, G.; He, M.; Zhao, F.; Xu, Z.; Zhang, M.; Qin, L. Insulator detection and damage identification based on improved lightweight YOLOv4 network. Energy Rep. 2021, 7, 187–197. [Google Scholar]
- Zhang, P.; Wang, C.; Jiang, C.; Han, Z. Deep reinforcement learning assisted federated learning algorithm for data management of IIoT. IEEE Trans. Ind. Inform. 2021, 17, 8475–8484. [Google Scholar] [CrossRef]
- Qiu, C.; Aujla, G.S.; Jiang, J.; Wen, W.; Zhang, P. Rendering Secure and Trustworthy Edge Intelligence in 5G-Enabled IIoT using Proof of Learning Consensus Protocol. IEEE Trans. Ind. Inform. 2022, 19, 9789427. [Google Scholar]
- Zhang, P.; Jiang, C.; Pang, X.; Qian, Y. STEC-IoT: A security tactic by virtualizing edge computing on IoT. IEEE Internet Things J. 2020, 8, 2459–2467. [Google Scholar] [CrossRef]
- Li, Q.; Zhao, F.; Xu, Z.; Li, K.; Wang, J.; Liu, H.; Qin, L.; Liu, K. Improved YOLOv4 algorithm for safety management of on-site power system work. Energy Rep. 2022, 8, 739–746. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Items | Parameters |
|---|---|
| GPU | 384-core NVIDIA VoltaTM architecture with 48 Tensor cores |
| CPU | six-core NVIDIA Carmel ARMv8.2 64-bit CPU |
| Memory | 16 GB 128-bit LPDDR4x@1600MHz |
| Data storage | 16GB eMMC5.1 |
| CSI | CSI support for up to six cameras (14 channels) MIPI CSI-2 D-PHY 1.2 |
| PCIE | 1 × 1(PCIE3.0) + 1 × 4(PCIE4.0), 144GT/s |
| Video encoding/ decoding | 2K × 4K60 Hz encoding (HEVC); 2K4K60 Hz decoding |
| Size | 69.6 mm × 45 mm |
| Model | FP32(FPS) | FP16(FPS) | INT8(FPS) |
|---|---|---|---|
| YOLOv5s | 31.56 | 60 | 61.05 |
| YOLOv5x | 3.94 | 12.1 | 12.43 |
| YOLOv7 | 7.46 | 22.42 | 23.65 |
| YOLOv7-tiny | 39.12 | 71.2 | 72.08 |
| YOLOv7x | 4.06 | 12.8 | 13.2 |
| YOLOv7e6 | 6.05 | 18.64 | 19.7 |
| Parameter | Configuration |
|---|---|
| CPU | Intel Core i7-10700F, CPU 2.90 Hz, RAM 32 GB |
| GPU | Nvidia GeForce GTX 2080Ti (24 G) |
| Accelerated Environment | CUDA 11.1, cuDNN8.0.5 |
| Visual Studio System | Pytorch1.7.1, Python 3.6 |
| Operating System | Ubuntu 18.04 |
| Epoch | Batch Size | IoU Threshold | Initial Learning Rate | Momentum | Input Image |
|---|---|---|---|---|---|
| 500 | 8 | 0.2 | 0.01 | 0.937 | 640*640 |
| Class | Labels | YOLOv5s | YOLOv5x | YOLOv7 | YOLOv7-tiny | YOLOv7x | YOLOv7e6 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | P | R | P | R | P | R | P | R | P | R | ||
| no_mask_hat | 728 | 0.867 | 0.852 | 0.858 | 0.878 | 0.855 | 0.856 | 0.828 | 0.852 | 0.86 | 0.854 | 0.853 | 0.832 |
| yes_mask_hat | 1064 | 0.919 | 0.886 | 0.907 | 0.907 | 0.899 | 0.902 | 0.897 | 0.898 | 0.891 | 0.91 | 0.917 | 0.875 |
| no_mask_yes_hat | 346 | 0.772 | 0.775 | 0.779 | 0.795 | 0.753 | 0.803 | 0.738 | 0.783 | 0.771 | 0.775 | 0.751 | 0.876 |
| yes_mask_no_hat | 790 | 0.868 | 0.784 | 0.86 | 0.824 | 0.845 | 0.81 | 0.833 | 0.805 | 0.848 | 0.797 | 0.842 | 0.773 |
| Model | P | R | mAP@.5 | mAP@.5:.95 | F1 | Speed in Jetson (ms) |
|---|---|---|---|---|---|---|
| YOLOv5s | 0.857 | 0.824 | 0.862 | 0.618 | 0.840 | 315 |
| YOLOv5x | 0.851 | 0.851 | 0.856 | 0.618 | 0.851 | 2694 |
| YOLOv7 | 0.855 | 0.856 | 0.891 | 0.629 | 0.855 | 1570 |
| YOLOv7-tiny | 0.824 | 0.835 | 0.879 | 0.613 | 0.830 | 212 |
| YOLOv7x | 0.842 | 0.834 | 0.886 | 0.632 | 0.838 | 2467 |
| YOLOv7e6 | 0.841 | 0.817 | 0.873 | 0.623 | 0.829 | 2063 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Z.; Zhou, C.; Pan, A.; Zhang, F.; Dong, C.; Liu, X.; Zhai, X.; Wang, H. A Kitchen Standard Dress Detection Method Based on the YOLOv5s Embedded Model. Appl. Sci. 2023, 13, 2213. https://doi.org/10.3390/app13042213
Zhou Z, Zhou C, Pan A, Zhang F, Dong C, Liu X, Zhai X, Wang H. A Kitchen Standard Dress Detection Method Based on the YOLOv5s Embedded Model. Applied Sciences. 2023; 13(4):2213. https://doi.org/10.3390/app13042213
Chicago/Turabian StyleZhou, Ziyun, Chengjiang Zhou, Anning Pan, Fuqing Zhang, Chaoqun Dong, Xuedong Liu, Xiangshuai Zhai, and Haitao Wang. 2023. "A Kitchen Standard Dress Detection Method Based on the YOLOv5s Embedded Model" Applied Sciences 13, no. 4: 2213. https://doi.org/10.3390/app13042213
APA StyleZhou, Z., Zhou, C., Pan, A., Zhang, F., Dong, C., Liu, X., Zhai, X., & Wang, H. (2023). A Kitchen Standard Dress Detection Method Based on the YOLOv5s Embedded Model. Applied Sciences, 13(4), 2213. https://doi.org/10.3390/app13042213