
Automatic Ship Object Detection Model Based on YOLOv4 with Transformer Mechanism in Remote Sensing Images




Abstract
:1. Introduction
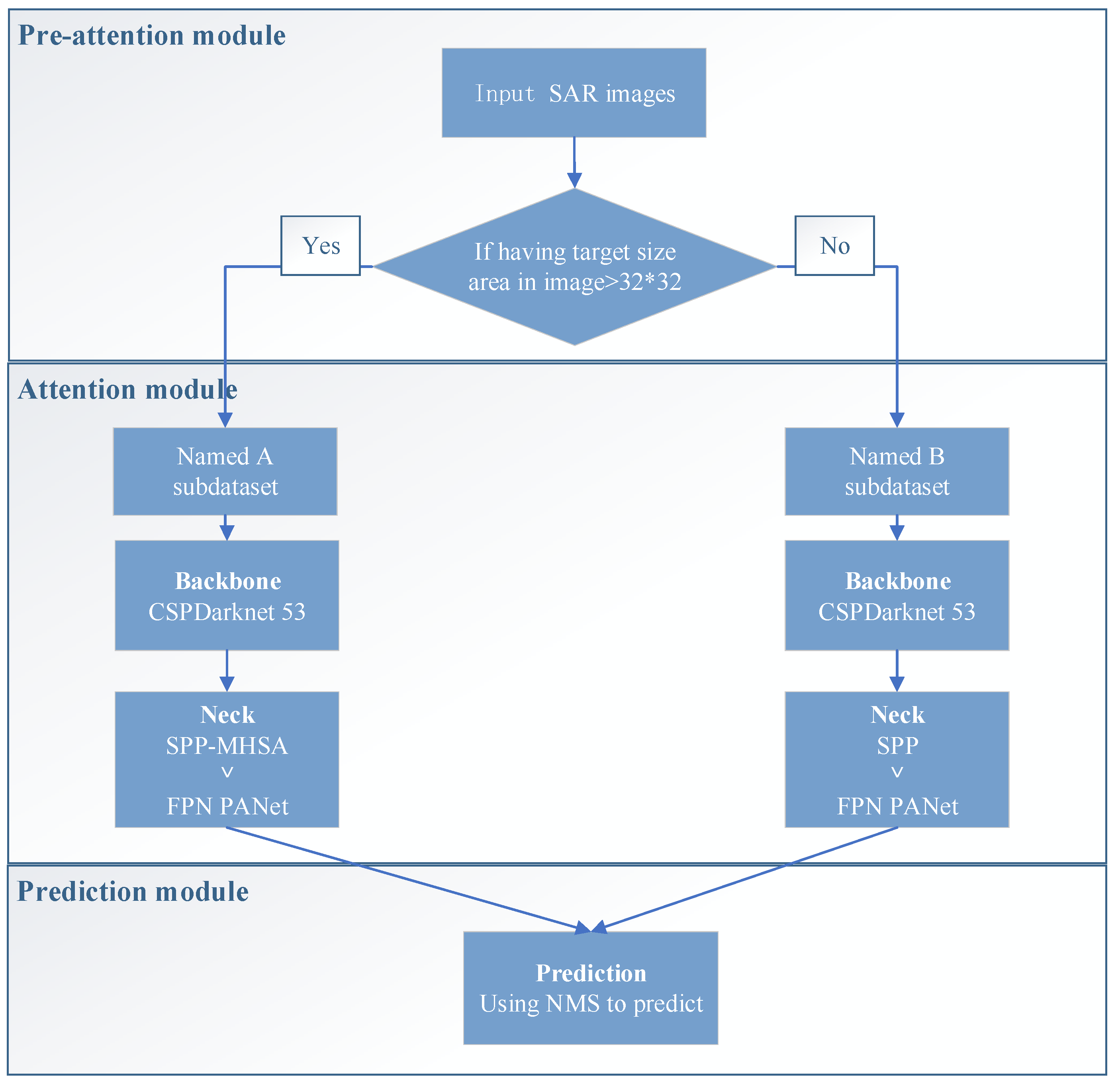
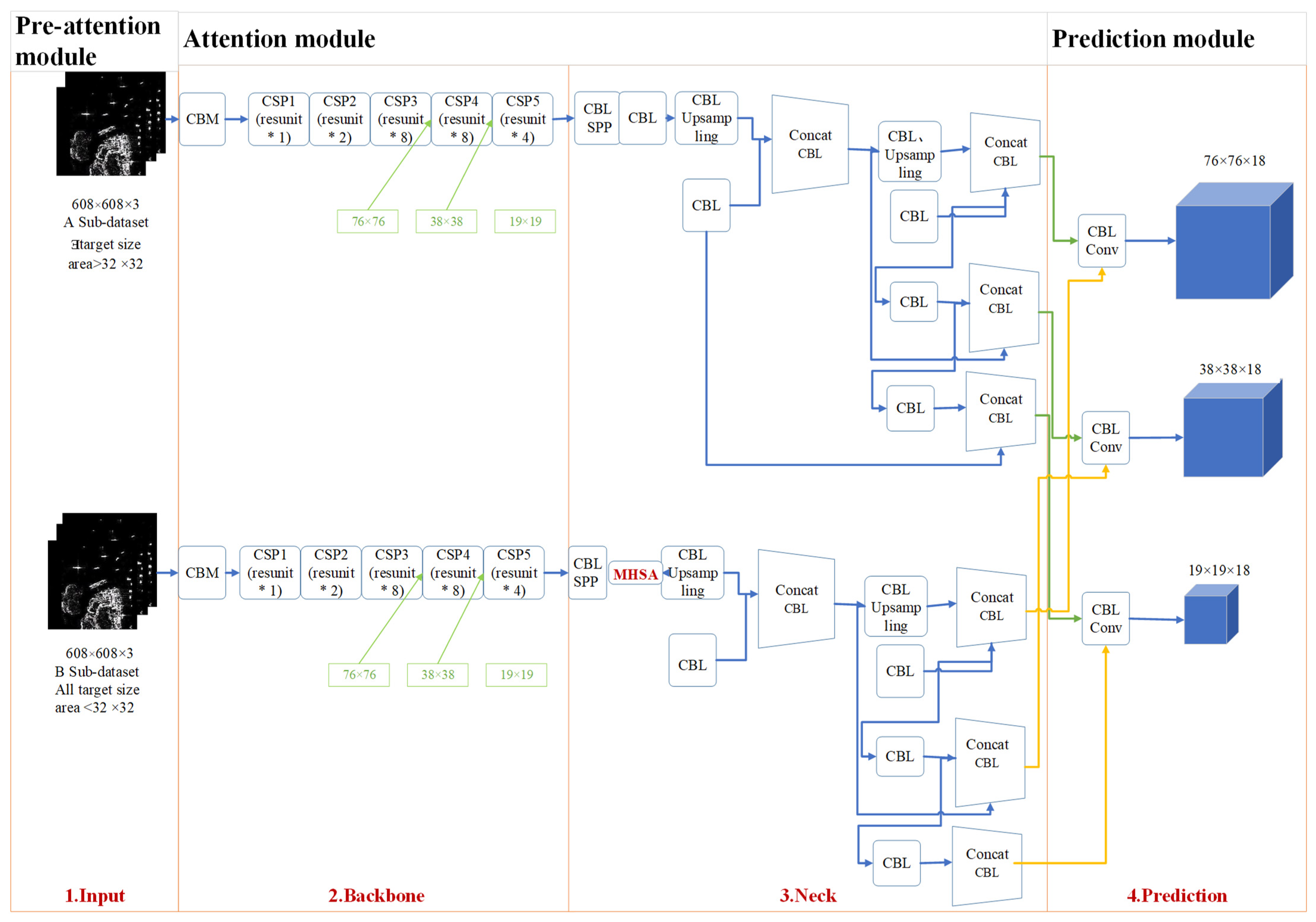
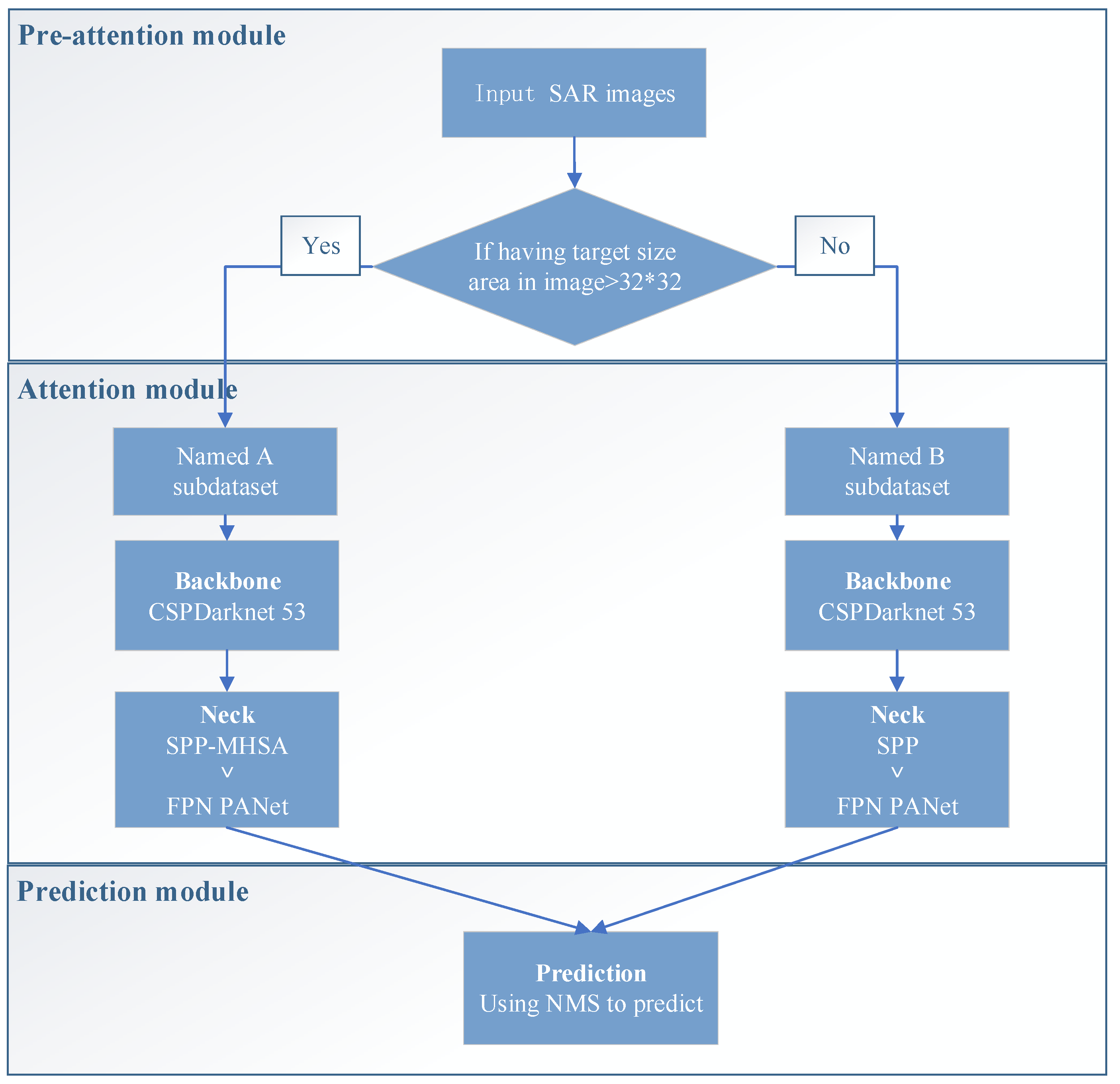
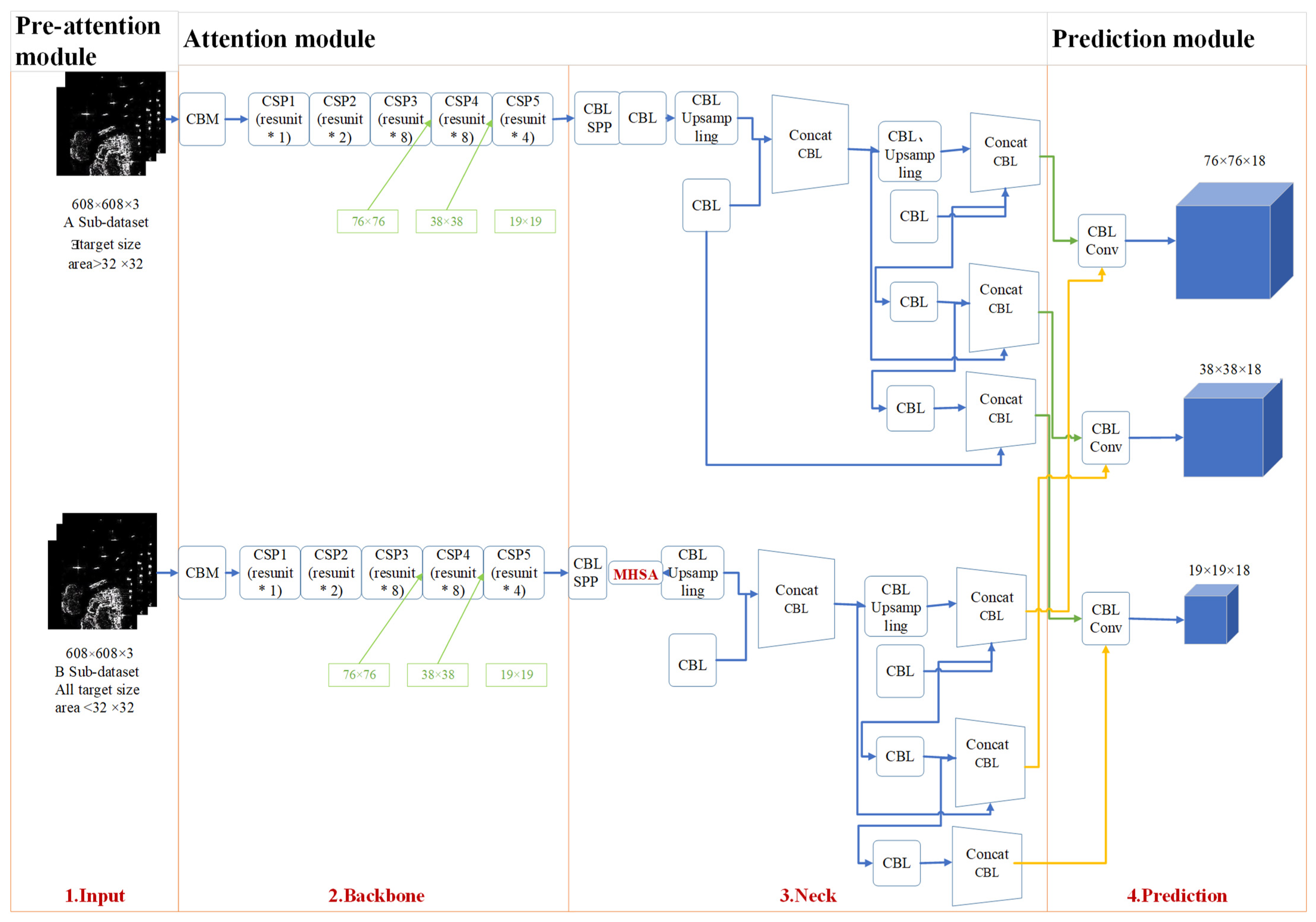
- Auto-T-YOLO is divided into preattention, attention, and prediction stages. The preattention module is introduced into the object detection network. The preattention module automatically classifies the dataset according to the target size. The operation of this module is used to simulate the process of human vision. In the attention module, the image features are selectively focused autonomously and efficiently. Finally, the prediction module performs the prediction frame accuracy evaluation mathematically.
- During the preattention stage, Auto-T-YOLO automatically classifies the images in the dataset according to the target size. The definition of target size is learned from the Microsoft Common Objects in Context (MS-COCO) dataset. Two types of images in the dataset are classified: the type with large-size targets and the second type with only small-size targets. In the experimental section, we analyze the definition of the large-size target setting.
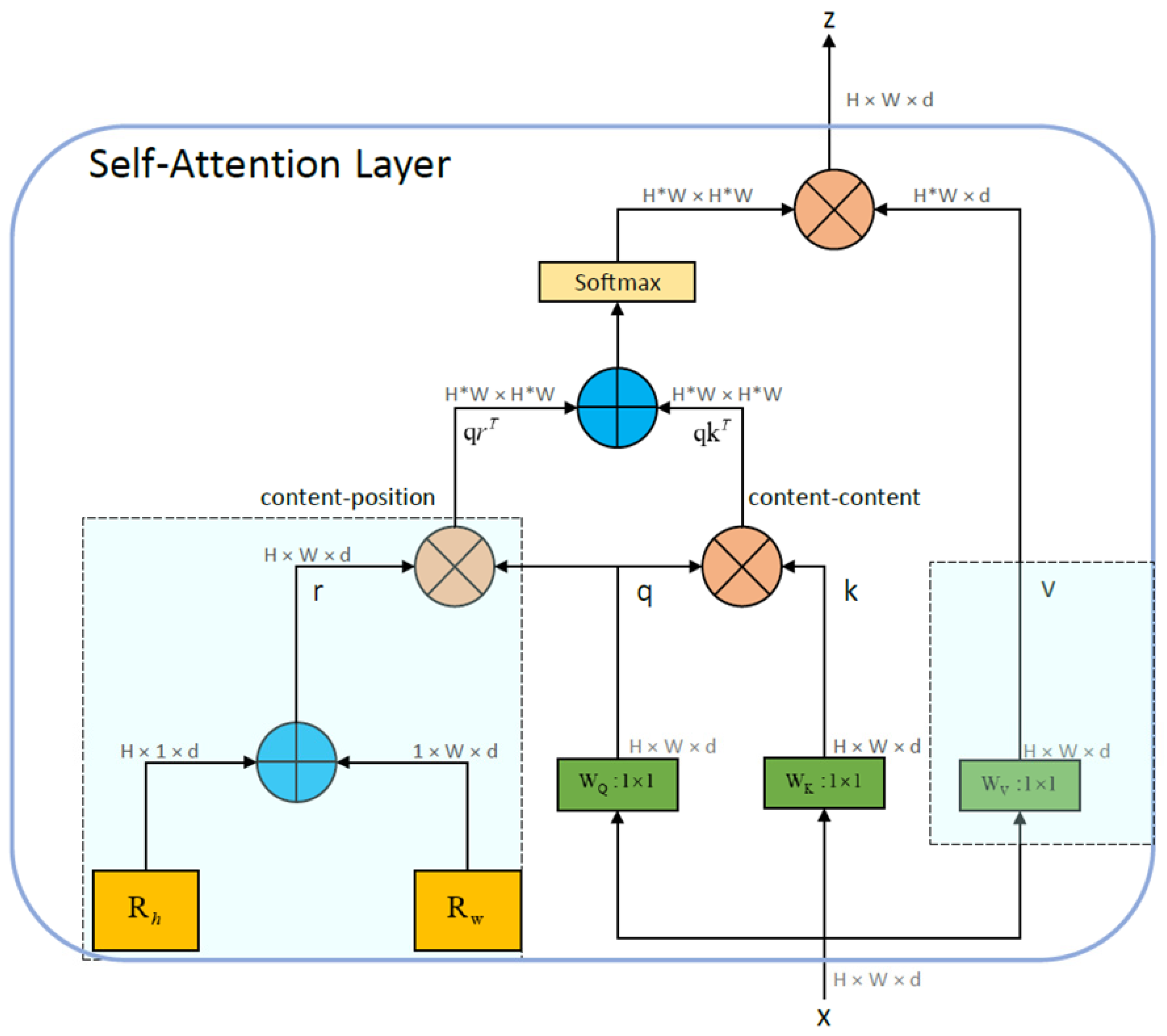
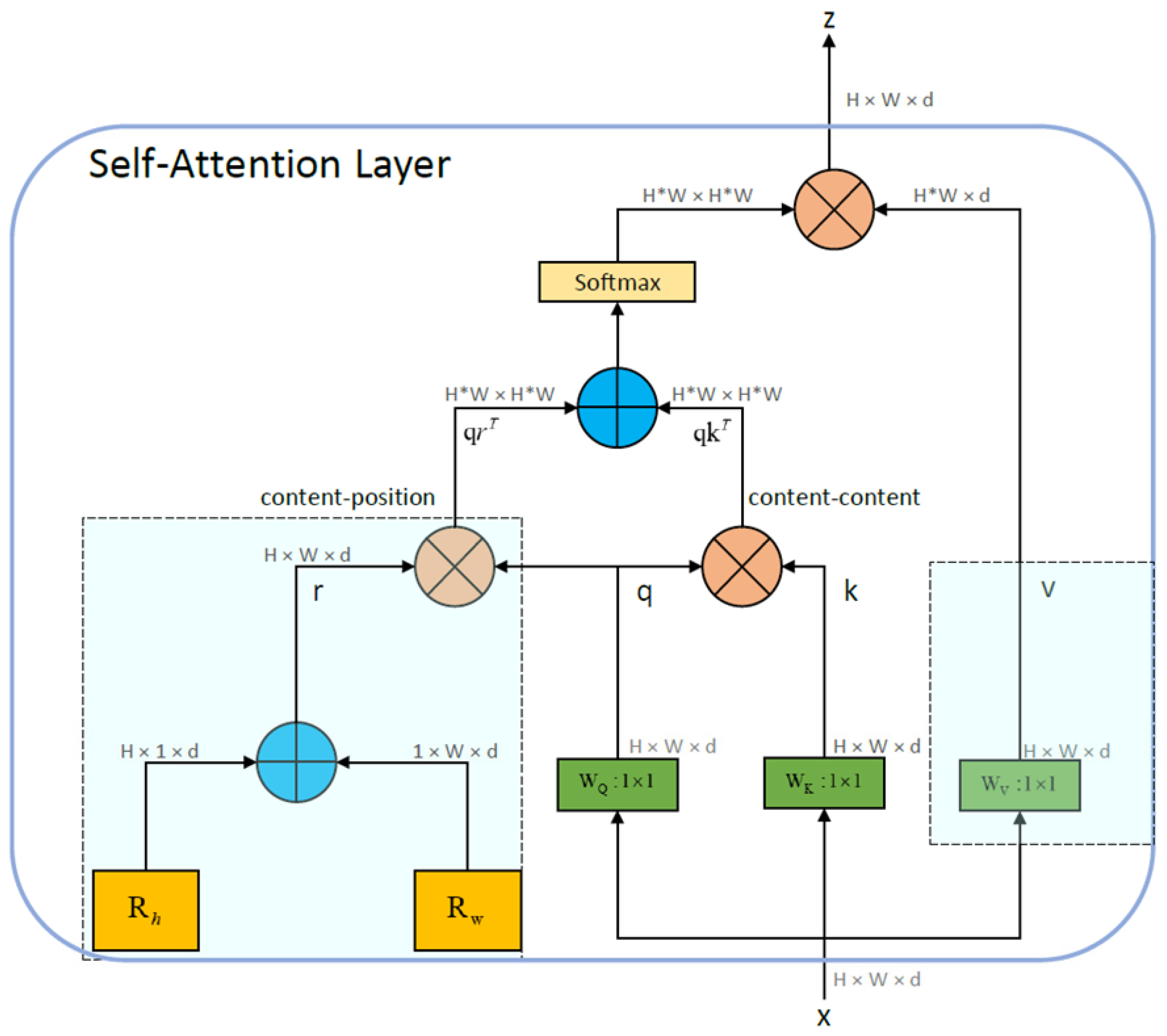
- In the attention stage, the MHSA module is introduced into the YOLOv4 network framework by replacing the 3 × 3 convolution block with the MHSA module after the SPP module.
- To analyze the performance of Auto-T-YOLO, two types of accuracy evaluation measures are employed. First, (fault detection rate), (missing alarm rate), and (false alarm rate) are evaluation indices in remote sensing. For deep learning object detection, the evaluation indexes are , , F1-score (), mean Average Precision (), and Frames Per Second (). The SSDD was divided into two subdatasets: inshore and offshore scenarios. Not only is the whole SSDD detected, but also Auto-T-YOLO detects the two subdatasets mentioned above.
2. Related Work
2.1. Methods of Constant False Alarm Rate (CFAR)
2.2. Deep Neural Network
2.3. Attention Mechanism
3. Materials and Methods
3.1. Preattention Module
3.2. Attention Module
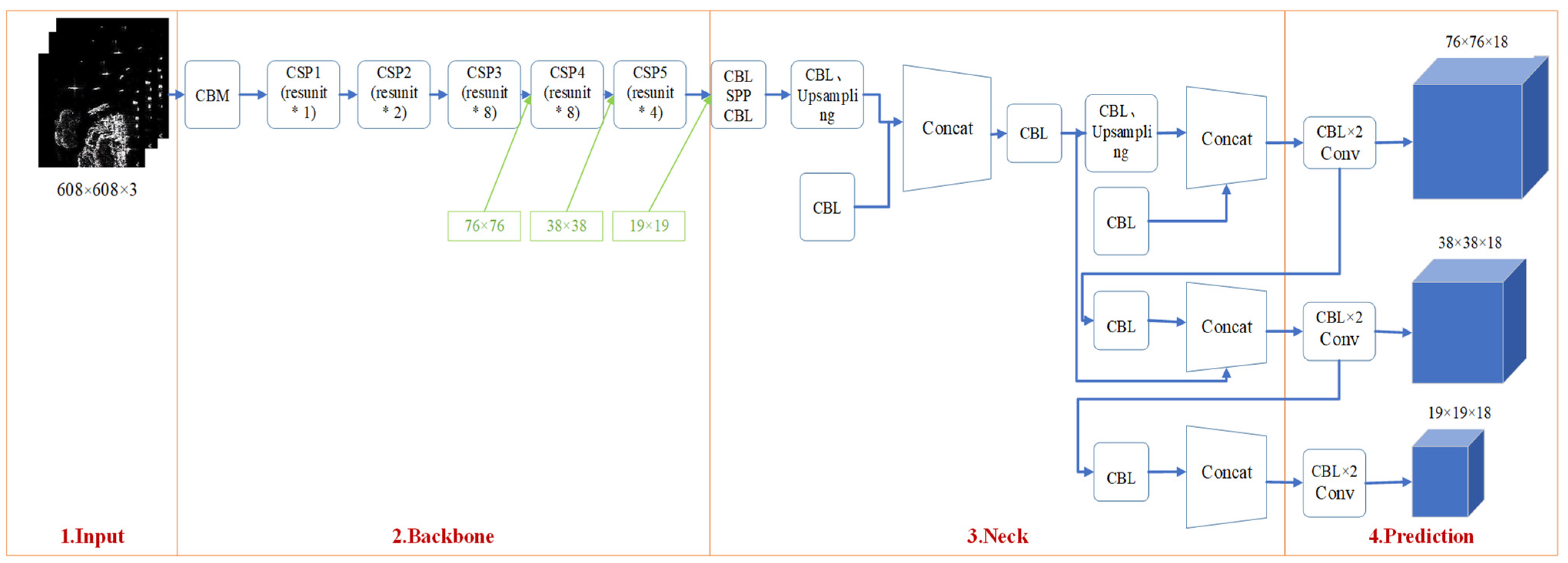
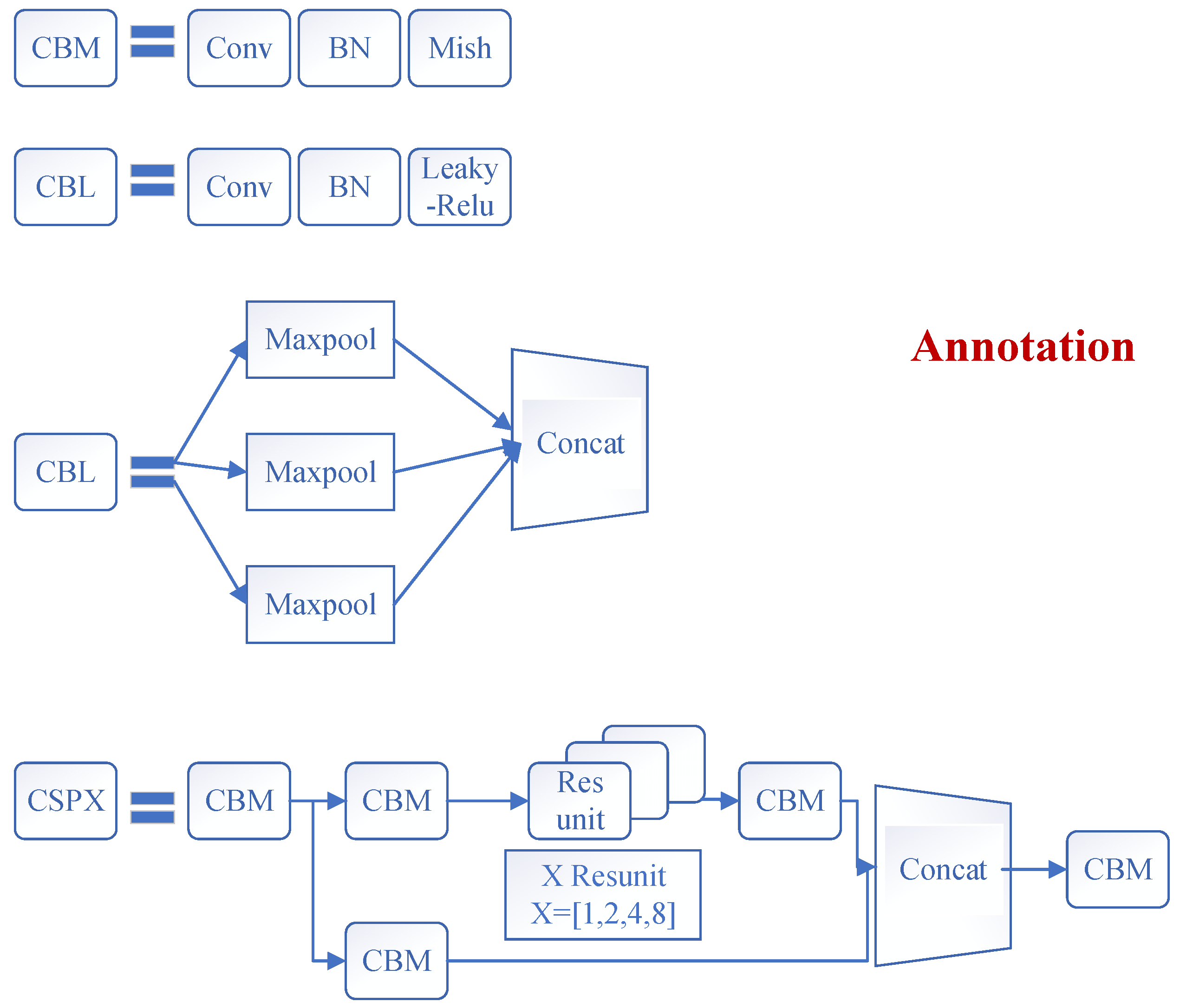
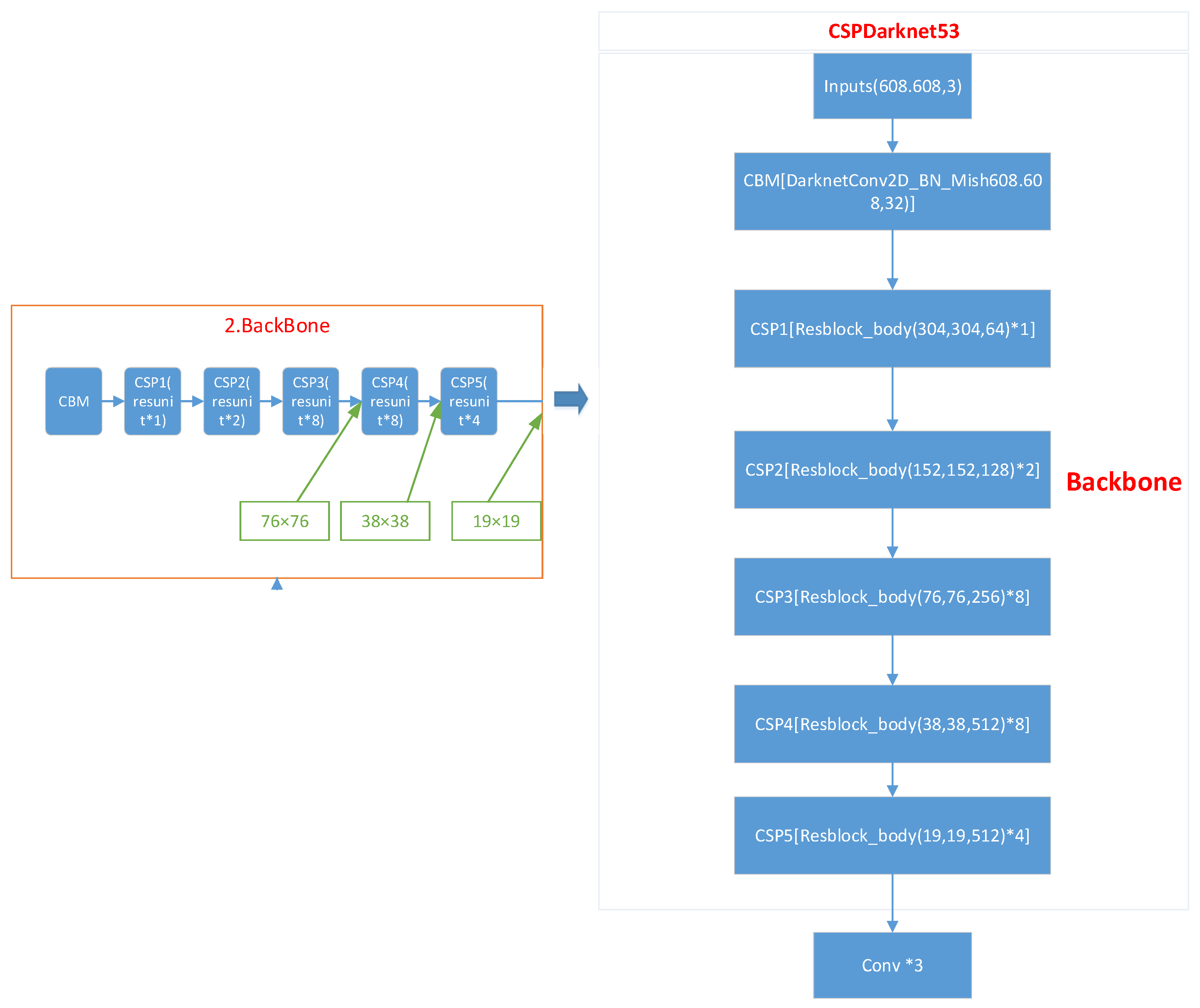
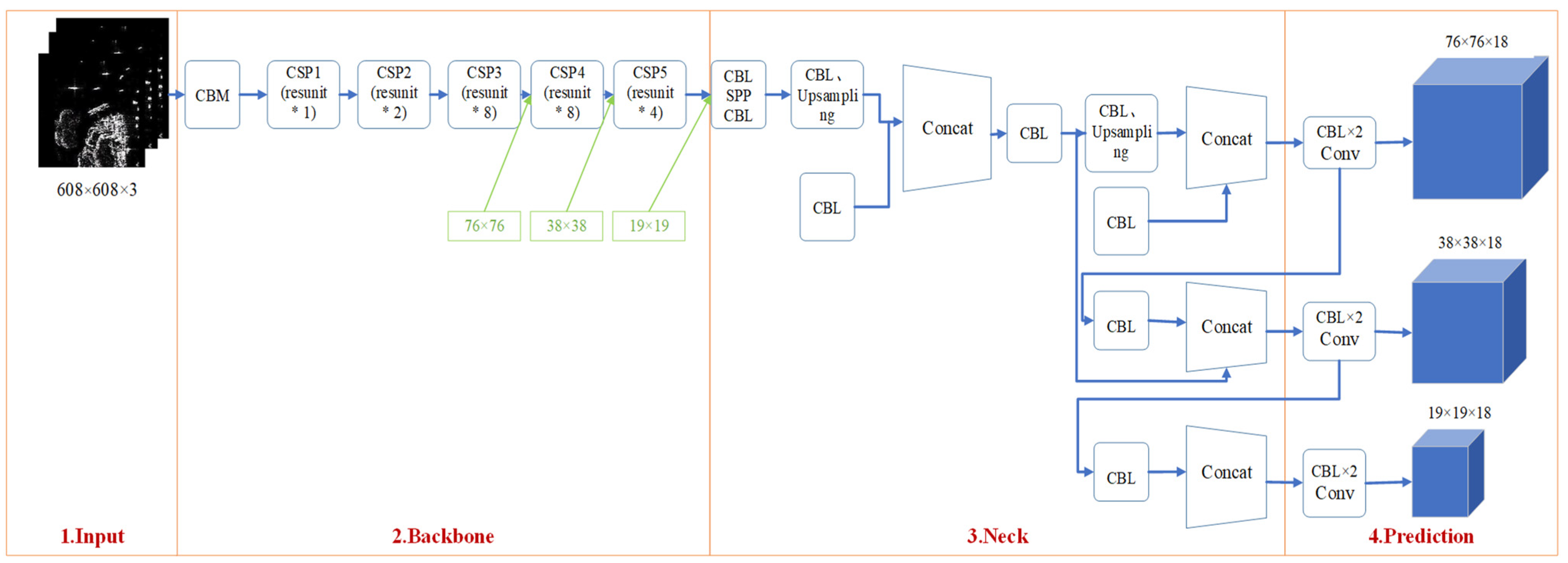
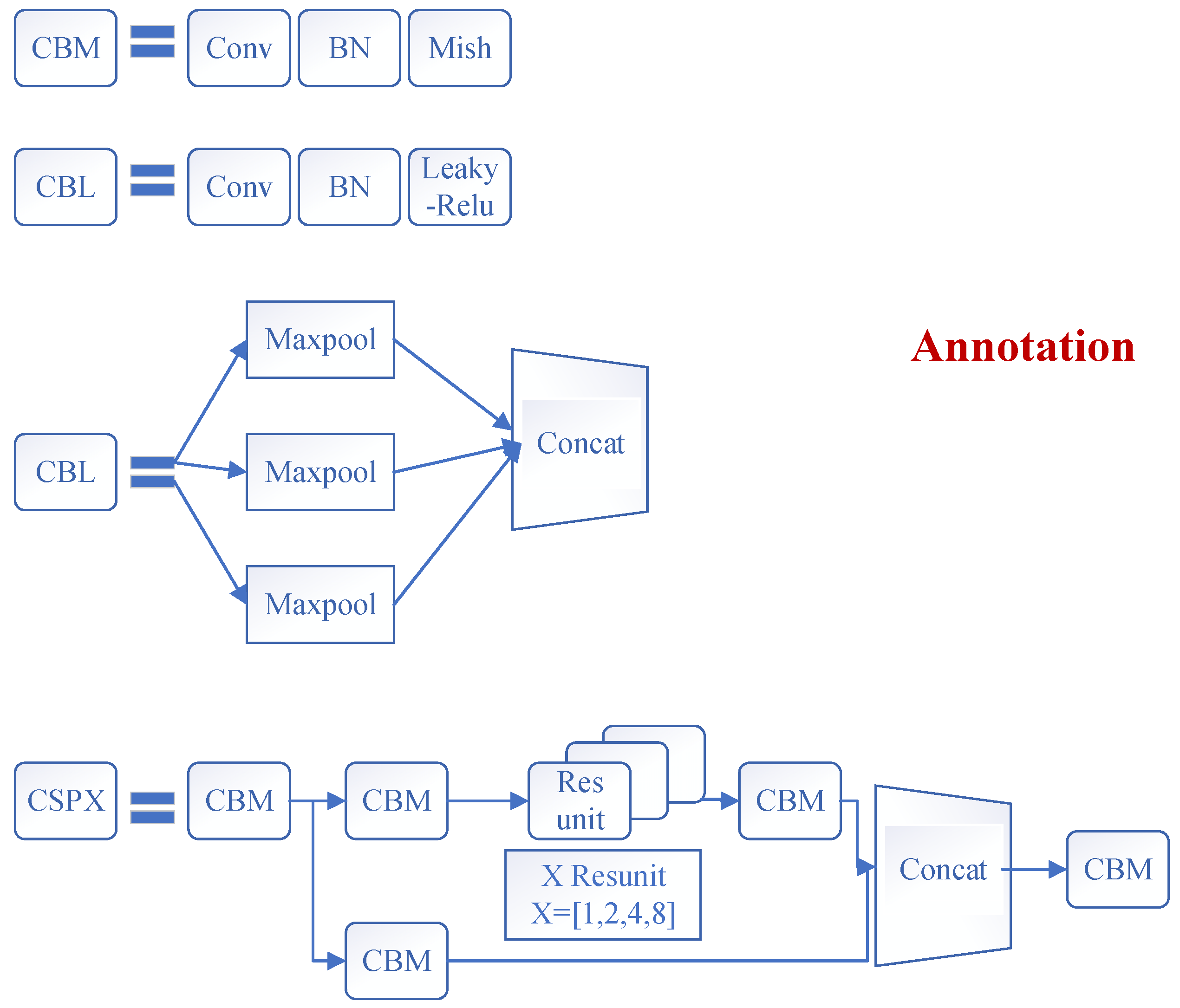
3.2.1. Backbone: Feature Extraction Network (CSPDarknet53)
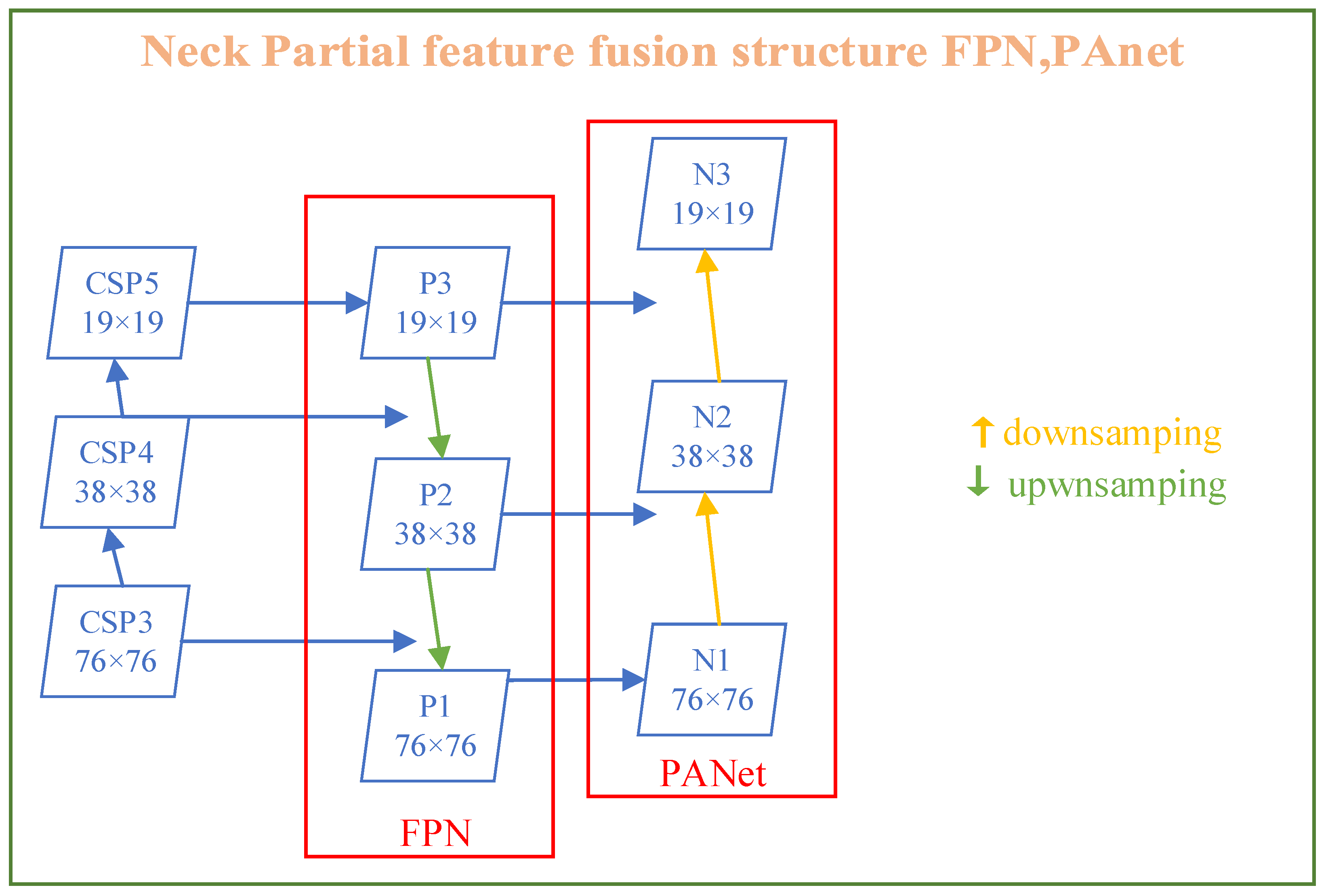
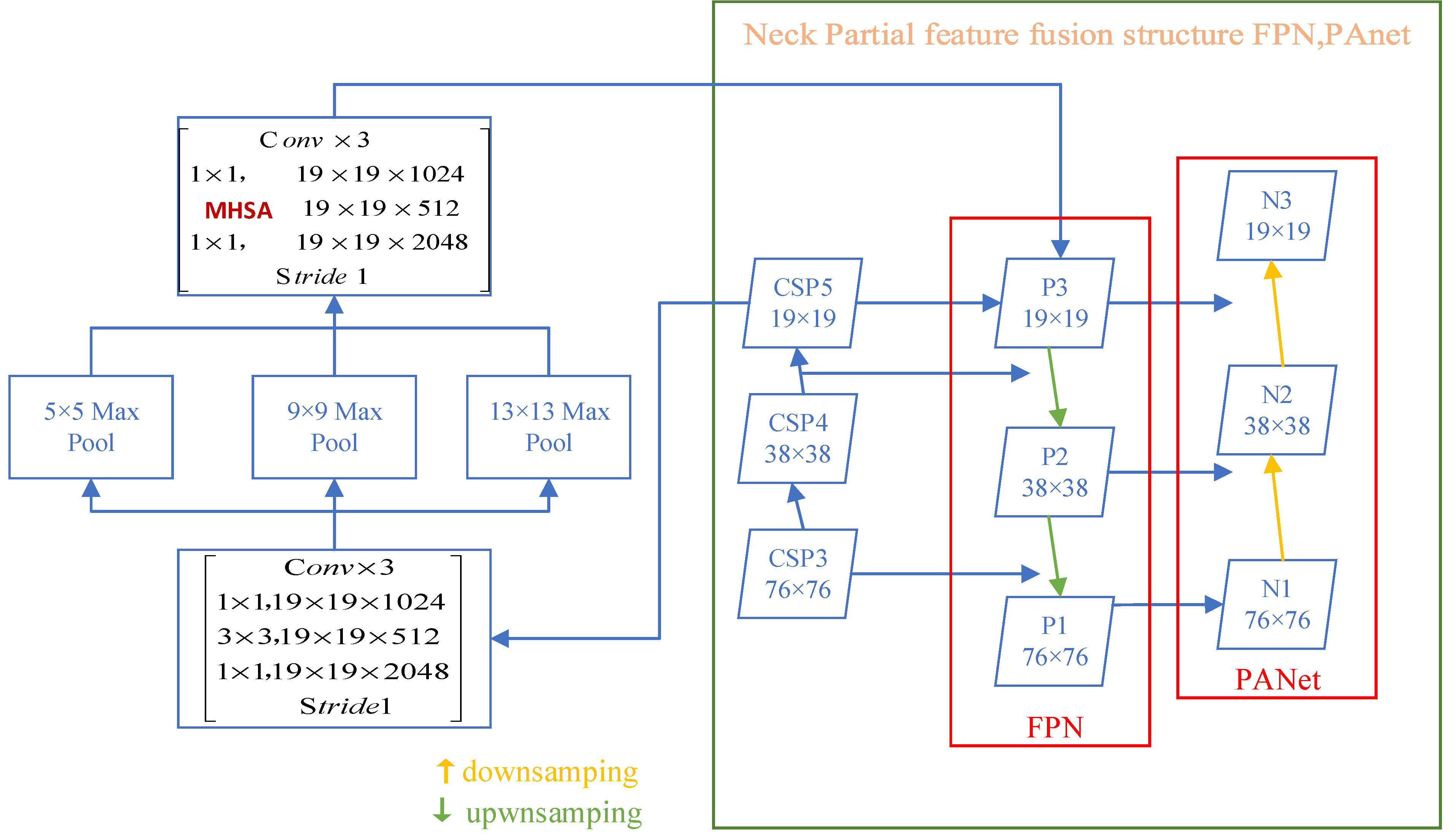
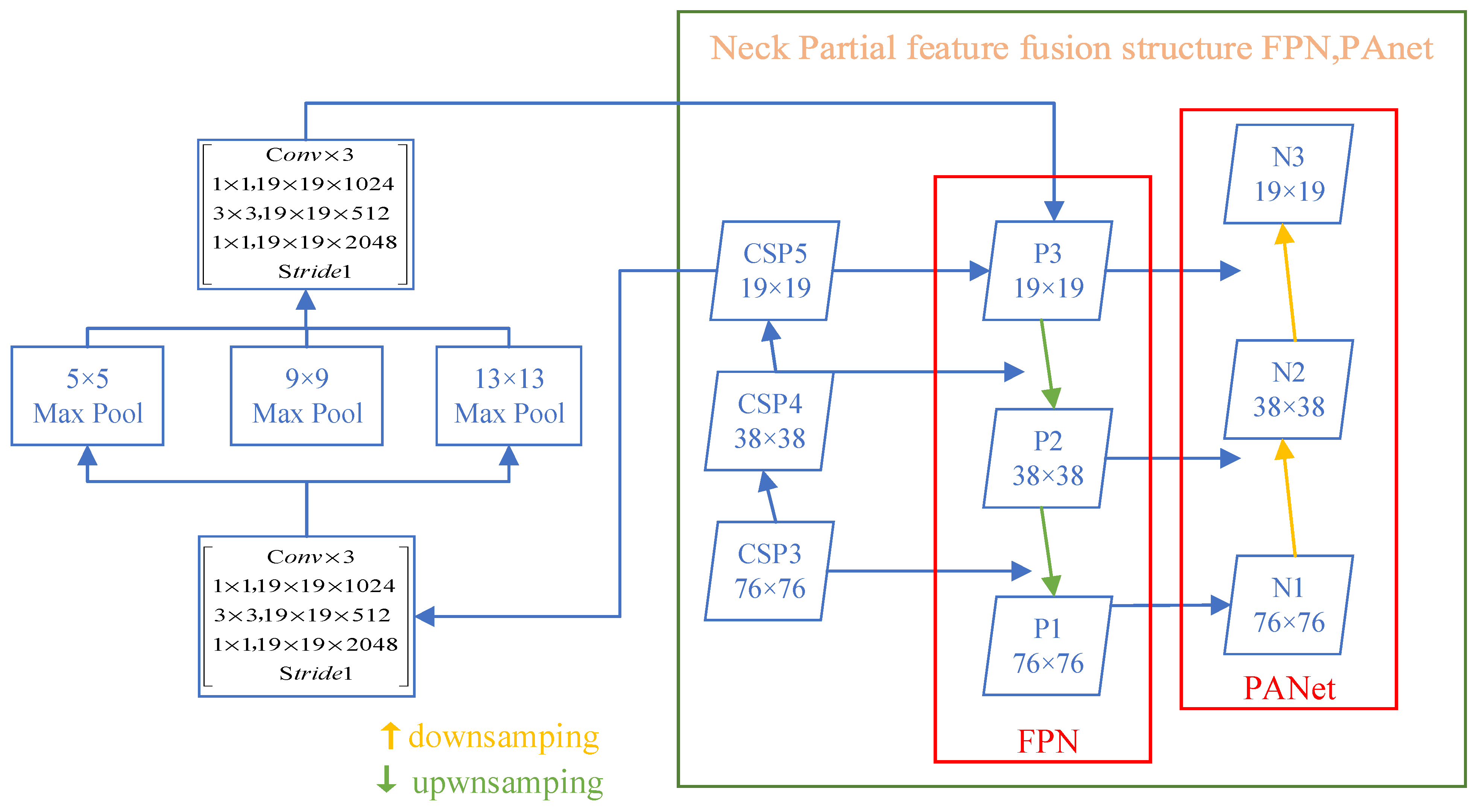
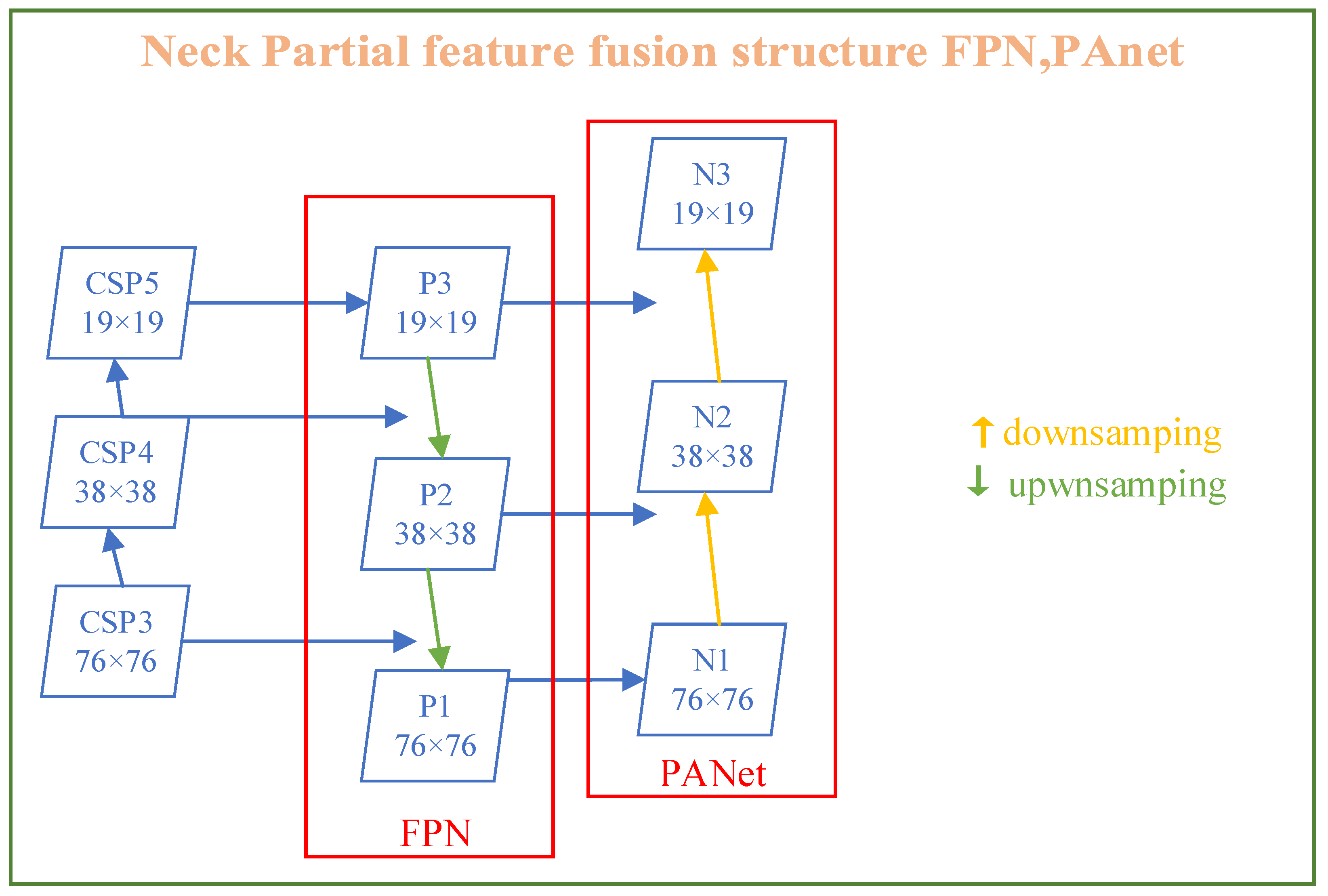
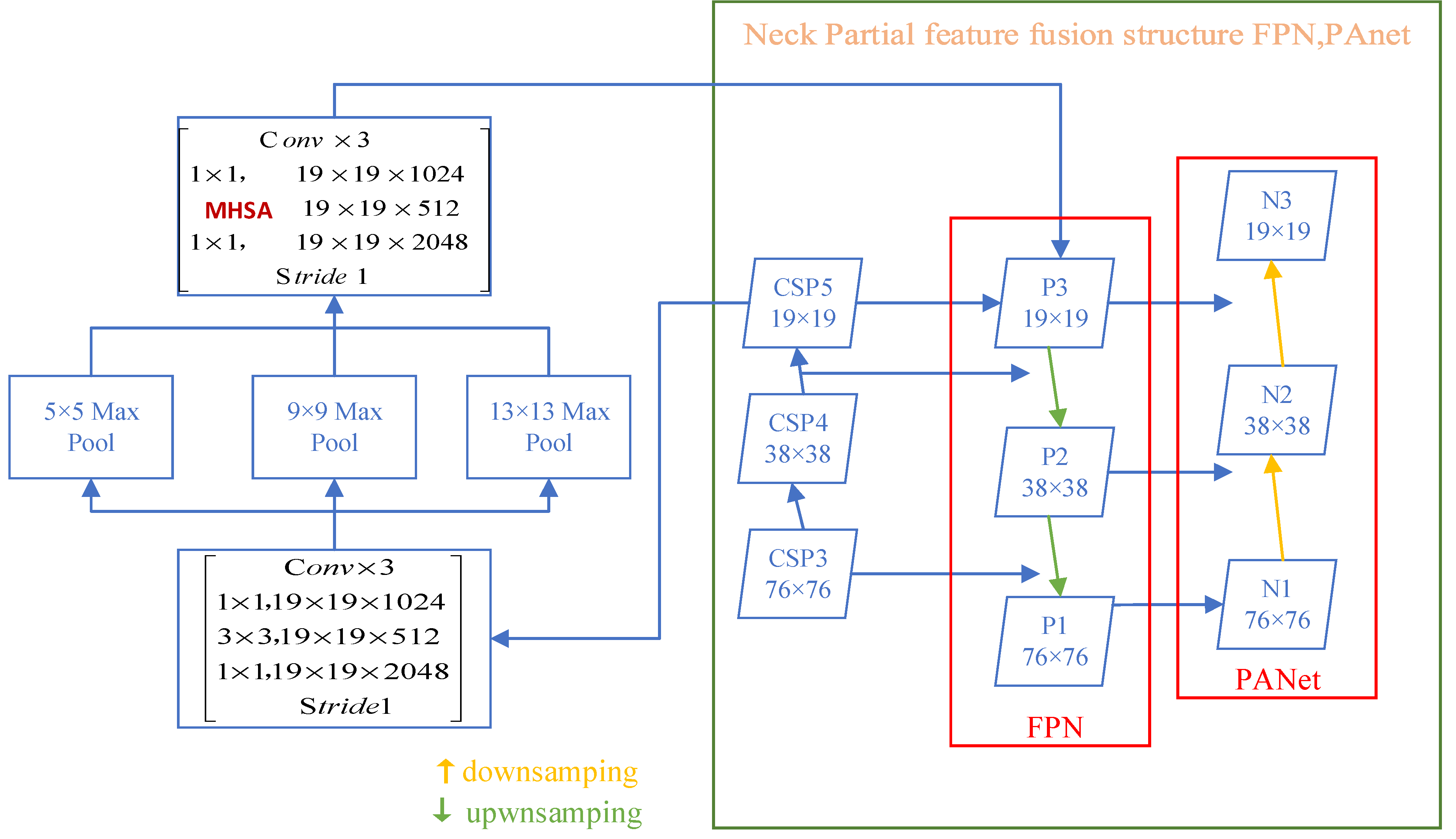
3.2.2. Neck: SPP-MHSA, FPN, and PANet
3.3. Prediction Module
3.3.1. CIoU Loss Function
3.3.2. DIoU-NMS
4. Experiments and Results
4.1. SSDD
4.2. Settings
4.3. Standard of Evaluation
4.3.1. Target Size Threshold Setting
4.3.2. Impact of the Preattention Module on SSDD including Offshore and Inshore Scenes
4.3.3. Figures of the Results of Some Ablation Experiments
4.4. Comparison with SOTA Models
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Brusch, S.; Lehner, S.; Fritz, T.; Soccorsi, M.; Soloviev, A.; van Schie, B. Ship surveillance with TerraSAR-X. IEEE Trans. Geosci. Remote Sens. 2010, 49, 1092–1103. [Google Scholar] [CrossRef]
- Crisp, D.J. A ship detection system for RADARSAT-2 dual-pol multi-look imagery implemented in the ADSS. In Proceedings of the 2013 International Conference on Radar, Adelaide, Australia, 9–12 September 2013; pp. 318–323. [Google Scholar]
- Torres, R.; Snoeij, P.; Geudtner, D.; Bibby, D.; Davidson, M.; Attema, E.; Rostan, F. GMES Sentinel-1 mission. Remote Sens. Environ. 2012, 120, 9–24. [Google Scholar] [CrossRef]
- Zhu, C.; Zhou, H.; Wang, R.; Guo, J. A novel hierarchical method of ship detection from spaceborne optical image based on shape and texture features. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3446–3456. [Google Scholar] [CrossRef]
- Liu, Z.; Gu, X.; Chen, J.; Wang, D.; Chen, Y.; Wang, L. Automatic recognition of pavement cracks from combined GPR B-scan and C-scan images using multiscale feature fusion deep neural networks. Autom. Constr. 2023, 146, 104698. [Google Scholar] [CrossRef]
- Wang, S.; Gao, S.; Zhou, L.; Liu, R.; Zhang, H.; Liu, J.; Qian, J. YOLO-SD: Small Ship Detection in SAR Images by Multi-Scale Convolution and Feature Transformer Module. Remote Sens. 2022, 14, 5268. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Zhang, L.; Lin, W. Selective Visual Attention: Computational Models and Applications; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Liu, Z.; Yeoh, J.K.W.; Gu, X.; Dong, Q.; Chen, Y.; Wu, W.; Wang, D. Automatic pixel-level detection of vertical cracks in asphalt pavement based on GPR investigation and improved mask R-CNN. Autom. Constr. 2023, 146, 104689. [Google Scholar] [CrossRef]
- Navon, D. Forest before trees: The precedence of global features in visual perception. Cognit. Psychol. 1977, 9, 353–383. [Google Scholar] [CrossRef]
- Henschel, M.D.; Rey, M.T.; Campbell, J.W.M.; Petrovic, D. Comparison of probability statistics for automated ship detection in SAR imagery. In Proceedings of the 1998 International Conference on Applications of Photonic Technology III: Closing the Gap between Theory, Development, and Applications, Ottawa, ON, Canada, 4 December 1998; pp. 986–991. [Google Scholar]
- Stagliano, D.; Lupidi, A.; Berizzi, F. Ship detection from SAR images based on CFAR and wavelet transform. In Proceedings of the 2012 Tyrrhenian Workshop on Advances in Radar and Remote Sensing (TyWRRS), Naples, Italy, 12–14 September 2012; pp. 53–58. [Google Scholar]
- Wang, R.; Huang, Y.; Zhang, Y.; Pei, J.; Wu, J.; Yang, J. An inshore ship detection method in SAR images based on contextual fluctuation information. In Proceedings of the 2019 6th Asia-Pacific Conference on Synthetic Aperture Radar (APSAR), Xiamen, China, 26–29 November 2019; p. 19493178. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. Int. Conf. Mach. Learn. 2015, 37, 448–456. [Google Scholar]
- Pinheiro, P.O.; Collobert, R. Weakly supervised semantic segmentation with convolutional networks. In CVPR; Citeseer: University Park, PA, USA, 2015; Volume 2, p. 6. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Tan, M.; Le, Q. Efficient net: Rethinking model scaling for convolutional neural networks. Int. Conf. Mach. Learn. 2019, 97, 6105–6114. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016, 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Chen, C.; Liu, M.Y.; Tuzel, O.; Xiao, J. R-CNN for small object detection. In Proceedings of the Computer Vision - ACCV 2016—13th Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Springer: Cham, Switzerland, 2017; pp. 214–230. [Google Scholar]
- Li, J.; Qu, C.; Shao, J. Ship detection in SAR images is based on an improved faster R-CNN. In Proceedings of the 2017 SAR in Big Data Era: Models, Methods and Applications (BIGSARDATA), Beijing, China, 13–14 November 2017; pp. 1–6. [Google Scholar]
- Wang, Y.; Wang, C.; Zhang, H.; Zhang, C.; Fu, Q. Combing Single Shot Multibox Detector with transfer learning for ship detection using Chinese Gaofen-3 images. In Proceedings of the 2017 Progress in Electromagnetics Research Symposium-Fall (PIERS-FALL), Singapore, 19–22 November 2017; pp. 712–716. [Google Scholar]
- Lin, Z.; Ji, K.; Leng, X.; Kuang, G. Squeeze and excitation rank faster R-CNN for ship detection in SAR images. IEEE Geosci. Remote Sens. Lett. 2018, 16, 751–755. [Google Scholar] [CrossRef]
- Mao, Y.; Yang, Y.; Ma, Z.; Li, M.; Su, H.; Zhang, J. Efficient, low-cost ship detection for SAR imagery based on simplified U-net. IEEE Access. 2020, 8, 69742–69753. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Shi, J.; Wei, S. HyperLi-Net: A hyper-light deep learning network for high-accurate and high-speed ship detection from synthetic aperture radar imagery. ISPRS J. Photogramm. Remote Sens. 2020, 167, 123–153. [Google Scholar] [CrossRef]
- Gong, H.; Mu, T.; Li, Q.; Dai, H.; Li, C.; He, Z.; Wang, B. Swin-Transformer-Enabled YOLOv5 with Attention Mechanism for Small Object Detection on Satellite Images. Remote Sens. 2022, 14, 2861. [Google Scholar] [CrossRef]
- Wang, D.; Liu, Z.; Gu, X.; Wu, W.; Chen, Y.; Wang, L. Automatic detection of pothole distress in asphalt pavement using improved convolutional neural networks. Remote Sens. 2022, 14, 3892. [Google Scholar] [CrossRef]
- Gallo, I.; Rehman, A.U.; Dehkordi, R.H.; Landro, N.; La Grassa, R.; Boschetti, M. Deep Object Detection of Crop Weeds: Performance of YOLOv7 on a Real Case Dataset from UAV Images. Remote Sens. 2023, 15, 539. [Google Scholar] [CrossRef]
- Huang, Z.; Li, Y.; Zhao, T.; Ying, P.; Fan, Y.; Li, J. Infusion port level detection for intravenous infusion based on Yolo v3 neural network. Math. Biosci. Eng. 2021, 18, 3491–3501. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Srinivas, A.; Lin, T.Y.; Parmar, N.; Shlens, J.; Abbeel, P.; Vaswani, A. Bottleneck transformers for visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16519–16529. [Google Scholar]
- Bichot, N.P. Neural mechanisms of top-down selection during visual search. In Proceedings of the 23rd Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Istanbul, Turkey, 25–28 October 2001; pp. 780–783. [Google Scholar]
- Peterson, M.S.; Kramer, A.F.; Wang, R.F.; Irwin, D.E.; McCarley, J.S. Visual search has memory. Psychol. Sci. 2001, 12, 287–292. [Google Scholar] [CrossRef] [PubMed]
- Shaw, P.; Uszkoreit, J.; Vaswani, A. Self-attention with relative position representations. arXiv 2018, arXiv:1803.02155. [Google Scholar]
- Bello, I.; Zoph, B.; Vaswani, A.; Shlens, J.; Le, Q.V. Attention augmented convolutional networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3286–3295. [Google Scholar]
- Zhao, H.; Jia, J.; Koltun, V. Exploring self-attention for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10076–10085. [Google Scholar]
- Ramachandran, P.; Parmar, N.; Vaswani, A.; Bello, I.; Levskaya, A.; Shlens, J. Stand-alone self-attention in vision models. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; p. 32. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Xie, C.; Wu, Y.; Maaten, L.V.D.; Yuille, A.L.; He, K. Feature denoising for improving adversarial robustness. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 501–509. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- Kang, M.; Ji, K.; Leng, X.; Lin, Z. Contextual region-based convolutional neural network with multilayer fusion for SAR ship detection. Remote Sens. 2017, 9, 860. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| small objects | area < 32 × 32 | ||
| medium objects | 32 | × | 32 < area < 64 × 64 |
| large objects | area > 64 × 64 |
| Name | Number of Areas >64 × 64 | Number of All Area >32 × 32 | Number of All Area <32 × 32 | Total |
|---|---|---|---|---|
| Inshore | 82 | 150 | 64 | 213 |
| Offshore | 206 | 647 | 300 | 947 |
| Total | 288 | 797 | 363 | 1160 |
| Sensors | Polarization | Scale | Resolution | Position |
|---|---|---|---|---|
| RadarSat-2 TerraSAR-X Sentinel-1 | HH, VV, VH, HV | 1:1 1:2 2:1 | 1 m-15 m | In the sea and offshore |
| Method | |||||||
|---|---|---|---|---|---|---|---|
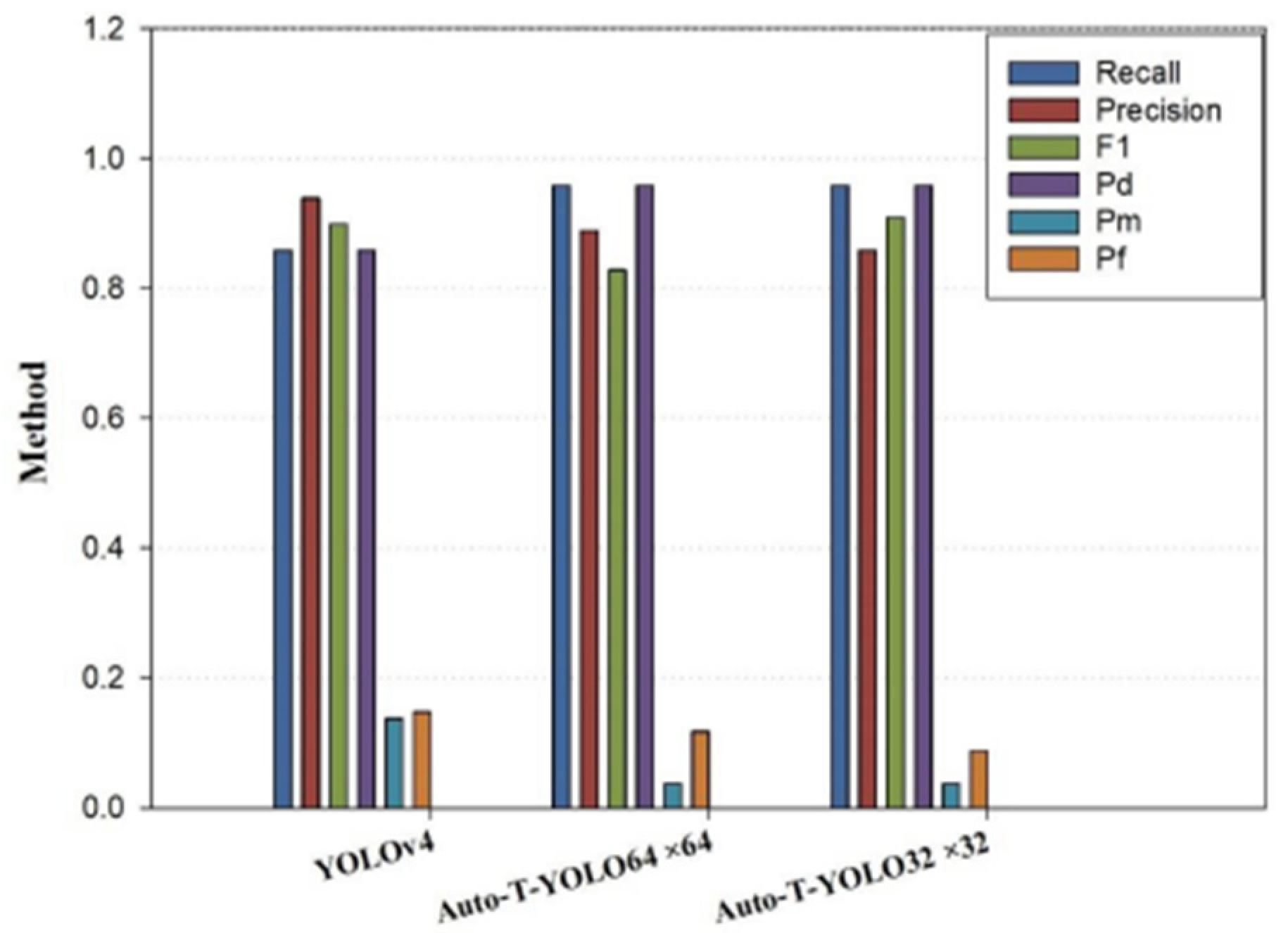
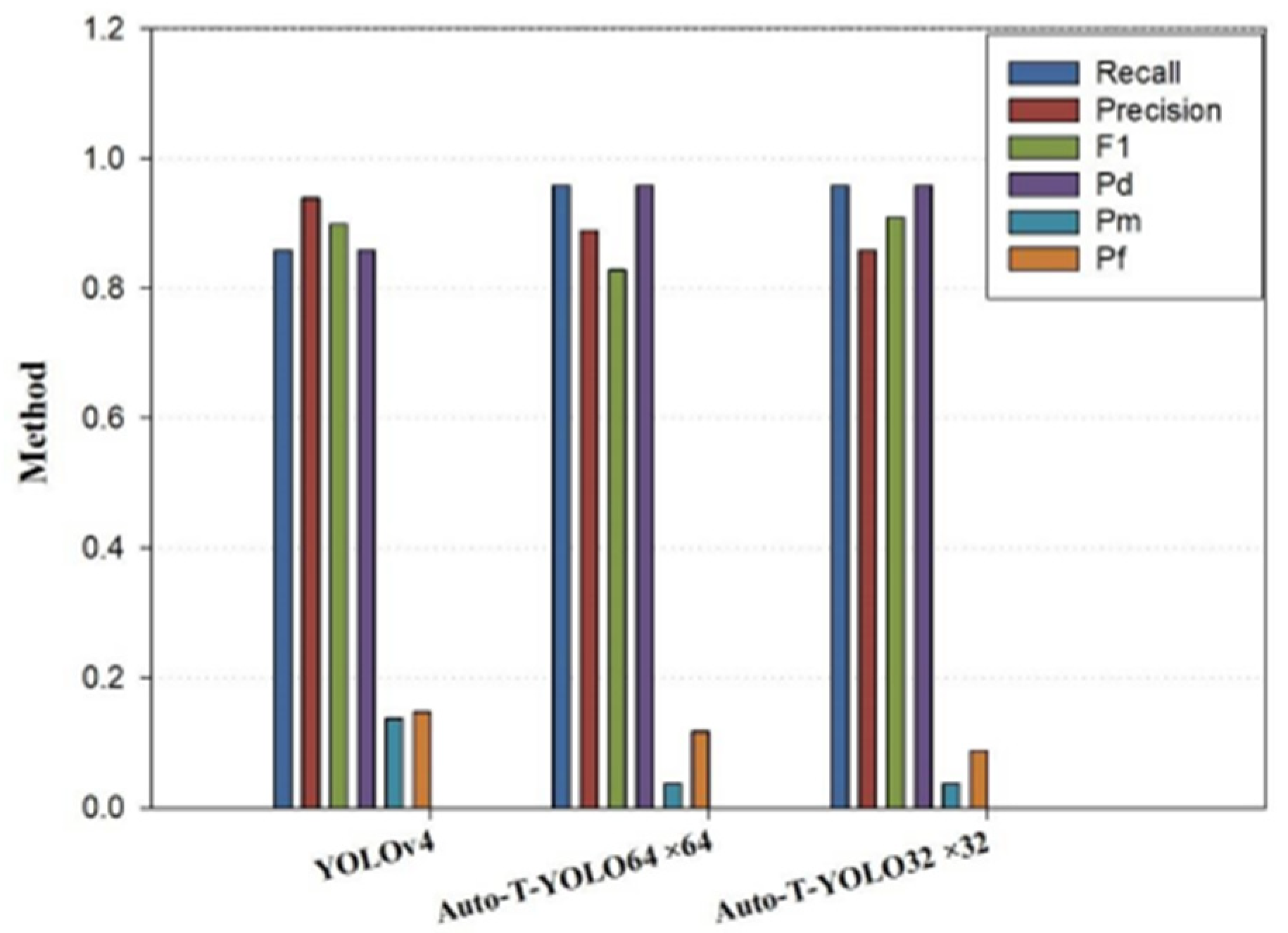
| YOLOv4 | 90.15% | 0.86 | 0.94 | 0.90 | 0.86 | 0.14 | 0.15 |
| 92.48% | 0.92 | 0.89 | 0.90 | 0.92 | 0.08 | 0.07 | |
| 96.3% | 0.96 | 0.86 | 0.91 | 0.96 | 0.04 | 0.09 |
| Method | |||||||
|---|---|---|---|---|---|---|---|
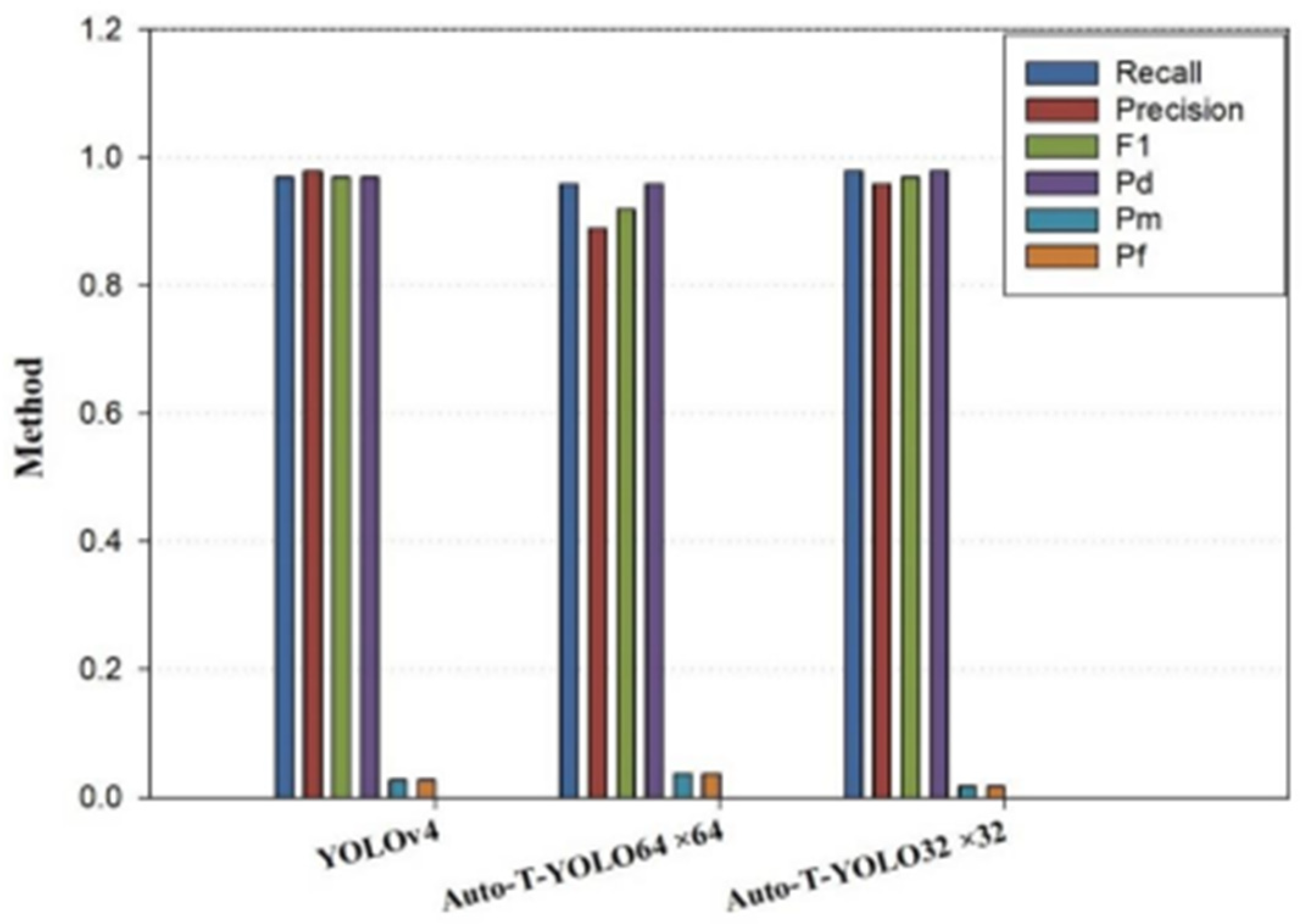
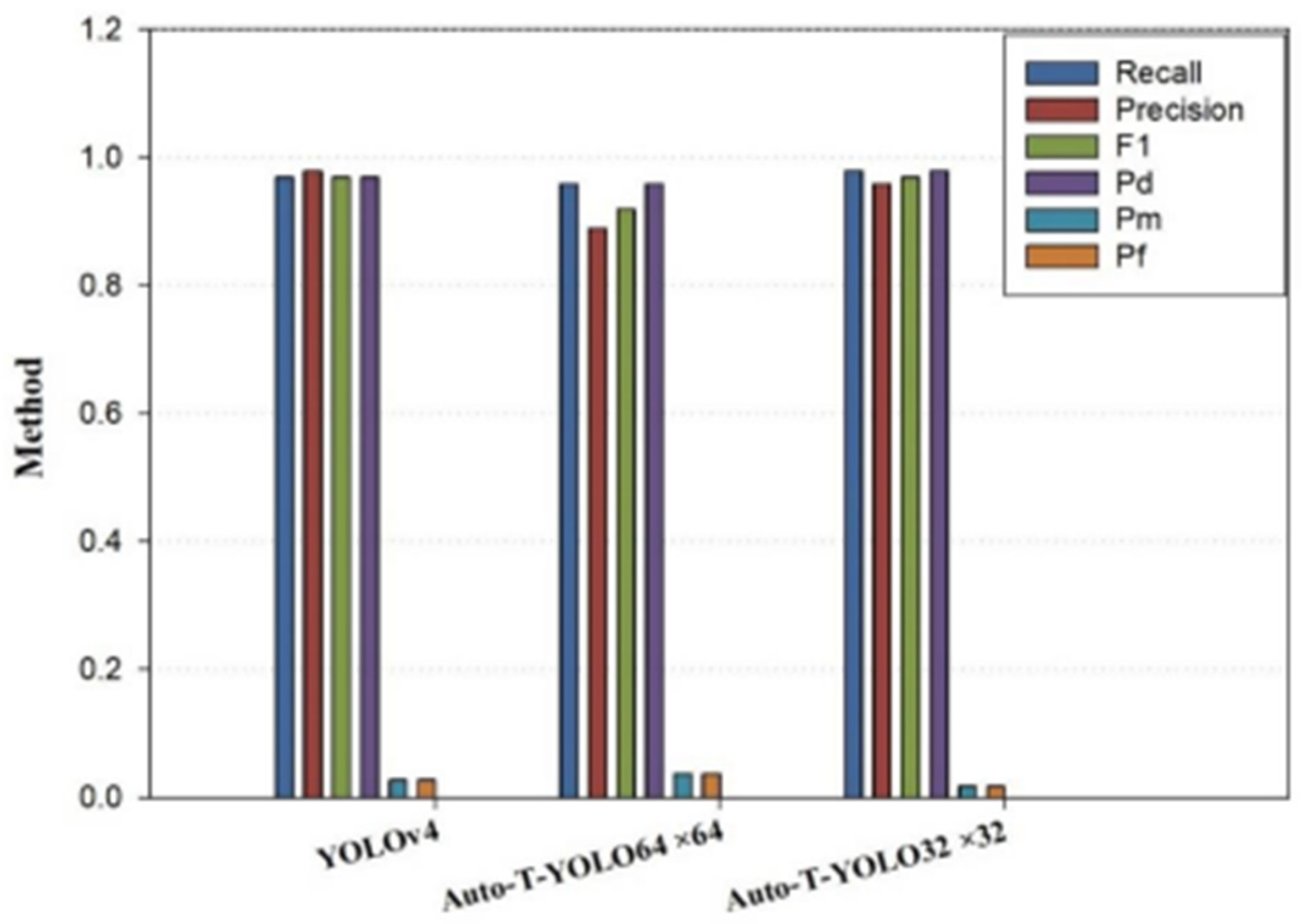
| YOLOv4 | 97.98% | 0.97 | 0.98 | 0.97 | 0.97 | 0.03 | 0.03 |
| 98.01% | 0.97 | 0.98 | 0.97 | 0.97 | 0.03 | 0.03 | |
| 98.33% | 0.98 | 0.96 | 0.97 | 0.98 | 0.02 | 0.02 |
| Method | |||||||
|---|---|---|---|---|---|---|---|
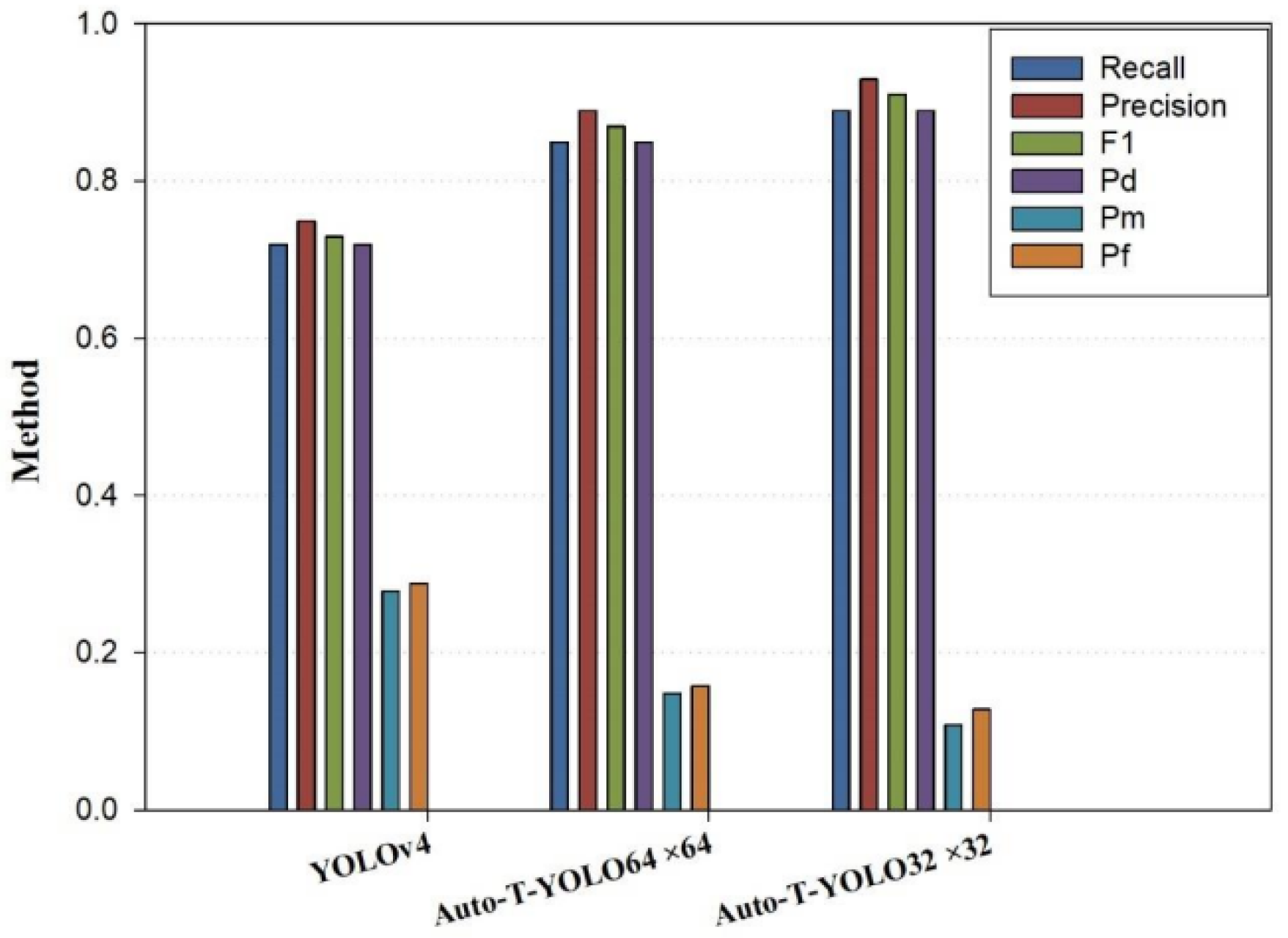
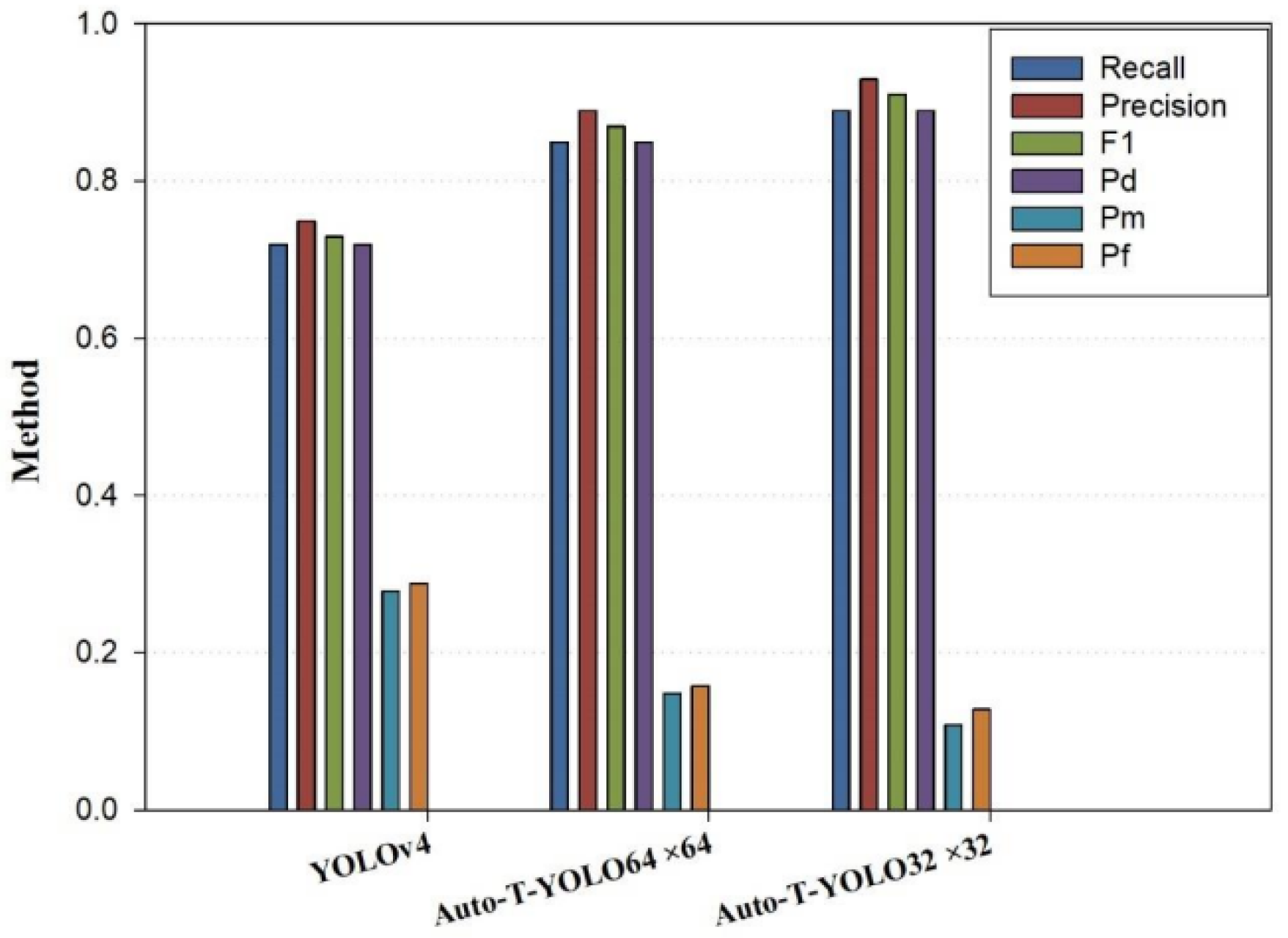
| YOLOv4 | 78.73% | 0.72 | 0.75 | 0.73 | 0.72 | 0.28 | 0.29 |
| 85.98% | 0.85 | 0.89 | 0.87 | 0.85 | 0.15 | 0.16 | |
| 91.78% | 0.89 | 0.93 | 0.91 | 0.89 | 0.11 | 0.13 |
| Method | |||||||
|---|---|---|---|---|---|---|---|
| YOLOv4 | 90.15% | 0.86 | 0.94 | 0.90 | 0.86 | 0.14 | 0.15 |
| YOLOv4-MHSA | 94.9% | 0.96 | 0.89 | 0.83 | 0.96 | 0.04 | 0.12 |
| Auto-T-YOLO | 96.3% | 0.96 | 0.86 | 0.91 | 0.96 | 0.04 | 0.09 |
| Method | |||||||
|---|---|---|---|---|---|---|---|
| YOLOv4 | 97.98% | 0.97 | 0.98 | 0.97 | 0.97 | 0.03 | 0.03 |
| YOLOv4-MHSA | 98.1% | 0.96 | 0.89 | 0.92 | 0.96 | 0.04 | 0.04 |
| Auto-T-YOLO | 98.33% | 0.98 | 0.96 | 0.97 | 0.98 | 0.02 | 0.02 |
| Method | |||||||
|---|---|---|---|---|---|---|---|
| YOLOv4 | 78.73% | 0.72 | 0.75 | 0.73 | 0.72 | 0.28 | 0.29 |
| YOLOv4-MHSA | 89.36% | 0.89 | 0.87 | 0.88 | 0.859 | 0.11 | 0.14 |
| Auto-T-YOLO | 91.78% | 0.89 | 0.93 | 0.91 | 0.89 | 0.11 | 0.13 |
| Method | AP | Recall | Precision | F1 | Pd | Pm | Pf | FPS | Param(M) |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv2 | 90.10% | 0.89 | 0.91 | 0.91 | 0.89 | 0.11 | 0.11 | 27 | 217 |
| YOLOv3 | 91.84% | 0.90 | 0.92 | 0.91 | 0.90 | 0.10 | 0.10 | 20.1 | 243.5 |
| SSD | 80.77% | 0.72 | 0.80 | 0.76 | 0.72 | 0.28 | 0.31 | 21.3 | 297.8 |
| Fater R-cnn | 92.94% | 0.71 | 0.92 | 0.76 | 0.71 | 0.29 | 0.38 | 13.3 | 482.4 |
| Mask R-cnn | 92.43% | 0.95 | 0.89 | 0.92 | 0.92 | 0.05 | 0.04 | 12.5 | 503.4 |
| RetinaNet | 94.1% | 0.94 | 0.92 | 0.93 | 0.94 | 0.06 | 0.05 | 12.8 | 442.3 |
| YOLOv4 | 90.15% | 0.86 | 0.94 | 0.90 | 0.86 | 0.14 | 0.15 | 24 | 244.2 |
| Auto-T-YOLO | 96.3% | 0.96 | 0.86 | 0.91 | 0.96 | 0.04 | 0.09 | 20.9 | 247.8 |
| Method | AP | Recall | Precision | F1 | Pd | Pm | Pf | FPS | Param(M) |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv3 | 95.39% | 0.99 | 0.95 | 0.97 | 0.99 | 0.01 | 0.01 | 20.1 | 243.5 |
| Fater R-cnn | 97.74% | 0.96 | 0.97 | 0.97 | 0.96 | 0.04 | 0.03 | 13.3 | 482.4 |
| RetinaNet | 97.81% | 0.96 | 0.95 | 0.96 | 0.96 | 0.04 | 0.04 | 12.8 | 442.3 |
| DAPN | 95.93% | 0.99 | 0.96 | 0.98 | 0.99 | 0.01 | 0.01 | 24 | 244.2 |
| HR-SDNet | 92.10 % | 0.94 | 0.95 | 0.94 | 0.94 | 0.06 | 0.06 | 11 | 598.1 |
| ARPN | 98.20 % | 0.96 | 0.97 | 0.96 | 0.96 | 0.04 | 0.04 | 13 | 490.7 |
| Auto-T-YOLO | 98.33% | 0.98 | 0.96 | 0.97 | 0.98 | 0.02 | 0.02 | 20.9 | 247.8 |
| Method | AP | Recall | Precision | F1 | Pd | Pm | Pf | FPS | Param(M) |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv3 | 78.50% | 0.71 | 0.73 | 0.72 | 0.71 | 0.29 | 0.30 | 20.1 | 243.5 |
| Fater R-cnn | 81.14% | 0.82 | 0.63 | 0.71 | 0.82 | 0.18 | 0.14 | 13.3 | 482.4 |
| RetinaNet | 82.1% | 0.83 | 0.86 | 0.84 | 0.83 | 0.27 | 0.18 | 12.8 | 442.3 |
| DAPN | 77.20% | 0.72 | 0.69 | 0.70 | 0.72 | 0.28 | 0.27 | 24 | 244.2 |
| HR-SDNet | 80.0% | 0.84 | 0.66 | 0.73 | 0.84 | 0.26 | 0.16 | 11 | 598.1 |
| ARPN | 84.1 % | 0.85 | 0.73 | 0.79 | 0.85 | 0.15 | 0.13 | 13 | 490.7 |
| Auto-T-YOLO | 91.78% | 0.89 | 0.93 | 0.91 | 0.89 | 0.11 | 0.13 | 20.9 | 247.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, B.; Wang, X.; Oad, A.; Pervez, A.; Dong, F. Automatic Ship Object Detection Model Based on YOLOv4 with Transformer Mechanism in Remote Sensing Images. Appl. Sci. 2023, 13, 2488. https://doi.org/10.3390/app13042488
Sun B, Wang X, Oad A, Pervez A, Dong F. Automatic Ship Object Detection Model Based on YOLOv4 with Transformer Mechanism in Remote Sensing Images. Applied Sciences. 2023; 13(4):2488. https://doi.org/10.3390/app13042488
Chicago/Turabian StyleSun, Bowen, Xiaofeng Wang, Ammar Oad, Amjad Pervez, and Feng Dong. 2023. "Automatic Ship Object Detection Model Based on YOLOv4 with Transformer Mechanism in Remote Sensing Images" Applied Sciences 13, no. 4: 2488. https://doi.org/10.3390/app13042488
APA StyleSun, B., Wang, X., Oad, A., Pervez, A., & Dong, F. (2023). Automatic Ship Object Detection Model Based on YOLOv4 with Transformer Mechanism in Remote Sensing Images. Applied Sciences, 13(4), 2488. https://doi.org/10.3390/app13042488