
Reinforcement Learning in Game Industry—Review, Prospects and Challenges



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Conduct an in–depth publication analysis via keyword analysis on existing literature data;
- Present key studies and publications that presented breakthroughs that addressed important issues in RL, such as policy degradation, exploding gradients, and general training instabilities;
- Draw important inferences regarding the growing nature of published research in DRL and its various domains;
- Analyze research on games in the field of DRL;
- Survey keystone DRL research done in game–based environments.
2. Theoretical Background
2.1. Markov Decision Process
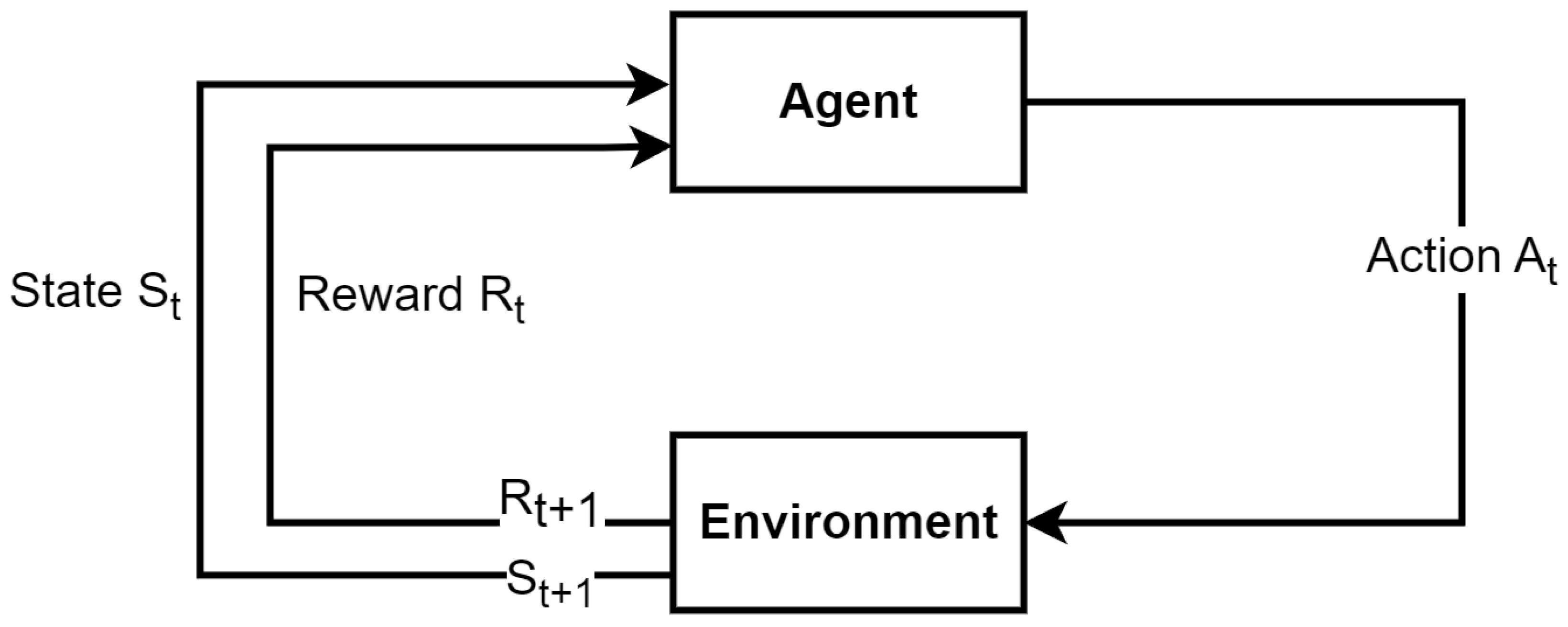
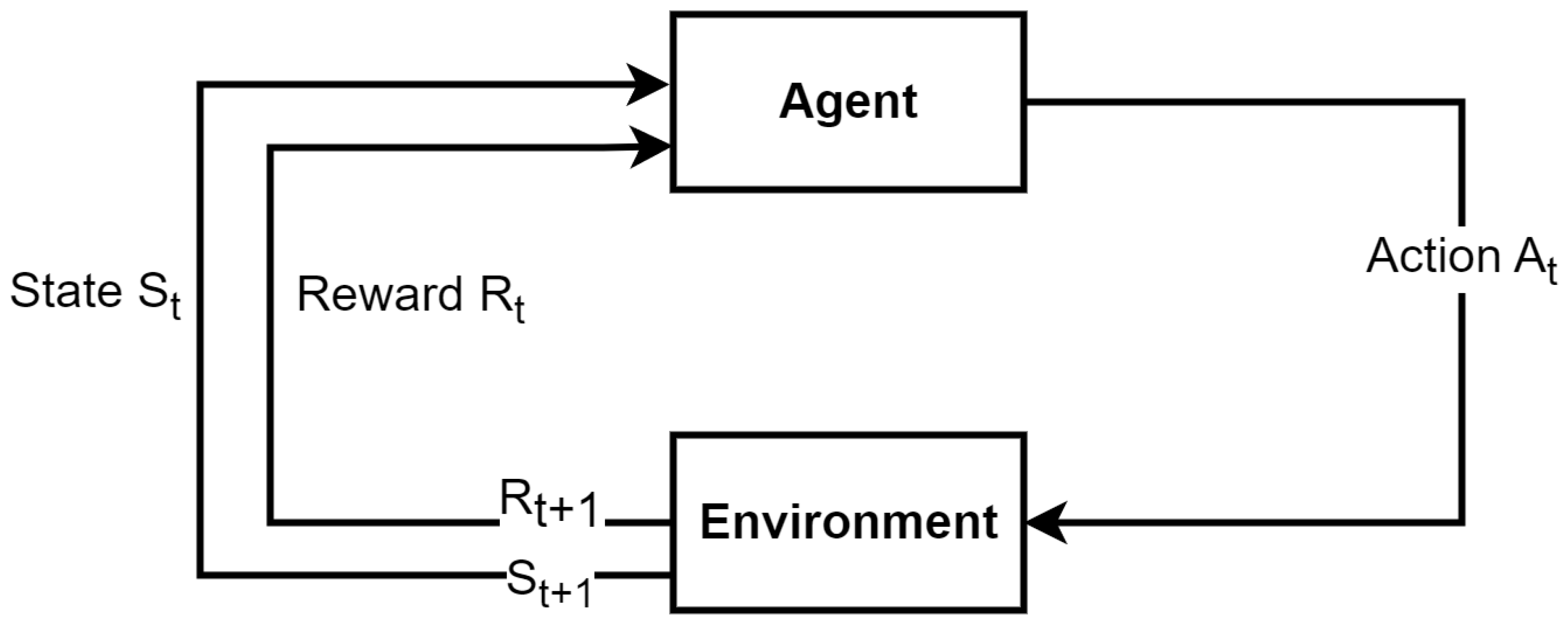
2.1.1. Reinforcement Learning
- The discrete different time–steps t;
- The state space S with state at time–step t;
- A set of actions A with action at time–step t;
- The policy function ;
- A reward function of an action , transitioning from state S to ;
- The state evaluation and energy evaluation .
2.1.2. Policy
- Exploration policy: The agent acts randomly to explore the state and the reward spaces.
- Exploitation policy: The agent acts based on preexisting knowledge.
2.1.3. State Evaluation
- the reward discount factor, which can take values between zero and one. The rate pushes for immediate rewards;
- the reward sum (discounted by ), from state until the end of the episode;
- the expected value of the rewards, given that the agent starts from the state s and acts based on policy .
2.1.4. Energy Evaluation
2.1.5. Bellman Equations
2.1.6. Best Policy
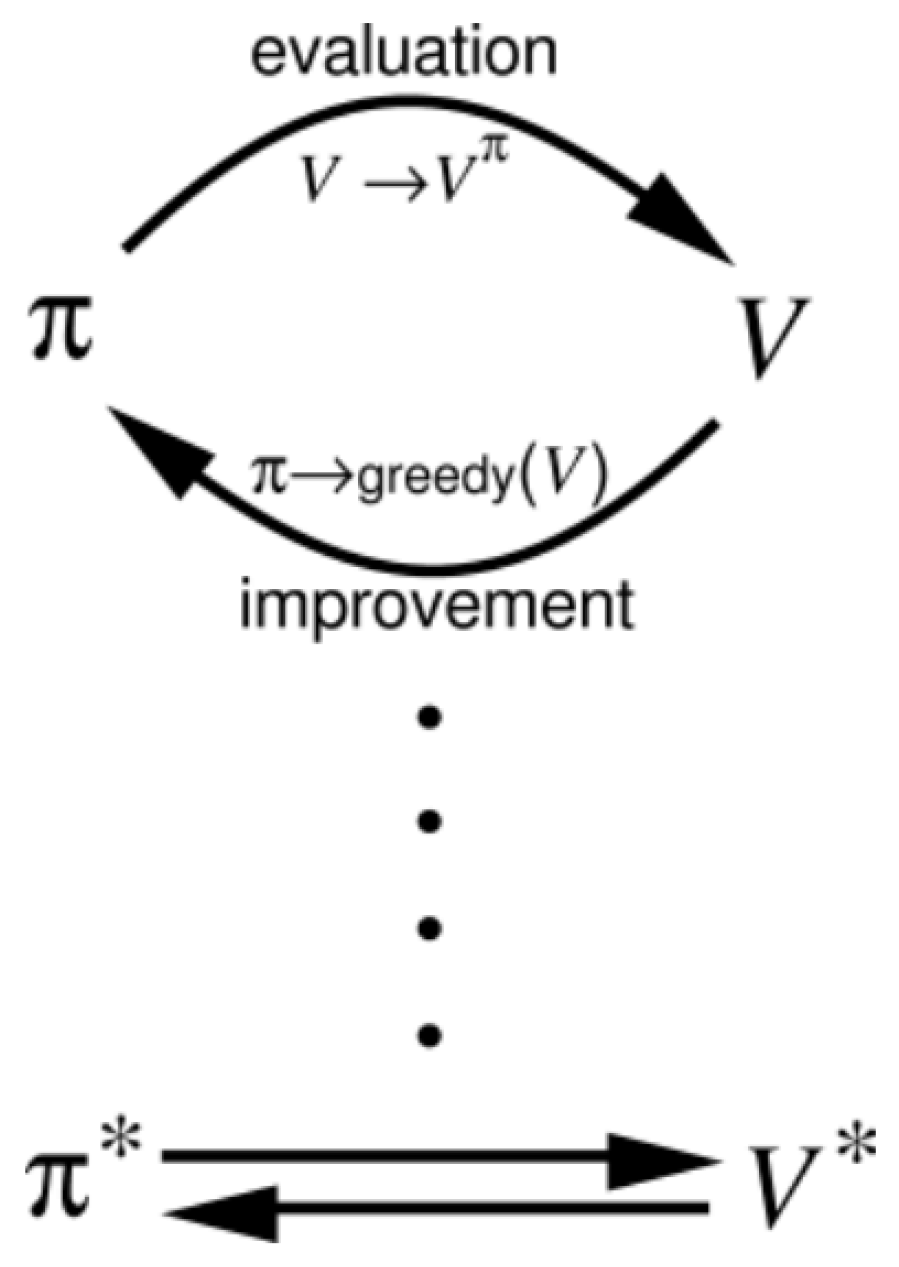
2.1.7. Policy Evaluation and Policy Improvement
2.1.8. Temporal Difference Learning
2.1.9. Q–Learning Algorithm
| Algorithm 1 Q–learning algorithm. |
|
3. Publication Analysis and Trends
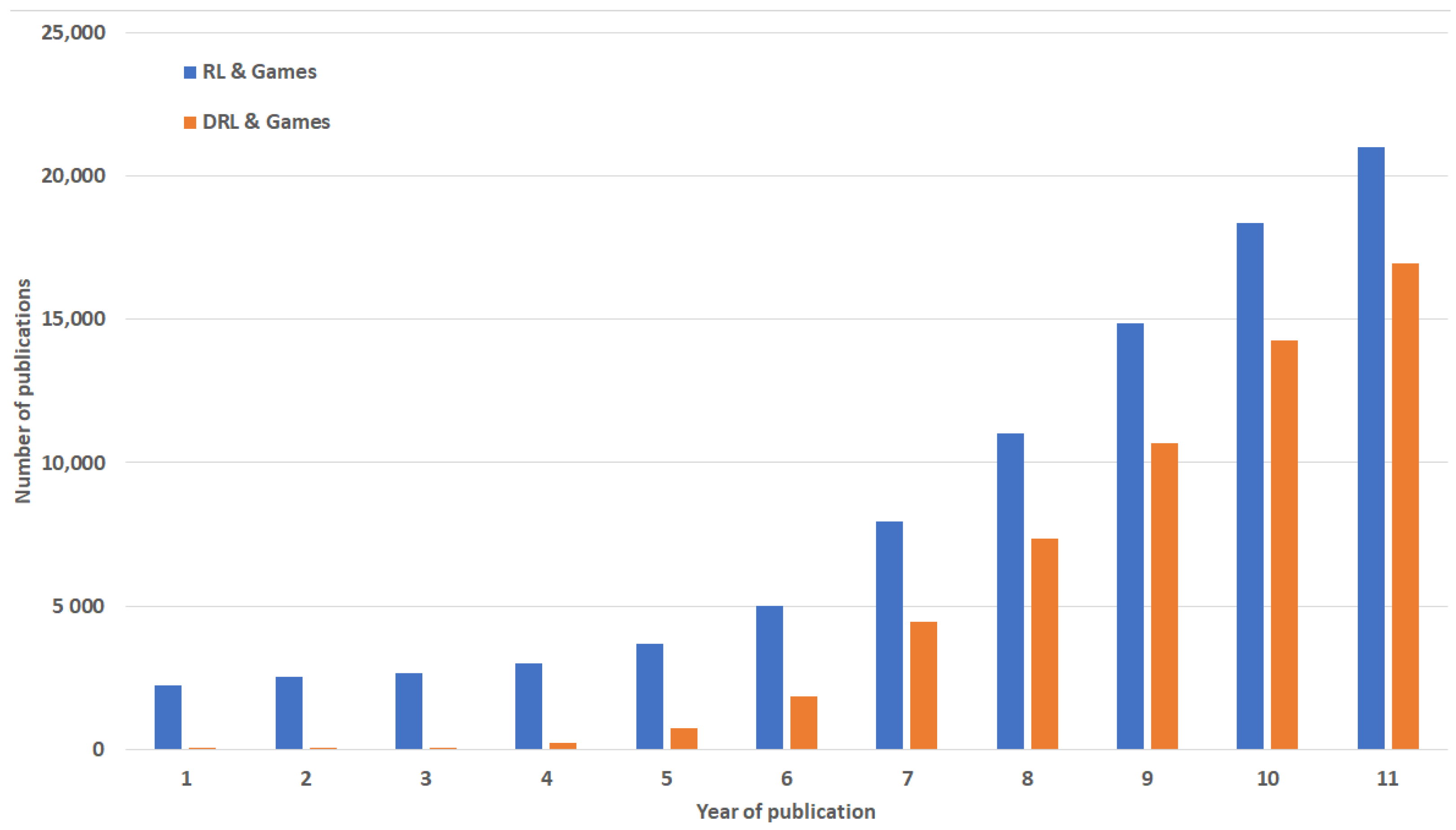
3.1. Statistics
3.2. Trends
3.3. Deep Reinforcement Learning and Games
3.3.1. Transition to Deep Reinforcement Learning
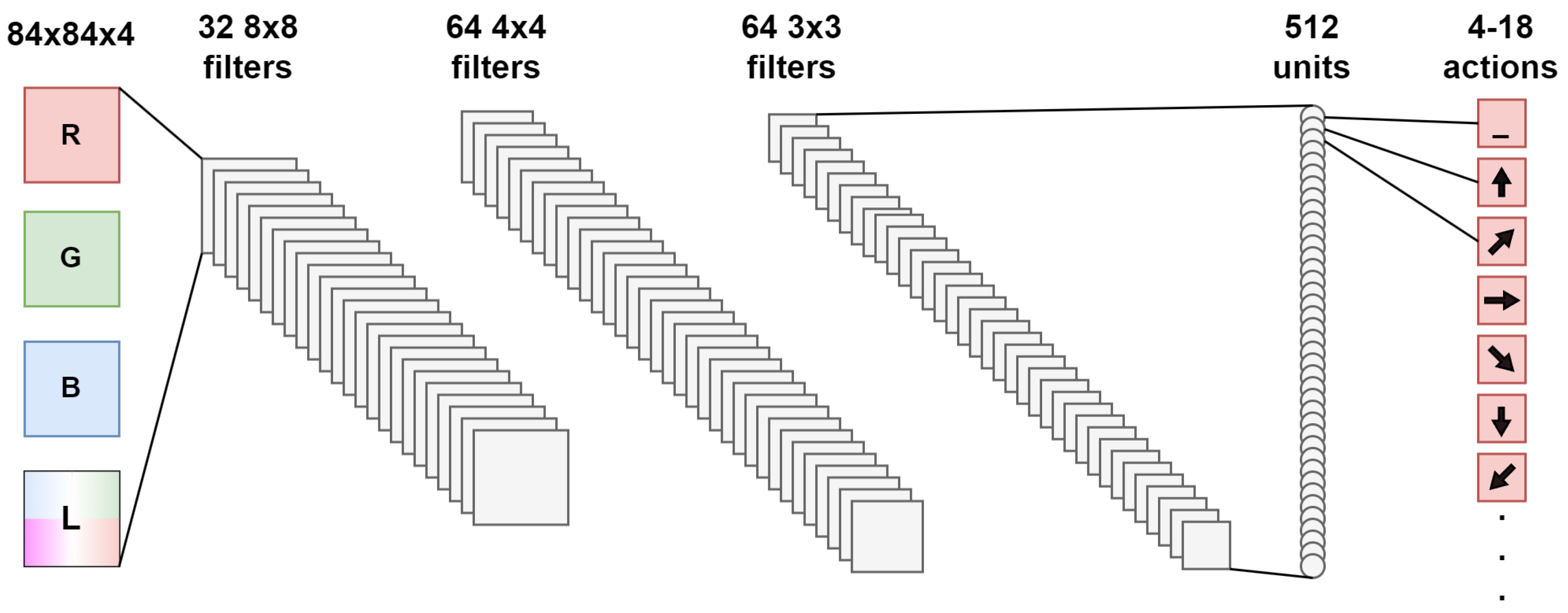
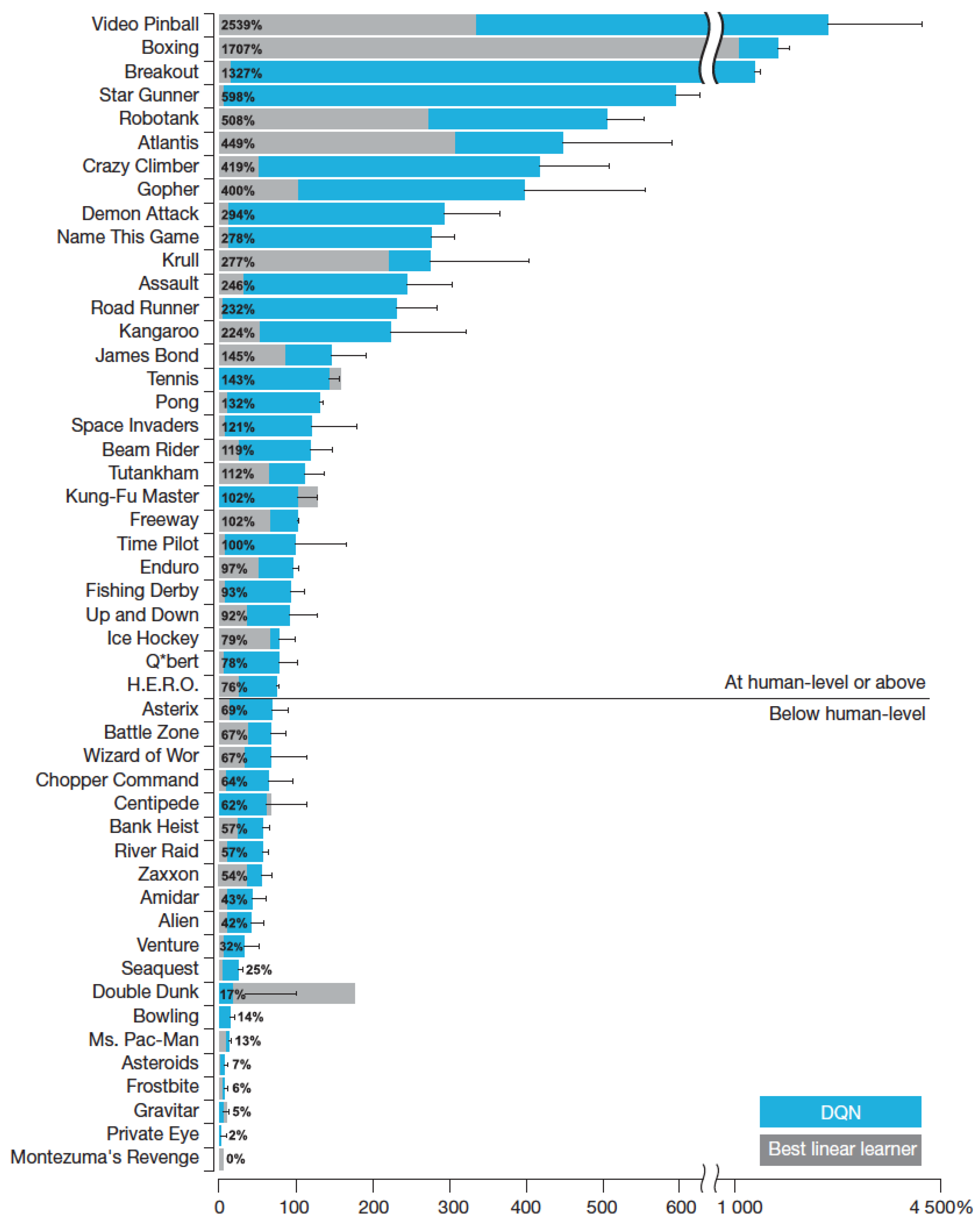
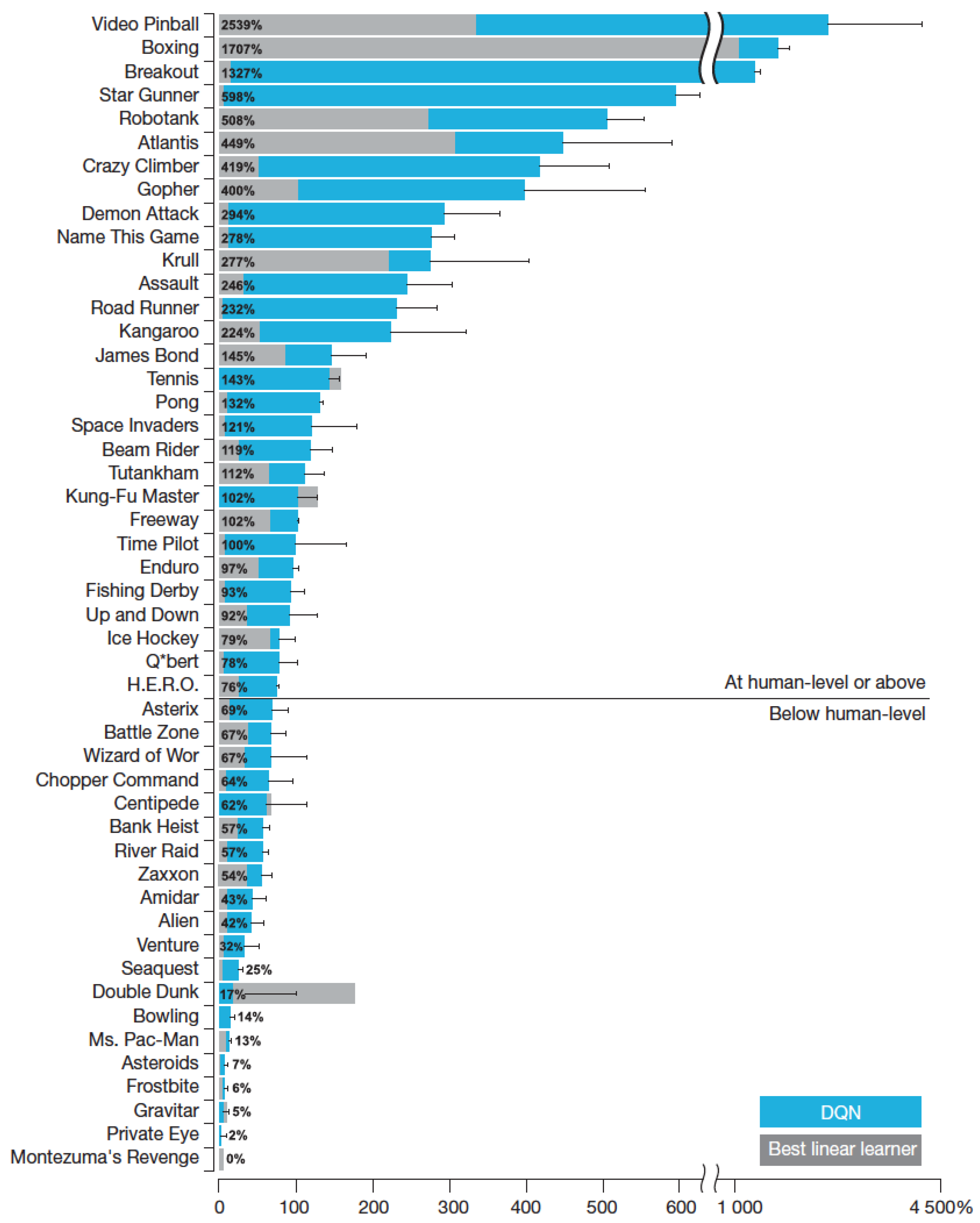
3.3.2. Deep Q–Network in ATARI
| Algorithm 2 Deep Q–learning algorithm. |
|
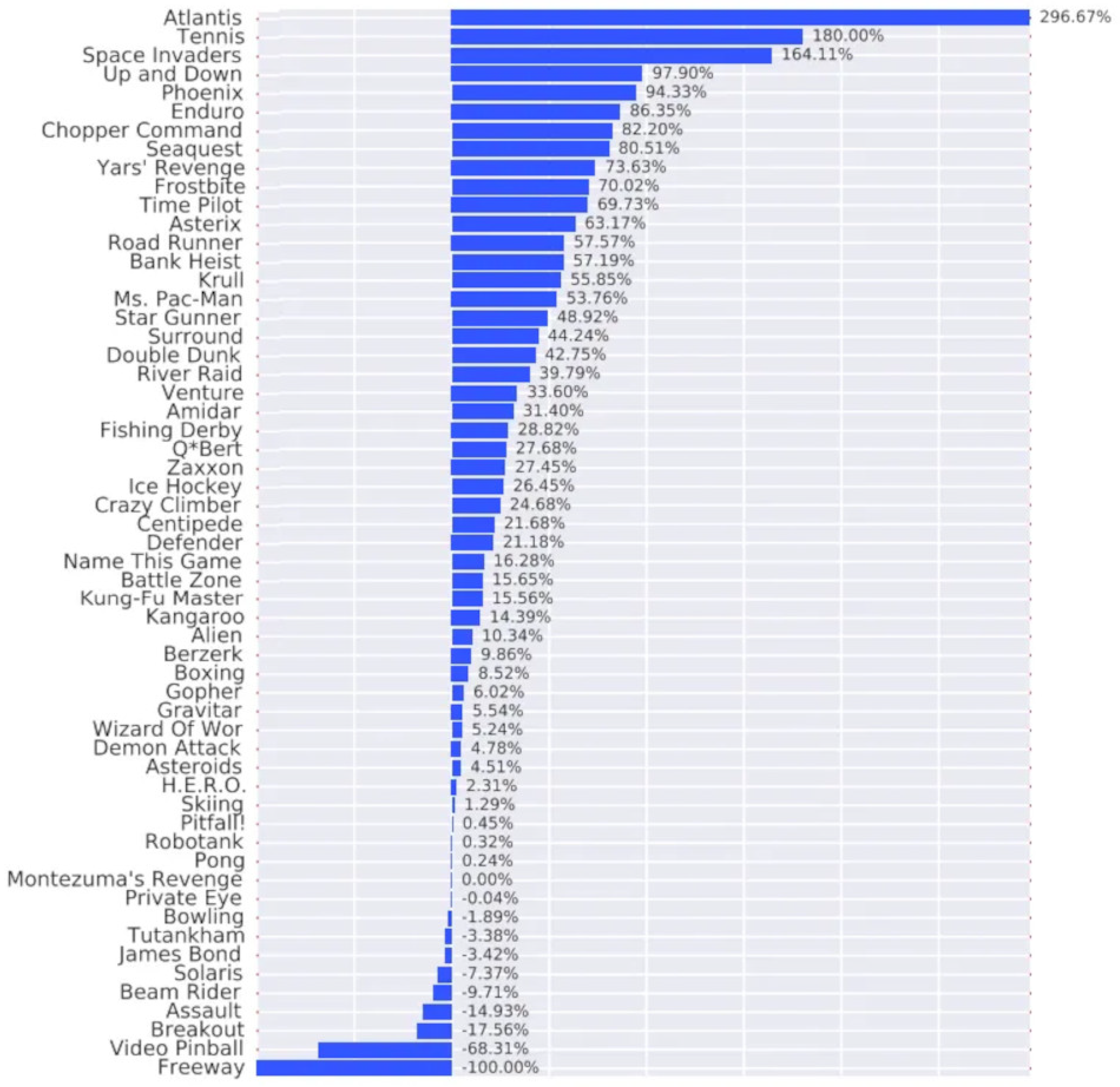
3.3.3. Double Q–Learning
| Algorithm 3 Double Q–learning algorithm. |
|
3.3.4. Prioritized Experience Replay
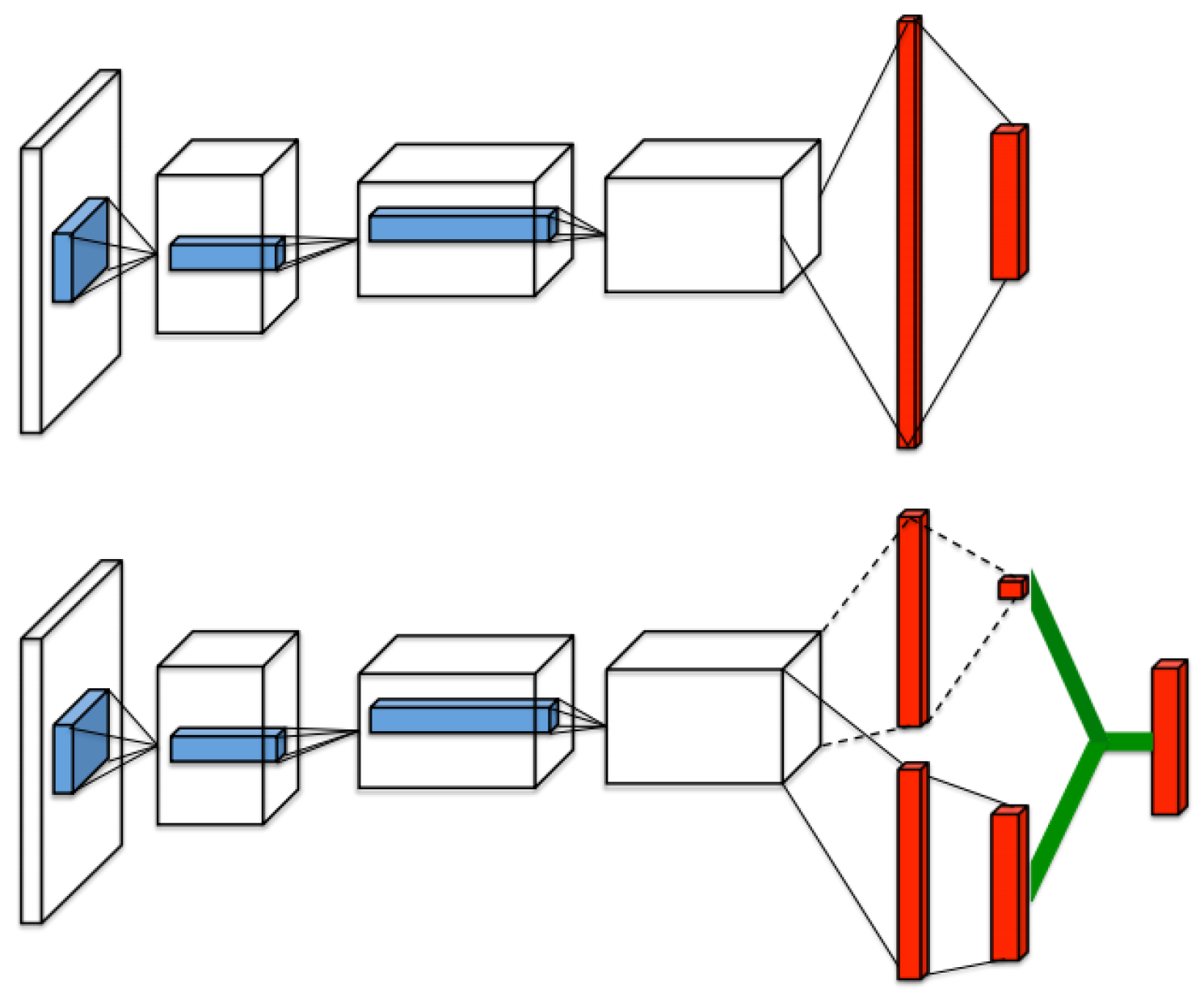
3.3.5. Dueling Networks
- One that calculates the state value ;
- One that will estimate the advantage of each action a in state s, .
3.3.6. Microsoft’s Success
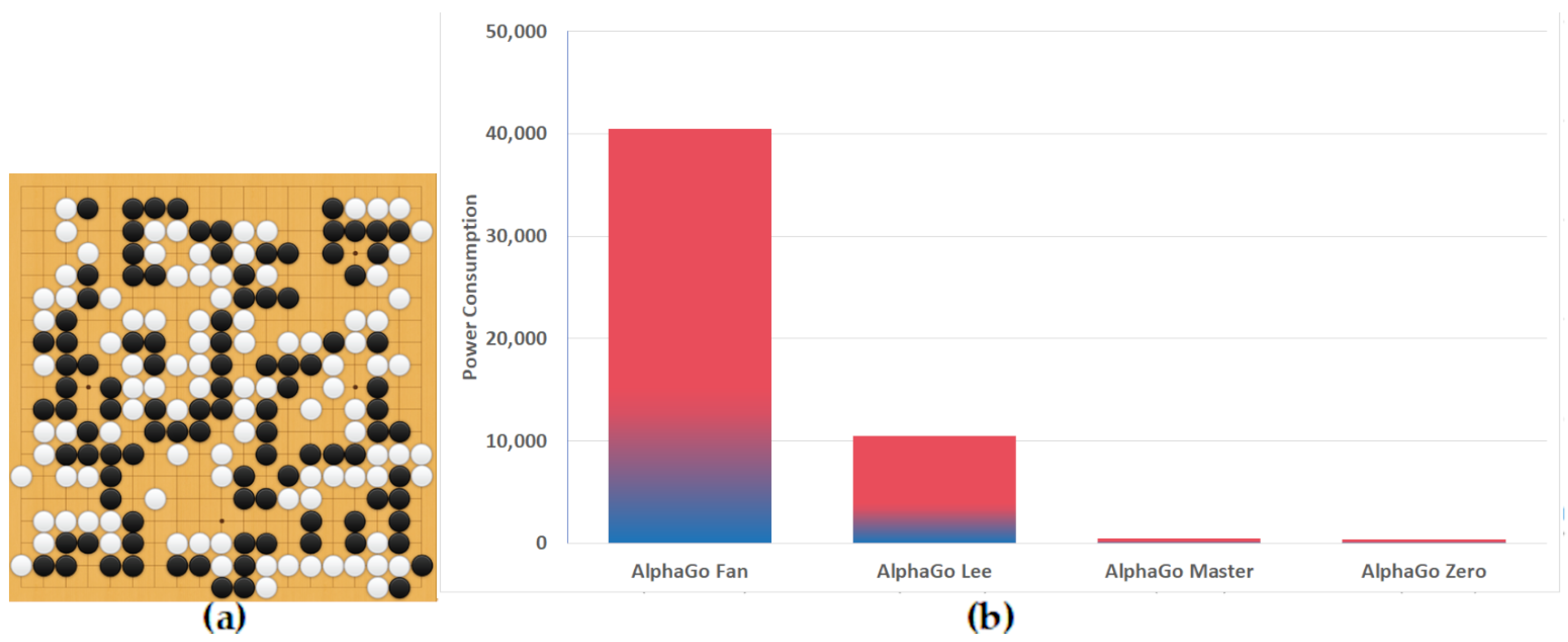
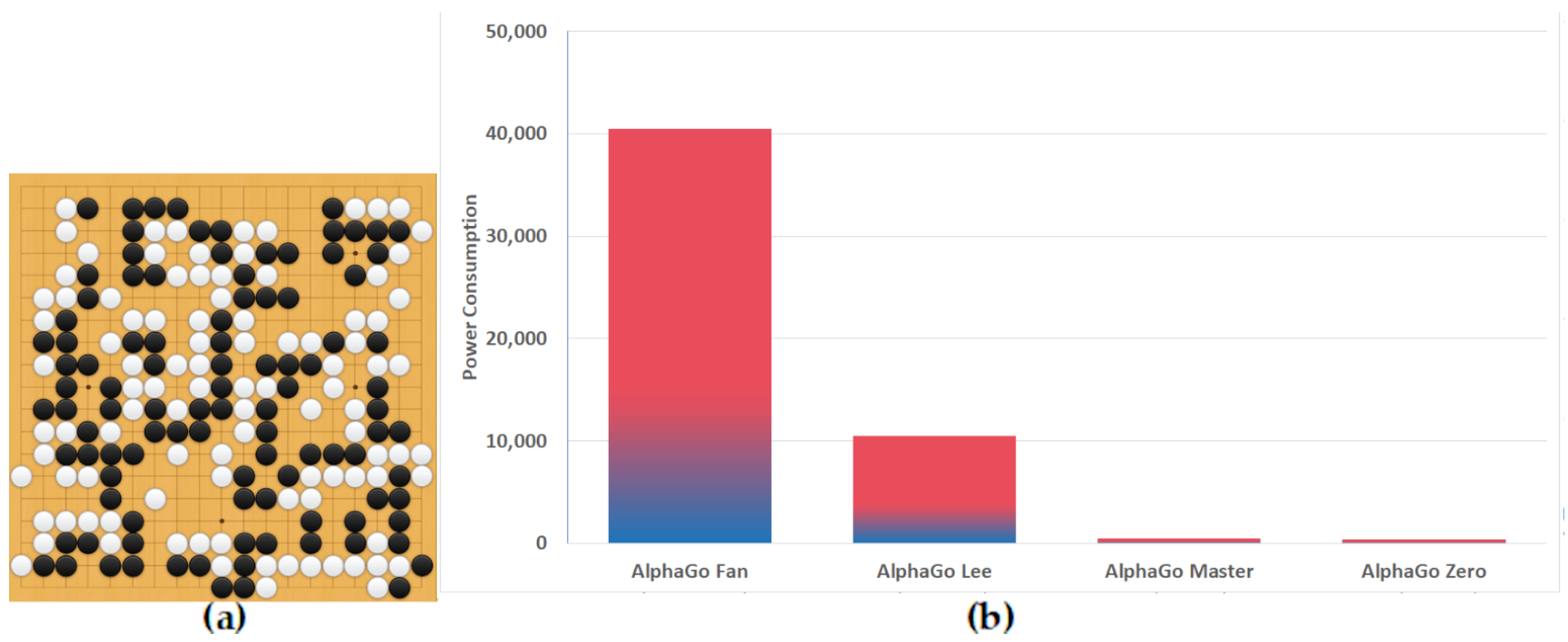
3.3.7. AlphaGo
3.3.8. OpenAI Five in DOTA2
3.3.9. AlphaStar in StarCraft II
3.3.10. Other Recent Notable Approaches
4. Benchmarks and Comparisons
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Broy, M. Software engineering from auxiliary to key technology. In Software Pioneers; Springer: Berlin/Germany, 2011; pp. 10–13. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. ImageNet: A large–scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Duy, T.; Sato, Y.; Inoguchi, Y. Performance evaluation of a green scheduling algorithm for energy savings in cloud computing. In Proceedings of the 2010 IEEE International Symposium on Parallel & Distributed Processing, Workshops and Ph.D. Forum (IPDPSW), Atlanta, GA, USA, 19–23 April 2010; pp. 1–8. [Google Scholar]
- Prevost, J.; Nagothu, K.; Kelley, B.; Jamshidi, M. Prediction of cloud data center networks loads using stochastic and neural models. In Proceedings of the 2011 6th International Conference on System of Systems Engineering, Albuquerque, NM, USA, 27–30 June 2011; pp. 276–281. [Google Scholar]
- Zhang, J.; Xie, N.; Zhang, X.; Yue, K.; Li, W.; Kumar, D. Machine learning based resource allocation of cloud computing in auction. Comput. Mater. Contin. 2018, 56, 123–135. [Google Scholar]
- Yang, R.; Ouyang, X.; Chen, Y.; Townend, P.; Xu, J. Intelligent resource scheduling at scale: A machine learning perspective. In Proceedings of the 2018 IEEE Symposium on Service–Oriented System Engineering, Bamberg, Germany, 26–29 March 2018; pp. 132–141. [Google Scholar]
- Islam, S.; Keung, J.; Lee, K.; Liu, A. Empirical prediction models for adaptive resource provisioning in the cloud. Future Gener. Comput. Syst. 2012, 28, 155–162. [Google Scholar] [CrossRef]
- Bellemare, M.G.; Naddaf, Y.; Veness, J.; Bowling, M. The Arcade Learning Environment: An Evaluation Platform for General Agents. arXiv 2012, arXiv:1207.4708. [Google Scholar] [CrossRef]
- Hausknecht, M.; Lehman, J.; Miikkulainen, R.; Stone, P. A Neuroevolution Approach to General Atari Game Playing. IEEE Trans. Comput. Intell. Games 2014, 6, 355–366. [Google Scholar] [CrossRef]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. A Brief Survey of Deep Reinforcement Learning. arXiv 2017, arXiv:1708.05866. [Google Scholar] [CrossRef]
- Fujimoto, S.; van Hoof, H.; Meger, D. Addressing Function Approximation Error in Actor–Critic Methods. In Proceedings of the 2018 International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. arXiv:1802.09477. [Google Scholar]
- Anschel, O.; Baram, N.; Shimkin, N. Averaged–DQN: Variance Reduction and Stabilization for Deep Reinforcement Learning. In Proceedings of the 34th International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; Volume 70, pp. 176–185. [Google Scholar]
- Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q–learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Hasselt, H.; Lanctot, M.; Freitas, N. Dueling network architectures for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1995–2003. [Google Scholar]
- Schulman, J.; Levine, S.; Moritz, P.; Jordan, M.I.; Abbeel, P. Trust Region Policy Optimization. In Proceedings of the 2015 International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Hausknecht, M.; Stone, P. Deep recurrent q–learning for partially observable mdps. In Proceedings of the 2015 AAAI Fall Symposium Series, Arlington, VA, USA, 12–14 November 2015. [Google Scholar]
- Zhao, Z. Variants of Bellman equation on reinforcement learning problems. In Proceedings of the 2nd International Conference on Artificial Intelligence, Automation, and High–Performance Computing (AIAHPC 2022), Zhuhai, China, 25–27 February 2022; Zhu, L., Ed.; International Society for Optics and Photonics, SPIE: Zhuhai, China, 2022; Volume 12348, p. 132. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.; Veness, J.; Bellemare, M.; Graves, A.; Riedmiller, M.; Fidjeland, A.; Ostrovski, G. Human–level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Khan, M.A.M.; Khan, M.R.J.; Tooshil, A.; Sikder, N.; Mahmud, M.A.P.; Kouzani, A.Z.; Nahid, A.A. A Systematic Review on Reinforcement Learning–Based Robotics Within the Last Decade. IEEE Access 2020, 8, 176598–176623. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; A Bradford Book; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized experience replay. arXiv 2015, arXiv:1511.05952. [Google Scholar]
- Lin, L.J. Reinforcement Learning for Robots Using Neural Networks. Ph.D. Thesis, Carnegie Mellon University, Pittsburgh, PA, USA, January 1993. [Google Scholar]
- Fortunato, M.; Azar, M.; Piot, B.; Menick, J.; Osband, I.; Graves, A.; Mnih, V.; Munos, R.; Hassabis, D.; Pietquin, O. Noisy networks for exploration. arXiv 2017, arXiv:1706.10295. [Google Scholar]
- Osband, I.; Blundell, C.; Pritzel, A.; Roy, B. Deep Exploration via Bootstrapped Dqn. Advances in Neural Information Processing Systems. 2016. Available online: https://proceedings.neurips.cc/paper/2016/file/8d8818c8e140c64c743113f563cf750f-Paper.pdf (accessed on 3 January 2023).
- Hester, T.; Vecerik, M.; Pietquin, O.; Lanctot, M.; Schaul, T.; Piot, B.; Horgan, D.; Quan, J.; Sendonaris, A.; Osband, I. Deep q–learning from demonstrations. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Andrew, A. Reinforcement Learning: An Introduction by Richard S. Sutton and Andrew G. Barto, Adaptive Computation and Machine Learning Series; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Roy, B. An analysis of temporal–difference learning with function approximation. Autom. Control. IEEE Trans. 1997, 42, 674–690. [Google Scholar]
- Kelly, S.; Heywood, M.I. Emergent Tangled Graph Representations for Atari Game Playing Agents. In Proceedings of the Genetic Programming; McDermott, J., Castelli, M., Sekanina, L., Haasdijk, E., García–Sánchez, P., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 64–79. [Google Scholar]
- Wilson, D.G.; Cussat–Blanc, S.; Luga, H.; Miller, J.F. Evolving Simple Programs for Playing Atari Games. In Proceedings of the Genetic and Evolutionary Computation Conference, Kyoto, Japan, 15–19 July 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 229–236. [Google Scholar] [CrossRef] [Green Version]
- Smith, R.J.; Heywood, M.I. Scaling Tangled Program Graphs to Visual Reinforcement Learning in ViZDoom. In Proceedings of the Genetic Programming; Castelli, M., Sekanina, L., Zhang, M., Cagnoni, S., García–Sánchez, P., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 135–150. [Google Scholar]
- Smith, R.J.; Heywood, M.I. Evolving Dota 2 Shadow Fiend Bots Using Genetic Programming with External Memory. In Proceedings of the Genetic and Evolutionary Computation Conference, Prague, Czech Republic, 13–17 July 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 179–187. [Google Scholar] [CrossRef]
- Zhao, D.; Wang, H.; Shao, K.; Zhu, Y. Deep reinforcement learning with experience replay based on sarsa. In Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence, Athens, Greece, 6–9 December 2016; pp. 1–6. [Google Scholar]
- Vinyals, O.; Ewalds, T.; Bartunov, S.; Georgiev, P.; Vezhnevets, A.; Yeo, M.; Makhzani, A.; Küttler, H.; Agapiou, J.; Schrittwieser, J. Starcraft ii: A new challenge for reinforcement learning. arXiv 2017, arXiv:1708.04782. [Google Scholar]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic policy gradient algorithms. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 387–395. [Google Scholar]
- Rudin, C. Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef]
- Melnik, A.; Fleer, S.; Schilling, M.; Ritter, H. Modularization of end–to–end learning: Case study in arcade games. arXiv 2019, arXiv:1901.09895. [Google Scholar]
- Polvara, R.; Patacchiola, M.; Sharma, S.; Wan, J.; Manning, A.; Sutton, R.; Cangelosi, A. Autonomous quadrotor landing using deep reinforcement learning. arXiv 2017, arXiv:1709.03339. [Google Scholar]
- Pan, X.; You, Y.; Wang, Z.; Lu, C. Virtual to real reinforcement learning for autonomous driving. arXiv 2017, arXiv:1704.03952. [Google Scholar]
- Loiacono, D.; Cardamone, L.; Lanzi, P. Simulated car racing championship: Competition software manual. arXiv 2013, arXiv:1304.1672. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Synnaeve, G.; Nardelli, N.; Auvolat, A.; Chintala, S.; Lacroix, T.; Lin, Z.; Richoux, F.; Usunier, N. Torchcraft: A library for machine learning research on real–time strategy games. arXiv 2016, arXiv:1611.00625. [Google Scholar]
- Peng, P.; Wen, Y.; Yang, Y.; Yuan, Q.; Tang, Z.; Long, H.; Wang, J. Multiagent bidirectionally–coordinated nets: Emergence of humanlevel coordination in learning to play starcraft combat games. arXiv 2017, arXiv:1703.10069. [Google Scholar]
- Foerster, J.; Farquhar, G.; Afouras, T.; Nardelli, N.; Whiteson, S. Counterfactual multi–agent policy gradients. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Logothetis, N. The ins and outs of fmri signals. Nat. Neurosci. 2007, 10, 1230–1232. [Google Scholar] [CrossRef] [PubMed]
- Oh, J.; Singh, S.; Lee, H.; Kohli, P. Zero–shot task generalization with multi–task deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; pp. 2661–2670. [Google Scholar]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. OpenAI Gym, 2016. arXiv 2017, arXiv:1606.01540. [Google Scholar]
- Xiong, Y.; Chen, H.; Zhao, M.; An, B. Hogrider: Champion agent of microsoft malmo collaborative ai challenge. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T. Mastering chess and shogi by self–play with a general reinforcement learning algorithm. arXiv 2017, arXiv:1712.01815. [Google Scholar]
- David, O.; Netanyahu, N.; Wolf, L. Deepchess: End–to–end deep neural network for automatic learning in chess. In Proceedings of the International Conference on Artificial Neural Networks, Barcelona, Spain, 6–9 September 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 88–96. [Google Scholar]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T. A general reinforcement learning algorithm that masters chess, shogi, and go through self–play. Science 2018, 362, 1140–1144. [Google Scholar] [CrossRef] [PubMed]
- Justesen, N.; Torrado, R.; Bontrager, P.; Khalifa, A.; Togelius, J.; Risi, S. Illuminating generalization in deep reinforcement learning through procedural level generation. arXiv 2018, arXiv:1806.10729. [Google Scholar]
- Choudhary, A. A Hands-On Introduction to Deep Q-Learning Using OpenAI Gym in Python. Anal Vidhya. 2019. Available online: https://www.analyticsvidhya.com/blog/2019/04/introduction-deep-q-learning-python/ (accessed on 21 October 2022).
- Silver, D.; Huang, A.; Sifre, L.; Driessche, v.d.G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; Dieleman, S.; Grewe, D.; et al. Arthur guez, an cjm. Nature 2016, 529, 484–492. [Google Scholar] [CrossRef]
- OpenAI; Berner, C.; Brockman, G.; Chan, B.; Cheung, V.; Debiak, P.; Dennison, C.; Farhi, D.; Fischer, Q.; Hashme, S.; et al. Dota 2 with large scale deep reinforcement learning. arXiv 2019, arXiv:1912.06680. [Google Scholar]
- Bellemare, M.; Srinivasan, S.; Ostrovski, G.; Schaul, T.; Saxton, D.; Munos, R. Unifying count–based exploration and intrinsic motivation. Adv. Neural Inf. Process. Syst. 2016, 29, 1479–1487. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short–term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Such, F.; Madhavan, V.; Conti, E.; Lehman, J.; Stanley, K.; Clune, J. Deep neuroevolution: Genetic algorithms are a competitive alternative for training deep neural networks for reinforcement learning. arXiv 2017, arXiv:1712.06567. [Google Scholar]
- Vinyals, O.; Fortunato, M.; Jaitly, N. Pointer networks. arXiv 2015, arXiv:1506.03134. [Google Scholar]
- Lee, J.; Lee, Y.; Kim, J.; Kosiorek, A.; Choi, S.; Teh, Y.W. Set Transformer: A Framework for Attention-based Permutation-Invariant Neural Networks. In Proceedings of the International Conference on Machine Learning, Stockholmsmässan, Sweden, 15–19 July 2018. [Google Scholar]
- Ammanabrolu, P.; Riedl, M.O. Playing Text–Adventure Games with Graph–Based Deep Reinforcement Learning. arXiv 2018, arXiv:1812.01628. [Google Scholar]
- Adolphs, L.; Hofmann, T. LeDeepChef: Deep Reinforcement Learning Agent for Families of Text–Based Games. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27–28 January 2019. [Google Scholar]
- Brown, N.; Bakhtin, A.; Lerer, A.; Gong, Q. Combining Deep Reinforcement Learning and Search for Imperfect–Information Games. arXiv 2020, arXiv:2007.13544. [Google Scholar]
- Ye, D.; Liu, Z.; Sun, M.; Shi, B.; Zhao, P.; Wu, H.; Yu, H.; Yang, S.; Wu, X.; Guo, Q.; et al. Mastering Complex Control in MOBA Games with Deep Reinforcement Learning. Proc. AAAI Conf. Artif. Intell. 2020, 34, 6672–6679. [Google Scholar] [CrossRef]












Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Souchleris, K.; Sidiropoulos, G.K.; Papakostas, G.A. Reinforcement Learning in Game Industry—Review, Prospects and Challenges. Appl. Sci. 2023, 13, 2443. https://doi.org/10.3390/app13042443
Souchleris K, Sidiropoulos GK, Papakostas GA. Reinforcement Learning in Game Industry—Review, Prospects and Challenges. Applied Sciences. 2023; 13(4):2443. https://doi.org/10.3390/app13042443
Chicago/Turabian StyleSouchleris, Konstantinos, George K. Sidiropoulos, and George A. Papakostas. 2023. "Reinforcement Learning in Game Industry—Review, Prospects and Challenges" Applied Sciences 13, no. 4: 2443. https://doi.org/10.3390/app13042443
APA StyleSouchleris, K., Sidiropoulos, G. K., & Papakostas, G. A. (2023). Reinforcement Learning in Game Industry—Review, Prospects and Challenges. Applied Sciences, 13(4), 2443. https://doi.org/10.3390/app13042443