Abstract
One of the main tasks in kernel methods is the selection of adequate mappings into higher dimension in order to improve class classification. However, this tends to be time consuming, and it may not finish with the best separation between classes. Therefore, there is a need for better methods that are able to extract distance and class separation from data. This work presents a novel approach for learning such mappings by using locally stationary kernels, spectral representations and Gaussian mixtures.
1. Introduction
During the 90’s, the use of kernels [1,2,3,4,5] in Machine Learning received a considerable attention for their ability to improve the performance of linear classifiers. By using kernels, Support Vector Machines and other kernel methods [6,7] can classify complex data sets by mapping them into high dimensional spaces. However, an underlying issue exists, summarized by a simple question: Which kernel should be used? [8].
Kernel selection is not a small task and would highly depend on the problem to be solved. A first idea to select the best kernel could be evaluating different kernels from a small set using leave-one-out cross-validation and selecting the kernel with better classification properties. Nevertheless, this can become a time-consuming task when the number of samples range in the thousands. A better idea is to use a combination of kernels to create kernels with better classification properties. Methods using this type of techniques are called Multiple Kernel Learning (MKL) [9]. For example, Lanckriet [10] uses a Semi-Definite Programming (SDP) to find the best conic combination of multiple kernels. However, these methods still require some pre-selected set of kernels as inputs. A better plan will be to use the distance information at the class data sets. For example, Hoi [11] tries to find a kernel Gram matrix by building the Laplacian Graph [12] of the data. Then, an SDP is applied to find the best combination of kernels.
However, none of these methods are scalable given that their Gram matrix needs to be built the computational complexity of building a Gram matrix is where N is the number of samples. As a possible solution, it has been proposed to use Sequential Minimal Optimization (SMO) [13] to reduce complexity. This allows to move the quadratic programming problem to a quadratic programming sub-problems. For example, Bach [14] uses an SDP setup and solves the problem by using an SMO algorithm. Other techniques [15] use a random sample of the training set, and a possible approximation to the Gram Matrix to reduce complexity , m sub-problem size). Expanding on this idea, Rahimi [16] approximates kernel functions using samples of the distribution, but only for stationary kernels. On the other hand, Ghiasi-Shirazi [17] proposes a method for learning m number of stationary kernels in the approach of MKL. The method has a main advantage, its ability to learn m number of kernels in an unsupervised way by reducing the complexity of the output function. Furthermore, it reduces the complexity of the classifier output from to by using m kernels. Finally, Oliva [18], makes use of Bayesian methods to learn a stationary kernel in a non-parametric way.
On this work, we propose to learn locally stationary kernel from data, given that stationary kernels are a subset of the locally stationary kernel, by using a spectral representation and Gaussian Mixtures [19]. This allows to improve the classification and regression task by looking at the kernel as the result of a sampling process on a spectral representation. This paper is structured in the following way: in Section 2, we show the basic theory to understand the idea of stationary and locally stationary kernels. In Section 3, the proposed algorithm is developed by using Fourier Basis and sampling. Additionally, a theorem is given about the performance of the spectral representation. In Section 4, we review the experiments for classification and regression tasks to test the robustness of the proposed algorithm. Finally, we present an analysis of the advantages of the proposed algorithm and possible venues of research in the Section 5.
2. The Concept of Kernels
The main idea of using kernel methods is to obtain the distance between samples on higher dimensional. Thus, avoid mapping the samples to higher dimensional spaces and using the inner product for such process. In other words, let be the input set, where , let be a feature space, and suppose the feature mapping function is defined as . Hence, the kernel function, , has the following property:
where . Thus, and the feature space can be implicitly defined. Now, let be the set of samples, be a valid kernel, and be a well defined inner product. Then, the elements at the Gram Matrix, , are computed using the mapping, . Given this definition, Genton [20] makes an in-depth study of the class of kernel from a statistics perspective, i.e., the kernel functions as a co-variance function. He pointed out that kernels have a spectral representation which can be used to represent their Gram matrix. Based on this representation, the proposed algorithm learns the Gram matrix by using a Gibbs sampler to obtain the structure of such matrix.
2.1. Stationary Kernels
Stationary kernels [20] are defined as . An important factor in such definition is its dependency on the lag vector which can be interpreted as generalizations of the Gaussian probability distribution functions which are used to represent distributions [15]. Additionally, Bochner [21] proved that a symmetric function is a positive definite in , if and only if, it has the form:
where is a positive finite measure. Equation (1) is called the spectral representation of . Now, suppose has a density and . Thus, it is possible to obtain:
In other words, the kernel function and its spectral density F are Fourier dual of each other. Furthermore, if and F is a probability measure, the unique condition to define a valid Gaussian process is . In other words, we need this condition to ensure that the kernel and the function f are correctly correlated.
2.2. Locally Stationary Kernels
Extending on the previous concept, Silverman [22] defines the locally stationary kernels as:
where is a non negative function and is a stationary kernel. This type of kernels increase the power of the representation by introducing a possible variance into the final calculated similarity through the use of . Furthermore, we can see from Equation (2) that the Locally Stationary Kernels include all stationary kernels. In order to see this, we make , where c is a positive constant, then , a multiple of all stationary kernels. Furthermore, the variance of locally stationary kernels is given by , thus, the variance is defined as:
This means that the variance of the Locally Stationary Kernels relies in the positive definite function .
The spectral representation of a locally stationary kernel is also given by [22], and it is defined as:
Furthermore, by setting , we can get:
Consequently, in order to define a locally stationary kernel, and must be integrable functions. Additionally, an important fact is that the kernel has a defined inverse, given by:
Moreover, is the Fourier transform of and is the Fourier transform of . Thus, if we introduce two dummy variables and , it is possible to obtain:
and
with this in mind, it is possible to use the ideas in [16] to approximate the locally stationary kernels.
3. Approximating Stationary Kernels
Rahimi [16] makes use of (1) to approximate stationary kernels. This is, if we define ; then, Equation (1) becomes:
where . Now, using Monte Carlo integration and taking , the kernel can be approximated as
In particular, if the kernel is real-valued; then, Equation (3) becomes
where . A side effect of (4) is that we can compute as . This means that function f can be approximated as
where is a constant. This constant makes possible to avoid some of the operations to obtain the Gram matrix.
3.1. Approximating Locally Stationary Kernel
As we know, is a stationary kernel which allows to approximate as presented in Section 3. Now, to obtain the locally stationary kernel, we would like to approximate . For this, we define :
where . Using Monte Carlo integration and taking , for , it is possible to approximate as:
To approximate the output of the locally stationary kernel, we can use Equations (3) and (5) as follows:
where and . In particular, if our kernel is real-valued, then previous equation becomes
where
and , . Thus, the advantage of representing the locally stationary kernel as Equation (6) is the possibility of computing as:
where . Given this representation, we only need to compute once, avoiding the use of total Gram Matrix representation.
Now, it is necessary to remark an interesting property of using this representation. It is possible to say that (using the Hoeddfing’s inequality [23]) almost everywhere. Given this, it is possible to obtain the following inequality: given any , and taking samples and from and respectively; then
Therefore, the proposed representation of the kernel allows to obtain a good approximation to . Furthermore, the following theorem gives a tighter bound making possible to say: Given a larger , the less likely is the possibility of having a larger .
Theorem 1.
Approximation of a locally stationary kernel.
Let be a compact subset of with diameter , and then the approximation of the kernel is given by:
Proof of Theorem 1.
Define , a locally stationary kernel and . Then, it is possible to say that . Given that is shift invariant, it is possible to define . Now, given that can be interpreted as the mean, it is possible to define . Consequently, it is possible to define . Let a compact bounded subset, it is known that and . With this in mind, it is possible to define -net that covers at most balls of radius r. Let denote the center of these T balls, and let be the Lipschitz constant of f. Therefore, we have that for all . Then, and for all i. Now, , where . Additionally, we know . Thus, it is possible to say:
Now, given that and are positive,
with and , where is the second momentum of Fourier transform of . Thus, using the Markov’s inequality,
Finally, using the Boole’s inequality we have
With this at hand, it is possible to say:
Meaning that we need to solve the following equation
where
The solution of (7) is given by . Then, plugging back this result,
After some development, it is possible to obtain:
Using this equality, we get (8) and (9).
Now, if , then . Finally:
□
3.2. Learning Locally Stationary Kernel, GaBaSR
In this section, we explain how to learn the proposed stationary kernel. This learning algorithm is based on the work presented in [18], named Bayesian Nonparametric Kernel (BaNK) algorithm. However, given its greatest representation capabilities, we propose learning a Gaussin mixture distribution to improve the performance of the algorithm. For this reason, we name this model as Gaussian Mixture Bayesian Nonparametric Kernel Learning using Spectral Representation (GaBaSR). Furthermore, to learn the Gaussian mixture, the proposed algorithm uses ideas proposed in [15], together with a different way to learn the kernel in the classification task. Additionally, one of its main advantages is the use of vague/non-informative priors, [15,24], as well as having fewer hyperparameters for learning the kernels.
3.2.1. GaBaSR Algorithm
Based in the previous ideas, we have the following high level description of the algorithm.
- Learn all the parameters for the Gaussian mixture :
- Let be the current parameters of the Gaussian Mixture Model (GMM), where is the prior probability of the kth component, is the mean and is the covariance matrix of the kth component, then the GMM is given by , here the output will be the new sample parameters for the GMM .
- Take M samples from , i.e., for the spectral representation.
- Here the input are the parameters of the GMM, and the frequencies , and the output will be the new frequencies sampled.
- Approximate the kernel as
- Predict the new samples:
- (a)
- If the task is a regression use:
- (b)
- If the task is a classification use:
In this work, we use a Markov Chain Monte Carlo (MCMC) algorithm, the Gibbs sampler [25], to learn and predict new inputs. The final entire process is described in the following subsections.
3.2.2. Learning the Gaussian Mixture
In order to learn the parameters and of the Gaussian mixture, we take the following steps:
- First sample :indicates the component of the Gaussian Mixture from which the random frequency is drawn.For do:
- (a)
- The element belongs to class with probability:
- (b)
- The element belongs to an unrepresented class, with probability:where the parameters and are sampled from their priors,where and are vague/non-informative priors.
- Second sample and :For , sample and from:
3.2.3. Sampling to approximate the kernel
As we established earlier, the kernel can be represented by:
where , and is a sampled from the learned Gaussian Mixture. In order to approximate the kernel, for each random representation, we take a candidate frequency with probability , where
Now, if the task is a regression, then Equation (10) is used. With classification, Equation (11) is used. Then, we take a random number and accept if ; otherwise reject . For this, it is clear that we need to sample from:
In order to compute , it is necessary to identify what type of task is being solved, regression or classification.
- In the case of a regression:where
- In the classification task, an approximation of the logistic regression is used,where . Thus, the likelihood is approximated by:where,
- Computing : the following criteria is used to accept a sample with probability r:
3.2.4. Learning Locally Stationary Kernels
In order to learn locally stationary kernels, we use a similar process, but we compute by using Equation (6) instead of Equation (4). Equation (6) needs the variables (approximating the ) and (approximation for ). To learn the variables in we use the algorithm showed; however to learn the variables to approximate , we approximate as a infinite Gaussian mixture. This means that we need to learn the variables and that approximate the function . Learning these variables is very similar on how we learn them from the stationary kernel with a slight modification:
- Sample : Sampling is analogous to learning the stationary kernel but with instead of .
- Sample : This sample is analogous to the previous section but with instead of .
- Sample : To sample , we sample fromIn order to compute , we use as a locally stationary kernel instead of a stationary kernel. This simple change allows to add more learning capabilities to GaBaSR.
3.2.5. Complexity of GaBaSR
- Complexity of sampling all : The complexity of sampling one is . Thus, the complexity of sampling all for is bounded by , where d is the dimension of the input vectors, M is the number of samples to approximate the kernel and K is the number of Gaussian’s found by the algorithm.
- Complexity of sampling all and :
- -
- Complexity of computing : To take a sample we need to compute which takes . Also, we need to compute which takes , so the complexity is bounded by .
- -
- Complexity of computing : To take a sample we need to compute which takes . After after that we need to compute the inverse of a matrix of which takes , so this step is bounded by .
- -
- Complexity of computing both and is bounded by .
We need to take K samples, so sample all and is bounded by . - Complexity of : The complexity of computing (doesn’t matter if it is a regression or classification task) is bounded by . Since the complexity of computing the matrix is ; then, the complexity of computing is . This means that the complexity of taking M samples ( is bounded by .
- Complexity of one swap (loop) of the algorithm: We sum the three complexities and we have: because .
- Complexity of s swaps (loops) of the algorithm: If we make s swaps, then the complexity of all the GaBaSR is bounded by .
4. Experiments
In this work, the experiments are performed without data cleaning i.e. no normalization or removal of outliers is done. Additionally, we use vague/non-informative priors to test the robustness of GaBaSR. We use the following variables , where is the identity matrix of dimension .
Using non-informative priors together with the fact that there is no need of prepossessing the data, can be seen as one of the many the advantage of GaBaSR. Finally, the main idea of the kernel methods is to give more power to linear machines via the kernel trick. For this reason, we designed the experiments to compare GaBaSR with pure linear machines. Unfortunately, when trying to collect the original datasets by Oliva et al. [18], we found that they are no longer available online. Thus, the comparison between GaBaSR and Oliva’s algorithm could not be performed.
4.1. Classification
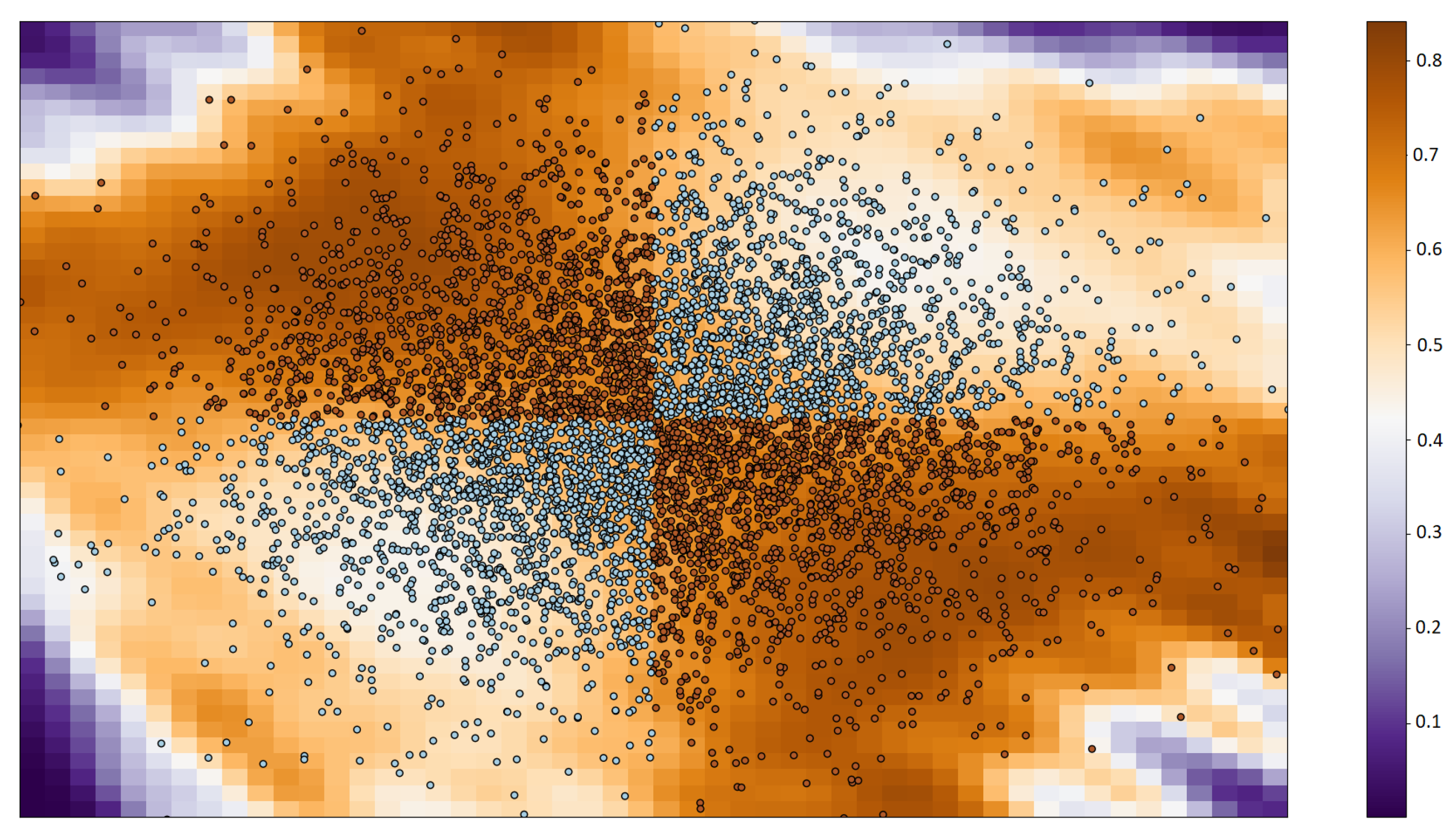
The first dataset is the XOR problem in 2D. We set the number of samples to . After five swaps with 300 frequencies (M), the proposal got an AUC of 0.98. The result of this experiment is shown in Figure 1.
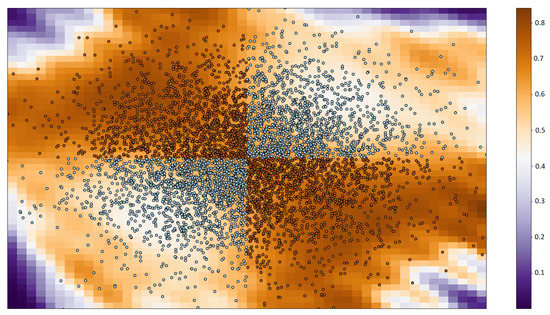
Figure 1.
The XOR problem with the probability of belonging to class 1 (orange). If the probability is more than 0.5, then the sample belongs to class 1 otherwise belongs to class 2.
All the results of the GaBaSR algorithm uses 500 samples (M) and 5 swaps each one. For classification problem we use some small datasets, Breast Cancer, Credit-g, Blood Transfusion, Electricity, Egg-eye-state and Kr vs Kp. The breast cancer dataset it comes from the UCI repository [26] dataset, this dataset is the breast cancer wisconsin dataset. The Credit-g dataset comes from the UCI repository [26] and classifies people by a set of attributes as good or bad credit risk. The Electricity Dataset we downloaded from openml.org and contains data from the Australian New South Wales. Dataset egg-eye-state we downloaded from UCI, this describes if the eye is closed (1) or open (0). Kr Vs Kp dataset was downloaded from UCI, is the King Rook vs King Pawn and it’s from the King+Rook’s side to move and the classification is see if win or not win.
Table 1, Table 2 and Table 3 show the results when we try to solve the problem using perceptron, SVM and GaBaSR, respectively. From those tables, we can see that the in the problems of Kr vs. Kp and Electricity GaBaSR has "similar" AUC to SVM but it is important to notice that in blood transfusion GaBaSR performs better than the perceptron and SVM.

Table 1.
Results of the Perceptron.
Table 2.
Results SVM Classification.
Table 3.
Results of GaBaSR Classification.
In other words, if we compare Table 3 with Table 2, it is possible to observe that the results, in general, for SVM Classification are better than for GaBaSR Classification. AUC equal to 0.5 indicates that the classifier is random, so it does not fulfil its function. Comparing Table 3 with Table 2, we can conclude that SVM Classification works properly for all tested datasets except Blood Transfusion, and GaBaSR Classification works properly only for Kr vs. Kp and Electricity. Results for Blood Transfusion obtained by GaBaSR are better than for SVM but still not satisfactory. A bad result is also a result that has its value.
In general we had a good accuracy, in most of the cases we had an accuracy above 0.8. For example in the dataset for the breast cancer, we had an accuracy of 0.89, which in general is a good accuracy. In the dataset credit-g we had 0.91 of accuracy using only 500 frequencies in 5 swaps.
4.2. Regression
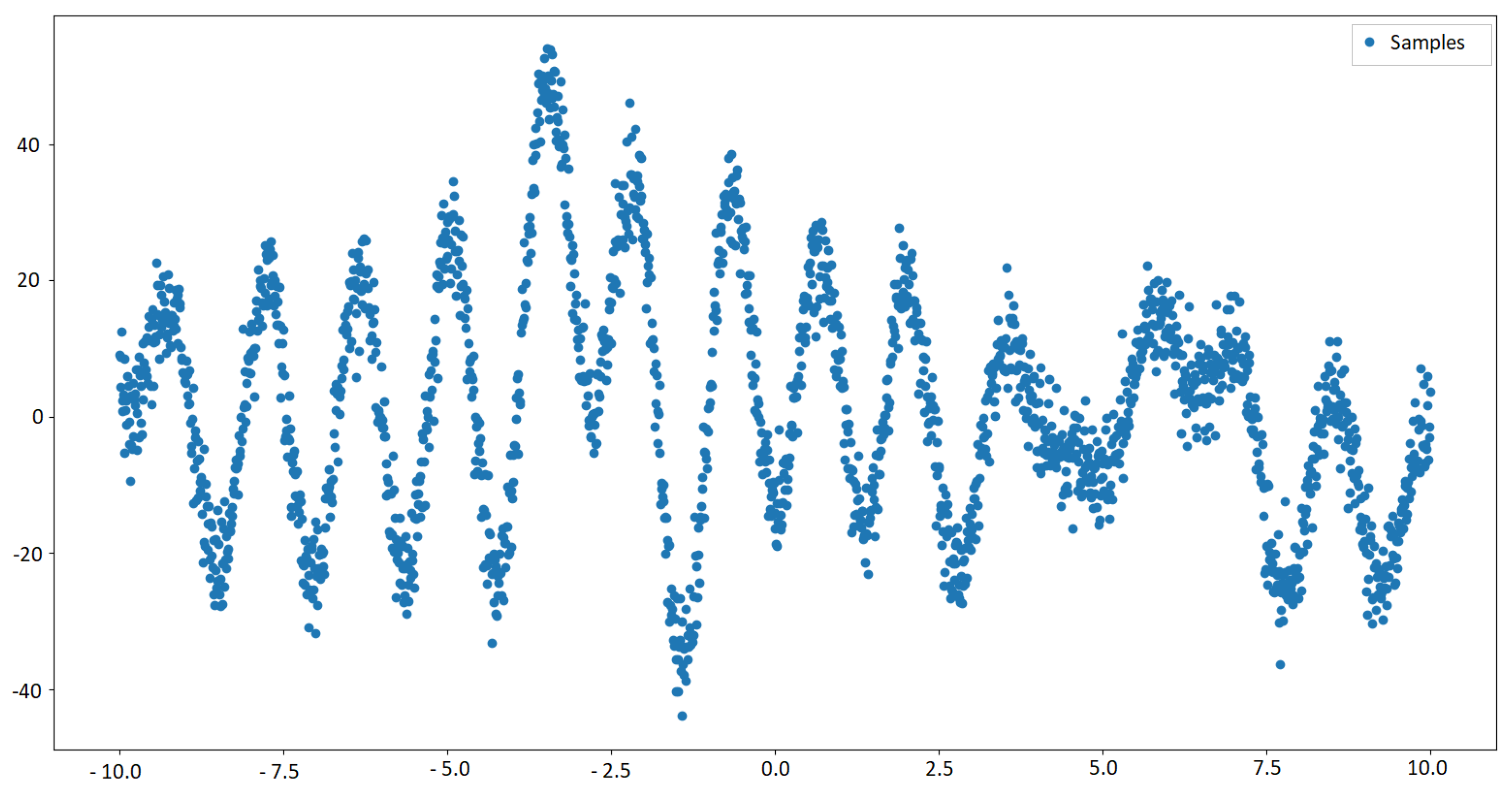
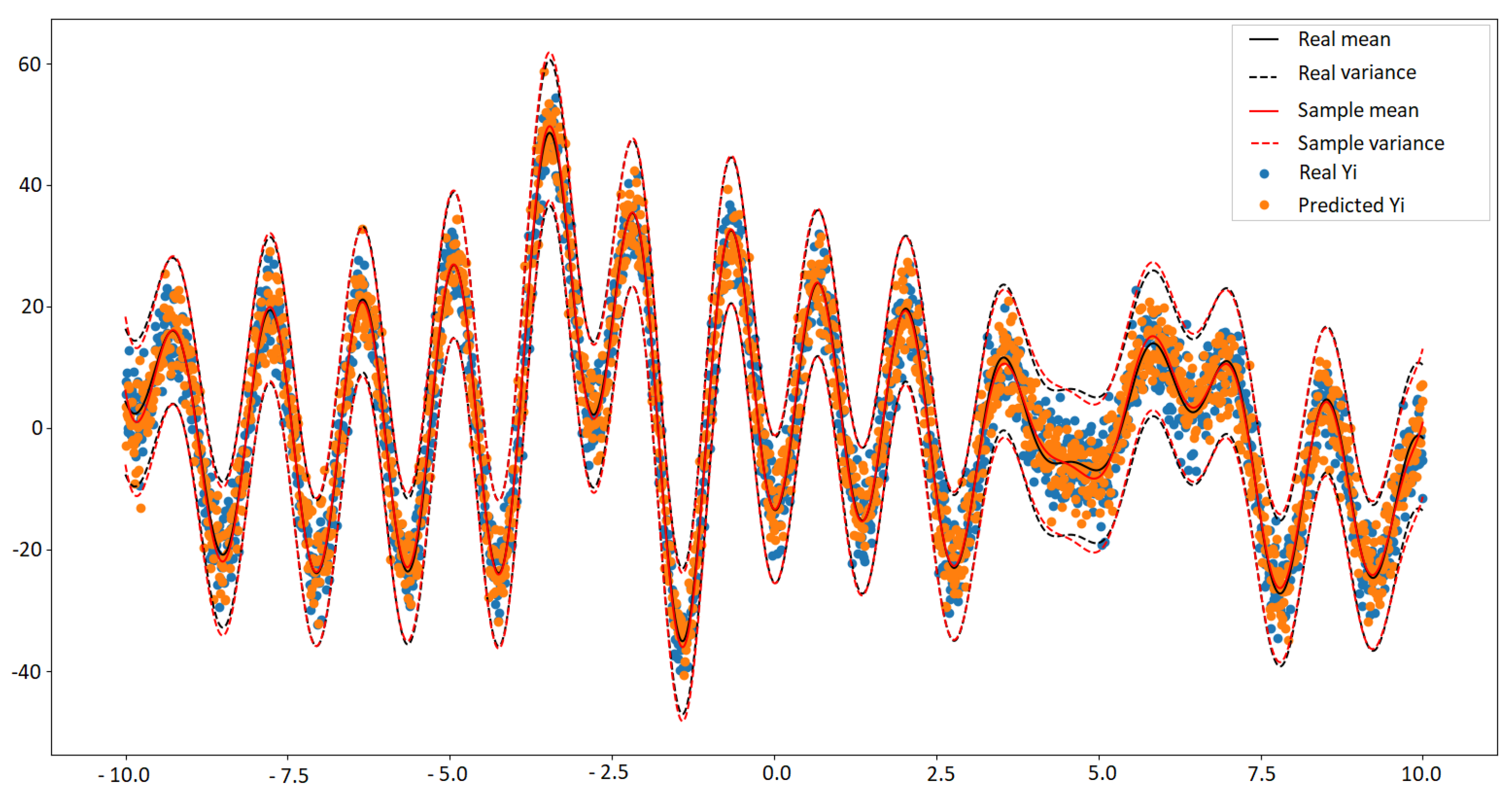
For the regression experiments, we use a synthetic data set in our regression attempt. For this, samples are taken from the Gaussian Mixture distribution shown in Equation (12). After that, are set. In fact, the number 501 is because the extended vector is used, which takes samples from , where represents the random features from , i.e. . Furthermore, an instance of this problem is shown in Figure 2. Also, 250 samples and vague/non-informative prior to learn the function are used, and the result is shown in Figure 3.
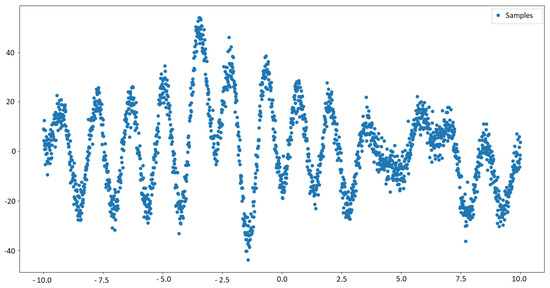
Figure 2.
An instance of the samples taken from Equation (12).
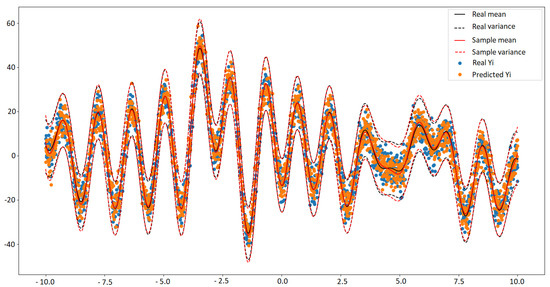
Figure 3.
The real vs. predicted using GaBaSR.
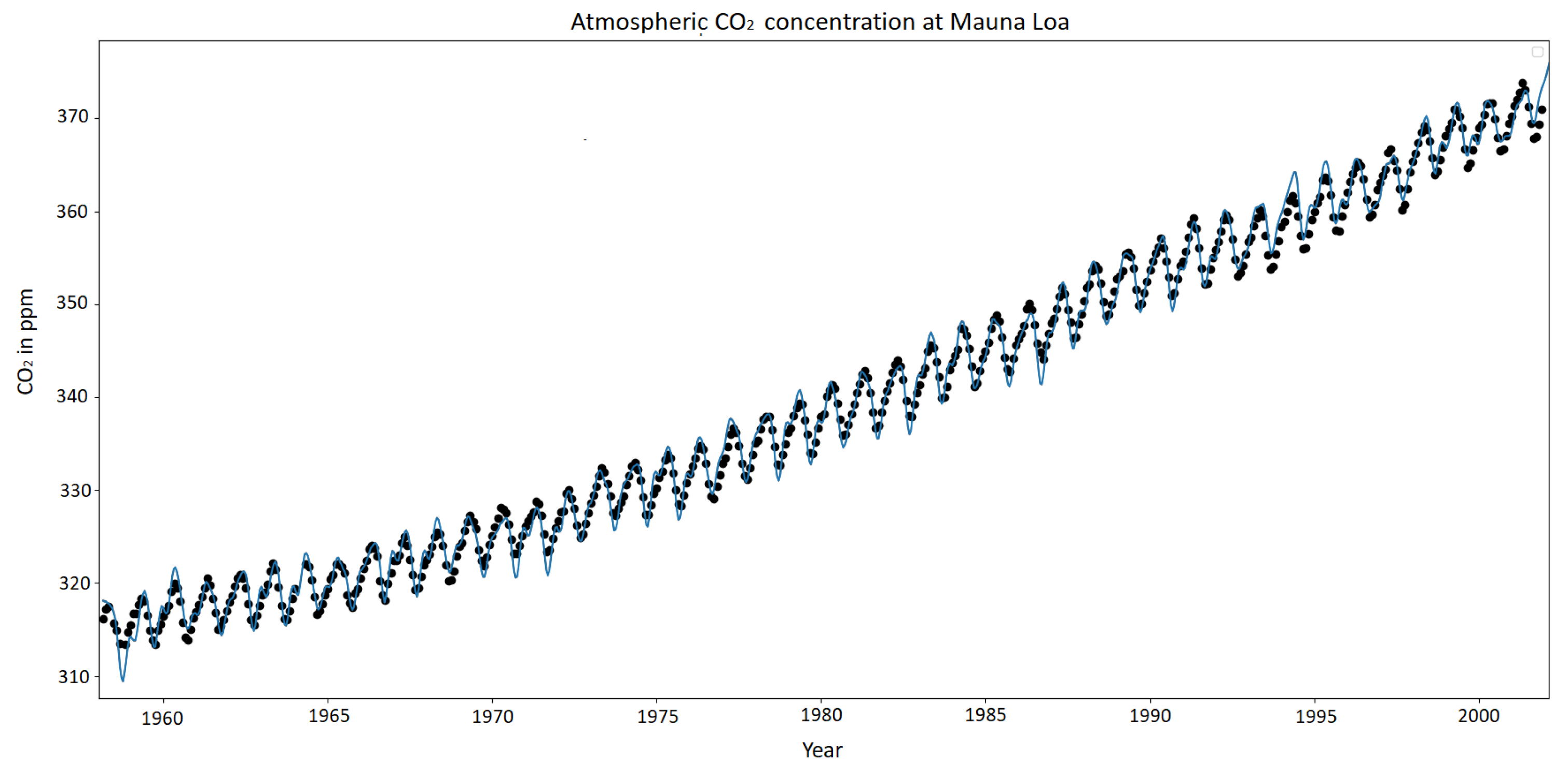
All the results of the GaBaSR algorithm uses 500 samples (M) and 5 swaps each one. For regression problems we use some small datasets, Mauna LOA CO, California Houses, Boston house-price, and Diabetes. The Mauna LOA CO [29] from the global monitoring laboratory this collects the information of the monthly mean CO, as we can see from Figure 4, this data it is stationary, has some repetitions and increments. The California Houses is a set of 20,640 rows with 8 columns. The Boston house price dataset was collected in 1978 from various suburbs in Boston. Diabetes Dataset has ten variables and the progression of the disease one year after.
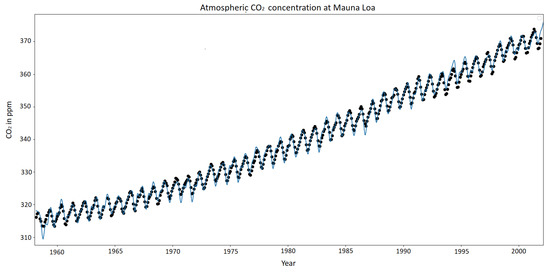
Figure 4.
Mauna LOA CO from 1958 to 2001 and the prediction.
In this section we show three tables of results, Table 4 shows the results of our algorithm. Table 5 and Table 6 we present the results of the linear regression and the Support Vector Machine with linear kernel, respectively.
Table 4.
Results GaBaSR Regression.
Table 5.
Results of Linear Regression.
Table 6.
Results Linear Regression SVM.
In this subsection, the experiments are performed with simple data and the result of a simple linear regression are shown. The results are shown in Table 4 and Table 5.
As it can be seen, an important result is the given by the Mauna LOA CO dataset. This dataset contains data from the year 1958 to 2001. Thus, for this experiment the algorithm is trained with and performing five swaps. After the model has been trained, to learn stationary kernels, it is possible to asses the performance of the model. For example, the achieved MSE is 0.6052 which helps at the estimation ot the CO outputs. For example, at the sample , we have prediction where the real measure for this value is . The total results of Mauna LOA CO are shown in Figure 4 and Table 4.
We use the following datasets: (1) Mauna LOA CO from [29], (2) California houses from [30], (3) Boston house-price from [30] and Diabetes from [30]
5. Conclusions
Although GaBaSR’s result are promising, there are still quite a lot of work to do. For example, sampling the is quite slow, and there is a need to update the matrix for only one sample. Oliva et al. [18] states that this can be done using low-rank updates. However, he does not present any procedure to perform such task, the low-rank updates are being consider for the next phase of GaBaSR. Thus, it is necessary to research how many samples M are required in order to obtain a low rank approximation.
In the experiments, it is possible to observe that GaBaSR is more accurate when performing a classification task rather than a regression task. This is an opportunity to improve the regression model. It means that the regression model needs more research to improve its performance or perhaps that a different model to learn the regression task is needed.
Author Contributions
Conceptualization, L.R.P.-L. and A.M.-V.; Methology, L.R.P.-L. and R.O.G.-M.; software L.R.P.-L. and A.G.; validation, R.O.G.-M.; formal analysis, L.R.P.-L. and A.M.-V.; resources, A.M.-V.; data curation, A.G.; writing—original draft preparation, L.R.P.-L. and R.O.G.-M.; writing—review and editing, A.M.-V. and A.G.; supervision, A.M.-V. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
All the data was cited and can be downloaded with their respective citation.
Acknowledgments
The authors wish to thank the The National Council for Science and Technology (CONACyT) in Mexico and Escuela Militar de Mantenimiento y Abastecimiento, Fuerza Aérea Mexicana Zapopan.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AUC | Area Under the Curve |
| MSE | Mean Squared Error |
| SVM | Support Vector Machine |
| Coefficient of determination | |
| MKL | Multiple Kernel Learning |
| SDP | Semi-Definite Programming |
| SMO | Sequential Minimal Optimization |
| BaNK | Bayesian Nonparametric Kernel |
| GaBaSR | Gaussian Mixture Bayesian Nonparametric Kernel Learning using Spectral Representation |
| GMM | Gaussian Mixture Model |
| MCMC | Markov Chain Monte Carlo |
| UCI | University of California, Irvine |
References
- Smola, A.J.; Schölkopf, B. Learning with Kernels; Citeseer: Princeton, NJ, USA, 1998; Volume 4. [Google Scholar]
- Soentpiet, R. Advances in Kernel Methods: Support Vector Learning; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Anand, S.S.; Scotney, B.W.; Tan, M.G.; McClean, S.I.; Bell, D.A.; Hughes, J.G.; Magill, I.C. Designing a kernel for data mining. IEEE Expert 1997, 12, 65–74. [Google Scholar] [CrossRef]
- Schölkopf, B.; Smola, A.; Müller, K.R. Kernel principal component analysis. In Proceedings of the International Conference on Artificial Neural Networks, Lausanne, Switzerland, 8–10 October 1997; pp. 583–588. [Google Scholar]
- Zien, A.; Rätsch, G.; Mika, S.; Schölkopf, B.; Lengauer, T.; Müller, K.R. Engineering support vector machine kernels that recognize translation initiation sites. Bioinformatics 2000, 16, 799–807. [Google Scholar] [CrossRef] [PubMed]
- Tipping, M.E. The relevance vector machine. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2000; pp. 652–658. [Google Scholar]
- Junli, C.; Licheng, J. Classification mechanism of support vector machines. In Proceedings of the WCC 2000-ICSP 5th International Conference on Signal Processing Proceedings 16th World Computer Congress, Beijing, China, 21–25 August 2000; Volume 3, pp. 1556–1559. [Google Scholar]
- Bennett, K.P.; Campbell, C. Support vector machines: Hype or hallelujah? Acm Sigkdd Explor. Newsl. 2000, 2, 1–13. [Google Scholar] [CrossRef]
- Gönen, M.; Alpaydın, E. Multiple kernel learning algorithms. J. Mach. Learn. Res. 2011, 12, 2211–2268. [Google Scholar]
- Lanckriet, G.R.; Cristianini, N.; Bartlett, P.; Ghaoui, L.E.; Jordan, M.I. Learning the Kernel Matrix with Semidefinite Programming. J. Mach. Learn. Res. 2004, 5, 27–72. [Google Scholar]
- Hoi, S.C.; Jin, R.; Lyu, M.R. Learning Nonparametric Kernel Matrices from Pairwise Constraints. In Proceedings of the 24th International Conference on Machine Learning ACM, Corvallis, OR, USA, 20–24 June 2007; pp. 361–368. [Google Scholar]
- Cvetkovic, D.M.; Doob, M.; Sachs, H. Spectra of Graphs; Academic Press: New York, NY, USA, 1980; Volume 10. [Google Scholar]
- Platt, J. Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines; Microsoft: Redmond, WA, USA, 1998. [Google Scholar]
- Bach, F.R.; Lanckriet, G.R.; Jordan, M.I. Multiple Kernel Learning, Conic Duality, and the SMO Algorithm. In Proceedings of the Twenty-First international Conference on Machine Learning ACM, Banff, AB, Canada, 4–8 July 2004; p. 6. [Google Scholar]
- Williams, C.K.; Rasmussen, C.E. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Rahimi, A.; Recht, B. Random features for large-scale kernel machines. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 3–5 December 2007; pp. 1177–1184. [Google Scholar]
- Ghiasi-Shirazi, K.; Safabakhsh, R.; Shamsi, M. Learning translation invariant kernels for classification. J. Mach. Learn. Res. 2010, 11, 1353–1390. [Google Scholar]
- Oliva, J.B.; Dubey, A.; Wilson, A.G.; Póczos, B.; Schneider, J.; Xing, E.P. Bayesian Nonparametric Kernel-Learning. In Proceedings of the Artificial Intelligence and Statistics, Cadiz, Spain, 9–11 May 2016; pp. 1078–1086. [Google Scholar]
- Rasmussen, C. The infinite Gaussian mixture model. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2000; pp. 554–560. [Google Scholar]
- Genton, M. Classes of kernels for machine learning: A statistics perspective. J. Mach. Learn. Res. 2001, 2, 299–312. [Google Scholar]
- Bochner, S. Harmonic Analysis and the Theory of Probability; California University Press: Berkeley, CA, USA, 1955. [Google Scholar]
- Silverman, R. Locally stationary random processes. IRE Trans. Inf. Theory 1957, 3, 182–187. [Google Scholar] [CrossRef]
- Hoeffding, W. Probability inequalities for sums of bounded random variables. In The Collected Works of Wassily Hoeffding; Springer: Berlin, Germany, 1994; pp. 409–426. [Google Scholar]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Dunson, D.B.; Vehtari, A.; Rubin, D.B. Bayesian Data Analysis; Chapman and Hall/CRC: Boca Raton, FL, USA, 2013. [Google Scholar]
- Geman, S.; Geman, D. Stochastic relaxation, Gibbs distributions, and the Bayesian restoration of images. IEEE Trans. Pattern Anal. Mach. Intell. 1984, 6, 721–741. [Google Scholar] [CrossRef] [PubMed]
- Dua, D.; Graff, C. UCI Machine Learning Repository. Open J. Stat. 2017, 10. [Google Scholar]
- Yeh, I.C.; Yang, K.J.; Ting, T.M. Knowledge discovery on RFM model using Bernoulli sequence. Expert Syst. Appl. 2009, 36, 5866–5871. [Google Scholar] [CrossRef]
- Gama, J. Electricity Dataset. 2004. Available online: http://www.inescporto.pt/~{}jgama/ales/ales_5.html (accessed on 6 August 2019).
- Carbon, D. Mauna LOA CO2. 2004. Available online: https://cdiac.ess-dive.lbl.gov/ftp/trends/CO2/sio-keel-flask/maunaloa_c.dat (accessed on 6 August 2019).
- Buitinck, L.; Louppe, G.; Blondel, M.; Pedregosa, F.; Mueller, A.; Grisel, O.; Niculae, V.; Prettenhofer, P.; Gramfort, A.; Grobler, J.; et al. API design for machine learning software: Experiences from the scikit-learn project. In Proceedings of the ECML PKDD Workshop: Languages for Data Mining and Machine Learning, Prague, Czech Republic, 23–27 September 2013; pp. 108–122. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).