
Human Pose Estimation Using MediaPipe Pose and Optimization Method Based on a Humanoid Model


Abstract
:1. Introductions
- In order to simulate and estimate a human-like pose, a full-body humanoid robot model with lumbar joints was constructed including effects of camera view angle and distance.
- Instead of solving the inverse kinematics of a humanoid for a given 2D skeletal model, the heuristic optimization method uDEAS directly adjusts the camera-relative body angles and intra-body joint angles to match the 2D projected humanoid model to the 2D skeletal model.
- The depth ambiguity problem can be solved by adding a loss function deviation of center of mass from the center of the supporting foot (feet) and appropriate penalty functions for the ranges of natural joint angle rotations.
- The proposed 3D human body pose estimation system showed an average performance of 0.33 s per frame using an inexpensive SBC without GPU.
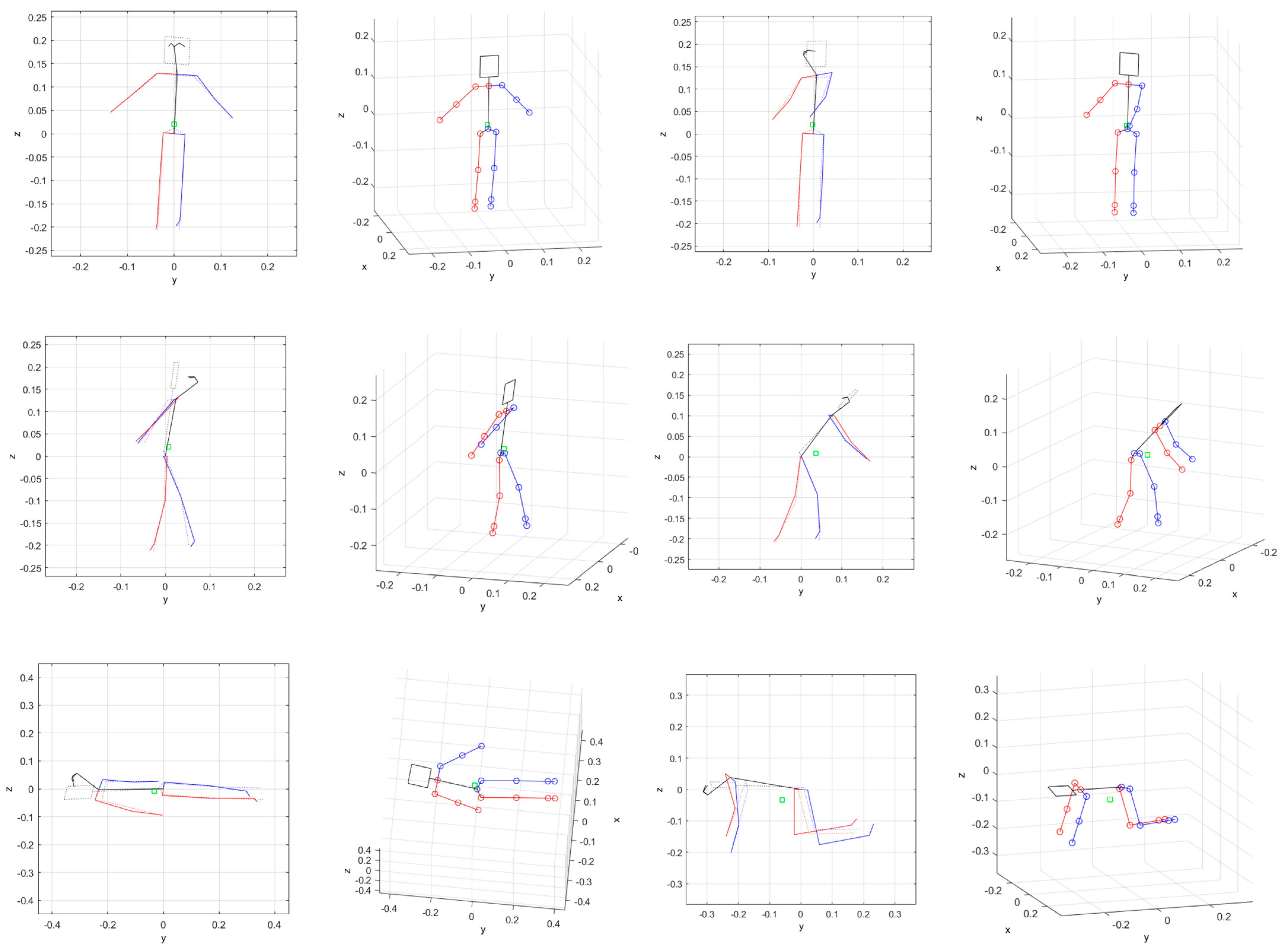
- We find that rare poses resulting from falling activity were well estimated in the present system. This may be difficult with deep learning methods due to the lack of training data.
2. Pose Estimation Approach
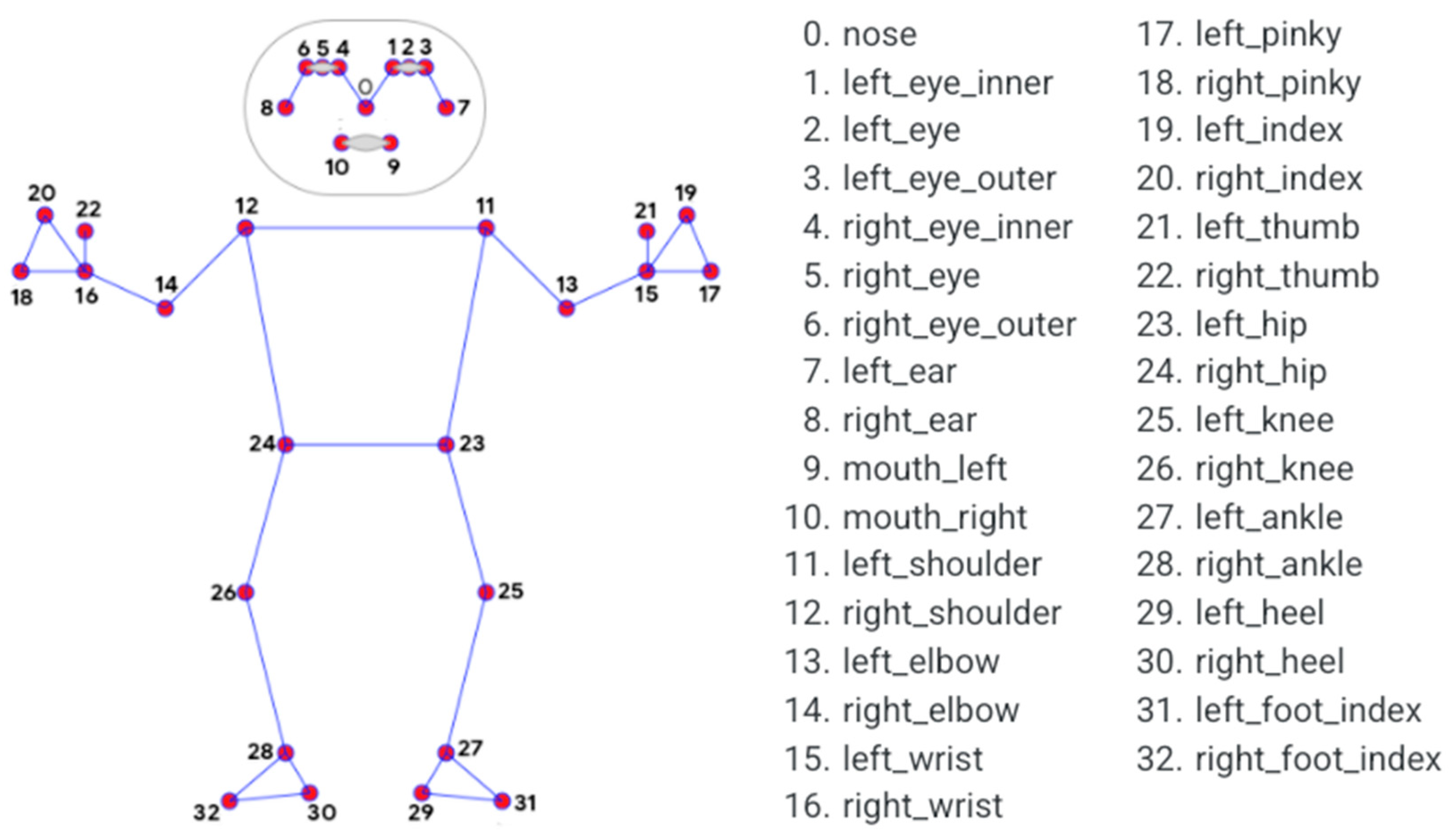
2.1. MediaPipe Pose
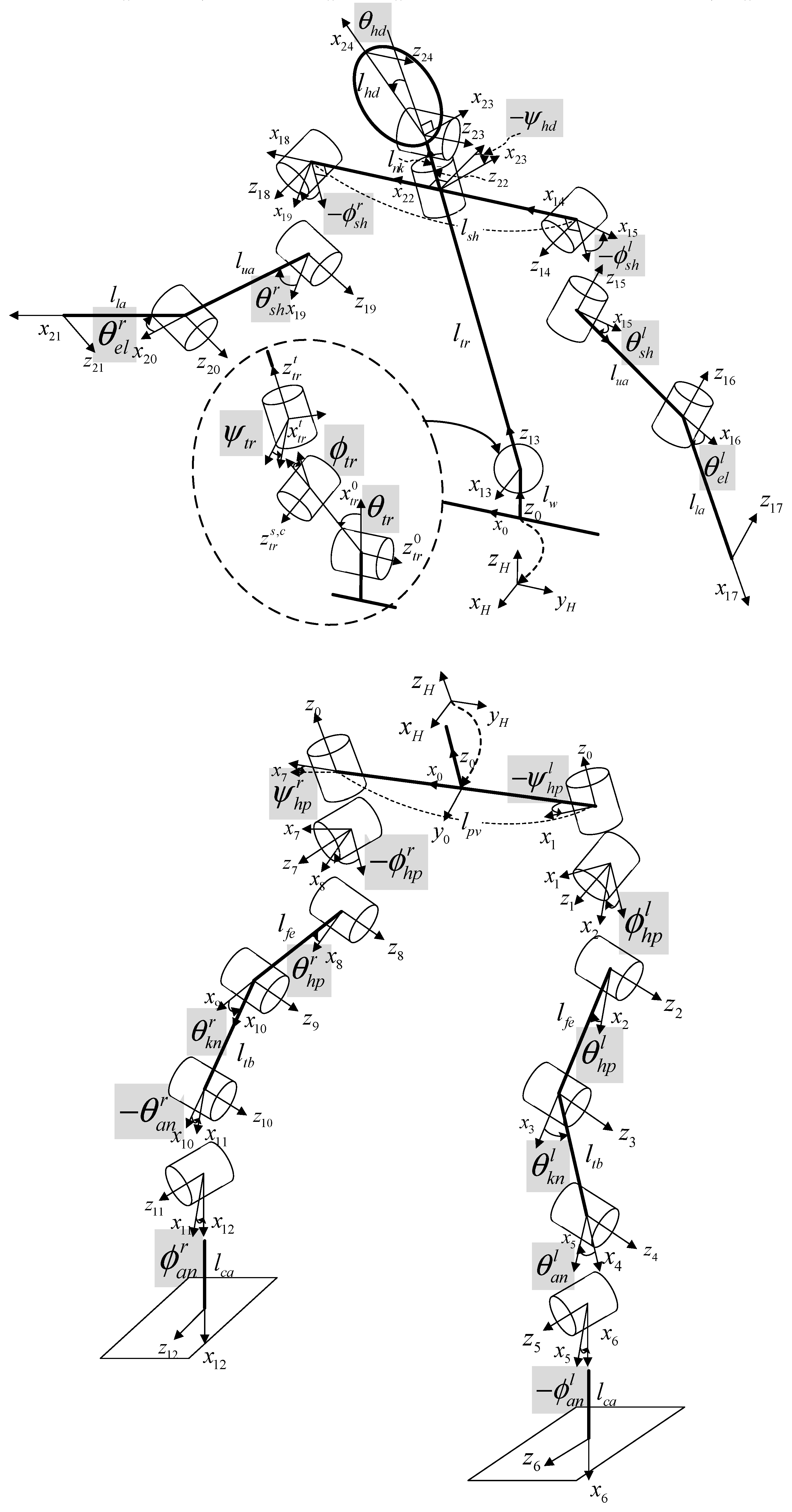
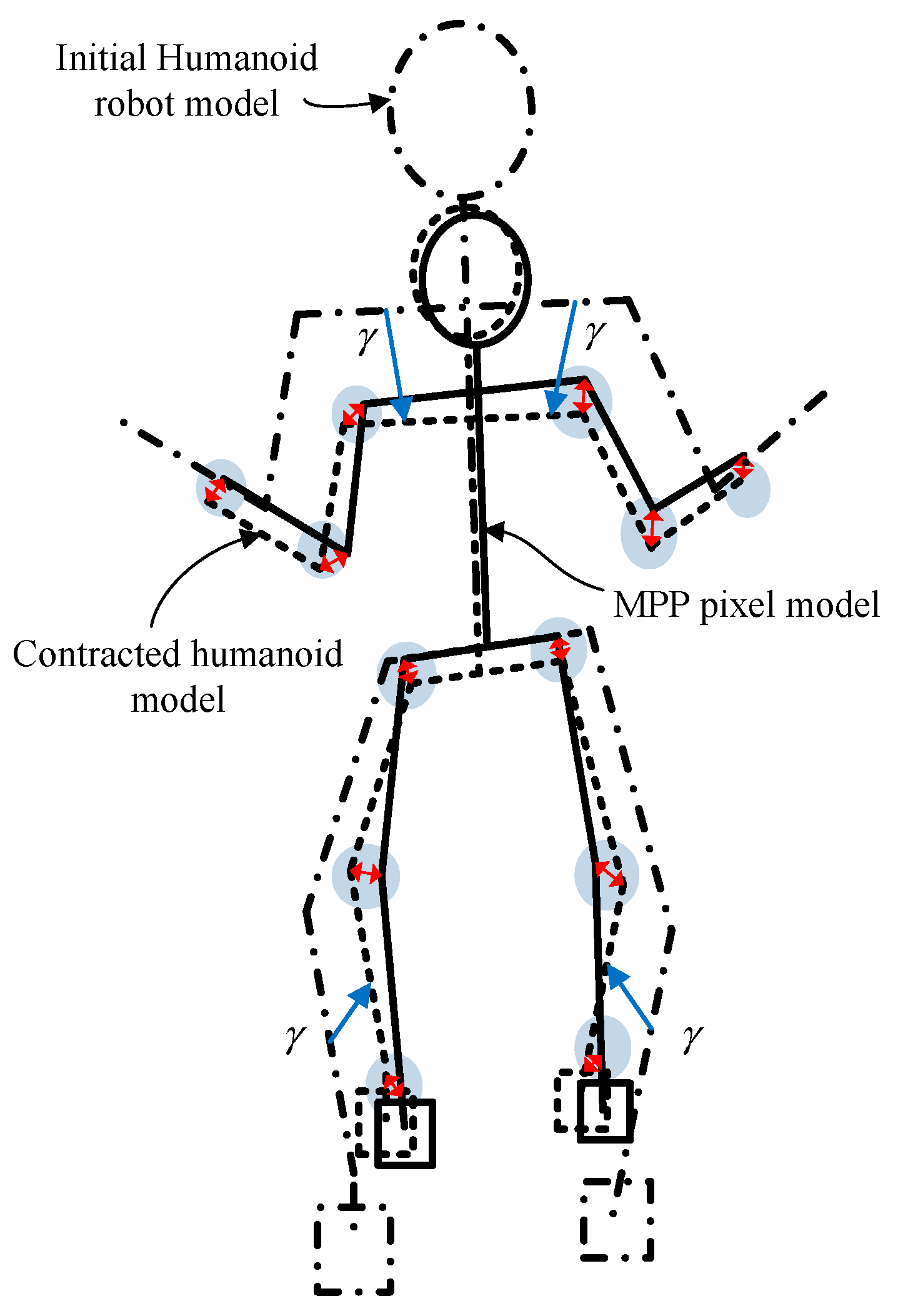
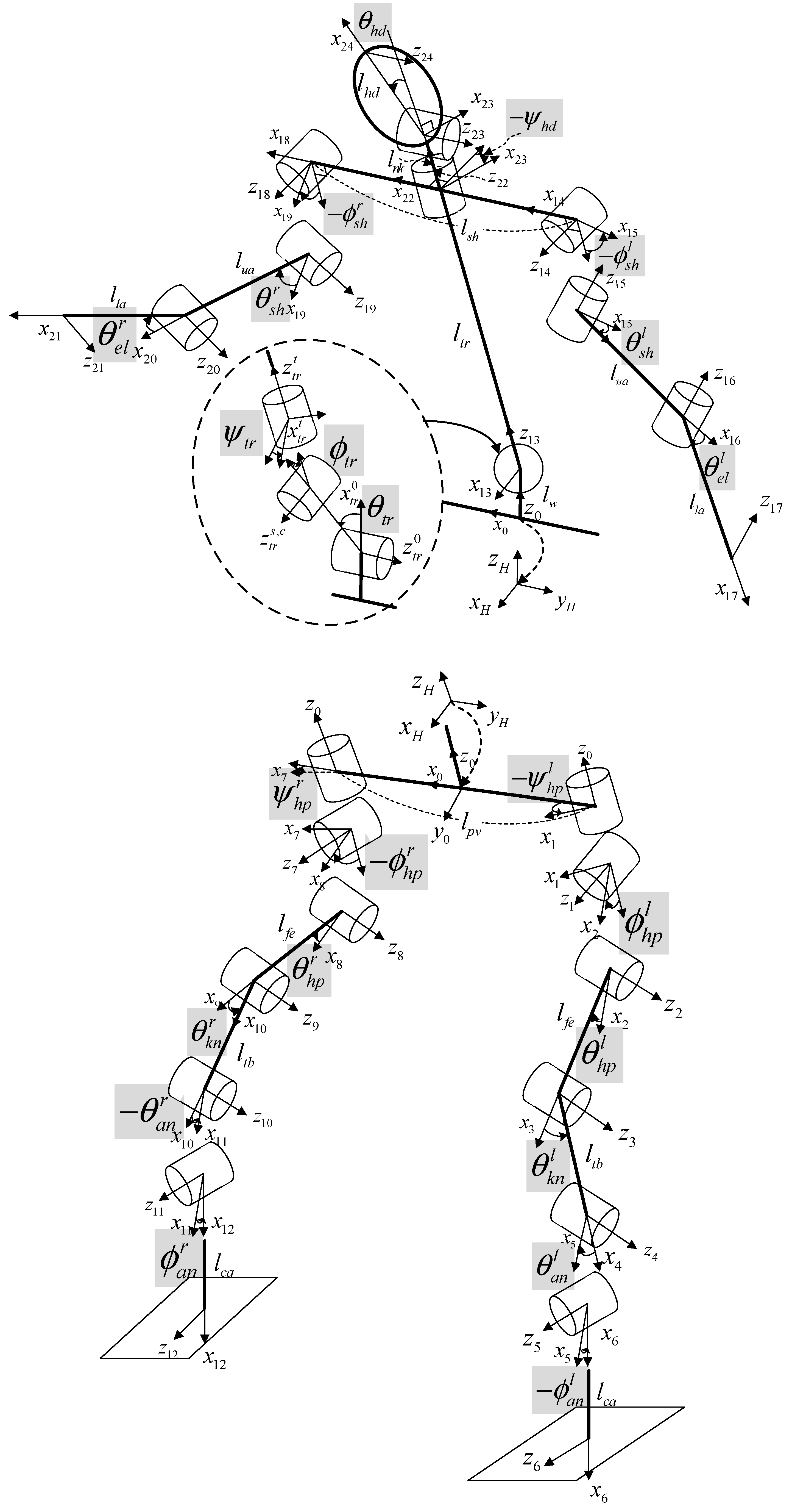
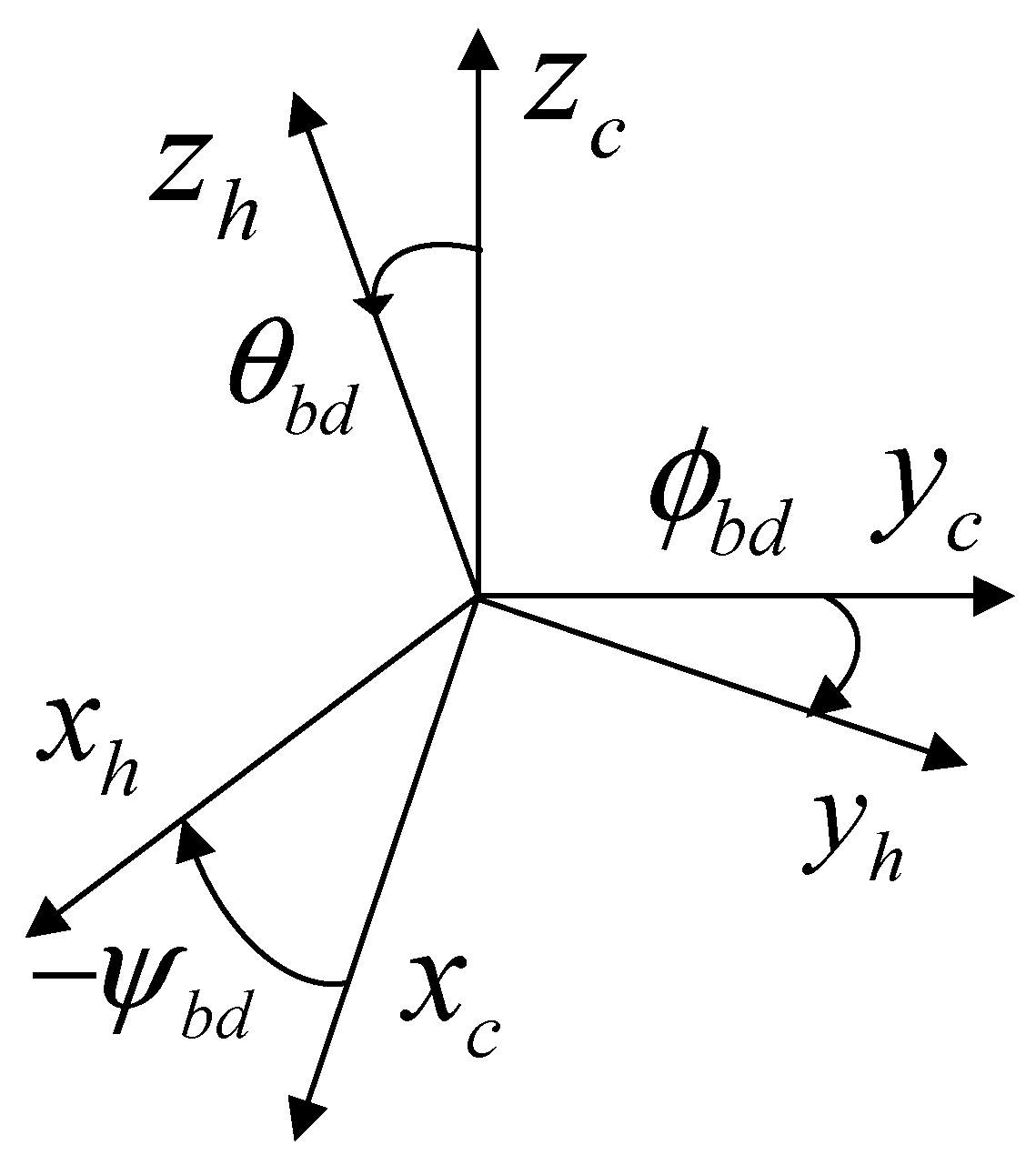
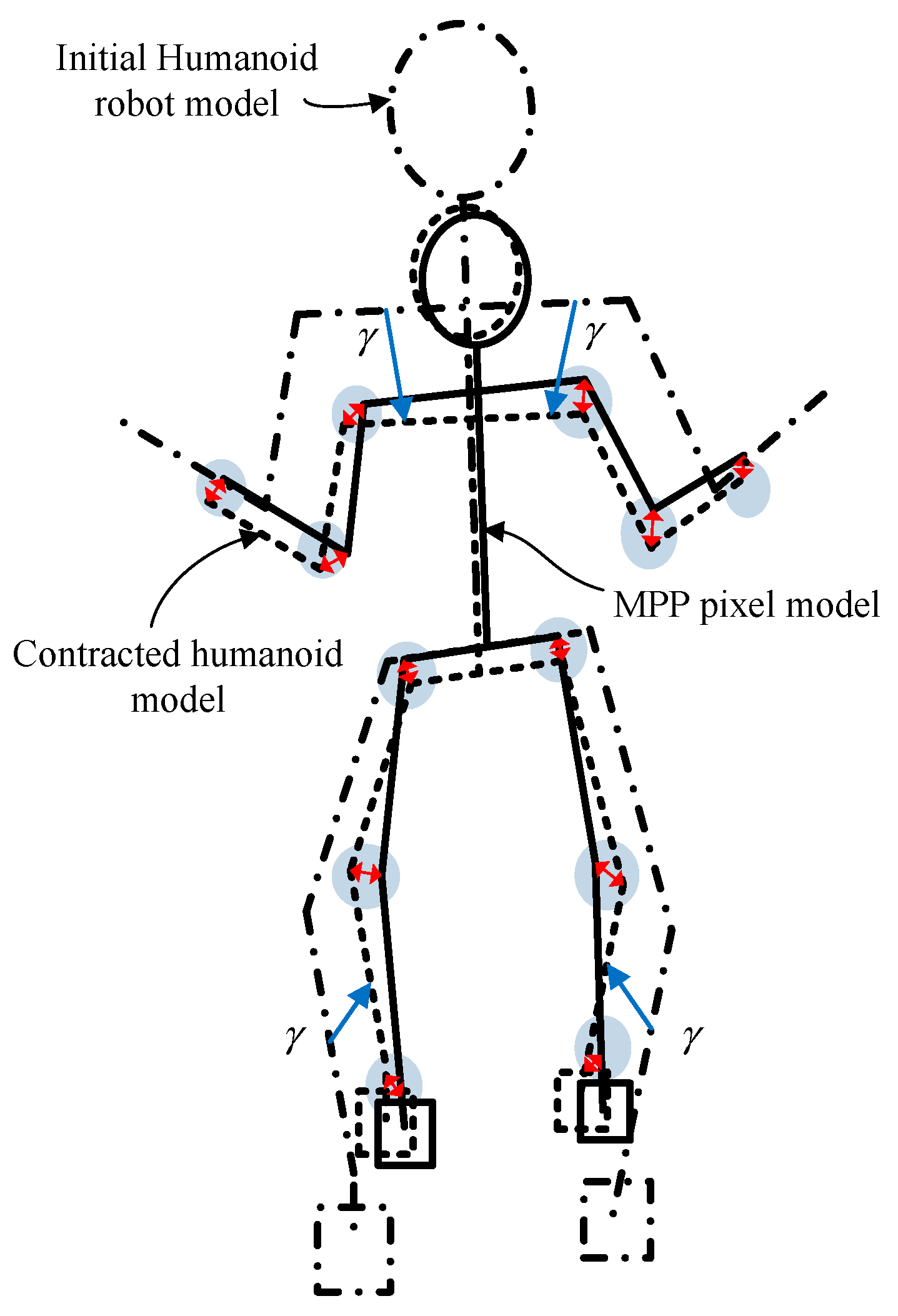
2.2. Humanoid Robot Model
- Locating the origin of the reference frame at the center of the body, i.e., the root joint, to create arbitrary poses.
- Adding three DoF lumbar spine joints at the center of the pelvis to create poses where only the upper body moves separately.
- Redefining the rotational polarity of all joint variables to match the Vicon motion capture system for better interoperability of the joint data measured by the system.
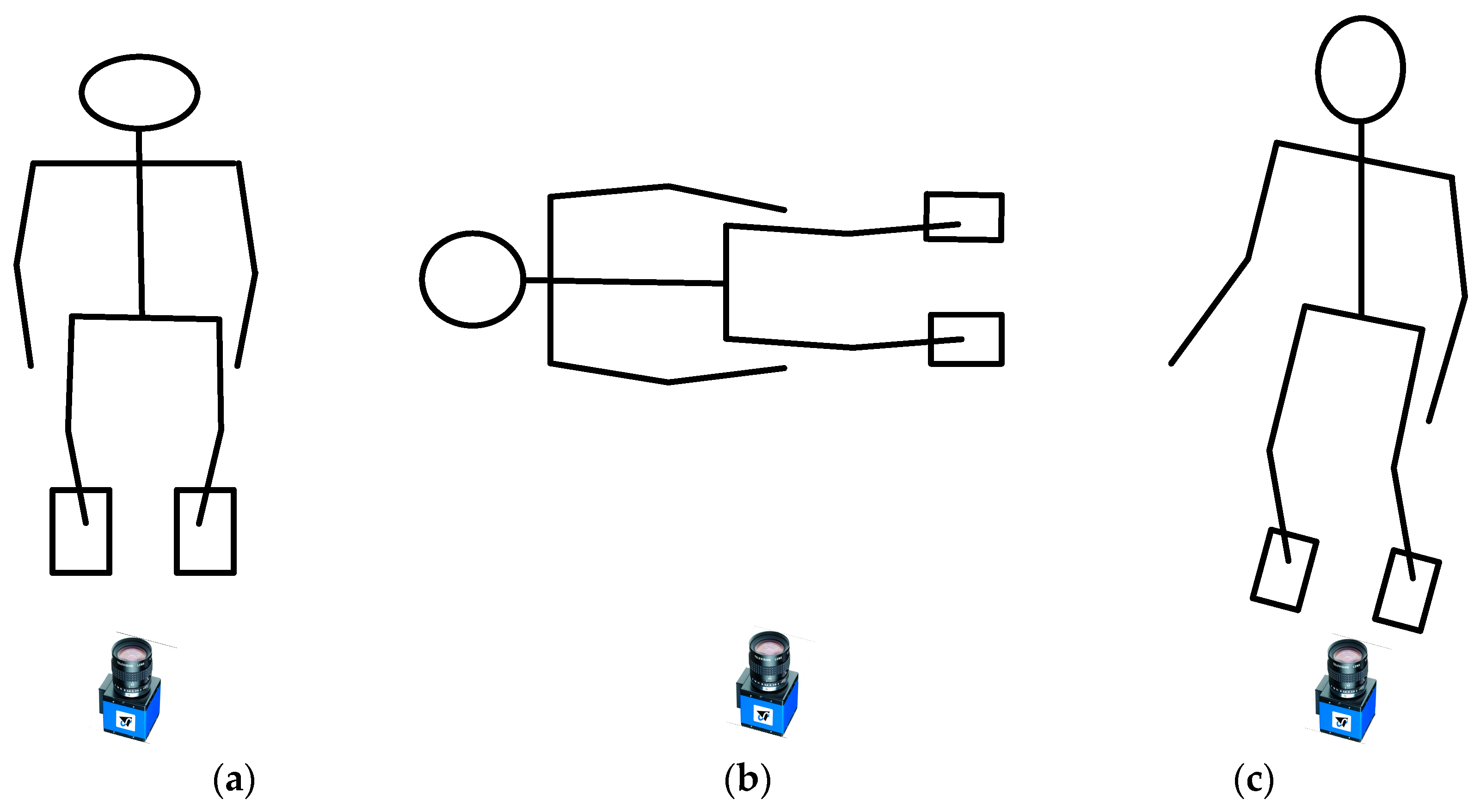
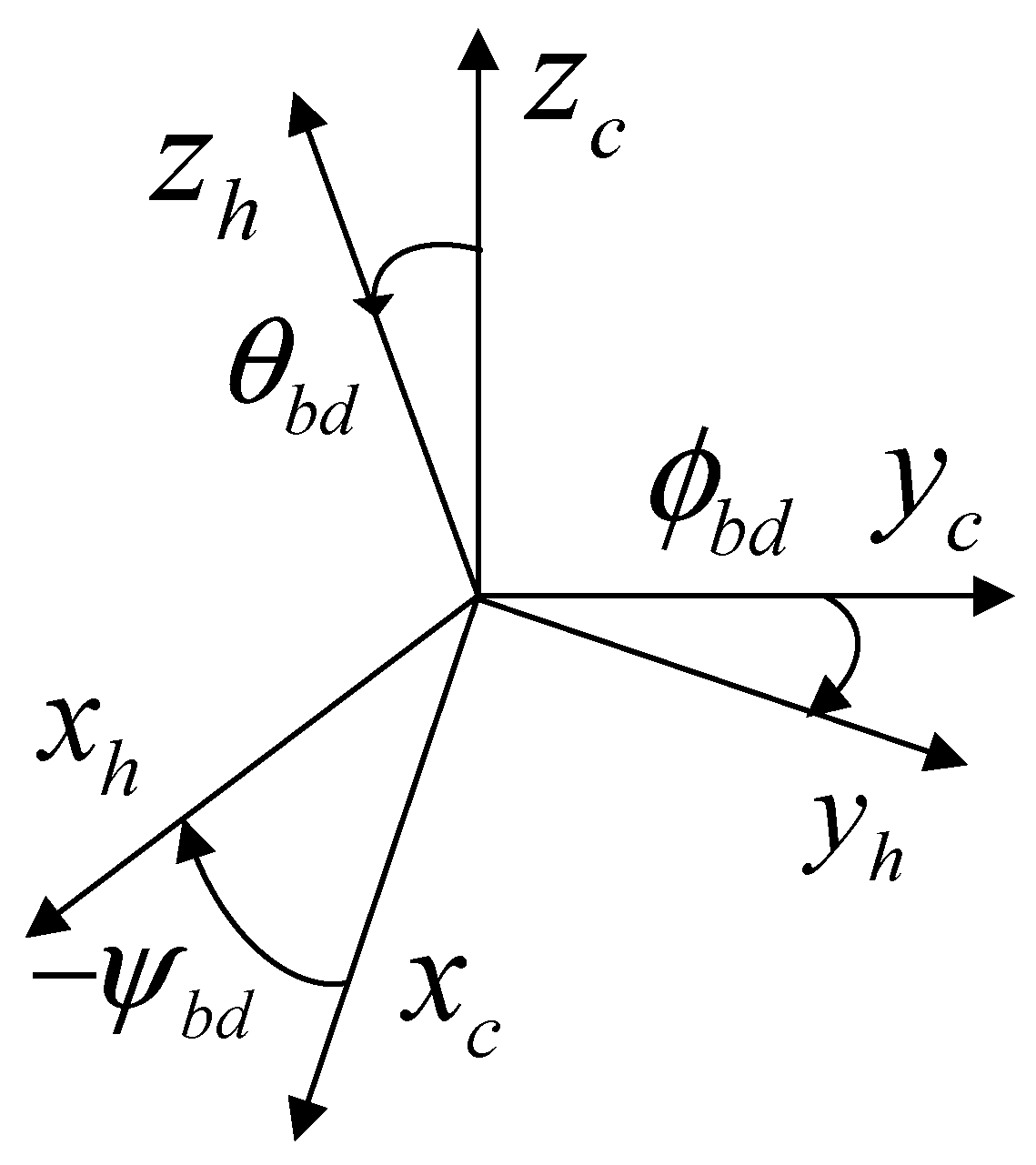
2.3. Reflecting Camera Effect
2.4. Fast Global Optimization Method
- Step 1. Initialization of new restart: Make an binary matrix which elements are randomly chosen binary digits. The row length index m is set . The optimization variable vector is .
- Step 2. Start the first session with .
- Step 3. BSS: From the current best matrix , the binary vector of the -th row is selected asAttach 0 or 1 as a new LSB of the row vector, which yieldsThen, these strings are decoded into real values and replaced with the jth variable of the current best optimization variable vector as follows:Next, compute cost values and . If , the direction for the UDS is set as ; otherwise, . The better row is saved as .
- Step 4. UDS: Depending on the direction , perform addition or subtraction to the jth row, which is described asCheck whether the new row contributes to a further reduction of the loss function. If so, the current binary string and the variable are updated as the optimal ones as follows, and go to Step 4.Otherwise, go to Step 5.
- Step 5. Save the resultant UDS best string, , into the jth row of the current best matrix.
- Step 6. If , set . Go to Step 3. Otherwise, if the current string length m is shorter than the prescribed maximal row length , set , increase the row length index as , and go to Step 2. In the case of , go to Step 7.
- Step 7. If the number of restarts is less than the specified value, go to Step 1. Otherwise, terminate the current local search routine and choose the global minimum with the smallest cost value among the local minima found so far.
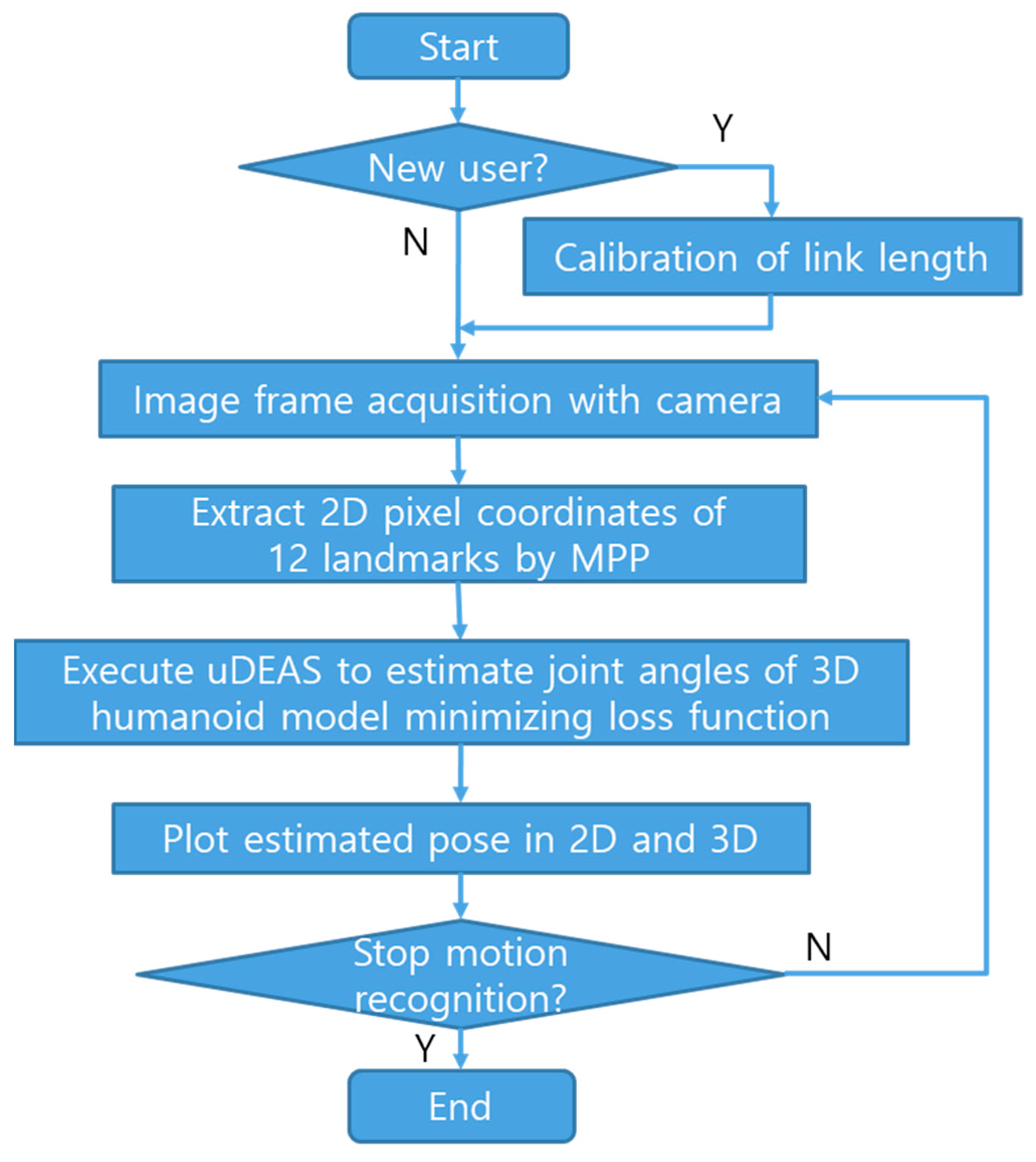
3. Proposed Pose Estimation Algorithm
Pose Estimation Process
- Step 1. Calibration of link length: Our system checks whether the human subject is a new user or not because the subject’s bone length information is basically necessary for the model-based pose estimation. If the present system has no link length data for the current subject, the link length measurement process begins; the subject stands with the arms stretched down, images are captured for at least 10 frames, and the length of each bone link is calculated as the average distance between the coordinates of the end joints of the bone at each frame.
- Step 2. Acquire images from an RGB camera with an image grabber module of SBC. Although an Intel RealSense camera is used in the present system, commercial RGB webcams are also available.
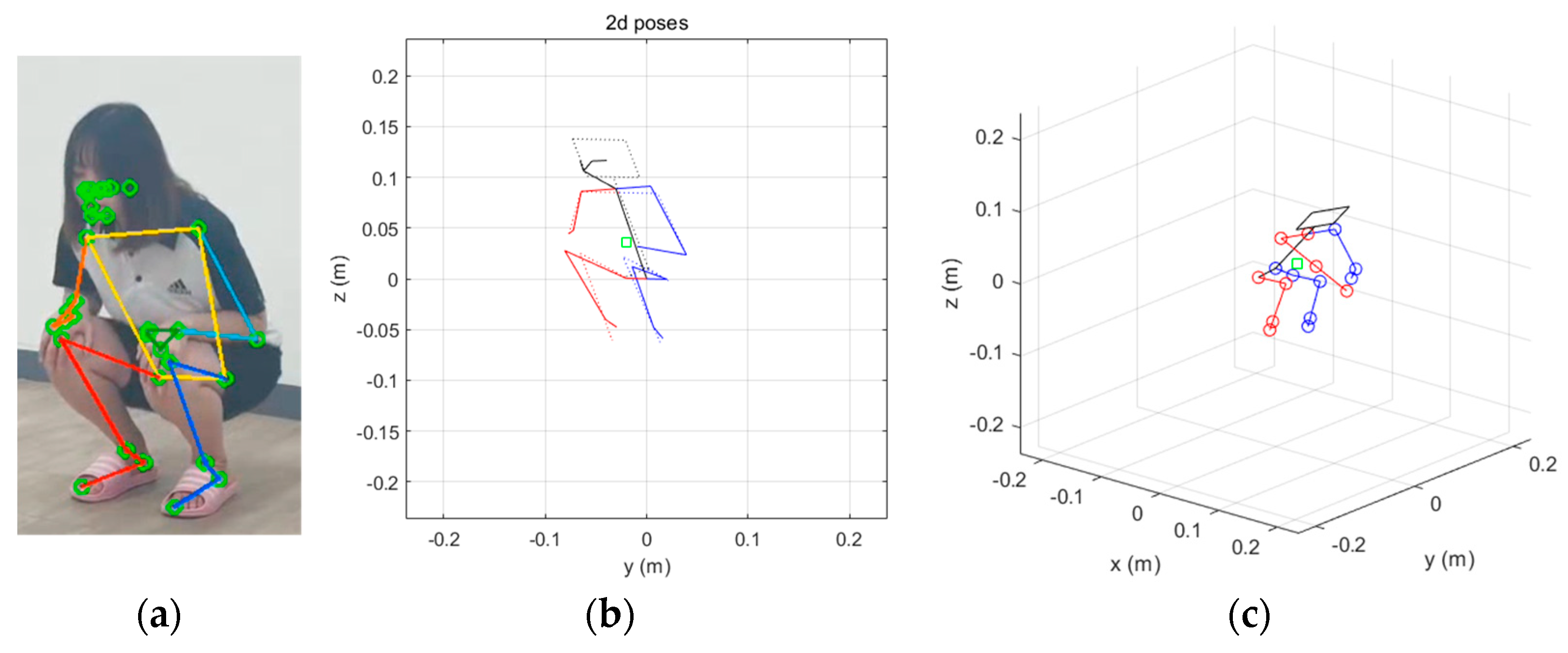
- Step 3. Execute MPP and obtain 2D pixel coordinates of the 17 landmarks for the captured human body.
- Step 4. Execute uDEAS to seek for unknown pose-relevant variables, such as the camera’s distance factor and viewing angles, and the intrabody joint angles by reducing the loss function formulated with the L2 norm between the joint coordinates obtained with MPP and those reprojected onto the corresponding 2D plane.
- Step 5. Plot the estimated poses in 2D or 3D depending on the application field.
- Step 6. If the current image frame is the last one or a termination condition is met, stop the pose estimation process. Otherwise, go to Step 2.
4. Experimental Setup and Results
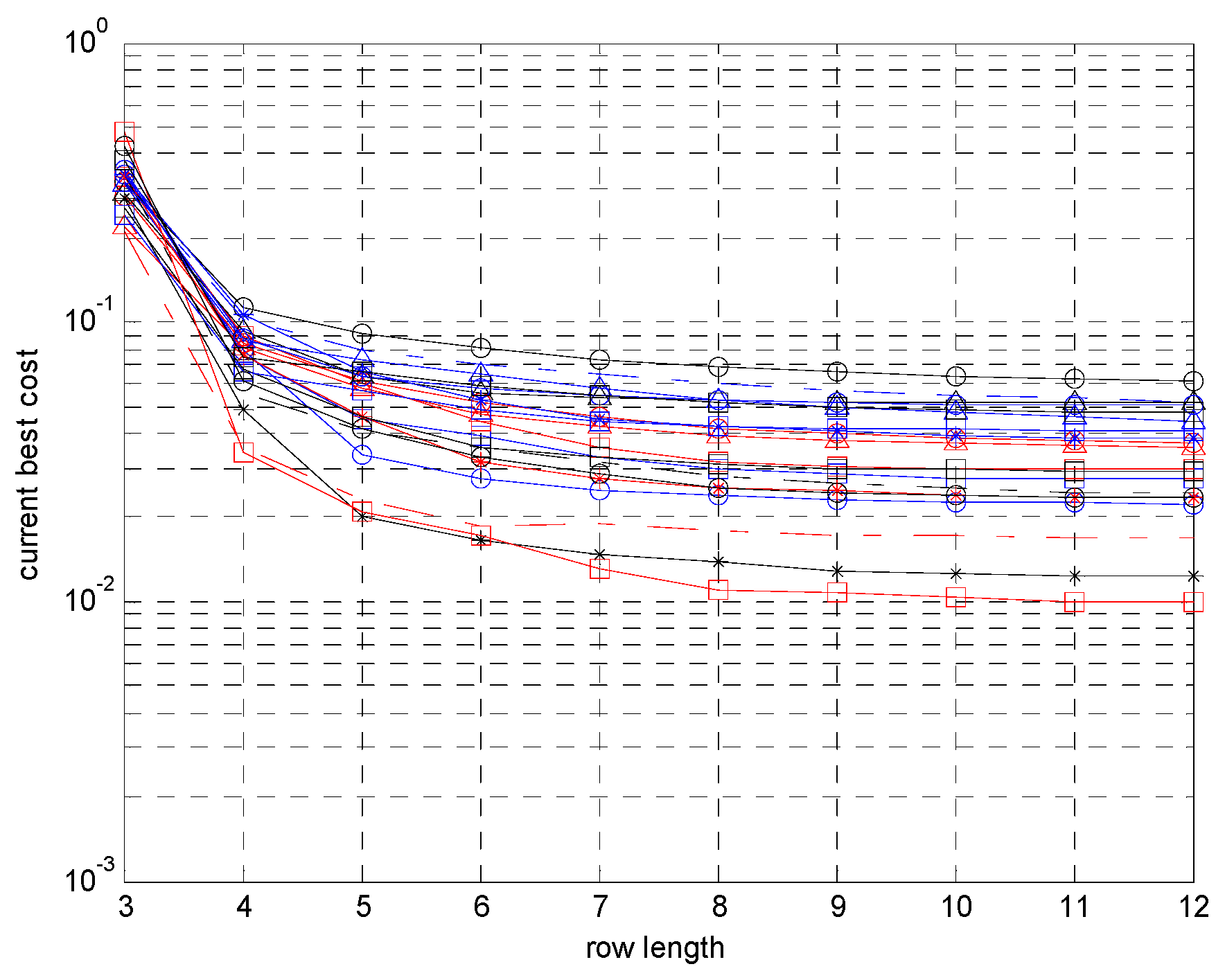
- Number of optimization variables: 19.
- Initial row length: 3.
- Maximum row length: 12.
- Number of maximum restarts: 20.
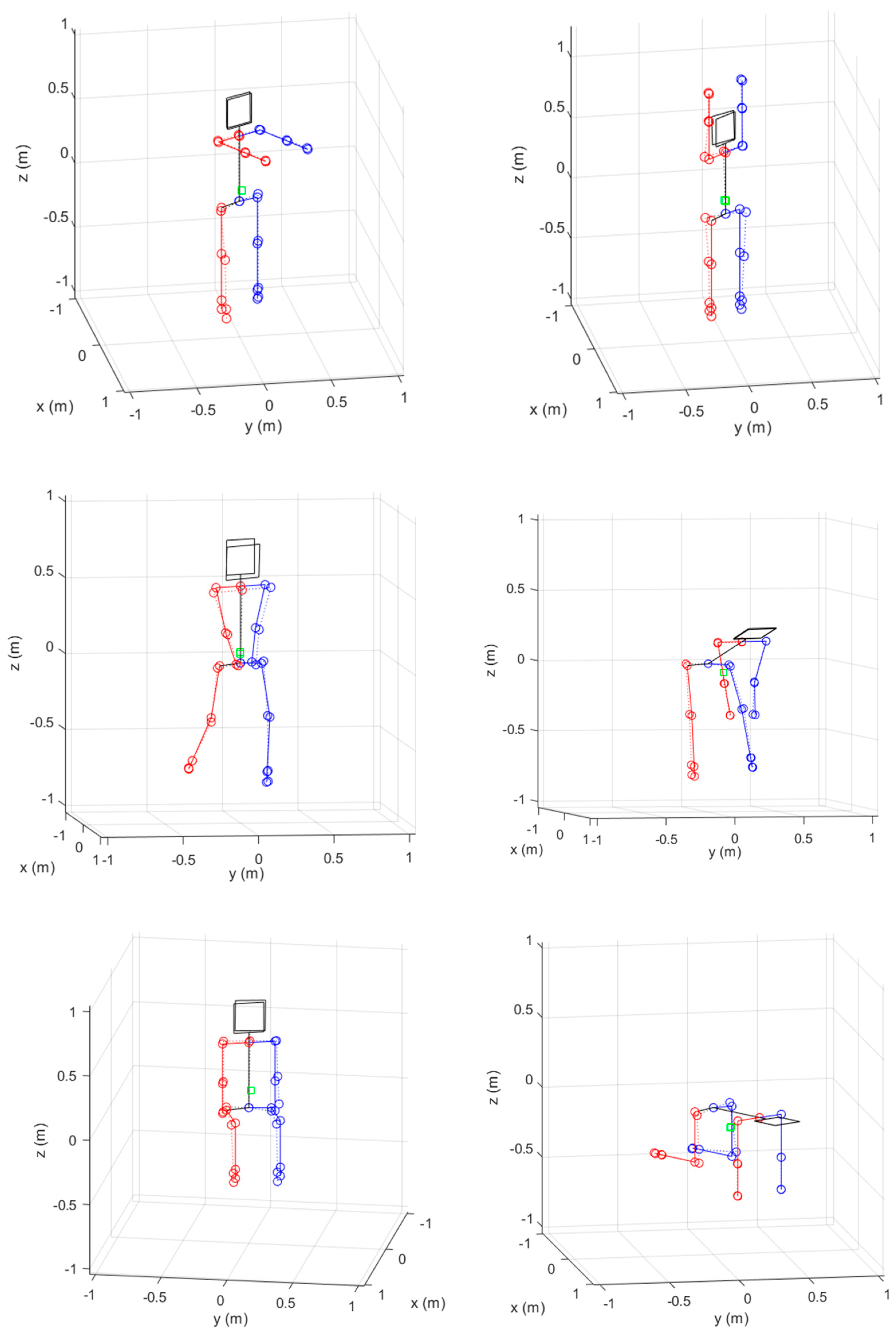
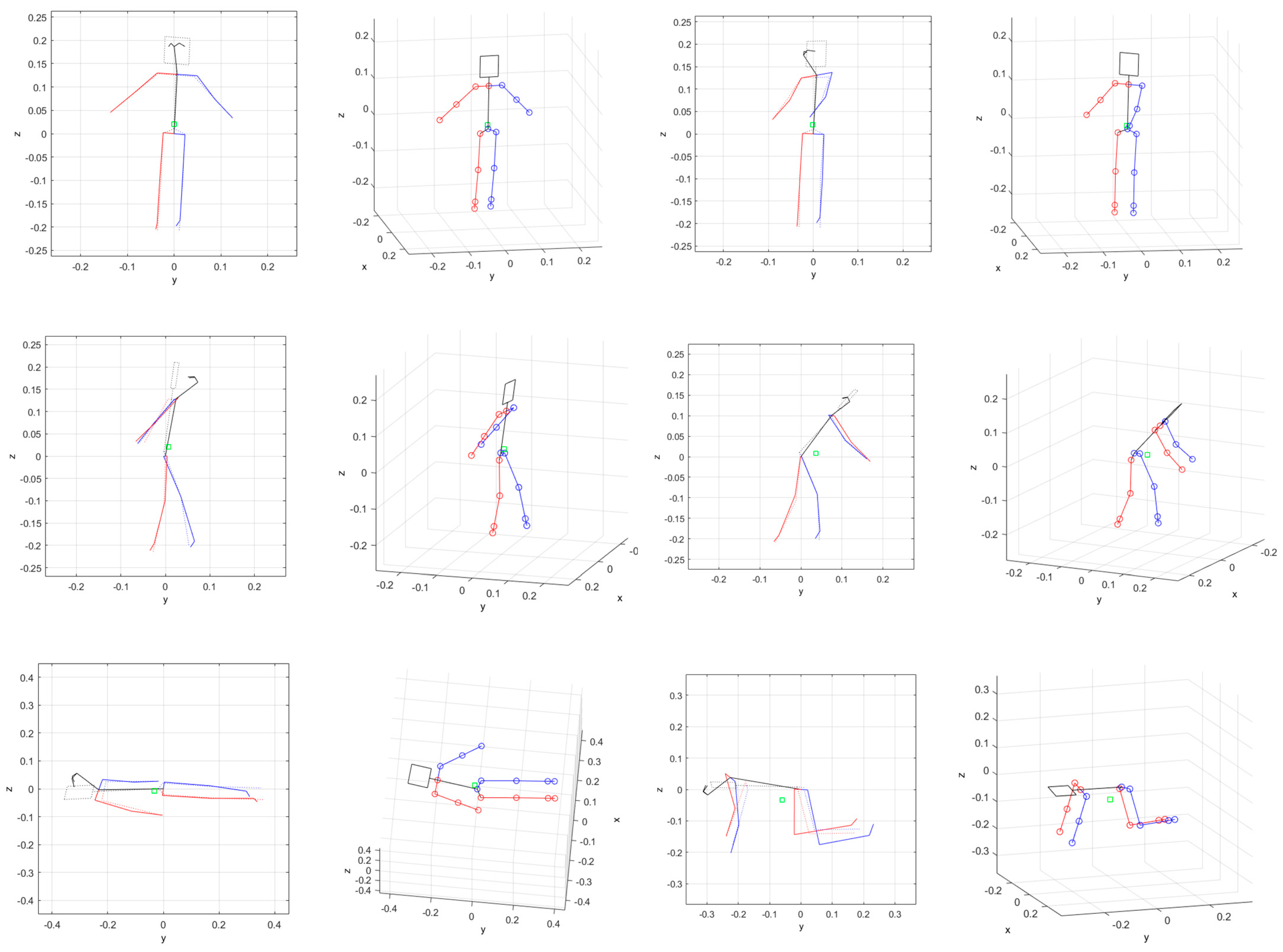
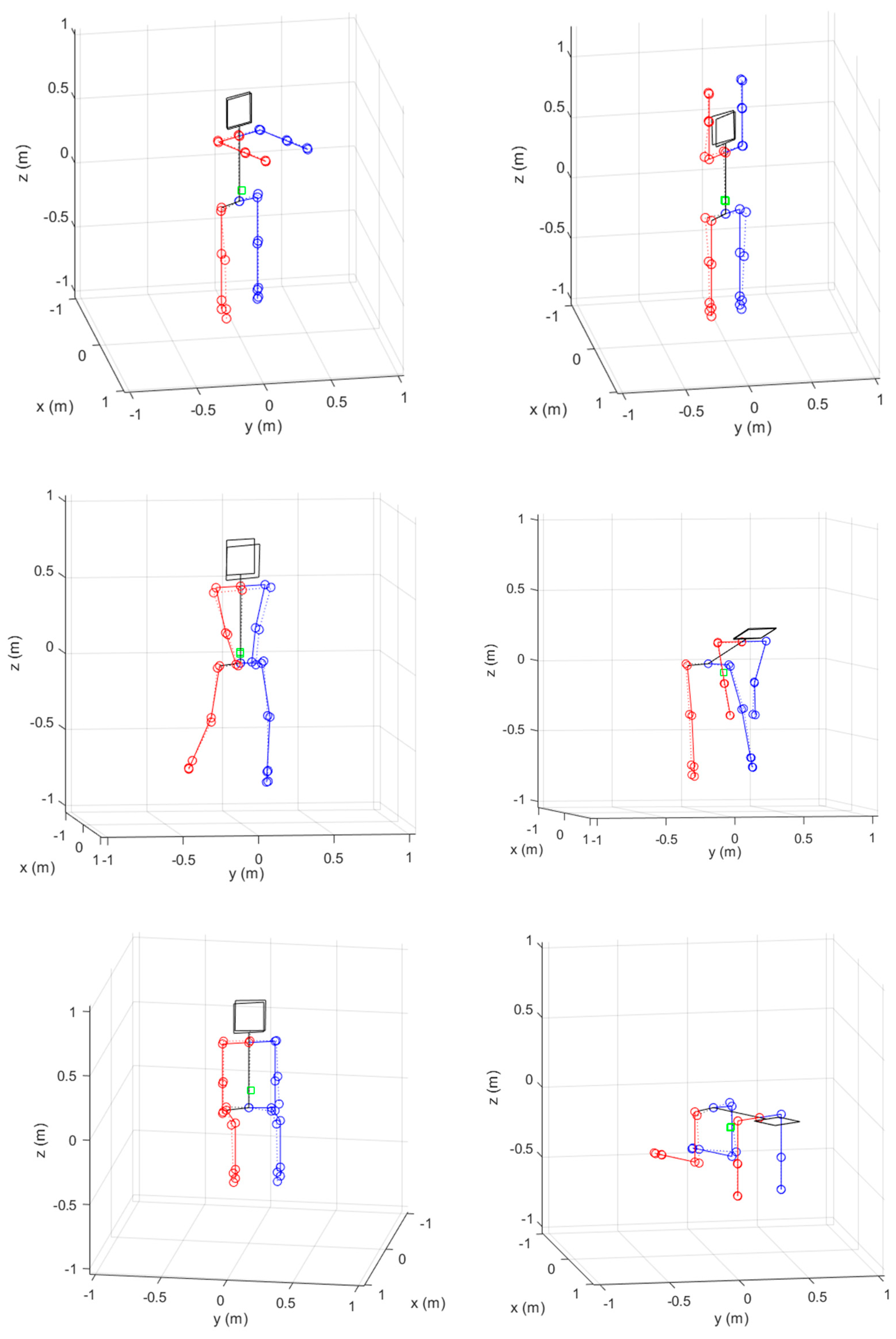
4.1. Pose Estimation with Simulation Data
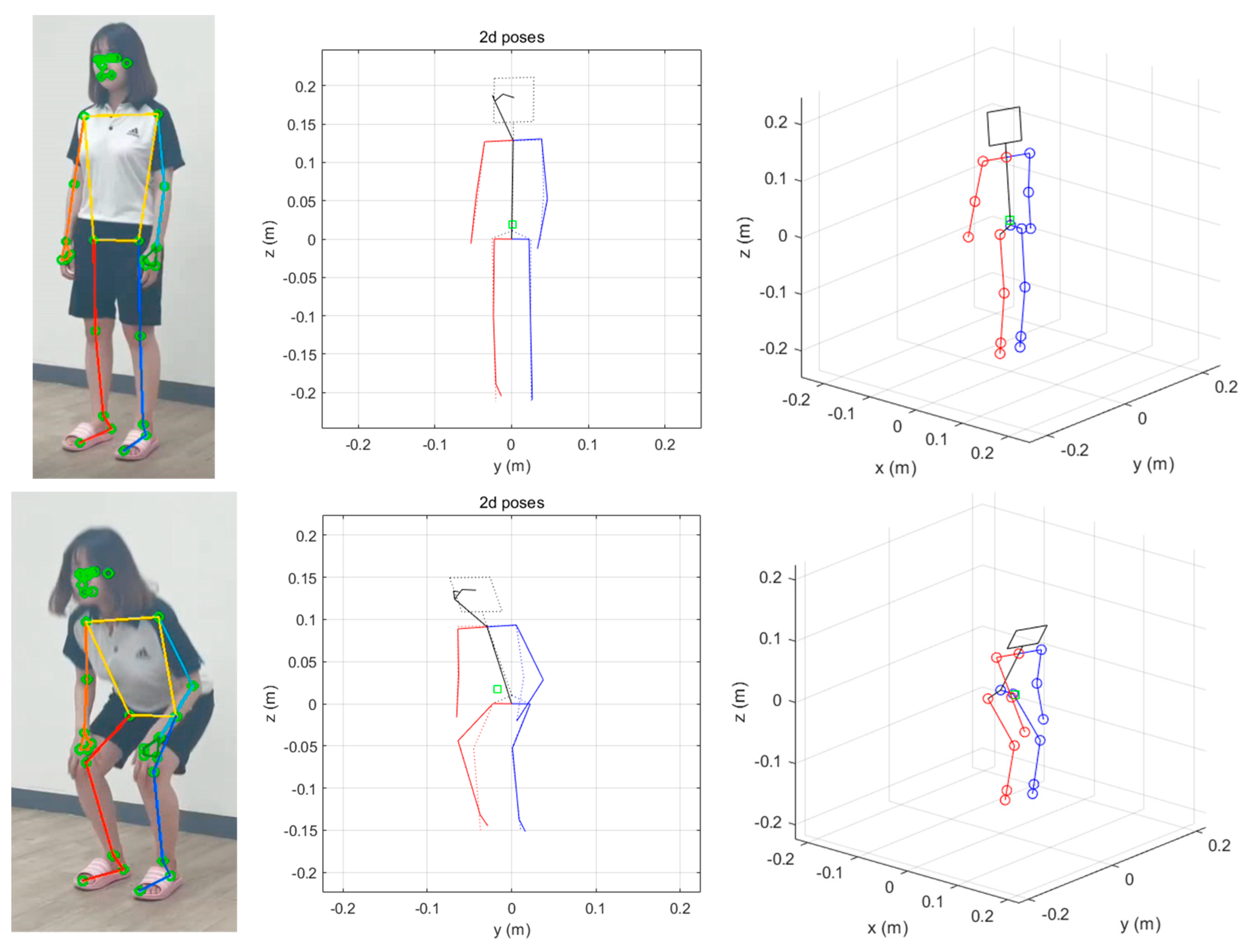
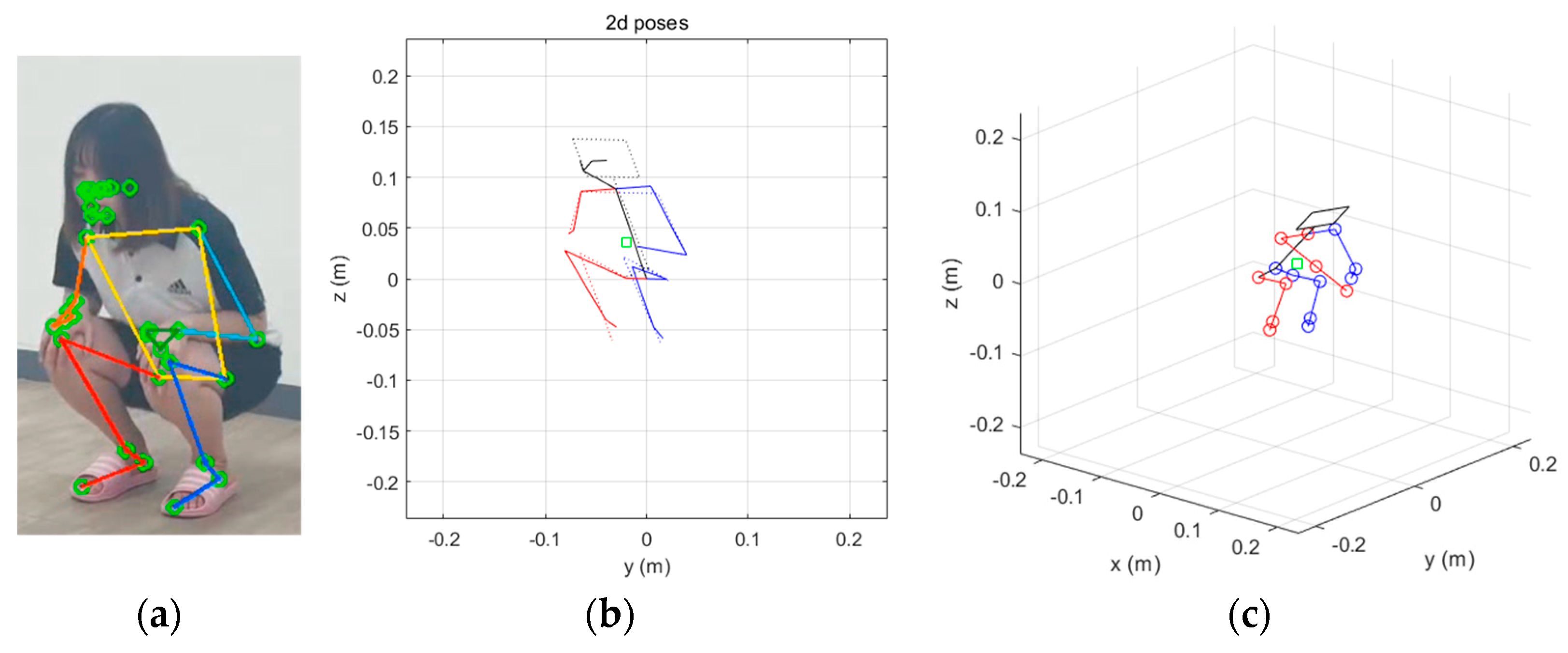
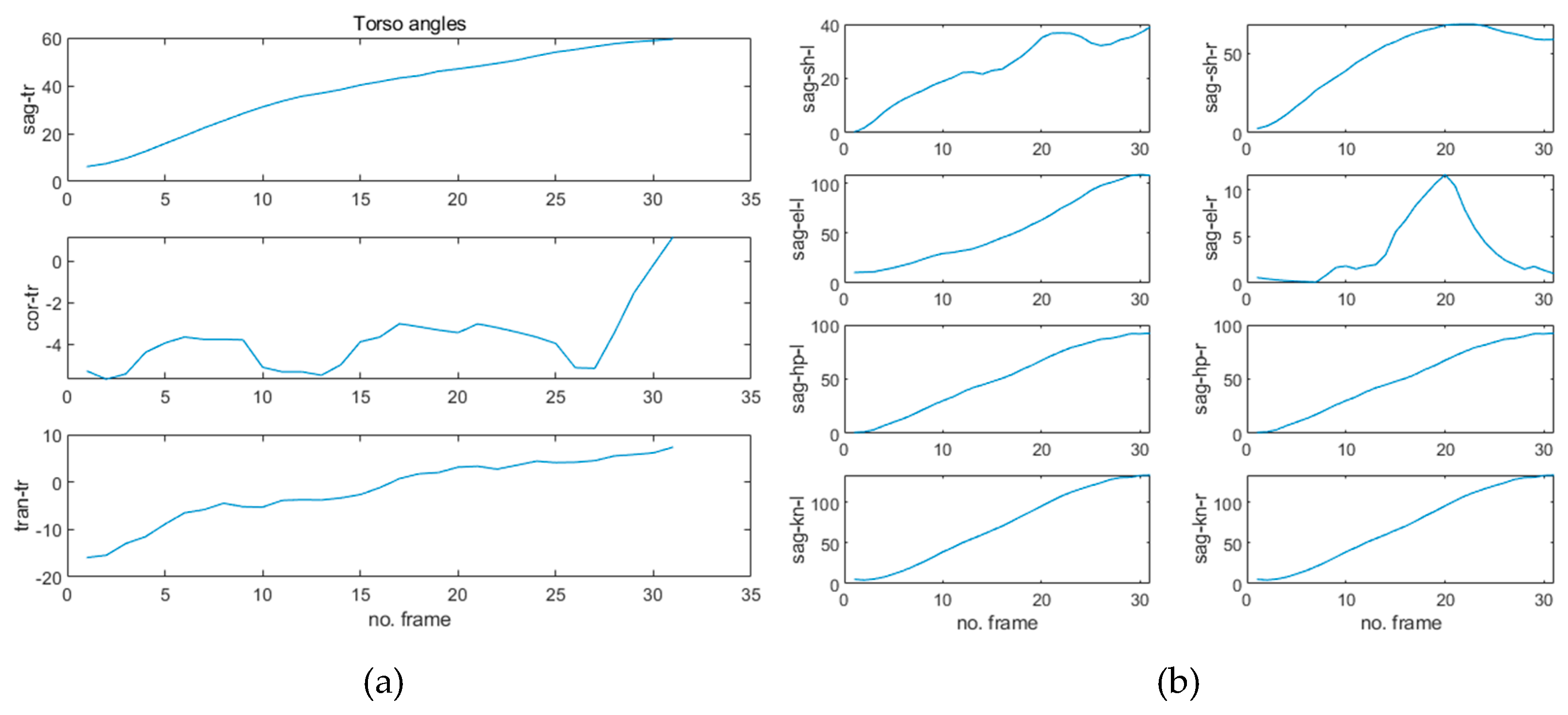
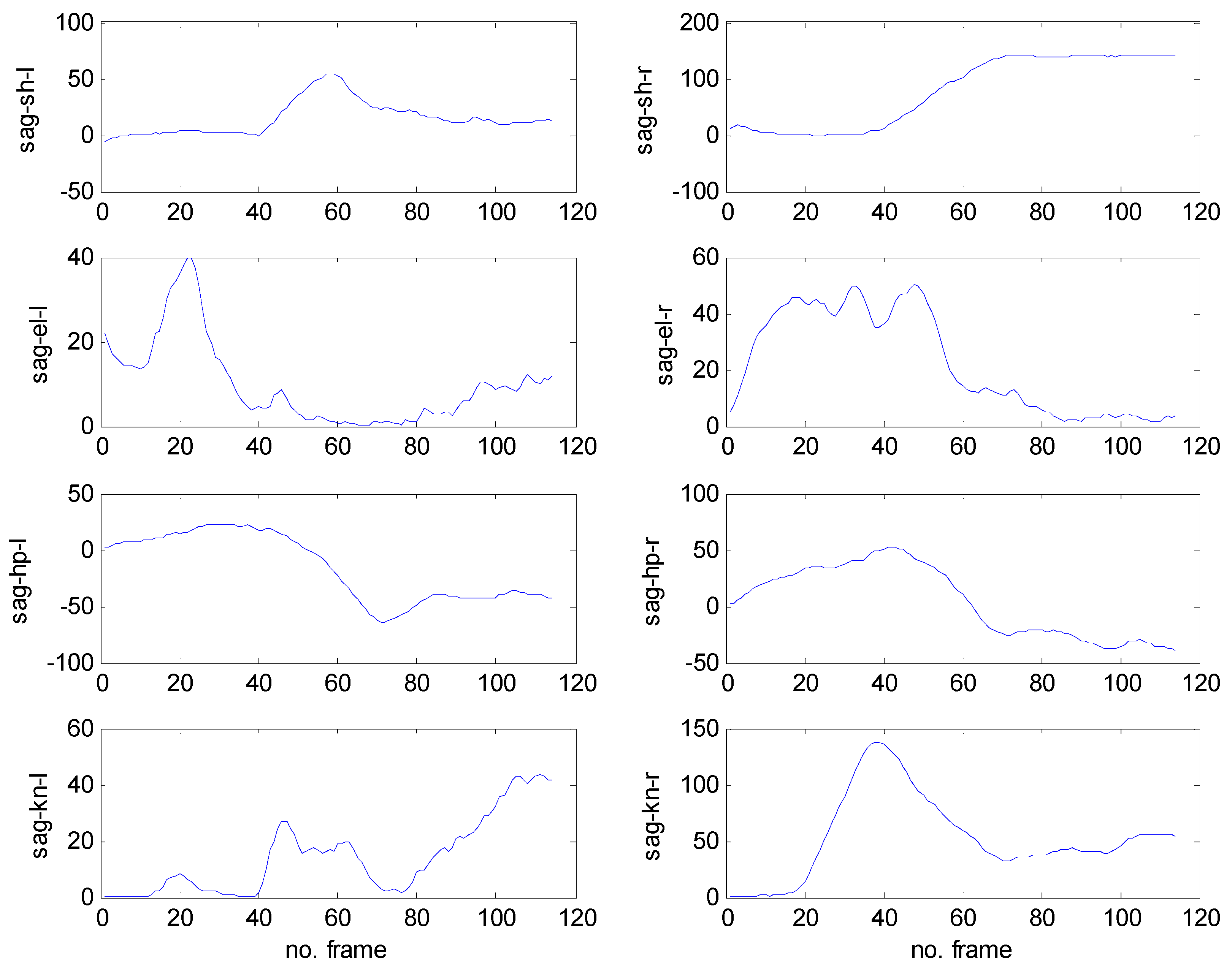
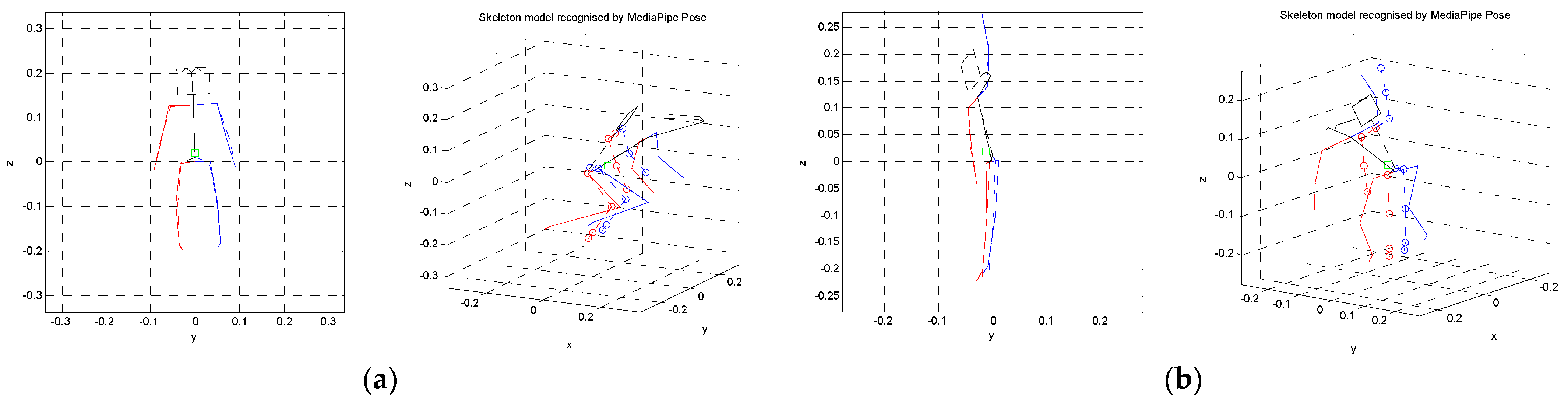
4.2. Pose Estimation with Experiment
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Su, M.; Hayati, D.W.; Tseng, S.; Chen, J.; Wei, H. Smart Care Using a DNN-Based Approach for Activities of Daily Living (ADL) Recognition. Appl. Sci. 2020, 11, 10. [Google Scholar] [CrossRef]
- Noreils, F.R. Inverse kinematics for a Humanoid Robot: A mix between closed form and geometric solutions. Tech. Rep. 2017, 1–31. [Google Scholar] [CrossRef]
- Yu, Y.; Yang, X.; Li, H.; Luo, X.; Guo, H.; Fang, Q. Joint-level vision-based ergonomic assessment tool for construction workers. J. Constr. Eng. Manag. 2019, 145, 04019025. [Google Scholar] [CrossRef]
- Rokbani, N.; Casals, A.; Alimi, A.M. IK-FA, a new heuristic inverse kinematics solver using firefly algorithm. Comput. Intell. Appl. Model. Control 2015, 369–395. [Google Scholar] [CrossRef] [Green Version]
- Xu, J.; Yu, Z.; Ni, B.; Yang, J.; Yang, X.; Zhang, W. Deep kinematics analysis for monocular 3d human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 899–908. [Google Scholar]
- Li, J.; Xu, C.; Chen, Z.; Bian, S.; Yang, L.; Lu, C. Hybrik: A hybrid analytical-neural inverse kinematics solution for 3d human pose and shape estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 3383–3393. [Google Scholar]
- Sarafianos, S.; Boteanu, B.; Ionescu, B.; Kakadiaris, I.A. 3D human pose estimation: A review of the literature and analysis of covariates. Comput. Vis. Image Underst. 2016, 152, 1–20. [Google Scholar] [CrossRef]
- Chen, Y.; Tian, Y.; He, M. Monocular human pose estimation: A survey of deep learning-based methods. Comput. Vis. Image Underst. 2020, 192, 102897. [Google Scholar] [CrossRef]
- Wang, J.; Tan, S.; Zhen, X.; Xu, S.; Zheng, F.; He, Z.; Shao, L. Deep 3D human pose estimation: A review. Comput. Vis. Image Underst. 2021, 210, 103225. [Google Scholar] [CrossRef]
- Yurtsever, M.M.E.; Eken, S. BabyPose: Real-time decoding of baby’s non-verbal communication using 2D video-based pose estimation. IEEE Sens. 2022, 22, 13776–13784. [Google Scholar] [CrossRef]
- Alam, E.; Sufian, A.; Dutta, P.; Leo, M. Vision-based human fall detection systems using deep learning: A review. Comput. Biol. Med. 2022, 146, 105626. [Google Scholar] [CrossRef]
- Pavlakos, G.; Zhou, X.; Derpanis, K.G.; Daniilidis, K. Coarse-to-fine volumetric prediction for single-image 3D human pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7025–7034. [Google Scholar]
- Luvizon, D.C.; Picard, D.; Tabia, H. 2d/3d pose estimation and action recognition using multitask deep learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5137–5146. [Google Scholar]
- Li, S.; Chan, A.B. 3d human pose estimation from monocular images with deep convolutional neural network. In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014; pp. 332–347. [Google Scholar]
- Zhou, X.; Sun, X.; Zhang, W.; Liang, S.; Wei, Y. Deep kinematic pose regression. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 186–201. [Google Scholar]
- Tome, D.; Russell, C.; Agapito, L. Lifting from the deep: Convolutional 3d pose estimation from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2500–2509. [Google Scholar]
- Wang, J.; Huang, S.; Wang, X.; Tao, D. Not all parts are created equal: 3D pose estimation by modelling bi-directional dependencies of body parts. arXiv 2019, arXiv:1905.07862. [Google Scholar]
- Wandt, B.; Rosenhahn, B. Repnet: Weakly supervised training of an adversarial reprojection network for 3d human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7782–7791. [Google Scholar]
- Sigal, L.; Balan, A.O.; Black, M.J. Humaneva; Synchronized video and motion capture dataset and baseline algorithm for evaluation of articulated human motion. IJCV 2010, 87, 4–27. [Google Scholar] [CrossRef]
- Ionescu, C.; Papava, D.; Olaru, V.; Sminchisescu, C. Human3.6m: Large scale datasets and predictive methods for 3d human sensing in natural environments. TPAMI 2014, 36, 1325–1339. [Google Scholar] [CrossRef] [PubMed]
- Pavllo, D.; Feichtenhofer, C.; Grangier, D.; Auli, M. 3D human pose estimation in video with temporal convolutions and semi-supervised training. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7753–7762. [Google Scholar]
- MediaPipe Pose. Available online: https://google.github.io/mediapipe/solutions/pose.html (accessed on 28 December 2021).
- Kim, J.-W.; Kim, T.; Park, Y.; Kim, S.W. On load motor parameter identification using univariate dynamic encoding algorithm for searches (uDEAS). IEEE Trans. Energy Convers. 2008, 23, 804–813. [Google Scholar]
- Vicon. Available online: https://www.vicon.com/ (accessed on 1 August 2021).
- Vakanski, A.; Jun, H.P.; Paul, D.; Baker, R. A data set of human body movements for physical rehabilitation exercises. Data 2018, 3, 2. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bazarevsky, V.; Grishchenko, I. On-Device, Real-Time Body Pose Tracking with MediaPipe BlazePose, Google Research. Available online: https://ai.googleblog.com/2020/08/on-device-real-time-body-pose-tracking.html (accessed on 10 August 2021).
- Denavit, J.; Hartenberg, R.S. A kinematic notation for lower-pair mechanisms based on matrices. J. Appl. Mech. 1955, 77, 215–221. [Google Scholar] [CrossRef]
- Kim, J.-W.; Tran, T.T.; Dang, C.V.; Kang, B. Motion and walking stabilization of humanoids using sensory reflex control. Int. J. Adv. Robot. Syst. 2016, 13, 1–10. [Google Scholar]
- Kim, J.-W.; Kim, T.; Choi, J.-Y.; Kim, S.W. On the global convergence of univariate dynamic encoding algorithm for searches (uDEAS). Int. J. Control Autom. Syst. 2008, 6, 571–582. [Google Scholar]
- Yun, J.P.; Choi, S.; Kim, J.-W.; Kim, S.W. Automatic detection of cracks in raw steel block using Gabor filter optimized by univariate dynamic encoding algorithm for searches (uDEAS). NDT E Int. 2009, 42, 389–397. [Google Scholar] [CrossRef]
- Kim, E.; Kim, M.; Kim, S.-W.; Kim, J.-W. Trajectory generation schemes for bipedal ascending and descending stairs using univariate dynamic encoding algorithm for searches (uDEAS). Int. J. Control Autom. Syst. 2010, 8, 1061–1071. [Google Scholar] [CrossRef]
- Kim, J.-W.; Ahn, H.; Seo, H.C.; Lee, S.C. Optimization of Solar/Fuel Cell Hybrid Energy System Using the Combinatorial Dynamic Encoding Algorithm for Searches (cDEAS). Energies 2022, 15, 2779. [Google Scholar] [CrossRef]
- Goldberg, D.E. Genetic Algorithm in Search, Optimization and Machine Learning; Addison Wesley: Berkeley, CA, USA, 1999. [Google Scholar]
- Size Korea. Available online: https://sizekorea.kr (accessed on 15 March 2022).
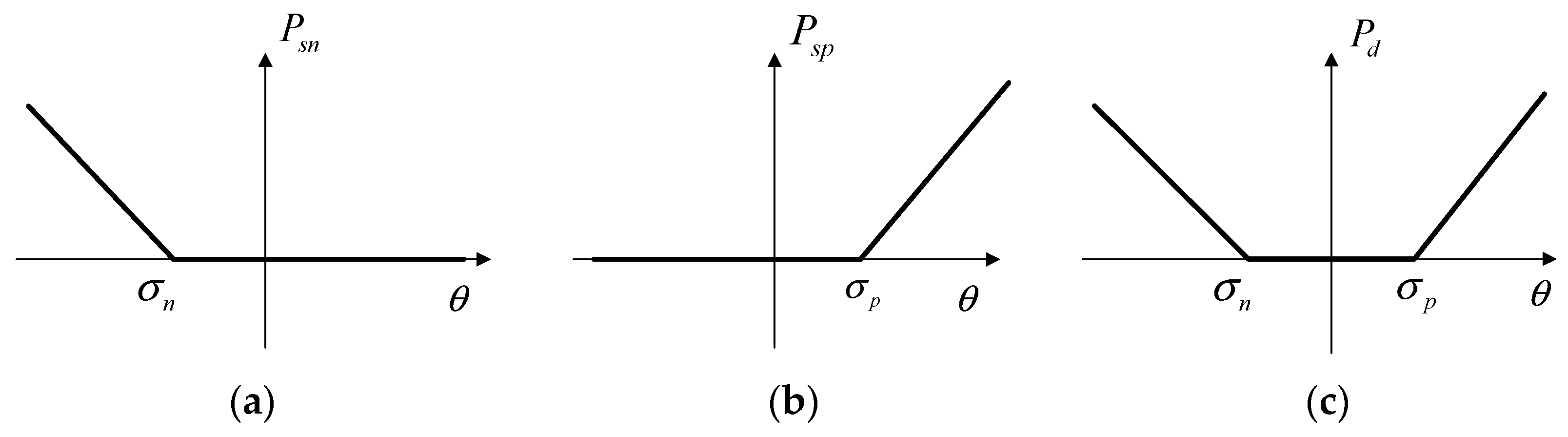






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
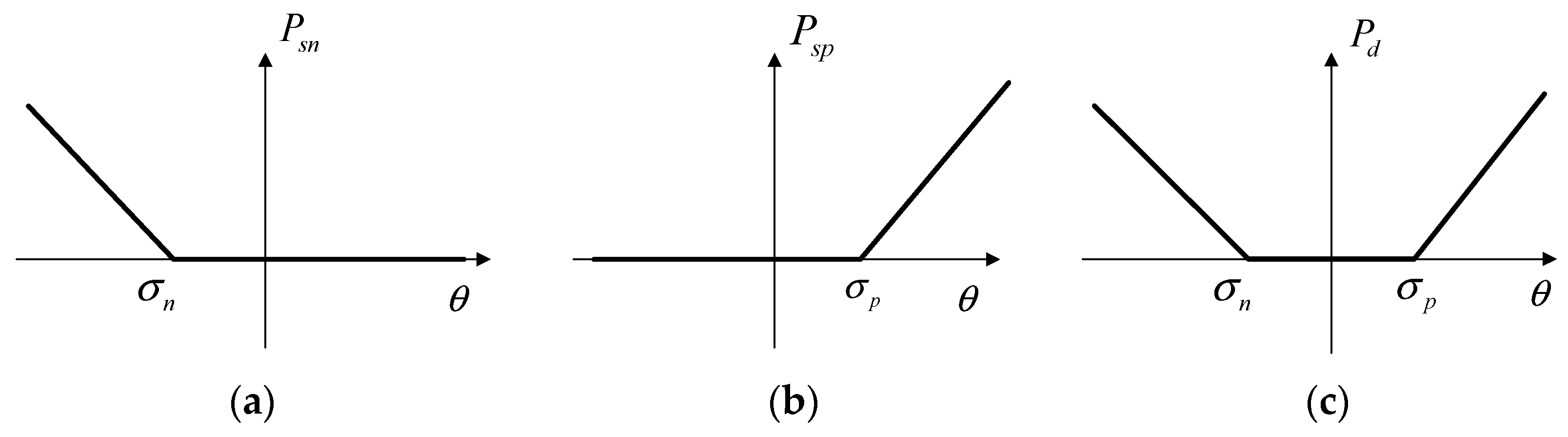{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1 | 10 | 10 | 90 | 90 | 40 | 30 | 90 | 90 | 90 | 90 | 180 | 90 | 180 | 90 | 40 | 40 | 40 | 40 | |
| 1 | −10 | −10 | −90 | −20 | −40 | −30 | −20 | 0 | −20 | 0 | −180 | 0 | −180 | 0 | −40 | −40 | −40 | −40 |
| Pose | 1 | 2 | 3 | 4 | 5 | 6 | Avg. |
|---|---|---|---|---|---|---|---|
| MPJPE (m) | 0.0055 | 0.0099 | 0.0111 | 0.0049 | 0.0150 | 0.0116 | 0.097 |
| Avg. ang. diff (deg) | 6.061 | 7.748 | 10.557 | 5.6 | 14.558 | 15.58 | 10.017 |
| No. Restart | Max. Row Length | Avg. Run Time Per Frame (s) | |
|---|---|---|---|
| 10 | 12 | 6.52 | 0.180 |
| 11 | 6.63 | 0.165 | |
| 10 | 6.63 | 0.137 | |
| 9 | 6.54 | 0.118 | |
| 8 | 6.74 | 0.096 | |
| 7 | 6.72 | 0.078 | |
| 6 | 6.94 | 0.062 | |
| 5 | 7.22 | 0.044 | |
| 4 | 12.89 | 0.028 | |
| 9 | 12 | 6.65 | 0.170 |
| 8 | 6.73 | 0.149 | |
| 7 | 6.68 | 0.130 | |
| 6 | 6.98 | 0.113 | |
| 5 | 7.15 | 0.096 | |
| 4 | 7.98 | 0.079 | |
| 6 | 6 | 7.04 | 0.033 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.-W.; Choi, J.-Y.; Ha, E.-J.; Choi, J.-H. Human Pose Estimation Using MediaPipe Pose and Optimization Method Based on a Humanoid Model. Appl. Sci. 2023, 13, 2700. https://doi.org/10.3390/app13042700
Kim J-W, Choi J-Y, Ha E-J, Choi J-H. Human Pose Estimation Using MediaPipe Pose and Optimization Method Based on a Humanoid Model. Applied Sciences. 2023; 13(4):2700. https://doi.org/10.3390/app13042700
Chicago/Turabian StyleKim, Jong-Wook, Jin-Young Choi, Eun-Ju Ha, and Jae-Ho Choi. 2023. "Human Pose Estimation Using MediaPipe Pose and Optimization Method Based on a Humanoid Model" Applied Sciences 13, no. 4: 2700. https://doi.org/10.3390/app13042700
APA StyleKim, J. -W., Choi, J. -Y., Ha, E. -J., & Choi, J. -H. (2023). Human Pose Estimation Using MediaPipe Pose and Optimization Method Based on a Humanoid Model. Applied Sciences, 13(4), 2700. https://doi.org/10.3390/app13042700