


Discovering and Ranking Relevant Comment for Chinese Automatic Question-Answering System

Abstract
:1. Introduction
- We verify the performance of three neural network models in question-answering tasks under the scenario of grid electric power company customer service. By predicting the answer to customer queries through the content of comments from platforms, the ultimate goal of the model is to find useful comments that can provide useful answers to customer queries.
- The input of our end-to-end neural network models is raw texts, which do not need to be processed by feature engineering before inputting into the model.
- We further build a dataset based on the data provided by the State Grid Hebei Electric Power Company and use them to construct a question-answering system suitable for the grid electric power field.
2. Related Work
3. Method and Approach
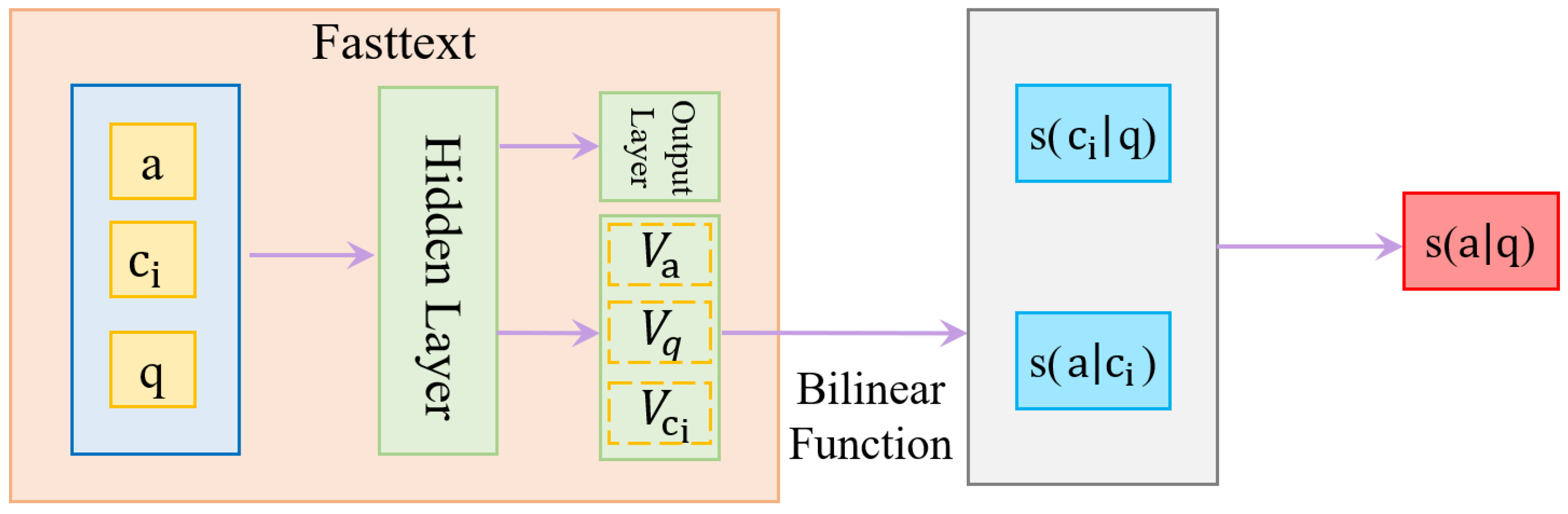
3.1. NN-RC
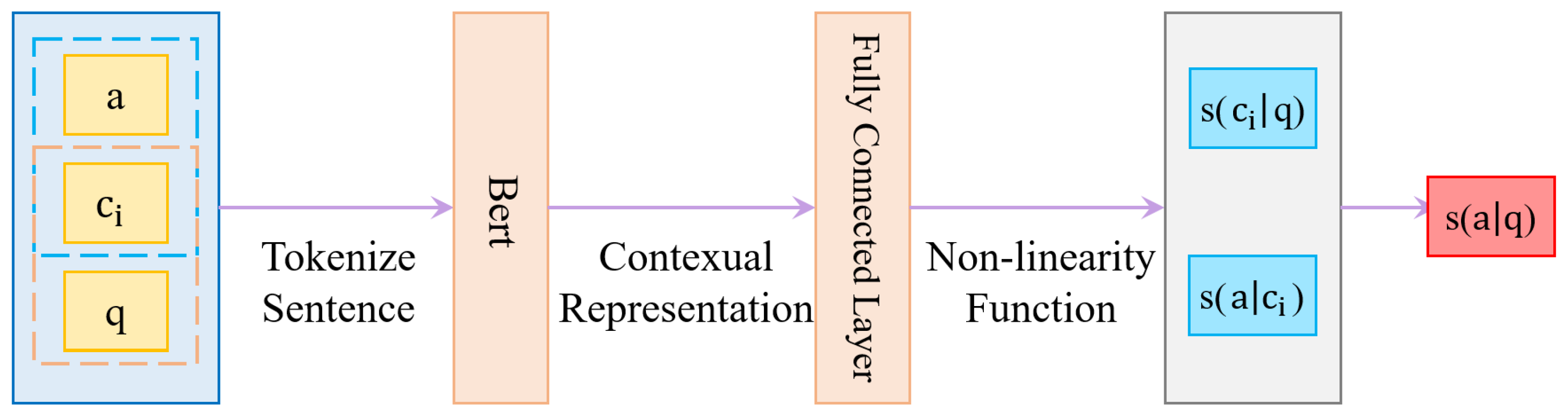
3.2. Bert-RC
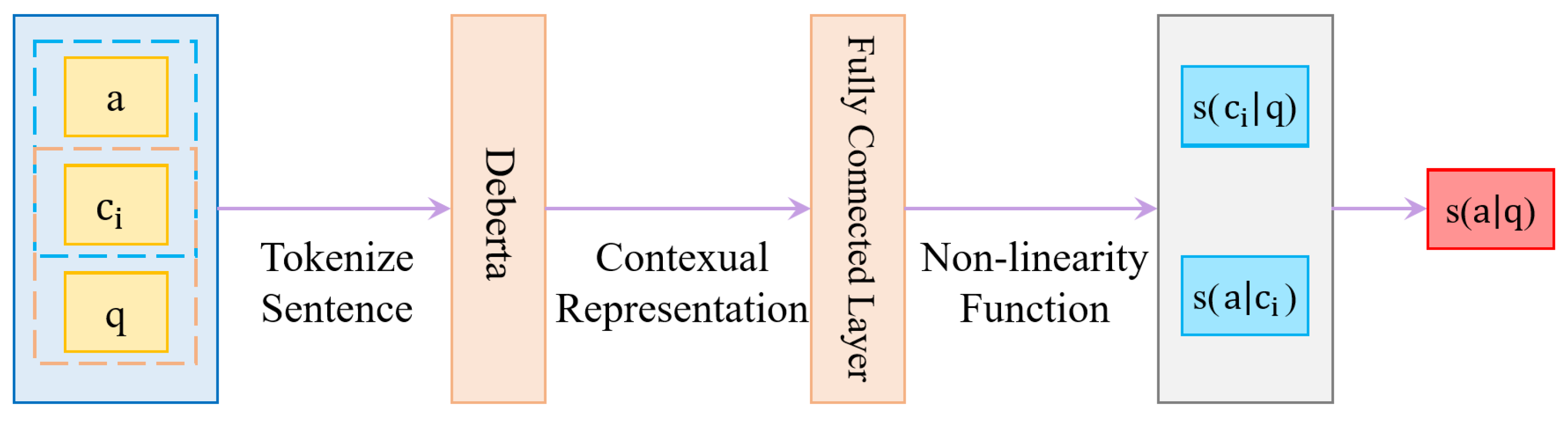
3.3. DeBerta-RC
3.4. Comment Filtering
3.5. Cross-Domain Pre-Training
4. Results and Discussion
4.1. Data Introduction
4.2. Qualitative Evaluation
4.2.1. Evaluation Metrics
4.2.2. Experiment Details
4.2.3. Result and Disscusion
4.3. Qualitative Survey
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mcauley, J.; Yang, A. Addressing Complex and Subjective Product-Related Queries with Customer Reviews. In Proceedings of the 25th International Conference on World Wide Web, Montreal, QC, Canada, 11–16 April 2016; pp. 625–635. [Google Scholar]
- Yin, D.; Cheng, S.; Pan, B.; Qiao, Y.; Zhao, W.; Wang, D. Chinese Named Entity Recognition Based on Knowledge Based Question Answering System. Appl. Sci. 2022, 12, 5373. [Google Scholar] [CrossRef]
- Yu, Q.; Lam, W.; Wang, Z. Responding e-commerce product questions via exploiting qa collections and reviews. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, SA, USA, 20–26 August 2018; pp. 2192–2203. [Google Scholar]
- Chen, L.; Guan, Z.; Zhao, W.; Zhao, W.; Wang, X.; Zhao, Z.; Sun, H. Answer identification from product reviews for user questions by multi-task attentive networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 45–52. [Google Scholar]
- Zhao, J.; Guan, Z.; Sun, H. Riker: Mining rich keyword representations for interpretable product question answering. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AL, USA, 4–8 August 2019; pp. 1389–1398. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MI, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Liu, P. Exploring the limits of transfer learning with a unified text-to-text transformer. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- He, P.; Liu, X.; Gao, J.; Chen, W. Deberta: Decoding-enhanced bert with disentangled attention. arXiv 2020, arXiv:2006.03654. [Google Scholar]
- Zhang, S.; Lau, J.H.; Zhang, X.; Chan, J.; Paris, C. Discovering relevant reviews for answering product-related queries. In Proceedings of the IEEE International Conference on Data Mining, New York, NY, USA, 10–11 September 2019; pp. 411–419. [Google Scholar]
- Wan, M.; Mcauley, J. Modeling Ambiguity, Subjectivity, and Diverging Viewpoints in Opinion Question Answering Systems. In Proceedings of the 16th International Conference on Data Mining, Barcelona, Spain, 12–16 December 2016. [Google Scholar]
- Yu, Q.; Lam, W. Aware Answer Prediction for Product-Related Questions Incorporating Aspects. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Houston, TX, USA, 5–9 February 2018; pp. 691–699. [Google Scholar]
- Gao, S.; Ren, Z.; Zhao, Y.; Zhao, D.; Yin, D.; Yan, R. Product-aware answer generation in e-commerce question-answering. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, Melbourne, Australia, 11–15 February 2019; pp. 429–437. [Google Scholar]
- Chen, S.; Li, C.; Ji, F.; Zhou, W.; Chen, H. Driven answer generation for product-related questions in e-commerce. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, Melbourne, Australia, 11–15 February 2019; pp. 429–437. [Google Scholar]
- iiMedia. Available online: https://www.iimedia.com.cn/en/about.jsp (accessed on 10 November 2022).
- Li, F.; Shao, X.D.; Zhou, L.H.; Jin, Y. The present situation and development of intelligent customer service robot. China Media Technol. 2015, 10, 3. [Google Scholar]
- Liu, J.; Li, Y.; Shen, X.; Zhou, X.; Li, F. Large enterprise information communication intelligent customer service integration solution. In Proceedings of the 17th Power industry informatization Annual Conference, Wuxi, China, 7–8 September 2019. [Google Scholar]
- ALIME. Available online: https://www.alixiaomi.com/#/ (accessed on 10 November 2022).
- Tencent Qidian. Available online: https://qidian.qq.com/ (accessed on 10 November 2022).
- Sobot. Available online: https://www.sobot.com/ (accessed on 10 November 2022).
- Huang, X.; Wu, G.; Yin, Y.; Wang, X. Perspective on Power Smart Customer Service Based on AI. In Proceedings of the 17th International Forum of Digital Multimedia Communication, Online, 3–4 December 2021. [Google Scholar]
- Zhang, X.H.; Sun, D.Y.; Ma, Y.B.; Wang, M.Z.; Cao, L.; Li, Y.H. Research on the application of emotion recognition technology in power intelligent customer service system. Electron. Dev. 2020, 43, 5. [Google Scholar]
- Zhu, Y.Y.; Dai, C.; Chen, Y.; Zhuo, L.; Liao, Y.; Zhao, M. Design of online power smart customer service system based on artificial intelligence. Mach. Tool Hydraul. 2019, 46, 190–193. [Google Scholar]
- Yan, H.; Huang, B.; Liu, L. Application prospect analysis of artificial intelligence in new generation power system. Electr. Power Inf. Commun. Technol. 2018, 11, 7–11. [Google Scholar]
- Rao, Z.; Zhang, Y. Research on intelligent customer service system based on knowledge map. Electr. Power Inf. Commun. Technol. 2017, 15, 41–45. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of tricks for efficient text classification. arXiv 2016, arXiv:1607.01759. [Google Scholar]
- Yu, L.; Li, L.; Wang, Z.; Zhang, Y. Optimization Algorithm of Power Marketing AI Response System in the Era of Intelligent Technology. In Proceedings of the IEEE 6th Advanced Information Technology, Electronic and Automation Control Conference, Beijing, China, 3–4 October 2022; pp. 2008–2013. [Google Scholar]
- Wang, X.; Bian, J.; Chang, Y.; Tseng, B. Model news relatedness through user comments. In Proceedings of the 21st International Conference on World Wide Web, Lyon, France, 16–20 April 2012; pp. 629–630. [Google Scholar]
- Wang, Y.; Chen, S. A Survey of Evaluation and Design for AUC Based Classifier. Pattern Recognit. Artif. Intell. 2011, 24, 64–71. [Google Scholar]
- Jacobs, R.; Jordan, M.; Nowlan, S.; Hinton, G. Adaptive mixtures of local experts. Neural Comput. 2014, 3, 79–87. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Question: The printer in the office cannot work and no paper is coming out. What should I do? |
| Answer: Remove the paper from the printer and then reuse it. |
| Comment: There is a paper jam in the public printer, which locates on the ninth floor of the main |
| building. After taking out the paper, it can be used normally after debugging. |
| Question: I forgot the computer password. I have inputted the password too many times. Now |
| the computer won’t allow me to input it. How can I solve this problem? |
| Answer: Shut down for 20 30 minutes, and then log on again. |
| Comment: There are too many times to enter the power-on password, so the computer is locked. |
| Turn it off for about 20 minutes and then turn it on again. |
| Category | Questions 1 | Services 1 | Comments 1 |
|---|---|---|---|
| Communication | 9256 | 342 | 200,278 |
| Business Application | 6386 | 157 | 130,964 |
| Terminal & Peripheral | 8832 | 286 | 154,394 |
| Baseline | NN-RC | NN-RC + PRE | NN-RC + FLTR + PRE | |
|---|---|---|---|---|
| Communication | 0.7073 | 0.6864 | 0.7518 | 0.7249 |
| Business Application | 0.7133 | 0.6890 | 0.7477 | 0.7191 |
| Terminal & Peripheral | 0.6925 | 0.6836 | 0.7538 | 0.7321 |
| Average | 0.7044 | 0.6863 | 0.7511 | 0.7254 |
| Bert-RC + FLTR | Bert-RC + FLTR + Pre | DeBerta-RC + FLTR | DeBerta-RC + FLTR + Pre | |
|---|---|---|---|---|
| Communication | 0.8011 | 0.8257 | 0.8716 | 0.9135 |
| Business Application | 0.7977 | 0.8138 | 0.8578 | 0.8918 |
| Terminal & Peripheral | 0.8035 | 0.8272 | 0.8707 | 0.9052 |
| Average | 0.8008 | 0.8222 | 0.8687 | 0.9035 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, S.; Yin, D.; Hou, Z.; Shi, Z.; Wang, D.; Fu, Q. Discovering and Ranking Relevant Comment for Chinese Automatic Question-Answering System. Appl. Sci. 2023, 13, 2716. https://doi.org/10.3390/app13042716
Cheng S, Yin D, Hou Z, Shi Z, Wang D, Fu Q. Discovering and Ranking Relevant Comment for Chinese Automatic Question-Answering System. Applied Sciences. 2023; 13(4):2716. https://doi.org/10.3390/app13042716
Chicago/Turabian StyleCheng, Siyuan, Didi Yin, Zhuoyan Hou, Zihao Shi, Dongyu Wang, and Qiang Fu. 2023. "Discovering and Ranking Relevant Comment for Chinese Automatic Question-Answering System" Applied Sciences 13, no. 4: 2716. https://doi.org/10.3390/app13042716
APA StyleCheng, S., Yin, D., Hou, Z., Shi, Z., Wang, D., & Fu, Q. (2023). Discovering and Ranking Relevant Comment for Chinese Automatic Question-Answering System. Applied Sciences, 13(4), 2716. https://doi.org/10.3390/app13042716