Op-Trans: An Optimization Framework for Negative Sampling and Triplet-Mapping Properties in Knowledge Graph Embedding


Abstract
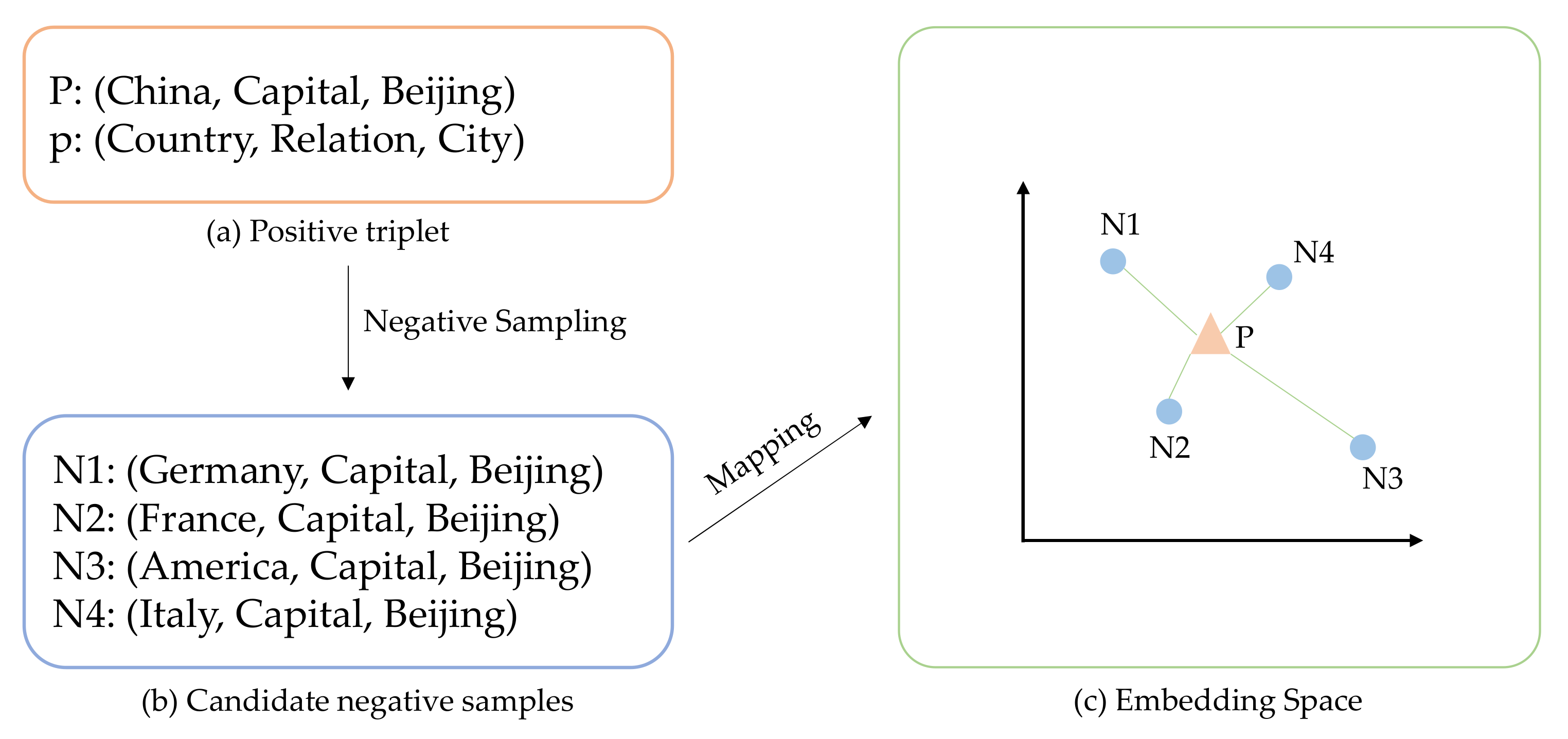
:1. Introduction
2. Related Works
2.1. The Translation Models
2.2. Negative Sampling Methods
3. Proposed Method
3.1. Review of Translation Model Framework
3.2. Op-Trans Framework
| Algorithm 1: Learning Op-TransE |
| Input: Training set , , entity set , relation set , dimension of embeddings , margin , value of K-Means. |
| 1: initialize: 2: for each entity . 3: for each . 4: for each . 5: for each . |
| 6: loop: 7: //sample a mini-batch of size 8: // initialize the set of positive and negative triplet pairs 9: for do 10: //sample a negative triplet or 11: 12: end for 13: updating model parameters w.r.t 14: if epoch % s == 0 then 15: Updating //cluster entities by K-Means 16: end if 17: end loop |
3.3. Negative Sampling
| Algorithm 2: Updating Cache |
| Input: head cache H of size . |
| 1: initialize 2: K-Means 3: uniformly sample entity subset of size from the cluster in which the head entity resides 4: ; 5: for i = 1, ……, do 6: calculate the score for all ; 7: sample with probability in Equation (4); 8: end for |
3.4. Triplets Mapping Properties Weighting
4. Experiments
4.1. Data Sets
4.2. Experiment Setup
4.3. Evaluation Task and Metrics
4.3.1. Link Prediction
4.3.2. Performance Measurements
4.4. Experimental Design
4.4.1. Comparing Different Negative Sampling Methods
4.4.2. Analysis of Experimental Results of Op-Trans
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chami, I.; Wolf, A.; Juan, D.C.; Sala, F.; Ravi, S.; Ré, C. Low-Dimensional Hyperbolic Knowledge Graph Embeddings. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 6901–6914. [Google Scholar]
- Miller, G.A. WordNet. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A Collaboratively Created Graph Database for Structuring Human Knowledge. In Proceedings of the 2008 ACM SIGMOD international conference on Management of data-SIG-MOD’08, Vancouver, BC, Canada, 9–12 June 2008; ACM Press: New York, NY, USA, 2008; pp. 1247–1250. [Google Scholar]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. DBpedia: A Nucleus for a Web of Open Data. In Proceedings of the Semantic Web: 6th International Semantic Web Conference, 2nd Asian Semantic Web Conference, ISWC 2007+ ASWC 2007, Busan, Korea, 11–15 November 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 722–735. [Google Scholar]
- Carlson, A.; Betteridge, J.; Kisiel, B.; Settles, B.; Hruschka, E.; Mitchell, T. Toward an architecture for never-ending language learning. In Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence, Atlanta, Georgia, 11–15 July 2010; pp. 1306–1313. [Google Scholar]
- Roopak, N.; Deepak, G. OntoKnowNHS: Ontology driven knowledge centric novel hybridised semantic scheme for image recommendation using knowledge graph. In Proceedings of the Iberoamerican Knowledge Graphs and Semantic Web Conference, Kingsville, TX, USA, 22–24 November 2021; Springer: Cham, Switzerland, 2021; pp. 138–152. [Google Scholar]
- Li, L.; Li, H.; Kou, G.; Yang, D.; Hu, W.; Peng, J.; Li, S. Dynamic Camouflage Characteristics of a Thermal Infrared Film Inspired by Honeycomb Structure. J. Bionic Eng. 2022, 19, 458–470. [Google Scholar] [CrossRef]
- Wu, X.; Tang, Y.; Zhou, C.; Zhu, G.; Song, J.; Liu, G. An Intelligent Search Engine Based on Knowledge Graph for Power Equipment Management. In Proceedings of the 2022 5th International Conference on Energy, Electrical and Power Engineering (CEEPE), Chongqing, China, 22–24 April 2022; pp. 370–374. [Google Scholar]
- Shi, M. Knowledge graph question and answer system for mechanical intelligent manufacturing based on deep learning. Math. Probl. Eng. 2021, 2021, 6627114. [Google Scholar] [CrossRef]
- Su, X.; He, J.; Ren, J.; Peng, J. Personalized Chinese Tourism Recommendation Algorithm Based on Knowledge Graph. Appl. Sci. 2022, 12, 10226. [Google Scholar] [CrossRef]
- Ding, J.H.; Jia, W.J. A Review of Knowledge Graph Completion Algorithms. Inf. Commun. Technol. 2018, 12, 56–62. [Google Scholar]
- Dong, X.; Gabrilovich, E.; Heitz, G.; Horn, W.; Lao, N.; Murphy, K.; Strohmann, T.; Sun, S.; Zhang, W. Knowledge vault: A web-scale approach to probabilistic knowledge fusion. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; ACM: Rochester, NY, USA, 2014; pp. 601–610. [Google Scholar]
- Wang, Q.; Mao, Z.; Wang, B.; Guo, L. Knowledge graph embedding: A survey of approaches and applications. IEEE Trans. Knowl. Data Eng. 2017, 29, 2724–2743. [Google Scholar] [CrossRef]
- Chang, L.; Zhu, M.; Gu, T.; Bin, C.; Qian, J.; Zhang, J. Knowledge graph embedding by dynamic translation. IEEE Acess 2017, 23, 20898–20907. [Google Scholar] [CrossRef]
- Bordes, A.; Weston, J.; Collobert, R.; Bengio, Y. Learning structured embeddings of knowledge based. In Proceedings of the AAAI 2011, San Francisco, CA, USA, 7–11 August 2011; AAAI: Menlo Park, CA, USA, 2011; pp. 301–306. [Google Scholar]
- Bordes, A.; Glorot, X.; Weston, J.; Bengio, Y. A semantic matching energy function for learning with multi-relational data. Mach. Learn. 2014, 94, 233–259. [Google Scholar] [CrossRef] [Green Version]
- Socher, R.; Chen, D.; Manning, C.D.; Ng, A. Reasoning with Neural Tensor Networks for Knowledge Base Completion. In Proceedings of the 27th Annual Conference on Neural Information Processing Systems 2013, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 926–934. [Google Scholar]
- Nickel, M.; Tresp, V.; Kriegel, H.P. A three-way model for collection learning on multi-Relational data. In Proceedings of the ICML 2011, Washington, DC, USA, 28 June–2 July 2011; ACM: New York, NY, USA, 2011; pp. 809–816. [Google Scholar]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 2787–2795. [Google Scholar]
- Liang, Z.; Yang, J.; Liu, H.; Huang, K.; Qu, L.; Cui, L.; Li, X. SeAttE: An Embedding Model Based on Separating Attribute Space for Knowledge Graph Completion. Electronics 2022, 11, 1058. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge graph embedding by translating on hyperplanes. In Proceedings of the 28th AAAI Conference on Artificial Intelligence, Palo Alto, CA, USA, 27–31 July 2014; pp. 1112–1119. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of the AAAI, Austin, TX, USA, 25–30 January 2015; AAAI: Menlo Park, CA, USA, 2015; pp. 2181–2187. [Google Scholar]
- Ji, G.; He, S.; Xu, L.; Liu, K.; Zhao, J. Knowledge graph embedding via dynamic mapping matrix. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing of the Asian Federation of Natural Language Processing, Beijing, China, 27–31 July 2015; pp. 687–696. [Google Scholar]
- Fan, M.; Zhou, Q.; Chang, E.; Zheng, F. Transition-based knowledge graph embedding with relational mapping properties. In Proceedings of the Twenty-Eighth Pacific Asia Conference on Language, Information and Computation, Phuket, Thailand, 12–14 December 2014; pp. 328–337. [Google Scholar]
- Ji, G.; Liu, K.; He, S.; Zhao, J. Knowledge graph completion with adaptive sparse transfermatrix. In Proceedings of the National Conference on Artificial Intelligence, Amsterdam, The Netherlands, 10–11 November 2016; pp. 985–991. [Google Scholar]
- Nguyen, D.Q.; Sirts, K.; Qu, L.; Johnson, M. STransE: A novel embedding model of entities and relationships in knowledge bases. In Proceedings of the NAACL HLT, San Diego, CA, USA, 12–17 June 2016; ACL: Stroundsburg, PA, USA, 2016; pp. 460–466. [Google Scholar]
- Xiao, H.; Huang, M.; Hao, Y.; Zhu, X. TransA: An adaptive approach for knowledge graph embedding. arXiv 2015, arXiv:1509.05490, 2015. [Google Scholar]
- Ji, S.; Pan, S.; Cambria, E.; Marttinen, P.; Philip, S.Y. A survey on knowledge graphs: Representation, acquisition, and applications. IEEE T Rans. Neural Netw. Learn. Syst. 2021, 33, 494–514. [Google Scholar] [CrossRef] [PubMed]
- Lei, Z.; Sun, Y.; Nanehkaran, Y.A.; Yang, S.; Islam, M.S.; Lei, H.; Zhang, D. A novel data-driven robust framework based on machine learning and knowledge graph for disease esification. Future Gener. Comput. Syst. 2020, 102, 534–548. [Google Scholar] [CrossRef]
- Sun, Z.Q.; Deng, Z.H.; Nie, J.Y.; Tang, J. RotatE: Knowledge graph embedding by relation in complex space [EB/OL]. arXiv 2019, arXiv:1902.10197. [Google Scholar]
- Zhang, Z.; Cai, J.; Zhang, Y.; Wang, J. Learning hierarchy -aware knowledge graph embeddings for link prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 9–11 February 2020; Volume 34, pp. 3065–3072. [Google Scholar]
- Tang, Y.; Huang, J.; Wang, G.; He, X.; Zhou, B. Orthogonal Relation Transforms with Graph Context Modeling for Knowledge Graph Embedding. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, 5–10 July 2020; pp. 2713–2722. [Google Scholar]
- Han, X.; Cao, S.; Lv, X.; Lin, Y.; Liu, Z.; Sun, M.; Li, J. Openke: An Open Toolkit for Knowledge Embedding. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Brussels, Belgium, 31 October–4 November 2018; pp. 139–144. [Google Scholar]
- Wang, Y.; Ruffinelli, D.; Gemulla, R.; Broscheit, S.; Meilicke, C. On evaluating embedding models for knowledge base completion. arXiv 2018, arXiv:1810.07180, 2018. [Google Scholar]
- Toutanova, K.; Chen, D. Observed versus latent features for knowledge base and text inference. In Proceedings of the 3rd Workshop on Continuous Vector Space Models and Their Compositionality, Beijing, China, 31 July 2015; pp. 57–66. [Google Scholar]
- Han, Z.; Chen, Y.; Li, M.; Liu, W.; Yang, W. An efficient node influence metric based on triangle in complex networks. Acta Phys. Sin. 2016, 65, 168901. [Google Scholar]
- Hu, X.; Tao, Y.; Chung, C.W. I/O-efficient algorithms on triangle listing and counting. ACM Trans. Database Syst. 2014, 39, 1–30. [Google Scholar] [CrossRef]
- Zhang, Y.; Yao, Q.; Shao, Y.; Chen, L. NSCaching: Simple and Efficient Negative Sampling for Knowledge Graph Embedding. In Proceedings of the IEEE International Conference on Data Engineering, Macao, China, 8–11 April 2019; pp. 614–625. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Wang, P.; Li, S.; Pan, R. Incorporating GAN for negative sampling in knowledge representation learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Cai, L.; Wang, W.Y. Kbgan: Adversarial learning for knowledge graph embeddings. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics, New Orleans, LA, USA, 1–6 June 2018; Volume 1, pp. 1470–1480. [Google Scholar]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A K-Means clustering algorithm. J. R. Stat. Soc. 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Hamerly, G.; Elkan, C. Alternatives to the K-Means algorithm that find better clusterings. In Proceedings of the 11th International Conference on Information and Knowledge Management, McLearn, VA, USA, 4–9 November 2002; pp. 600–607. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Dai, C.; Chen, L.; Li, B.; Li, Y. Link prediction in multi-relational networks based on relational similarity. Inf. Sci. 2017, 394–395, 198–216. [Google Scholar] [CrossRef]
- Wang, P.; Liu, J.; Hou, D.; Zhou, S. A Cybersecurity Knowledge Graph Completion Method Based on Ensemble Learning and Adversarial Training. Appl. Sci. 2022, 12, 12947. [Google Scholar] [CrossRef]
- Dettmers, T.; Minervini, P.; Stenetorp, P.; Riedel, S. Convolutional 2D knowledge graph embeddings. In Proceedings of the AAAI, New Orleans, LA, USA, 2–3 February 2018; pp. 1811–1818. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbols | Concepts |
|---|---|
| The entity set of the knowledge graph | |
| The relation set of the knowledge graph | |
| Head entity, relation, and tail entity, respectively. , | |
| The embedding vector of | |
| The triplet set of the knowledge graph | |
| The triplet in the knowledge graph, | |
| The negative triplet set generated | |
| The negative triplet that is not in the knowledge graph, |
| Dataset | #Entity | #Relation | #Train | #Valid | #Test |
|---|---|---|---|---|---|
| WN18RR | 40,943 | 11 | 86,835 | 3034 | 3134 |
| FB15K237 | 14,541 | 237 | 272,115 | 17,535 | 20,466 |
| WN18 | 40,943 | 18 | 141,442 | 5000 | 5000 |
| FB15K | 14,951 | 1345 | 483,142 | 50,000 | 59,071 |
| FB15K237 | WN18RR | FB15K | WN18 | |
|---|---|---|---|---|
| 80 | 80 | 150 | 80 | |
| 0.0001 | 0.0001 | 0.0005 | 0.0005 | |
| 5 | 5 | 4 | 4 | |
| 1000 | 1000 | 2000 | 1000 | |
| k | 50 | 50 | 50 | 50 |
| s | 30 | 30 | 30 | 30 |
| 2 | 2 | 2 | 2 | |
| epoch | 3000 | 3000 | 3000 | 3000 |
| Model | Score Function |
|---|---|
| TransE | |
| TransH | |
| TransR | |
| TransD |
| Model | Dateset | WN18RR | FB15K237 | ||||
|---|---|---|---|---|---|---|---|
| Metrics | MR | MRR | Hits@10 | MR | MRR | Hits@10 | |
| TransE | Bernoulli | 3924 | 0.1784 | 0.4509 | 197 | 0.2556 | 0.4189 |
| Kbgan | 5356 | 0.1808 | 0.4324 | 722 | 0.2926 | 0.4659 | |
| NSCaching | 4472 | 0.2002 | 0.4783 | 186 | 0.2993 | 0.4764 | |
| CCS | 4481 | 0.2031 | 0.4809 | 182 | 0.3101 | 0.4802 | |
| TransH | Bernoulli | 4113 | 0.1862 | 0.4509 | 202 | 0.2329 | 0.4010 |
| Kbgan | 4881 | 0.1869 | 0.4481 | 455 | 0.2779 | 0.4619 | |
| NSCaching | 4491 | 0.2041 | 0.4804 | 185 | 0.2832 | 0.4659 | |
| CCS | 4337 | 0.2273 | 0.4894 | 187 | 0.2897 | 0.4726 | |
| TransR | Bernoulli | 3824 | 0.1884 | 0.4603 | 191 | 0.2397 | 0.4201 |
| Kbgan | 4572 | 0.1871 | 0.4521 | 793 | 0.2424 | 0.4431 | |
| NSCaching | 3639 | 0.2010 | 0.4822 | 181 | 0.2751 | 0.4773 | |
| CCS | 3801 | 0.2300 | 0.4891 | 174 | 0.2822 | 0.4830 | |
| TransD | Bernoulli | 3555 | 0.1901 | 0.4641 | 188 | 0.2451 | 0.4289 |
| Kbgan | 4083 | 0.1875 | 0.4641 | 825 | 0.2465 | 0.4440 | |
| NSCaching | 3104 | 0.2013 | 0.4839 | 189 | 0.2863 | 0.4785 | |
| CCS | 3317 | 0.2415 | 0.5297 | 177 | 0.2890 | 0.4852 | |
| Model | WN18RR | FB15K237 | ||||
|---|---|---|---|---|---|---|
| MR | MRR | Hits@10 | MR | MRR | Hits@10 | |
| Op-TransE | 4171 | 0.2122 | 0.5102 | 177 | 0.2415 | 0.4852 |
| Op-TransH | 4404 | 0.2307 | 0.5121 | 180 | 0.2893 | 0.4815 |
| Op-TransR | 3685 | 0.2415 | 0.5217 | 169 | 0.2993 | 0.4873 |
| Op-TransD | 3352 | 0.2900 | 0.5425 | 182 | 0.3010 | 0.4924 |
| MR | MRR | Hits@1 | Hits@3 | Hits@10 | |
|---|---|---|---|---|---|
| TransE | 251 | 0.779 | 0.709 | 0.820 | 0.892 |
| CCS + TransE | 237 | 0.792 | 0.728 | 0.822 | 0.925 |
| Op-TransE | 223 | 0.803 | 0.711 | 0.836 | 0.937 |
| MR | MRR | Hits@1 | Hits@3 | Hits@10 | |
|---|---|---|---|---|---|
| TransE | 125 | 0.451 | 0.297 | 0.418 | 0.471 |
| CCS + TransE | 84 | 0.524 | 0.302 | 0.603 | 0.682 |
| Op-TransE | 77 | 0.550 | 0.371 | 0.617 | 0.744 |
| Predicting Head (Hits@10) | Predicting Tail (Hits@10) | |||||||
|---|---|---|---|---|---|---|---|---|
| 1-to-1 | 1-to-N | N-to-1 | N-to-N | 1-to-1 | 1-to-N | N-to-1 | N-to-N | |
| TransE | 0.437 | 0.657 | 0.182 | 0.472 | 0.437 | 0.197 | 0.667 | 0.500 |
| Op-TransE | 0.503 | 0.776 | 0.231 | 0.523 | 0.514 | 0.232 | 0.747 | 0.685 |
| TransH | 0.668 | 0.876 | 0.287 | 0.645 | 0.655 | 0.398 | 0.833 | 0.672 |
| Op-TransH | 0.759 | 0.893 | 0.315 | 0.741 | 0.759 | 0.400 | 0.841 | 0.717 |
| TransR | 0.788 | 0.892 | 0.341 | 0.692 | 0.792 | 0.374 | 0.904 | 0.721 |
| Op-TransR | 0.796 | 0.927 | 0.339 | 0.765 | 0.793 | 0.378 | 0.925 | 0.817 |
| TransD | 0.861 | 0.955 | 0.398 | 0.785 | 0.854 | 0.506 | 0.944 | 0.812 |
| Op-TransD | 0.874 | 0.962 | 0.441 | 0.822 | 0.881 | 0.566 | 0.958 | 0.854 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, H.; Li, X.; Wu, K. Op-Trans: An Optimization Framework for Negative Sampling and Triplet-Mapping Properties in Knowledge Graph Embedding. Appl. Sci. 2023, 13, 2817. https://doi.org/10.3390/app13052817
Han H, Li X, Wu K. Op-Trans: An Optimization Framework for Negative Sampling and Triplet-Mapping Properties in Knowledge Graph Embedding. Applied Sciences. 2023; 13(5):2817. https://doi.org/10.3390/app13052817
Chicago/Turabian StyleHan, Huixia, Xinyue Li, and Kaijun Wu. 2023. "Op-Trans: An Optimization Framework for Negative Sampling and Triplet-Mapping Properties in Knowledge Graph Embedding" Applied Sciences 13, no. 5: 2817. https://doi.org/10.3390/app13052817