
Classification of Bugs in Cloud Computing Applications Using Machine Learning Techniques

 ,
,  , ,
, ,  ,
,
Abstract
1. Introduction
1.1. Problem Statement
1.2. Objective of Our Studies
- To design a machine learning model that can classify the bugs from cloud-based applications’ errors.
- To predict the priority of bugs from classified bugs.
- To achieve the best possible results and accuracy for bug classification and prioritization.
1.3. Significance of Work
2. Literature Review
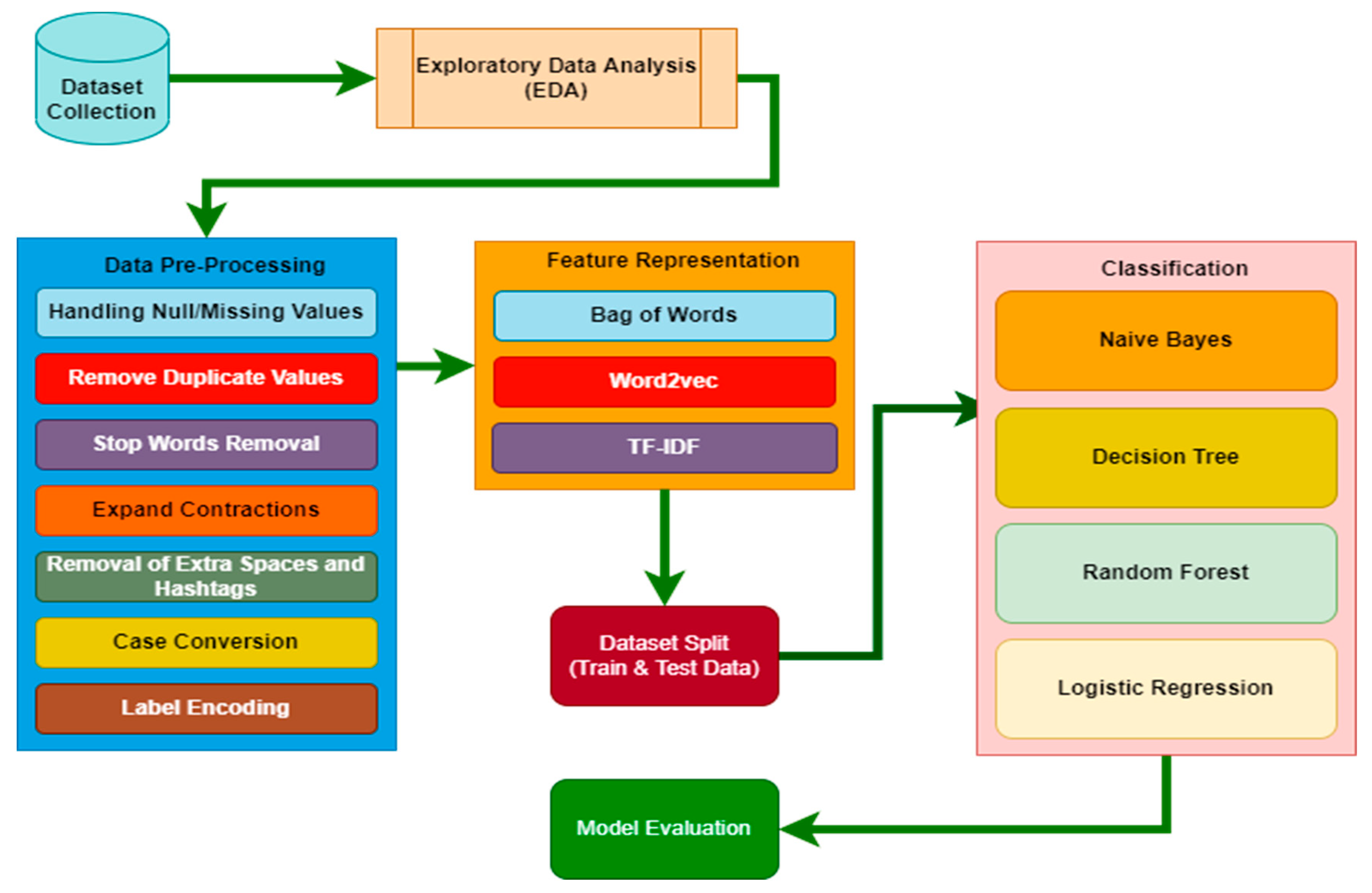
3. Solution Design and Implementation
3.1. Dataset Description
3.2. Dataset Preprocessing
4. Result and Analysis
- Naive Bayes
- Decision tree
- Random forest
- Logistic regression
- Three vectorization techniques (Bag-of-words, TF-IDF and Wfigord2vec).
- Parameter tuning using Randomized SearchCV (for both BOW and TF-IDF).
- Comparative analysis of four models based on Accuracy, Precision, Recall, and F1-score.
5. Comparative Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kim, J. Deep Learning vs. Machine Learning vs. AI: An InDepth Guide, readspeaker.ai, 3 May 2021. Available online: https://www.readspeaker.ai/blog/deep-learning-vs-machine-learning/ (accessed on 16 July 2022).
- Thota, M.K.; Shajin, F.H.; Rajesh, P. Survey on software defect prediction techniques. Int. J. Appl. Sci. Eng. 2020, 17, 331–344. [Google Scholar] [CrossRef]
- Iqbal, S.; Naseem, R.; Jan, S.; Alshmrany, S.; Yasar, M.; Ali, A. Determining Bug Prioritization Using Feature Reduction and Clustering With Classification. IEEE Access 2020, 8, 215661–215678. [Google Scholar] [CrossRef]
- Umer, Q.; Liu, H.; Sultan, Y. Emotion Based Automated Priority Prediction for Bug Reports. IEEE Access 2018, 6, 35743–35752. [Google Scholar] [CrossRef]
- Harer, J.A.; Kim, L.Y.; Russell, R.L.; Ozdemir, O.; Kosta, L.R.; Rangamani, A.; Hamilton, L.H.; Centeno, G.I.; Key, J.R.; Ellingwood, P.M.; et al. Automated software vulnerability detection with machine learning. arXiv 2018, arXiv:1803.04497. [Google Scholar]
- Waqar, A. Software Bug Prioritization in Beta Testing Using Machine Learning Techniques. J. Comput. Soc. 2020, 1, 24–34. [Google Scholar]
- Huda, S.; Liu, K.; Abdelrazek, M.; Ibrahim, A.; Alyahya, S.; Al-Dossari, H.; Ahmad, S. An Ensemble Oversampling Model for Class Imbalance Problem in Software Defect Prediction. IEEE Access 2018, 6, 24184–24195. [Google Scholar] [CrossRef]
- Goyal, A.; Sardana, N. Empirical Analysis of Ensemble Machine Learning Techniques for Bug Triaging. In Proceedings of the 2019 Twelfth International Conference on Contemporary Computing (IC3), Noida, India, 8–10 August 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Gupta, A.; Sharma, S.; Goyal, S.; Rashid, M. Novel XGBoost Tuned Machine Learning Model for Software Bug Prediction. In Proceedings of the 2020 International Conference on Intelligent Engineering and Management (ICIEM), London, UK, 17–19 June 2020; pp. 376–380. [Google Scholar] [CrossRef]
- Ahmed, H.A.; Bawany, N.Z.; Shamsi, J.A. CaPBug-A Framework for Automatic Bug Categorization and Prioritization Using NLP and Machine Learning Algorithms. IEEE Access 2021, 9, 50496–50512. [Google Scholar] [CrossRef]
- Sarwar, M.I.; Iqbal, M.W.; Alyas, T.; Namoun, A.; Alrehaili, A.; Tufail, A.; Tabassum, N. Data Vaults for Blockchain-Empowered Accounting Information Systems. IEEE Access 2021, 9, 117306–117324. [Google Scholar] [CrossRef]
- Leotta, M.; Olianas, D.; Ricca, F. A large experimentation to analyze the effects of implementation bugs in machine learning algorithms. Future Gener. Comp. Syst. 2022, 133, 184–200. [Google Scholar] [CrossRef]
- Hai, T.; Zhou, J.; Li, N.; Jain, S.K.; Agrawal, S.; Dhaou, I.B. Cloud-based bug tracking software defects analysis using deep learning. J. Cloud. Comp. 2022, 11. [Google Scholar] [CrossRef]
- Pandey, N.; Sanyal, D.K.; Hudait, A.; Sen, A. Automated classification of software issue reports using machine learning techniques: An empirical study. Innov. Syst. Softw. Eng. 2017, 13, 279–297. [Google Scholar] [CrossRef]
- Tabassum, N.; Alyas, T.; Hamid, M.; Saleem, M.; Malik, S. Hyper-Convergence Storage Framework for EcoCloud Correlates. Comput. Mater. Contin. 2022, 70, 1573–1584. [Google Scholar] [CrossRef]
- Catolino, G.; Palomba, F.; Zaidman, A.; Ferrucci, F. Not all bugs are the same: Understanding, characterizing, and classifying bug types. J. Syst. Softw. 2019, 152, 165–181. [Google Scholar] [CrossRef]
- Kukkar, A.; Mohana, R. A Supervised Bug Report Classification with Incorporate and Textual field Knowledge. Procedia Comput. Sci. 2018, 132, 352–361. [Google Scholar] [CrossRef]
- Shuraym, Z. An efficient classification of secure and non-secure bug report material using machine learning method for cyber security. Mater. Today Proc. 2021, 37, 2507–2512. [Google Scholar] [CrossRef]
- Kukkar, A.; Mohana, R.; Nayyar, A.; Kim, J.; Kang, B.-G.; Chilamkurti, N. A Novel Deep-Learning-Based Bug Severity Classification Technique Using Convolutional Neural Networks and Random Forest with Boosting. Sensors 2019, 19, 2964. [Google Scholar] [CrossRef] [PubMed]
- Dam, H.K.; Pham, T.; Ng, S.W.; Tran, T.; Grundy, J.; Ghose, A.; Kim, C.J. Lessons learned from using a deep tree-based model for software defect prediction in practice. In Proceedings of the IEEE International Working Conference on Mining Software Repositories, Montreal, QC, Canada, 26–27 May 2019; pp. 46–57. [Google Scholar] [CrossRef]
- Bani-Salameh, H.; Sallam, M.; Al Shboul, B. A deep-learning-based bug priority prediction using RNN-LSTM neural networks. E-Inform. Softw. Eng. J. 2021, 15, 29–45. [Google Scholar] [CrossRef]
- Ramay, W.Y.; Umer, Q.; Yin, X.C.; Zhu, C.; Illahi, I. Deep Neural Network-Based Severity Prediction of Bug Reports. IEEE Access 2019, 7, 46846–46857. [Google Scholar] [CrossRef]
- Polat, H.; Polat, O.; Cetin, A. Detecting DDoS Attacks in Software-Defined Networks Through Feature Selection Methods and Machine Learning Models. Sustainability 2020, 12, 1035. [Google Scholar] [CrossRef]
- Umer, Q.; Liu, H.; Illahi, I. CNN-Based Automatic Prioritization of Bug Reports. IEEE Trans. Reliab. 2020, 69, 1341–1354. [Google Scholar] [CrossRef]
- Ni, Z.; Li, B.; Sun, X.; Chen, T.; Tang, B.; Shi, X. Analyzing bug fix for automatic bug cause classification. J. Syst. Softw. 2020, 163, 110538. [Google Scholar] [CrossRef]
- Aung, T.W.W.; Wan, Y.; Huo, H.; Sui, Y. Multi-triage: A multi-task learning framework for bug triage. J. Syst. Softw. 2022, 184, 111133. [Google Scholar] [CrossRef]
- Hirsch, T. Using textual bug reports to predict the fault category of software bugs. Array 2022, 15, 100189. [Google Scholar] [CrossRef]
- Wu, H. A spatial–temporal graph neural network framework for automated software bug triaging. Knowl. Based Syst. 2022, 241, 108308. [Google Scholar] [CrossRef]

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SR# | Attribute | Description | DataType |
|---|---|---|---|
| 1 | Unnamed | The column has unique ID’s against each record. | Integer |
| 2 | Title | The column contains all text of error as a record. | Object |
| 3 | Type | Label column. | Integer |
| Title | Type |
|---|---|
| Doc strings omitted from AST | Performance |
| Upload failed (400): Digests do not match on .tar.gz ending with x0d binary code | Resource usage |
| ConfigParser writes a superfluous final bank line | Performance |
| csv.reader() to support QUOTE_ALL | Crash |
| IDLE: make smart indent after comments line consistent | Performance |
| xml.etree.Elementinclude does not include nested xincludes | Crash |
| Add Py_BREAKPOINT and sys._breakpoint hooks | Crash |
| documentation of ZipFile file name encoding | Performance |
| Allow ‘continue’ in ‘finally’ clause | Crash |
| Move unwinding od stack for “pseudo exceptions” from interpreter to compile | Crash |
| Improve regular expression HOWTO | Crash |
| Windows python cannot handle an early PATH entry containing “…” and python.exe | Enhancement |
| tkinter after_cancel does not behave correctly when called with id=None | Performance |
| PEP 1: Allow provisional status for PEPs | Crash |
| os.chdir(), os.getcwd() may crash on windows in presence of races | Enhancement |
| tk busy command | Crash |
| os.chdir() may leak memory on windows | Compiler error |
| Sr# | Dataset | BOW | TF-IDF | Word2vec | PT—BOW | PT—TFIDF |
|---|---|---|---|---|---|---|
| 1 | Imbalance | Train: 86.43 Test: 66.66 | Train: 81.42 Test: 65.28 | Train: 98.47 Test: 34.16 | Train: 64.98 Test: 65.13 | Train: 66.19 Test: 66.19 |
| 2 | Balance | Train: 91.66 Test: 83.54 | Train: 91.89 Test: 84.11 | Train: 92.11 Test: 41.29 | Train: 93.34 Test: 87.01 | Train: 97.14 Test: 88.18 |
| Sr# | Dataset | BOW | TF-IDF | Word2vec | PT—BOW | PT—TFIDF |
|---|---|---|---|---|---|---|
| 1 | Imbalance | Train: 100 Test: 62.89 | Train: 100 Test: 61.88 | Train: 99.81 Test: 43.11 | Train: 99.52 Test: 64.02 | Train: 100 Test: 65 |
| 2 | Balance | Train: 100 Test: 86.14 | Train: 99.98 Test: 85.56 | Train: 99.28 Test: 43.12 | Train: 100 Test: 88.45 | Train: 100 Test: 87.79 |
| Sr# | Dataset | BOW | TF-IDF | Word2vec | PT—BOW | PT—TFIDF |
|---|---|---|---|---|---|---|
| 1 | Imbalance | Train: 100 Test: 66.54 | Train: 100 Test: 66.03 | Train: 99.81 Test: 57.91 | Train: 100 Test: 64.84 | Train: 100 Test: 65.53 |
| 2 | Balance | Train: 100 Test: 89.52 | Train: 99.24 Test: 88.76 | Train: 100 Test: 58.12 | Train: 100 Test: 90.86 | Train: 100 Test: 91.73 |
| Sr# | Dataset | BOW | TF-IDF | Word2vec | PT—BOW | PT—TFIDF |
|---|---|---|---|---|---|---|
| 1 | Imbalance | Train: 95.44 Test: 66.28 | Train: 84.33 Test: 65.66 | Train: 48.47 Test: 46.60 | Train: 66.66 Test: 65.78 | Train: 67.14 Test: 66.16 |
| 2 | Balance | Train: 90.52 Test: 87.52 | Train: 92.24 Test: 86.22 | Train: 40.12 Test: 42.15 | Train: 93.37 Test: 88.27 | Train: 90.03 Test: 85.55 |
| SR# | Classifier | Training Accuracy | Test Accuracy |
|---|---|---|---|
| 1 | Naive Bayes | 93.84% | 87.01% |
| 2 | Decision tree | 100% | 88.45% |
| 3 | Random forest | 100% | 91.73% |
| 4 | Logistic regression | 93.37% | 88.27% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tabassum, N.; Namoun, A.; Alyas, T.; Tufail, A.; Taqi, M.; Kim, K.-H. Classification of Bugs in Cloud Computing Applications Using Machine Learning Techniques. Appl. Sci. 2023, 13, 2880. https://doi.org/10.3390/app13052880
Tabassum N, Namoun A, Alyas T, Tufail A, Taqi M, Kim K-H. Classification of Bugs in Cloud Computing Applications Using Machine Learning Techniques. Applied Sciences. 2023; 13(5):2880. https://doi.org/10.3390/app13052880
Chicago/Turabian StyleTabassum, Nadia, Abdallah Namoun, Tahir Alyas, Ali Tufail, Muhammad Taqi, and Ki-Hyung Kim. 2023. "Classification of Bugs in Cloud Computing Applications Using Machine Learning Techniques" Applied Sciences 13, no. 5: 2880. https://doi.org/10.3390/app13052880
APA StyleTabassum, N., Namoun, A., Alyas, T., Tufail, A., Taqi, M., & Kim, K.-H. (2023). Classification of Bugs in Cloud Computing Applications Using Machine Learning Techniques. Applied Sciences, 13(5), 2880. https://doi.org/10.3390/app13052880