Vehicle detection has gained considerable attention in the research community in the past two decades. In this section, we briefly discuss the recent advances in the vehicle detection domain. For readers’ fair understanding, we categorize the literature into two streams as illustrated below.
2.2. YOLO-Based Methods
In [
12] a vision-based object detection and recognition framework for autonomous driving was proposed with particular emphasis on: (i) an optimized model based on the structure of YOLOv4 was presented to detect 10 types of objects; (ii) a fine-tuned part affinity fields approach was developed; (iii) eXplainable Artificial Intelligence (XAI) was integrated to assist the approximations in the risk evaluation phase; (iv) an intricate self-driving dataset was developed, which included several different subsets for each relevant task; and (v) an end-to-end system with a high-accuracy model was discussed.
The overall parameters of enhanced YOLOv4 are reduced by 74%, which meets the real-time capacity. Moreover, when evaluated with other methods, the detection precision of the enhanced YOLOv4 improved by 2.6%. In [
13], a novel and efficient detector named YOLO-ACN is developed, which is inspired by the high detection accuracy and speed of YOLOv3. This technique is improved by the addition of an attention mechanism, a CIoU (complete intersection over union) loss function, Soft-NMS, and depth wise separable convolution. In this method, initially, the attention mechanism is built in the channel and spatial dimensions in each residual block focus on small targets. Later, CIoU loss is adopted to achieve accurate bounding box regression. Besides, to filter out a more accurate BBox and avoid deleting occluded objects in dense images, the CIoU is applied in the Soft-NMS, and the Gaussian model in the Soft-NMS is employed to suppress the surrounding BBox. Finally, to improve the detection speed, standard convolution is replaced by depth wise separable convolution. Meanwhile, a hard-swish activation function is utilized in deeper layers.
In [
14], a multi-stage object detection architecture, which authors refer as Cascade R-CNN, is developed to address objects appearance and detection. The proposed R-CNN is composed of a sequence of detectors that are trained with varying IoU thresholds, to be sequentially more discriminating against close false positives. These detectors are trained stage-to-stage and by leveraging the scrutiny that the output of a detector is a good distribution for training the next higher stage detector. The resampling of improved hypotheses assures that all detectors have a positive set of examples of equivalent size, and thus reducing the overfitting. The same systematic method is applied at inference, enabling a closer match between the hypotheses and the detector quality of each stage. A simple implementation of the Cascade R-CNN is shown to surpass all single-model object detectors on the challenging COCO dataset. Simulations also reveal that the Cascade R-CNN is widely applicable across detector architectures and achieves consistent gains of the baseline detector strength.
A method to detect smoky vehicles with high precision and speed has been proposed in [
15] using an enhanced lightweight network based on Yolov5. This work uses Mobilenetv3-small modified Yolov5s’ backbone to reduce the number of model parameters and calculations. A vehicle exhaust dataset is collected and created to detect motor vehicle exhaust with high precision. Cutout and saturation transformations were used to enlarge the self-built dataset, which was eventually expanded to 6102 photos, due to the interference of vehicle shadows and occlusion between vehicles. The results demonstrate that applying data augmentation improves detection accuracy by 8.5%. The upgraded network is installed on embedded devices and has a detection speed of 12.5 FPS, which is two times faster than Yolov5. Only 0.48 million network parameters have been improved. This study suggests an effective target detection model as well as a strategy for developing low-cost and quick vehicle exhaust detection equipment. An effective nighttime vehicle detection approach is developed in [
16]. First, an optimal MSR algorithm was used to improve the original nighttime photos. The improved photos were then used to fine-tune a pre-trained YOLO v3 network. Finally, the network was employed to distinguish vehicles from each other and outperforming two popular object detection approaches, the Faster R-CNN and SSD, in terms of precision and detection efficiency. The suggested method has an average precision of 93.66%, which is 6.14% and 3.21% higher than the Faster R-CNN and SSD, respectively.
In [
17], the proposed work contributed to the field of autonomous driving through the DL techniques to detect objects. This work primarily uses the YOLO to locate numerous objects on the roads and categorized into the type that they belong to with the aid of bounding boxes. The YOLOv4 weights are used to custom train the model to detect the objects, and the data is acquired using the OIDv4 toolkit from the open-source data collection. In [
18], an updated YOLOv3 algorithm for vehicle detection is developed. Initially, it clusters the data set using a clustering analysis approach, then optimizes the network structure to raise the number of final output grids and boost the comparatively low vehicle prediction ability. It also optimizes the data set as well as the input image. Its robustness under various external situations is due to its resolution. Experiments demonstrate that the modified YOLOv3 algorithm outperforms the traditional approach in terms of detection accuracy and rate. In [
19], researchers proposed the newest YOLOv3 algorithm to detect traffic participants. They trained the network for five different object classes, which are vehicle, truck, pedestrian, traffic signs, and lights. This work also discusses the range of driving scenarios that include bright and overcast sky, snow, fog, and night conditions. In [
20], the baseline YOLO is used to detect moving cars. Meanwhile, a modified Kalman filter method is used to dynamically track the detected vehicles, which results in overall competitive performance in both day and night. The testing results reveal that the system is resistant to occluding vehicles or congested highways, with an average vehicle counting accuracy of 92.11% at the rate of 2.55 FPS. In [
21], researchers suggested an updated Yolov3 transfer learning-based deep learning algorithm for object detection. In this work, the network is trained on a difficult data set, and the output is fast and precise, which is beneficial for applications that need object detection. In [
22], a method is proposed that classifies vehicular traffic on video using a neural network. The necessity to regulate traffic on the roads has emerged as the number of vehicles on the road has increased, resulting in traffic congestion and a high accident rate. Collecting data from video of vehicles on the road will aid in the creation of statistics that can be used to efficiently consider traffic regulation on the roads. The challenge of vehicle categorization on video was solved using the YOLOv5 powerful real-time object classification method. For neural network training 750 images from outdoor surveillance camera were used as a dataset. After testing the model, the recognition accuracy was 89%.
YOLOv2 and YOLO9000 models were discussed in [
23]. Their strength in real-time detection and classification of objects in videos made them useful in several applications. The YOLOv2 is very efficient at detecting and classifying simple objects. The GPU features and the Anchor Box approach were used to accomplish the desired speed and precision. Furthermore, YOLOv2 can accurately detect object movement in video recordings. YOLO9000 is a real-time framework that can maximize detection and classification while also bridging the gap. The YOLOv2 model and the YOLO 9000 detection system can detect and classify a wide range of items, from multiple occurrences of a single object to multiple instances of various objects. In [
24], an improved YOLOv4-based video stream vehicle target detection system was used to address the problem of slow detection speed. This study first presents a theoretical overview of the YOLOv4 algorithm, then offers an algorithmic technique for increasing detection speed, and lastly conducts real road tests. According to the experimental results, the algorithm in this work can improve detection speed without sacrificing accuracy, which can be used to make decisions for safe vehicle driving.
In [
25], the YOLOv5 is used to locate weighty supplies vehicles during cold weather and thus allowed the prediction of parking place slots in real-time. The authors employ infrared network cameras, since snowy conditions and the polar night in the winter pose certain obstacles for image recognition. Authors used the YOLOv5 to analyze if the front cabin and back are adequate features to identify heavy goods vehicles because these photos repeatedly have large overlaps. The trained algorithm reliably distinguishes the front of heavy goods vehicles. However, detecting the back cabin appears to be more difficult, especially when the vehicle is placed far away from the camera. Finally, they show that detecting heavy goods vehicles utilizing their front and rear instead of the entire vehicle improves detection during winters, which mostly experience difficult images with significant objects overlaps and cut-offs.
Recently, some of the learning-based approaches [
26] and the CNN based methods [
27] also report encouraging results in the vehicle detection domain. In [
26], authors developed a box-free instance segmentation method using semi-supervised iterative learning. The iterative learning procedure considered labeling vehicles from the entire scene and then trained the deep learning model for classification. Authors also considered vehicle interiors and borders to isolate instances using a semantic segmentation. In [
27], researchers performed a fully convolutional regression network. In this method the training stage uses an input image along with its ground to describe each vehicle as a 2-D Gaussian function distribution. Hence, the vehicle’s original format attains a simplified elliptical shape in the ground truth and output images. The vehicle segmentation uses a fixed threshold in the predicted density map to generate a binary mask. This method prevents grouping cars and favors counting. Moreover, vehicles take on a different form that is expressed by the Gaussian function.
In [
28], a robust vehicle detection model is developed, which is referred to as YOLOv4_AF. This model introduces an attention mechanism that suppresses the interference features of images through channel length and spatial dimension. In addition, a modification of the Feature Pyramid Network (FPN) part of the Path Aggregation Network (PAN) is also applied to enhance the effective features. This way, the objects are steadily positioned in the 3D space that ultimately improves the vehicle object detection and classification performance. In [
29], vehicle detection and tracking are achieved through a multi-scale deep convolution neural network. This work also applies conventional Gaussian mixture probability hypothesis along with hierarchical data association that divides into detection-to-track and track-to-track associations. Moreover, the cost matrix of each stage is resolved using the Hungarian algorithm. Only detection information is used in the previous so as to achieve rapid execution. In [
30], Faster-RCNN is tuned to detect vehicles in various scenarios. Moreover, this work also uses basic image processing methods along with morphological operations and multiple thresholding to achieve vehicle exact location in near-real-time. In [
31], vehicle and distance detection method is developed in a virtual environment. This work mainly uses the Yolo v5s neural network structure and develops a novel neural network system, which the authors refer as the Yolo v5-Ghost. In the discussed approach, the authors further fine-tuned the network layer structure of the Yolo v5s. Experiments performed therein indicate that this method is suitable to be deployed in real-time environments. The authors of this work also claim that their work is suitable for embedded and edge devices and object detection in general [
32]. In [
33], a novel bounding box regression loss approach is developed that learns objects bounding box through miscellaneous transformations and variance localizations. The learned localization variance is further merged during non-maximum suppression that increases the localization performance. In [
34], a dynamic vehicle detection method, which is based on a likelihood-field-based model and on Coherent Point Drift (CPD), is developed. This study also applies an adaptive thresholding on the distance and grid angular resolutions to detect the moving vehicles. This work also presents the pose estimation that is based on the CPD to estimate the vehicle pose. The scaling series algorithm is also coupled with a Bayesian filter to update the vehicle localization states during various intervals.
In [
35], a new Multi-Level Feature Pyramid Network (MLFPN) is proposed that constructs effective feature pyramids to detect objects. This method initially fuses multi-level features and later feeds the base features into a block of alternating joint thinned U-shape networks. Meanwhile, the decoder layers are gathered up with correspondent sizes to build a feature pyramid for object detection. In [
36], the proposed method is primarily based on Trident Network (TridentNet), which aims to generate scale-specific feature maps. This scheme also constructs parallel multi-branches in which each branch shares the same transformation parameters. This algorithm also adopts a scale-aware training scheme to specialize each branch by sampling object instances of proper scales for training. The proposed TridentNet achieves significant improvements without any additional parameters. In [
37], a single-stage method uses Mask SSD to investigate objects. This work uses a convolutional series to predict pixelwise objects’ separation. This work also optimizes the whole network through multitask loss function. Ultimately, the network directly predicts final objects presence results. This work also uses multi-scale and feedback features that perform well on various objects of different scales and aspect ratios. In [
38], the developed method uses two classifiers to tackle the problem of failure to locate vehicles that have occlusions or slight interference. It accomplishes vehicle detection through a local binary pattern along with a support vector machine. This method also uses the CNN in the second phase to remove the interference areas between vehicles and any moving object.
In [
39], a novel CornerNet is developed achieve accurate object detection. The CornerNet approach detects objects bounding box as a pair of keypoints. The top-left corner and the bottom-right corners are localized through a single CNN. Through an intelligent paired keypoints approach, this method eliminates the need to design a set of anchor boxes that are normally used in prior single-stage detectors. This work also introduces corner pooling, which is a new type of pooling layer and helps the network to better visualize and localize the objects’ corners. In [
40], a novel approach, which authors refer to as Mask R-CNN, is discussed that extends Faster R-CNN by adding a new branch to predict an object mask. The Mask R-CNN is simple to train and adds only a small overhead to Faster R-CNN. Moreover, Mask R-CNN is easy to generalize to other tasks, for instance to estimate object orientation in the same framework. This method is conceptually simple and flexible and efficiently detects objects in an image. In [
41], an anchor-free vehicle detection approach is developed that is capable of detecting arbitrarily oriented vehicles in high-resolution images. This work considers vehicles as a multitask learning problem and predicts high-level vehicle features via a fully convolutional network. In this work, initially, coarse and fine feature maps outputted from different stages of a residual network are integrated through a feature pyramid fusion. Later, four convolutional layers are added to predict possible vehicle features. In [
42], a scale-insensitive CNN (SINet) is proposed to locate vehicles with a large variance of scales. Initially, a context-aware RoI pooling is done to maintain the contextual information and original structure of objects. Later, a multi-branch decision mechanism is introduced to minimize the intra-class distance of various features. The proposed techniques can be further equipped with any deep network architectures and keep them trained end-to-end.
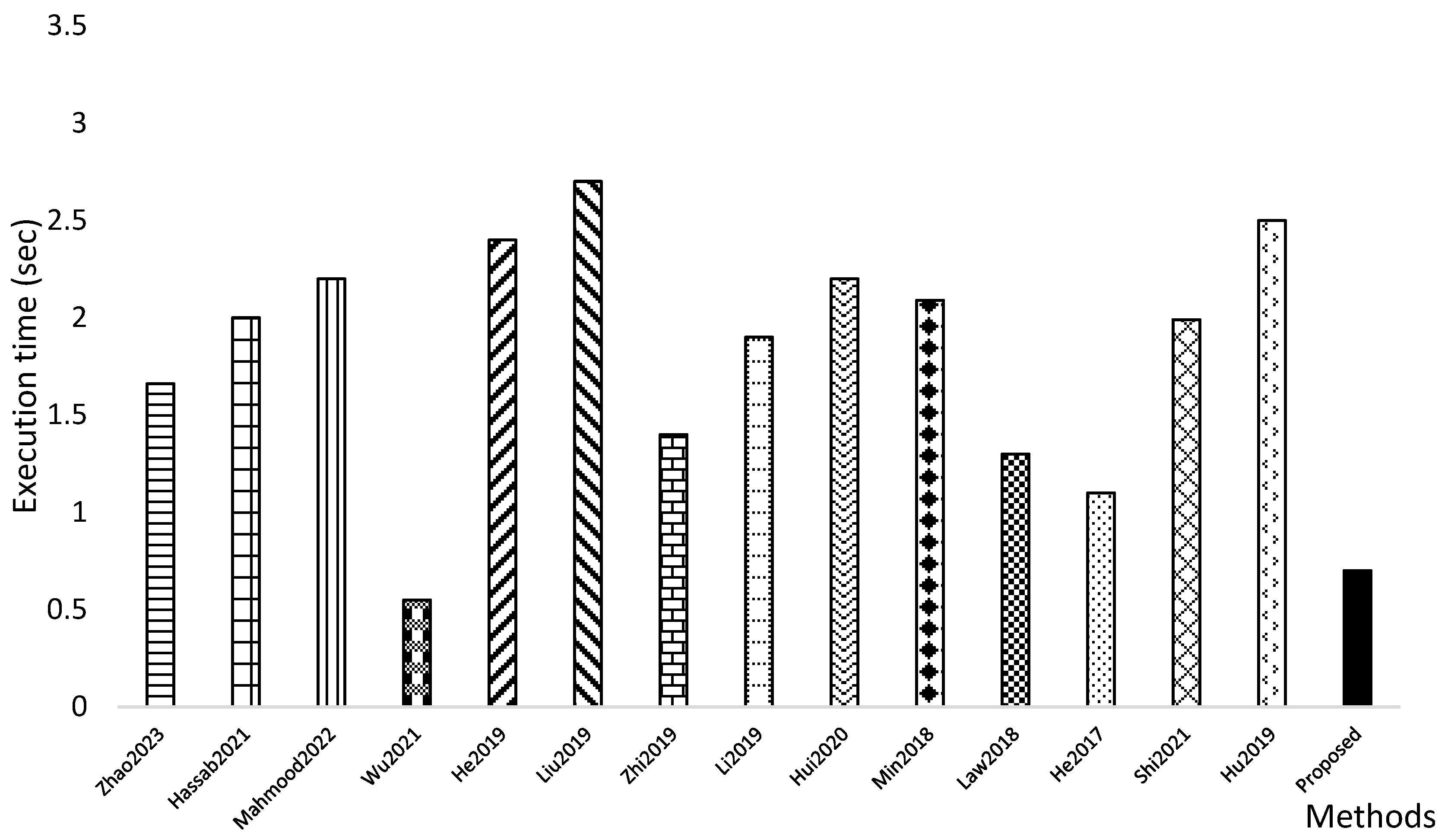
The preceding discussion offers a good suggestion that vehicle detection is a crucial step to develop systematic mechanisms, such as an intelligent transportation system. The methods describe above are a few of the efficient and good works that aim to address the vehicle detection problem in various environments. As we will see in
Section 4, different datasets are publicly available to address the vehicle detection problem under diverse conditions. We believe that our work is an efficient addition in the vehicle detection domain. In the next section, we discuss our developed vehicle detection method.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}