
An Empirical Analysis of State-of-Art Classification Models in an IT Incident Severity Prediction Framework

 , , and
, , and
Abstract
1. Introduction
- Multi-modal Unstructured Data: Incident reports often contain text and numerical information.
- Mixing Data: Incident reports with similar content could be linked to a significant outage or only a minor problem.
- Imbalanced Data: Many incident reports are often related to minor incidents, rather than major incidents.
1.1. Scope and Problem Definition
1.2. Contributions
- We proposed a novel framework for automating the prediction of major incidents to mitigate risks associated with the escalation of incidents. We aimed to transform reactive major incident management to proactive, within IT infrastructure.
- We presented different possible solutions to handle the imbalances in the major incident report (MIR) and non-major incident report (NMIR) records in the dataset.
- We then conducted a comparative analysis of state-of-art classification models designed to predict major IT incidents.
2. Background

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Pre-Processing | Feature Engineering | Techniques | Ref |
|---|---|---|---|---|
| Open-source data of Endava helpdesk operators | anonymization, lowercasing, lemmatizing, stemming, noise removal | No | CNN, RF, GB, average and stack ensemble | [24] |
| ITIL CHM department | removing stop words, punctuation, turning to lowercase, stemming | linguistic Features | TF-IDF and KNN, decision tree, NB, LR, SVM, QUICKSUCCESS | [25] |
| Fast-food restaurant chain | DateTime column named closed ticket transform from string to DateTime format. | feature extraction was performed based on daily data. Irrelevant features were removed. The feature was selected based on probability theory. | NB, LR, and gradient boosting decision tree model | [26] |
| IT department from a big multinational company | tokenization, stop word and digits removal, word stemming, and part-of-speech filtering by selecting only open grammatical classes | word count per solution category against text data. | TF-IDF and multinomial naive Bayes SVM, KNN, decision tree, and logistic regression | [27] |
| IBM Tivoli monitoring system | No | No | HMDB and ICTR model | [28] |
| German Jordanian University. | remove HTML tags and special characters | TF-IDF feature vectorization | SVM, NB, rule-based, and decision tree | [29] |
| IT infrastructural incident data | remove stop words, special characters, date and time, phone number, and email address | Chi-squared was used to select important features using TFIDF vectorizer. Top 1000 important feature selected. | NB, SVM, and Ada SVM | [30] |
| IBM CMDB dataset | keywords and their annotations as classification features | Selecting top Configuration Item records from CMDB to prevent complexity. TF-IDF was used to give importance | SVM | [31] |
| Incident issue tracking system of Istanbul Technical University data | purifying of tickets from HTML and numerical expression tags was carried out | Bag of words using TF-IDF | decision trees, SVM, KNN, and NB | [32] |
| Confidential data of IT Company | tokenization, stop words removal, and stemming | part of speech tagging was performed to filter out vocabulary | SVM | [19] |
| Real-world incident ticket data | tokenization, stop words removal and stemming | TFIDF | SVM | [33] |
| Real-world IT infrastructure service desk ticket data | remove stop words, special character, date and time, phone number, and email address | TF-IDF | LR, K-NN, MNB and SVM | [34] |
| Organization ticket data | lemmatization, POS tagging | TFIDF with Jaccard coefficient filtration | k-means clustering, Jaccard distance, and cosine distance | [35] |
| UCI ML repository | No | embedding | relational graph convolutional networks | [36] |
| Case study data | No | TFIDF | SVM using RBF kernel and XGBoost | [37] |
| IBM real-time dataset | HTML tag removal, Unicode inconsistencies, header/footer/entities replacement | semantic role sampling | BERT | [17] |
| Telco trouble ticket dataset | remove punctuation and stop words | TFIDF | random forest, DL, gradient boosting, XGBoost, and extremely randomized trees classifiers | [38] |
| Service Now dataset in IT help desk and ticketing | remove punctuation and stop words | Doc2vec using ServiceNow ticketing system | logistic regression | [18] |
| Tickets dataset of service level agreement | remove punctuation and stop words, URL. | Count Vectorizer | decision trees, SVM, KNN and NB | [39] |
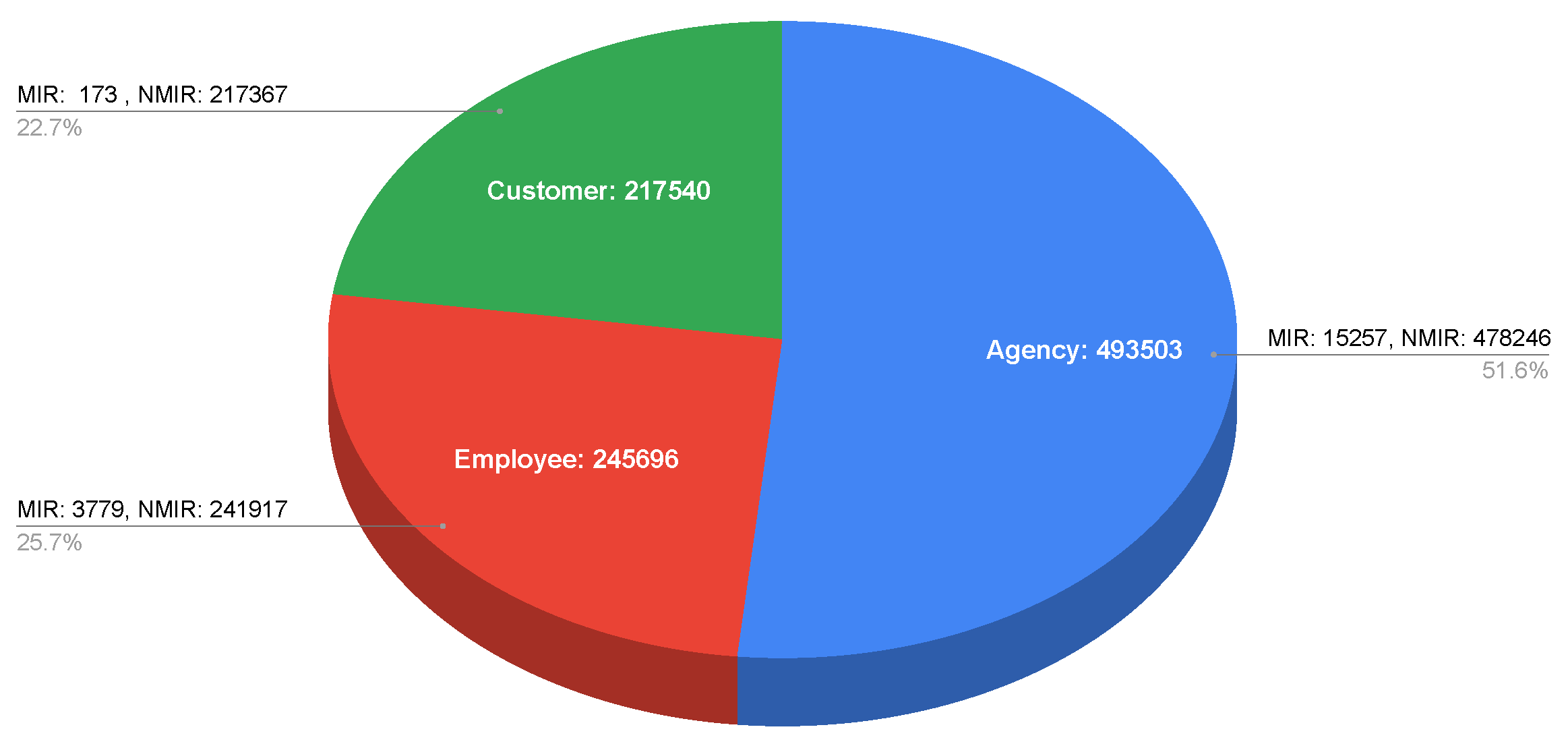
3. Dataset Description
- MIR: “Why am I unable to print from any application? All staff is unable to print. No error message.”
- Non-MIR: “How do I update Java? Outlook web version running slow.”
4. Proposed Framework
- NB [42]: Naive Bayes classifier is based on Bayes theorem and is one of the popular ML algorithms for classification. NB is a simple probabilistic model that assumes that each feature or variable of the same class makes an independent and equal contribution to the outcome. Our dataset was divided into a feature matrix and a target vector. The feature matrix (X) contained all the vectors (rows) of the dataset, in which each vector consisted of the value of dependent features. We assumed that the number of features were d, while the target vector (y) contained the value of the class variable for each row, according to its feature matrix. The feature matrix (X) was the incident description reported in the database system. The target (y) value would either be MIR or NMIR. In this instance, was the probability of the class y (for MIR or NMIR), according to the incident description (X). The maximum probability function provided the classification label, either MIR or NMIR.
- GB [43]: Gradient boosting classifier is an approach developed to train a weak hypothesis iteratively to arrive at a better hypothesis. Gradient boosting combines the previous model with the next generated model to minimize the prediction error. It minimizes the loss function iteratively, starting with a negative gradient, i.e., a weak hypothesis. In this work, we performed a binary classification (MIR or NMIR) using the description column of the incident. The algorithm began with one leaf node that predicted the initial value for each description of the incident. Next, the algorithm used the of the target value, yielding an average survival value assigned to our initial leaf node. If the probability of surviving exceeded , we first classified every sample in the training dataset as MIR. (Note: where was a common threshold value associated with binary classification decision based on probability).
- XGBoost [44]: Extreme gradient boosting is an optimized GB technique that provides efficient, flexible, and portable tree model results. It offers parallel tree boosting that provides solutions quickly and accurately. XGBoost is efficient for open-source implementation and significantly distributed environments, such as Hadoop, Sun Grid Engine (SGE), and Message Passing Interface (MPI). It predicts the residual or error of prior models to obtain its final predictions. The gradient descent algorithm minimizes loss when adding new models. We trained the model with 500 trees and a depth (max_depth) of 1 (for the root node). As compared to other available boosting techniques, e.g., GB, XGBoost was fast, memory efficient, and highly accurate [45].
- Catboost [46]: Category and boosting adopts minimal variance sampling, a type of stochastic gradient boosting with weighted sampling. In this instance, the weighted sampling occurred at the tree level and not the split level. It grows as a balanced tree; the split score minimizes the loss and maximizes the accuracy score. Changing policy parameters (with a penalty function at level nodes) is also possible. In contrast to a traditional approach, this study addressed the MIR and NMIR classification problems. We trained the model with 400 trees and a depth (max_depth) of 1 (root node only). As compared to the XGBoost, Catboost was twice as fast with better accuracy [47].
- SVM [48]: Support vector machines utilize associated learning to analyze data for classification. Based on the descriptions of known incidents, SVM built a model that assigned MIR or NMIR labels to new incidents. The algorithm considered all incident descriptions and mapped them to a space that maximized the distance between the two classes. In the context of this study, we had a training dataset of incident descriptions labeled “0” for MIR and “1” for NMIR, where is either 0 or 1, each denoting to a point , where each is a p-dimensional real vector. We were interested in the maximum-margin hyperplane that divided the group of points , for which from the group of points for which , which was defined so that the distance between the hyperplane and the nearest point from either group was maximized. Any hyperplane could be written as the set of points x, satisfying , where w was the (not necessarily normalized) normal vector to the hyperplane. This was similar to Hesse’s normal form, except that w was not necessarily a unit vector. The parameter determined the offset of the hyperplane from the origin along the normal vector W.
- Bi-LSTM [49]: Bi-directional long short-term memory is an improved version of the LSTM model (a variant of the recursive DL architecture) that can process data in both forward and backward directions. Bi-LSTM helps map models that allow for sequential dependencies in words and phrases. For our framework, Bi-LSTM assisted in training MIR and NMIR sequences by preserving this information using two independent RNN cells that stored the iterative states for a longer time. Bi-LSTM contained the IT incident input concatenated with hidden state , which was further forwarded to three gates (Forget, Input, and Output). The Input gate has an embedded gate known as an Update. The Update gate memorized the past and present sentence sequence. The value from the update gate multiplied the cell state , resulting in the hidden state or unit . Our Bi-LSTM architecture comprised five layers: one embedding layer with a size of 300, one bi-directional layer with 280 LSTM neurons, two dropout layers, and one classification layer (dense layer). The total number of trainable parameters for the model was 23,346,401.
- CNN [50]: Convolutional neural network is synonymous with image classification, but recently, it has significantly contributed to NLP. CNN is used to extract high-level feature functions from n-gram. For example, ref. [51] developed a word-embedding matrix layer that memorized the weights during the network training phase. We used our framework’s input labels (MIR or NMIR) as tokens to map to the word-embedding matrix. In this mapping, every convolutional filter mapped to each window of the embedding layer. In CNN, matrix reduction reduced the dimension of the matrix to a constant length. We executed the matrix reduction on every possible window. Each reduced matrix was the input for the fully connected layer. In the next layer, we used the activation function to create a single dimension input of features per tensor output; The global max pooling layer with 256 batch sizes and 23,027,144 trainable parameters were used. In the final layer, we applied the Softmax activation function to translate the real-probability values into MIR or NMIR labels.
- GRU [52]: Gated recurrent unit is an RNN DL variant that retains information for a longer time and improves the computing speed. GRU consists of two neural gates (Update and Reset gates) for updating the previous cell state and discarding the irrelevant state. For this purpose, we provided MIR or NMIR values as input , which concatenated with hidden states and moved to the Update gate. In the final phase, we used the Sigmoid activation function to maintain an output within the range of (0,1), resulting in an MIR or NMIR value. The architecture comprised 5 layers, containing one embedding layer with a size of 300 vectors, one GRU layer with 140 neurons, and one dense layer with a sigmoid activation function. The model had a total of 23,037,981 trainable parameters.
- BERT [14]: Bidirectional encoder representations from transformers consists of several encoder transformers within a pool of pre-trained models. BERT follows the bidirectional orientation of learning information from a sequence of words from left to right and right to left. Each encoder encapsulates two sub-layers: a self-attention layer and a feed-forward layer. We have employed a trained BERT architecture contain 12 layers of the encoder, 12 attention heads, 768 hidden sizes, and 110M trainable parameters. It was pre-trained on 800M unlabeled data extracted from BooksCorpus and 2500 M words from Wikipedia, and then, it was transferred to the incident prediction problem. We performed an additional preprocessing step for our dataset using the BERTtokenizer. It tokenized and reformatted the sequence of tokens by adding CLS (a classification token indicating the start of a sequence) and SEP tokens (appended to the end of the sequence). The length of our incident description token was less than 512 tokens; therefore, we utilized padding (PAD) to fill the unused token slots (further details below). Our BERT model output an embedding vector of 768 in each of the tokens and had 340M trainable parameters.
- ERNIE 2.0 [16]: Enhanced Representation through knowledge Integration (ERNIE) is a pre-trained framework that performs the training of new sequences with historically trained tasks. For text classification, ERNIE 2.0 has outperformed BERT with highly accurate results [16]. ERNIE 2.0 captures the contextual information with a series of shared text encoding layers, customized with recurrent neural networks or deep transformers with a stacked self-attention layer. Its multi-task learning encodes lexical, syntactic, and semantic information across tasks. When a new task arrives, this framework can incrementally train the distributed representations without forgetting the previously trained parameters. In our framework, we used 12 layers, 12 self-attention heads, and 768 dimensions in the hidden layer, resulting in 94M trainable parameters.
- RoBERTa [15]: Robustly optimized BERT emphasizes data being used for pre-training and the number of passes for training. The RoBERTa architecture was proposed to overcome the drawback of the original BERT model by increasing batch size from 256 to 8k, providing better speed for performance metrics [15]. We used a pre-trained transformer with built-in (vocab) 160GB in size for RoBERTa to conserve our computational resources. It reduced the perplexity of the masked language model by providing the provision to train with larger batches and longer sequences. It also provided the dynamic masking pattern over the training data during data preprocessing. In our framework, we implemented a large RoBERTa model with 12 encoder layers, 12 attention heads, and 768 dimensions in the hidden layer, resulting in 110M trainable parameters.
5. Experimental Setup
5.1. Pre-Processing
5.2. Tokenizer
5.3. Training
5.4. Validation
6. Result and Analysis
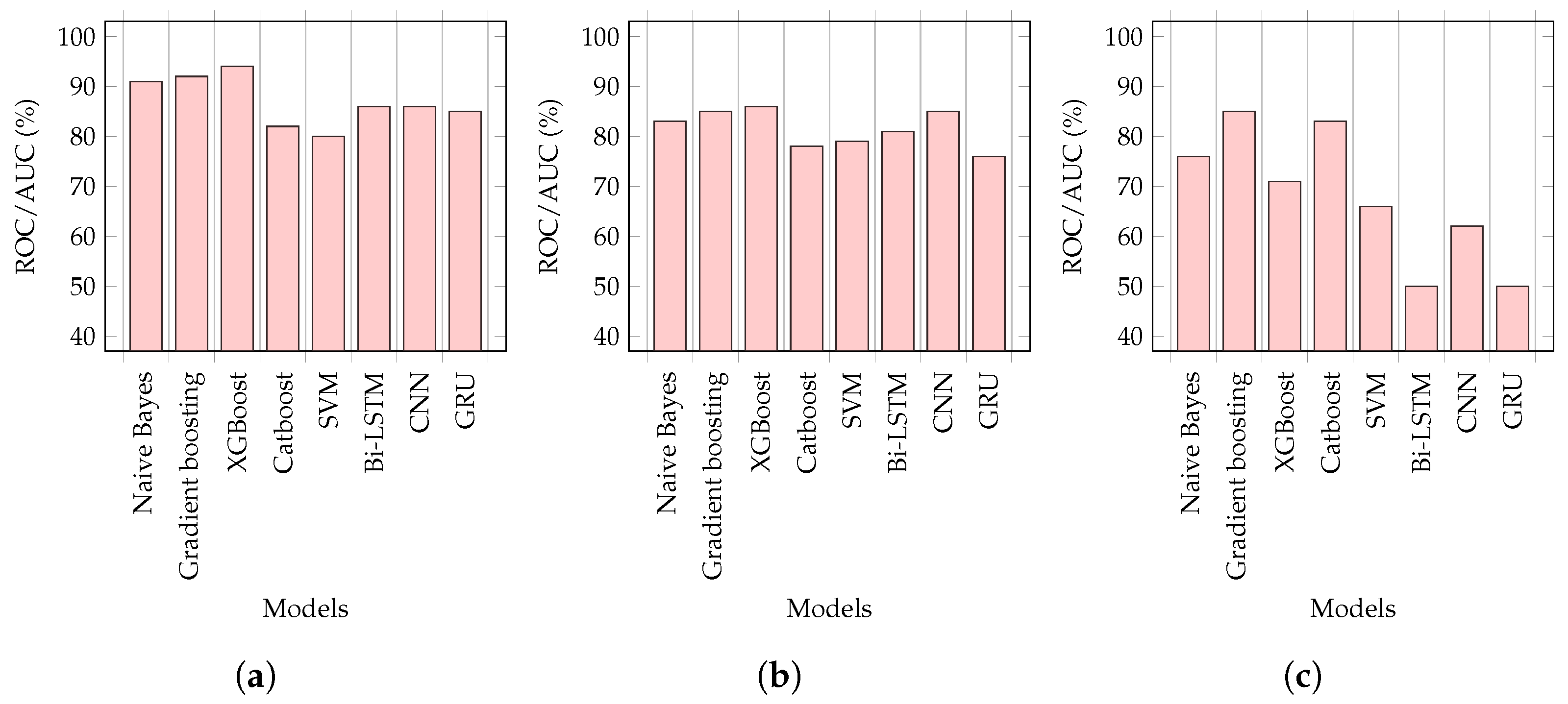
6.1. Tokenizer Analysis
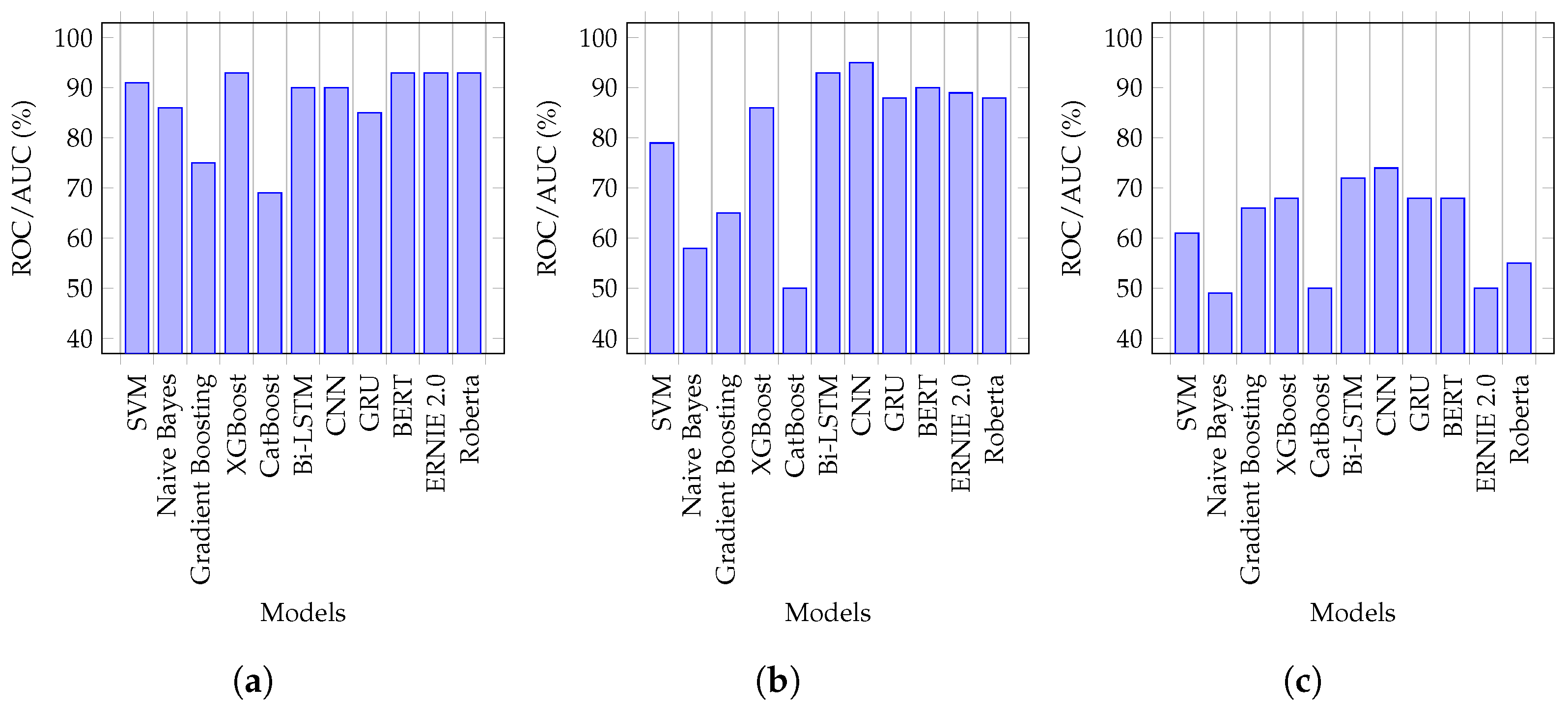
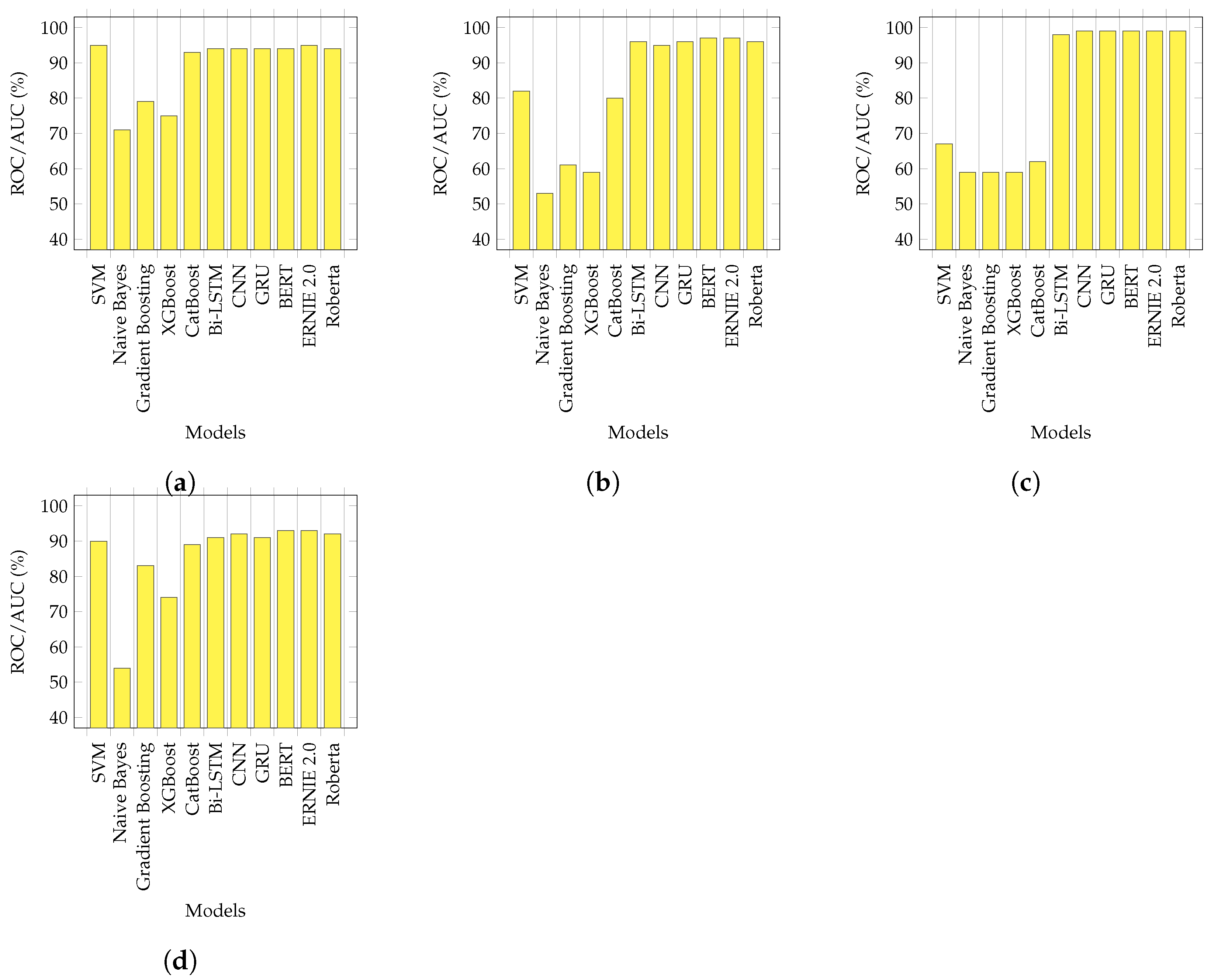
6.2. Quantitative Evaluation
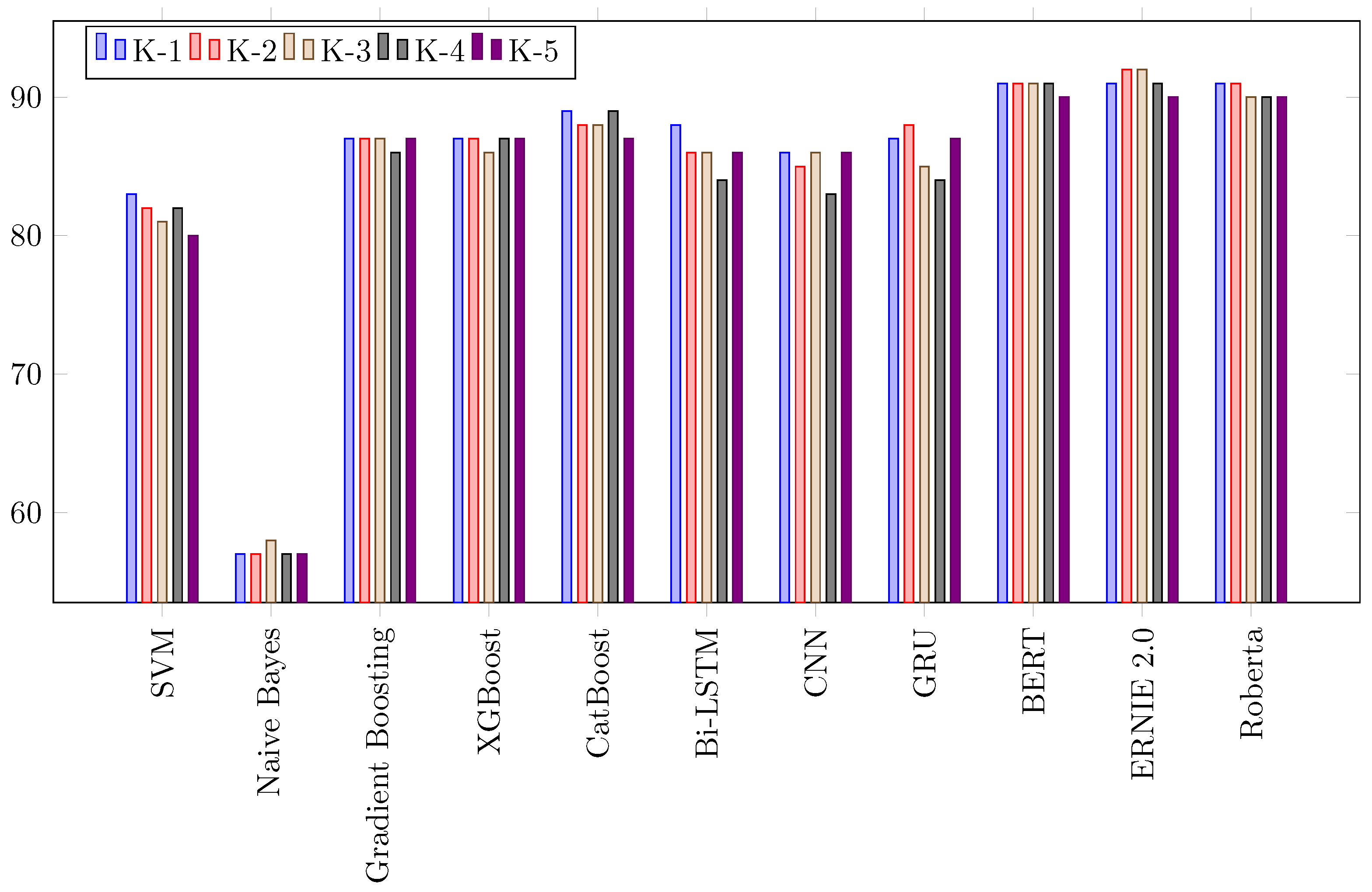
6.3. Cross Validation
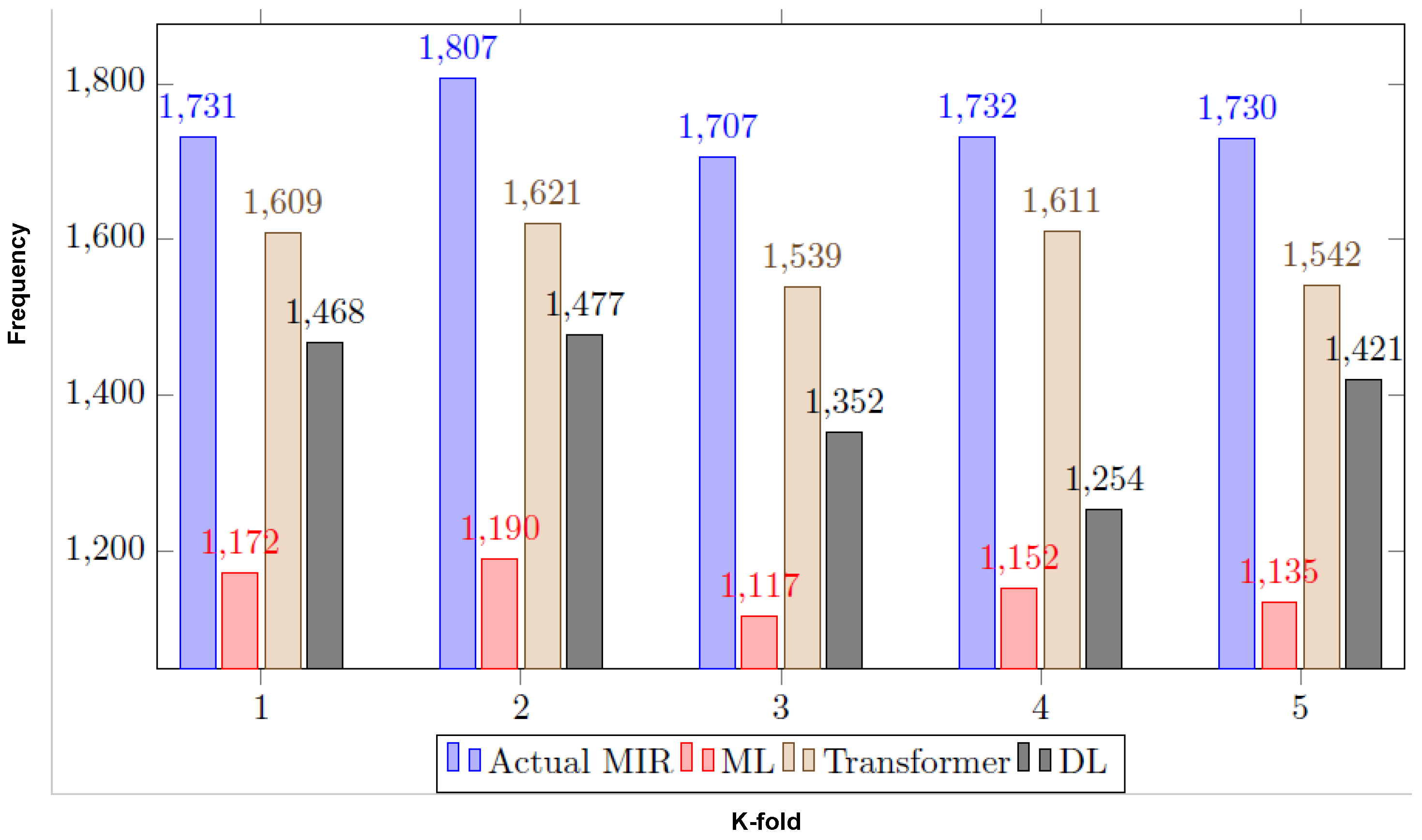
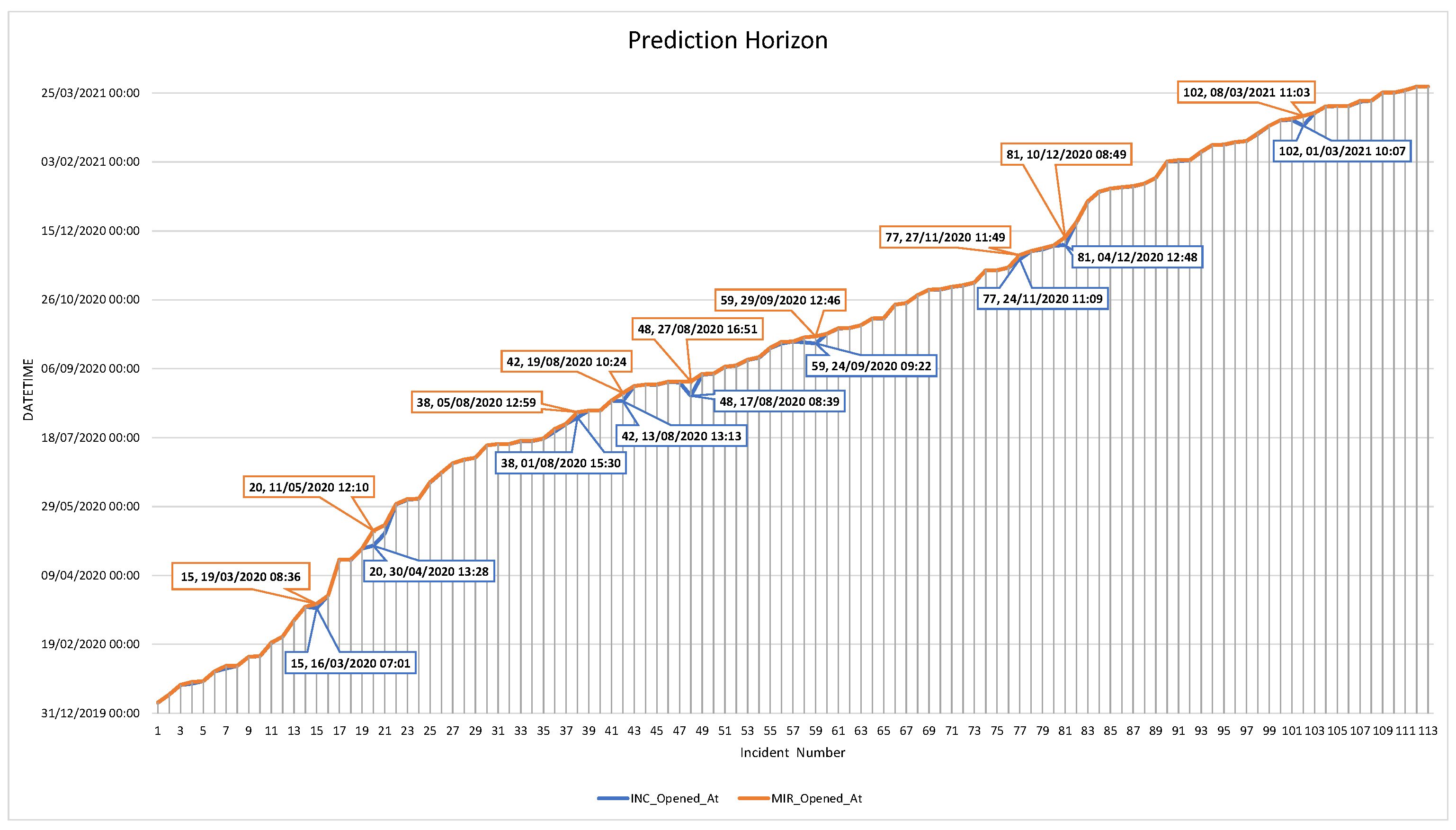
6.4. Mean-Time Resolution
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cortina, S.; Barafort, B.; Picard, M.; Renault, A. Using a Process Assessment Model to Prepare for an ISO/IEC 20000-1 Certification: ISO/IEC 15504-8 or TIPA for ITIL? In Proceedings of the Systems, Software and Services Process Improvement—23rd European Conference, EuroSPI 2016, Graz, Austria, 14–16 September 2016; Communications in Computer and Information Science; Kreiner, C., O’Connor, R.V., Poth, A., Messnarz, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; Volume 633, pp. 83–93. [Google Scholar] [CrossRef]
- Lou, J.G.; Lin, Q.; Ding, R.; Fu, Q.; Zhang, D.; Xie, T. Software analytics for incident management of online services: An experience report. In Proceedings of the 2013 28th IEEE/ACM International Conference on Automated Software Engineering (ASE), Silicon Valley, CA, USA, 11–15 November 2013; pp. 475–485. [Google Scholar]
- Bartolini, C.; Sallé, M.; Trastour, D. IT service management driven by business objectives An application to incident management. In Proceedings of the 2006 IEEE/IFIP Network Operations and Management Symposium NOMS 2006, Vancouver, BC, Canada, 3–7 April 2006; pp. 45–55. [Google Scholar]
- Takeshita, K.; Yokota, M.; Nishimatsu, K. Early network failure detection system by analyzing Twitter data. In Proceedings of the 2015 IFIP/IEEE International Symposium on Integrated Network Management (IM), Ottawa, ON, Canada, 11–15 May 2015; pp. 279–286. [Google Scholar]
- Zhou, W.; Tang, L.; Zeng, C.; Li, T.; Shwartz, L.; Grabarnik, G.Y. Resolution recommendation for event tickets in service management. IEEE Trans. Netw. Serv. Manag. 2016, 13, 954–967. [Google Scholar] [CrossRef]
- Zhou, W.; Li, T.; Shwartz, L.; Grabarnik, G.Y. Recommending ticket resolution using feature adaptation. In Proceedings of the 2015 11th International Conference on Network and Service Management (CNSM), Barcelona, Spain, 9–13 November 2015; pp. 15–21. [Google Scholar]
- Deljac, Ž.; Randić, M.; Krčelić, G. Early detection of network element outages based on customer trouble calls. Decis. Support Syst. 2015, 73, 57–73. [Google Scholar] [CrossRef]
- Glenn, J.S.; Rose, K.L. Establishing Governance for Project and Service Management. In Proceedings of the 2019 ACM SIGUCCS Annual Conference, SIGUCCS 2019, New Orleans, LA, USA, 3–6 November 2019; Haring-Smith, B., McIntosh, K.M., Lineberry, B., Eds.; ACM: New York, NY, USA, 2019; pp. 145–147. [Google Scholar] [CrossRef]
- Stoneburner, G.; Goguen, A.; Feringa, A. Risk Management Guide for Information Technology Systems; SP 800-30; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2022. [Google Scholar]
- Beresnev, A.; Gusarova, N. Comparison of Intelligent Classification Algorithms for Workplace Learning System in High-Tech Service-Oriented Companies. In Proceedings of the International Conference on Digital Transformation and Global Society, St. Petersburg, Russia, 17–19 June 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 363–372. [Google Scholar]
- Tolciu, D.T.; Sacarea, C.; Matei, C. Analysis of Patterns and Similarities in Service Tickets using Natural Language Processing. J. Commun. Softw. Syst. 2021, 17, 29–35. [Google Scholar] [CrossRef]
- Nikulin, V.; Shibaikin, S.; Vishnyakov, A. Application of machine learning methods for automated classification and routing in ITIL. J. Phys. Conf. Ser. 2021, 2091, 012041. [Google Scholar] [CrossRef]
- Kodepogu, K.R.; Annam, J.R.; Vipparla, A.; Krishna, B.V.N.V.S.; Kumar, N.; Viswanathan, R.; Gaddala, L.K.; Chandanapalli, S.K. A Novel Deep Convolutional Neural Network for Diagnosis of Skin Disease. Trait. Signal 2022, 39, 1873–1877. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Sun, Y.; Wang, S.; Li, Y.; Feng, S.; Tian, H.; Wu, H.; Wang, H. ERNIE 2.0: A continual pre-training framework for language understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8968–8975. [Google Scholar]
- Ali Zaidi, S.S.; Fraz, M.M.; Shahzad, M.; Khan, S. A multiapproach generalized framework for automated solution suggestion of support tickets. Int. J. Intell. Syst. 2022, 37, 3654–3681. [Google Scholar] [CrossRef]
- Gouryraj, S.; Kataria, S.; Swvigaradoss, J. Service Level Agreement Breach Prediction in ServiceNow. In Proceedings of the 2021 Third International Conference on Inventive Research in Computing Applications (ICIRCA), Coimbatore, India, 2–4 September 2021; pp. 689–698. [Google Scholar]
- Agarwal, S.; Aggarwal, V.; Akula, A.R.; Dasgupta, G.B.; Sridhara, G. Automatic problem extraction and analysis from unstructured text in IT tickets. IBM J. Res. Dev. 2017, 61, 4–41. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Zhao, H.; Lai, Z.; Leung, H.; Zhang, X. A Gentle Introduction to Feature Learning. In Feature Learning and Understanding; Springer: Berlin/Heidelberg, Germany, 2020; pp. 1–12. [Google Scholar]
- Al Qadi, L.; El Rifai, H.; Obaid, S.; Elnagar, A. A scalable shallow learning approach for tagging arabic news articles. Jordanian J. Comput. Inf. Technol. 2020, 6, 263–280. [Google Scholar]
- Ye, Y.; Ma, F.; Lu, Y.; Chiu, M.; Huang, J.Z. iSurfer: A Focused Web Crawler Based on Incremental Learning from Positive Samples. In Proceedings of the Advanced Web Technologies and Applications, 6th Asia-Pacific Web Conference, APWeb 2004, Hangzhou, China, 14–17 April 2004; Lecture Notes in Computer Science; Yu, J.X., Lin, X., Lu, H., Zhang, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; Volume 3007, pp. 122–134. [Google Scholar] [CrossRef]
- Revina, A.; Buza, K.; Meister, V.G. IT Ticket Classification: The Simpler, the Better. IEEE Access 2020, 8, 193380–193395. [Google Scholar] [CrossRef]
- Revina, A.; Buza, K.; Meister, V.G. Designing Explainable Text Classification Pipelines: Insights from IT Ticket Complexity Prediction Case Study. Interpret. Artif. Intell. A Perspect. Granul. Comput. 2021, 937, 293. [Google Scholar]
- Zuev, D.; Kalistratov, A.; Zuev, A. Machine learning in IT service management. Procedia Comput. Sci. 2018, 145, 675–679. [Google Scholar] [CrossRef]
- Costa, J.; Pereira, R.; Ribeiro, R. ITSM automation-Using machine learning to predict incident resolution category. In Proceedings of the 33rd International Business Information Management Association Conference: Education Excellence and Innovation Management through Vision 2020, IBIMA 2019, Granada, Spain, 10–11 April 2019; pp. 5819–5830. [Google Scholar]
- Wang, Q.; Zeng, C.; Iyengar, S.; Li, T.; Shwartz, L.; Grabarnik, G.Y. AISTAR: An intelligent system for online IT ticket automation recommendation. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 1875–1884. [Google Scholar]
- Al-Hawari, F.; Barham, H. A machine learning based help desk system for IT service management. J. King Saud Univ. Comput. Inf. Sci. 2021, 33, 702–718. [Google Scholar] [CrossRef]
- Paramesh, S.; Shreedhara, K. IT Help Desk Incident Classification using Classifier Ensembles. ICTACT J. Soft Comput. 2019, 9, 1980–1987. [Google Scholar]
- Gupta, R.; Prasad, K.H.; Mohania, M. Automating ITSM incident management process. In Proceedings of the 2008 International Conference on Autonomic Computing, Chicago, IL, USA, 2–6 June 2008; pp. 141–150. [Google Scholar]
- Altintas, M.; Tantug, A.C. Machine learning based ticket classification in issue tracking systems. In Proceedings of the International Conference on Artificial Intelligence and Computer Science (AICS 2014), Bandung, Indonesia, 15–16 September 2014; pp. 195–207. [Google Scholar]
- Silva, S.; Pereira, R.; Ribeiro, R. Machine learning in incident categorization automation. In Proceedings of the 2018 13th Iberian Conference on Information Systems and Technologies (CISTI), Caceres, Spain, 13–16 June 2018; pp. 1–6. [Google Scholar]
- Paramesh, S.; Shreedhara, K. Automated IT service desk systems using machine learning techniques. In Data Analytics and Learning; Springer: Berlin/Heidelberg, Germany, 2019; pp. 331–346. [Google Scholar]
- Roy, S.; Muni, D.P.; Tack Yan, J.J.Y.; Budhiraja, N.; Ceiler, F. Clustering and labeling IT maintenance tickets. In Proceedings of the International Conference on Service-Oriented Computing, Banff, AB, Canada, 10–13 October 2016; pp. 829–845. [Google Scholar]
- Schad, J.; Sambasivan, R.; Woodward, C. Predicting help desk ticket reassignments with graph convolutional networks. Mach. Learn. Appl. 2022, 7, 100237. [Google Scholar] [CrossRef]
- Aglibar, K.D.; Alegre, G.C.; Del Mundo, G.; Duro, K.F.; Rodelas, N. Ticketing System: A Descriptive Research on the Use of Ticketing System for Project Management and Issue Tracking in IT Companies. arXiv 2022, arXiv:2202.06213. [Google Scholar]
- YAYAH, F.C.; Ghauth, K.I.; TING, C.Y. The automated machine learning classification approach on telco trouble ticket dataset. J. Eng. Sci. Technol. 2021, 16, 4263–4282. [Google Scholar]
- Bajpai, H. Building ML Based Intelligent System to Analyze Production LSI (Live Site Incidents). Int. J. Eng. Adv. Technol. (IJEAT) 2021, 10, 41–46. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M.; Furht, B. Text Data Augmentation for Deep Learning. J. Big Data 2021, 8, 101. [Google Scholar] [CrossRef] [PubMed]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Webb, G.I.; Keogh, E.; Miikkulainen, R. Naïve Bayes. Encycl. Mach. Learn. 2010, 15, 713–714. [Google Scholar]
- Mayr, A.; Binder, H.; Gefeller, O.; Schmid, M. The evolution of boosting algorithms. Methods Inf. Med. 2014, 53, 419–427. [Google Scholar] [PubMed]
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V.; Tang, Y.; Cho, H.; Chen, K.; Mitchell, R.; Cano, I.; Zhou, T. Xgboost: Extreme Gradient Boosting; R Package; R Code Team: Vienna, Austria, 2015; pp. 1–4. [Google Scholar]
- Couronné, R.; Probst, P.; Boulesteix, A.L. Random forest versus logistic regression: A large-scale benchmark experiment. BMC Bioinform. 2018, 19, 270. [Google Scholar] [CrossRef]
- Dorogush, A.V.; Ershov, V.; Gulin, A. CatBoost: Gradient boosting with categorical features support. arXiv 2018, arXiv:1810.11363. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 30, 1–9. [Google Scholar]
- Suthaharan, S. Support vector machine. In Machine Learning Models and Algorithms for Big Data Classification; Springer: Berlin/Heidelberg, Germany, 2016; pp. 207–235. [Google Scholar]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- O’Shea, K.; Nash, R. An Introduction to Convolutional Neural Networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Collobert, R.; Weston, J. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 160–167. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the properties of neural machine translation: Encoder-decoder approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Bird, S.; Loper, E. NLTK: The Natural Language Toolkit. In Proceedings of the ACL Interactive Poster and Demonstration Sessions; Association for Computational Linguistics: Barcelona, Spain, 2004; pp. 214–217. [Google Scholar]
- Ling, C.X.; Huang, J.; Zhang, H. AUC: A Better Measure than Accuracy in Comparing Learning Algorithms. In Advances in Artificial Intelligence; Xiang, Y., Chaib-draa, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; pp. 329–341. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. Adv. Neural Inf. Process. Syst. 2018, 31, 1–11. [Google Scholar]
- Lagoudakis, M.G.; Parr, R. Reinforcement learning as classification: Leveraging modern classifiers. In Proceedings of the 20th International Conference on Machine Learning (ICML-03), Washington, DC, USA, 21–24 August 2003; pp. 424–431. [Google Scholar]
- Ramamurthy, R.; Sifa, R.; Bauckhage, C. NLPGym—A toolkit for evaluating RL agents on Natural Language Processing Tasks. 2020. Available online: http://xxx.lanl.gov/abs/2011.08272 (accessed on 30 August 2022).













| Column ID | Description | Values |
|---|---|---|
| Incident number | The unique internal code of the incident | INC123xxxx |
| Assignment group | The group to which the incident has been assigned. | |
| Opened at | Date/Timestamp of when created the incident record. | 17 March 2020 |
| Closed at | Date/Timestamp of when the incident record was closed. | 18 March 2020 |
| Incident severity | The level of impact for each incident. | (1—High; 2—Medium; 3—Low; 4—None) |
| CMDB | The name of the configuration management database associated with the incident | |
| Category | The category associated with the incident | |
| Short description | Brief information about the incident. | |
| Description | Detailed information about the incident. | |
| Status | The manual mapping from problem to incident. | (0—MIR; 1—Non-MIR). |
| MIR opened at | Date/timestamp of when created the MIR record. | 17 March 2020 |
| Incident opened at | Date/timestamp of when the incident record was opened. | 18 March 2020 |
| Classifier | Vocab_Size | Max_Features | Embedding_dim | Batch_Size | Filters | Kernel | Activation | Loss | Optimizer | Learning_Rate |
|---|---|---|---|---|---|---|---|---|---|---|
| (500, 1 k, 10 k, 20 k, 30 k, 50 k) | (5 k, 10 k, 50 k, 200 k) | (64, 128, 256, 512) | (8, 16, 64, 128, 256) | (200, 400, 600, 800) | (1, 2, 3, 4, None) | (Relu, Sigmoid, Gelu, Tanh) | (categorical crossentropy, crossentropy loss) | (Adam, AdamW) | (0.01, , ) | |
| CNN | 10,000 | 1000 | 128 | 256 | 100 | 4 | Relu | categorical crossenthropy | Adam | 0.01 |
| Bi-LSTM | 10,000 | 1000 | 128 | 256 | 25 | None | Sigmoid | categorical cross entropy | Adam | 0.01 |
| GRU | 10,000 | 1000 | 128 | 256 | 128 | 3 | Sigmoid | categorical cross entropy | Adam | |
| Bert | 30,522 | 3072 | 512 | 8 | 768 | None | Gelu | cross entropy loss | AdamW | |
| RoBERTa | 50,000 | 3072 | 514 | 8 | 768 | None | Gelu | cross entropy loss | AdamW | |
| ERNIE | 18,000 | 3072 | 256 | 8 | 768 | None | Relu | cross entropy loss | AdamW |
| Configuration Name | Version |
|---|---|
| Tensorflow | 2.8.0 |
| Python | 3.7.7 |
| Jupyter notebook | 6.2.0 |
| GPU | Tesla P100-PCIE-12 GB |
| GPU Memory | 12 GB HBM2 |
| System Interface | PCI e 3.0 * 16 |
| Power Consumption | 250 w |
| Naive Bayes | Gradient Boosting | XG Boost | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| -fold | TP | TN | FN | FP | TP | TN | FN | FP | TP | TN | FN | FP |
| 1 | 276 | 64,735 | 1455 | 3 | 1154 | 64,638 | 577 | 100 | 1322 | 64,623 | 409 | 115 |
| 2 | 271 | 64,659 | 1536 | 3 | 1166 | 64,584 | 641 | 78 | 1363 | 64,562 | 444 | 100 |
| 3 | 275 | 64,758 | 1432 | 3 | 1068 | 64,682 | 639 | 79 | 1272 | 64,636 | 435 | 125 |
| 4 | 267 | 64,732 | 1465 | 4 | 1112 | 64,644 | 620 | 92 | 1284 | 64,620 | 448 | 116 |
| 5 | 261 | 64,729 | 1469 | 8 | 1075 | 64,461 | 655 | 96 | 1286 | 64,606 | 444 | 131 |
| Mean | 270 | 64,722 | 1471 | 4 | 1115 | 64,601 | 626 | 89 | 1305 | 64,609 | 436 | 117 |
| CatBoosting | SVM | |||||||||||
| -fold | TP | TN | FN | FP | TP | TN | FN | FP | ||||
| 1 | 1302 | 64,621 | 429 | 117 | 1370 | 64,635 | 361 | 103 | ||||
| 2 | 1373 | 64,565 | 434 | 97 | 1407 | 64,570 | 400 | 92 | ||||
| 3 | 1256 | 64,646 | 451 | 115 | 1301 | 64,666 | 406 | 95 | ||||
| 4 | 1303 | 64,621 | 429 | 115 | 1355 | 64,624 | 377 | 112 | ||||
| 5 | 1287 | 64,611 | 443 | 126 | 1304 | 64,634 | 426 | 103 | ||||
| Mean | 1304 | 64,612 | 437 | 114 | 1347 | 64,625 | 394 | 101 | ||||
| GRU | Bi-LSTM | CNN | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| -fold | TP | TN | FN | FP | TP | TN | FN | FP | TP | TN | FN | FP |
| 1 | 1334 | 64,513 | 397 | 225 | 1251 | 64,588 | 480 | 150 | 1304 | 64,553 | 427 | 185 |
| 2 | 1328 | 64,537 | 497 | 125 | 1301 | 64,514 | 506 | 148 | 1403 | 64,392 | 404 | 270 |
| 3 | 1260 | 64,599 | 447 | 162 | 1238 | 64,652 | 469 | 109 | 1205 | 64,633 | 502 | 128 |
| 4 | 1205 | 64,643 | 527 | 93 | 1169 | 64,666 | 563 | 70 | 1189 | 64,632 | 543 | 104 |
| 5 | 1280 | 64,575 | 450 | 162 | 1278 | 64,584 | 452 | 153 | 1289 | 64,563 | 441 | 174 |
| Mean | 1281 | 64,573 | 460 | 153 | 1247 | 64,600 | 494 | 126 | 1278 | 64,554 | 463 | 172 |
| Bert | Roberta | ERNIE | ||||||||||
| -fold | TP | TN | FN | FP | TP | TN | FN | FP | TP | TN | FN | FP |
| 1 | 1437 | 64,590 | 294 | 148 | 1429 | 64,616 | 302 | 122 | 1430 | 64,603 | 301 | 135 |
| 2 | 1438 | 64,597 | 293 | 141 | 1539 | 64,508 | 268 | 154 | 1486 | 64,562 | 321 | 100 |
| 3 | 1423 | 64,623 | 284 | 138 | 1525 | 64,495 | 282 | 167 | 1395 | 64,641 | 312 | 120 |
| 4 | 1454 | 64,613 | 278 | 123 | 1428 | 64,592 | 304 | 144 | 1401 | 64,529 | 331 | 207 |
| 5 | 1411 | 64,602 | 319 | 135 | 1390 | 64,580 | 340 | 157 | 1394 | 64,632 | 336 | 105 |
| Mean | 1432 | 64,605 | 239 | 137 | 1462 | 64,558 | 299 | 148 | 1421 | 64,539 | 320 | 133 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmed, S.; Singh, M.; Doherty, B.; Ramlan, E.; Harkin, K.; Bucholc, M.; Coyle, D. An Empirical Analysis of State-of-Art Classification Models in an IT Incident Severity Prediction Framework. Appl. Sci. 2023, 13, 3843. https://doi.org/10.3390/app13063843
Ahmed S, Singh M, Doherty B, Ramlan E, Harkin K, Bucholc M, Coyle D. An Empirical Analysis of State-of-Art Classification Models in an IT Incident Severity Prediction Framework. Applied Sciences. 2023; 13(6):3843. https://doi.org/10.3390/app13063843
Chicago/Turabian StyleAhmed, Salman, Muskaan Singh, Brendan Doherty, Effirul Ramlan, Kathryn Harkin, Magda Bucholc, and Damien Coyle. 2023. "An Empirical Analysis of State-of-Art Classification Models in an IT Incident Severity Prediction Framework" Applied Sciences 13, no. 6: 3843. https://doi.org/10.3390/app13063843
APA StyleAhmed, S., Singh, M., Doherty, B., Ramlan, E., Harkin, K., Bucholc, M., & Coyle, D. (2023). An Empirical Analysis of State-of-Art Classification Models in an IT Incident Severity Prediction Framework. Applied Sciences, 13(6), 3843. https://doi.org/10.3390/app13063843