

Gesture Detection and Recognition Based on Object Detection in Complex Background
Abstract
:1. Introduction
- A gesture recognition algorithm based on improved YOLOv5 is proposed for complex background scenarios.
- By using an efficient layer aggregation network module, the benchmark network YOLOv5 is enhanced for complex background gesture feature extraction. It can also effectively reduce model complexity and improve network recognition speed.
- The CBAM attention mechanism module is introduced to filter out irrelevant features and improve network robustness to complex backgrounds.
2. Related Work
3. Methodology
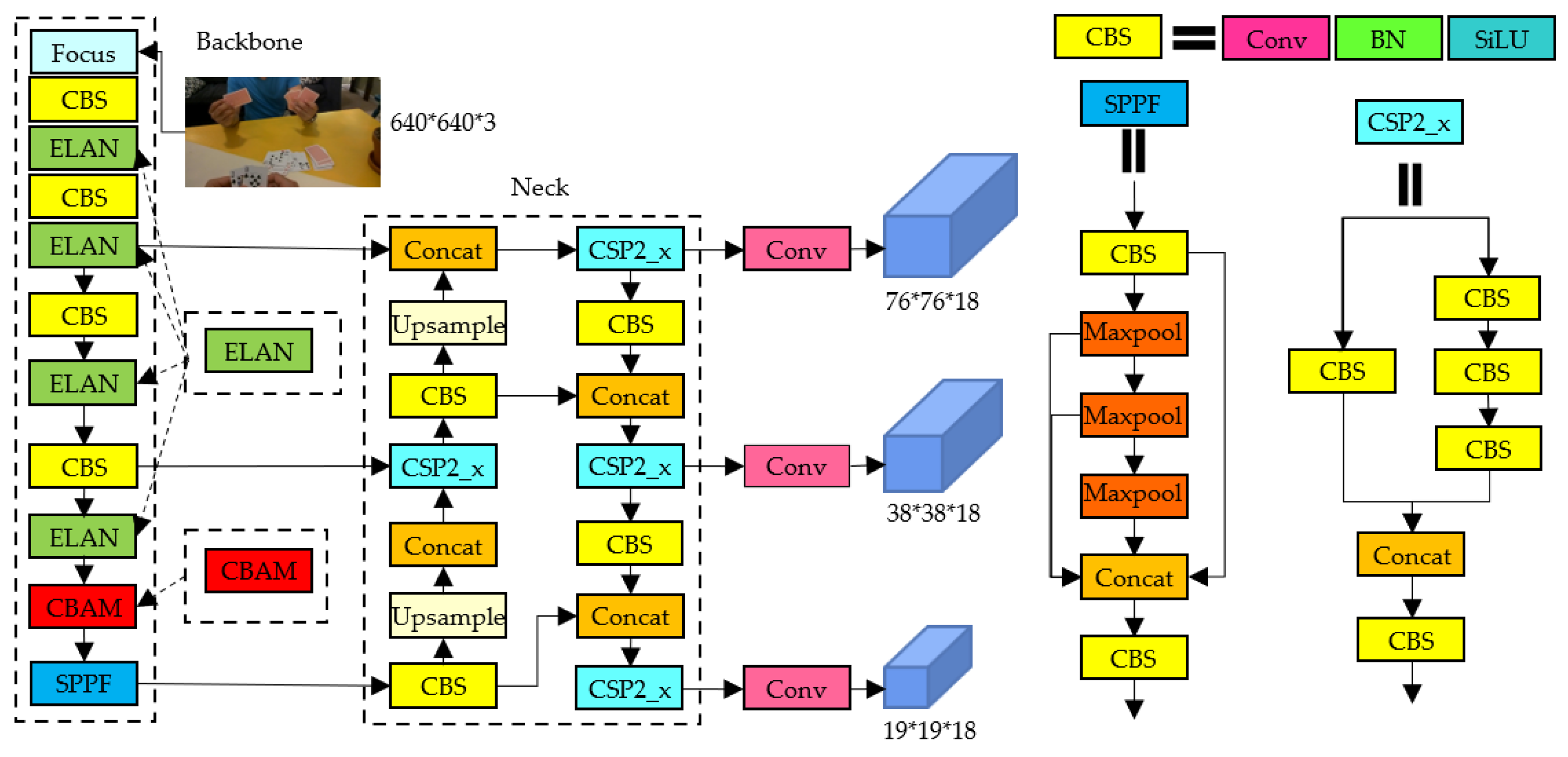
3.1. YOLOv5l
3.2. ELAN
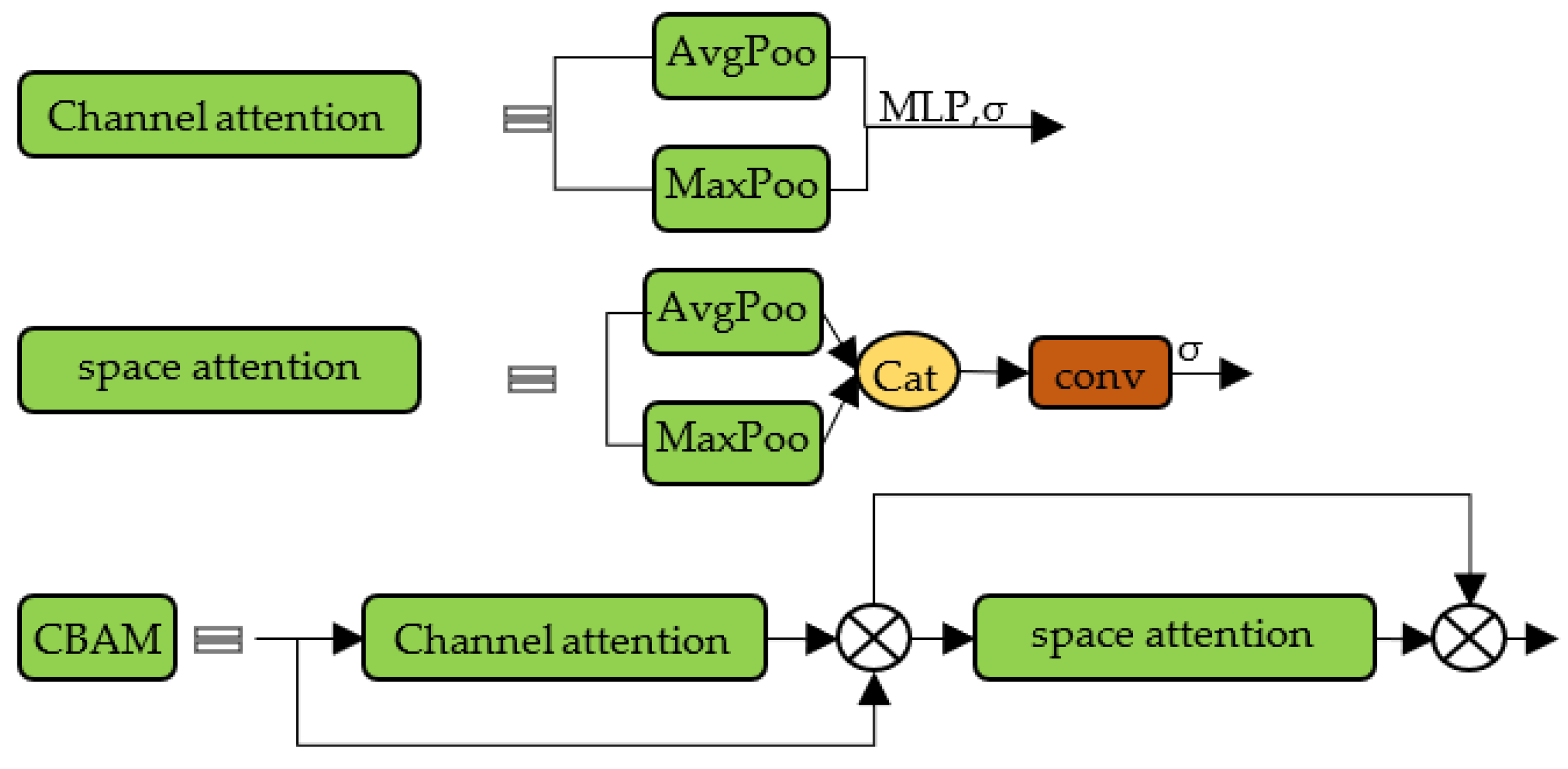
3.3. CBAM Attention Mechanism
3.4. Improved YOLOv5l
4. Experimental Evaluation
4.1. Experimental Environment and Datasets
4.2. Evaluation Indicators
4.3. Comparison with Other Gesture Recognition Methods
4.4. Ablation Experiments
4.5. Validation on Other Dataset
4.6. Comparison of Actual Test Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Guo, L.; Lu, Z.; Yao, L. Human-machine interaction sensing technology based on hand gesture recognition: A review. IEEE Trans. Hum.-Mach. Syst. 2021, 51, 300–309. [Google Scholar] [CrossRef]
- Ahmed, S.; Kallu, K.D.; Ahmed, S.; Cho, S.H. Hand Gestures Recognition Using Radar Sensors for Human-Computer-Interaction: A Review. Remote Sens. 2021, 13, 527. [Google Scholar] [CrossRef]
- Serrano, R.; Morillo, P.; Casas, S.; Cruz-Neira, C. An empirical evaluation of two natural hand interaction systems in augmented reality. Multimedia Tools Appl. 2022, 81, 31657–31683. [Google Scholar] [CrossRef]
- Tsai, T.H.; Huang, C.C.; Zhang, K.L. Design of hand gesture recognition system for human-computer interaction. Multimed. Tools Appl. 2020, 79, 5989–6007. [Google Scholar] [CrossRef]
- Gao, Q.; Chen, Y.; Ju, Z.; Liang, Y. Dynamic Hand Gesture Recognition Based on 3D Hand Pose Estimation for Human–Robot Interaction. IEEE Sens. J. 2021, 22, 17421–17430. [Google Scholar] [CrossRef]
- Liao, S.; Li, G.; Wu, H.; Jiang, D.; Liu, Y.; Yun, J.; Liu, Y.; Zhou, D. Occlusion gesture recognition based on improved SSD. Concurr. Comput. Pract. Exp. 2021, 33, e6063. [Google Scholar] [CrossRef]
- Sharma, S.; Singh, S. Vision-based hand gesture recognition using deep learning for the interpretation of sign language. Expert Syst. Appl. 2021, 182, 115657. [Google Scholar] [CrossRef]
- Parvathy, P.; Subramaniam, K.; Prasanna Venkatesan, G.K.D.; Karthikaikumar, P.; Varghese, J.; Jayasankar, T. Development of hand gesture recognition system using machine learning. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 6793–6800. [Google Scholar] [CrossRef]
- Yadav, K.S.; Kirupakaran, A.M.; Laskar, R.H.; Bhuyan, M.K.; Khan, T. Design and development of a vision-based system for detection, tracking and recognition of isolated dynamic bare hand gesticulated characters. Expert Syst. 2022, 39, e12970. [Google Scholar] [CrossRef]
- Chen, G.; Xu, Z.; Li, Z.; Tang, H.; Qu, S.; Ren, K.; Knoll, A. A Novel Illumination-Robust Hand Gesture Recognition System with Event-Based Neuromorphic Vision Sensor. IEEE Trans. Autom. Sci. Eng. 2021, 18, 508–520. [Google Scholar] [CrossRef]
- Li, H.; Wu, L.; Wang, H.; Han, C.; Quan, W.; Zhao, J.P. Hand Gesture Recognition Enhancement Based on Spatial Fuzzy Matching in Leap Motion. IEEE Trans. Ind. Inform. 2019, 16, 1885–1894. [Google Scholar] [CrossRef]
- Zhou, W.; Chen, K. A lightweight hand gesture recognition in complex backgrounds. Displays 2022, 74, 102226. [Google Scholar] [CrossRef]
- Chung, Y.L.; Chung, H.Y.; Tsai, W.F. Hand gesture recognition via image processing techniques and deep CNN. J. Intell. Fuzzy Syst. 2020, 39, 4405–4418. [Google Scholar] [CrossRef]
- Güler, O.; Yücedağ, İ. Hand gesture recognition from 2D images by using convolutional capsule neural networks. Arab. J. Scie. Eng. 2022, 47, 1211–1225. [Google Scholar] [CrossRef]
- Li, J.; Li, C.; Han, J.; Shi, Y.; Bian, G.; Zhou, S. Robust Hand Gesture Recognition Using HOG-9ULBP Features and SVM Model. Electronics 2022, 11, 988. [Google Scholar] [CrossRef]
- Jain, R.; Karsh, R.K.; Barbhuiya, A.A. Literature review of vision-based dynamic gesture recognition using deep learning techniques. Concurrency and Computation: Pract. Exp. 2022, 34, e7159. [Google Scholar] [CrossRef]
- Hu, B.; Wang, J. Deep Learning Based Hand Gesture Recognition and UAV Flight Controls. Int. J. Autom. Comput. 2019, 17, 17–29. [Google Scholar] [CrossRef]
- Dong, Y.; Liu, J.; Yan, W. Dynamic Hand Gesture Recognition Based on Signals from Specialized Data Glove and Deep Learning Algorithms. IEEE Trans. Instrum. Meas. 2021, 70, 1–14. [Google Scholar] [CrossRef]
- Al-Hammadi, M.; Muhammad, G.; Abdul, W.; Alsulaiman, M.; Bencherif, M.A.; Alrayes, T.S.; Mathkour, H.; Mekhtiche, M.A. Deep Learning-Based Approach for Sign Language Gesture Recognition with Efficient Hand Gesture Representation. IEEE Access 2020, 8, 192527–192542. [Google Scholar] [CrossRef]
- Wang, X.; Zhu, Z. Vision-based hand signal recognition in construction: A feasibility study. Autom. Constr. 2021, 125, 103625. [Google Scholar] [CrossRef]
- Mahmoud, R.; Belgacem, S.; Omri, M.N. Towards wide-scale continuous gesture recognition model for in-depth and grayscale input videos. Int. J. Mach. Learn. Cybern. 2021, 12, 1173–1189. [Google Scholar] [CrossRef]
- Mahmoud, R.; Belgacem, S.; Omri, M.N. Deep signature-based isolated and large scale continuous gesture recognition approach. J. King Saud Univ.—Comput. Inf. Sci. 2020, 34, 1793–1807. [Google Scholar] [CrossRef]
- Wan, J.; Lin, C.; Wen, L.; Li, Y.; Miao, Q.; Escalera, S.; Anbarjafari, G.; Guyon, I.; Guo, G.; Li, S.Z. ChaLearn Looking at People: IsoGD and ConGD Large-Scale RGB-D Gesture Recognition. IEEE Trans. Cybern. 2020, 52, 3422–3433. [Google Scholar] [CrossRef] [PubMed]
- Deng, M. Robust human gesture recognition by leveraging multi-scale feature fusion. Signal Process. Image Commun. 2019, 83, 115768. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhang, S.; Wen, L.; Lei, Z.; Li, S.Z. RefineDet++: Single-shot refinement neural network for object detection. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 674–687. [Google Scholar] [CrossRef]
- Fang, Z.; Cao, Z.; Xiao, Y.; Gong, K.; Yuan, J. MAT: Multianchor Visual Tracking with Selective Search Region. IEEE Trans. Cybern. 2020, 52, 7136–7150. [Google Scholar] [CrossRef]
- Wang, R.; Jiao, L.; Xie, C.; Chen, P.; Du, J.; Li, R. S-RPN: Sampling-balanced region proposal network for small crop pest detection. Comput. Electron. Agric. 2021, 187, 106290. [Google Scholar] [CrossRef]
- Chaudhary, A.; Raheja, J.L. Light invariant real-time robust hand gesture recognition. Optik 2018, 159, 283–294. [Google Scholar] [CrossRef]
- Yang, X.W.; Feng, Z.Q.; Huang, Z.Z.; He, N.N. Gesture recognition by combining gesture principal direction and Hausdorff-like distance. J. Comput.-Aided Des. Comput. Graph. 2016, 28, 75–81. [Google Scholar]
- Ma, J.; Zhang, X.D.; Yang, N.; Tian, Y. Gesture recognition method combining dense convolution and spatial transformation network. J. Electron. Inf. Technol. 2018, 40, 951–956. [Google Scholar]
- Xu, C.; Cai, W.; Li, Y.; Zhou, J.; Wei, L. Accurate Hand Detection from Single-Color Images by Reconstructing Hand Appearances. Sensors 2019, 20, 192. [Google Scholar] [CrossRef] [Green Version]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A.A. Generative Adversarial Networks: An Overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Soe, H.M.; Naing, T.M. Real-time hand pose recognition using faster region-based convolutional neural network. In Proceedings of the First International Conference on Big Data Analysis and Deep Learning; Springer: Singapore, 2019; pp. 104–112. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; p. 28. [Google Scholar]
- Fu, L.; Feng, Y.; Majeed, Y.; Zhang, X.; Zhang, J.; Karkee, M.; Zhang, Q. Kiwifruit detection in field images using Faster R-CNN with ZFNet. IFAC-PapersOnLine 2018, 51, 45–50. [Google Scholar] [CrossRef]
- Pisharady, P.K.; Vadakkepat, P.; Loh, A.P. Attention based detection and recognition of hand postures against complex backgrounds. Int. J. Comput. Vis. 2013, 101, 403–419. [Google Scholar] [CrossRef]
- Wang, F.H.; Huang, C.; Zhao, B.; Zhang, Q. Gesture recognition based on YOLO algorithm. Trans. Beijing Inst. Technol. 2020, 40, 873–879. [Google Scholar]
- Xin, W.B.; Hao, H.M.; Bu, M.L. Static gesture real-time recognition method based on ShuffleNetv2-YOLOv3 model. J. Zhejiang Univ. (Eng. Sci.) 2021, 55, 1815–1824+1846. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Lu, D.; Ma, W.Q. Gesture Recognition Based on Improved YOLOv4-tiny Algorithm. J. Electron. Inf. Technol. 2021, 43, 3257–3265. [Google Scholar]
- Osipov, A.; Shumaev, V.; Ekielski, A.; Gataullin, T.; Suvorov, S.; Mishurov, S.; Gataullin, S. Identification and Classification of Mechanical Damage During Continuous Harvesting of Root Crops Using Computer Vision Methods. IEEE Access 2022, 10, 28885–28894. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bao, P.; Maqueda, A.I.; del-Blanco, C.R.; García, N. Tiny hand gesture recognition without localization via a deep convolutional network. IEEE Trans. Consum. Electron. 2017, 63, 251–257. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; He, M.; Wang, X.; Yao, W. Sewing gesture recognition based on improved YOLO deep convolutional neural network. J. Text. Res. 2020, 41, 142–148. [Google Scholar]
- Peng, Y.; Zhao, X.; Tao, H.; Liu, X.; Li, T. Hand Gesture Recognition against Complex Background Based on Deep Learning. Robot 2019, 41, 534–542. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Yeh, I.H. Designing Network Design Strategies Through Gradient Path Analysis. arXiv 2022, arXiv:2211.04800. [Google Scholar]
- Bambach, S.; Lee, S.; Crandall, D.J.; Yu, C. Lending a hand: Detecting hands and recognizing activities in complex egocentric interactions. In Proceedings of the International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1949–1957. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Lee, Y.; Park, J. Centermask: Real-time anchor-free instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13906–13915. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Precision/% | Recall/% | mAP/% | FPS | Model Size/MB | GFLOPs |
|---|---|---|---|---|---|---|
| YOLOv3-tiny-T | 95.1 | 90.3 | 66.0 | 227 | 9.4 | 7.2 |
| ShuffleNetv2-YOLOv3 | 92.8 | 78.8 | 61.6 | 69 | 49.1 | 42.5 |
| YOLOv5l | 96.2 | 92.2 | 73.5 | 54 | 92.8 | 108.2 |
| YOLOv7 | 92.6 | 83.8 | 59.5 | 68 | 74.8 | 105.1 |
| literature [50] | 96.1 | 90.1 | 68.5 | 31 | 122.6 | 152.0 |
| proposed algorithm | 97.8 | 94.4 | 75.6 | 64 | 88.3 | 97.2 |
| Method | Precision/% | Recall/% | mAP/% | FPS | Model Size/MB | GFLOPs |
|---|---|---|---|---|---|---|
| YOLOv5l | 96.2 | 92.2 | 73.5 | 54 | 92.8 | 108.2 |
| YOLOv5l + ShuffleNetv2 | 92.2 | 89.4 | 69.3 | 31 | 47 | 42.1 |
| YOLOv5l + E-ELAN | 97.0 | 90.5 | 73.5 | 70 | 73.5 | 76.8 |
| YOLOv5l + VoVNetv2 | 96.8 | 92.3 | 73.6 | 27 | 103.2 | 107.7 |
| YOLOv5l + ELAN | 97.3 | 93.5 | 74.8 | 71 | 84.1 | 95.1 |
| YOLOv5l + ELAN + sSE | 97.2 | 89.8 | 72.7 | 58 | 88.5 | 96.9 |
| YOLOv5l + ELAN + CBAM | 97.8 | 94.4 | 75.6 | 64 | 88.3 | 97.2 |
| Method | Precision/% | Recall/% | mAP/% |
|---|---|---|---|
| YOLOv3-tiny-T | 94.1 | 97.6 | 65.1 |
| YOLOv5l | 97.4 | 98.3 | 65.3 |
| YOLOv7 | 96.2 | 98.6 | 64.5 |
| Proposed method | 97.7 | 99.3 | 66.8 |
| Hand Classes | Precision/% | Recall/% | mAP/% |
|---|---|---|---|
| fist | 97.6 | 99.3 | 66.8 |
| l | 100 | 100 | 58.3 |
| OK | 96.5 | 95.2 | 70.9 |
| palm | 96.5 | 100 | 69.7 |
| pointer | 96.7 | 100 | 56.2 |
| thumb down | 99.1 | 100 | 69.9 |
| thumb up | 97.4 | 100 | 70.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, R.; Tian, X. Gesture Detection and Recognition Based on Object Detection in Complex Background. Appl. Sci. 2023, 13, 4480. https://doi.org/10.3390/app13074480
Chen R, Tian X. Gesture Detection and Recognition Based on Object Detection in Complex Background. Applied Sciences. 2023; 13(7):4480. https://doi.org/10.3390/app13074480
Chicago/Turabian StyleChen, Renxiang, and Xia Tian. 2023. "Gesture Detection and Recognition Based on Object Detection in Complex Background" Applied Sciences 13, no. 7: 4480. https://doi.org/10.3390/app13074480
APA StyleChen, R., & Tian, X. (2023). Gesture Detection and Recognition Based on Object Detection in Complex Background. Applied Sciences, 13(7), 4480. https://doi.org/10.3390/app13074480